TAL [CLA2T/SYLED & U. DE PARIS 3, Sorbonne nouvelle]
Fils de Presse...
Ce projet est une des 2 composantes du projet "Corpus Chronologique Le Monde". Ce dernier est composť de 2 parties :
Le Monde En Surface : architecture (prťsentťe infra) construite pour traiter les fils RSS mis ŗ disposition sur le site Web du journal Le Monde (díautres fils sont aussi traitťs dans cette architecture, en particulier celui du site de líAFP) ;
Le Monde Profond : architecture (prťsentťe ici) mise en úuvre pour construire et analyser un corpus chronologique de la version ťlectronique du journal Le Monde.
Présentation du projet (janvier 2006) : "Le Monde En Surface, Fils de Presse et Archivages des Fils" au Format PDF.
Voir aussi ici : Master pluriTAL, cf projet Nuages (texte+slides+cours)
Sommaire
- Préambule
- Les projets "Fils de Presse" et "Plateforme d'archivage des fils"
- "Plateforme d'archivage des fils"
- "Fils de Presse"
- Prototype "Fils De Presse" et Plateforme d'archivage des fils
- Liens externes (projets divers)
- Lectures
- Dťveloppements en cours
Préambule
Le projet "Fils de Presse" prend appui sur un programme qui est une implémentation en Perl díun tutorial rédigé par Jack Herrington sur le site díIBM :
"Use PHP and XSL to create a DHTML link graph, Build an RSS parser that creates a keyword list with word frequencies[1]", par Jack Herrington, Senior Software Engineer, Leverage Software, 4 octobre 2005. (désormais note [Herrington, 2005])
Abstract : In this tutorial, you learn to build a link graph with XML, PHP, and JavaScript code. Link graphs are paragraphs of keywords in which the font size of each word is determined by some data value -- in this case, the frequency of the term. The more often the term occurs, the larger the font size of the word. This tutorial shows how to build an RSS parser that in turn builds a keyword list along with the word frequencies. It also demonstrates how to use XSLT to create an HTML page that shows the link graph and relates its term to its original article.
On trouve sur le site d'Amazon, une application similaire ŗ celle décrite dans le tutorial précédent : il est possible de construire une concordance sur le contenu d'un livre présenté sur le site d'Amazon ; pour lancer cette concordance, il suffit de placer la souris au dessus de l'image de la couverture du livre visé puis de sélectionner le programme "concordance" qui apparaît dans le menu "popup". Exemple : présentation du livre "In the Beginning...was the Command Line", par Neal Stephenson, 1999 ŗ cette adresse :
"In the Beginning...was the Command Line", sur Amazon
Le menu contextuel (en passant sur l'image de couverture) donne accŤs ŗ un programme " Concordance " qui construit dans un premier temps un nuage de mots (les 100 mots les plus fréquents du livre) :
"In the Beginning...was the Command Line", le nuage de mots (concordance)
chaque mot est ensuite cliquable et donne ainsi accŤs aux contextes du mot visé (ici le mot commande):
"In the Beginning...was the Command Line", les contextes (concordance)
Les projets "Fils de Presse" et "Plateforme d'archivage des fils"
Le projet est composť de 2 modules.
Le premier (" Fil(s) de presse ") correspond au module permettant de traiter un fil de presse donnť (au format RSS) et de construire des traitements sur le contenu de ce fil (au dťpart, un nuage de mots).
Le second (" Archivage des Fils de Presse ") correspond au module permettant d'archiver les fils de maniŤre continue et automatique afin de constituer la mťmoire de ces fils.
"Plateforme d'archivage des fils"
Un processus expťrimental a ťtť mis en place pour archiver les fils de presse. L'idťe est la suivante :
- on a ŗ disposition le corpus Le Monde depuis Avril 2003 ("le Monde PROFOND")
- on peut aussi avoir accŤs au fils RSS publiťs quotidiennement ("le Monde EN SURFACE")
En archivant rťguliŤrement les fils on a donc ŗ portťe de main le PROFOND et la SURFACE. Le processus mis en place aspire rťguliŤrement les fils visťs et crťť des pages de navigation pour donner ŗ voir les donnťes archivťes et les nuages de mots crťťs sur chacun des fils (cf infra le projet "Fil(s) de Presse" : programme construisant un nuage de mots ŗ partir des contenus textuels prťsents dans un fil donnť). Les donnťes sont visibles provisoirement ici :
http://sfmac.no-ip.com/fils-presse-arch/index.xml (accŤs restreint)
L'archivage mis en place concerne les fils du journal Le Monde (cf infra) et celui de l'AFP . La figure suivante donne une reprťsentation de l'organisation de cet archivage :
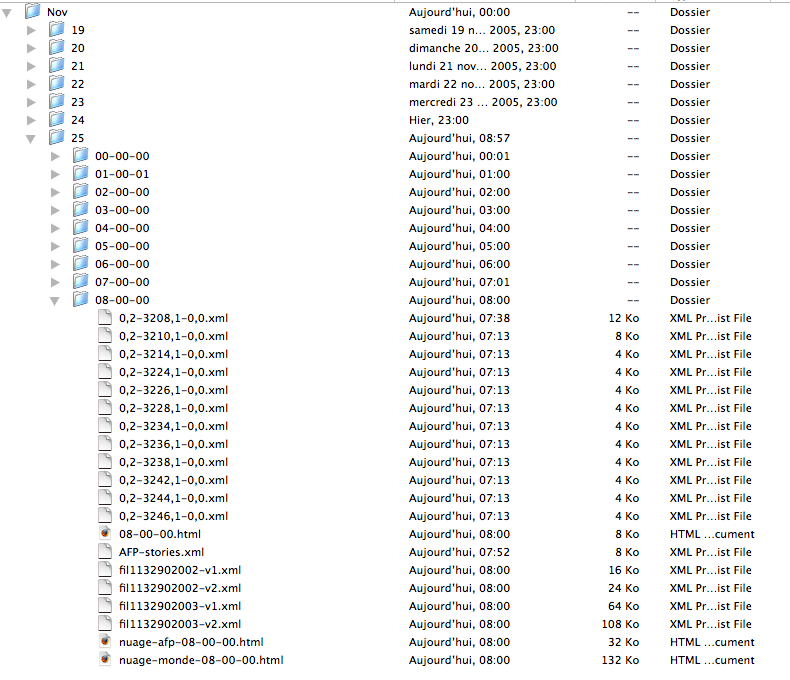
Figure 0 : Archivage des fils, arborescence
Le processus d'archivage est dťclenchť toutes les heures et produit ŗ chaque lancement un archivage des fils, des pages de navigation et les donnťes nťcessaires pour construire les nuages de mots.
"Fils de Presse"
Le programme construit prend en entrée des fils†RSS disponibles sur des sites de presse (Le Monde[2], Le Figaro[3], Libération[4]Ö) et produit des résultats donnant à voir :
- des nuages de mots
- une présentation des fils scrutés au format HTML et des comptages lexicométriques à partir des contenus textuels des descriptions des articles (disponibles dans les fils)† mis à la disposition par les journaux.
Les figures suivantes présentent les différents types de nuages construits :

Figure 1 : nuage de mots sans lien
Dans cette première figure, le nuage de mots donne à voir líensemble des mots présents dans les descriptions des articles des fils díun journal en ligne à un moment donné (ici Le Figaro).

Figure 2 : nuage de mots avec liens
Dans la seconde, on peut voir un nuage similaire dans lequel chaque mot donne accès via un clic aux contextes dans lesquels ce mot apparaît (colonne de droite) : le contexte est constitué par le titre de líarticle, sa description et son URL.
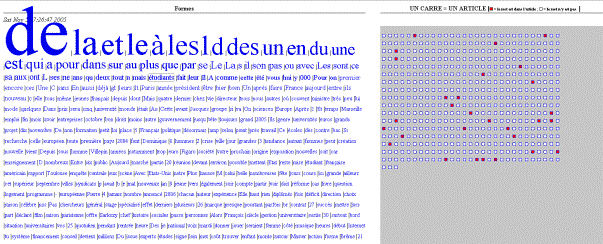
Figure 3 : nuages de mots avec "carte des sections" (1 section = 1 carré = 1 article)
Dans la troisième, on y voit toujours le même nuage de mots sur la gauche, dans lequel chaque mot donne accès via un clic à une ę représentation cartographique[5] Ľ du contenu du fil scruté dans laquelle le contenu textuel de la description díun article est représenté par un carré, les articles contenant le mot cliqué sont associées à des carrés rouges ![]() †et les autres à des carrés blancs
†et les autres à des carrés blancs ![]() †. Chaque carré pointe sur un article en ligne : un clic sur le carré donne accès à líarticle en ligne.
†. Chaque carré pointe sur un article en ligne : un clic sur le carré donne accès à líarticle en ligne.
Dans les trois figures, la taille de la police de caractères utilisée pour afficher le mot dans le nuage est déterminée par la fréquence du mot dans líensemble des articles scrutés pour un journal donné.
Architecture du projet ę nuage de mots Ľ
Dans le projet initial [Herrington, 2005], líarchitecture ę en amont Ľ de líapplication a líallure suivante :
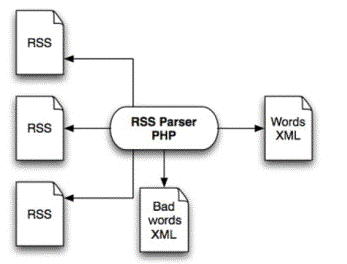
Figure 4 : architecte initiale "en amont"
Líapplication lit des flux RSS et déclenche un parser RSS (écrit en PHP) qui a pour t‚che de sélectionner les zones de texte à explorer puis de lancer une opération de segmentation de ces contenus textuels en ne retenant que les mots non présents dans une liste prédéterminée (mots† vides).
Líarchitecture maintenue pour le projet présenté ici est la suivante :
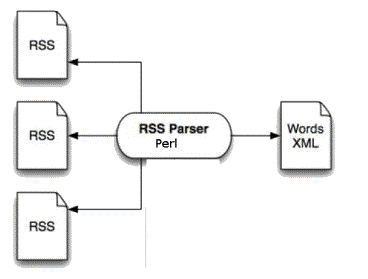
Figure 5 : architecture modifiée "en amont"
Le principe général est conservé, tout le code est réécrit en Perl, parser compris. Tous les mots présents dans les contenus textuels scrutés sont conservés. Les mots retenus et comptés sont sauvegardés au format XML. Le fichier produit a líallure suivante :
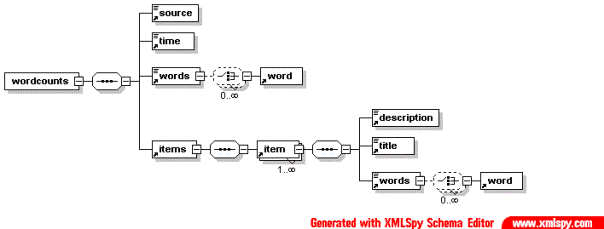
Figure 6 : schéma du lexique construit
Dans ce schéma, l élément words contient la liste de tous les mots (et leur fréquence) pour un fil de presse donné, líélément item contenant la liste de tous les mots pour un article donné contenu dans ce fil.
On présente ci-dessous un extrait du lexique construit :
<?xml version="1.0" encoding="iso-8859-1"?>
<?xml-stylesheet type="text/xsl" href="parserss.xsl"?>
<wordcounts>
<source>LIBERATION</source>
<time>Wed Oct 26 08:06:28 2005</time>
<words>
<word text="de" count="16" />
<word text="le" count="5" />
<word text="la" count="5" />
<word text="d" count="5" />
Ö
</words>
<items>
<item url="http://www.liberation.fr/page.php?Article=332624" title="">
<description><![CDATA[Mort du dessinateur aux personnages diaphanes et angéliques, rendu célèbre par un générique d'Antenne 2.]]></description>
<title><![CDATA[Feu Folon]]></title>
<words>
<word text="Mort" text2="Mort" />
<word text="du" text2="du" />
<word text="dessinateur" text2="dessinateur" />
<word text="aux" text2="aux" />
<word text="personnages" text2="personnages" />
<word text="diaphanes" text2="diaphanes" />
<word text="et" text2="et" />
<word text="angéliques" text2="angeliques" />
<word text="rendu" text2="rendu" />
<word text="célèbre" text2="celebre" />
<word text="par" text2="par" />
<word text="un" text2="un" />
<word text="générique" text2="generique" />
<word text="d" text2="d" />
<word text="Antenne" text2="Antenne" />
<word text="2" text2="2" />
</words>
</item>
Ö
</items>
</wordcounts>
Une modification mineure a été réalisée dans la grammaire du fichier lexique produit par rapport à líapplication initiale. La présence de caractères accentués dans les mots posant des problèmes pour la seconde partie de líapplication (celle utilisant le script établissant le lien entre le mot et ses contextes), un attribut a été ajouté dans les éléments décrivant les mots, celui-ci contenant après transcodage, la forme graphique normalisée du mot sans caractères accentués (génériqueest réécritgenerique).
Dans un deuxième temps, líapplication construit le nuage des mots en utilisant le lexique produit et en appliquant sur la sortie XML contenant ce lexique une feuille de style XSL (utilisant un script Javascript).
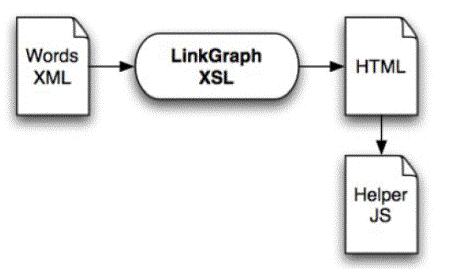
Figure 7 : architecture "en aval"
Cette architecture ę en aval Ľ maintient intégralement le principe présenté dans [Herrington, 2005]. Plusieurs†modifications ont cependant été apportées :
- La feuille de style initiale a díabord été réécrite pour ne produire quíun nuage de mot sans lien i.e. sans liens vers les contextes originaux contenant les mots scrutés.
- Elle a aussi été modifiée pour affiner les sorties produites (contextes ou carte des sections)
Prototype "Fils De Presse" et Plateforme d'archivage des fils
Liens Prototype "Fils De Presse" (page officielle)
- Application en cours de développement (version 3) : Fils-de-Presse (notée v3). (MŗJ : janvier 2008)
- Application en cours de développement (version 2) : Fils-de-Presse (notée v2). (MŗJ : janvier 2008)
- Exemples de sorties produites (version 2) : 3 Fils de Presse - Nuages de Mots
Liens Prototype "Fils De Presse" (accès restreint)
- Application en cours de développement (version 1) : accès restreint
- Application en cours de développement (version 2) : accès restreint [MŗJ : 03/07/2006 suite ŗ la mise en ligne de la version "Web 2.0" de Libťration.fr]
Liens Prototype "Fils2Clouds" (accès restreint)
- Fils2Clouds construit un nuage de mots ŗ partir des fils de Presse archivťs dans le projet Plateforme d'archivage des fils (cf infra)
- Application accessible ici : accès restreint
- Exemples de sorties produites : A voir sur le blog (pluri)TAL (nuages construits sur la pťriode 19/11/2005-28/01/2005)
Liens Plateforme d'archivage des fils (page officielle)
- Application en cours de développement (version 1) : (accès restreint sur demande)
- Un index des nuages disponibles : On donne ŗ voir ici un index díune partie des nuages disponibles ŗ ce jour (site Le Monde) : INDEX Nuage (2 mois, heure par heure). Dans les nuages de mots, chaque mot donne accŤs via un clic aux contextes dans lesquels ce mot apparaÓt (colonne de droite) : ce contexte est constituť par le titre de líarticle, sa description ďtextuelleĒ dans le fil original et líURL visťe par cette description (cf figure 2).
Liens Plateforme d'archivage des fils (accès restreint)
- Application en cours de développement (version 3) (avec gťnťration automatique de corpus pour Lexico3 contenant le texte des fils et le contenu complet de l'article associť) : accès restreint
- Application en cours de développement (version 2) : accès restreint
- Application en cours de développement (version 1) : accès restreint
Liens Prototype "ChronoFil/ChronoMonde" (accès restreint)
Dans la cadre de ce projet, mise en place de 2 modules, ChronoFil et ChronoMonde :
- ChronoFil construit une reprťsentation graphique de líťvolution díun mot dans les Fils de Presse archivťs par le module du mÍme nom dans le projet Fils de Presse
- ChronoMonde construit une reprťsentation graphique de líťvolution díun mot dans la version ťlectronique du journal Le Monde, [pťriode : Avril 2003 Ė Dťcembre2005] (cf Projet CLM)
- Les deux Applications sont accessibles ici : accès restreint
Liens externes (projets divers)
Technocrati
- Les nuages de Tags chez Technocrati : A tag is like a subject or category. This page shows the most popular 250 tags in alphabetical order. The bigger the text, the more active it is : http://www.technorati.com/tags/
TagCloud
- TagCloud : TagCloud is an automated Folksonomy tool. Essentially, TagCloud searches any number of RSS feeds you specify, extracts keywords from the content and lists them according to prevalence within the RSS feeds. Clicking on the tag's link will display a list of all the article abstracts associated with that keyword http://www.tagcloud.com/
TagCloud Le_Monde
- Exemple d'application : TagCloud "Le Monde" : (Lien direct : http://www.tagcloud.com/cloud/html/Le_Monde/default/50)
10x10
- 10x10 : Outil d'exploration interactive passe au crible les fils RSS de Reuters, de la BBC et du NewYorker pour crťer une mosaÔque de photos d'actualitťs (Every hour, 10x10 scans the RSS feeds of several leading international news sources, and performs an elaborate process of weighted linguistic analysis on the text contained in their top news stories) http://tenbyten.org/index.html
Newsmap
- Newsmap : Newsmap is an application that visually reflects the constantly changing landscape of the Google News news aggregator. A treemap visualization algorithm helps display the enormous amount of information gathered by the aggregator. Treemaps are traditionally space-constrained visualizations of information. Newsmap's objective takes that goal a step further and provides a tool to divide information into quickly recognizable bands which, when presented together, reveal underlying patterns in news reporting across cultures and within news segments in constant change around the globe http://www.marumushi.com/apps/newsmap/newsmap.cfm
Newscloud
- Newscloud : NewsCloud is an application that takes all of the RSS feeds from the Washington Post website and builds a blog like tag cloud from the keywords. Each story's full text is pulled from the website and indexed by keywords thses keywords. There are typically around 11,000 news stories and 60,000 keywords being indexed at any given time. http://www.revsys.com/newscloud/. (Prťsentation de ce projet sur le blog "La Feuille" dans ce billet).
1000Tags
- 1000Tags : 1000tags.com is a project that aims to put to the test in its simplest form the viability of tagging as a way to advertise, by presenting a tag cloud formed by tags added by people who try to promote a particular site or page. This is done by offering a web page where anyone can book a particular tag that will later be displayed in the main tag cloud at the 1000tags.com page, as well as allowing web site owners to add their tag - for free of course - by syndicating a small tag cloud at their pages. http://1000tags.com/.
ZoomTags
- ZoomTags : ZoomTags is a professional implementation of the commericial tagcloud idea introduced by 1000Tags. http://www.zoomtags.com/. (Prťsentation de ce projet sur le blog "TechCrunch " dans ce billet).
ZoomClouds
- ZoomClouds : ZoomClouds est un service permettant de gťrťner un nuages de tags ŗ partir de n'importe quel fil RSS et offrant en plus la possibilitť de choisir le nombre de jour ŗ prendre en compte. http://www.zoomclouds.com/.
- Exemple d'application : ZoomCloud "Le Monde" (fil RSS "Le Une" sur 90 jours) :
reverbiage
- reverbiage : Reverbiage.com is a news feed aggregator featuring NPR News Headlines. Reverbiage is not affiliated with NPR nor its member stations.. http://www.reverbiage.com/.
Lectures
TagClouds Obervations, Font Sizes and Colors
- Sur le blog 3spots, TagClouds Obervations, Font Sizes and Colors : "Some people may not like Tag Clouds, I personally find them interesting, useful and aesthetically appealing even if they are not precis information. They can have different useful purposes, ma.gnolia icon ma.golia for example uses it when adding a bookmark which I find a good idea as the most used ones are quickly accessible and as for the other tags, well I search though all the small ones ignoring the big ones..."
Visual Complexity
- Le site Visual Complexity (http://www.visualcomplexity.com/vc/) propose, classťs par thŤmes (biologie, arts, rťseaux sociaux, web ...), des projets (231 au total) de visualisation de masses complexes d'informations et/ou de documents (Source : De la reprťsentation visuelle ŗ la complexitť documentaire, sur le Blog affordance.info)
Blog Technologies du Langage (Jean Vťronis)
- Web: Surfez sur les nuages http://aixtal.blogspot.com/2006/01/web-surfez-sur-les-nuages.html
- Texte: Nuages dynamiques http://aixtal.blogspot.com/2005/11/texte-nuages-dynamiques.html
- Texte: Chirac sur un nuage http://aixtal.blogspot.com/2005/11/texte-chirac-sur-un-nuage.html
- Blogs: Banlieues dans les nuages http://aixtal.blogspot.com/2005/11/blogs-banlieues-dans-les-nuages.html
- Blogs: Un nuage sur les banlieues http://aixtal.blogspot.com/2005/11/blogs-un-nuage-sur-les-banlieues.html
- Dialogue entre blogues http://aixtal.blogspot.com/2005/10/rcr-dialogue-entre-blogues.html
Blog La Feuille
- "Anticiper les usages des lecteurs", billet publiť le 27 novembre 2005.
Blog bibliosession
- "BibliothŤque 2.0", billet publiť le 23 Novembre 2005.
Travaux rťalisťs / en cours
[1] Voir ici : Master pluriTAL, cf projet Nuages (texte+slides+cours)
[2] Voir aussi sur le weblog du projet Master TAL 2005-2006:
la page projet Nuages et la page Travaux projet Nuages
[3] (cf post-504, post-509, post-510, post-516) Des nuages de mots (qui s'attirent).
Fils et Information mutuelle : "Information mutuelle : repťrer les mots qui s'attirent..." par BenoÓt Habert.
Une synthŤse complŤte et in-progress des travaux en cours (Fils et Information mutuelle) est visible ici :
Des nuages de mots (qui s'attirent) (1) (Mars-Avril 2006) ou ici : Des nuages de mots (qui s'attirent) (1) (Mars-Avril 2006)
Des nuages de mots (qui s'attirent) (2) (Juin 2006)
Des nuages de mots (qui s'attirent) (3) (Septembre 2006)
[4]"La variation dans les fils" : repťrage de la variation dans les fils de Presse.
[5]"Les Candidats 2007" : Cartographie des candidats dans les Fils du Monde.fr / Navigations dans les Fils du Monde.fr
- Navigations dans les Fils 1 (18/10/2006 Ė 05/11/2006)
- Navigations dans les Fils 2 (18/10/2006 Ė 19/11/2006)
- Information mutuelle dans le Fil "Prťsidentielle 2007" (1) : cartographie des candidats (18/10/2006 Ė 23/11/2006)
- Information mutuelle dans le Fil "Prťsidentielle 2007" (2) : cartographie des candidats (18/10/2006 Ė 27/11/2006)
- Information mutuelle dans le Fil "Prťsidentielle 2007" (3) : cartographie des candidats (18/10/2006 Ė 13/12/2006)
- Information mutuelle dans le Fil "Prťsidentielle 2007" (4) : cartographie des candidats (18/10/2006 Ė 09/01/2007)
- Information mutuelle dans les Fils du Monde (1) : cartographie des candidats (17/01/2006 Ė 19/09/2006)
- Information mutuelle dans les Fils du Monde (2) : cartographie des candidats (17/01/2006 Ė 28/11/2006)
- Information mutuelle dans les Fils du Monde (3) : cartographie des candidats (17/01/2006 Ė 13/12/2006)
[4] http://www.liberation.com/interactif/rss/ [MŗJ : 03/07/2006 suite ŗ la mise en ligne de la version "Web 2.0" de Libťration.fr. Ancienne adresse : http://www.liberation.fr/page.php?Article=149907]
[5]Ce développement síinscrit dans les travaux faits autour de Lexico3 pour construire des représentations des textes donnant à voir les unités textuelles manipulées à travers des objets graphiques :
http://www.tal.univ-paris3.fr/lexico/,† http://www.tal.univ-paris3.fr/CE-query/††