
Sommaire
![]()
- Actus mkAlign
- Présentation de mkAlign
- Documentation mkAlign
- Rapports d'utilisation de mkAlign
- Chantiers en Cours autour de mkAlign
- Diffusion de mkAlign
- Téléchargement
- Corpus Alignés au format TMX
- FAQ
- Liens
- Lectures
- Copies d'écran de mkAlign
![]()
Actus mkAlign
07/12/2015 Dernière mise à jour de mkAlign, version : 2.0b160 (Téléchargement)
[02/2016]. mkAlign arrive sous MacOsX : une première distribution du mkAlign est désormais disponible pour MacOsX (cf Téléchargement)
[12/2013]. Atelier "exploration corpus" (mkAlign), organisé par le Consortium Corpus écrits , 10 décembre 2013, Université Paris-Diderot.
![]()
Présentation
La notion de corpus parallèle, qui émerge actuellement dans les travaux de différents chercheurs comme : corpus comportant plusieurs volets qui correspondent chacun à une version dun même texte dans deux ou plusieurs langues différentes, renvoie à des situations connues de coexistence de textes présentant des liens forts dans leur structuration. Le traitement de corpus parallèles suppose une phase préalable dalignement , cest-à-dire de mise en correspondance dans chacun des volets de différents types dunités textuelles [Zimina, 2004]. Aligner des corpus de textes originaux et de leurs traductions cest mettre en relation des unités textuelles qui se correspondent. On peut établir des correspondances entre des unités de différents niveaux : mots, syntagmes, phrases, paragraphes, sections, etc.
Le programme mkAlign permet de construire, corriger et visualiser un alignement de deux textes via un éditeur à double entrée. Il permet dafficher simultanément les textes source et cible pour y rajouter ou corriger des segments équivalents. Ce programme nest pas (seulement) un aligneur automatique. Il est conçu pour aider lutilisateur dans la création, lalignement, la correction et la validation de textes traduits. Lutilisateur garde la maîtrise sur lensemble de ces processus, depuis la mise en correspondance initiale des segments équivalents jusquà lexport final du bi-texte produit. Il appartient à lutilisateur de construire lalignement et de définir son degré de précision (résolution). Cette résolution peut varier pour mettre en évidence les correspondances entre les segments textuels des différents niveaux. La notion de sauvegarde de session de travail (création de fichiers dexport/import de bi-textes au format xml et html) permet de commencer le travail sur un corpus à deux volets textuels, lexporter au format désiré, puis le réimporter plus tard pour y apporter des modifications. La visualisation de lalignement dans une représentation cartographique (bi-text map) offre plusieurs possibilités de gestion de corpus qui partagent des similitudes au plan traductionnel.
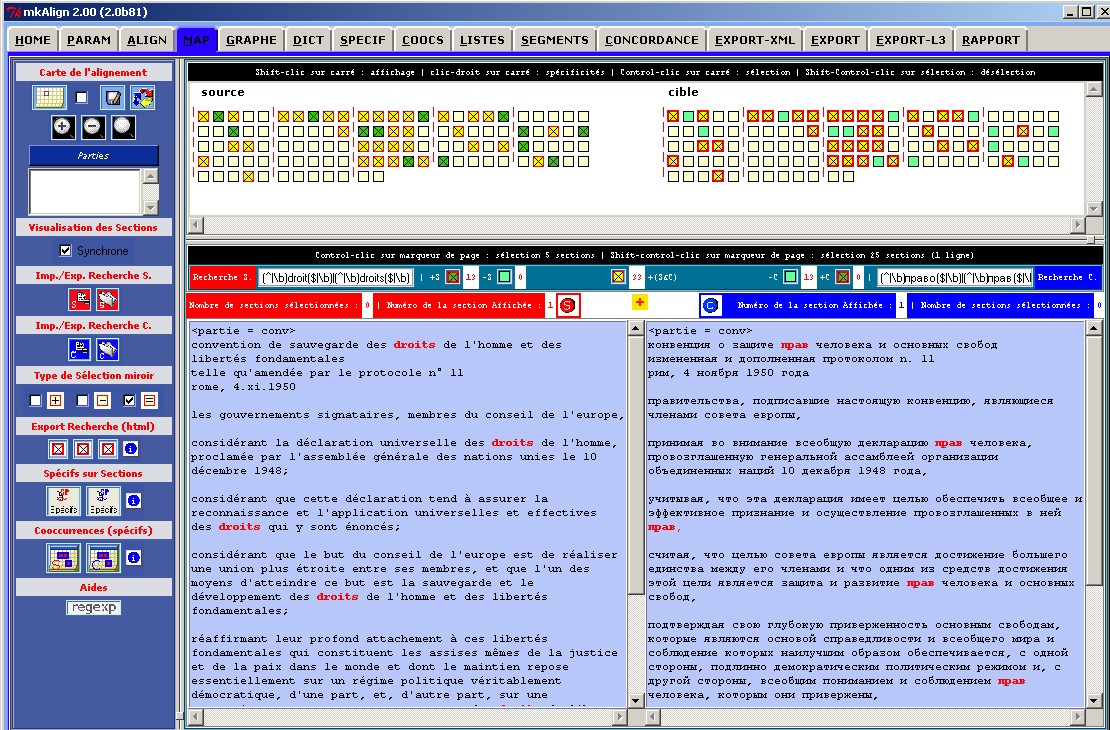
![]()
Documentation
Serge Fleury, Maria Zimina (EA2290 SYLED/CLA2T), "mkAlign, Manuel d'utilisation" : format PDF, format HTML. Cette documentation est aussi disponible (localement) après installation du logiciel.
Démo complète (animation flash)
Démo séquentielle :
Démo 1 : Paramétrage de l'alignement (segmenteur de l'alignement, délimiteurs de formes, encodage des fichiers).
Démo 2 : Principales fonctionnalités de mkAlign (figement de cellule, fractionnement et fusion de cellules par insertion du segmenteur au clavier ou via les modes MERGE et SPLIT) (1)
Démo 3 : Principales fonctionnalités de mkAlign (figement de cellule, fractionnement et fusion de cellules par insertion du segmenteur au clavier ou via les modes MERGE et SPLIT) (2)
Démo 4 : Principales fonctionnalités de mkAlign, recherche de motifs dans l'éditeur de l'alignement
Démo 5 : les segments répétés dans mkAlign, génération, recherche de segments.
Démo 6 : Création de la carte de l'alignement. Recherche de motifs dans la carte.
Démo 7 : Carte de l'alignement. Recherche de cooccurrents d'une forme via les spécificités
Démo 8 : Carte de l'alignement. Recherche des mots spécifiques dans une sélection de sections
Démo 9 : Carte de l'alignement. Recherche des mots dans la carte. Export HTML : source avec motif, cible avec motif, bi-texte avec motif.
Démo 10 : Carte de l'alignement. Chargement de la carte en tenant compte d'une partition prédéfinie.
Démo 11 : Carte de l'alignement. Projection de formes ou de segments sur la carte.
Démo 12 : Sauvegarde d'une session de travail, réimport d'une session
![]()
Rapports d'utilisation de mkAlign
Corpus Europarl (français/anglais)
Corpus Convention (français/russe)
![]()
Chantiers en cours
Repérage de la variation dans les textes par projections lexicométriques ou par comparaison sur alignement construit via mkAlign. Exemples de traitements réalisés :
- Deux traductions du discours d'investiture de B. Obama :
- Deux discours de Ségolène Royal (campagne 2007) :
- export comparaison après alignement automatique
- projection
- Deux discours de Nicolas Sarkozy (conférence de presse 2008) :
- export comparaison après alignement automatique
- projection
- Deux versions du contenu d'un fil RSS
Module de calcul des cooccurrents et des poly-cooccurrents : exemples de rapport construit
![]()
Diffusion de mkAlign
Contact
serge.fleury[at]sorbonne-nouvelle.fr
![]()
Téléchargement
 mkAlign 2.00 (b160) , exécutable sous Windows : http://www.tal.univ-paris3.fr/mkAlign/setup-mkAlign.exe
mkAlign 2.00 (b160) , exécutable sous Windows : http://www.tal.univ-paris3.fr/mkAlign/setup-mkAlign.exe
 mkAlign 2.00 (b160), version MacOsX : http://www.tal.univ-paris3.fr/mkAlign/mkAlign-2.00-OSX.zip
mkAlign 2.00 (b160), version MacOsX : http://www.tal.univ-paris3.fr/mkAlign/mkAlign-2.00-OSX.zip
Pour utiliser cette version de mkAlign, procéder de la manière suivante :
![]()
Corpus alignés au format TMX
Bartleby, I Would Prefer Not To : 2 volets (anglais, français). Alignement réalisé via mkAlign
Discours 1 de Grégoire de Nazianze : 2 volets (grec-ancien, géorgien). Alignement réalisé par : Bastien Kindt, Tamar Pataridze, CIOL-Institut orientaliste; Université catholique de Louvain (Louvain-la-Neuve, Belgique)
Corpus Discours d'investiture :
- Discours d'investiture de B. Obama : version anglaise et 4 traductions en français. Cette archive contient les 5 volets originaux dans 5 fichiers indépendants.
- Discours d'investiture de B. Obama : Alignement des 4 traductions FR via Allongos
Discours de B. Obama le 04/06/2009 (Le Caire) : 3 langues (anglais, français, espagnol).
Discours de B. Obama le 04/06/2009 (Le Caire) : 2 langues (français, arabe).
Convention de sauvegarde des droits de l'homme et des libertés fondamentales : 3 langues.
Corpus DH v1.1 : 2 langues (source : Corpus Droits de l'Homme, LDI, UMR 7187).
La Divine Comédie. Partie 1 : l'Enfer : 5 langues (source : The Project Gutenberg).
Corpus Alice au pays des mesures :
Sources : anglais, japonais, français (traduction 1), français (traduction 2), italien, chinois, polonais, russe, allemand
Alignement Alice au pays des merveilles : 8 langues (anglais, japonais, français (2 traductions), italien, chinois, polonais, russe, allemand) ; lemmatisation via treetagger (EN, FR, IT), segmentation et lemmatisation via chasen (JP), segmentation via NLPIR (ZH).
Alignement Alice au pays des merveilles : idem que le précédent avec affichage sélectif des volets visés.
Chacun des volets de l'alignement est accessible ici (extraction via mkAlign à partir du TMX précédent) :
- FR (traduction 1), FR (traduction 1 lemme), FR (traduction 2), FR (traduction 2 lemme), EN, EN (lemme), IT, IT (lemme), JP, JP (lemme), JP (segmenté), ZH, ZH (segmenté), PL, RU, ALL.
- Tous ces fichiers intègrent en fin de chaque ligne le segmenteur # permettant de les recharger alignés 2 à 2 en utilisant le segmenteur par défaut de mkAlign.
Kit d'alignement Alice : fichier au format RTF contenant dans une colonne la version de référence en anglais, et une colonne à compléter en y intégrant le nouveau volet à aligner.
Ulysse : version anglaise et traduction en français (Source : Ulysse, par jour (1) (jusqu'au 21/01/2013), Ulysse, par jour (2) (depuis le 21/01/2013))
- Alignement complet (dans l'état actuel de la traduction)
Corpus Le Vieil Homme Aligné :
Le vieil homme et la mer (extraits) : version anglaise et 3 traductions en français (Source : embruns.net)
- Alignement complet (extraits)
- Affichage sélectif des volets (extraits)
- Le Vieil Homme Aligné : Alignement des 3 traductions FR via Allongos
Le vieil homme et la mer (extraits) : 2 volets (volet français) traduction de François Bon (2012), (volet français) traduction de slate.fr (2012)
- Alignement complet (extraits choisis par les traducteurs de slate.fr)
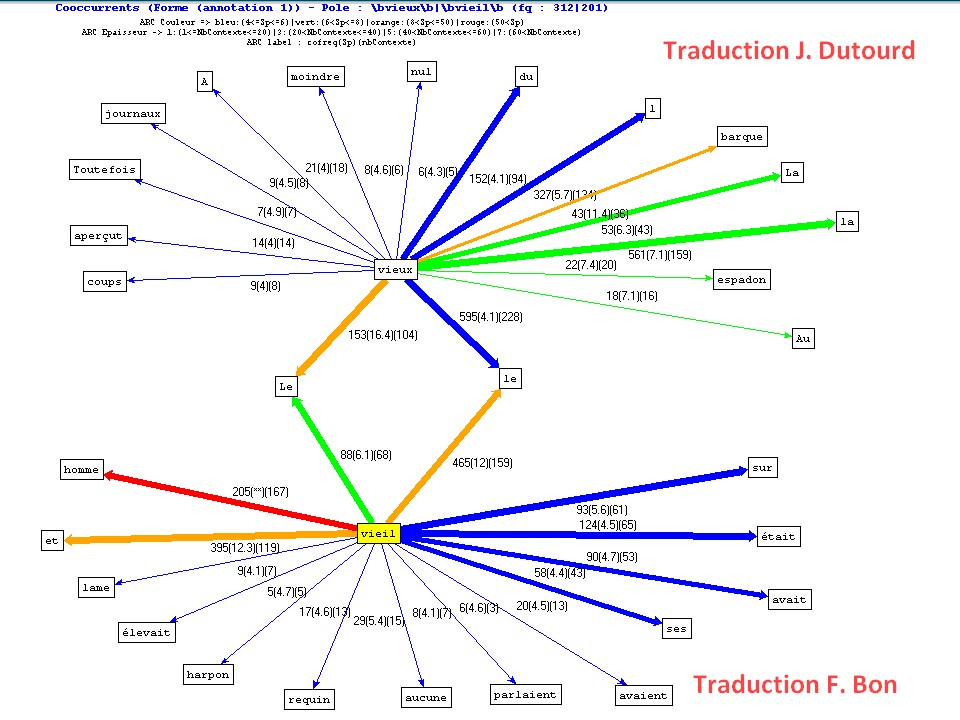
Le vieil homme et la mer (extraits) : 4 volets : (volet anglais) Hemingway (version originale), (volet français) traduction de J. Dutourd (1952), (volet français) traduction de François Bon (2012), (volet français) traduction de slate.fr (2012)
- Alignement complet (disponible sur demande à serge.fleury[at]sorbonne-nouvelle.fr)
- Affichage sélectif des volets (disponible sur demande à serge.fleury[at]sorbonne-nouvelle.fr)
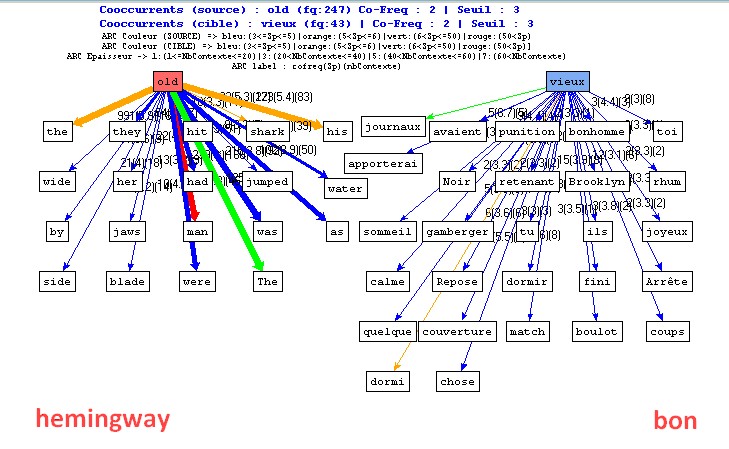
Le vieil homme et la mer (texte intégral). 4 volets : (volet anglais) Hemingway (version originale), (volet français) traduction de J. Dutourd (1952), (volet français) traduction de François Bon (2012), (volet espagnol) Colección "Dante Quincenal" (1989)
- Alignement complet (disponible sur demande à serge.fleury[at]sorbonne-nouvelle.fr)
- Affichage sélectif des volets (disponible sur demande à serge.fleury[at]sorbonne-nouvelle.fr)
- Le Vieil Homme Aligné : Alignement des 2 traductions FR via Allongos (disponible sur demande à serge.fleury[at]sorbonne-nouvelle.fr)
- Repérage de la variation dans les 2 volets français (disponible sur demande à serge.fleury[at]sorbonne-nouvelle.fr)
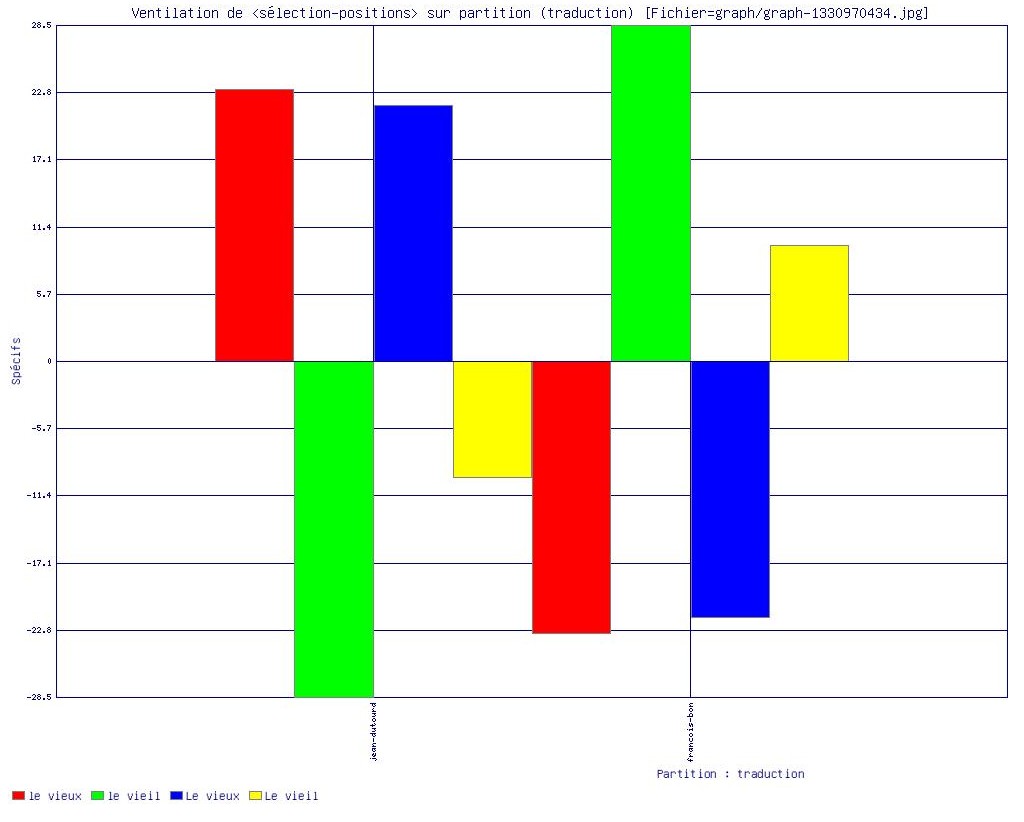
"le vieux" versus "le vieil" dans les 2 traductions en français (via Le Trameur)
Cooccurrents "vieux/vieil" dans les 2 traductions en français (via Le Trameur)
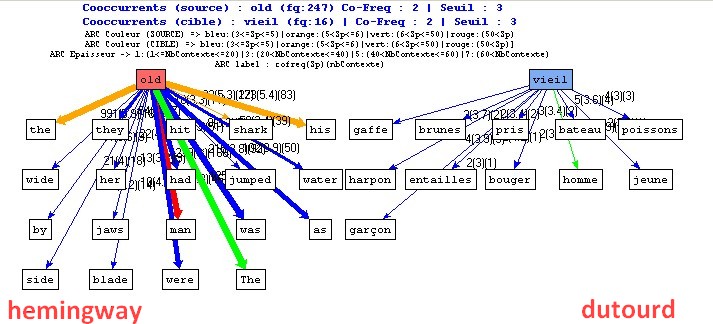
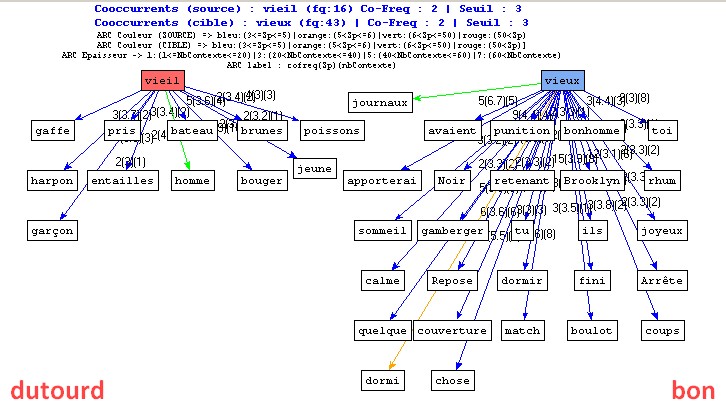
Cooccurrents "vieux/vieil" dans les bitextes anglais/français (via mkAlign)
{kind=link}
![]()
FAQ
![]()
Liens
Sur la page personnelle d'Olivier Kraif : une section pointant vers des ressources concernant la constitution et l'exploitation de corpus multilingues, comparables, parallèles ou alignés.
Alignator : un aligneur en ligne développé par Kim Gerdes.
Alignoscope : navigation dans une base de textes multilingues (Romain Rolland, Jean Christophe) par Kim Gerdes.
COOCS : Outils lexicométriques pour l'analyse des cooccurrences développés par William Martinez.
OPUS : an open source parallel corpus.
WIT3 : Web Inventory of Transcribed and Translated Talks is a ready-to-use version for research purposes of the multilingual transcriptions of TED talks.
![]()
Lectures
Fleury Serge, Zimina Maria, "Exploring Translation Corpora with mkAlign", in Translation Journal, Volume 11, n°1 January 2007.
Fleury Serge, Zimina Maria, "Utilisations de mkAlign pour la traduction philologique" (PDF), in Actes JADT 2008, Journées Internationales d'Analyse Statistiques des Données Textuelles, Lyon, 2008.
Fleury Serge, André Salem (resp.), "Explorations textométriques", n° spécial, revue Lexicometrica (2009)
Leblanc Jean-Marc, Martinez William, "L'analyse contrastive des réseaux de cooccurrence Le monde dans les discours des présidents de la Cinquième République" (PDF), in Actes JADT 2006, Journées Internationales d'Analyse Statistiques des Données Textuelles, Besançon, 2006.
Martinez William, Zimina Maria, "Utilisation de la méthode des cooccurrences pour l'alignement des mots de textes bilingues." (PDF), in Actes JADT 2002, Journées Internationales d'Analyse Statistiques des Données Textuelles, St Malo, 2002.
Véronis Jean, Alignement de corpus multilingues (PDF), in Pierrel, J.-M., éditeur, Ingénierie des langues, Informatique et systèmes dinformation, chapitre 6, pages 151172. Hermès Sciences, 2000.
Zimina Maria, Approches quantitatives de l'extraction de ressources traductionnelles à partir de corpus parallèles. (slides) Présentation à la soutenance de thèse, Université de
Zimina Maria, Lalignement textométrique des unités lexicales à correspondances multiples dans les corpus parallèles. (PDF) Conférence aux 7es Journées internationales d'Analyse statistique des Données Textuelles JADT'2004, Louvain-la-Neuve (Belgique), 2004.
Zimina Maria, Topographie bi-textuelle et approches quantitatives de lextraction de ressources traductionnelles à partir de corpus parallèles (PDF), in Actes des 7es Journées scientifiques du Réseau de chercheurs "Lexicologie, Terminologie, Traduction", Institut supérieur de traducteurs et interprètes (ISTI), Bruxelles, 8-10 septembre 2005.
Zimina Maria, Corpus multilingues : exploration textométrique dans l'espace intertextuel, in Ballard M., Pineira-Tresmontant C. (éd) Les corpus en linguistique et en traductologie" (p. 107-121), Artois Presses Université, 2007.
![]()
Copies d'écran
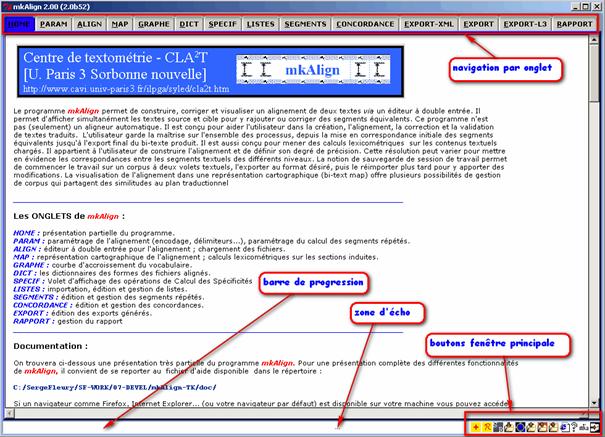
Figure 1 : Interface.
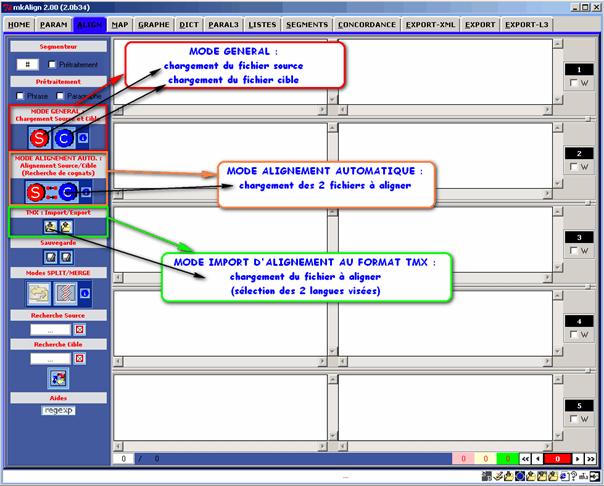
Figure 2 : Alignement.
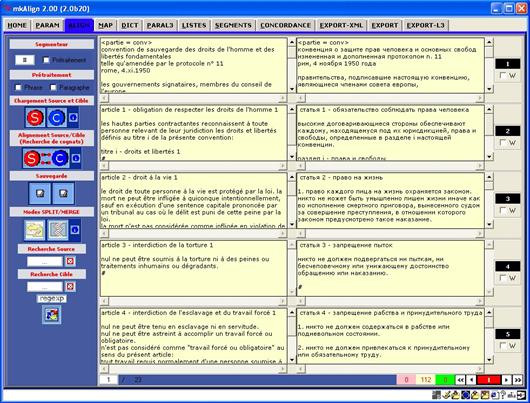
Figure 3 : Editeur (source/cible).
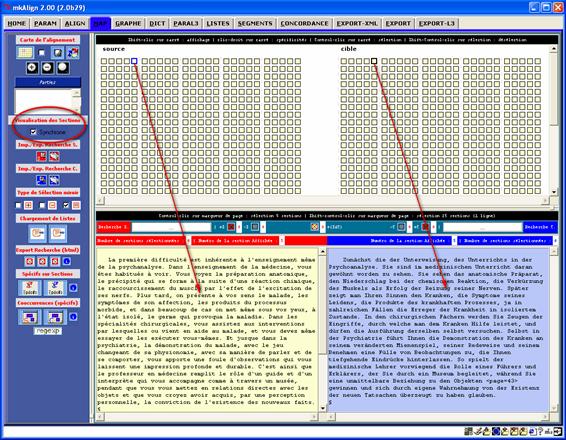
Figure 4 : Carte (source/cible).
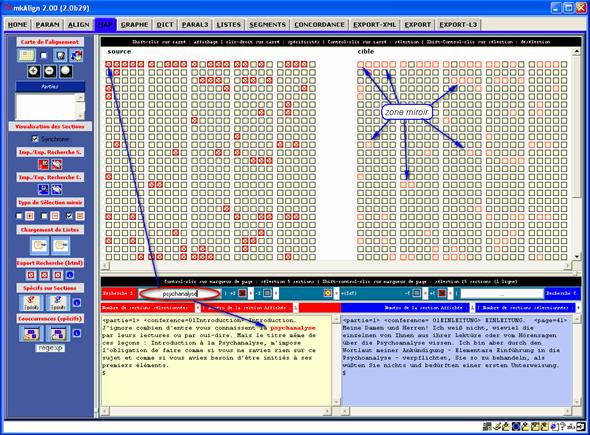
Figure 5 : Recherche/Miroir.
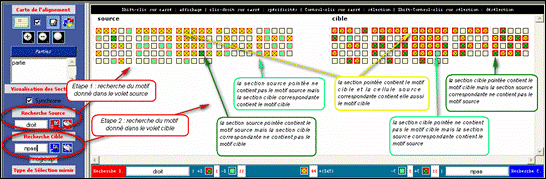
Figure 6 : Recherche (Intersection, Différence).
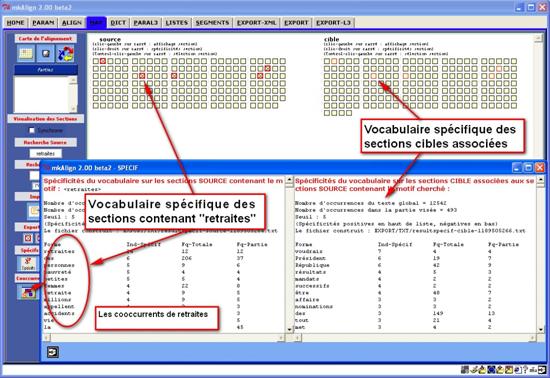
Figure 7 : Spécificités (source/cible).
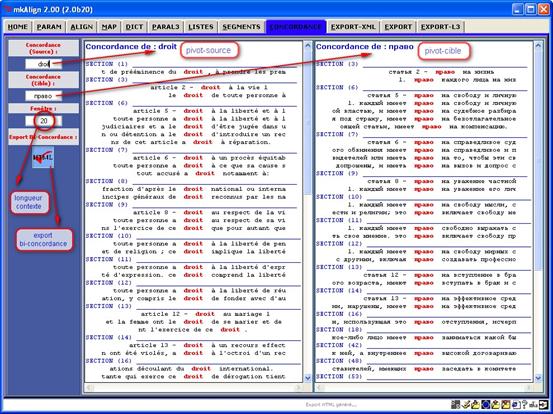
Figure 8 : Bi-Concordance.
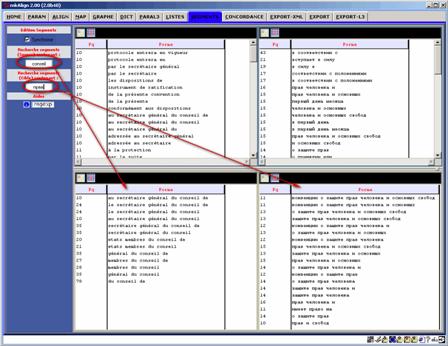
Figure 9 : Segments (source/cible).
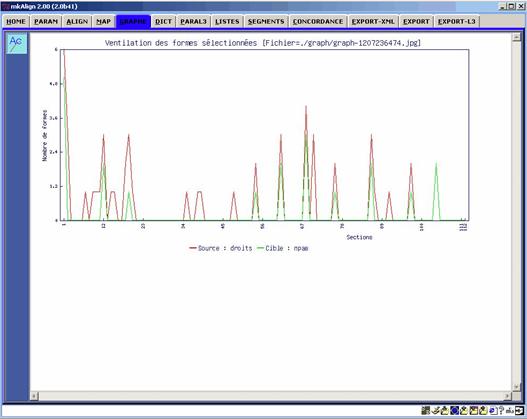
Figure 10 : Ventilations (source/cible).
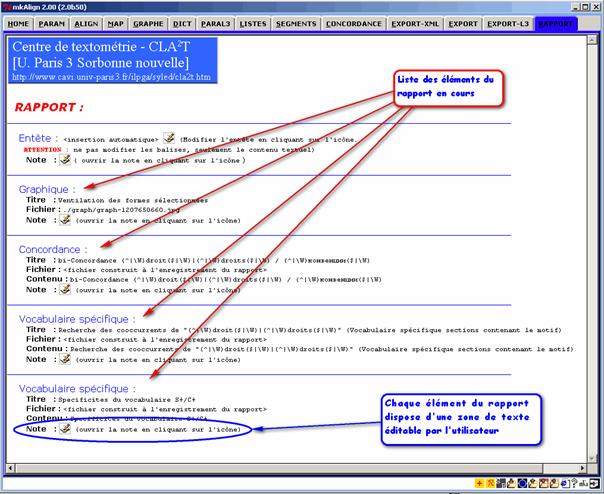
Figure 11 : Rapport.
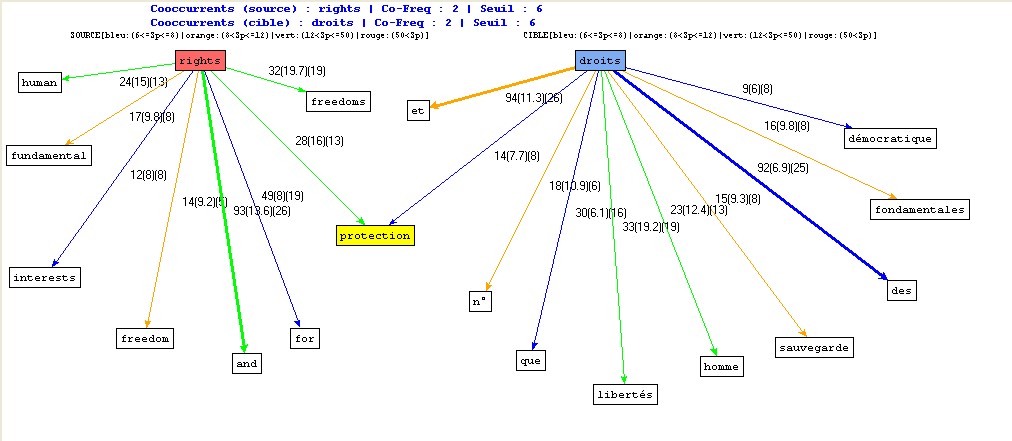
Figure 12 : Réseau de cooccurents autour d'un pôle (source et cible).
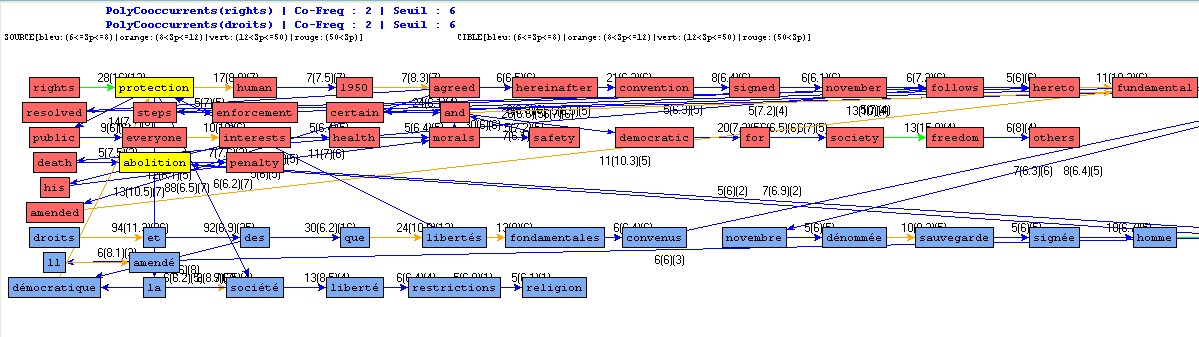
Figure 13 : Réseau de polycooccurents autour d'un pôle (source et cible).
2005 | CLA2T/SYLED | http://www.tal.univ-paris3.fr/mkAlign/ | serge.fleury[at]sorbonne-nouvelle.fr | 2016