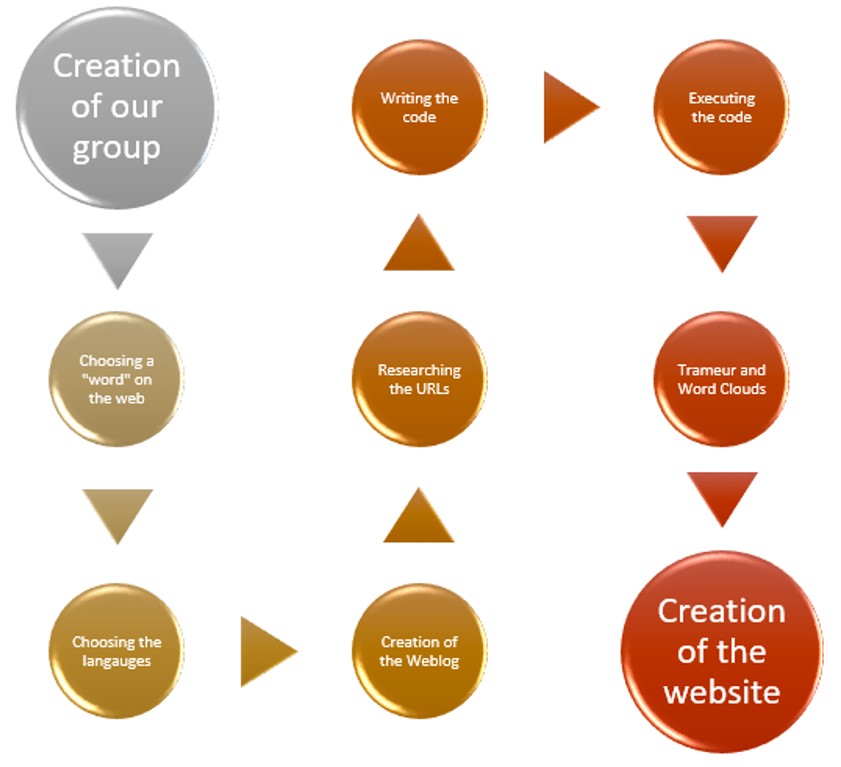
Despite the fact that choosing a word, and/or concept, should have taken some time, the first four steps displayed in this flowchart were completed rather quickly. After sharing different ideas, we realized that “what seems strange/weird for some, may not necessarily be so, for others”. Therefore, “weird” was picked for this study. The desired outcome, is to distinguish, if there are, different ways in which this word is used, in the working languages we have chosen.
The fifth step was the gathering of the URLs. To this end, we came across quite a few questions, such as: “Are we going to focus only on the press?” “Would it be a good idea to use blogs too?” “How many URLs should we find?”, etc. Finally, we agreed on 70 URLs from the press of each language. Our goal was to construct a fairly balanced corpus.
Before starting the sixth step, which is the writing of the script, it is strongly advised to describe in “human language” what the script should do.
In our case, the draft looks like this :
- Locating the input file (parametres.txt) which contains relative paths for the URLs, the final table, and the pattern searched.
- Locating the output file (tableau-final.html) where the results are to be written.
- Processing each of the files in the "URLS" directory.
- Reading each line of the file, that is, each URL
- Downloading the URL (using the command-line curl)
- Detecting the encoding (either using curl, or egrep to find the charset in the P.A.)
- If the encoding is utf-8 : we use lynx –dump, then we look for the pattern with egrep and finally, we count the frequency of the pattern in each URL using the argument –c («count»)
- If the encoding is not utf-8, before executing the commands mentioned above, we first have to check if this encoding is recognized by iconv (we use iconv –l to display the list of encodings recognized by iconv, and then egrep and the recovered encoding)
- If the encoding is recognized by iconv, it must be transcoded into utf-8. Then, we execute the commands above. Otherwise, we cannot do anything....
- Writing the results in the output file (tableau-final.html)
Our final tables contain 12 columns :
- N° : a counter for all the URLs in the table
- URL : a link to the website
- Code CURL : if it is «200», there were no problems in the downloading of the page
- Statut CURL : the result of the search in the network's perspective
- P.A. : the aspirated pages
- Encodage Initial : the initial encoding of the aspirated pages
- DUMP Initial : DUMP of a text that is not in utf-8 and that will have to be transcoded
- DUMP UTF-8 : DUMP of a text in utf-8
- Contexte UTF-8 (txt) : extraction of the environment of the given word from DUMP
- Contexte UTF-8 (html) : context display with the minigrep program
- Freq MOTIF : the nomber of occurrences of the pattern in DUMP
- Index DUMP : list of all the word in DUMP, with their frequency
The seventh step concerns the use of a textometry tool, Trameur. We use it to look for occurrences, as well as co-occurrences, of the word "weird". We then use several programs available on the Internet, in order to create word clouds (using the DumpGlobal and ContexteGlobal files). We have used, among others: Tagul, Tagxedo, ImageChef, WordClouds.
The last step is the creation of this website, in order to present our work, fullfilled during this semester.
We hope you like it...
 English
English العَرَبِيَّة
العَرَبِيَّة Français
Français Ελληνικά
Ελληνικά 한국어
한국어 Türkçe
Türkçe