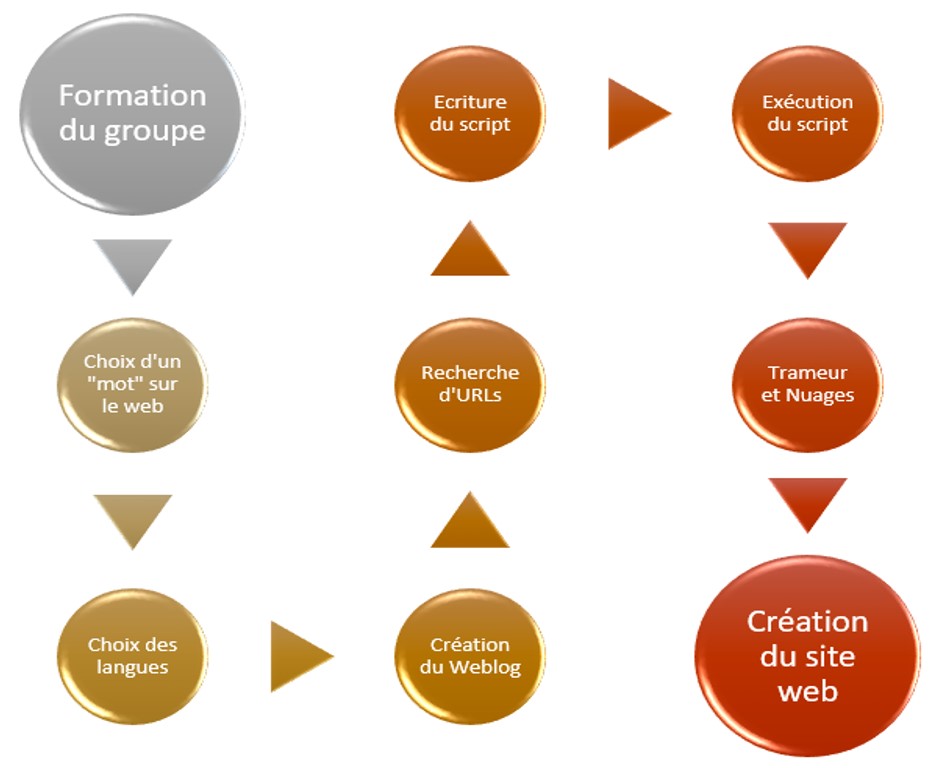
Les 4 premières étapes affichées dans ce diagramme ont été réalisées assez rapidement, malgré le fait que le choix du mot doit être fait avec beaucoup de réflexion. Dans notre cas, après avoir proposé des différentes idées, nous nous sommes rendues compte que « ce qui semble bizarre pour certains ne l’est pas forcément pour d’autres ». En conséquence, nous avons décidé de prendre le mot «bizarre», et essayer de distinguer, s’il y en a, les différents contextes d’utilisation dans les langues de travail que nous avons choisies.
La 5ème étape était la récolte des URLs. Il a fallu que nous répondions à quelques questions du genre «Est-ce qu’on va se concentrer seulement sur la presse?», «Serait-il une bonne idée, toujours selon le mot ‘bizarre’, d’utiliser des blogs aussi ?», «Combien d’URLs faut-il trouver?», etc. Enfin, nous nous sommes mises d’accord; 70 URLs issus de la presse pour chaque langue. Notre but était d’avoir un corpus plutôt équilibré.
Avant de commencer la 6ème étape, l’écriture du script, il est fortement conseillé de décrire en langage humain ce que le script doit faire.
Dans notre cas, le brouillon semble à cela :
- Localisation du fichier d’entrée (parametres.txt) qui contient des chemins relatifs pour les URLs, le Tableau Final et le motif cherché
- Localisation du fichier de sortie (tableau-final.html) où les résultats seront écrits
- Traitement de chacun des fichiers qui se trouvent dans le répertoire «URLS»
- Lecture de chaque ligne du fichier, c’est-à-dire, chaque URL
- Téléchargement d’URL (avec la commande curl)
- Détection de l’encodage (soit avec la commande curl, soit avec egrep pour trouver le charset dans la P.A.)
- Si l’encodage est d’utf-8 : on fait un lynx –dump, puis on cherche le motif avec egrep et enfin, on compte la fréquence du motif dans chaque URL en utilisant l’argument –c («count»)
- Si l’encodage n’est pas d’utf-8, avant d’exécuter les commandes ci-dessus, on vérifie tout d’abord si cet encodage est reconnu de la commande iconv (on fait iconv –l pour afficher la liste d’encodages reconnus d’iconv, et puis egrep et l’encodage récupéré)
- Si l’encodage est reconnu d’iconv, on doit le transcoder en utf-8 et exécuter les commandes ci-dessus. Sinon, on ne peut rien faire...
- Ecriture des résultats dans le fichier de sortie (tableau-final.html)
Nos tableaux finaux contiennent 12 colonnes :
- N° : un compteur pour tous les URL du tableau
- URL : un lien vers le site
- Code CURL : Si c’est «200», il n’y avait pas des problèmes lors du téléchargement de la page
- Statut CURL : le résultat de la requête d’un point de vue du réseau
- P.A. : les pages aspirées
- Encodage Initial : l’encodage initial des pages aspirées
- DUMP Initial : DUMP d’un texte qui n’est pas en utf-8 et qu’il va falloir transcoder
- DUMP UTF-8 : DUMP du texte en utf-8
- Contexte UTF-8 (txt) : extraction de l’environnement du mot choisi à partir de DUMP
- Contexte UTF-8 (html) : affichage du contexte avec le programme minigrep
- Freq MOTIF : le nombre d’occurrences du motif dans le DUMP
- Index DUMP : liste de tous les mots dans le DUMP, avec leur fréquence
La 7ème étape porte sur l’utilisation d’un outil de textométrie, Trameur. Nous l’avons utilisé afin de chercher les occurrences, ainsi que les cooccurrences, du mot «bizarre». Puis, nous avons utilisé plusieurs applications disponibles sur le web, afin de créer des nuages de mots (en utilisant les fichiers DumpGlobal et ContexteGlobal). Parmi ceux que nous avons utilisés : Tagul, Tagxedo, ImageChef, WordClouds.
La dernière étape s’agit de la création de ce site web, afin de présenter notre travail, réalisé au fil de ce semestre.
En espérant que cela vous plaît…
 Français
Français العَرَبِيَّة
العَرَبِيَّة English
English Ελληνικά
Ελληνικά 한국어
한국어 Türkçe
Türkçe