Secteur TAL Informatique,
Université Sorbonne nouvelle, Paris 3
19 rue des Bernardins, 75005 Paris


Cours "Programmation et projet encadré" 1 et 2 - MASTER TAL M1
Cours Programmation et Projet encadré | pluriTAL.org
Master TAL 1 (semestre 1 et 2) Paris 3 / Paris X / INALCO
 |
Responsables du cours
Serge Fleury (Paris 3), Jean-Michel Daube (Inalco), Rachid Belmouhoub (Inalco).
(contact : serge.fleury[at]univ-paris3.fr)
Architecture du cours
L'architecture du cours "Projet encadré" s'organise de la manière suivante :
- La page officielle du cours est celle que vous êtes en train de lire : http://www.tal.univ-paris3.fr/cours/masterproj.htm. Beaucoup de liens sont à explorer sur cette page...
- Un espace "privé" L7TIL5 Programmation et projet encadré 1 sur l'espace numérique de Paris 3 accessible avec vos identifiants de Paris 3
- Un espace "privé" L8TIL3 Programmation et projet encadré 2 sur l'espace numérique de Paris 3 accessible avec vos identifiants de Paris 3
- Les blogs mis en oeuvre par chaque groupe d'étudiants (les adresses de ces blogs devront être adressées à SF)
Descriptif du cours
Mise en oeuvre d'une chaîne de traitement textuel semi-automatique, depuis la récupération des données jusqu'à leur présentation. Ce cours posera d'abord la question des objectifs linguistiques à atteindre (lexicologie, recherche d'information, traduction...) et fera appel aux méthodes et outils informatiques nécessaires à leur réalisation (récupération de corpus, normalisation des textes, segmentation, étiquetage, extraction, structuration et présentation des résultats...). Ce cours sera aussi l'occasion d'une évaluation critique des résultats obtenus, d'un point de vue quantitatif et qualitatif.
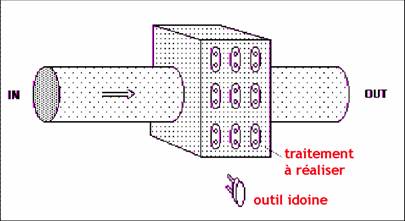 |
Sommaire des projets S1 et S2
- Semestre 1
- Intersemestre
- Semestre 2
- Projet Boîte à Outils
- Boîte à Outils : préambule
- Boîte à Outils 1 : extraction de texte (initiation à Perl)
- Boîte à Outils 2 : étiquetage
- Boîte à Outils 3 : extraction de patron
- Boîte à Outils 4 : des textes aux graphes
- Boîte à Outils 5 : information mutuelle
- Rubrique "Travaux BAO réalisés (S2)"
- Lectures
- Outils
- Liens
Projet La vie "multilingue" des mots sur le web
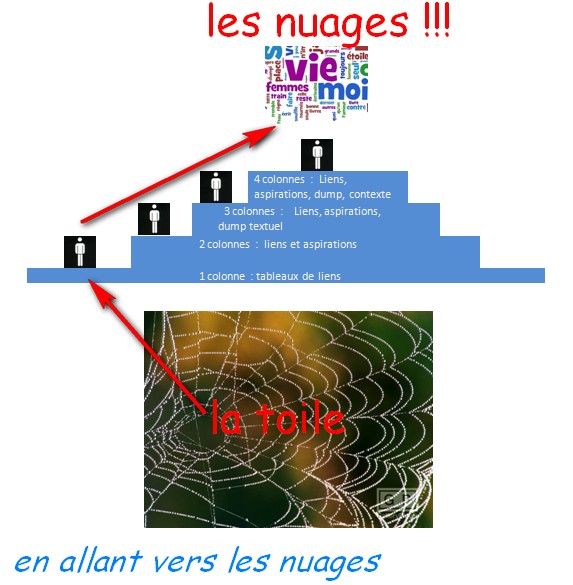
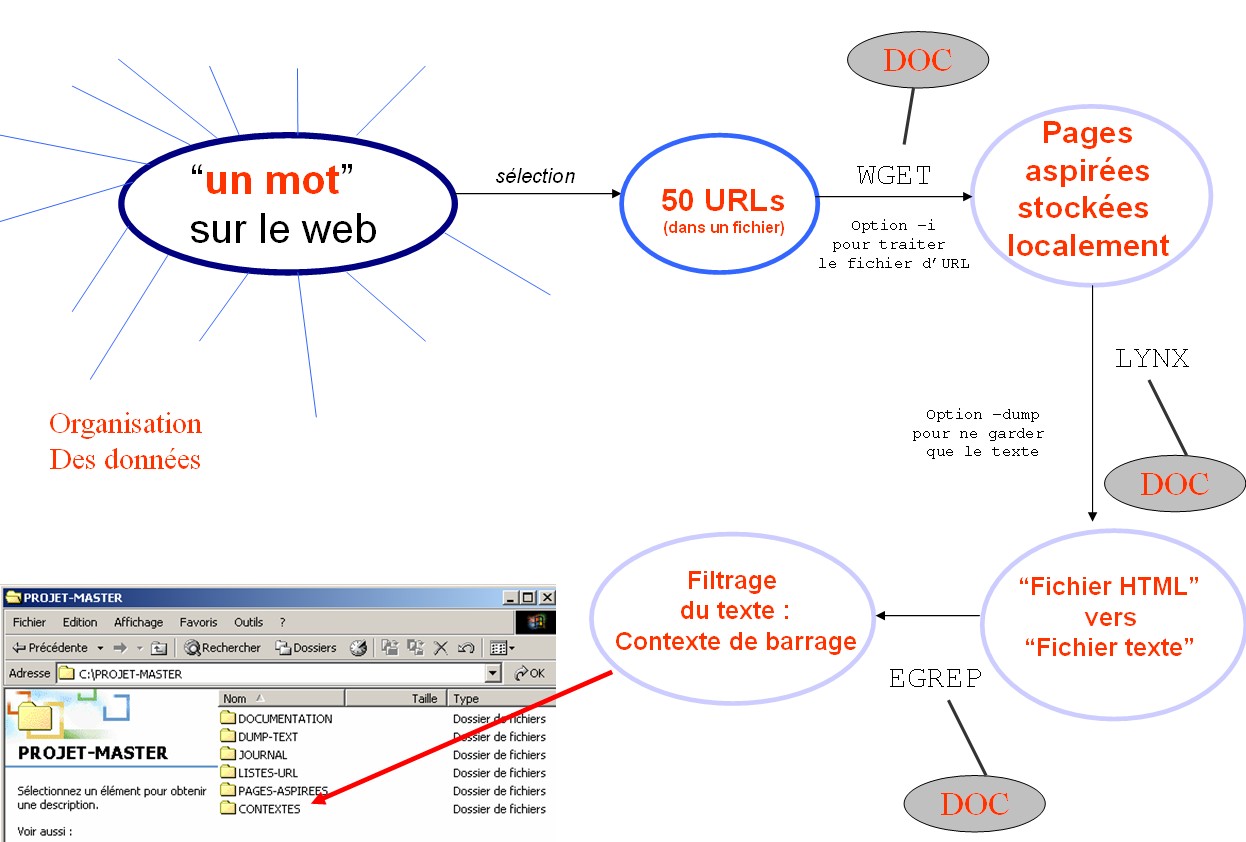
SLIDES Projet1
Une lecture nécessaire pour démarrer : "Unix for the Beginning Mage"
Transparents Série 1 (version PDF), "Présentation du cours et du projet, le mini-projet "un mot sur le web", ... ou (version HTML).
Transparents Série 2 (version PDF) : "Fichiers et systèmes de fichiers"
Transparents Série 3 (HTML) : "Egrep et expressions régulières"
Phase 1
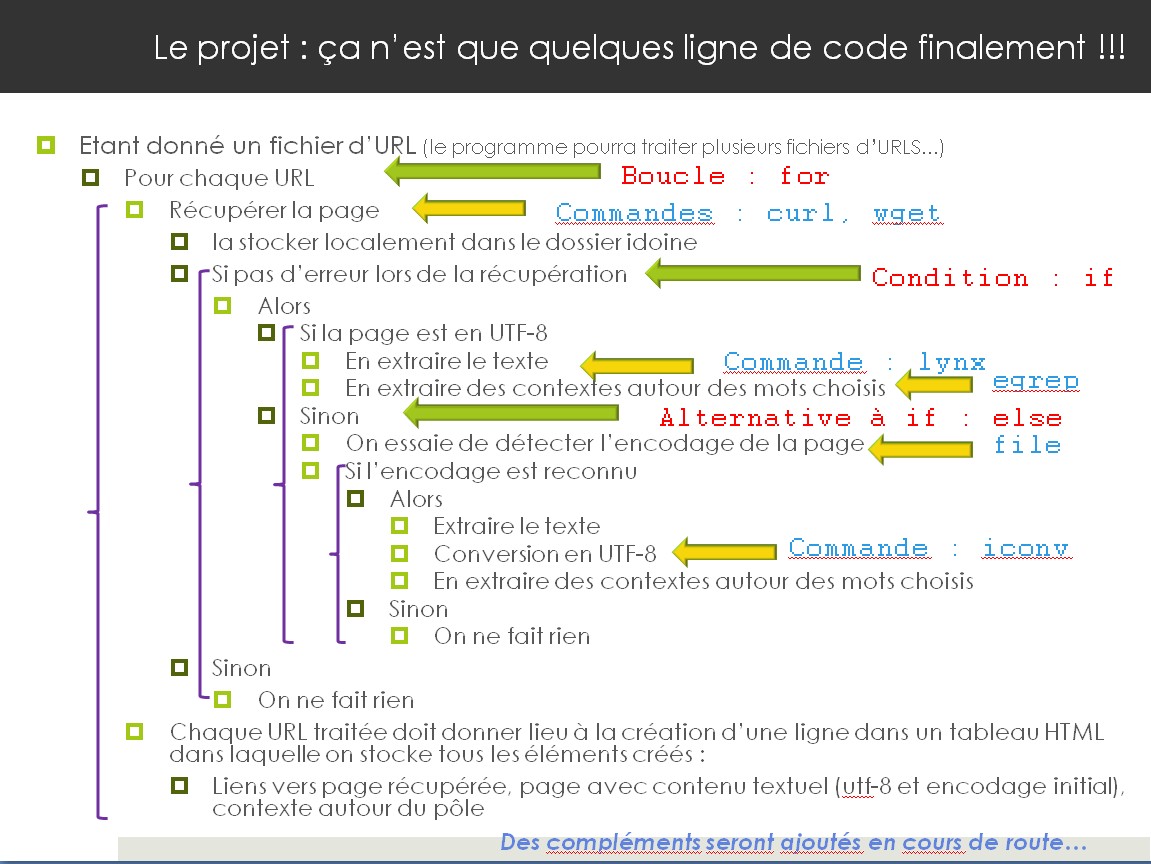
Ci-dessous, la chaîne de traitements à mettre en oeuvre sur une URL :
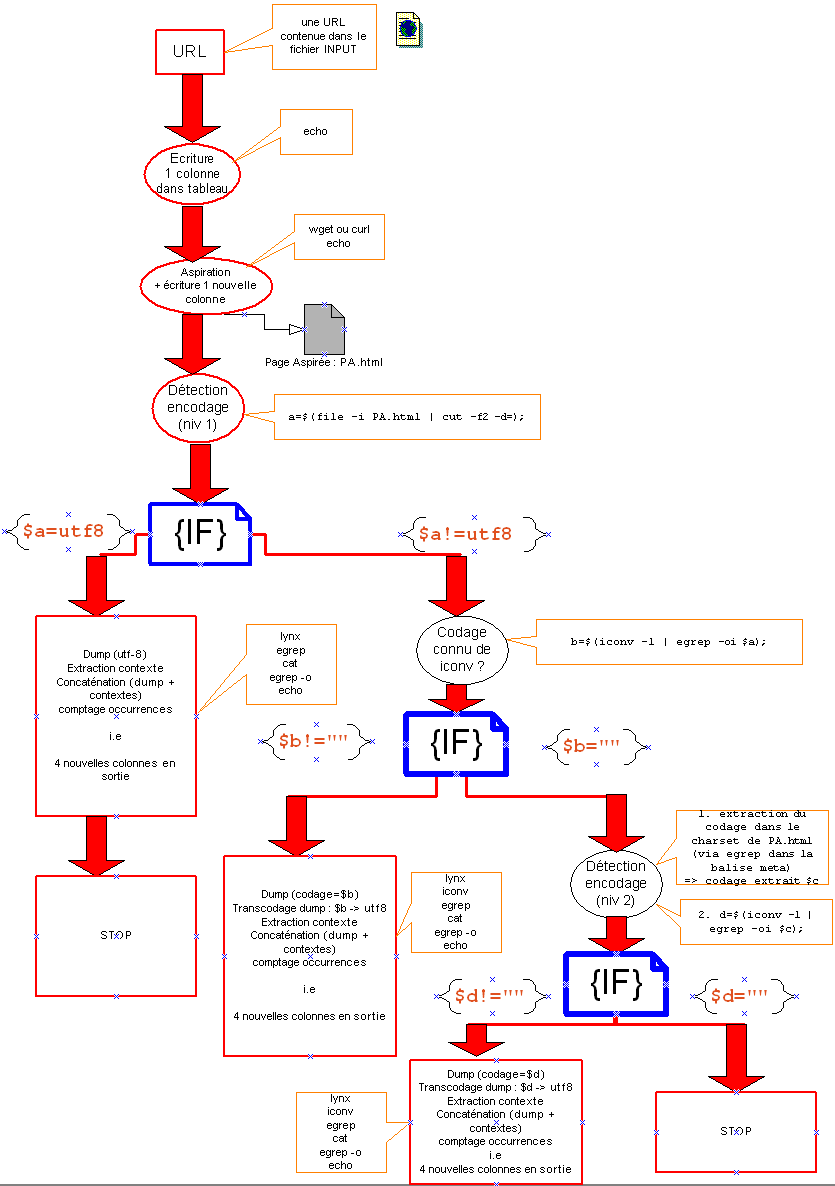
- Phase 1 : Les différentes étapes d'écriture des scripts de traitement des pages contenant les mots choisis
- Un mini-grep multilingue en Perl
- Mode d'emploi : installation de mini-grep multilingue sous cygwin
- Archives : Parcours par étapes
- "Automatisation des tâches" (étape 1)
- Incise "Introduction à Unix" (Transparents du cours de R.Belmouhoub)
- "Automatisation des tâches" (étape 2)
- "Automatisation des tâches" (étape 3)
Phase 2
Ressources complémentaires
- un modèle de site (vide) pour le rapport final. On regardera aussi sur ce site : [1] Apprendre le langage HTML ("site réservé aux débutants") et ici : [2] Maîtrisez le langage HTML ("cours pour niveau avancé en HTML") ou encore ici sur le site de l'académie de Créteil
- Pour préparer la création de votre site du projet, quelques adresses pour récupérer des modèles de site web : http://www.free-css-templates.com/ ou http://www.oswd.org/ (il y en a d'autres... accessibles très facilement sur google. Vous pouvez aussi vous inspirer des travaux des étudiants des années passées. Certains sont très beaux). Si vous choisissez un modèle sur les sites mentionnés, il faut ensuite procéder de la manière suivante :
- Une fois le modèle téléchargé, vous obtenez un fichier qu'il vous faut décompresser pour obtenir un dossier contenant le fichier index.html (la page d'accueil de votre futur site) ainsi que d'autres fichiers utiles pour l'apparence du site : image de fond, feuille de style, etc.
- C'est ce fichier "index.html" qu'il vous faut ouvrir avec un éditeur de texte type notepad (ou un éditeur HTML type NVU) pour le modifier et y ajouter du contenu propre à votre site.
- Vous pouvez ensuite dupliquer ce fichier index.html plusieurs fois de manière à obtenir un fichier pour chaque page de votre site, que vous pourrez éditer de la même façon à l'aide de votre éditeur préféré.
- N'oubliez pas de modifier les liens des menus (attention à l'écriture des chemins des fichiers dans l'écriture des liens... des chemins relatifs a priori), pour permettre à vos visiteurs de passer d'une page à l'autre.
- Une fois que vous aurez l'impression que tout est opérationnel, vous zippez le dossier contenant votre site et vous l'envoyer à SF (à cette adresse sergefleury@gmail.com).
Lectures complémentaires
Les moteurs de recherche multilingues.
Traduction et Veille stratégique multilingue : Supports et communications. On regardera en particulier : M. Jean-Paul PINTE, Institut Catholique de Lille :
« La Veille pédagogique : outils et ressources pour les traducteurs »
Outils, liens :
Un nouveau service de traduction en ligne qui permet d'accéder à des millions de textes traduits par d'autres personnes : http://www.linguee.fr/
http://www.2lingual.com/
http://ajaxime.chasen.org : système de saisie en ligne (pratique par exemple quand le japonais n'est pas disponible sur votre machine).
http://blog.imtranslator.com/ : module à installer dans Firefox ou IE.
http://clusty.com/
http://ultralingua.com/online-dictionary/
http://babelplex.com/
http://www.kvisu.com/
http://www.touchgraph.com/
http://www.ujiko.com/v2a/flash.php?langue=fr
http://mapdream.com
http://urfist.univ-lyon1.fr/risi/outils.htm
Intermède Perl pour les linguistes
Préambule
"Pourquoi programmer (1) et pourquoi Perl (2)" :
(1) "Working with language data is nearly impossible these days without a computer. Data are massaged, analyzed, sorted, and distributed on computers. Various software packages are available for language researchers, but to truly take control of this domain, some amount of programming expertise is essential"
(2) "The Perl programming language may provide an answer. There are a number of reasons why Perl may be an excellent choice. First, Perl was designed for extracting information from text files. This makes it ideal for many of the kinds of tasks language researchers need. Second, there are free Perl implementations for every type of computer. It doesn't matter what kind of operating system you use or computer architecture it's running on. There is a free Perl implementation available. Third, it's free. Again, for any imaginable computer configuration, there is a free Perl implementation. Fourth, it's extremely easy. In fact, it might not be an exaggeration to claim that of the languages that can do the kinds of things language researchers need, Perl may be the easiest to learn. Fifth, Perl is an interpreted language. This means that you can write and run your programs immediately without going through an explicit intermediate stage to convert your program into something that the computer will understand. Sixth, Perl is a natural choice for programming for the web. Finally, Perl is a powerful programming language."
(source : [Hammond 2003])
Ressources pour le cours
Le cours sera fait à partir des transparents présentés pendant les différentes séances. Ces transparents sont disponibles ci-dessus et ci-dessous en version flash.
IMPORTANT :
On regardera (très souvent) les fiches "MEMO PERL" disponibles sous iCampus
Fiche-intro.pdf : Introduction
Fiche1.pdf : généralités
Fiche2-generalites.pdf : généralités (suite)
Fiche2.pdf : généralités (suite)
Fiche3-regexp.pdf : les expressions régulières
Fiche4-TableauxEtHachages.pdf : Les tableaux de scalaires et les tables de hashage
Fiche5-references.pdf : les références (tableau de tableaux...)
Fiche6-fichiers.pdf : les entrées/sorties, gestion de fichiers
Une introduction par l'exemple (avec interface graphique) :
Perl pour le TAL :
Un polycopié est aussi disponible (sous iCampus) pour enrichir la présentation du langage Perl.
Ce polycopié est composé de 3 volumes :
1. Le langage de base
2. Une "programmothèque"
3. Présentation détaillée de Perl/tk
Un polycopié complémentaire traite de Perl/XML (utilisation des bibliothèque de la "galaxie XML" avec Perl, voir aussi les slides Perl/XML et les slides Perl/TK).
Lectures conseillées
Perl pour les linguistes : Programmes en Perl pour l'exploitation des données langagières, 2007. Un environnement de travail complet ainsi que tous les programmes présentés dans le livre sont disponibles sur ce site : http://perl.linguistes.free.fr/. On regardera en particulier tous les programmes disponibles sur ce site que l'on pourra (ré)utiliser.
Sur le site Developpez.com, un portail Perl avec de très belles ressources : cours en ligne, outils, codes etc... détour indispensable : http://perl.developpez.com/
Tutoriel des expressions rationnelles en Perl : http://perl.enstimac.fr/DocFr/perlretut.html
Eric Wilhelm has written six tutorials - from "Getting Started with Perl" to "Your First GUI DesktopApplication". The six tutorials are :
http://learnperl.scratchcomputing.com/tutorials/getting_started/ : Getting Started with Perl
http://learnperl.scratchcomputing.com/tutorials/csss/ : Control, Structures, Scoping, and Subroutines
http://learnperl.scratchcomputing.com/tutorials/modules/ : Using and Creating Modules
http://learnperl.scratchcomputing.com/tutorials/objects/ : An Introduction to Objects
http://learnperl.scratchcomputing.com/tutorials/configuration/ : Perl/CPAN Configuration Howto
http://learnperl.scratchcomputing.com/tutorials/wxperl/ : Your First GUI Desktop Application
Projet Boîtes à outils
Préambule
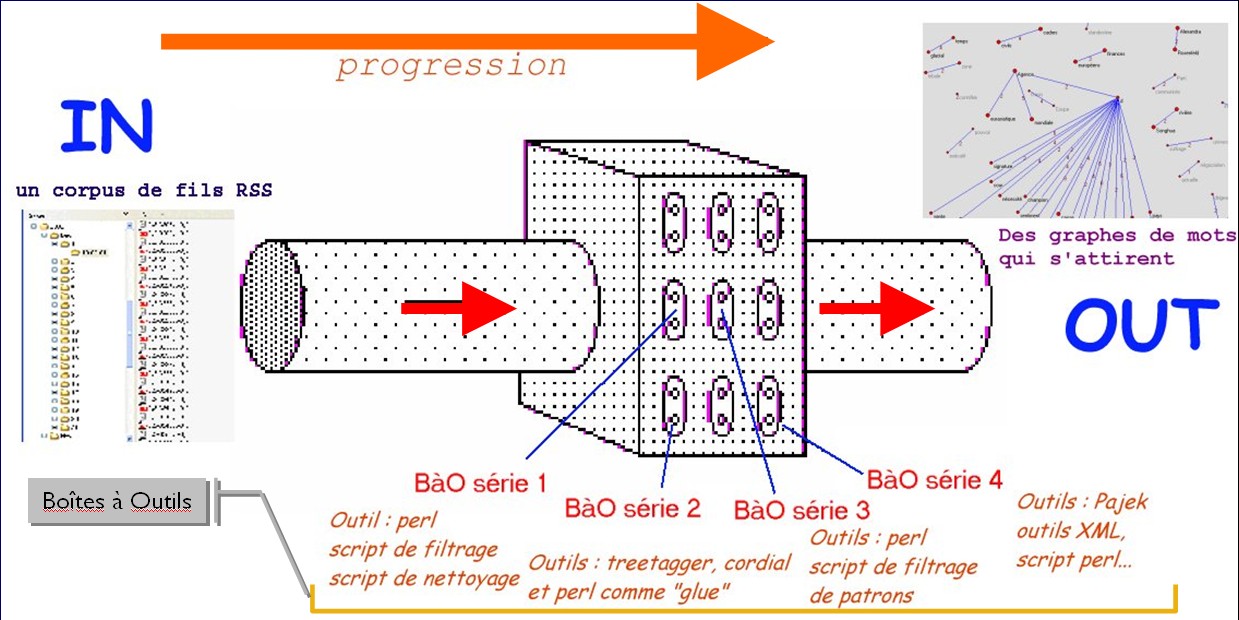
Lectures complémentaires autour de RSS et de ses applications
- RSS : Le bouche à oreille électronique
- Introduction à RSS sur le site commentcamarche.com.
- Présentation très complète réalisée par des bibliothécaires de l'université de Montréal : "La première partie se veut une introduction générale à RSS tandis que la seconde partie s'applique à démontrer des exemples d'usages courants et innovateurs de cette technologie par les bibliothèques, usages qui pourraient être amenés à se généraliser dans le futur."
- Support de cours réalisé par Stéphane Cottin pour la formation ADBS : "Utiliser les fils RSS". Les points abordés au cours de cette formation : Définition(s) et usages du format RSS, Comment s'y abonner ? Comment en trouver ? Quels outils ou services pour les exploiter (services en ligne, logiciels indépendants, fonctionnalités des navigateurs). Comment chercher dans des fils RSS ? Comment syndiquer du contenu ?
- Fils RSS et veille. Présentation réalisée par Sylvie Le Bars expliquant comment mettre en pratique les flux RSS dans un processus de veille.
Projet Boîte à Outils (BàO) : présention générale
- Transparents : VERSION PDF.
Boîte à Outils (BàO) : série 1
- "Boîte à outils Série 1 : script Perl". Transparents : VERSION PDF ; VERSION HTML (avec liens actifs, version "optimisée" pour Internet Explorer)
- Corpus de Travail et ressources
- Outils et ressources pour démarrer : le corpus de test et les scripts à utiliser pour démarrer sont accessibles dans cette archive.
- REMARQUE : Un poly perl et des ressources autour de Perl seront disponibles sur iCampus...
- Mise en oeuvre de la BAO1 :
- Données de départ : le script parcours-arborescence-fichiers.pl fourni dans cette archive et le corpus de test disponible dans la même archive
- Modifier le script fourni pour produire 2 sorties : version TXT brut, version XML. On essaiera d'expliciter les problèmes à résoudre pour la construction de la version XML (cf au regard de la version proposée ici en exemple). On regardera notamment le complément n°1 ci-dessous...
- IMPORTANT : on distinguera pour chaque article, le titre et sa description (résumé). On veillera aussi à ne pas mémoriser plus d'une fois le même article. On nettoiera les données...
- IMPORTANT encore... : en sortie, la BàO1 doit construire 2 types de sortie (XML, TXT). Ces sorties peuvent contenir le traitement de l'ensemble des rubriques (ou une sélection de rubrique). En outre, il est préférable de produire des sorties distinctes pour chaque rubrique : par exemple, le traitement de la rubrique A la Une conduit à 2 fichiers de sortie, celui de la rubrique International aussi etc.
- IMPORTANT encore et encore... : une lecture indispensable "Understanding recursive subroutines - traversing a directory tree"
- Solution provisoire : le script suivant sera à améliorer... A suivre, d'autres méthodes plus judicieuses...
- Complément n°1 : Comment mettre en oeuvre l'extraction des contenus textuels dans les fils RSS ? Objectifs, difficultés, 2 solutions provisoires...
- Présentation au format PDF. Archive contenant le texte de présentation, 2 fils RSS pour illustrer les problèmes à résoudre, des scripts proposant des solutions (quasi définitives mais à adapter au traitement global de l'arborescence à traiter)...
- Complément n°2 : Programme d'extraction des balises DESCRIPTION dans les fils RSS via la bibliothèque Perl XML::RSS
- Présentation au format PDF. Script d'exemple.
- Complément n°2 bis (11/2/2015) : Programme d'extraction des balises DESCRIPTION dans les fils RSS via la bibliothèque Perl XML::RSS
- Complément n°3 : Programme d'extraction des balises DESCRIPTION dans les fils RSS via les bibliothèques Perl XML::XPath et XML::LibXML
- Complément n°4 : Solution complète pour l'extraction des contenus textuels dans une arborescence de fils (méthode n°1 : à base de regexp)
- Cette archive contient l'arborescence de test (15 jours de 2008), le script "parcours-arborescence" intégrant la méthode n°1 d'extraction des contenus textuels et les résultats produits. Le script proposé ici peut encore être amélioré...
- On pourra s'inspirer du script proposé ci-dessus pour construire ceux intégrant les autres méthodes (XML::RSS, XML::XPath, XML::LibXML...)
- Exemple de sortie produite : contenu du fichier XML produit par le script précédent accompagné ici d'une feuille de style permettant de la visualiser dans votre navigateur...
IMPORTANT: Pour le projet BàO 2016-2017, le corpus de travail sera constitué de l'ensemble des fils RSS disponibles sur le site du journal Le Monde recueillis tous les jours de l'année 2016 à 19h .
On commencera par tester la chaîne de traitement sur un échantillon (15 jours seulement de l'année 2008) correspondant à celui fourni dans les ressources disponibles dans cette archive.
Pour récupérer le corpus complet de l'année 2016 : on trouvera le lien vers cette archive CORPUS-BAO-2016 sur la page iCampus du cours.
On pourra aussi traiter 7 autres années en récupérant au même endroit les archives : CORPUS-BAO-2015, CORPUS-BAO-2014, CORPUS-BAO-2013, CORPUS-BAO-2012, CORPUS-BAO-2011, CORPUS-BAO-2010, CORPUS-BAO-2009.
Séance de démarrage : Parcours d'une arborescence de fils RSS et extraction des contenus textuels. Application sur le corpus de test (15 jours de 2008)
Boîte à Outils (BàO) : série 2
- Présentation de la BàO2 :
- Boîte à outils Série 2 :étiquetage". Transparents : VERSION PDF ; VERSION HTML (avec liens actifs, version "optimisée" pour Internet Explorer). Voir aussi infra les slides version flash.
- Lecture complémentaire : "Etiquetage morphosyntaxique"
- Descriptif sommaire du travail à réaliser pour cette étape de travail :
- Dans la série "Boite à Outils" n°2, vous devez produire un étiquetage des données textuelles extraites dans l'arborescence des fils RSS du Monde en suivant les 2 parcours décrits ci-dessous :
- Etiquetage via Cordial de la concaténation complète des textes extraits (**) au cours du parcours de l'arborescence : en sortie un fichier texte avec 3 colonnes (forme, lemme, catégorie) ayant l'allure suivante
- Etiquetage via Treetagger "au fil de l'eau" i.e. vous devez modifier le(s) script(s) (vu à la BàO1) de parcours de l'arborescence des fils afin d'étiqueter les contenus textuels des fils RSS juste après leur extraction : en sortie, un fichier XML (format "fourni" par le script treetagger2xml à utiliser après l'étiquetage (cf mode d'emploi)) ayant l'allure suivante (dans cette seconde sortie, une feuille de style XSLT est associée au fichier XML)
- Etape complémentaire : vous pouvez aussi traiter "la concaténation complète des textes extraits" (**) avec Le Trameur. Ce programme permet de charger et d'étiqueter (avec treetagger) votre fichier de travail. Vous pouvez ensuite réaliser l'extraction de patron (cf mode d'emploi en ligne) que l'on mettra en oeuvre dans la BàO3 aussi.. On présente ici un exemple de sortie produite avec le Trameur sous la forme d'un rapport d'exploration contenant : (1) la liste des séquences de terme associées au patron NOM ADJ, (2) un graphe construit à partir de la liste précédente et réduit aux séquences contenant la forme "crise", données construites à partir du la rubrique POLITIQUE sur l'année 2008.
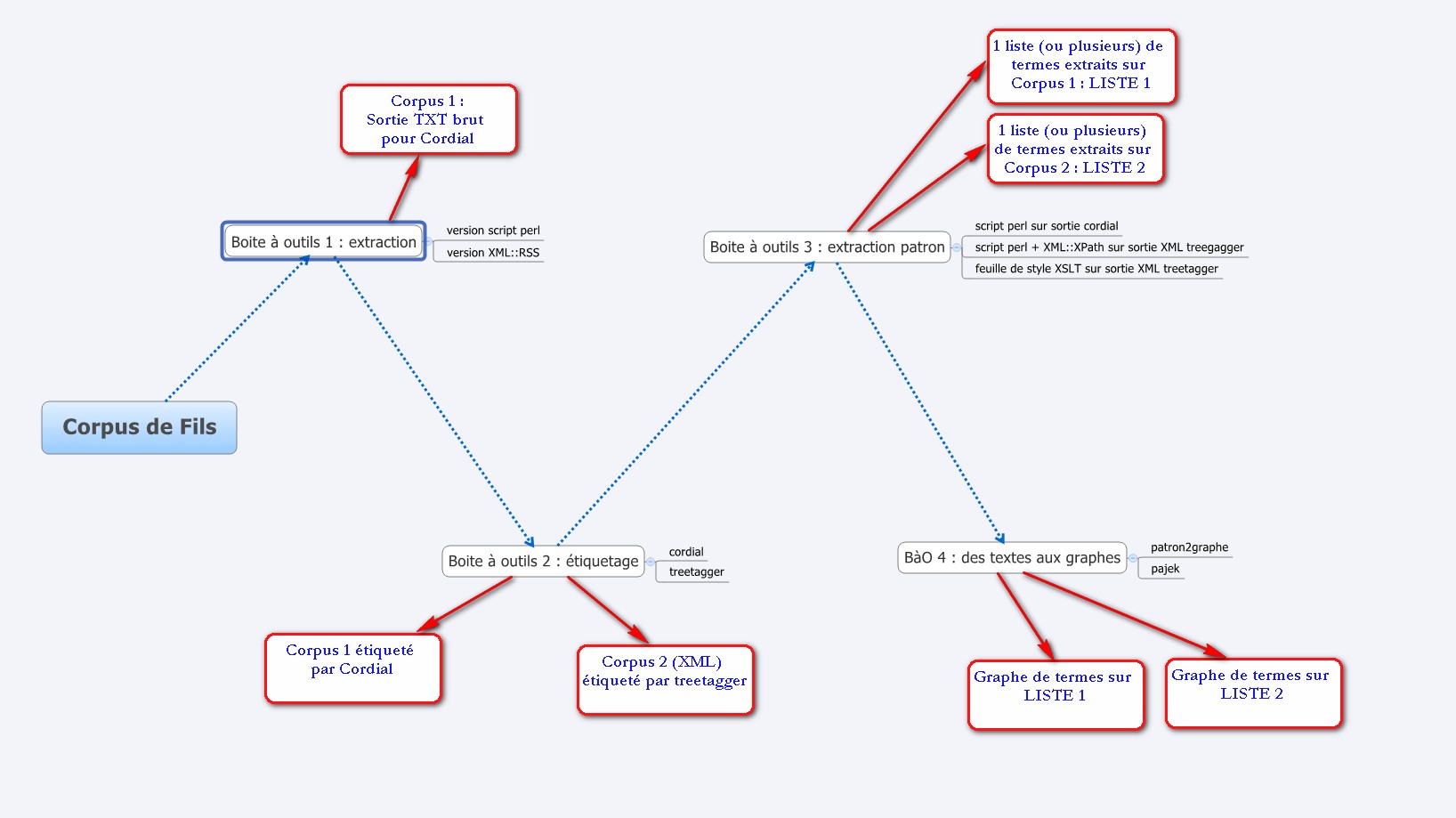
- La BàO1 ayant conduit à mettre en oeuvre plusieurs méthodes pour extraire les contenus textuels, l'intégration de l'étiquetage dans cette BàO2 se fera sur chacune des méthodes mises en oeuvre dans la BàO1.
- Ressources à utiliser :
- Ressources pour treetagger (win32) : Présentation de treetagger (version PDF ou version HTML). Archive complète avec treetagger et présentation. Pour les autres versions de Treetagger (linux, macosx), on ira les chercher sur le site de Treetagger.
- Exemple réduit de résultat à construire pour l'étiquetage avec Treetagger : Afficher le source pour visualiser la codage XML. Le fichier XML est présenté ici avec une feuille de styles XSLT reformatant son contenu pour affichage dans le navigateur.
- Ressources pour Cordial : une présentation au format PDF.
- Compléments :
- Complément n°1 : Solution complète pour l'extraction des contenus textuels dans une arborescence de fils (méthode n°1 : à base de regexp) avec étiquetage avec Treetagger
- Cette archive (mise à jour le 23/03/2011 : avec modif treetagger2xml) contient l'arborescence de test (2 jours de 2008), le script "parcours-arborescence" intégrant la méthode n°1 d'extraction des contenus textuels (via regexp) et leur étiquetage avec treetager et les résultats produits (dans le sous-dossier SORTIE : pour chaque rubrique, on trouve la sortie TXT, XML et XML-treetagger). Le script proposé ici peut encore être amélioré...
- On pourra s'inspirer du script proposé ci-dessus pour construire ceux intégrant les autres méthodes (XML::RSS, XML::XPath, XML::LibXML...)
- On pourra s'inspirer aussi de la feuille de style XSLT associée à l'exemple précédent de résultat (montrant la sortie XML-treetagger) et l'adapter à vos besoins...
- Sorties produites par la BAO2 :
- 2008 : corpus de test : liste-fichiers-bao2-2008.html
- 2013 : corpus complet : liste-fichiers-bao2-2013.html
Boîte à Outils (BàO) : série 3
- "Boîte à outils Série 3 : Introduction Extraction de patrons". Transparents du cours : Version PDF ou version PPT.
- Dans les transparents qui suivent, on présente les 3 étapes à réaliser :
- Extraction de patrons sur les sorties "brutes" de l'étiquetage (via Cordial) issues de la Boîte à Outils Série 2 via un script perl (détail dans les transparents et liens qui suivent)
- On propose ci-dessous 3 solutions pour cette étape que vous devrez tester et éventuellement mettre à jour pour traiter vos données :
- Solution 1 : script vu en cours avec JMD
- Solution 2 : alternative proposée par SF
- Solution 3 : alternative proposée par Axel Court
- Solution 4 : alternative proposée par SF sur NOM ADJ (comme dans Le Trameur...). Il faudra faire la même chose pour d'autres patrons...
- Extraction de patrons sur les sorties au format XML de l'étiquetage (via Treetagger) issues de la Boîte à Outils Série 2 via un script perl (vu avec RB) utilisant la bibliothèque XML::LibXML.
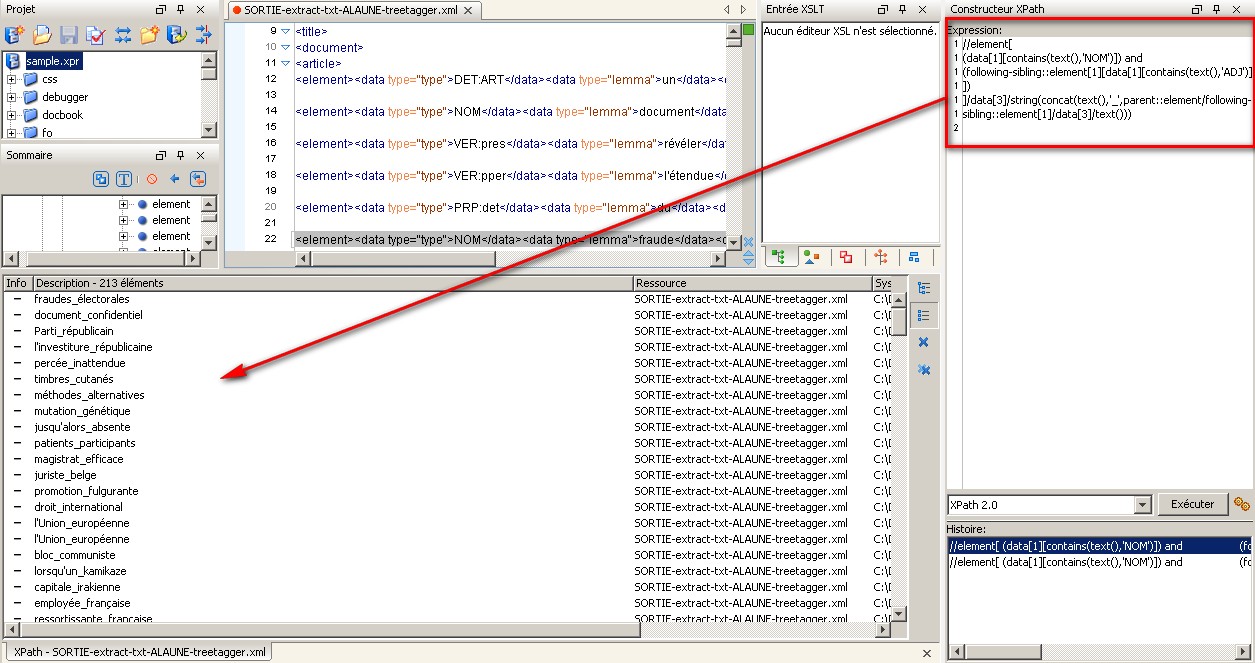
- Extraction de patrons sur les sorties au format XML de l'étiquetage (via Treetagger) issues de la Boîte à Outils Série 2 via un script perl (vu avec RB) utilisant la bibliothèque XML::XPath. Ressources complètes pour cette étape (version 2012)
- Présentation du script : code commenté
- Prérequis :
- L'arborescence du fichier de tags en entrée du script d'extraction doit être celle produite par le script treetagger2xml.pl, comme dans cet exemple.
- Le nombre de motifs recherchés est laissé au libre choix de l'utilisateur, dans notre fichier exemple nous avons deux motifs : "NOM PRP NOM" et "NOM ADJ".
- Le script stocke les résultats obtenus pour chaque motif dans un fichier différent, par exemple pour le motif "NOM ADJ".
- ARCHIVES : ancienne version de ce script. Ressources complètes pour cette étape : slides et code (cf slides infra)
- Extraction de patrons sur les sorties au format XML de l'étiquetage (via Treetagger) issues de la Boîte à outils Série 2 : on utilisera ici une requête XPath dans une feuille de styles XSLT pour construire la liste des patrons visés.
- On donne à voir dans un premier temps le résultat attendu (patron : NOM ADJ) construit à partir d'un exemple réduit de résultat construit dans Boîte à outils Série 2 (Afficher le source pour visualiser la codage XML, le fichier XML est présenté ici avec une feuille de styles XSL reformatant son contenu pour affichage dans le navigateur). [Lien direct vers la feuille de styles utilisée pour construire le résultat attendu]
- On donne maintenant à voir le résultat attendu (patron : NOM PRP NOM) construit à partir d'un exemple réduit de résultat construit dans Boîte à outils Série 2 (Afficher le source pour visualiser la codage XML, le fichier XML est présenté ici avec une feuille de styles XSL reformatant son contenu pour affichage dans le navigateur). [Lien direct vers la feuille de styles utilisée pour construire le résultat attendu]
- Autre exemple de sortie : traitement du fil RSS "Présidentielle 2007" proposé sur le site du journal "Le Monde". Période traitée : 20/11/2006-10/02/2007. Extraction du patron NOM ADJ : (1) 20/11/2006-31/12/2006 (2) 01/01/2007-10/02/2007.
- Enfin, une autre solution utilisant une requête XPath 2.0 sur le patron "NOM ADJ" et mise en oeuvre ici dans oXygen :
- "Boîte à outils Série 3 : Extraction de patrons"". Transparents du cours (suite 1 : extraction via script)
- "Boîte à outils Série 3 : Extraction de patrons" Compléments et détails.
- "Boîte à outils Série 3 et 4 : Extraction de patrons" Travail à réaliser avec le TRAMEUR : extraction de patrons et graphes de mots.
Boîte à Outils (BàO) : série 4
- "Boîte à outils Série 4" (via patron2graph) : Le programme patron2graph.exe : le programme, mode d'emploi et fichiers de test. Exemple de sortie :
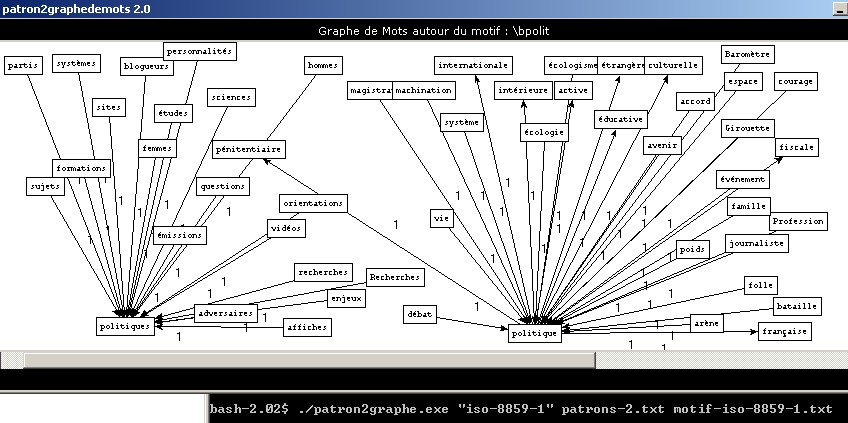
- "Boîte à outils Série 4" (via pajek) : Des textes aux Graphes : pas à pas (et à la main!).
Boîte à Outils (BàO) : série 5
- "Boîte à outils Série 5 : Information mutuelle" (ressources complètes zippées)
Web Services
lectures
- Service Web sur wikipedia
- Web Services Tutorial
- Web services et bibliothèques
WebServices à voir
- uclassify : uClassify is a free web service where you can easily create your own text classifiers.
- Open Calais : The OpenCalais Web Service automatically creates rich semantic metadata for the content you submit - in well under a second. Using natural language processing (NLP), machine learning and other methods, Calais analyzes your document and finds the entities within it. But, Calais goes well beyond classic entity identification and returns the facts and events hidden within your text as well.
- DayLife : Daylife API lets you complement your enterprise reporting by giving your editors and developers access to a vast trove of high-quality content as it's published. Create tens of thousands of pages of new content and inventory using a fraction of the resources normally required.
- AlchemyAPI : AlchemyAPI provides content owners and web developers with a rich suite of content analysis and meta-data annotation tools.
Lectures
- Tutorial Perl : The tutorial is split into twenty-one sections, although you'll probably find it easier if you start from the beginning, especially if you're new to Perl. Lessons zero to ten deal with the basics, and the rest deal with more advanced topics, like servers, perl's guts, and parsing. Lesson 12 seems particularly popular: it deals with perl under Windows. The tutorial should be in line with modern Perl practices, so hopefully you won't see any more bareword filehandles, two-argument open or -w switches.
- Guide avancé d'écriture des scripts Bash, sur le Site de traduction français pour le guide ABS Advanced Bash Scripting Guide
(Lien : Version 5 http://abs.traduc.org/abs-5.0-fr/)
Une exploration en profondeur de l'art de la programmation shell. Ce tutoriel ne suppose aucune connaissance de la programmation de scripts, mais permet une progression rapide vers un niveau intermédiaire/avancé d'instructions tout en se plongeant dans de petites astuces du royaume d'UNIX. Il est utile comme livre, comme manuel permettant d'étudier seul, et comme référence et source de connaissance sur les techniques de programmation de scripts. Les exercices et les exemples grandement commentés invitent à une participation active du lecteur avec en tête l'idée que la seule façon pour vraiment apprendre la programmation de scripts est d'écrire des scripts.
On regardera en particulier : la seconde partie, le chapitre 10, le chapitre 14, etc. - Pour utilisateurs débutants ou confirmés : Unix, le Terminal, les Expressions régulières... tout ça est sur le site d'Isabelle Volant. On y retournera souvent donc.
- La documentation de Perl : Article publié dans Linux Magazine 53, septembre 2003. Repris dans Linux Dossiers 2 (avril/mail/juin 2004), "L'objectif de cet article est de vous fournir les moyens de trouver seul la réponse aux questions que vous vous posez, ou au moins de progresser aussi loin que possible avant de finir par poser la question sur un forum ou une liste de discussion."
- Sur le site d'IBM, la série "Speaking Unix" :
- Speaking UNIX, Part 15: !$#@*%
Learn even more command-line tricks and operators. - Speaking UNIX, Part 14: It is all about the inode
Have you ever wondered what Iused and %Iused mean in UNIX® commands like df or what people are talking about when the say inode? UNIX and Linux® systems both use inodes, and IBM® AIX® is no different. Discover what an inode is and why inodes are important to UNIX, the structure of an inode, and commands for working with inodes. - Speaking UNIX, Part 13: Ten more command-line concoctions
This month, discover ten more secrets of the UNIX command-line wizards. - Speaking UNIX, Part 12: Do-it-yourself projects
If your UNIX(R) system lacks a tool you need, chances are you can find an apt solution in the enormous inventory of software available online. This month, learn how to build software from source code. - Speaking UNIX, Part 11: Ramble around the UNIX file system
Many directories in the UNIX® file system serve a special purpose, and certain directories are named per long-standing convention. In this installment of the "Speaking UNIX" series, discover where UNIX stores important files. - Speaking UNIX, Part 10: Customize your shell
You can customize the UNIX® shell to save time, to save typing, and to adapt to your style of work. Shell startup files capture your preferences and recreate your shell environment session after session, even machine to machine. - Speaking UNIX, Part 9: Regular expressions
Virtually all non-trivial problems require you to filter good data from bad. Discover the many UNIX® command line utilities that use regular expressions to discern the relevant from the irrelevant. - Speaking UNIX, Part 8: UNIX processes
On UNIX® systems, each system and end-user task is contained within a process. The system creates new processes all the time and processes die when a task finishes or something unexpected happens. Here, learn how to control processes and use a number of commands to peer into your system. At a recent street fair, I was mesmerized by the one-man band. Yes, I am easily amused, but I was impressed nonetheless. Combining harmonica, banjo, cymbals, and a kick drum -- at mouth, lap, knees, and foot, respectively -- the veritable solo symphony gave a rousing performance of the Led Zeppelin classic "Stairway to Heaven" and a moving interpretation of Beethoven's Fifth Symphony. By comparison, I'm lucky if I can pat my head and rub my tummy in tandem. (Or is it pat my tummy and rub my head?). Lucky for you, the UNIX® operating system is much more like the one-man band than your clumsy columnist. UNIX is exceptional at juggling many tasks at once, all the while orchestrating access to the system's finite resources (memory, devices, and CPUs). In lay terms, UNIX can readily walk and chew gum at the same time. This month, let's probe a little deeper than usual to examine how UNIX manages to do so many things simultaneously. While spelunking, let's also glimpse the internals of your shell to see how job-control commands, such as Control-C (terminate) and Control-Z (suspend), are implemented. Headlamps on! To the bat cave! - Speaking UNIX, Part 7: Command-line locution
UNIX® has a dialect all its own, and its vocabulary of commands is quite large. But you don't have to learn everything all at once. Here, discover more command-line combinations and expand your mastery of the UNIX language. Whenever you travel to a foreign country in which the inhabitants speak an unusual native tongue, you might arm yourself with essential survival phrases, such as "How much does this cost?," "What kind of meat is this?," and "Where is the bathroom?" Memorizing such little quips ensures that you don't get overcharged for that snake sandwich you ordered, and you know where to go when Mother Nature (or the snake sandwich) calls. UNIX®, too, has a dialect all its own and, over the past six months, this Speaking UNIX series has provided something of a crash course in command-line locution. This month, learn several helpful phrases that will have you blending with the locals in no time. Grab your toothbrush, pack some comfortable shoes, and update your inoculations. You're off for sun, sand, and shells. (For the sun and sand, scoop up your laptop, head to the beach, plop down near the water's edge, and read this column. And don't forget your sunscreen.) - Speaking UNIX, Part 6: Automate, automate, automate!
Discover how shell scripts can mechanize virtually any personal or system task. Scripts can monitor, archive, update, report, upload, and download. Indeed, no job is too small or too great for a script. Here's an introduction. - Speaking UNIX, Part 5: Data, data everywhere
Take a look at several techniques that illustrate how to move files among systems and how to keep such far-flung data in sync. - Speaking UNIX, Part 4: UNIX ownership and permissions provide for privacy and participation
Learn how to manipulate file permissions to protect your files, or share them with others. - Speaking UNIX, Part 3: Do everything right from the command line
Discover three essential UNIX(R) utilities that deliver the entire Internet to your command line. - Speaking UNIX, Part 2: Working smarter, not harder
Learn how to leverage the many shortcuts that the UNIX(R) shell provides. With a little practice, you'll work smarter, not harder. - Speaking UNIX, Part 1: Command the power of the command line
Learn the basics of the UNIX shell and discover how you can use the command line to combine the finite set of UNIX utilities into innumerable data transforms.
Outils
- Unicode Input Tool/Converter 2.5.7 : Unicode lookup and chart view to find international characters or symbols; converts entities or character references (hex and dec) into Unicode and back
- GnuWin32 provides ports of tools with a GNU or similar open source license, to MS-Windows (Microsoft Windows 95 / 98 / ME / NT / 2000 / XP / 2003 / Vista / 2008)
- Cygwin beta20
- Cygwin
- Portable Ubuntu
- Emacs
- Perl
