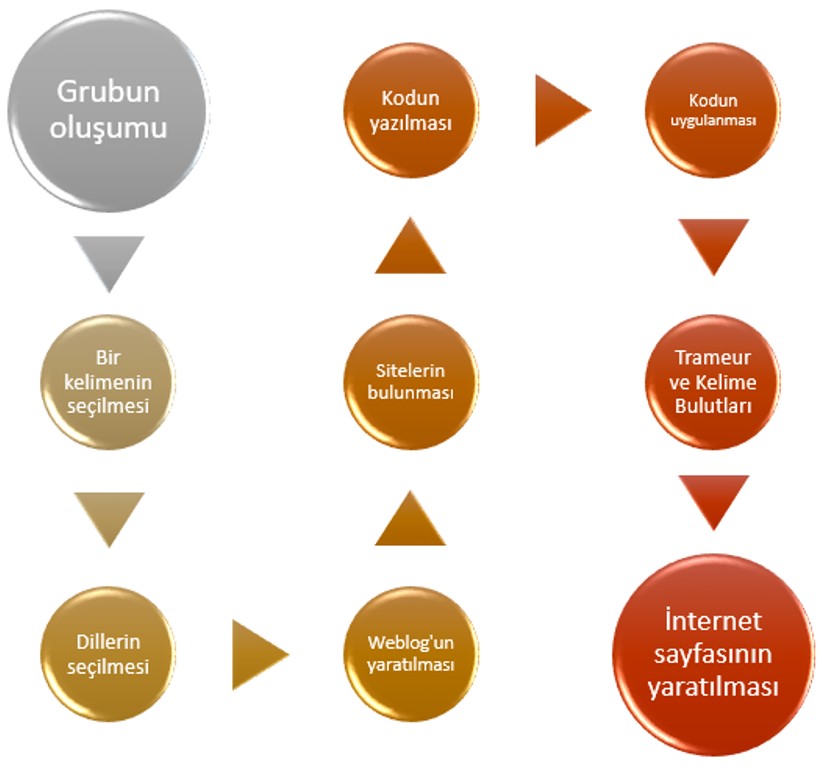
Grafiğin ilk dört adımları, önemli olmalarına rağmen, yeterince hızlı bir şekilde gerçekleştirildiler. Kelimenin seçimi çok düşünülmeli. Ancak projemizin başında, anladık ki, «bir insana garip gelen birşey, başka bire garip gelmeyebilir». Bundan dolayı, «garip» kelimesini seçmeye, ve, değişik durumlarda ve dillerde nasıl kullanıldığını karşılaştırmaya karar verdik.
Beşinci adıma gelince, sitelerin toplanmasıydı. Başlamadan önce, bazı sorulara cevap vermeliydik: «Kullanılacağımız siteler sadece basından mı olacak?», «Seçtiğimiz kelimeye göre, blogarın kullanılması da iyi bir fikir mi?», «Kaç site bulmalıyız?», vs. Sonunda, her dil için, basından 70 site bulmaya karar verdik. Amacımızi oldukça dengeli bir külliyat (corpus) kurmaktı.
Altıncı adımı, yani kodun yazılmasını başlamadan önce, kodun ne yapması gerektiğini insan dilinde anlatmak önerilir.
Taslağımız:
- Sitelerin, tablonun ve motif'in görelli dosya yollarının bulunduğu, girdi (parametres.txt) dosyasının bulunması.
- Sonuçların yazılacağı, çıktı (tableau-final.html) dosyasının bulunması.
- «URLS» repertuarında bulunan her dosyasının işlenmesi
- Dosyanın her satırı, yani her sitenin, okunması
- (curl komutuyla) sayfanın indirilmesi
- (curl ya da egrep komutlarıyla) sayfanın kodlamasının bulunması
- Eğer kodlama utf-8 ise: lynx –dump yapıp, sonra aradığımız motif'i egrep ile buluyoruz, ve sıklığını bulabilmek için –c («count») 'ı kullanıyoruz.
- Eğer kodlama utf-8 değilse, yukarıdaki komutları yapmadan önce, ilk olarak kodlamanın iconv komutundan tanıldığını kontrol ediyoruz (önce komutun hangi kodlamalarını tanıdığını bir liste de görebilmek için iconv –l komutu kullanıyoruz, sonra da bu listeden egrep yapıp, kodlamamızı ayırıyoruz)
- Eğer bulduğumuz kodlama iconv komutundan tanılıyorsa, o zaman onu utf-8 'e çevirmemiz lazım. Mümkün değilse, devam edemeyiz...
- Sonuçların çıktı (tableau-final.html) dosyasında yazılması
Tablolarımızda 12 sütun vardır :
- N° : tablodaki her sayfanın sayılması için kullanılan bir ölçer
- URL : sitenin bağlantısı
- Code CURL : «200» ise, o zaman sayfanın indirilmesinde bir sorun çıkmadı
- Statut CURL : uygulamanın sonucu
- P.A. : indirilen sayfalar
- Encodage Initial : indirilen sayfaların kodlaması
- DUMP Initial : utf-8 olmayan, ve çevirilmesi gerekeceği, bir metnin DUMP 'ı (indirilmesi)
- DUMP UTF-8 : utf-8 olan, bir metnin DUMP 'ı (indirilmesi)
- Contexte UTF-8 (txt) :seçilmiş kelimenin bağlamının DUMP'dan çıkarılması
- Contexte UTF-8 (html) :minigrep programıyla bu bağlamının gösterilmesi
- Freq MOTIF :DUMP'da seçilmiş kelimenin frekansı
- Index DUMP :DUMP'da bulunan her kelime, frekansıyla birlikte, liste olarak gösterilir
Yedinci adım, Trameur denilen bir sözcük ölçüm cihazının kullanımına bağlıdır. Programı, «garip» kelimesinin tekrar sıklığını bulabilmek için kullandık. Sonra, İnternet'te müsait olan bazı uygulamarı, kelime bulutları yapmak için kullandık. Kelime bulutları yapmak için DumpGlobal ve ContexteGlobal dosyaları, ve Tagul, ImageChef, WordClouds uygulamaları kullandık.
Son adım, projemizi oluşumunu göstermek için, bu sitenin oluşturulmasıydı.
Umarız hoşunuza gider...
 Türkçe
Türkçe العَرَبِيَّة
العَرَبِيَّة English
English Français
Français Ελληνικά
Ελληνικά 한국어
한국어