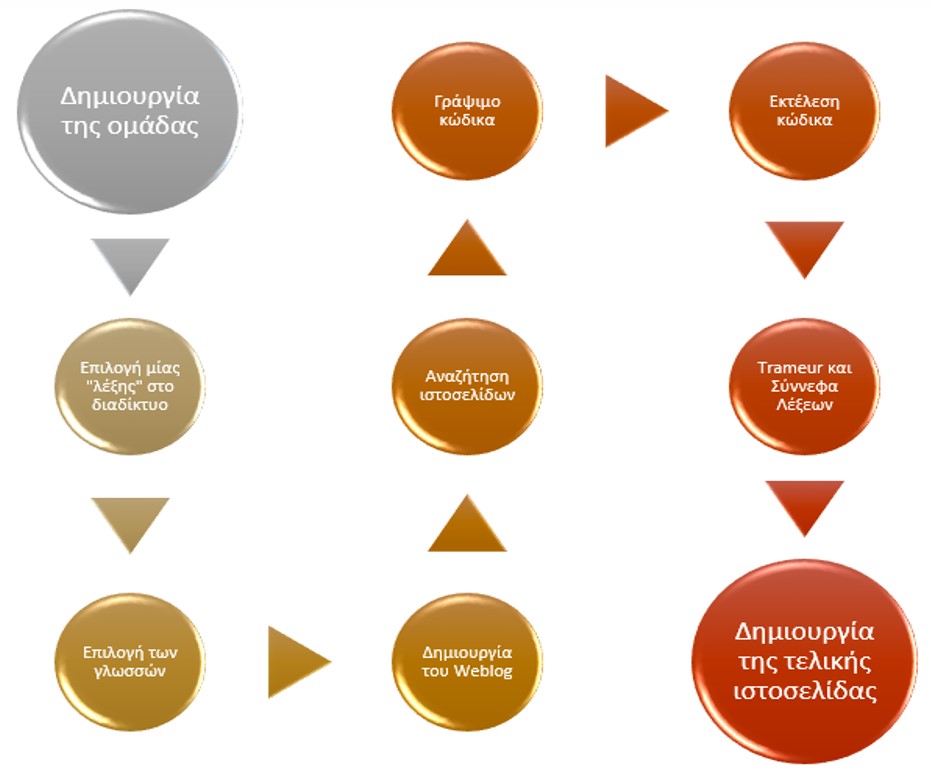
Τα πρώτα τέσσερα στάδια που αναγράφονται στο ανωτέρω σχεδιάγραμμα, έγιναν σχετικά γρήγορα, παρά το πολύ σημαντικό στάδιο της επιλογής μίας λέξης, μια επιλογή η οποία πρέπει να γίνεται ύστερα από αρκετή σκέψη. Στη δική μας περίπτωση, έπειτα από αρκετές προτάσεις, συνειδητοποιήσαμε ότι αυτό που φαίνεται περίεργο για κάποιους, δεν είναι αναγκαστικά και για άλλους. Κατά συνέπεια, αποφασίσαμε να επιλέξουμε τη λέξη «περίεργο», και να προσπαθήσουμε να διαχωρίσουμε τις διαφορετικές λειτουργίες της λέξης αυτής σε συγκεκριμένα συγκείμενα, αν υπάρχουν, στις γλώσσες εργασίας που διαλέξαμε.
Το πέμπτο στάδιο ήταν η συγκέντρωση των ιστοσελίδων. Προτού ξεκινήσουμε, έπρεπε να απαντήσουμε σε κάποια ερωτήματα, όπως «Θα επικεντρωθούμε μόνο στον Τύπο;», «Θα ήταν καλή ιδέα, σύμφωνα πάντα με τη λέξη «περίεργο» να χρησιμοποιήσουμε και μπλογκ;», «Πόσες ιστοσελίδες πρέπει να βρούμε;», κλπ. Συμφωνήσαμε τελικά να βρούμε 70 ιστοσελίδες από τον Τύπο, για κάθε γλώσσα. Στόχος μας ήταν να έχουμε ένα σώμα κειμένου σχετικά ισορροπημένο.
Πριν ξεκινήσουμε το έκτο στάδιο, δηλαδή τον κώδικα, συστήνεται να γίνεται υπό μορφής προχείρου, η περιγραφή του τί ακριβώς πρέπει να μπορεί να κάνει ο εν λόγω κώδικας.
Το δικό μας πρόχειρο, είχε την εξής μορφή:
- Εντοπισμός του αρχείου εισόδου (parametres.txt) το οποίο περιέχει πληροφορίες για τις ιστοσελίδες, τον τελικό πίνακα, και το αναζητούμενο μοτίβο
- Εντοπισμός του αρχείου εξόδου (tableau-final.html) όπου θα αποθηκεύονται τα αποτελέσματα
- Επεξεργασία κάθε αρχείου που βρίσκεται στον φάκελο "URLS"
- Ανάγνωση κάθε γραμμής του αρχείου, δηλαδή κάθε ιστοσελίδας
- Κατέβασμα της ιστοσελίδας (curl)
- Εντοπισμός της κωδικοποίησης της ιστοσελίδας (είτε με την εντολή curl, είτε με την egrep για να εντοπίσει το charset στην P.A.)
- Αν η κωδικοποίηση είναι utf-8 : εκτελούμε πρώτα την εντολή lynx –dump, έπειτα αναζητούμε το μοτίβο με την egrep και τέλος, καταμετρούμε τη συχνότητα του μοτίβου σε κάθε ιστοσελίδα χρησιμοποιώντας το –c («count»)
- Αν η κωδικοποίηση δεν είναι utf-8, προτού εκτελέσουμε τις ανωτέρω εντολές, επιβεβαιώνουμε αρχικά ότι η κωδικοποίηση που βρήκαμε αναγνωρίζεται από την εντολή iconv (εκτελούμε την εντολή iconv –l για να απεικονίσουμε τη λίστα των κωδικοποιήσεων που αναγνωρίζει η iconv, και κατόπιν χρησιμοποιούμε την egrep για να βρούμε την κωδικοποίηση)
- Αν η κωδικοποίηση αναγνωρίζεται από την iconv, πρέπει να την μετατρέψουμε σε utf-8 και να εκτελέσουμε τις ανωτέρω εντολές. Διαφορετικά, δεν μπορούμε να κάνουμε τίποτα...
- Καταγραφή των αποτελεσμάτων στο αρχείο εξόδου (tableau-final.html)
Οι τελικοί πίνακες έχουν από 12 στήλες:
- N° : μετρητής για κάθε ιστοσελίδα του πίνακα
- URL : σύνδεσμος προς την ιστοσελίδα
- Code CURL : αν είναι "200", δεν υπήρξαν προβλήματα κατά το κατέβασμα της ιστοσελίδας
- Statut CURL : αποτέλεσμα της αναζήτησης, από άποψη δικτύου
- P.A. : οι κατεβασμένες ιστοσελίδες
- Encodage Initial : αρχική κωδικοποίηση των κατεβασμένων σελίδων
- DUMP Initial : DUMP ενός κειμένου που δεν είναι utf-8 και που θα πρέπει να μετατραπεί σε utf-8
- DUMP UTF-8 : DUMP ενός κειμένου που είναι utf-8
- Contexte UTF-8 (txt) : εξαγωγή του συγκειμένου του μοτίβου με DUMP
- Contexte UTF-8 (html) : απεικόνιση συγκειμένου με το πρόγραμμα minigrep
- Freq MOTIF : συχνότητα του μοτίβου στο DUMP
- Index DUMP : λίστα όλων των λεξημάτων στο DUMP, με τη συχνότητά τους
Το έβδομο στάδιο αφορά τη χρήση ενός λεξικομετρικού εργαλείου, του Trameur. Το χρησιμοποιήσαμε με στόχο την ανεύρεση των λεξημάτων, αλλά και του συγκειμένου, της λέξης "περίεργο". Στη συνέχεια, χρησιμοποιήσαμε πολλές εφαρμογές στο διαδίκτυο, με στόχο τη δημιουργία "σύννεφων λέξεων", ή ακόμη καλύτερα "word clouds" (χρησιμοποιώντας τα αρχεία DumpGlobal και ContexteGlobal). Χρησιμοποιήσαμε, μεταξύ άλλων, τις εξής εφαρμογές: Tagul, Tagxedo, ImageChef, WordClouds.
Το τελευταίο στάδιο ήταν η δημιουργία αυτής της ιστοσελίδας, που είχε ως στόχο να παρουσιάσει τη δουλειά μας στα πλαίσια αυτού του εξαμήνου.
Ελπίζουμε να σας αρέσει...
 Ελληνικά
Ελληνικά العَرَبِيَّة
العَرَبِيَّة English
English Français
Français 한국어
한국어 Türkçe
Türkçe