
Le Trameur / iTrameur aka Le Métier Textométrique
Dans une perspective lexicométrique / textométrique, représentation du texte en machine sous la forme d'une Trame et d'un Cadre (i.e le métier textométrique), pour ensuite réaliser des calculs textométriques.
Le Trameur est un programme danalyse comportant de nombreuses fonctionnalités pour lanalyse automatique, statistique et documentaire de textes en vue de leur profilage sémantique, thématique et de leur interprétation. Ce logiciel est à lorigine un outil de textométrie : il intègre les fonctionnalités classiques de ce type doutils dans ce domaine. Il dispose aussi des fonctionnalités particulières qui permettent dannoter dynamiquement des corpus ou dexplorer des ressources richement annotées (treebanks monolingues/multilingues ou des alignements). Présentation et téléchargement du logiciel ci-dessous.
iTrameur est une application en ligne mettant en oeuvre les fonctionnalités disponibles dans Le Trameur. Application à utiliser dans votre navigateur habituel à cette adresse : http://www.tal.univ-paris3.fr/trameur/iTrameur/
![]()
Sommaire
- Actus Le Trameur / iTrameur
- Préambule
- Trame et Cadre : les objets de la textométrie
- Le Trameur Version GUI
- Documentation
- Formats de fichier pour créer une nouvelle base textométrique
- Démo : construire et explorer un corpus issu du web en 4 fiches
- Exemples de Bases Textométriques
- Rapports d'analyse construits
- Nuages d'annotations sur la Trame
- Téléchargement
- Copies d'écran
- iTrameur Version "sur la toile"
- Le Trameur Version console
- Liens
- Lectures
- Programmes complémentaires
![]()
Actus Le Trameur / iTrameur
[10/2020] iTrameur-Ecriscol. Une version de iTrameur pour l'exploration d'un corpus de copies d'élèves (Projet ECRISCOL) : http://www.tal.univ-paris3.fr/trameur/iTrameur-Ecriscol/ (prototype en cours de mise au point).
[05/2020] iTrameur-Naija. Une version de iTrameur pour l'exploration du Naija (Projet NAIJA SYNCOR) : http://www.tal.univ-paris3.fr/trameur/iTrameur-naija/admin-dashboard.html.
08/09/2019 Dernière mise à jour de Le Trameur, version : 12.176 (Téléchargement)
[07/2019] Trameur 12.174. Mise à jour : Module d'export vers iTrameur. Labélisation des annotations dans une base (via export ou import). Illustration sur la nouvelle version de la base Rhapsodie pour le Trameur : "Rhapsodie2Trameur" (v8) avec labels
[07/2018] iTrameur. Mise à jour : intégration d'une labélisation des annotations sur la première ligne d'une base annotée. Bases de test en ligne, cf Onglet Aide : http://www.tal.univ-paris3.fr/trameur/iTrameur.
[06/2019] Trameur 12.170. Mise à jour : annotation de sections (cf PDF).
[05/2019] iTrameur Fonctions avancées de lanalyse textométrique pour les corpus multiannotés (M. Zimina) : le 6 mai 2019, salle 208 ODG, Paris Diderot. Ressources en ligne.
[03/2019] iTrameur Formation Introduction à la textométrie multilingue (M. Zimina) : le 11 mars 2019, salle 208 ODG, Paris Diderot . Ressources en ligne.
[12/2018] Trameur 12.164. Mise à jour : Nouvelles fonctionnalités sur corpus chronologique : calcul du barycentre temporel et du coefficient de Von Neumann pour la mise au jour de termes évolutifs, cf "Les séries textuelles chronologiques", André Salem, 1991.
[12/2018] iTrameur : Nombreuses mises à jour, cf documentation en ligne (onglet Aide) : http://www.tal.univ-paris3.fr/trameur/iTrameur.
[11/2018] CORLI : 15/11/2018 Formation "Explorer un corpus annoté avec le Trameur / iTrameur. Ressources en ligne.
[03/2018] iTrameur : Nombreuses mises à jour, cf documentation en ligne (onglet Aide) : http://www.tal.univ-paris3.fr/trameur/iTrameur.
[12/2017] iTrameur : Nombreuses mises à jour, cf documentation en ligne : http://www.tal.univ-paris3.fr/trameur/iTrameur.
[10/2017] CORLI : 25 26 octobre Formation JE Annotation. Ressources en ligne.
[09/2017] Trameur 12.154. Mise à jour : 2 modes de calcul pour les cooccurrents (cf DOC).
[04/2017] iTrameur : Nombreuses mises à jour, cf documentation en ligne : http://www.tal.univ-paris3.fr/trameur/iTrameur.
[03/2017] iTrameur : Application utilisable dans votre navigateur habituel et reproduisant des calculs disponibles dans Le Trameur : http://www.tal.univ-paris3.fr/trameur/iTrameur.
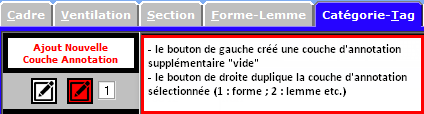
[01/2017] La version 12.148 intègre 1 mise à jour permettant de créer une couche "vide" d'annotation, de dupliquer une couche d'annotation existante, de fusionner 2 ou plusieurs couches d'annotations (en "fusionnant" les valeurs des couches visées).
Pour créer une couche fusionnant des couches d'annotation,
par exemple les couches 2 et 3, il suffit de le noter ainsi dans la zone de saisie : 2&3[12/2016] iTrameur : Des programmes en ligne (utilisables dans votre navigateur habituel) et reproduisant des calculs disponibles dans Le Trameur : http://www.tal.univ-paris3.fr/trameur/#iTrameur.
[12/2016] La version 12.144 intègre 2 mises à jour : (1) sélection de termes associés à un patron (dans module "recherche de patron") ; (2) Sélection de MOTIFs : un nouvel onglet dans le Gestionnaire de Sélections permet de rechercher des MOTIFs et de sélectionner leurs occurrences en contexte : mise au jour d'une suite d'items de longueur arbitraire de la Trame en correspondance avec un modèle prédéfini (le MOTIF). Un fichier d'exemple de motifs est fourni après installation (dans le dossiers motifs du dossier d'installation). Documentation provisoire.
[11/2016] CORLI : 14 15 novembre Formation aux outils dexploration de corpus. Ressources en ligne.
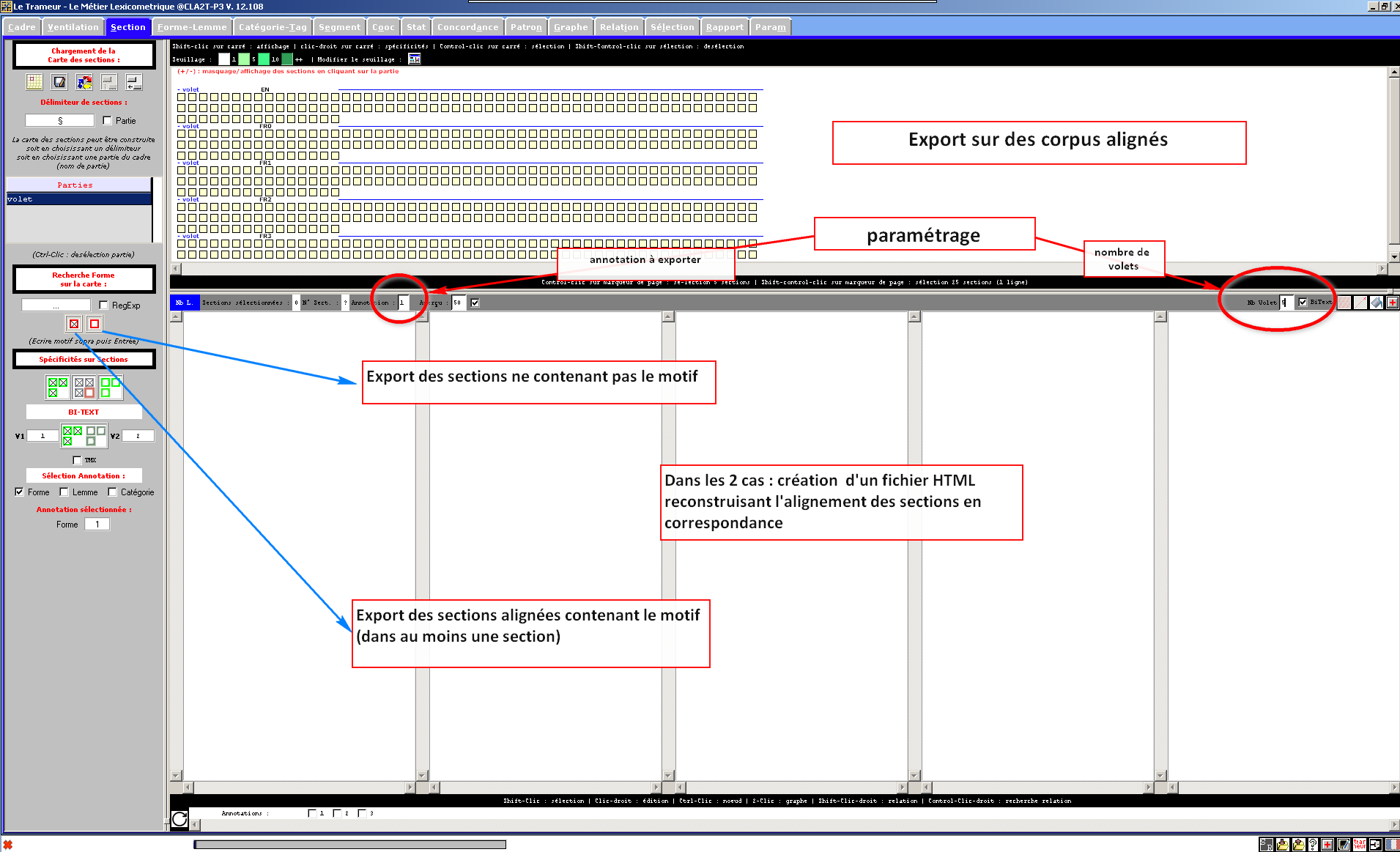
[09/2016] La version 12.126 intègre une mise à jour pour l'affichage simultané des sections de ressources alignées (pas de limite pour le nombre de sections alignées à afficher simultanément) + correctif format de corpus alignés + nouvelles langues pour treetagger (cf infra).
[06/2016] La version 12.120 intègre une mise à jour pour le calcul des dépendances syntaxiques spécifiques.
[05/2016] La version 12.116 intègre : (1) une mise à jour sur l'interface graphique de certains onglets (TFG, concordance) ; (2) calcul de cooccurrence sur tous les niveaux d'annotation.
[05/2016] Mise à jour de la documentation : Insertion ou modification d'annotations, cf parties 22 et 23.
[04/2016] La version 12.110 intègre de nouvelles fonctionnalités pour le traitement des corpus alignés. Illustration ci-dessous :
[clic sur image pour détails]Exemples de sortie :
- (1) Alignement avec présence du motif (annotation n°1 : forme),
- (2) Alignement avec présence du motif (annotation n°2 : lemme),
- (3) Alignement avec absence du motif (annotation n°1 : forme),
- (4) Alignement complet (annotation n°1 : forme).
- Les motifs cherchés sont matérialisés en rouge gras, les items préalablement sélectionnés via le Gestionnaire sont matérialisés en jaune.
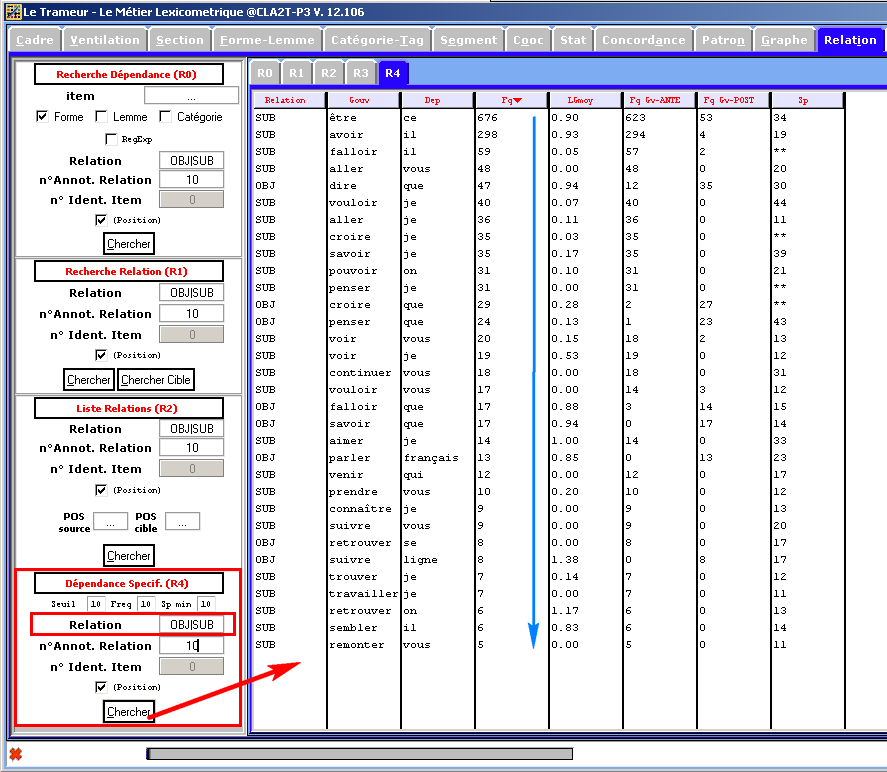
[03/2016] La version 12.106 intègre un module permettant de mettre au jour toutes les dépendances spécifiques ; cf figure ci-dessous, sur la base Rhapsodie, recherche des dépendances spécifiques sur la relation OBJ (objet) ou SUB (sujet) :
[clic sur image pour détails][02/2016]
Le Trameur arrive sous MacOsX : une première distribution du Trameur est désormais disponible pour MacOsX (cf Téléchargement)
[02/2016] La version 12.104 intègre notamment des maj sur l'AFC (projection des mots ou des segments répétés sur le graphique de l'AFC) : cf figure ci-dessous.
AFC, partition sélectionnée, annotation n°1 (forme), projection d'items sur le graphe.
Corpus LIBERATION 1998-2012, (taille : 8.000.000 mots)[11/2015] Zimina Maria, Fleury Serge, "Perspectives de larchitecture Trame/Cadre pour les alignements multilingues". Nouvelles perspectives en sciences sociales : revue internationale de systémique complexe et d'études relationnelles, volume 11, numéro 1, novembre 2015.
http://www.erudit.org/revue/npss/2015/v11/n1/index.html
[Résumé][10/2015] Améliorations des performances du "Moteur C" du Trameur.
[09/2015] Intégration de nouvelles fonctionnalités pour la recherche de relation de dépendances ; amélioration du rendu graphique des ventilations ; mise à jour du gestionnaire de sélections (sélection de spécificités) ; diverses mises à jour mineures.
[06/2015] Intégration de nouvelles fonctionnalités pour la recherche de relation de dépendances (cf documentation en ligne, parties 25.4 et 25.12) et de nouvelles fonctionnalités d'exploration des bases textométriques intégrant des alignements de texte via notamment un éditeur de sections multi-volets (cf documentation en ligne, partie 30.2).
[03/2015] Mise en place d'une interface bilingue (français/anglais) et d'un traitement spécifique pour les bases textométriques intégrant 2 (ou plusieurs) textes alignés (cf ce PDF pour la présentation de cette fonctionnalité) ; les modules "Inventaire typographique" et "Inventaire des parties" permettent d'aider à la préparation/correction d'une nouvelle base ; mise à jour du module de concordance et du module d'affichage des relations de dépendance dans une section ; mise en place du module petiMoteur : création d'une base textométrique à partir d'une liste d'URLs ; graphiques de ventilation en sélectionnant des éléments relevant de différents niveaux d'annotation ; graphiques de ventilation sur une sélection de parties d'une partition donnée (via le gestionnaire de sélection).
Pour toutes ces mises à jour : cf documentation.[08/2014] Serge Fleury and Maria Zimina, Trameur: A Framework for Annotated Text Corpora Exploration, Proceedings of COLING 2014, the 25th International Conference on Computational Linguistics: System Demonstrations, August 2014, Dublin, Ireland, pages 57-61, (PDF). Slides (PDF)
![]()
Préambule
L'objectif principal de la textométrie est de compter des éléments (des contenus textuels) dans des ensembles (des contenants regroupant des unités élémentaires d'un texte ou des zones de texte couvrant un certain nombre ou un certain type d'unités élémentaires).
- Les contenus se réalisent sous la forme de ressources textuelles (une séquence de caractères organisée en phrases, en paragraphes etc.).
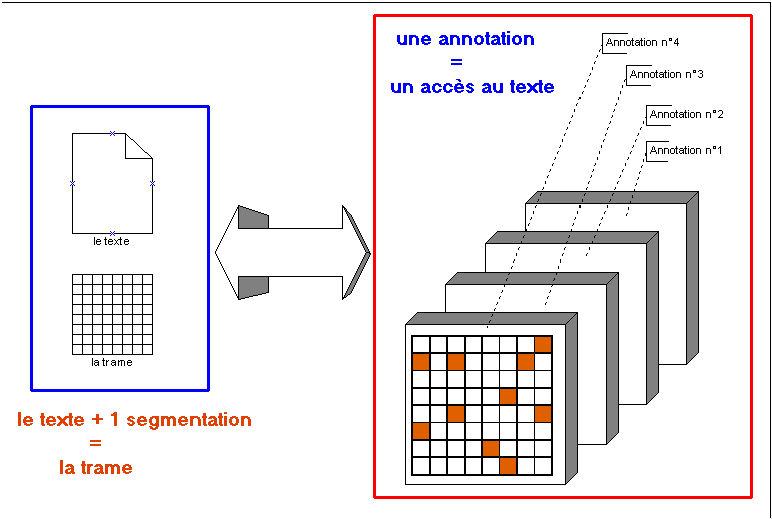
- Les contenants existent sous la forme de système de masques ou de calques que l'on peut définir sur les contenus. Il s'agit de systèmes d'annotations que l'on peut définir sur tout ou partie des zones textuelles, ces annotations constituant en retour des accès sur les parties textuelles qu'elles définissent (le marquage des phrases ou des paragraphes étant un exemple d'annotation particulier pour décrire un certain niveau de la structure du texte).
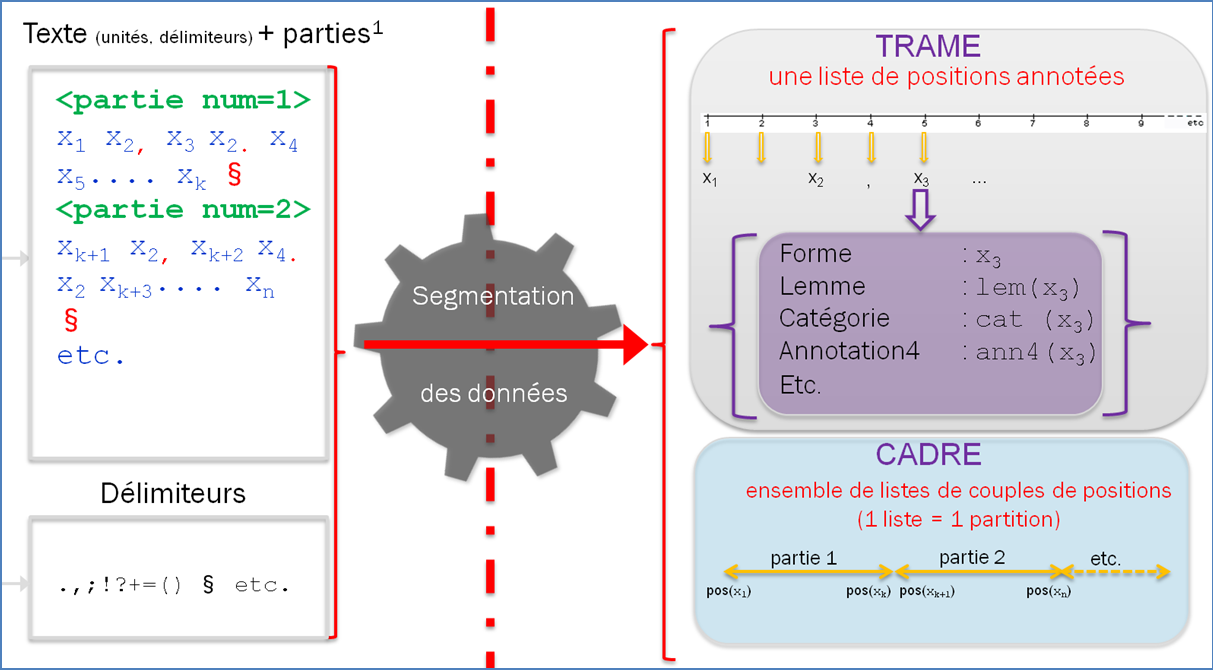
Le processus de comptage nécessite au préalable d'identifier les contenus et les contenants. Ce préalable consiste à expliciter une segmentation du texte conduisant à la mise au jour d'une Trame sur laquelle des annotations pourront se greffer ultérieurement.
![]()
Trame et Cadre : les objets de la textométrie
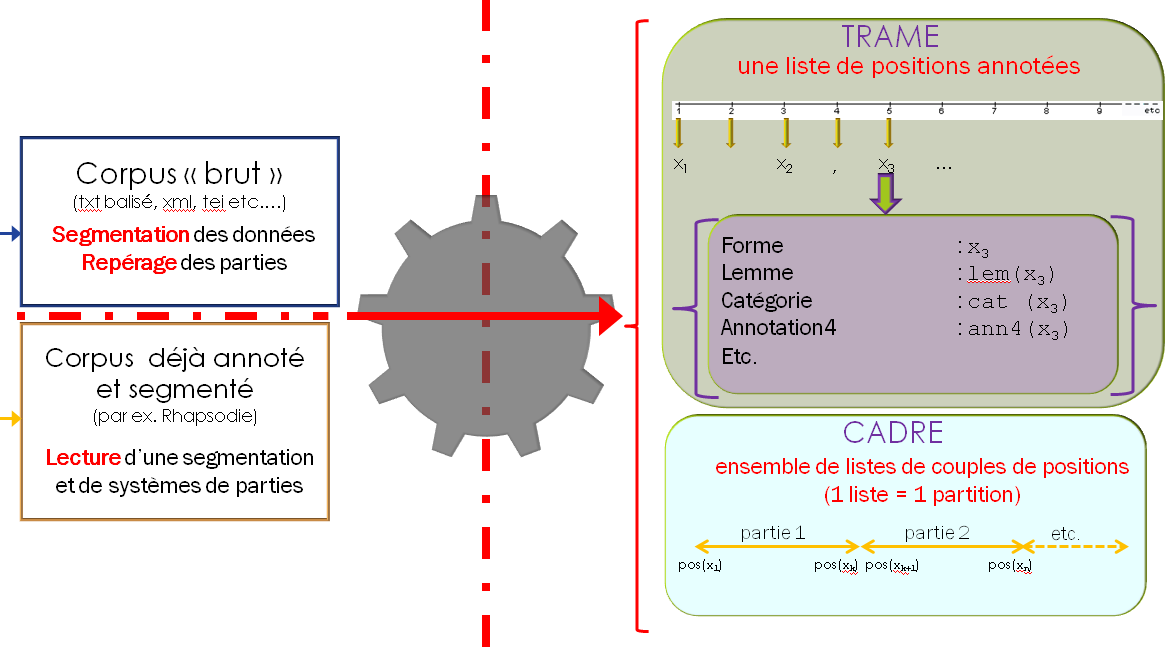
A partir d'un texte segmenté, la numérotation des items découpés dans le texte de départ permet de constituer un système de coordonnées sur le texte dans lequel chaque item est repéré par son numéro d'ordre. Nous appelons ce système de coordonnées sur la séquence textuelle : la Trame textométrique. Ce même système de coordonnées permet de définir et de localiser, au sein du corpus, des zones textuelles (zones formées par une suite d'items consécutifs, entre la position x1 et la position x2, réunion d'un certain nombre de zones de ce type, etc.).
La définition d'une Trame textométrique sur un corpus de textes permet de décrire les systèmes de zones qui correspondent aux contenants de l'analyse textométrique (parties, paragraphes, phrases, sections, chapitres etc.). On peut rassembler les descriptions relatives aux systèmes de contenants dans une structure de données particulière le Cadre textométrique.
Structuration logique du texte
Comment on entre dans le Trameur
Le Moteur textométrique : création d'une nouvelle base
Le texte en machine : mise au jour du Cadre, de la Trame, d'un item de la TrameNous appelons Trameur l'outil informatique qui permet de construire une ressource textométrique Trame/Cadre, à partir d'une ensemble de textes rassemblés en corpus, selon les principes définis plus haut. La partie Trame de la ressource textuelle produite par le Trameur est constituée par la suite des items isolés lors de l'opération de segmentation. La partie Cadre rassemble les données relatives aux différents découpages réalisés sur le corpus.
La transmission d'une ressource textuelle constituée sous la forme Trame/Cadre (une base textométrique) constitue une solution suffisante pour servir de base à toute exploration textométrique ultérieure.Source : [Söze-Duval, 2008], Keyser Söze-Duval. Pour une textométrie opérationnelle (DOC)
Lecture complémentaire : [Fleury, 2013], Serge Fleury. Le Trameur. Propositions de description et dimplémentation des objets textométriques, (PDF), (texte en cours).
Le document précédent met au jour une description des objets textométriques et les méthodes mises en uvre dans le Trameur pour travailler sur et avec ces objets dans une perspective textométrique. On y détaille aussi les opérations permises sur une base textométrique : format des données textuelles, modification dynamique de la Trame, correction ou ajout d'annotation etc.

![]()
Le Trameur
Le Trameur : Programme de génération puis de gestion de la Trame et du Cadre d'un texte (i.e découpage en unité et partitionnement du texte : le métier textométrique) pour construire des opérations lexicométriques / textométriques (ventilation des unités, carte des sections, cooccurrence, spécificité, AFC...). Le Trameur intègre en outre le programme treetagger : système d'étiquetage automatique des catégories grammaticales des mots avec lemmatisation. Il permet aussi de généner et de gérer des annotations multiples sur les unités du texte (et de traiter les niveaux d'annotations visés)
![]()
Documentation
Documentation : format PDF, format HTML
Ci-dessous, la documentation complète du Trameur disponible en ligne via issuu :
Documentation complémentaire intégrant uniquement une des mises à jour de la version 12 pour le traitement d'une base textométrique de textes alignés : format PDF
Documentation complémentaire intégrant uniquement les mises à jour "Intégration Modules R" : v. 11.04 format PDF
Documentation complémentaire intégrant uniquement les mises à jour "relation de dépendance" : v. 10.56 format PDF. La présentation de la base Rhapsodie2Trameur (cf infra) illustre plus avant les processus mis en oeuvre pour le traitement des relations de dépendance.
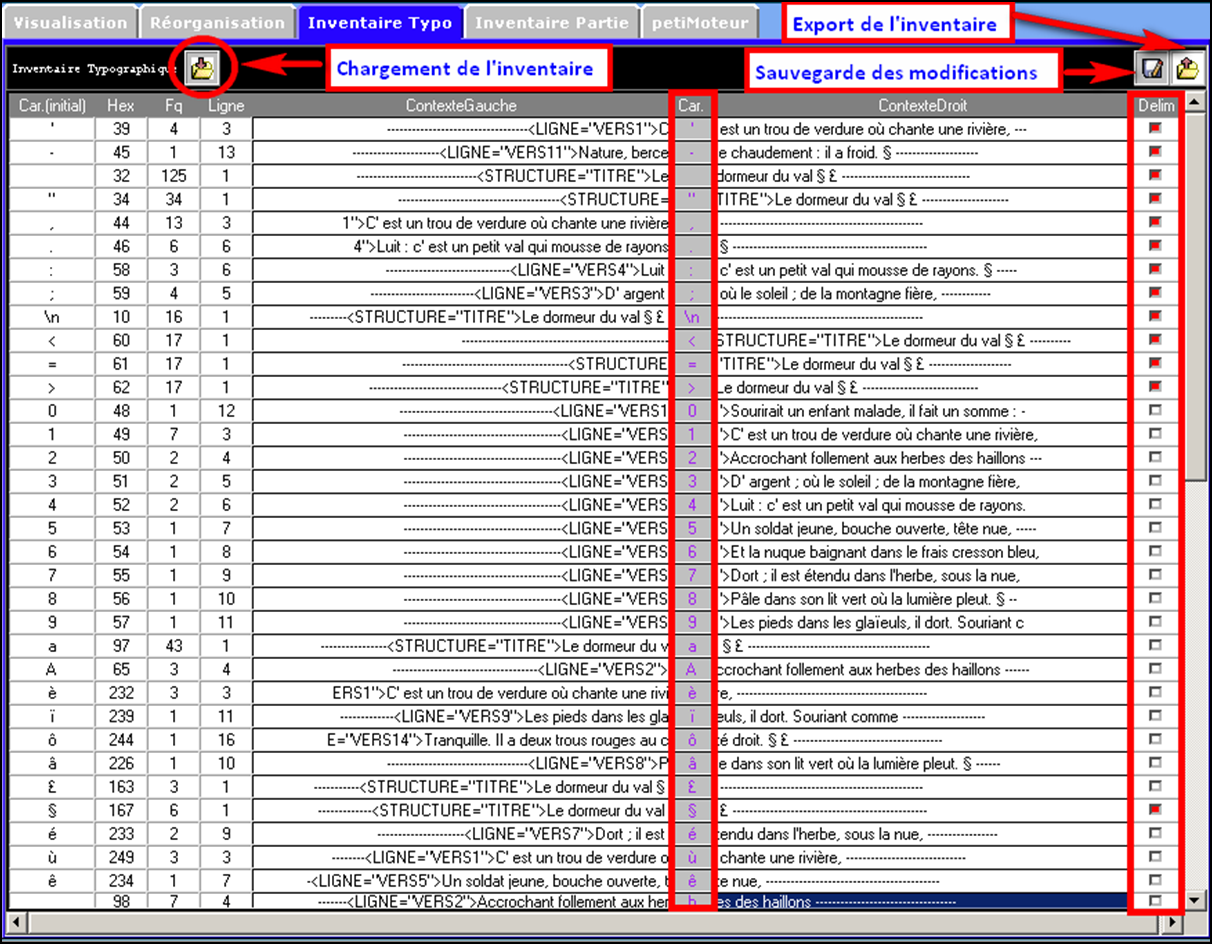
A partir de la version 10.90, le Trameur intègre un nouveau module "Inventaire Typographique" : ce dernier permet de visualiser tous les caractères d'un fichier, de les éditer et de les modifier (cf figure ci-dessous). Il permet donc de finaliser la préparation d'un texte avant de constituer une base textométrique : une fois que l'inventaire typographique est cohérent, le texte peut être chargé par le processus de chargement d'une nouvelle base disponible dans le Trameur. Le module "Inventaire Typographique" existe aussi sous la forme d'un programme exécutable disponible infra.
![]()
Formats : les formats de fichier pour créer une nouvelle base textométrique avec Le Trameur
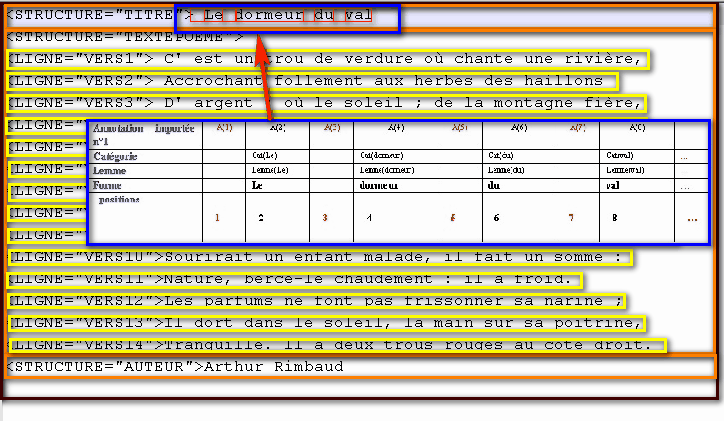
Les formats de fichier suivants sont présentés dans la documentation en ligne. Illustration sur Le Dormeur du Val et Ulysse (2 volets : EN, FR)
- [DORMEUR] - Format texte brut. Format texte brut avec marquage de sections (dans les 2 cas, pas de Cadre).
- [DORMEUR] - Format texte brut : balisage à la Lexico. Format texte brut : balisage à la Lexico (étendu).
- [DORMEUR] - Format texte XML. Format XML/TEI.
- [ULYSSE] - Corpus Aligné : avec balisage et marquage de sections alignées.
- [ULYSSE] - Corpus Aligné : avec balisages XML pour les volets et les sections de l'alignement.
![]()
Démo : construire et explorer un corpus issu du web en 4 fiches
Ces fiches fournissent un mode d'emploi pour construire un corpus chronologique issu du web (via Gromoteur) puis pour l'analyser (via Le Trameur). Le corpus est construit à partir des URLs de pages de journaux en ligne. On trouvera la liste de ces URLs dans ce fichier : LISTE_URL_UNES
Fiche n°1 : Construire un corpus avec Gromoteur
Fiche n°2 : Préparer le corpus issu de Gromoteur. (exemple de corpus)
Fiche n°3 : Le Trameur, démarrage
Fiche n°4 : Exploration textométrique du corpus issu de Gromoteur avec Le Trameur
![]()
Exemples de Bases Textométriques
Corpus CFPP2000. Le Corpus de Français Parlé Parisien (CFPP2000) est composé d'un ensemble d'interviews sur les quartiers de Paris et de la proche banlieue. Téléchargez le fichier sur votre ordinateur, puis après avoir démarré le logiciel, ouvrir le fichier en choisissant l'option "Créer une nouvelle base".
On trouvera ci-dessous des exemples de Bases Textométriques produites avec Le Trameur (ou produites pour Le Trameur). Ces bases sont à charger dans Le Trameur par le module d'Importer une base :
(in-progress)
Bases Universal Dependencies. Construites à partir des ressources disponibles sur la site du projet http://universaldependencies.org: Version 1.3 treebanks http://hdl.handle.net/11234/1-1699.
Base FR-UD : 330.000 mots ; 10 niveaux d'annotation. Dépendance codée dans annotation n°4
Base EN-UD : 180.000 mots ; 10 niveaux d'annotation. Dépendance codée dans annotation n°4
(in-progress)
Base bilingue BBC-EN-RU (corpus comparable aligné anglais/russe). Les 2 volets de cette base disposent de 3 niveaux d'annotation. Cette base est construite à partir des ressources disponibles sur cette page : English-Russian temporally aligned corpus.
(in-progress)
Base bilingue ParTUT2Trameur (français/anglais). Les 2 volets de cette base disposent de 9 niveaux d'annotation (Alignement de treebank). Cette base permet de tester les traitements spécifiques pour les bases textométriques intégrant 2 textes alignés (cf PDF pour cette fonctionnalité).
Alignement de Treebank pour le Trameur (pdf) : présentation du processus de transcodage de 2 treebanks ParTUT pour construire une base Textométrique.
Base bilingue "Investiture Obama" (français/anglais). Cette base regroupe le discours original en anglais prononcé par B. Obama le 20 janvier 2009 à Washington, publié sur le site de The New York Times (volet EN), et 4 traductions françaises de ce discours (volets FR0-1-2-3). Les traductions ont été récupérées sur le site officiel de la Maison Blanche (volet FR0), sur les sites des journaux français Le Monde (volet FR1) et Libération (volet FR2), ainsi que sur le site de RFI (volet FR3). Les 5 volets de cette base disposent de 3 niveaux d'annotation (forme, lemme, catégorie). Cette base permet de tester les traitements spécifiques pour les bases textométriques intégrant 2 textes alignés (cf PDF pour cette fonctionnalité). Cette archive contient les 5 volets originaux dans 5 fichiers indépendants.
Base bilingue "Convention" (français/anglais). Les 2 volets de cette base disposent de 3 niveaux d'annotation (forme, lemme, catégorie). Cette base permet de tester les traitements spécifiques pour les bases textométriques intégrant 2 textes alignés (cf PDF pour cette fonctionnalité).
Base "Rhapsodie2Trameur" construite à partir des ressources développées dans le cadre du projet Rhapsodie.
"Rhapsodie2Trameur" (v8) avec labels (màj : 14.07.2019). Même chose que la base précédente. Intégration des labels des annotations.
"Rhapsodie2Trameur" (v8) (màj : 11.05.2015). Chaque item de la Trame est associé à 61 niveaux d'annotation (prosodie, micro et macro-syntaxe).
SOURCES : projet Rhapsodie
Descriptif et sources des annotations : Annotations Rhapsodie pour le Trameur (v8) (pdf)
Présentation du processus de transcodage des annotations Rhapsodie pour construire une base Textométrique. Présentation des différents processus de traitements des annotations de dépendance.
Base "OrfeoCFPP2Trameur" construite à partir des ressources développées dans le cadre du projet ORFEO.
"OrfeoCFPP2Trameur" (v1) (màj : 07.04.2016). Chaque item de la Trame est associé à 4 niveaux d'annotation (forme, lemme, pos, annotation en dépendance syntaxique).
Ressources : 27 entretiens (sur 37) du corpus CFPP2000 utilisés dans le projet ORFEO et disponibles sous la forme de 31 fichiers tabulés (exemple de fichier orfeo-tabulé).
Ces fichiers tabulés ont été reformatés sous la forme d'une base textométrique (processus similaire à la base Rhapsodie2trameur) contenant environ 500.000 mots (4 annotations sur chaque item).
Base "Corpus de contes français" (Fairy Tales Corpus, FTC) construite à partir des ressources développées par Ismaïl El Maarouf. Chaque item de la Trame est associé à 7 niveaux d'annotation.
SOURCES : I. El Maarouf et J. Villaneau (2012). A French Fairy Tale Corpus syntactically and semantically annotated. In Proceedings of LREC 2012. Istanbul (Tk).
Pour les formes : copyright Momes.net, http://momes.net.
Lemme et POS via treetagger : fichier paramètre langue (français, utf-8) développé par Christophe Benzitoun (ATILF)
Pour les annotations : http://elmaarouf.legtux.org/Accueil.html
Descriptif et sources des annotations :
balise <f> (forme) : copyright Momes.net, http://elmaarouf.legtux.org/data/FTC_FORM.txt
balise <l> (lemme) : fichier paramètre langue (français oral, utf-8) développé par Christophe Benzitoun (ATILF) (source : http://cnrtl.fr/corpus/perceo/)
balise <c> (POS) : fichier paramètre langue (français oral, utf-8) développé par Christophe Benzitoun (ATILF)
Annotations complémentaires (http://elmaarouf.legtux.org/Accueil.html) :
- Identifiants de mots : http://elmaarouf.legtux.org/data/FTC_ID.txt (première balise <a>)
- Annotation référentielle : http://elmaarouf.legtux.org/data/FTC_REF.txt (seconde balise <a>)
- Annotation en rôles sémantiques pour 26 verbes : http://elmaarouf.legtux.org/data/FTC_SEMROLE.txt (troisième balise <a>)
- Annotation syntaxique en dépendance pour 137 verbes : http://elmaarouf.legtux.org/data/FTC_SYNROLE.txt (dernière balise <a>)
L'ensemble des annotations du corpus initial (+ lemme et POS) regroupées ici au format d'une base textométrique pour le Trameur.
Base Prématurés 96 (cf "Projet Prématurés") ; 2 fichiers dans cette archive : pour le premier, chaque item de la Trame est associé à 3 niveaux d'annotation (forme, catégorie, lemme), pour le second, chaque item est associé à 4 niveaux d'annotation (forme, catégorie, lemme, sémantique).
Base Duchn (le journal du Père Duchesne) : chaque item de la Trame est associé à 3 niveaux d'annotation (forme, catégorie, lemme)
Base Convention (Russe, UTF8): chaque item de la Trame est associé à 3 niveaux d'annotation (forme, catégorie, lemme)
Base SOU 1790-2008 (1.600.000 mots) : chaque item de la Trame est associé à 3 niveaux d'annotation (forme, catégorie, lemme). Descriptif : State Of The Union (SOTU) provides access to the corpus of all the State of the Union addresses from 1790 to 2008. SOTU allows you to explore how specific words gain and lose prominence over time, and to link to information on the historical context for their use. SOTU focuses on the relationship between individual addresses as compared to the entire collection of addresses, highlighting what is different about the selected document. You are invited to try and understand from this information the connection between politics and languagebetween the state we are in, and the language which names it and calls it into being. cf State of the Union (Visualizations, Statistical Analysis, and Searchable texts).
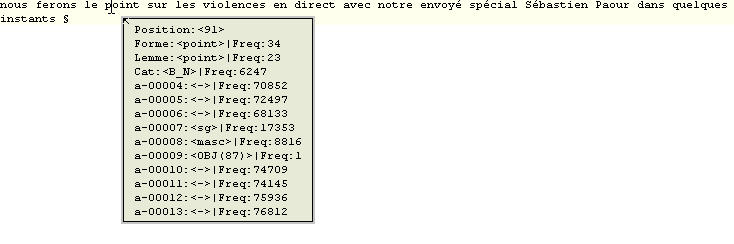
![]()
Exemples de rapports de travail produits avec Le Trameur
- Rapport n°1 (via trameur 7.0b30) : Corpus de Travail "Le journal du Père Duchesne".
- Rapport n°2 (via trameur 7.0b63) : Corpus de Travail "Le journal du Père Duchesne".
- Rapport n°3 (via trameur 7.0b31) : Corpus de Travail "Discours 2007". Discours campagne présidentielle 2007.
- Rapport n°4 (via trameur 7.0b105) : Corpus de Travail "SOU 1790-2008" (Base SOU 1790-2008 cf supra)
- Rapport n°5 (via trameur 8.0b52) : Corpus de Travail "Amharique", [texte en amharique (Ethiopie), installation préalable de ces polices] .
- Rapport n°6 (via trameur 8.0b55) : Corpus de Travail "Inaugural Adresses". Corpus constitué à partir des discours d'investiture des présidents des USA (source : Inaugural Addresses of the Presidents of the United States).
![]()
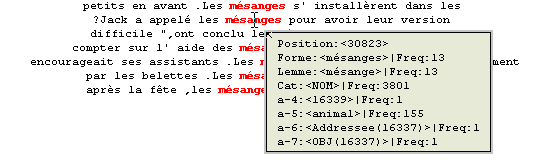
Nuages d'annotations sur la Trame (via trameur 8.0 b057)
- Base Duchn
- Nuage de formes sur la Trame de la Base Duchn.
- Nuage de formes (les mots commençant par "républi") sur la Trame de la Base Duchn.
- Nuage de lemmes sur la Trame de la Base Duchn.
- Base Prématurés 96
- Nuage de formes sur la Trame de la Base Prématurés 96.
- Nuage de lemmes sur la Trame de la Base Prématurés 96.
- Nuage de catégories sur la Trame de la Base Prématurés 96.
- Nuage d'annotations sémantiques sur la Trame de la Base Prématurés 96.
- Base Amharique
- Nuage de formes sur la Trame de Amharique.
- Base Inaugural Adresses
- Nuage de formes sur la Trame de Inaugural Adresses. Corpus constitué à partir des discours d'investiture des présidents des USA (source : Inaugural Addresses of the Presidents of the United States)
Téléchargement
Toutes les distributions "complètes" intègrent par défaut les modules complémentaires : R, Treetagger et Pajek. Ces distributions intègrent aussi une ressource d'annotation pour Treetagger adaptée au français oral, celle-ci a été réalisée par Christophe Benzitoun (ATILF) (source : http://cnrtl.fr/corpus/perceo/). Me contacter pour disposer du lien vers la distribution complète.
Toutes les distributions "allégées" sont directement téléchargeables ci-dessous. Ces distributions n'intègrent pas les modules complémentaires : Treetagger et Pajek. Pour les installer, suivre le mode d'emploi infra.
Le Trameur 12.176 (Version "allégée")
setup-trameur-12-l.exe
Cette distribution pour MacOsX ne permet pas à ce jour d'activer les opérations suivantes (intégrant des composants windows dans la version standard) : AFC, Pajek (intégration à venir). Tree-Tagger est intégré dans cette distribution avec les fichiers de langue standards.
Pour utiliser cette version du Trameur, procéder de la manière suivante :
- Télécharger l'archive letrameur-osX
- Décompresser-la sur le bureau
- Démarrer le Terminal (programme disponible dans le dossier Applications/Utilitaires de votre mac)
- Taper la commande suivante : cd Desktop/letrameur-osX (puis entrée pour lancer la commande)
- Lancer Le Trameur en tapant la commande : ./letrameur (puis entrée pour lancer la commande)
Comment installer la version complète à partir de la version dite "allégée" :
Récupérez le setup 12.176 (ou celui-ci setup x64 12.176), puis procédez à l'installation du setup récupéré.
La version dite "complète" intègre par défaut l'installation de 2 programmes externes : treetagger et pajek.
A contrario, le programme d'installation de la version dite "allégée" n'intègre pas ces 2 programmes.
Pour disposer de ces 2 modules, il est possible de réaliser un "installation" complémentaire en procédant comme suit :
- Récupérez la version de Treetagger 3.2 pour windows
(-> dézippez l'archive et localisez le programme tree-tagger.exe)
- Récupérez les fichiers de langues utiles pour treetagger :
- English parameter file (gzip compressed, Latin1)
- English parameter file (gzip compressed, utf-8)
- German parameter file (gzip compressed, Latin1)
- German parameter file (UTF-8) (gzip compressed, UTF-8)
- French parameter file (Latin1) (gzip compressed, information about this file)
- French parameter file (UTF-8)
- Base PERCEO (français oral) (utf-8)
- Italian parameter file (gzip compressed, Latin1, information about this file)
- Italian parameter file (gzip compressed, UTF-8)
- Dutch parameter file (gzip compressed, Latin1)
- Dutch parameter file (gzip compressed, UTF-8)
- Spanish parameter file (gzip compressed, Latin1)
- Spanish parameter file (UTF8) (gzip compressed, UTF8)
- Bulgarian parameter file (gzip compressed, UTF-8)
- Estonian parameter file (gzip compressed, UTF-8)
- Swahili parameter file (gzip compressed, Latin1)
- Russian parameter file (gzip compressed, UTF8)
- Galician parameter file (gzip compressed, UTF-8)
- Slovak parameter file (gzip compressed, UTF-8)
- Finnish parameter file (UTF8)
- "Latin médiéval" parameter file (gzip compressed, UTF-8)
- Latin parameter file (gzip compressed, UTF-8)
- "Ancien français" parameter file (gzip compressed, UTF-8)
- Slovenian parameter file (gzip compressed, UTF-8)
- Portuguese parameter (gzip compressed, UTF-8)
- Portuguese parameter file with fine-grained tagset (gzip compressed, UTF-8)
- Romanian parameter file (gzip compressed, UTF-8)
- Polish parameter file (gzip compressed, UTF-8)
- Danish parameter file (gzip compressed, utf-8)
- Norwegian (Bokmaal) parameter file (gzip compressed, utf-8)
- Swedish parameter file (gzip compressed, utf-8)
- Placez le programme tree-tagger.exe dans le répertoire courant du Trameur
- Placez les fichiers de langue dans le sous-répertoire langues du répertoire courant du Trameur en respectant les noms de fichier visibles dans la figure suivante :
PAJEK :
- Récupérez Pajek
- Installez Pajek sur votre poste de travail
- Si vous installez Pajek 2.0 (32 ou 64 bits), localisez le programme PAJEK.exe (dans le lieu d'installation de Pajek). Placez le programme PAJEK.exe dans le sous-répertoire Pajek du répertoire courant du Trameur
- Si vous installez Pajek 3.0 (et suivants) (32 ou 64 bits), localisez le programme PAJEK.exe et toutes les dll associées (dans le lieu d'installation de Pajek). Placez le programme PAJEK.exe et les dll dans le sous-répertoire Pajek du répertoire courant du Trameur
![]()
Copies d'écran
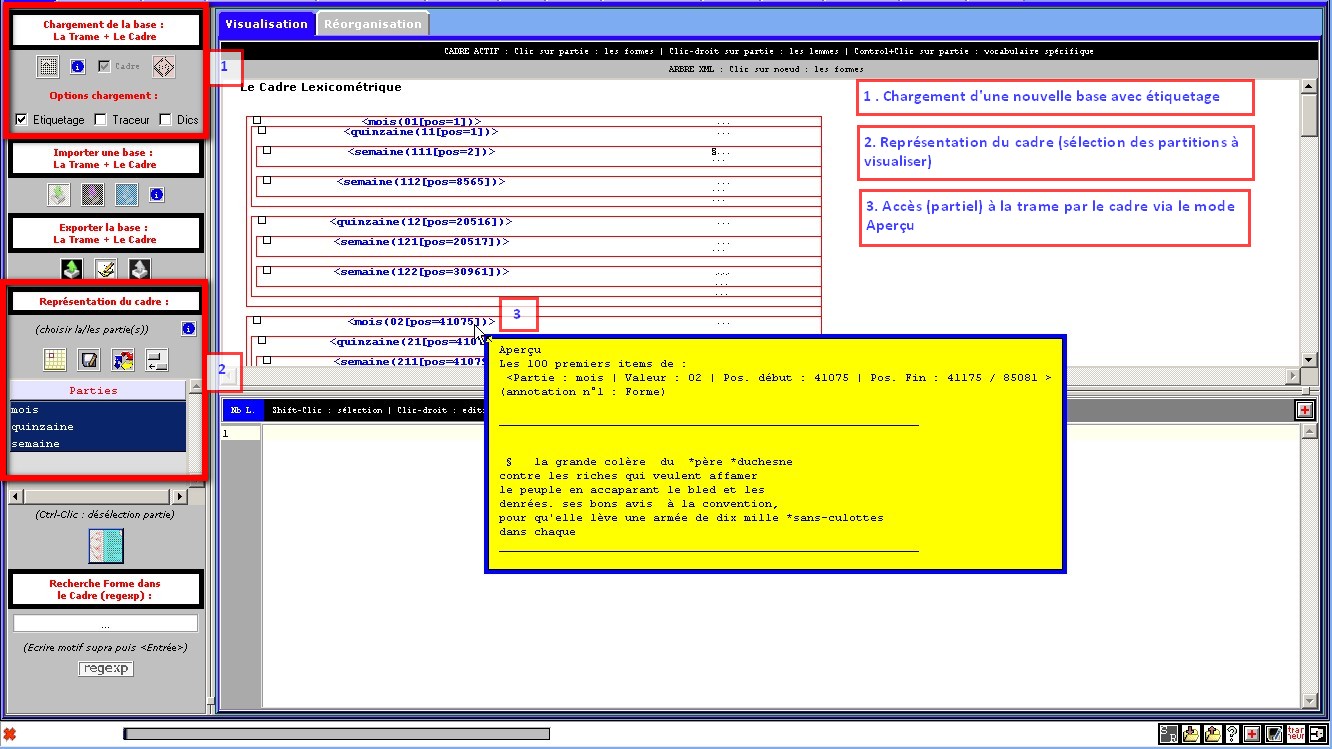
Figure 1 : Chargement d'un texte :
construction de la Trame et du Cadre.
Matérialisation du cadre.
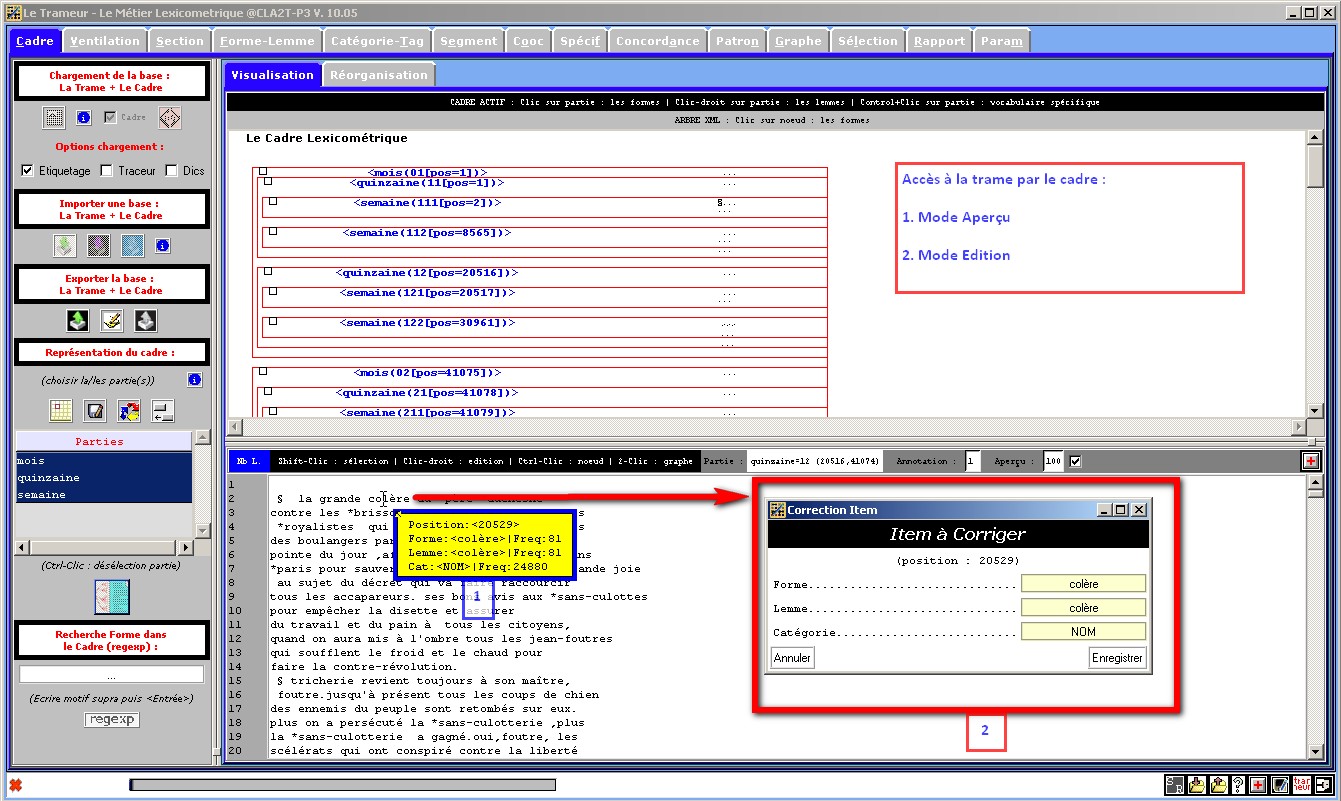
Figure 2 : Le Cadre. Accès au texte par le Cadre.
Edition/Modification d'un item de la Trame.
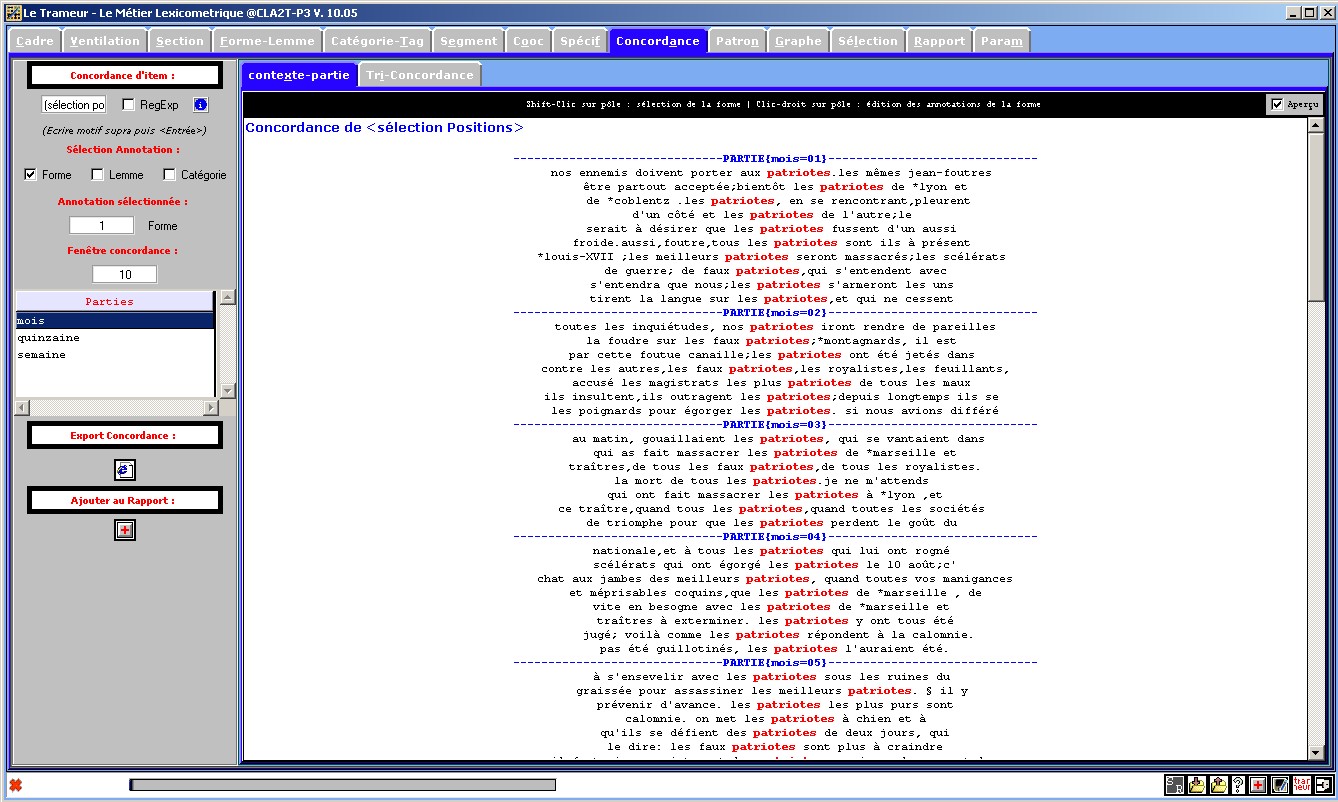
Figure 3 : Concordances (fenêtre édition).
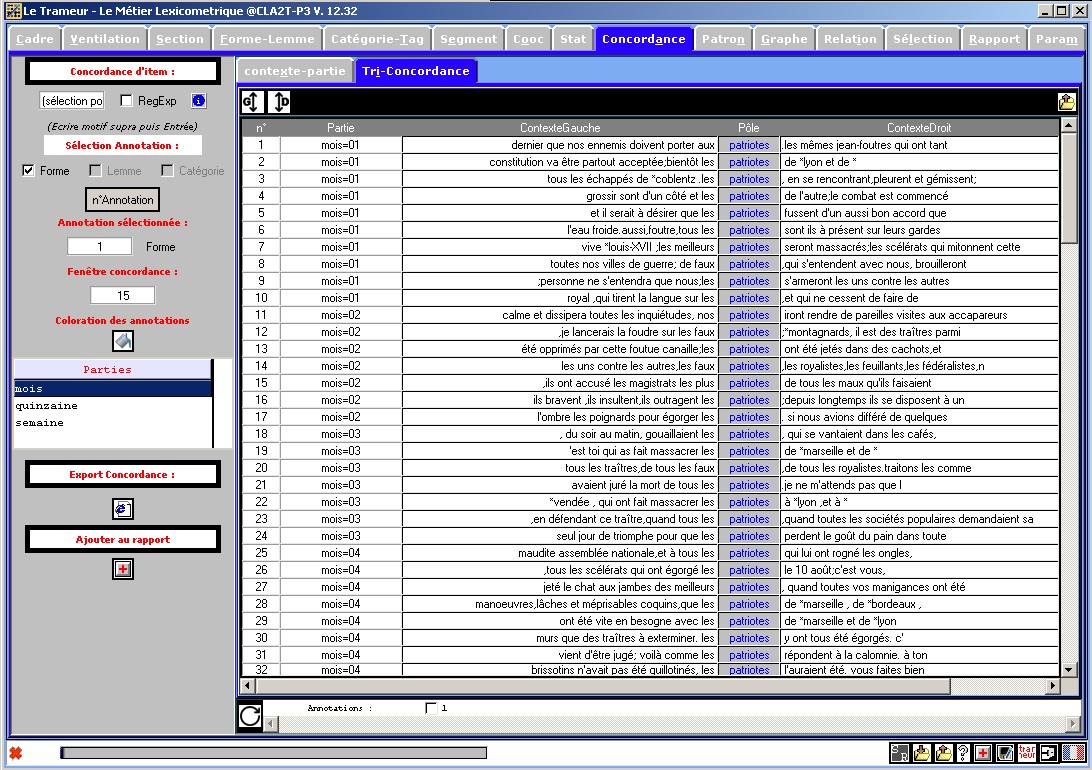
Figure 4 : Concordances (fenêtre tri).
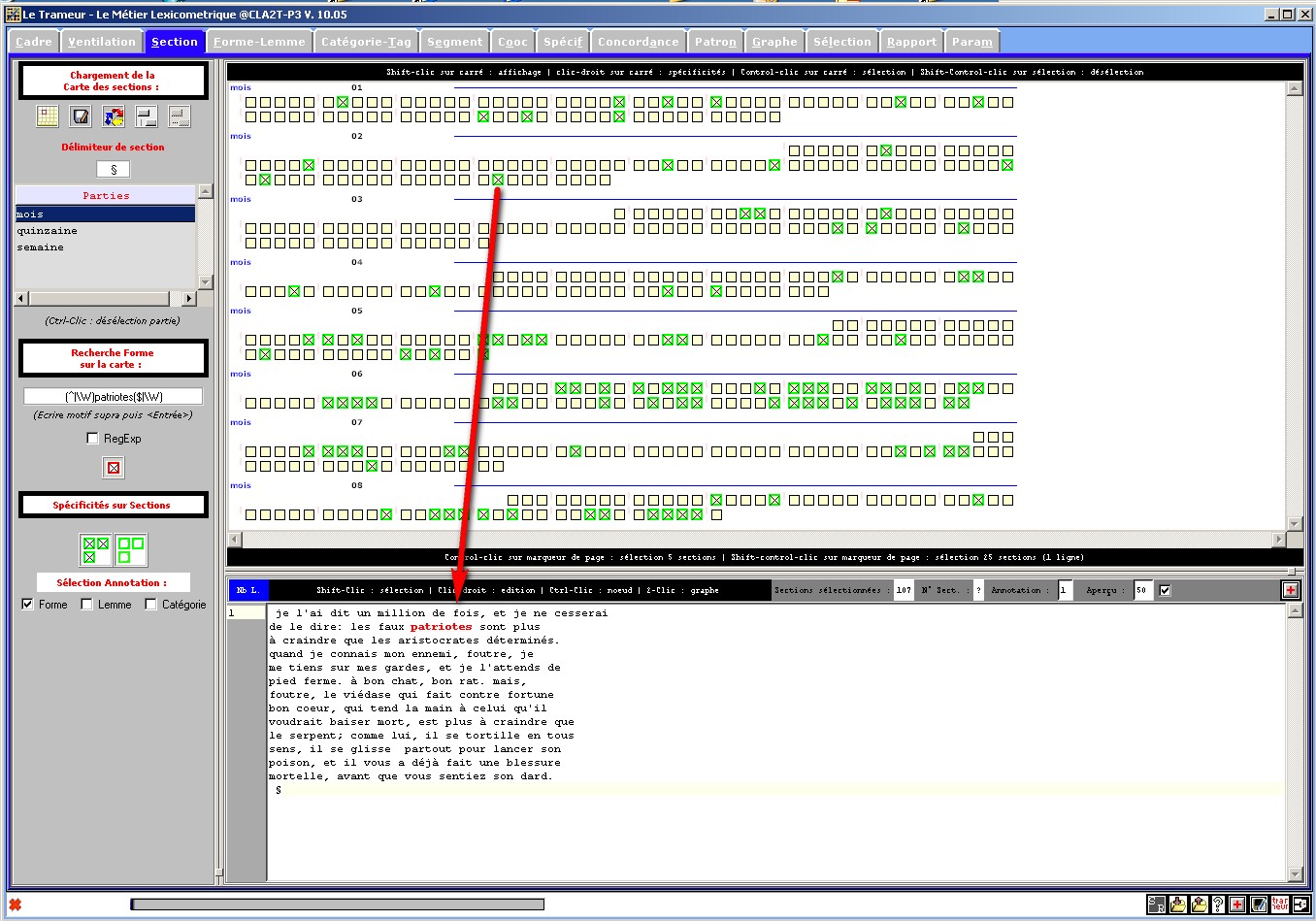
Figure 5 : Carte des sections => Edition de la Trame.
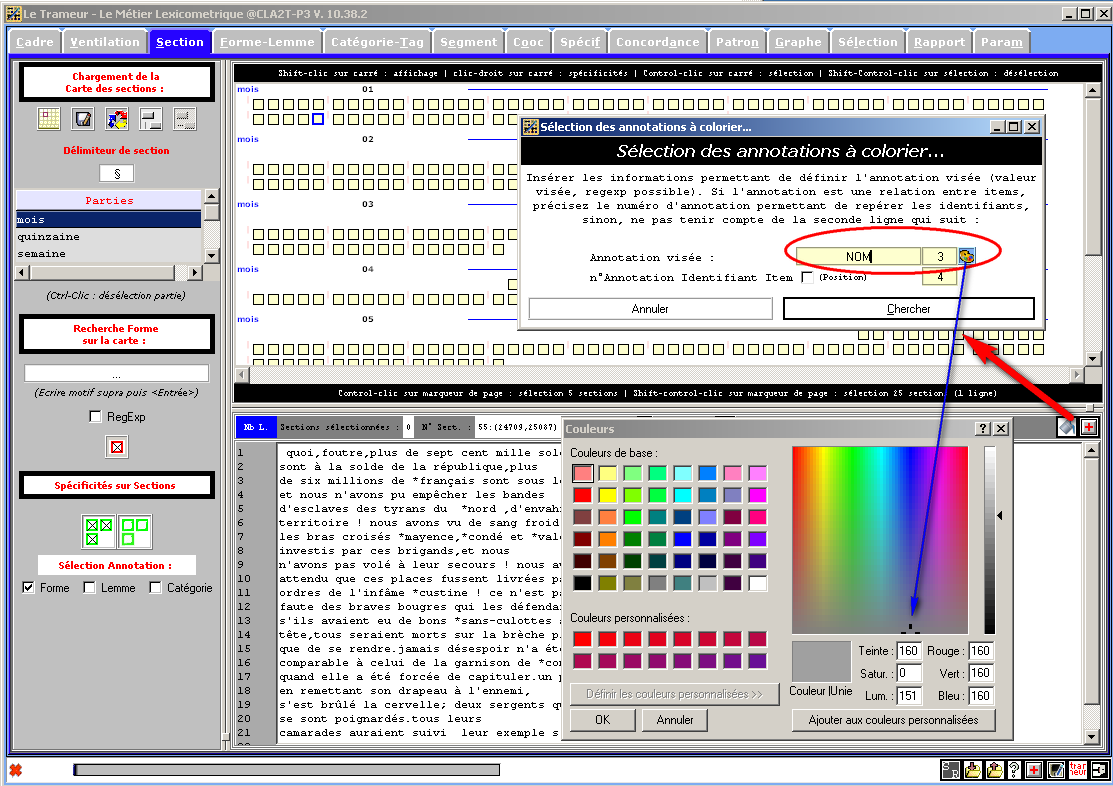
Figure 6 : Editeur de la Trame (carte des sections) :
paramétrage du marquage des annotations en contexte
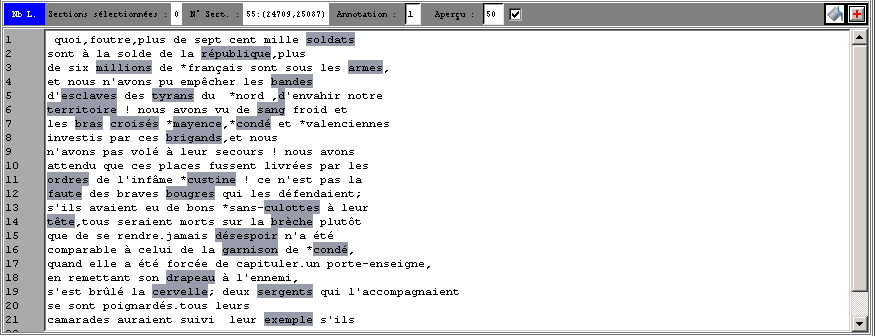
Figure 7 : Editeur de la Trame (carte des sections) :
marquage des annotations en contexte (annotation n°3 : NOM)
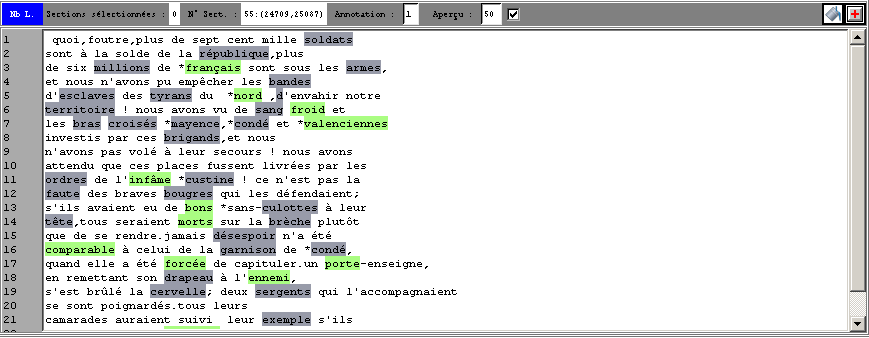
Figure 8 : Editeur de la Trame (carte des sections) :
marquage des annotations en contexte (annotation n°3 : 2 valeurs distinctes)

Figure 9 : Editeur de la Trame (carte des sections) :
marquage des annotations (de dépendance) en contexte (annotation n°7 (relation) : SUJ)
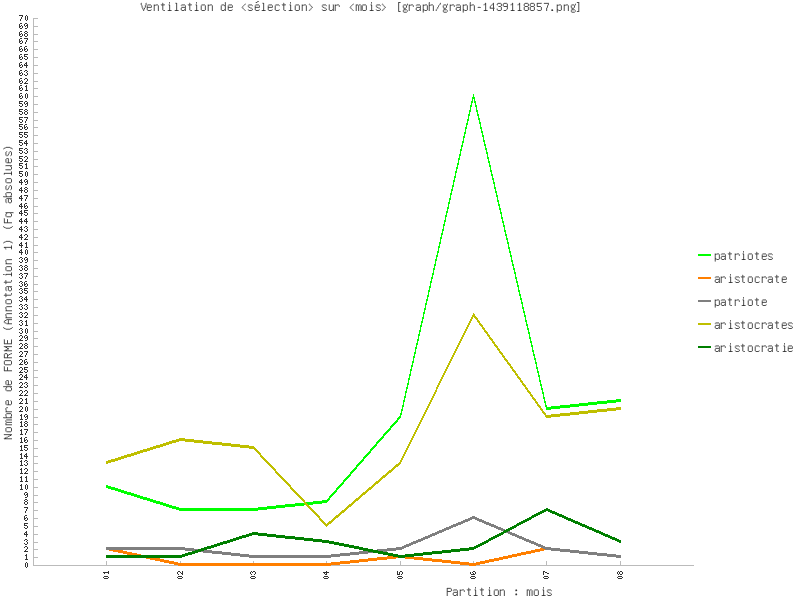
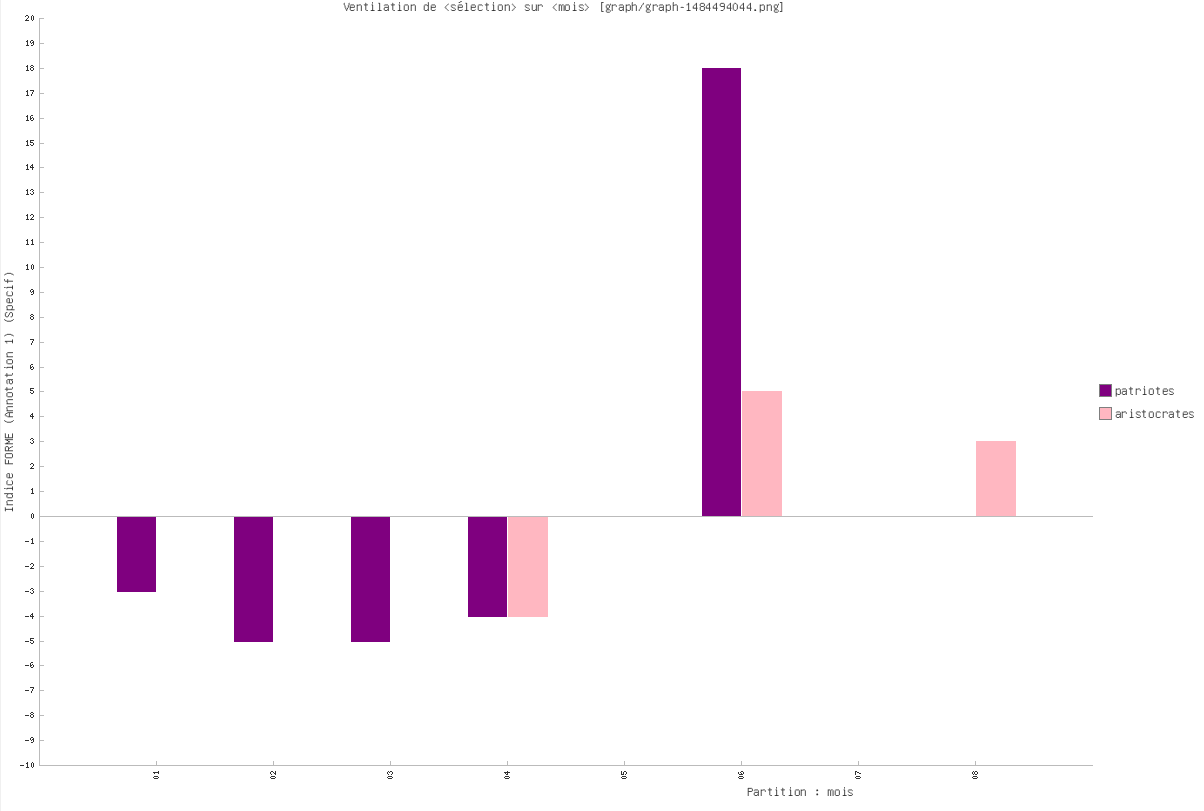
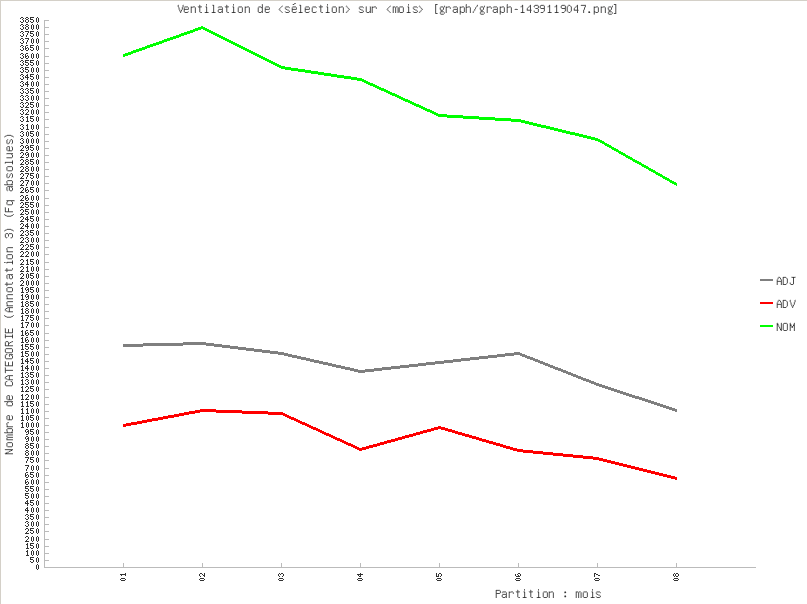
Figure 10 : Courbe de ventilation de plusieurs items (annotation=forme. Fq abs).
Courbe de ventilation de plusieurs items (annotation=forme. Ind spécif).
Courbe de ventilation de plusieurs items (annotation=catégorie. Fq abs).
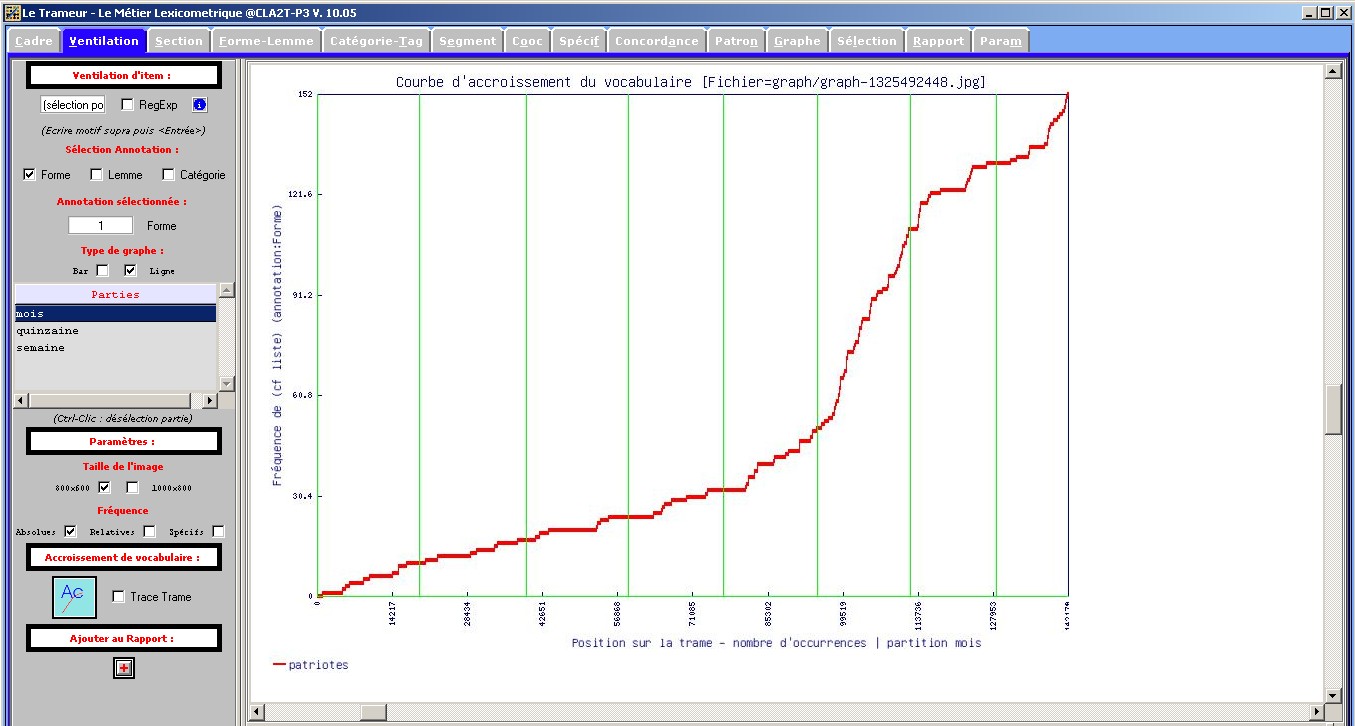
Figure 11 : Courbe d'accroissement du vocabulaire (forme sélectionnée).
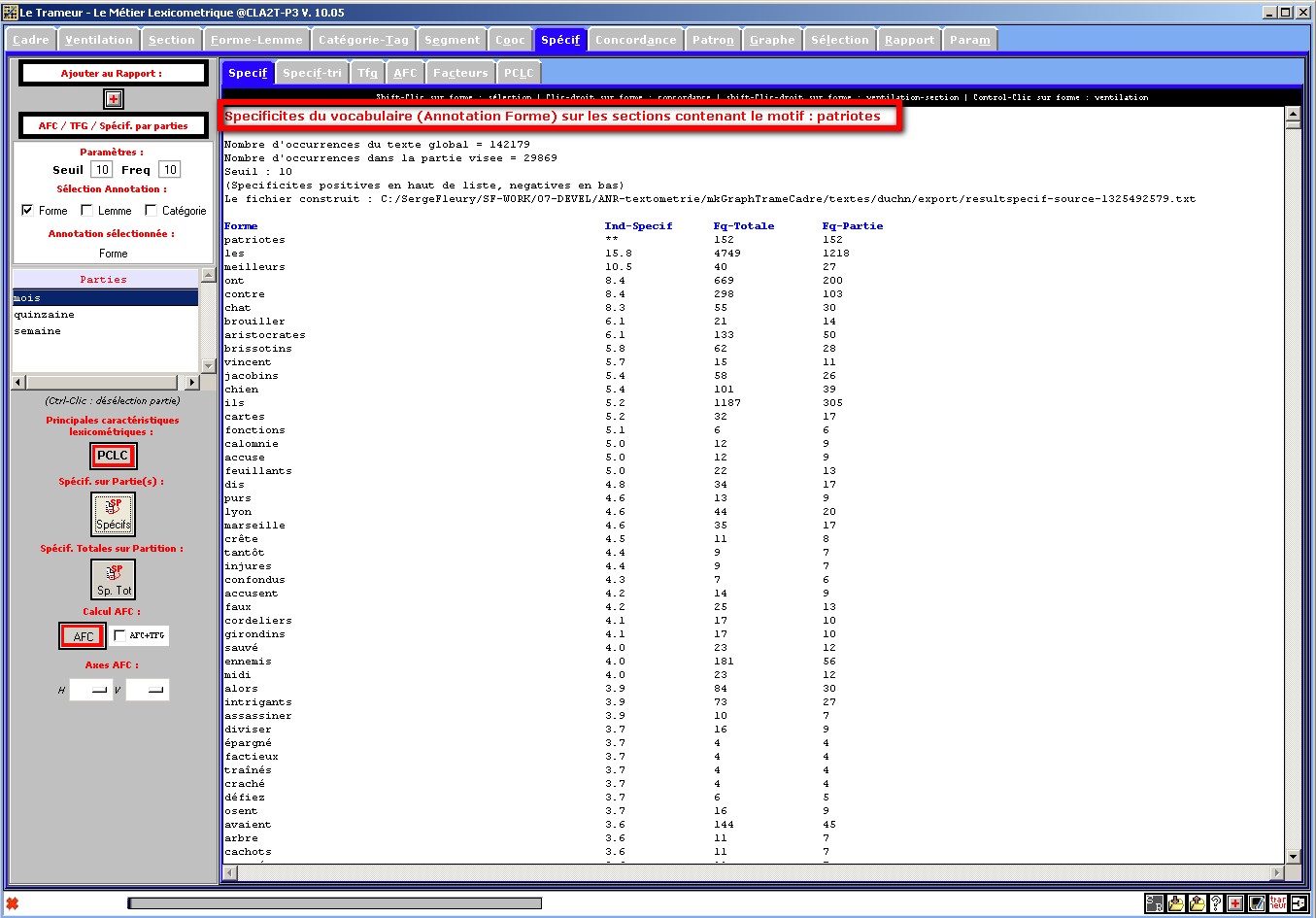
Figure 12 : Carte des sections => Recherche de cooccurrents :
spécificités des sections contenant un motif donné.
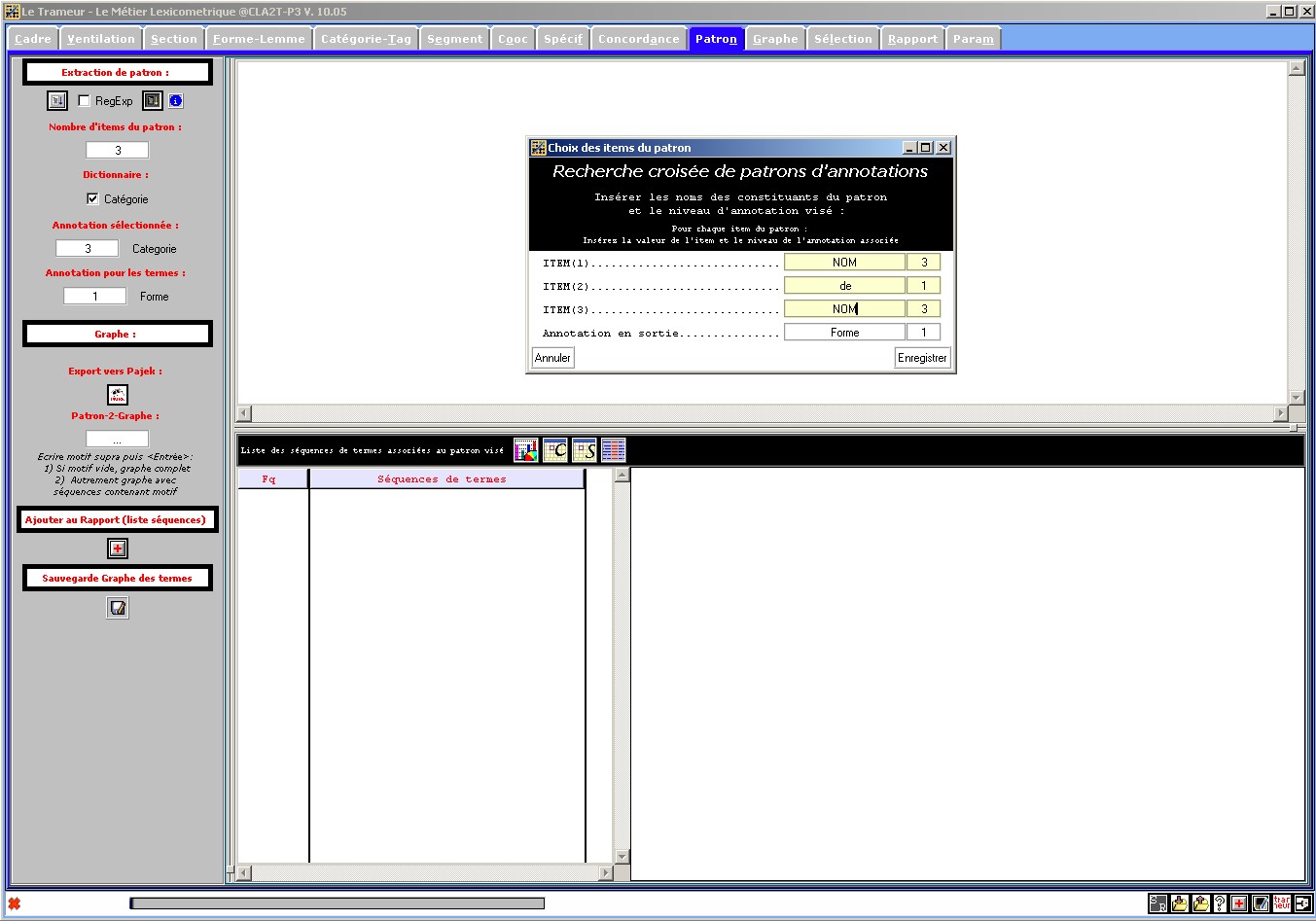
Figure 13 : (1) Recherche de patron et extraction de séquences de termes associées.
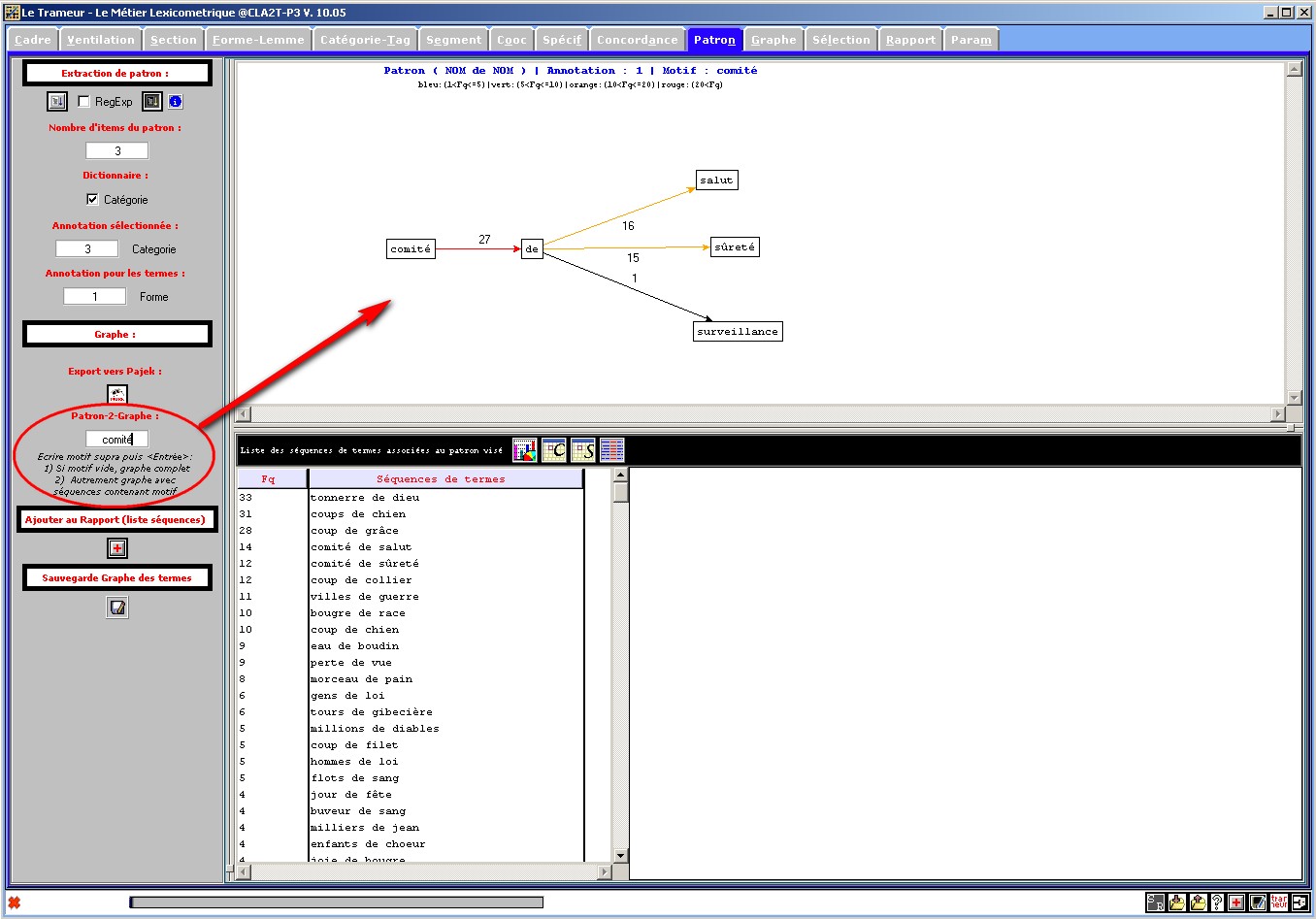
Figure 14 : (2) Recherche de patron : affichage des séquences
de termes associées et graphe de mots (sortie le Trameur).
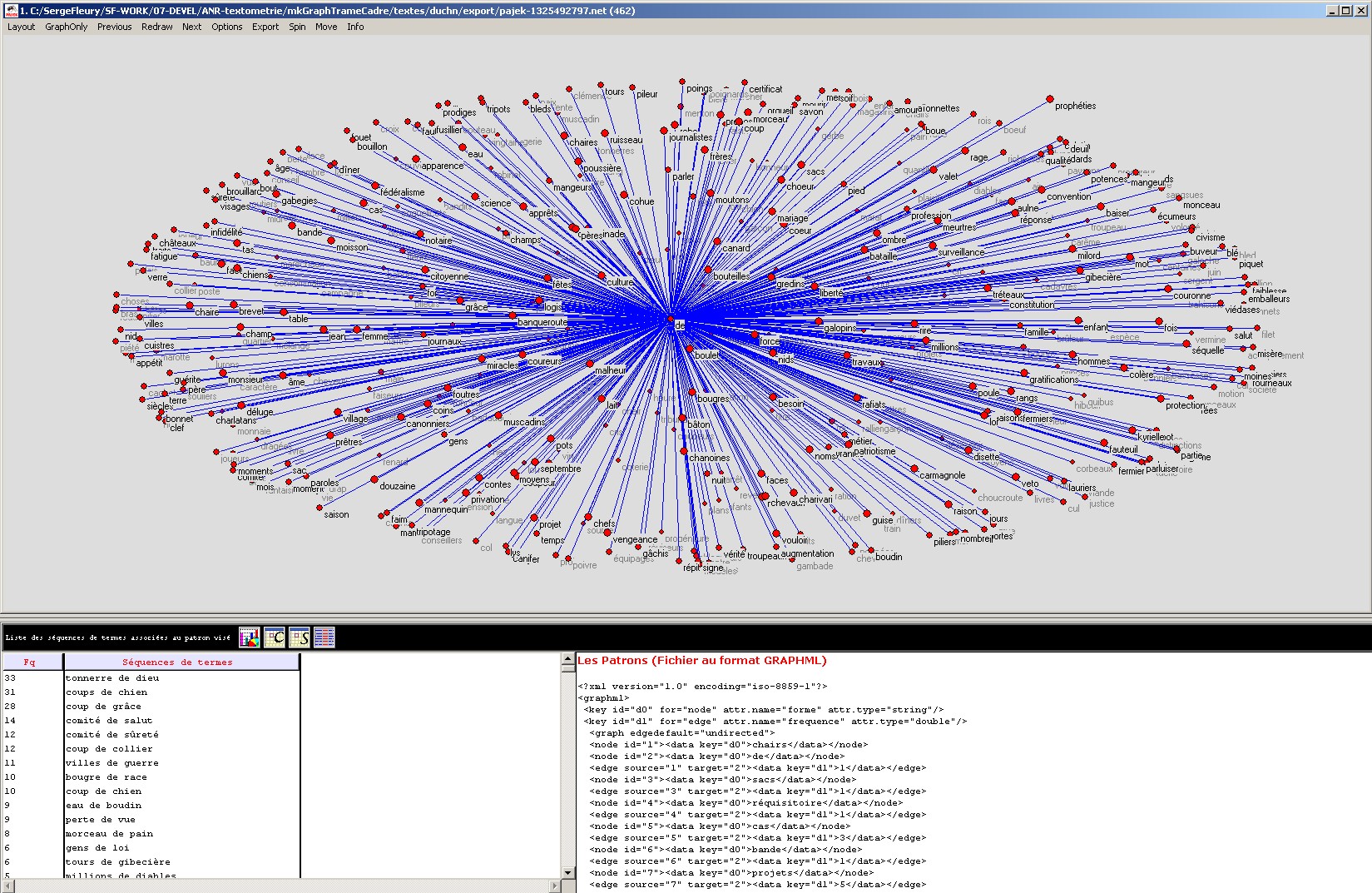
Figure 15 : (2) Recherche de patron : affichage des séquences
de termes associées et graphe de mots (sortie Pajek).

Figure 16 : Graphe (complet) du patron NOM ADJ
dans le Père Duchesne (cf rapport supra).
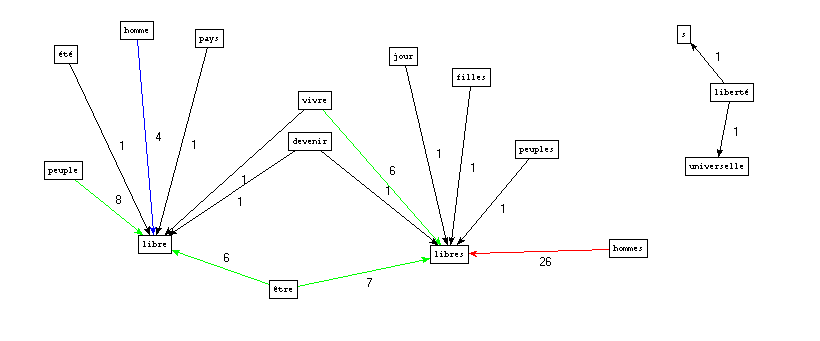
Figure 17 : Graphe (partiel) du patron NOM ADJ (contenant "\blib")
dans le Père Duchesne (cf rapport supra).
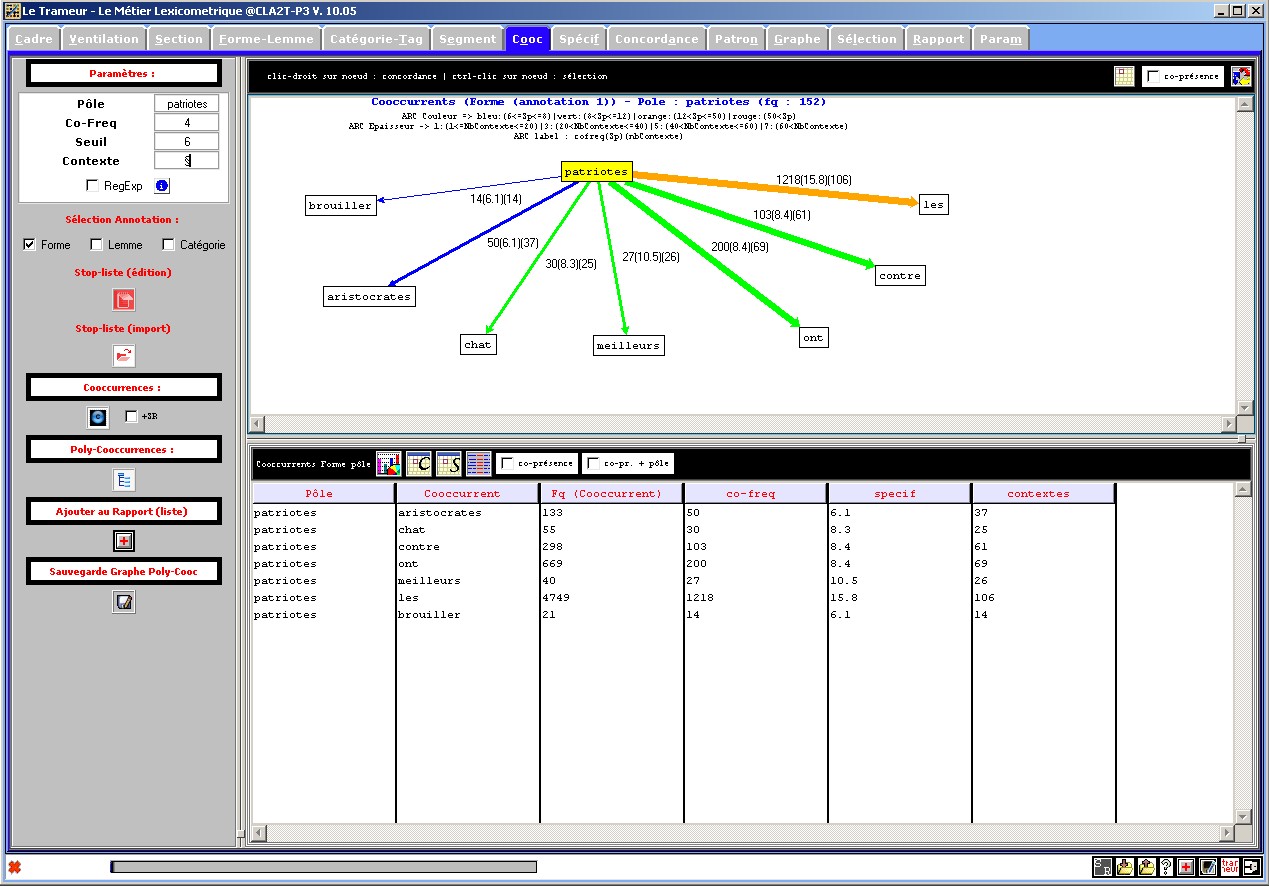
Figure 18 : Réseau de cooccurence autour d'un pôle, annotation n°1 (forme).
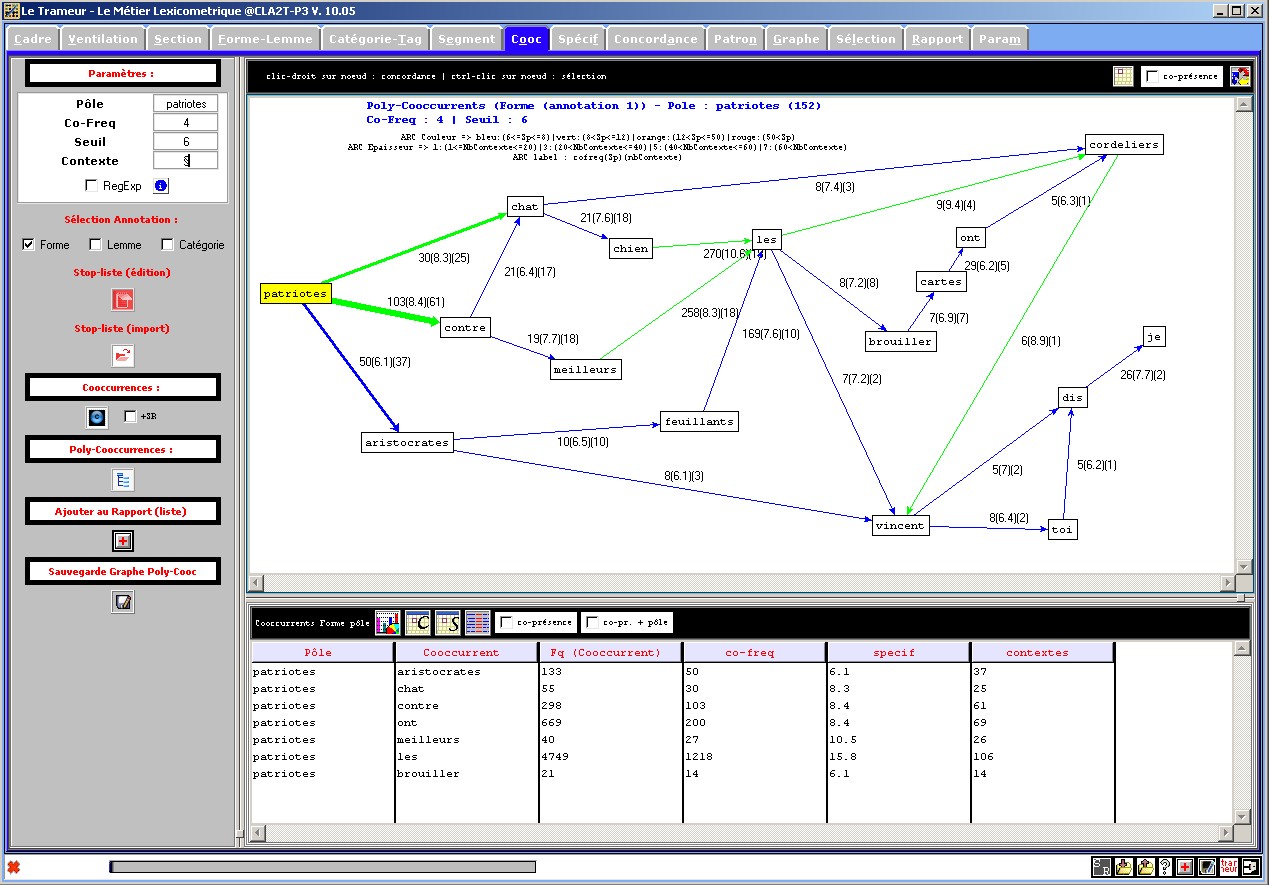
Figure 19 : Réseau de polycooccurrence autour d'un pôle, annotation n°1 (forme).
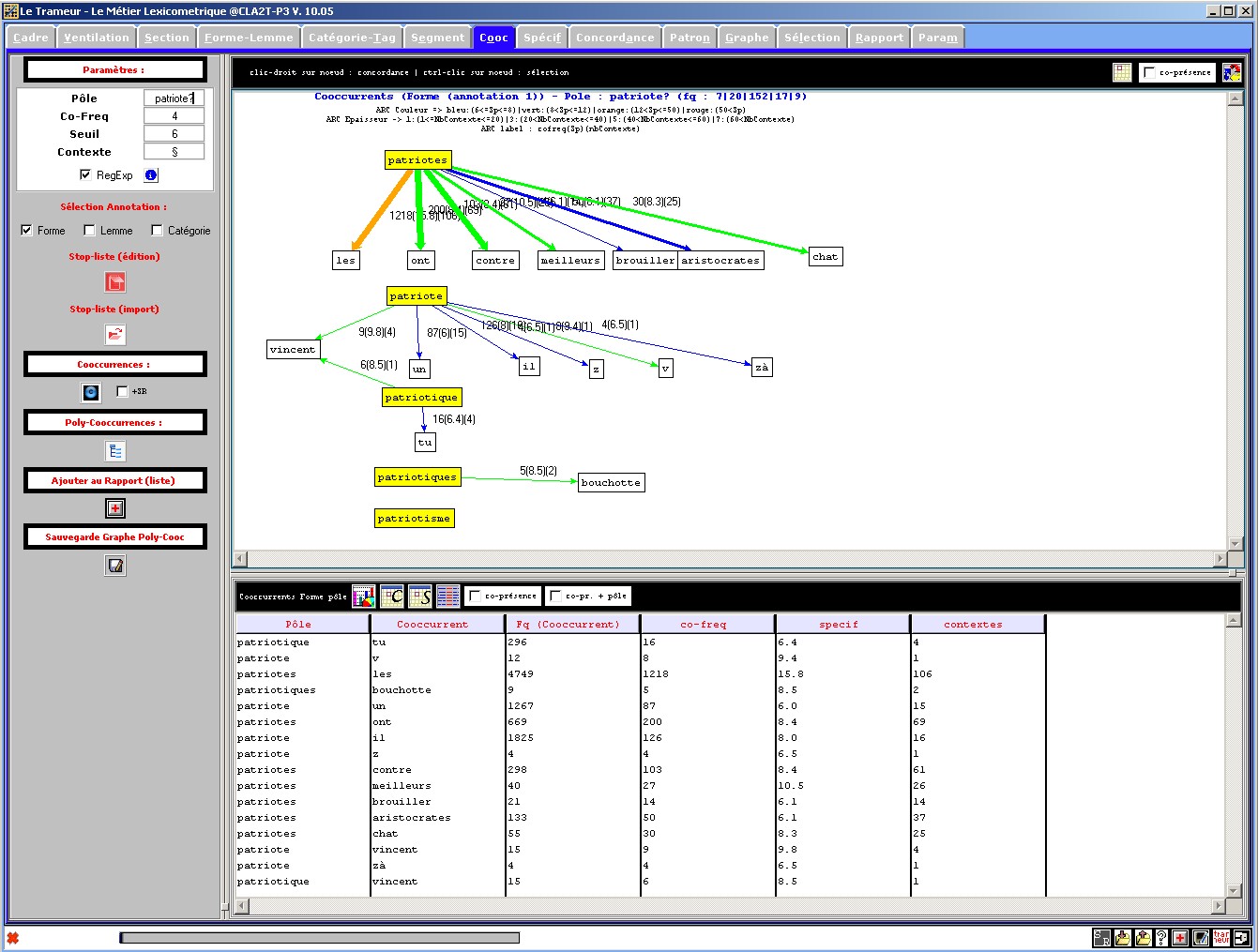
Figure 20 : Réseau de cooccurences autour d'un groupe de pôles, annotation n°1 (forme).
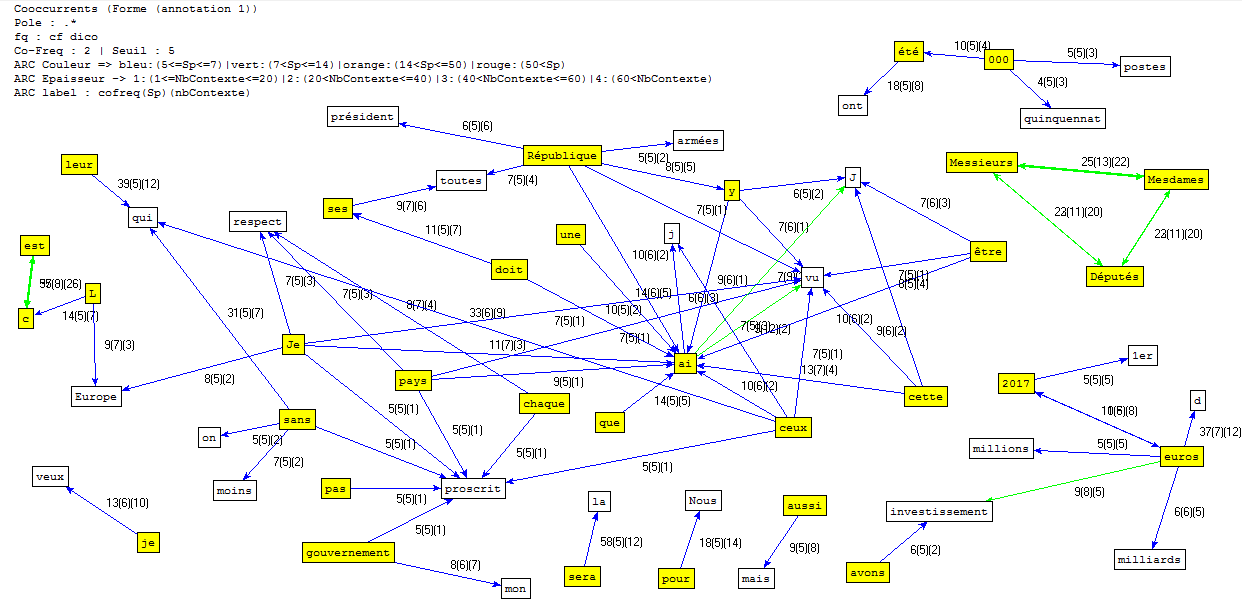
Figure 21 : Réseau de cooccurences généralisées, annotation n°1 (forme).
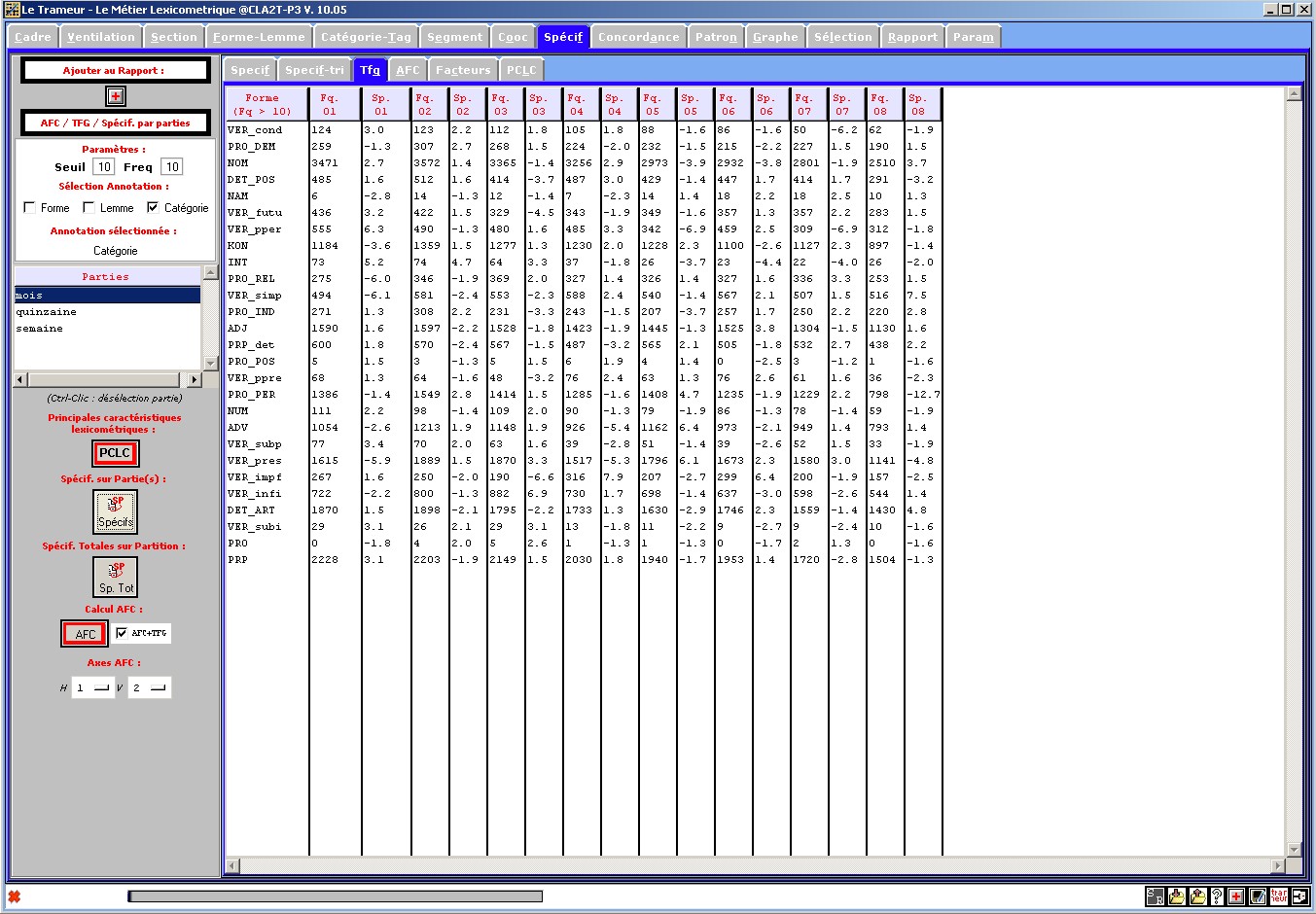
Figure 22 : TFG : tableau de formes graphiques (sur annotation sélectionnée)
(ventilation et spécificité de chaque forme dans les parties d'une partition).
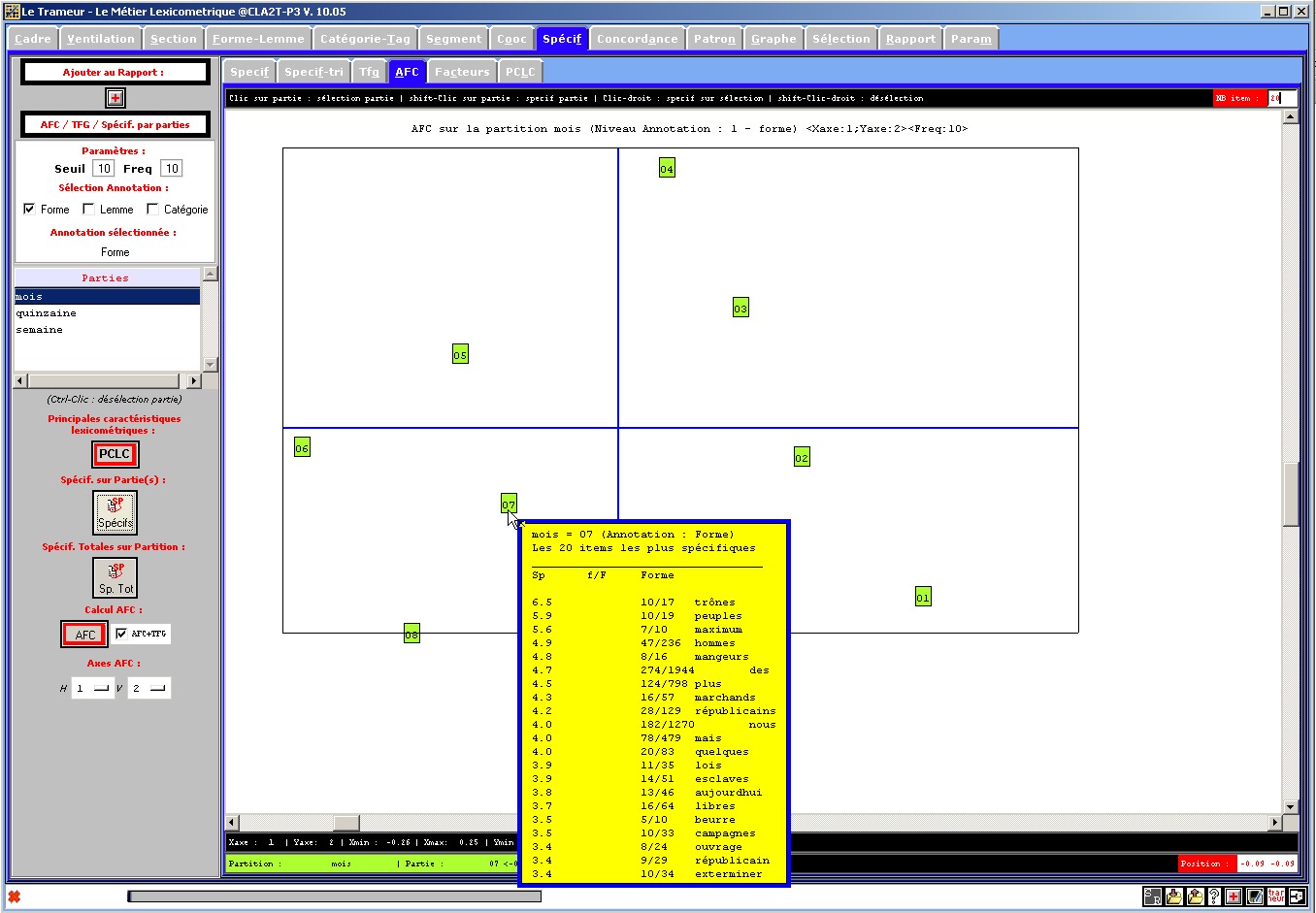
Figure 23 : AFC, partition sélectionnée, annotation n°1 (forme),
affichage des items spécifiques par partie sur le graphe.
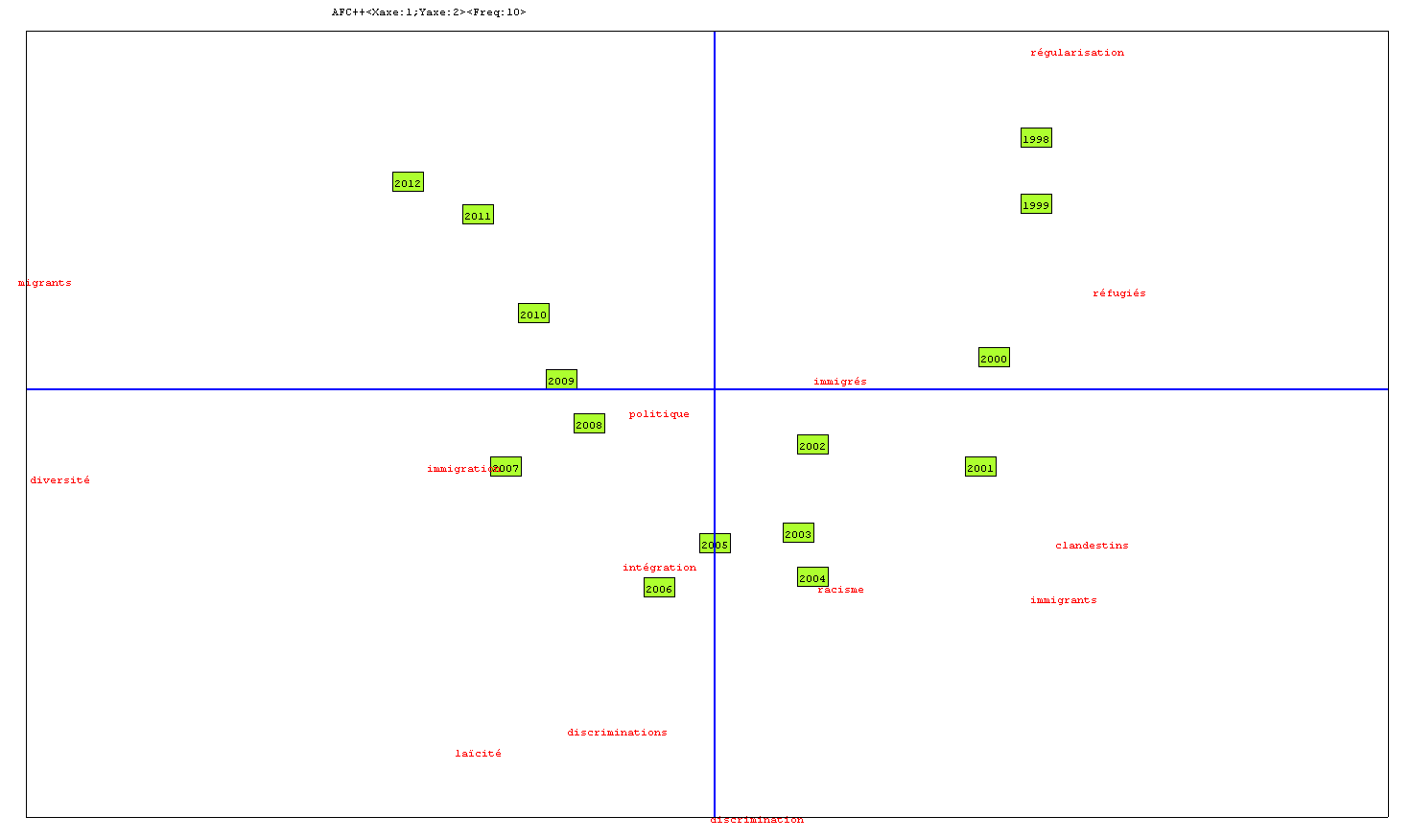
Figure 24 : AFC, partition sélectionnée, annotation n°1 (forme),
projection d'items sur le graphe.
Corpus LIBERATION 1998-2012, (taille : 8.000.000 mots)
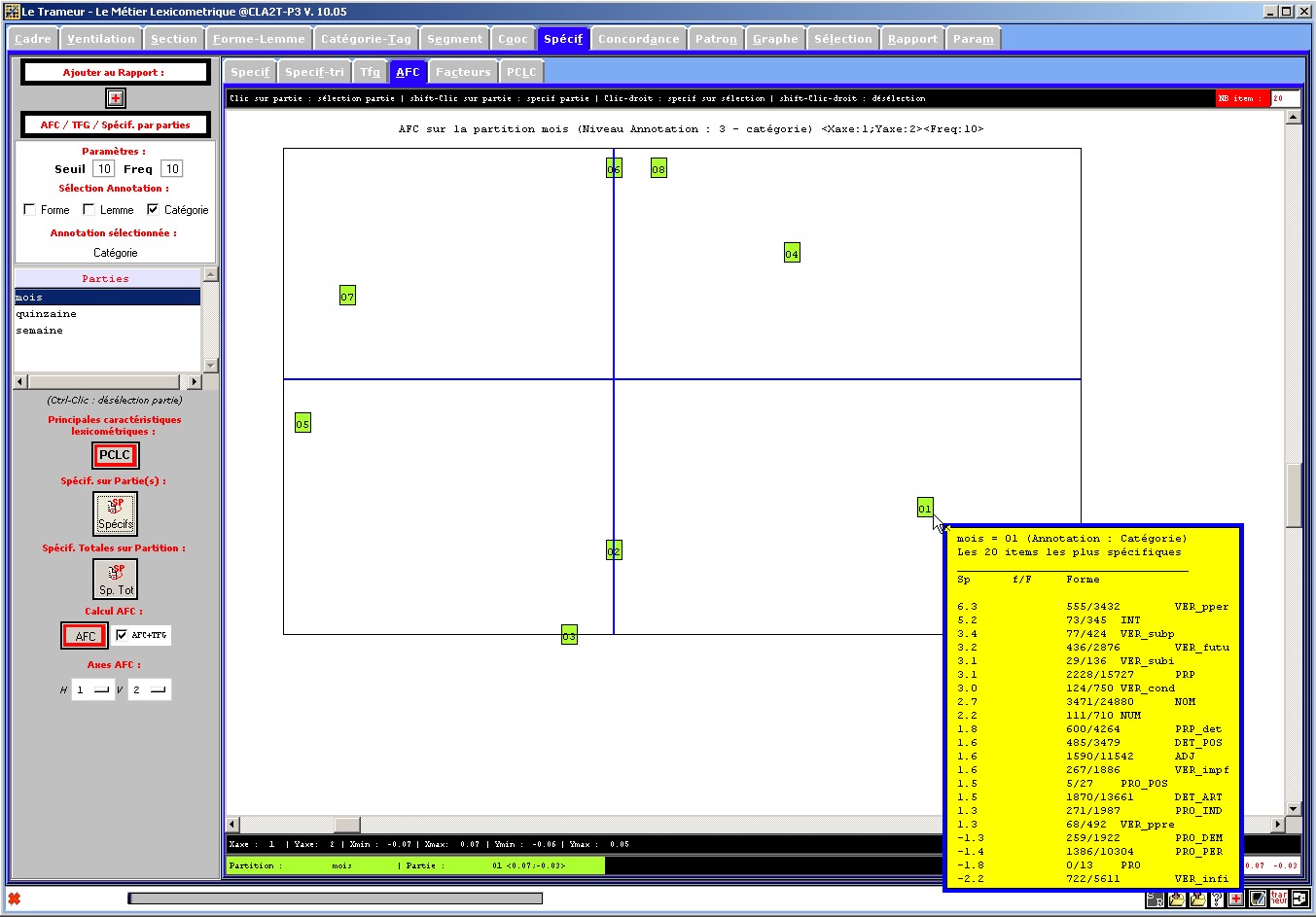
Figure 25 : AFC, partition sélectionnée, annotation n°3 (catégorie),
affichage des items spécifiques par partie sur le graphe.
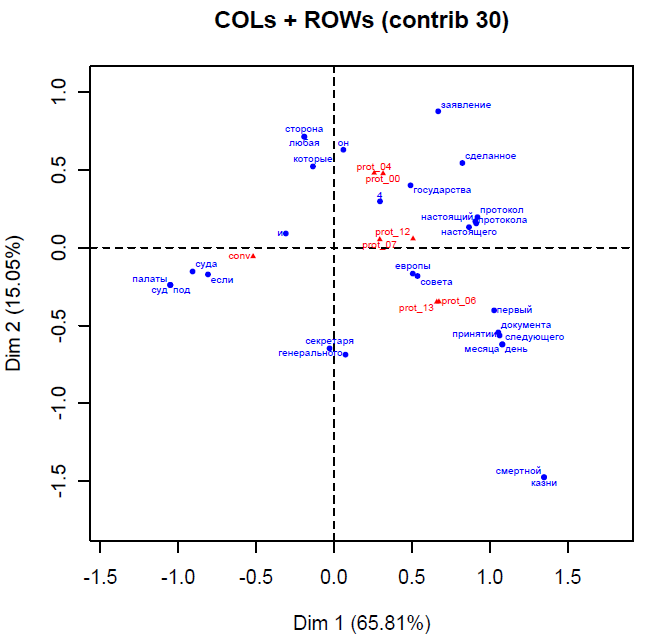
Figure 26 : AFC (via R), partition sélectionnée, annotation n°1 (forme).
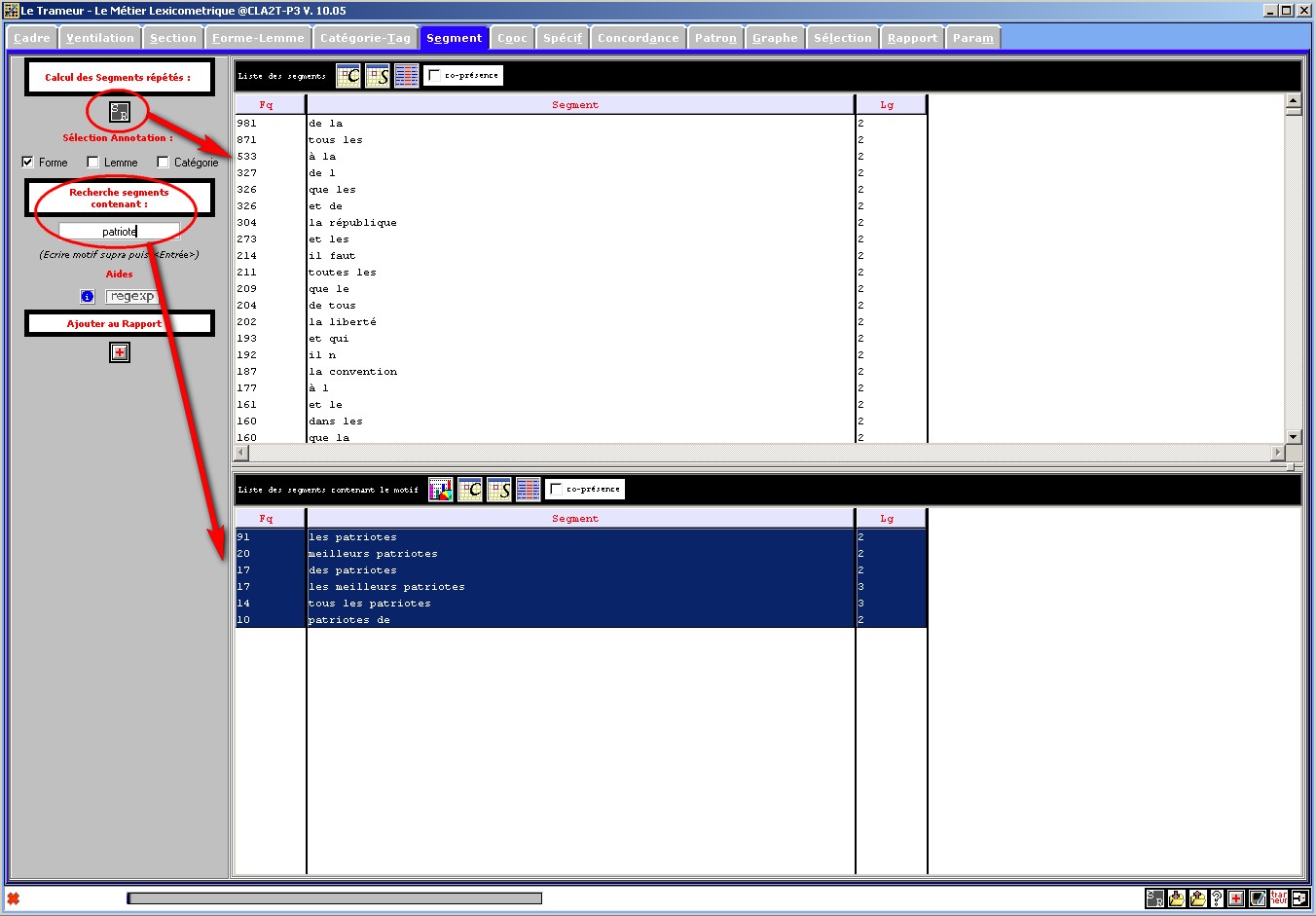
Figure 27 : Segments répétés (sur annotation sélectionnée).
Recherche de segments.
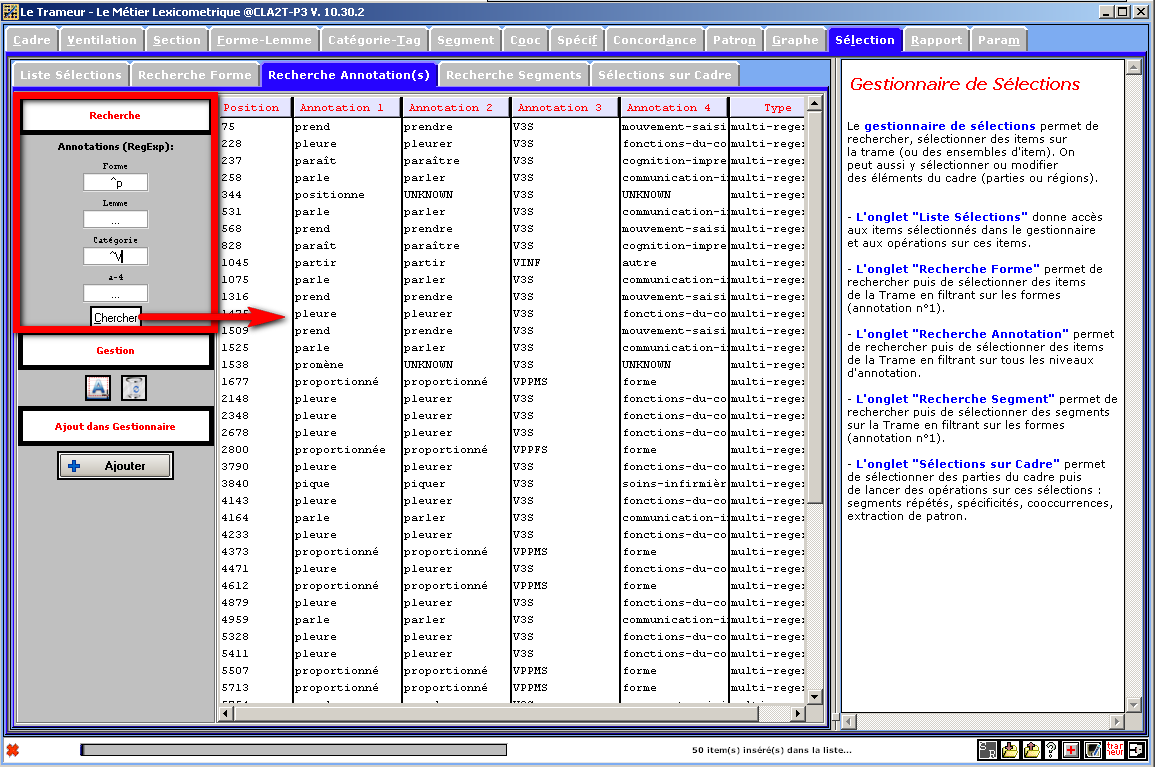
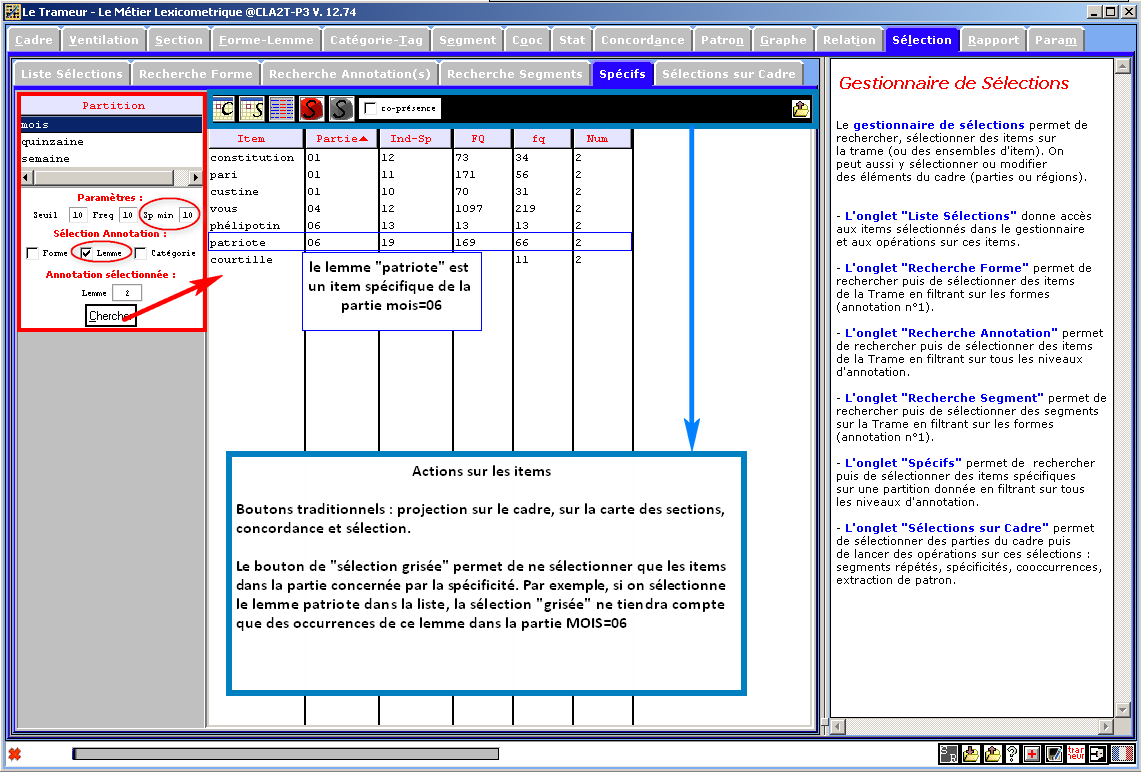
Figure 28 : Gestionnaire de sélections.
Mode "sélection sur la Trame : sélection d'items"
(sur cet exemple, recherche croisée => Forme : ^p ; Catégorie : ^V)"
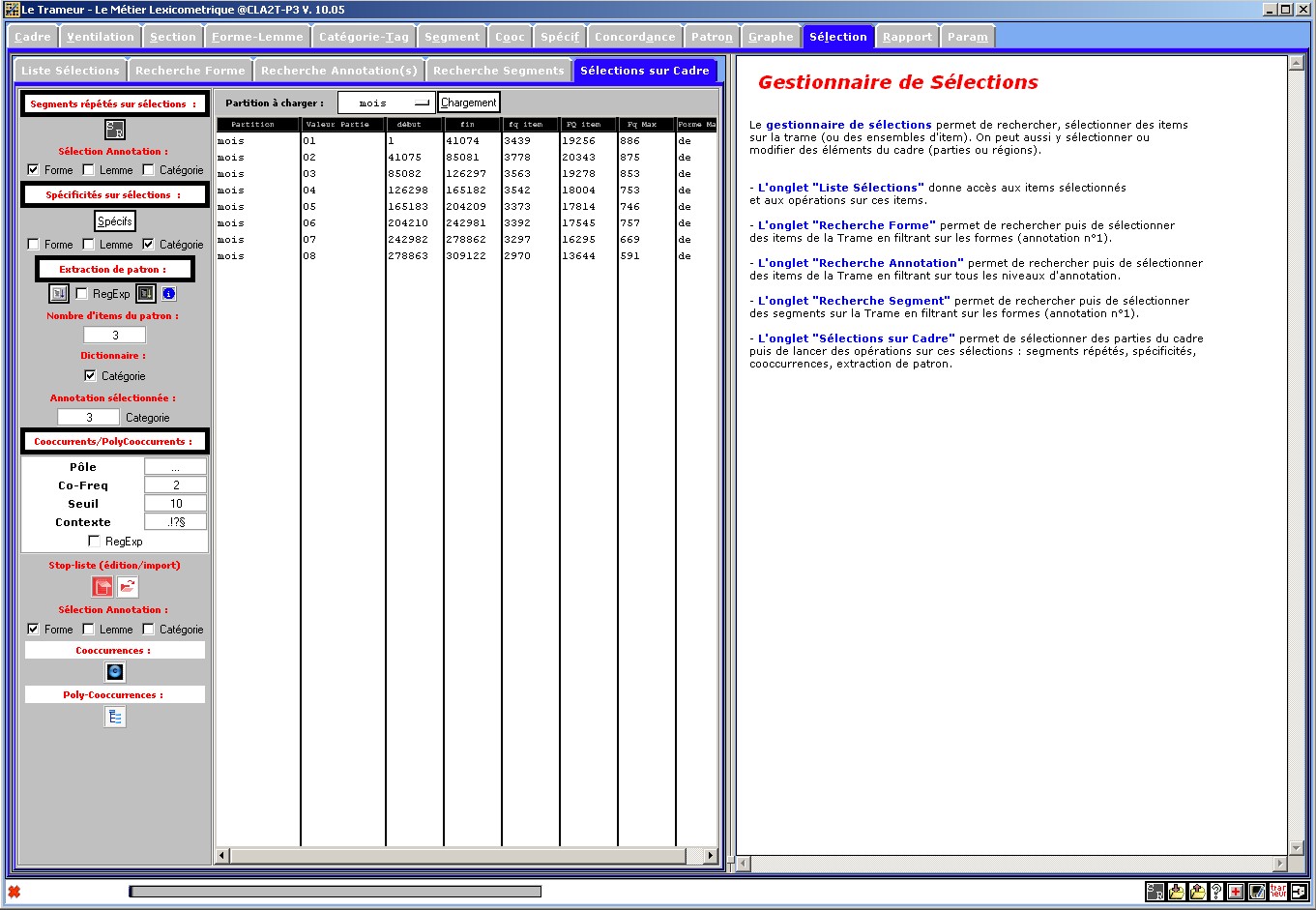
Figure 29 : Gestionnaire de sélections.
Mode "sélection sur le Cadre : sélection de partie".

Figure 30 : Affichage du Graphe de toutes les Relations de type SUJ (annotation de dépendance)
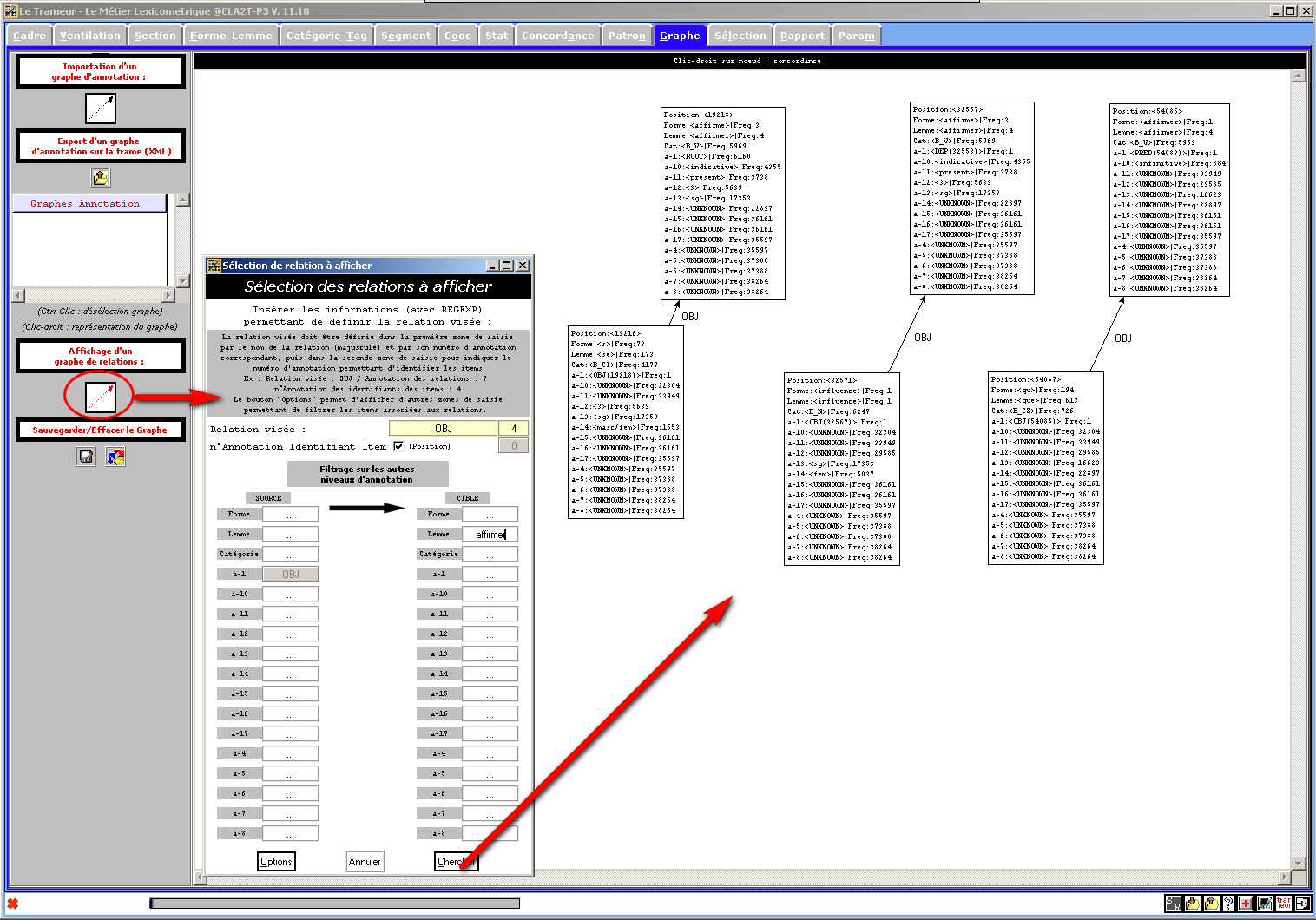
Figure 31 : Les objets de "affirmer" (cf base Rhapsodie2Trameur)
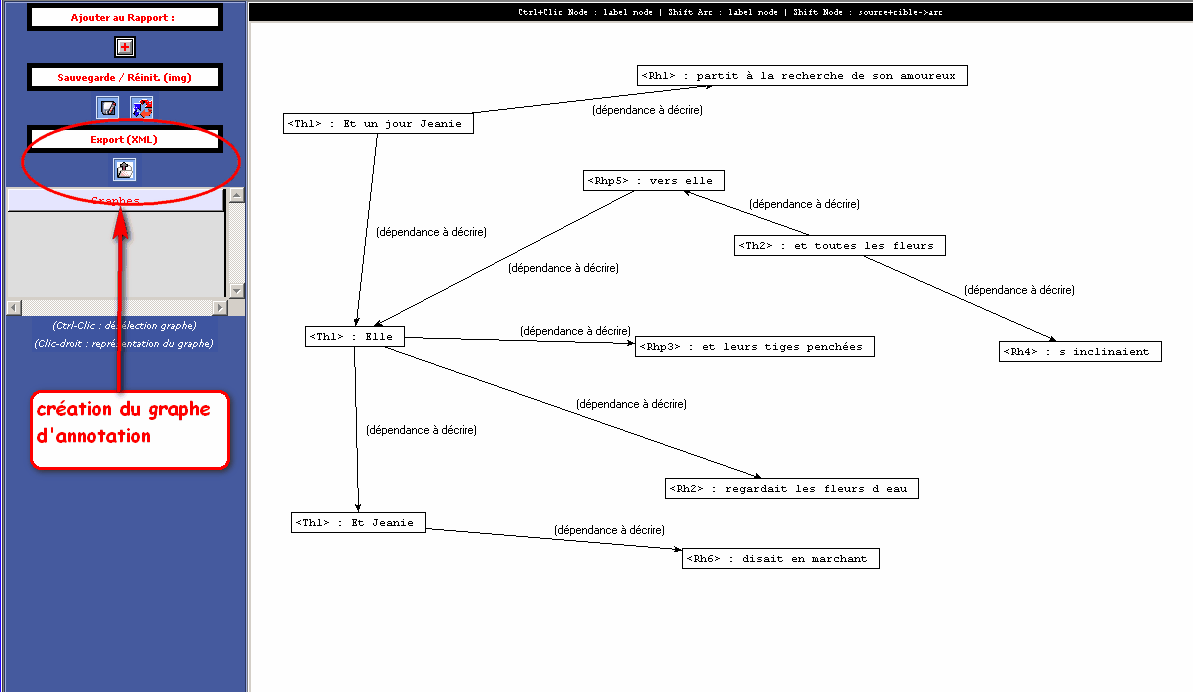
Figure 32 : Graphe et annotations (thème/rhème).
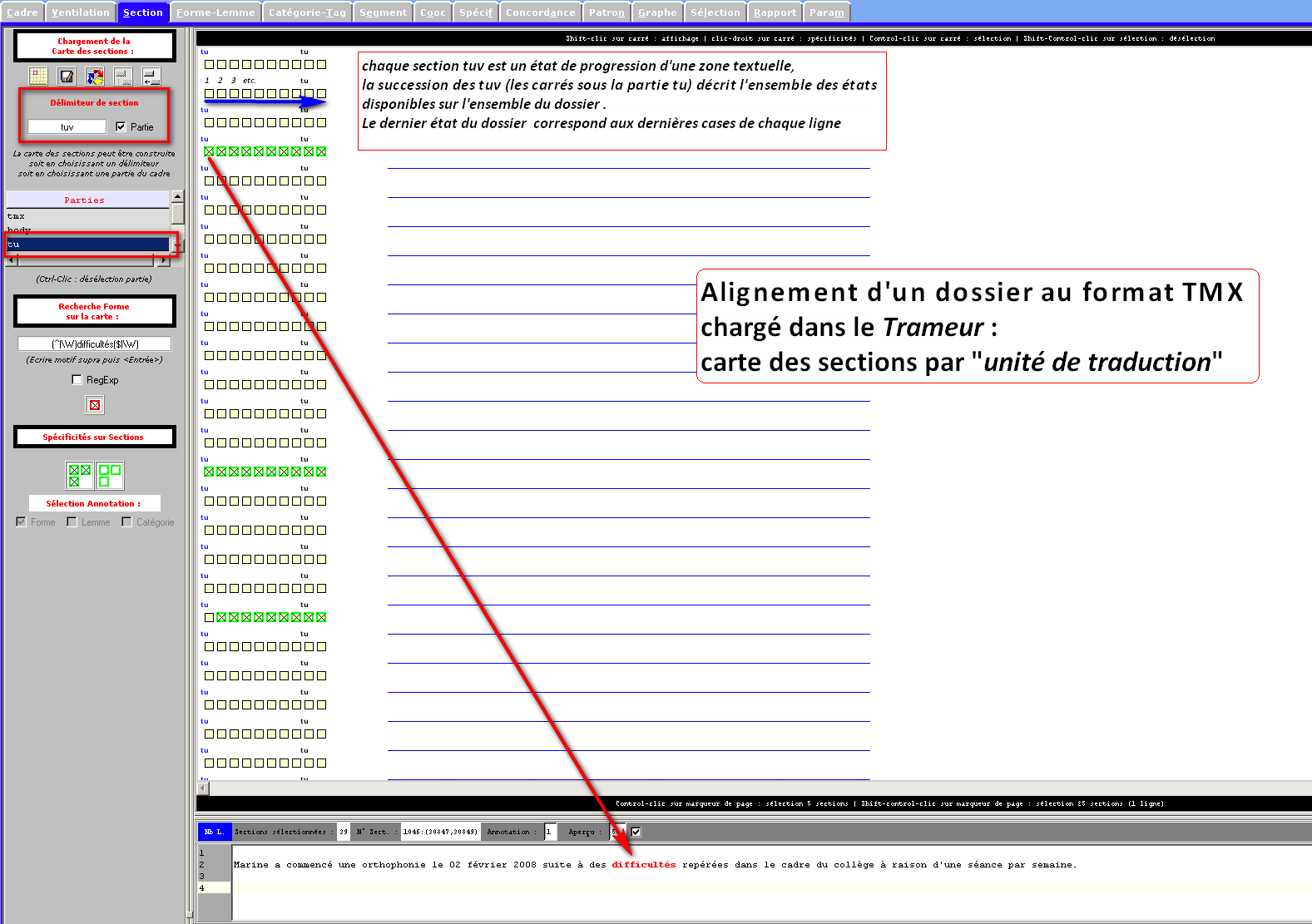
Figure 33 : Chargement d'un fichier aligné au format TMX :
Affichage de la "progression" de l'alignement dans la carte des sections
(illustration sur un alignement de brouillons)
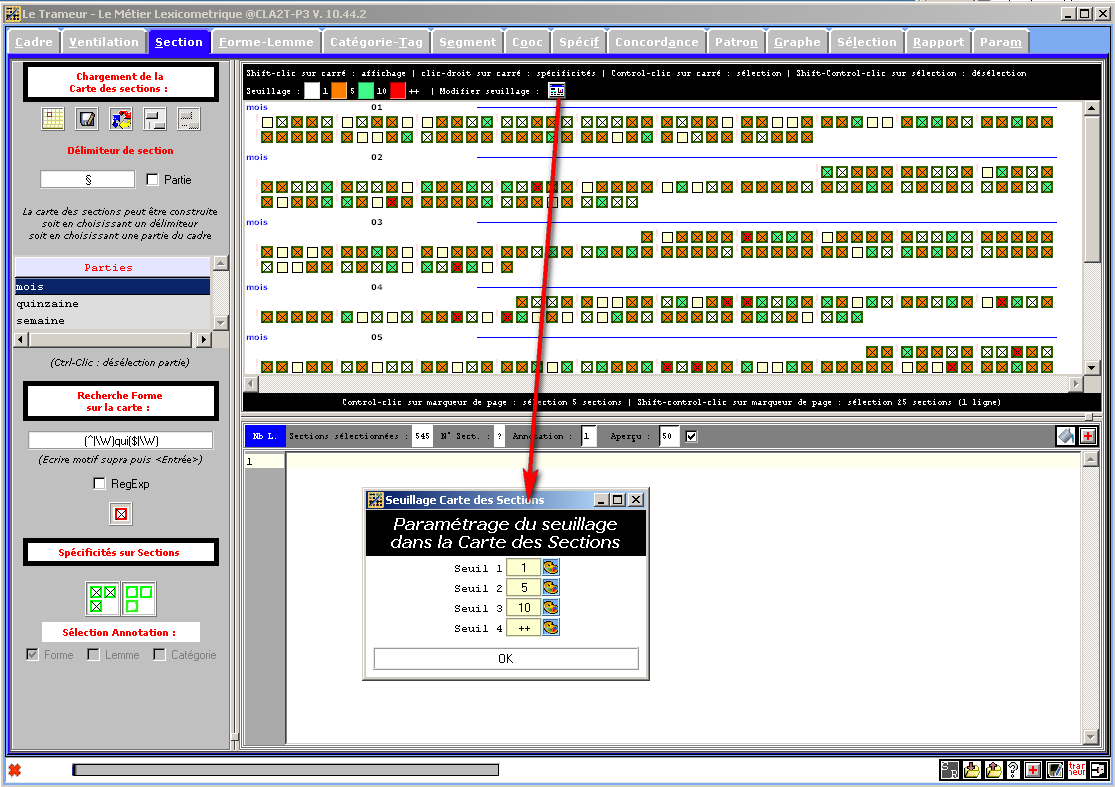
Figure 34 : Seuillage paramétrable dans la Carte des Sections
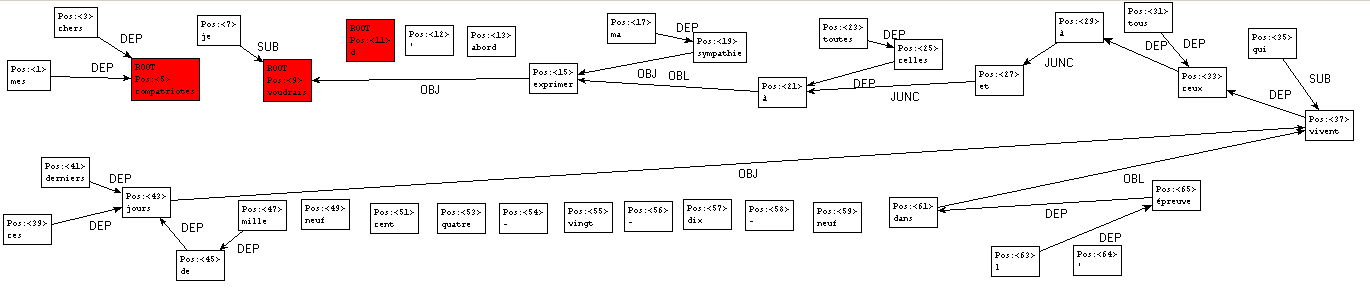
Figure 35 : Graphe de dépendances en contexte (une section)
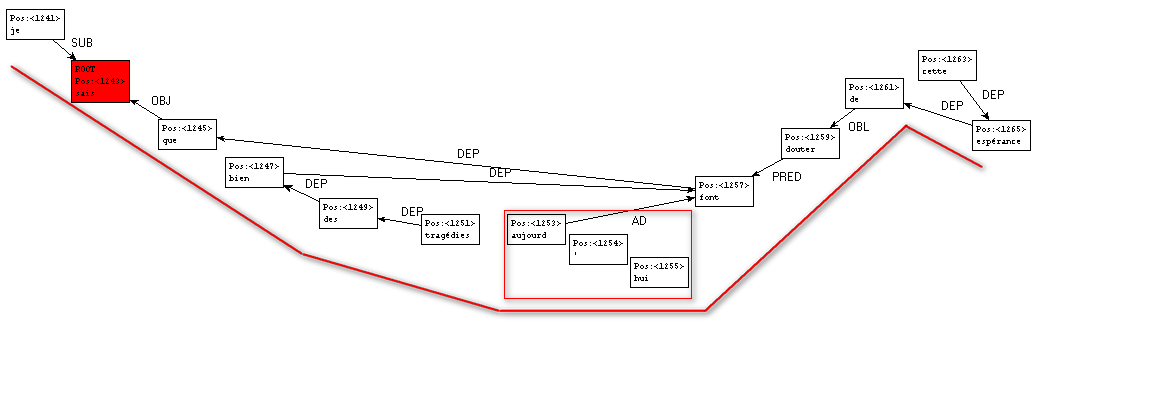
Figure 36 : Graphe de dépendances en contexte (une section)
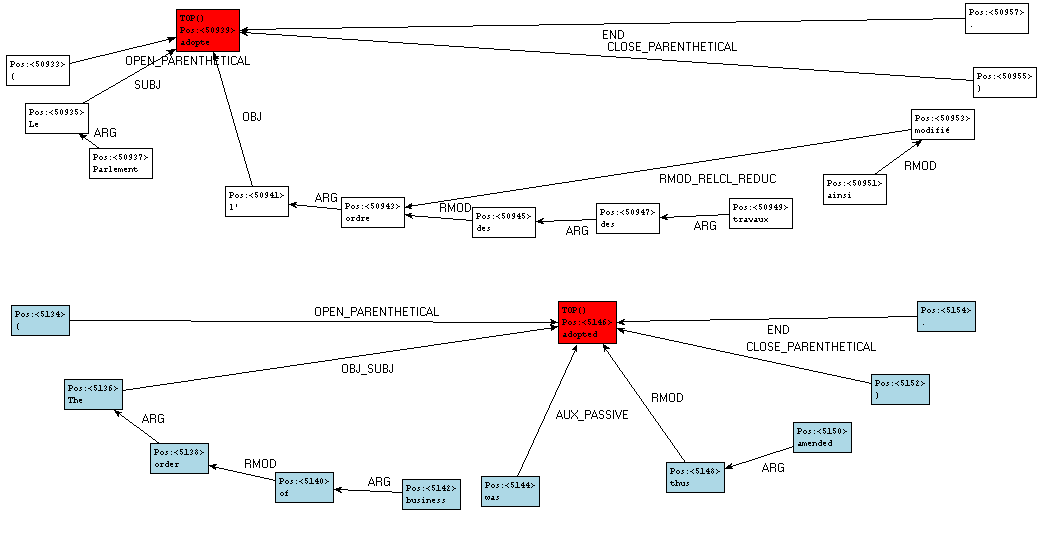
Figure 37 : Graphe de dépendances en contexte (un alignement de section)
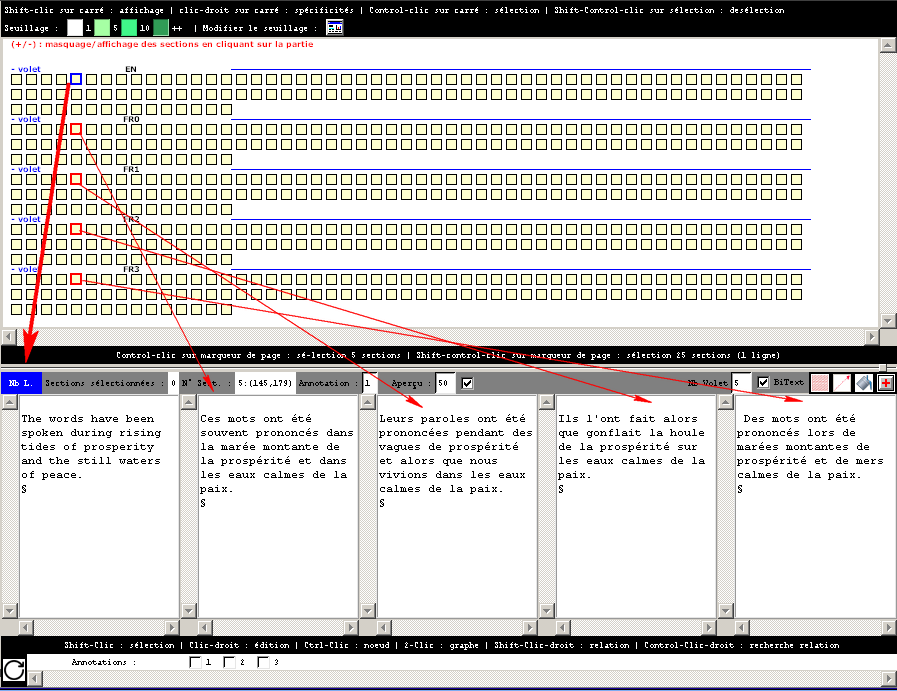
Figure 38 : Edition multi-volets dans une base textométrique constituée par un alignement de plusieurs volets
![]()
Le Trameur "sur la toile"
iTrameur
iTrameur est une application en ligne mettant en oeuvre des fonctionnalités disponibles dans Le Trameur. Application à utiliser dans votre navigateur habituel.iTrameur : http://www.tal.univ-paris3.fr/trameur/iTrameur/
Cette application permet :
(1) de charger un fichier (structuré en parties et/ou découpé en sections) ou une base annotée (même type de structuration et comportant en outre plusieurs couches d'annotation : forme, lemme, catégorie, etc.). Le texte chargé peut aussi être un bitexte (un corpus aligné par exemple).
(2) d'explorer les données chargées via les opérations textométriques "classiques" : dictionnaire, concordancier, spécificités, segments répétés, graphique de ventilation, cooccurrents, etc.
(3) d'explorer des corpus richement annotés (cf documentation dans l'onglet Aide).
Documentation et corpus de test intégrés dans l'onglet Aide de l'application.
iTrameur intègre certains modules déjà disponibles :
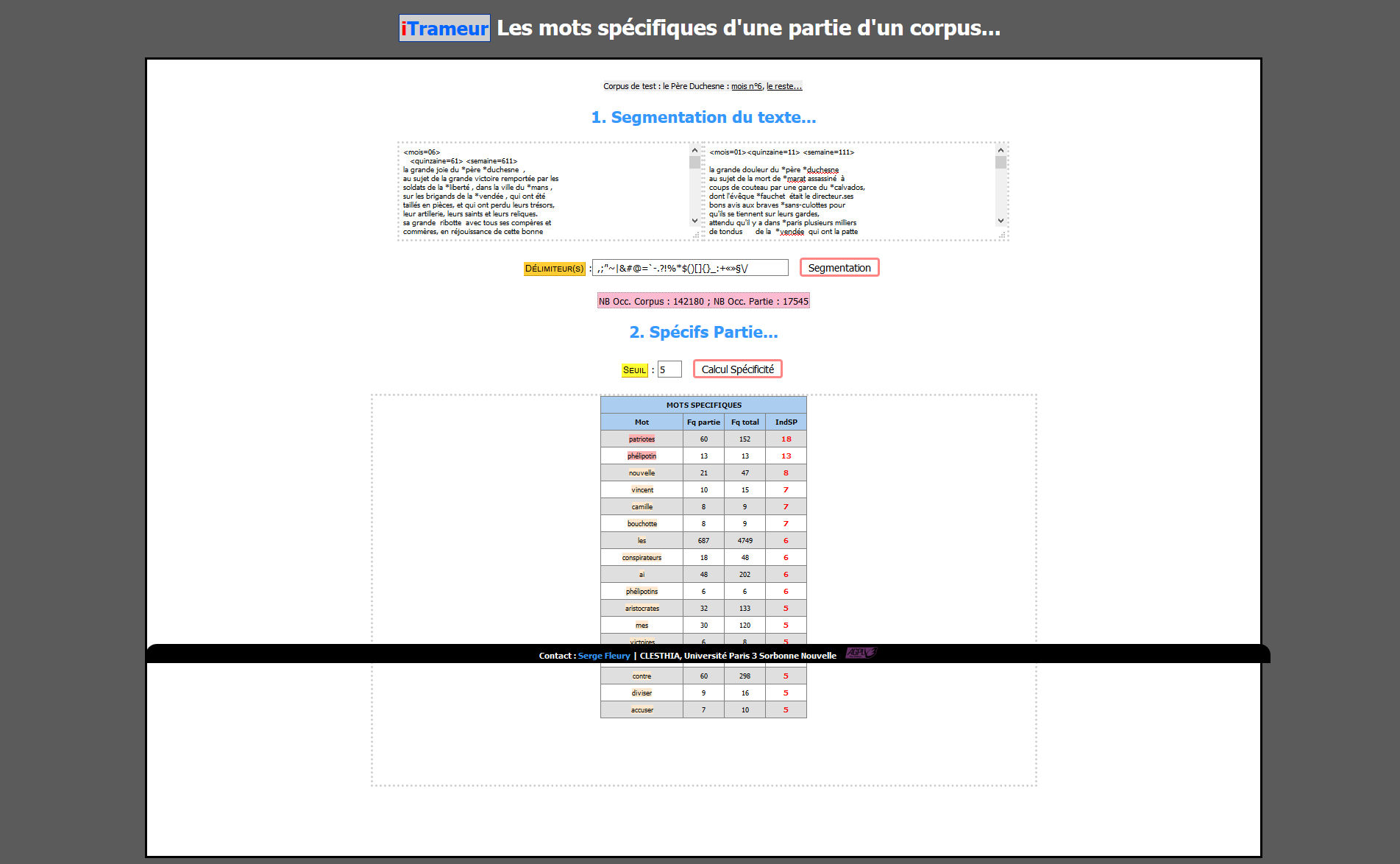
iTrameur-Specif-Partie : les mots spécifiques d'une partie d'un corpus ; navigation via la carte des sections ; illustration ci-dessous sur Le père Duchesne :
[clic sur image pour détails]iTrameur-CooCs-Bitext : les cooccurrents d'un pôle sur un corpus aligné (avec retour en contexte); navigation via la carte des sections alignées ; illustration ci-dessous sur 2 traductions alignées de Einführung in die Psychoanalyse de Sigmund Freud :
[clic sur image pour détails]iTrameur-CooCs : un graphe de cooccurrents sur un pôle donné (avec retour en contexte); navigation via la carte des sections ; illustration ci-dessous sur Le père Duchesne :
[clic sur image pour détails]iTrameur-CooCs-regexp : un graphe de cooccurrents sur un ensemble de pôles définis via une regexp ; navigation via la carte des sections ; illustration ci-dessous sur Le père Duchesne :
[clic sur image pour détails]iTrameur-Réseau CooCs : un réseau de cooccurrences généralisées ; illustrations ci-dessous (à gauche: sur Le père Duchesne ; à droite : sur le discours de politique générale de B. Cazeneuve du 12/12/2016) :

[clic sur image pour détails] (voir aussi figure 21, supra)iTrameur-Nuage : un nuage de mots (version provisoire pour enseignements)




![]()
Le Trameur Version console
Générateur d'un Cadre et d'une Trame (le métier) pour la construction de ressources lexicométriques incrémentales.
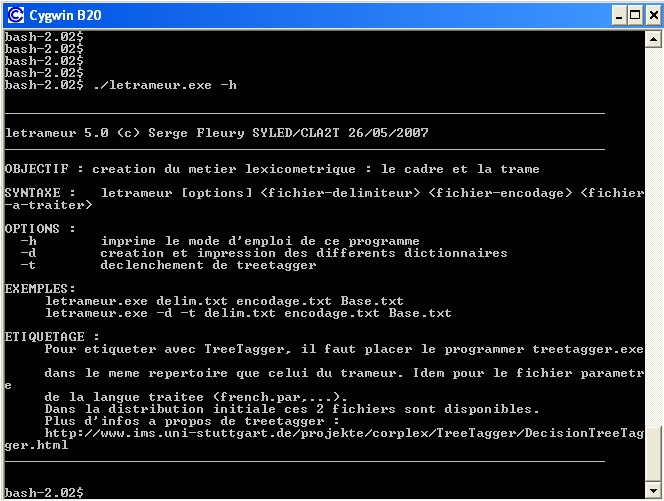
Le Trameur en mode console s'utilise dans une fenêtre de commandes :
Figure 1 : Le Trameur, version console.
Le seul objectif de ce programme est de construire le Cadre et la Trame d'un fichier.
![]()
Liens
Projet Textomètre par Michel Jacobson. Maquette d'un logiciel illustrant le principe de distinction des concepts de "trame" et de "cadre" pour l'exploration textométrique de ressources textuelles. Cette maquette implémente déjà quelques fonctions utilisables et peut-être utiles. Cette maquette illustre aussi les possibilités offertes par les nouveaux standards tels que XML ou Unicode pour la textometrie.
JADT.org : http://jadt.org. Les Journées internationales dAnalyse statistique des Données Textuelles (JADT) réunissent tous les deux ans, depuis 1990, des chercheurs travaillant dans les différents domaines concernés par les traitements automatiques et statistiques de données textuelles : statisticiens, linguistes, sociologues, spécialistes danalyse du discours, informaticiens, spécialistes de lexicographie et de fouille de textes. Elles permettent aux participants de présenter leurs résultats, de confronter leurs outils et leurs expériences.
Lexico : http://www.tal.univ-paris3.fr/lexico/
Wiki Lexicométrie : http://tal.univ-paris3.fr/wakka/wakka.php?wiki=Glossaire
PERCEO : un Projet d'Etiqueteur Robuste pour l'Ecrit et pour l'Oral : http://cnrtl.fr/corpus/perceo/
![]()
Lectures
[Zimina, Fleury, 2015] Zimina Maria, Fleury Serge, "Perspectives de larchitecture Trame/Cadre pour les alignements multilingues". Nouvelles perspectives en sciences sociales : revue internationale de systémique complexe et d'études relationnelles, volume 11, numéro 1, novembre 2015.
http://www.erudit.org/revue/npss/2015/v11/n1/index.html
[Résumé][Fleury, Zimina, 2014], Serge Fleury, Maria Zimina, Trameur: A Framework for Annotated Text Corpora Exploration, Proceedings of COLING 2014, the 25th International Conference on Computational Linguistics: System Demonstrations, August 2014, Dublin, Ireland, pages 57-61, (PDF)
[Fleury, 2013a], Fleury Serge, Approches textométriques des brouillons, (PDF), séminaire projet ANR ECRITURES, 14 janvier 2013.
[Fleury, 2013b], Fleury Serge, Le Trameur. Propositions de description et dimplémentation des objets textométriques, (PDF), (texte en cours).
[Fleury, 2013-2015], Fleury Serge, Annotations Rhapsodie pour le Trameur, (PDF), (texte en cours)
[Fleury, Salem, 2009], Fleury Serge, André Salem (resp.), "Explorations textométriques", n° spécial, revue Lexicometrica, 2009.
[Söze-Duval, 2008], Keyser Söze-Duval. Pour une textométrie opérationnelle. (DOC)
[Salem, 2006], Salem André, Lamalle Cédric, Fleury Serge, "Vers une description formelle des traitements textométriques" (PDF), in Actes JADT 2006, Journées Internationales d'Analyse Statistiques des Données Textuelles, Besançon 2006.
[Lamalle, 2002], Lamalle Cédric, Salem André, "Types généralisés et topographie textuelle dans l'analyse quantitative des corpus textuels" (PDF), in Actes des 6èmes Journées d'analyse statistique des données textuelles, St Malo, Inria, 2002.
[Lebart, 1994], Lebart Ludovix et Salem André (1994), Statistique textuelle (en ligne), Paris, Dunod.
[Lafon, 1984], Lafon Pierre, Dépouillements et statistiques en lexicométrie, Genève-Paris, Slatkine-Champion.
![]()
Programmes complémentaires
DTM2Lexico / Lexico2DTM
Le programme DTM2Lexico transcode un fichier au format DTM (3 fichiers en entrée) en un fichier au format Lexico/Trameur.
Mode d'emploi : DTM2Lexico.exe TDA_dat.txt TDA_dic.txt TDA_txt.txt
En sortie : DTM2LEXICO.txt
Le programme Lexico2DTM transcode un fichier au format Lexico/Trameur en un fichier au format DTM (3 fichiers en sortie).
Mode d'emploi : DTM2Lexico.exe DTM2LEXICO.txt
En sortie (3 fichiers) : LEXICO2DTM_DAT.txt , LEXICO2DTM_FIC.txt, LEXICO2DTM_TXT.txt
L'archive précédente contient des exemples d'entrées et de sorties nécessaires pour chacun des 2 programmes.
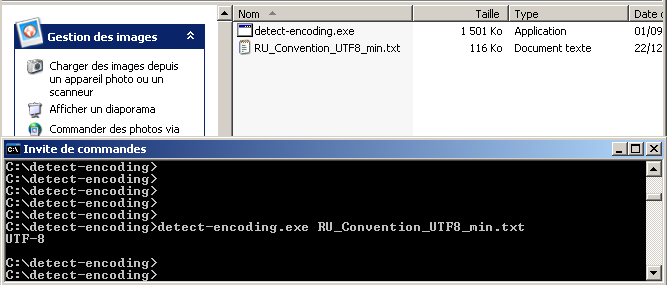
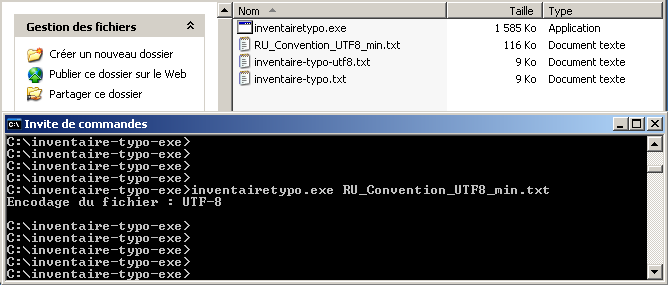
Détection d'encodage
Ce programme s'utilise comme suit : le nom de l'exécutable suivi du fichier à traiter (dans un fenêtre de commandes).
Le programme détecte l'encodage et le retourne.
CONCAT
Concat-v1
Concat-v2
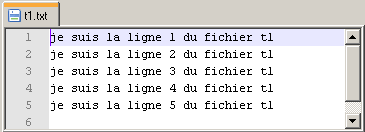
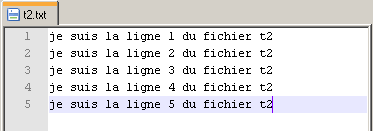
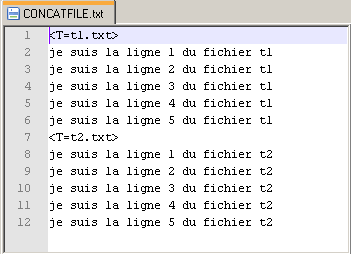
L'archive ci-dessus contenant un petit programme pour Windows réalisant une opération de concaténation de tous les fichiers (format txt brut et encodés en UTF-8) contenus dans un même répertoire. Le lancement du script concat.exe (double-clic sur licône du programme) déclenche la concaténation de tous les fichiers présents dans le répertoire (sauf le programme lui-même) et créé un nouveau fichier nommé CONCATFILE.txt. Les contenus des fichiers de départ sont concaténés lun derrière lautre et délimités par un jalon textuel (une balise) précisant leur origine.
(concat-v1) Le fichier-résultat est une première ébauche de fichier directement pris en charge par les logiciels Lexico ou Le Trameur.
(concat-v2) Le fichier-résultat est une première ébauche de fichier directement pris en charge par les logiciels iTrameur ou Le Trameur.
Dans le second, toutes les balises ouvertes sont fermées alors que dans le premier, les balises fermantes sont implicites et ne sont pas "écrites" dans le fichier résultant (cf image ci-dessous).
Inventaire typographique
Ce programme s'utilise comme suit : le nom de l'exécutable suivi du fichier à traiter (dans un fenêtre de commandes).
Le programme détecte l'encodage et construit l'inventaire typographique dans un fichier en sortie sous la forme d'un concordancier de caractères comme celui-ci : concordance de tous les caractères du fichier avec affichage du premier contexte d'apparition.
Inventaire typographique (v2)
Ce programme s'utilise comme suit : le nom de l'exécutable (dans un fenêtre de commandes et sans argument).
Le programme lit par défaut un fichier nommé params-invent-typo-utf8.txt. Ce fichier (encodé en UTF8) contient 3 lignes décrivant : le nom du fichier à traiter, l'encodage du fichier à traiter, le nom du fichier de sortie dont le contenu sera un concordancier de caractères comme celui-ci : concordance de tous les caractères du fichier avec affichage du premier contexte d'apparition.
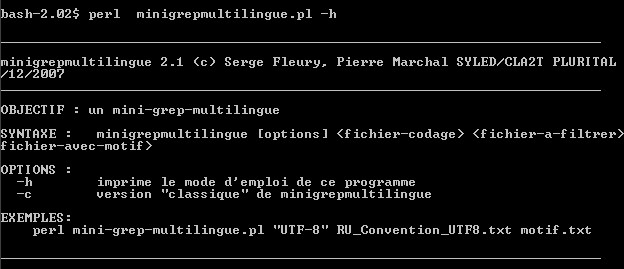
Minigrep multilingue
En entrée : un fichier à filtrer (dit FILEINPUT) dont on connaît l'encodage ; un motif à rechercher et extraire dans FILEINPUT.
En sortie : un fichier au format UTF-8 contenant les lignes du fichier FILEINPUT contenant le motif visé.
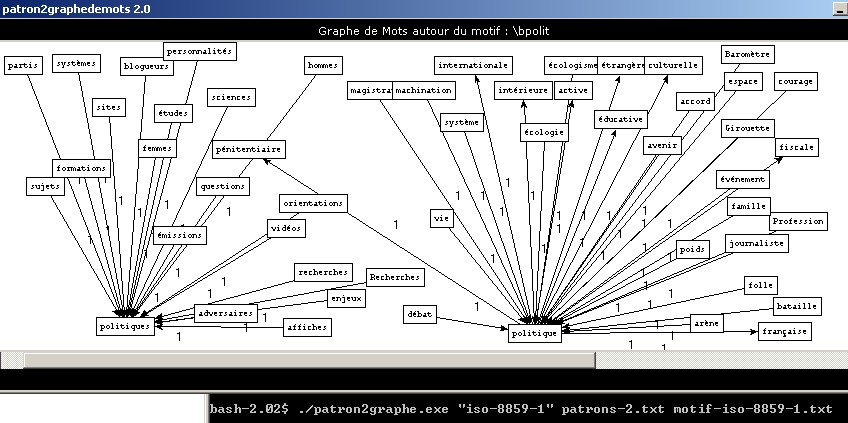
Patron2graphe
Ce programme s'utilise comme suit : patron2graphe.exe "codagedes2fichiers" FichierEnEntree FichierContenantLeMotif
par exemple :
1. Pour afficher tous les noeuds du graphe
patron2graphe.exe "iso-8859-1" patrons-1.txt
2. avec uniquement des noeuds obtenus par filtrage prealable du motif dans les patrons
patron2graphe.exe "iso-8859-1" patrons-1.txt motif-iso-8859-1.txt
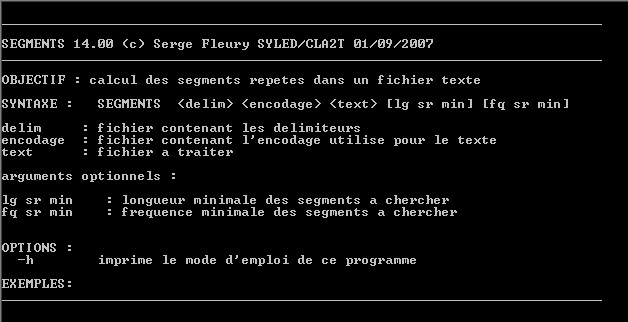
segments
Le programme segments permet de construire les segments répétés dans un fichier texte.
{kind=link}
2007 | CLESTHIA EA-7345 | http://www.tal.univ-paris3.fr/trameur/ | Contact : serge.fleury[at]sorbonne-nouvelle.fr | MàJ : 14/07/2019