Le sujet du projet est d’étudier la vie multilingue d’un mot sur le web. Pour être plus précis, nous allons observer et un mot et son contexte au sein d’un corpus que nous allons tirer du web, puis les analyser grâce aux outils du traitement automatique des langues.
Plus d'infosPremière partie et pas des moindres, faire une liste d'URLS dont nous allons extraire le contenu des pages associées. Nous avons donc parcouru le web (enfin, on a utilisé Google quoi) pour trouver des sites web qui parlent du président de la Mère Patrie. Nous avons toutefois décidé de nous focaliser essentiellement sur des sites d'actualité, et le tout en français, en anglais et en russe.
Ensuite...Deuxième partie, parce qu'on aime bien en faire plus, aller chercher des tweets à propos de Vladimir. À ce sujet, voir les articles sur le blog du projet : poutineinput.wordpress.com qui détaillent l'aspect technique d'une telle manipulation.
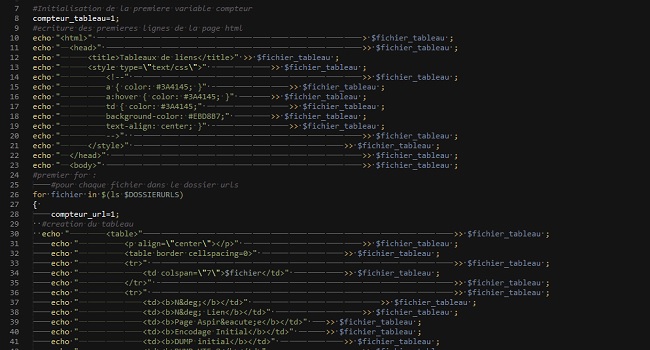
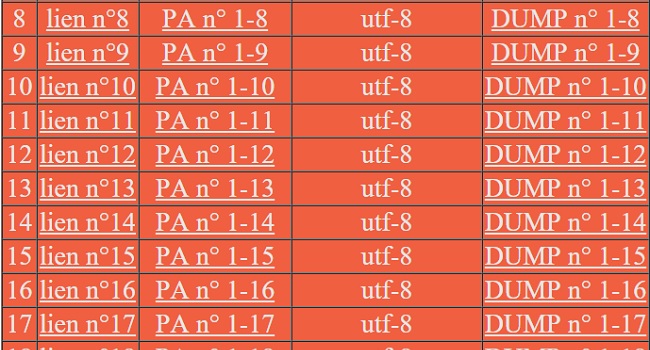
Ensuite...Le cœur du projet, le nerf de la guerre, un script tout-en-un qui extrait les pages web, en récupère le texte, le convertit en UTF-8, et insère le tout dans un tableau html. Une grosse prise de tête, un bel exercice de programmation. La suite ? Le script ici : Script
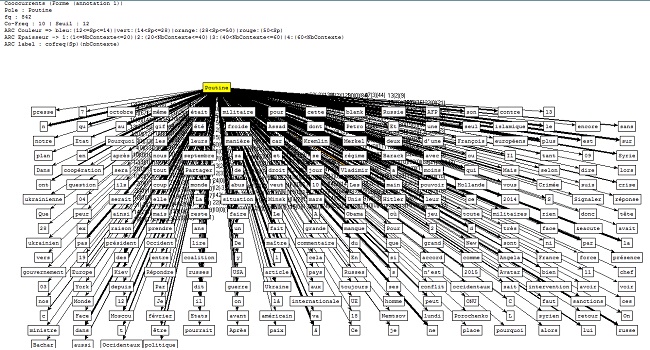
Ensuite...Nous avons tout d'abord écrit un script (disponible ici) pour extraire les contextes dans lesquels apparaît le nom de l'actuel président russe, pour ensuite faire quelques analyses à l'aide du Trameur. Voici les graphes des coocurrents (cliquez pour agrandir) :
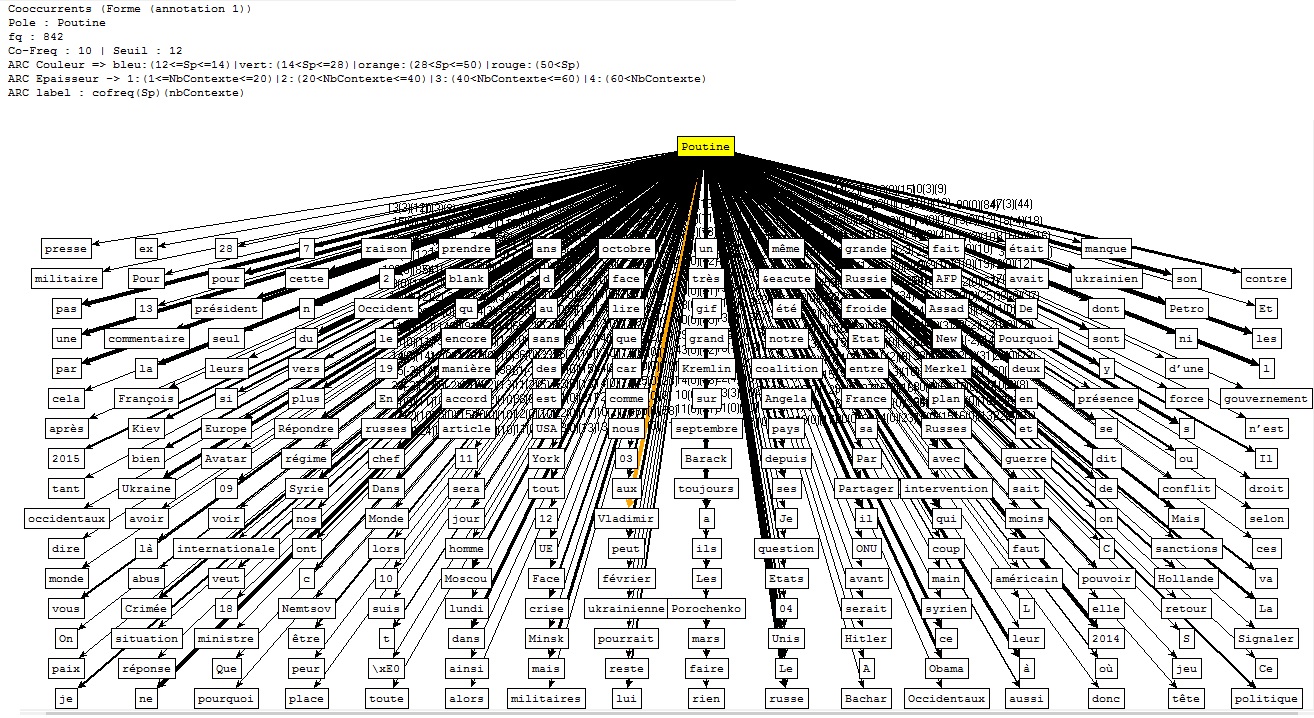
Cooccurrents pour le corpus d'Urls en Français
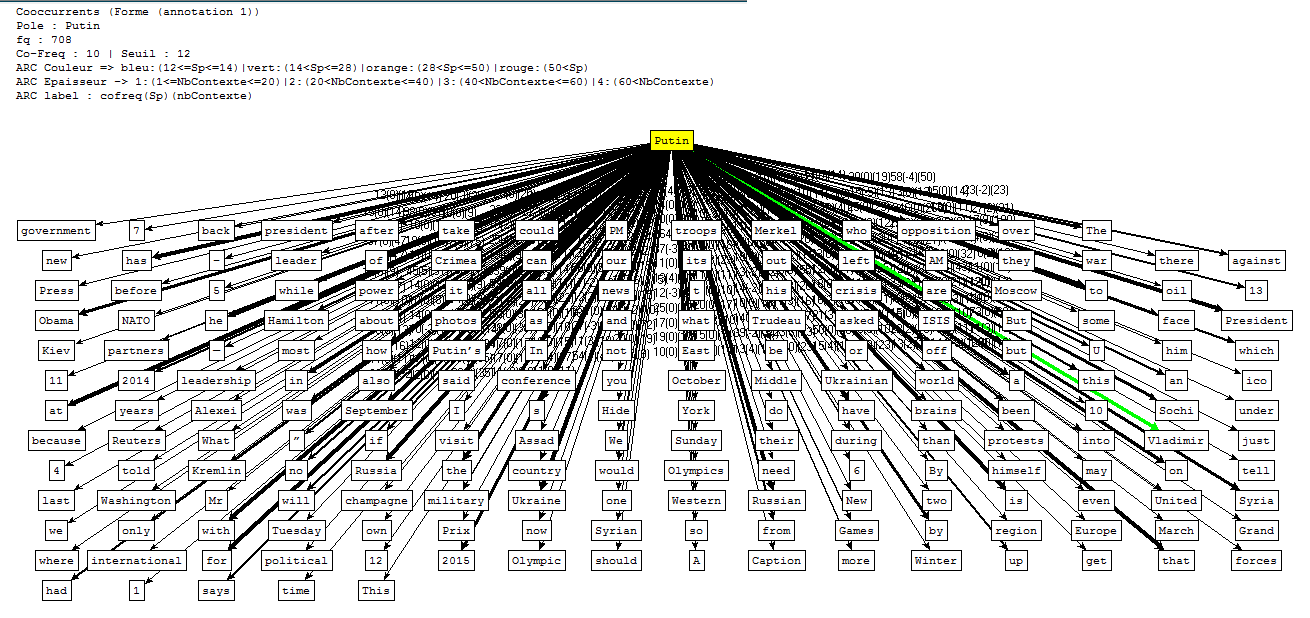
Cooccurrents pour le corpus d'Urls en Anglais
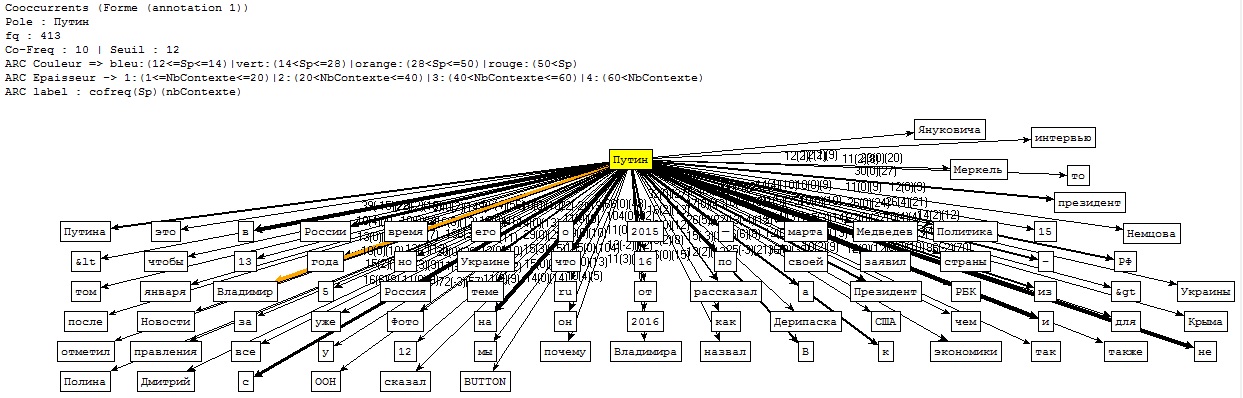
Cooccurrents pour le corpus d'Urls en Russe
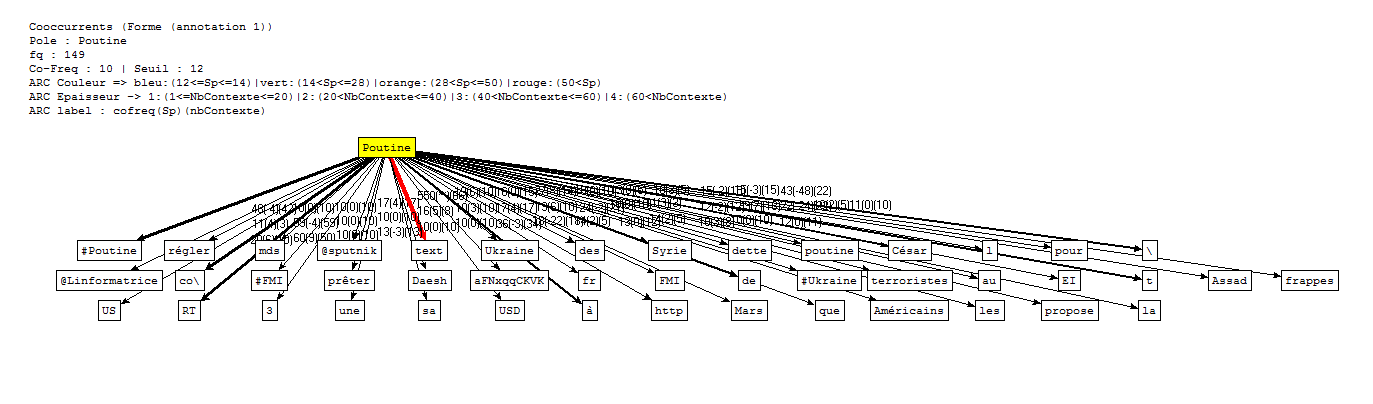
Cooccurrents pour le corpus Twitter en Français
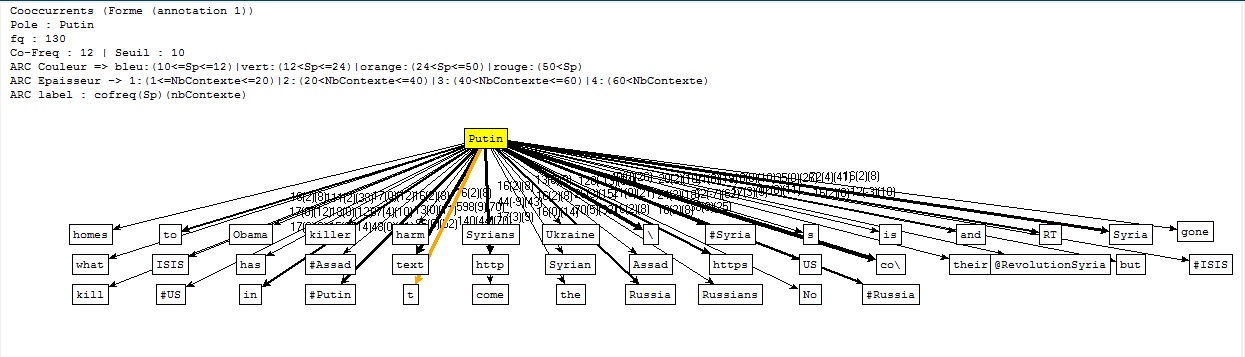
Cooccurrents pour le corpus Twitter en Anglais
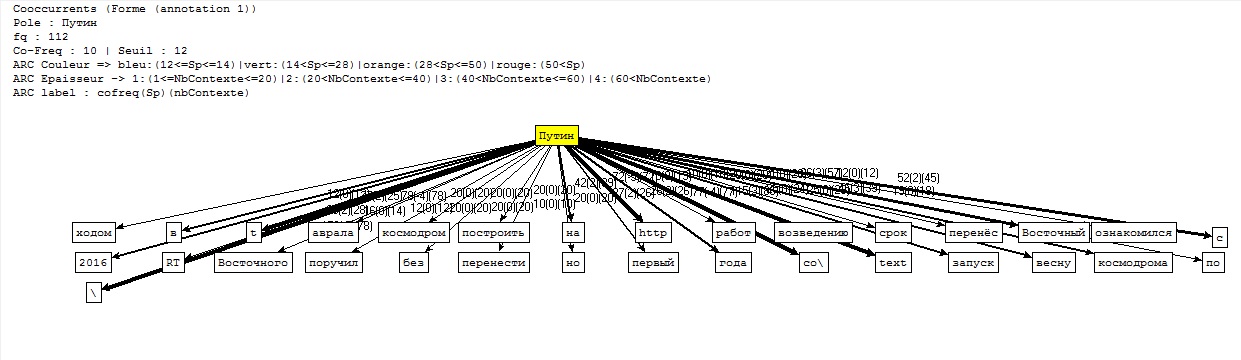
Cooccurrents pour le corpus Twitter en Russe
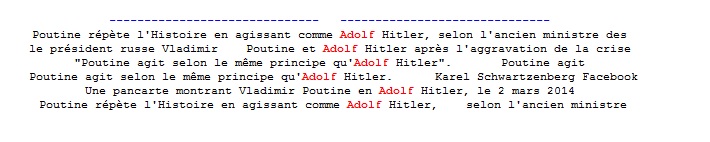
BONUS : un petit point Godwin.
Allez, quelques petits nuages de mots pour finir ! (cliquez pour agrandir)