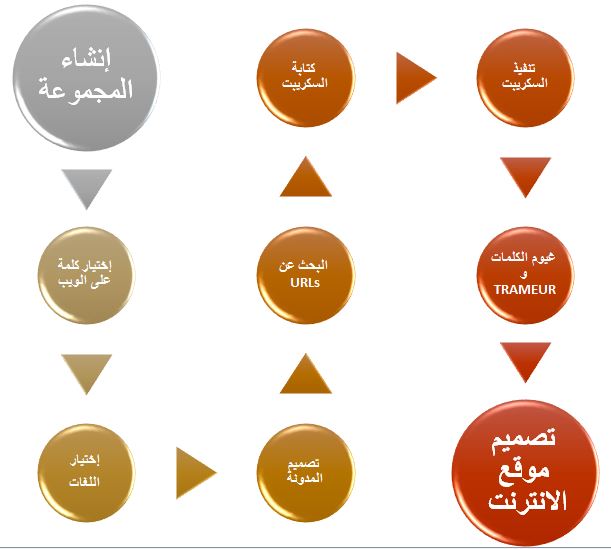
يظهر هذا الرسم البياني مختلف المراحل التي تطلبها المشروع . المراحل الأربعة الأولى لم تتخذ وقتاً طويلاً قيد التحضير على الرغم من أن إختيار الكلمةكان من المفروض "أن يستوجب وقتا أكثر في التفكير. و بعد إقتراحات عديدة، أدركنا أن "ما يبدو غريبا للبعض ليس بالضرورة غريباً للبعض الأخر".بِالتّالي ، قررنا إختيار كلمة "غريب" في هذا العمل لدراسةإختلاف تواجدها السياقي في اللغات المختارة.
المرحلة الخامسة تتمثل في جمع عناوين الانترنت "URL".بالتالي، توجب الإجابة على بعض الأسئلة التالية:"هل سيقع التركيز على الصحافة الالكترونية فقط ؟
هل إستعمال بعض المدونات على الانترنت هي فكرة جيدة ؟كم نستحق من عنوان لهاته الدراسة ؟" إلخ .تم الإتفاق في الأخير على سبعين عنوان لكل لغة لكي نتحصل على قاعدة متوازنة من المعطيات.
قبل البدء في المرحلة السادسة وهي كتابة السكريبت ، من المحبذ كتابة ما سيقوم به السكريبت عن طريق ما يسمى ب "اللغة البشرية".
في هاته الحالة، مسودة العمل تكون كما يلي :
- تحديدمكان ملف الدخول (parametres.txt) الذي يحتوي على المسارات النسبية لعناوين الانترنت، الجدول النهائي والمصطلح المبحوث عنه.
- تحديدمكان ملف الخروج (tableau-final.html) أين سيتم كتابة النتائج.
- معالجة كلن من الملفات المتواجدة في فهرس عناوين الانترنت «URLS».
- قراءة كل سطر من الملف، يعني كل عنوان انترنت «URL».
- تحميل كل URL عن طريق الأداة(curl).
- كشف الترميز(عبر الأداةcurl ،أو عبر egrepلوجود charset في صفحات التحميل).
- إذا كان الترميز هو utf-8 : نقوم ب lynx –dump ،ثم نبحث عن المصطلح مع egrep وأخيراً نقوم بإحصاء عدد مرات تردد المصطلح في كل URL عن طريق
count»)-c»).
- إذا كان الترميز غير utf-8 : قبل تنفيذ الأوامر أعلاه، علينا أولا معرفة ما اذا كان يتم التعرف على هذا الترميز عبر (iconv) نستخدم (iconv -l) لإظهار لائحة التراميز المتعرف عليها من قبل iconv، من ثم egrep والترميز المتحصل عليه.
- إذا تم التعرف على الترميز عبر, يجب تحويله إلىutf-8 و تنفيذ الأوامر أعلاه.خلاف ذلك،لا يمكننا فعل أي شيء .
- كتابة النتائج في ملف الخروج (tableau-final.html)
الجداول النهائية تتكون من إثني عشرة خانة :
- °N : عداد لجميع URL الجدول.
- URL : رابط إلى موقع الويب.
- كود CURL : لو كان الكود «200» ، هذا يعني أنه لم يكن هنالك أي مشاكل عند تحميل الصفحة.
- نظام CURL : النتيجة من منظور الشبكة.
- P.A. : صفحات التحميل.
- الترميز الأوّليّ : الترميز الأوّليّ لصفحات التحميل.
- DUMP الأوّليّ: نص DUMP في غير utf-8 و إستوجاب تحويله.
- DUMP UTF-8 : نص DUMP في utf-8.
- سياق txt)UTF-8) : إستخراج محيط المصطلح عن طريق DUMP .
- سياق html)UTF-8) : عرض السياق عبر minigrep.
- Freq MOTIF :عدد تواتر المصطلح في DUMP.
- فهرست DUMP : قائمة بجميع الكلمات فى DUMP و تواترها.
الخطوة السابعة هي إستخدام أداة Trameur. تم إستخدام هذه الأداة للبحث عن كلمة "غريب" و ورود سياقاتها. بعد ذلك، لقد قمنا بإستخدام العديد من التطبيقات المتاحة على شبكة الإنترنت لخلق غيوم من الكلمات (باستخدام DumpGlobal و ContexteGlobal). بعض التطبيقات المستخدمة هنا : Tagul, Tagxedo, ImageChef, WordClouds.
الخطوة الأخيرة هي إنشاء موقع الويب الذي سيقدم عملنا خلال هذا الفصل الدراسي،
نأمل أن يحظى هذا الأخير حسن ظنكم ...
 العَرَبِيَّة
العَرَبِيَّة English
English Français
Français Ελληνικά
Ελληνικά 한국어
한국어 Türkçe
Türkçe