- iTrameur : Des programmes en ligne (utilisables dans votre navigateur habituel) et reproduisant des calculs disponibles dans Le Trameur : http://www.tal.univ-paris3.fr/trameur/#iTrameur.
- Projet ANR ProText : Le projet Pro-TEXT ambitionne délucider les dynamiques du processus de textualisation, grâce à la modélisation des relations entre les indices temporels des processus cognitifs et la nature des formes linguistiques produites lors de lécriture enregistrée. Cette recherche interdisciplinaire innovante vise à rendre compte des régularités de production des jets textuels (séquences produites entre deux pauses: [p] le sens de [p]) en français, à travers une approche inductive articulant des données linguistiques et comportementales multi-paramétiques, et des méthodes dapprentissage automatique. Cette approche novatrice donnera lieu à une analyse linguistique complète des jets textuels en mettant en relation les régularités incrémentales du processus de textualisation et les contraintes cognitives et contextuelles de la performance langagière. Le projet Pro-TEXT va en outre développer des méthodes et des outils modélisant ces régularités et mettant en évidence des schémas de textualisation.
- Projet ANR E-CALM : À partir dun corpus décrits délèves et détudiants que le projet rendra accessible en open access, il sagit de caractériser certaines compétences scripturales (orthographe et cohérence textuelle) et de mieux comprendre la manière dont les enseignants, par leurs interventions sur les copies, orientent lécriture, afin détayer laccompagnement de la réécriture de lécole à luniversité.
- Projet ANR NaijaSynCor : NaijaSynCor (A Corpus-based Macro-Syntactic Study of Naija, aka Nigerian Pidgin) takes an exhaustive and in-depth look at the structure of Naija (Nigerian Pidgin) in Nigeria today. Spoken by educated Nigerians, it has been proved to develop in Lagos as a discrete language, separate from Nigerian English. This study proposes to assess whether this holds true for the rest of Nigeria where Naija is spoken by over 75 million speakers. It examines diachronic, diatopic, diaphasic, diastratic, and genre variation.
- Projet ECRISCOL : Le projet de recherche ECRISCOL est centré sur lanalyse des écrits produits en situation scolaire. Il sagit de faire le rapport entre des traits caractéristiques de ces écrits et des situations dapprentissage et denseignement suscitant leur production, de manière à faire apparaître des dispositifs didactiques favorisant certains types d'écrits et certaines stratégies ou procédures d'écriture.
- CFPP2000 : S. Branca-Rosoff, S. Fleury, F. Lefeuvre, M. Pires
Discours sur la ville. Corpus de Français Parlé Parisien des années 2000 (CFPP2000)
http://cfpp2000.univ-paris3.fr/- Le Trameur : Le Trameur (http://www.tal.univ-paris3.fr/trameur/) est un programme danalyse comportant de nombreuses fonctionnalités pour lanalyse automatique, statistique et documentaire de textes en vue de leur profilage sémantique, thématique et de leur interprétation. Ce logiciel est à lorigine un outil de textométrie : il intègre les fonctionnalités classiques de ce type doutils dans ce domaine. Il dispose aussi des fonctionnalités particulières qui permettent dannoter dynamiquement des corpus ou dexplorer des ressources richement annotées (treebanks monolingues/multilingues ou des alignements).
- Développement de Lexico3
- "Corpus Le Monde Chronologique" : Analyse de Corpus de Veille avec Lexico3
- mkAlign : Le programme mkAlign permet de construire et visualiser l'alignement de deux textes en modifiant au besoin la correspondance entre leurs segments respectifs. Ce programme n'est pas uniquement un aligneur automatique. Il appartient à l'utilisateur de construire l'alignement et de définir son degré de précision (résolution). Cette résolution peut varier pour mettre en évidence les correspondances entre les segments textuels de différents niveaux.
- Corpus alignés au format TMX
Discours d'investiture de B. Obama : version anglaise et 4 traductions en français
Discours de B. Obama le 04/06/2009 (Le Caire) : 3 langues (anglais, français, espagnol).
Discours de B. Obama le 04/06/2009 (Le Caire) : 2 langues (français, arabe).
Convention de sauvegarde des droits de l'homme et des libertés fondamentales : 3 langues.
Corpus DH v1.1 : 2 langues (source : Corpus Droits de l'Homme, LDI, UMR 7187).
La Divine Comédie. Partie 1 : l'Enfer : 5 langues (source : The Project Gutenberg).
Corpus Alice au pays des mesures :
Sources : anglais, japonais, français (traduction 1), français (traduction 2), italien, chinois, polonais, russe, allemand
Alignement Alice au pays des merveilles : 8 langues (anglais, japonais, français (2 traductions), italien, chinois, polonais, russe, allemand) ; lemmatisation via treetagger (EN, FR, IT), segmentation et lemmatisation via chasen (JP), segmentation via ICTCLAS (ZH).
Alignement Alice au pays des merveilles : idem que le précédent avec affichage sélectif des volets visés.
Chacun des volets de l'alignement est accessible ici (extraction via mkAlign à partir du TMX précédent) :
- FR (traduction 1), FR (traduction 1 lemme), FR (traduction 2), FR (traduction 2 lemme), EN, EN (lemme), IT, IT (lemme), JP, JP (lemme), JP (segmenté), ZH, ZH (segmenté), PL, RU, ALL.
- Tous ces fichiers intègrent en fin de chaque ligne le segmenteur # permettant de les recharger alignés 2 à 2 en utilisant le segmenteur par défaut de mkAlign.
Kit d'alignement Alice : fichier au format RTF contenant dans une colonne la version de référence en anglais, et une colonne à compléter en y intégrant le nouveau volet à aligner.
Ulysse : version anglaise et traduction en français (Source : Ulysse, par jour)
- Alignement complet (dans l'état actuel de la traduction)
Corpus Le Vieil Homme Aligné :
Le vieil homme et la mer (extraits) : version anglaise et 3 traductions en français (Source : embruns.net)
- Alignement complet (extraits)
- Affichage sélectif des volets (extraits)
Le vieil homme et la mer (extraits) : 2 volets (volet français) traduction de François Bon (2012), (volet français) traduction de slate.fr (2012)
- Alignement complet (extraits choisis par les traducteurs de slate.fr)
Le vieil homme et la mer (extraits) : 4 volets : (volet anglais) Hemingway (version originale), (volet français) traduction de J. Dutourd (1952), (volet français) traduction de François Bon (2012), (volet français) traduction de slate.fr (2012)
- Alignement complet (disponible sur demande à serge.fleury[at]univ-paris3.fr)
- Affichage sélectif des volets (disponible sur demande à serge.fleury[at]univ-paris3.fr)
Le vieil homme et la mer. 4 volets : (volet anglais) Hemingway (version originale), (volet français) traduction de J. Dutourd (1952), (volet français) traduction de François Bon (2012), (volet espagnol) Colección "Dante Quincenal" (1989)
- Alignement complet (disponible sur demande à serge.fleury[at]univ-paris3.fr)
- Affichage sélectif des volets (disponible sur demande à serge.fleury[at]univ-paris3.fr)
- Repérage de la variation dans les 2 volets français (disponible sur demande à serge.fleury[at]univ-paris3.fr)
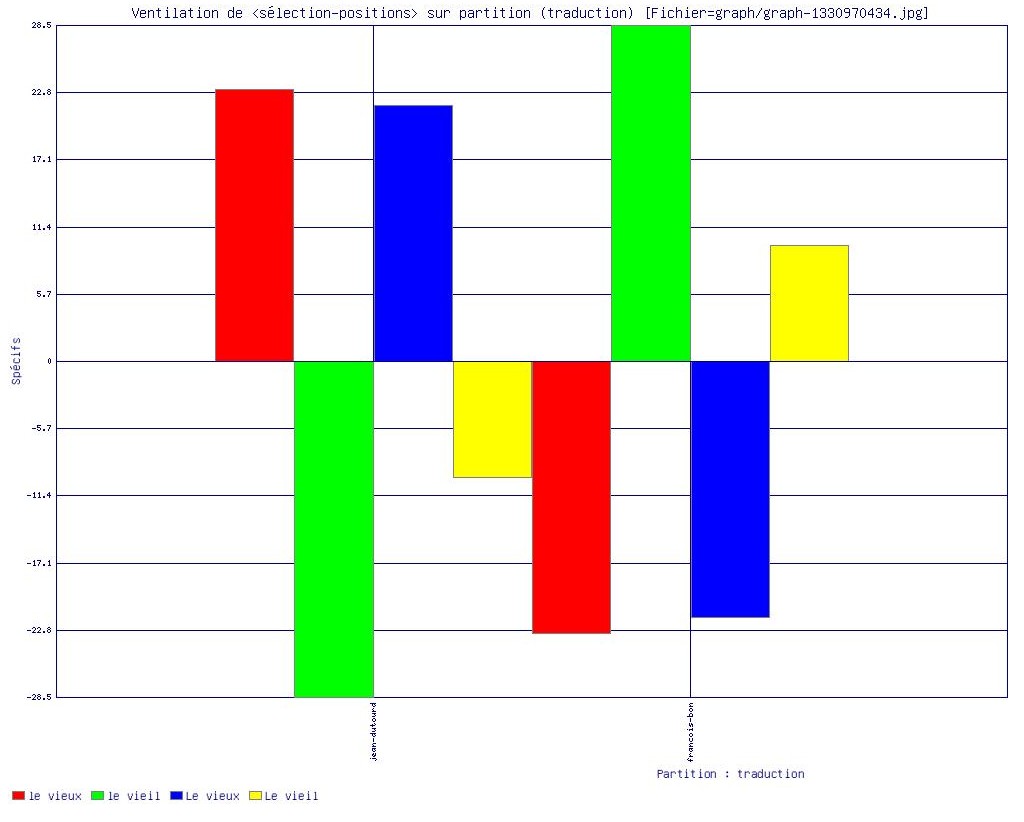
"le vieux" versus "le vieil" dans les 2 traductions en français (via Le Trameur)
Cooccurrents "vieux/vieil" dans les 2 traductions en français (via Le Trameur)- Projet ANR 2011-2013 ECRITURES, Brouillons d'écrits sociaux : approche génétique, discursive et textométrique de l'écriture professionnelle.
- Contexte du Projet
- Description scientifique
- Programme scientifique
- Bibliographie
- Membres
- Corpus du Projet
- Publications
- Tâches
- Projet innovant Approche discursive et génétique des brouillons : les écrits des travailleurs sociaux dans le champ de l'enfance en danger, responsable G. Cislaru
- Séries chronologiques alignées (29/08/2008). Le Monde "en surface" vs Le Monde "profond".
- Exploration textométrique dans une série chronologique constituée de deux volets d'un corpus de presse "alignables" par jour et par article.
- La variation dans les textes
- Repérage de la variation dans les textes par projections lexicométriques sur alignement construit via mkAlign (Janvier 2008). 3 exemples de traitements réalisés : Le texte d'un fil RSS, Deux discours de Ségolène Royal (campagne 2007), Deux discours de Nicolas Sarkozy (conférence de presse 2008)
- "La variation dans les discours" (Février 2007) : repérage de la variation dans les discours "Présidentielles 2007. Application sur 2 versions d'un discours de Ségolène Royal du 11/02/2007.
- "La variation dans les fils" (Mars 2007) : repérage de la variation dans les fils de Presse (mise à jour).
- "La variation dans les fils" (Octobre 2006) : repérage de la variation dans les fils de Presse (i.e fils RSS) (sous-partie du chantier Navigations dans Le Monde). Le journal Le Monde propose sur son site des fils RSS : Les fils RSS sont des flux de contenus gratuits en provenance de sites Internet. Ils incluent les titres des articles, des résumés et des liens vers les articles intégraux à consulter en ligne. Les dernières informations publiées sur Le Monde.fr peuvent ainsi venir enrichir automatiquement votre site Internet ou compléter vos sources d'informations déjà agrégées via un logiciel de lecture des flux RSS.
Navigations dans Le Monde (Le Monde en Surface vs Le Monde Profond)(Septembre 2006) (accès restreint). Avec en particulier une analyse de la variation textuelle dans "la surface" et dans "la profondeur" du Monde. Période traitée : 17 janvier 2006 au 19 septembre 2006, nombre total de fils : 328 250, variation repérée sur un sous corpus de 500 fils environ.- Des nuages de mots
Des nuages de mots (qui s'attirent)(Septembre 2006) - cf Projet Fils de PresseDes nuages de mots (qui s'attirent)(Juin 2006) - cf Projet Fils de PresseDes nuages de mots (qui s'attirent)(Mars-Avril 2006) - cf Projet Fils de Presse- Présidentielle 2007
- Navigations dans les "Discours 2007" :
l'ensemble des navigations- Pacte présidentiel vs pacte républicain
(3),(2),(1)Navigations dans le Fil "Présidentielle 2007"- Investiture "Présidentielle 2007" (7) :
Je/Nous/Vous/Ils- Investiture "Présidentielle 2007" : mots de candidature (qui sattirent)
(6),(5),(4),(3),(2),(1)- Information mutuelle dans le Fil "Présidentielle 2007", cartographie des candidats : (4),
(3),(2),(1)- Information mutuelle dans les Fils du Monde, cartographie des candidats :
(3),(2),(1)- Moteur (de requête XPath) pour la constitution européenne : navigation dans un fichier normalisé avec XPath
- Moteur XPath pour la constitution : Avec ce programme, (1) on peut avoir accès à un article donné de la constitution européenne en choisissant dans la liste proposée (par le numéro de l'article), l'article sera affiché dans la zone de résultat , (2) on peut aussi rechercher un article contenant une forme graphique donnée, les articles contenant la forme cherchée seront aussi affichés dans la zone d'affichage des résultats, les lignes contenant la forme seront colorées en rouge... On peut aussi utiliser la version n°2 [l] du moteur qui intègre le dictionnaire des formes graphiques construit par Lexico3 et sélectionner dans ce lexique la forme à rechercher (Attention le chargement de la page est assez long...)
Projet Innovant ED268 2004-2006: Propositions de Normalisation pour une Base de Corpus Multimédia à l'ED268- makeMetadata 2.00 (03/01/2009) : Le programme makeMetadata permet de générer ou de corriger des métadonnées. Version exécutable pour Windows. HTML, Doc PDF
URL projet : http://pi-ed268.univ-paris3.fr.- MkCorpus : Outil de Préparation de Corpus pour Analyse
- GASPAR : Programmation à Prototypes (avec Self) et TALN
- TyPTex : Typologie et Profilage de Textes
- TyPWeb : Typologie et Profilage de sites Web
- SensNet : Catégorisation sémantique des usages et des parcours sur le Web
|