Cours Projet encadré - plurital.org
Projet : La vie "multilingue" des mots sur le web.
Des nuages et des arbres de mots
(retour page d'accueil du cours)
Préambule
Pour commencer cette séquence, 2 lectures :
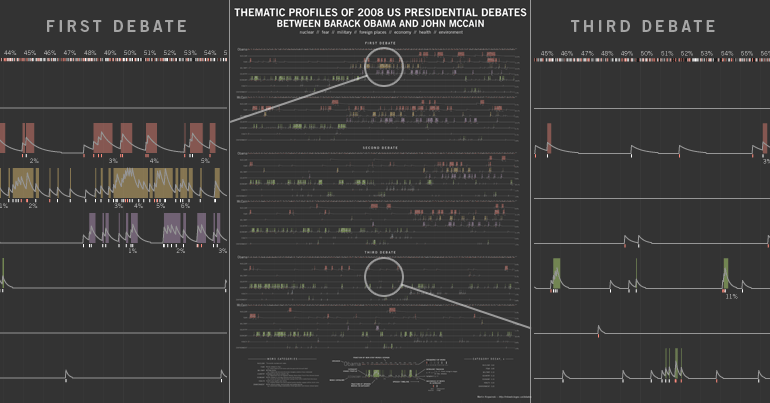
On commencera par une visite du site Partie2campagne : cartographie les mots-clés de la campagne (presse / politique). Avec notamment une présentation sous forne de nuage de mots-clés (« Tag cloud ») On lira aussi l'analyse réalisée à la suite des débats entre les candidats au cours de la campagne présidentielle américaine 2008 : Lexical Analysis of 2008 US Presidential and Vice-Presidential Debates who's the Windbag ? : une rafale de nuages !!!!
On pourra ensuite tester Wordle, application en ligne qui permet de faire de jolis nuages de mots : "Wordle is a toy for generating word clouds from text that you provide. The clouds give greater prominence to words that appear more frequently in the source text. You can tweak your clouds with different fonts, layouts, and color schemes. The images you create with Wordle are yours to use however you like. You can print them out, or save them to the Wordle gallery to share with your friends".
Idem avec Tagcloud Generator
ou avec Word It Out

De la préparation du corpus de travail (issu des étapes d'automatisation) aux nuages !
Phase 1
Nuages de mots contextualisés avec le programme Le Trameur :
Le Trameur : Programme de génération puis de gestion de la Trame et du Cadre d'un texte (le métier Textométrique) pour construire des opérations lexicométriques / textométriques. Le Trameur intègre le programme treetagger : système d'étiquetage automatique des catégories grammaticales des mots avec lemmatisation.
Documentation : format PDF, format HTML
Ci-dessous, la documentation disponible en ligne via issuu :
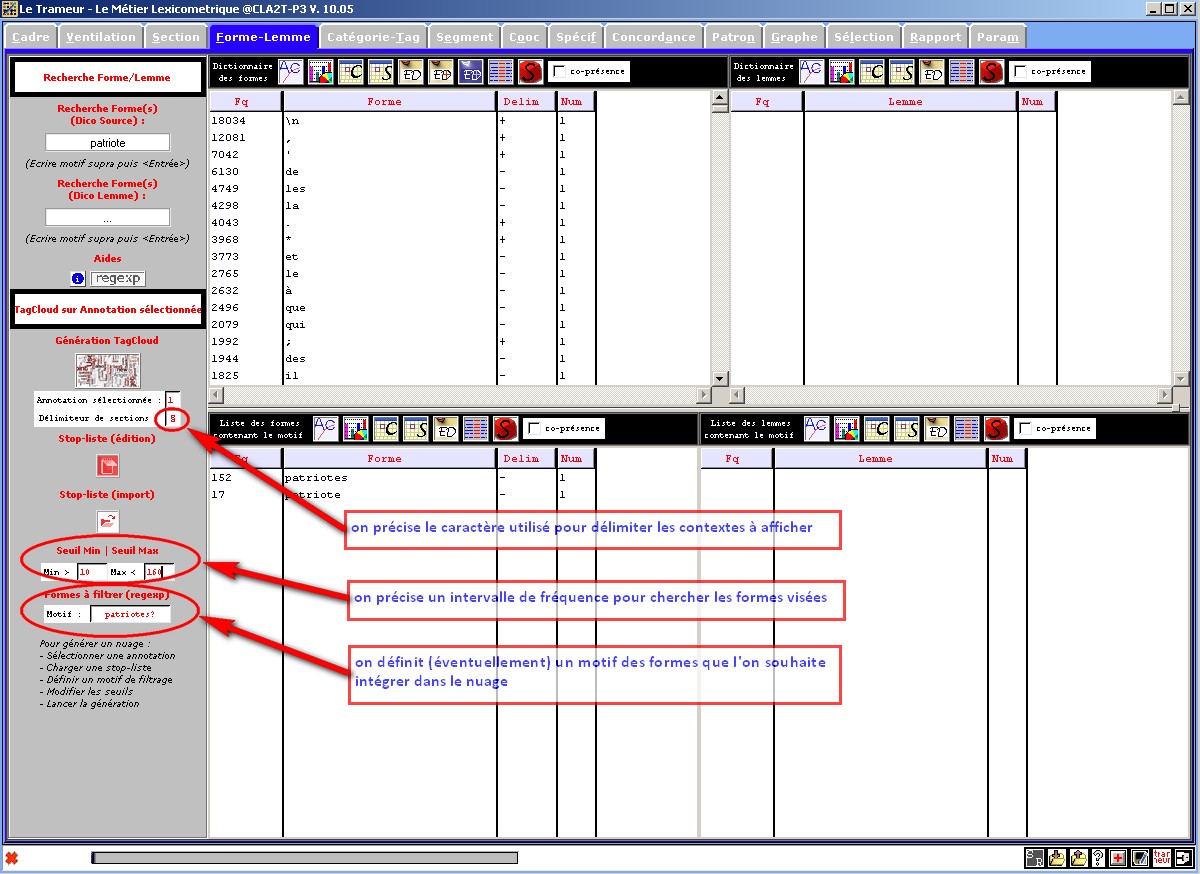
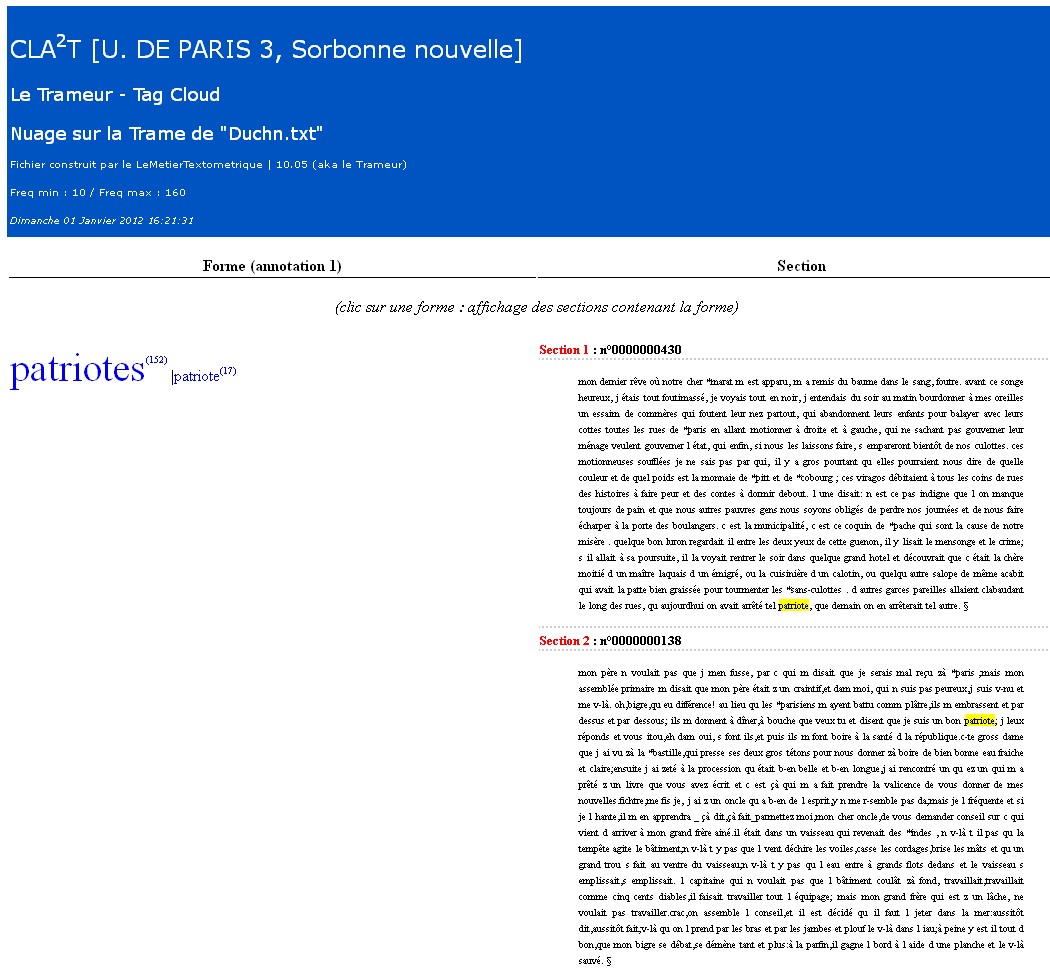
Après chargement du fichier de travail dans le programme (démonstration en cours), la figure qui suit illustre le mode d'emploi à suivre pour générer le nuages de mots. On travail ici sur "Le journal du Père Duchesne" et on s'intéresse aux occurrences de "patriote(s)"
Chargement du résultat dans le navigateur : les contextes sont visibles en cliquant sur un tag du nuage.
Lien vers la sortie produite (avec ici une recherche du motif "\bpatri|\baristo" ) : nuage "\bpatri|\baristo"
Vous pourrez mettre en oeuvre cette solution sur les fichiers construits dans la première étape du projet : fichiers DUMPS concaténés par exemple.
Phase 2
Dans ce qui suit nous utilisons les ressources construites par P. Marchal disponibles sur cette page. Plus précisément, nous désignerons par LE CORPUS la concaténation de l'ensemble des 28 textes en français de la colonne DUMPS de cette page. Le résultat de cette concaténation (UTF-8) a été transcodé dans un nouveau fichier (iso-8859-1) pour être soumis à 2 programmes (fournis par Philippe Gambette sur cette page) :
- TreeCloud, un programme pour créer des nuages de mots arborés (c'est à dire des nuages de mots disposés autour d'un arbre qui indique leur proximité dans le texte)
- TagCould Builder, un petit utilitaire pour créer des nuages de mots.
Lectures
- Lecture d'un arbre phylogénétique (Un arbre phylogénétique est un arbre de parenté, qui permet de déterminer les groupes frères...)
- L'arbre des prétendants (source : J. Véronis)
- L'arbre des thèmes (source : J. Véronis)
- L'arbre des politiques (source : J. Véronis)
- tag cloud + tag tree = nuage arboré (1) (source : Ph. Gambette)
- Base de données bibliographique sur les réseaux phylogénétiques (source : Ph. Gambette)
- Rapport de stage par Ph. Gambette sur l'optimisation de la représentation de graphes phylogénétiques dans le programme Splitstree (source : Ph. Gambette)
Utilisation de TagCould Builder
"Ce petit programme gratuit consiste à charger une liste de mots avec leur nombre d'occurrences dans un texte, fournie par exemple par l'utilitaire gratuit Dico de Jean Véronis".
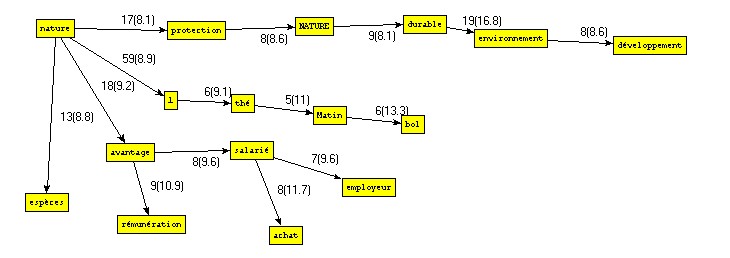
- Le résultat produit par TagCould est ici : le nuage NATURE
Utilisation de TreeCloud :
TreeCloud peut être utilisé en ligne ou en utilisant le logiciel TreeCloud après installation sur votre machine
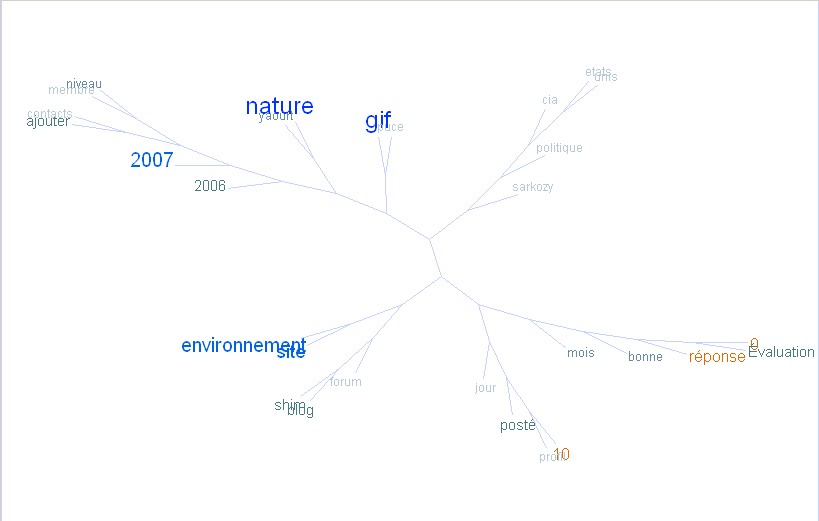
(Source)En décembre 2007, Jean Véronis a construit sur son blog un nuage de mots organisés en arbre pour refléter la proximité sémantique des mots à l'intérieur d'un corpus d'articles de presse.
Le programme ci-dessous, TreeCloud, est un prototype (à utiliser à vos risques et périls...) qui permet de construire de tels nuages arborés pour un texte quelconque. Les intérêts sont variés : visualisation rapide du contenu global d'un texte (rapport, livre...), analyse littéraire, comparaison de textes par comparaison de leurs nuages arborés. Pour en savoir plus, allez écouter ce diaporama (en anglais) ou voir celui-ci en français. A propos de l'utilisation en analyse littéraire, un exemple d'analyse comparative des pièces Cinna et Othon de Corneille, menée avec TreeCloud et Lexico3, est disponible dans cet article.
Si vous utilisez TreeCloud, merci de citer cette page ou bien :
Philippe Gambette, Jean Véronis : Visualising a Text with a Tree Cloud, IFCS'09 (matériel supplémentaire).
- Le fichier CORPUS précédent a d'abord été "nettoyé" : nouveau fichier sans délimiteur...
- Le résultat produit par TreeCloud est ici : le nuage arboré NATURE.
(via TreeCloud)
- Si on ne garde que les contextes contenant la forme "nature", on obtient : le nuage NATURE (via TagCould Builder), et le nuage arboré NATURE :
(via TreeCloud)Présentation de TreeCloud faite à Dresde (Allemagne) pour l'IFCS'2009 : Visualising a text with a tree cloud
Vous pourrez mettre en oeuvre cette solution sur les fichiers construits dans la première étape du projet : fichiers DUMPS concaténés par exemple.

Phase 3
Nous utilisons ci-dessous le programme Le Trameur :
Le Trameur : Programme de génération puis de gestion de la Trame et du Cadre d'un texte (le métier Textométrique) pour construire des opérations lexicométriques / textométriques. Le Trameur intègre le programme treetagger : système d'étiquetage automatique des catégories grammaticales des mots avec lemmatisation.
Documentation : format PDF, format HTML
Ci-dessous, la documentation disponible en ligne via issuu :
Après chargement du CORPUS (avec étiquetage) :
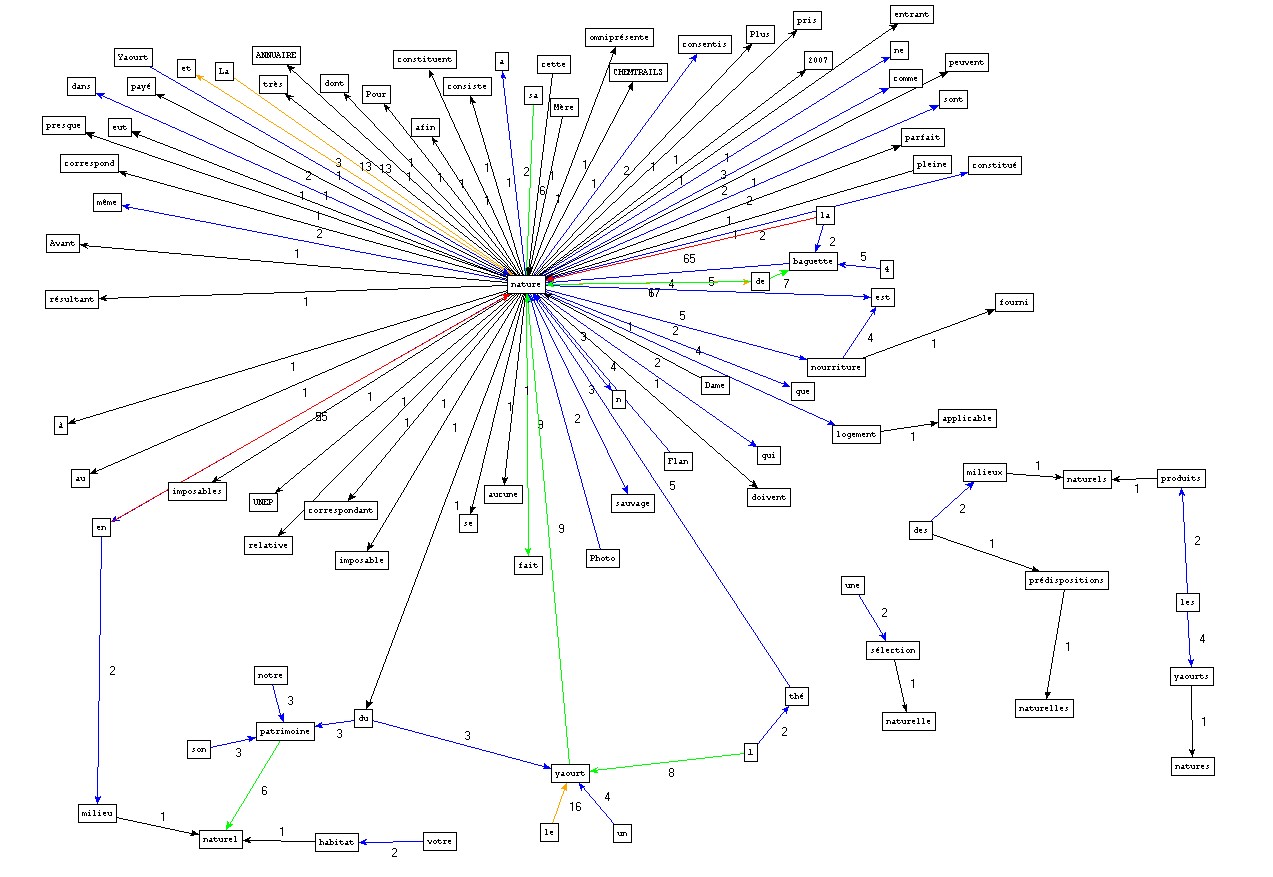
- on peut extraire par exemples des instances du patron ".* NOM .*" (i.e. les séquences de 3 termes dont le second est un NOM et dont les autres termes sont de nature quelconque) et contenant la forme "nature" (cf documentation):
- On peut aussi mettre au jour les cooccurrents puis les polycooccurrents (cf documentation) de la forme pôle "nature" :
(param 5 8)
(param 5 5)Une cooccurrence désigne lapparition de deux mots en même temps et dans le même contexte.
Le terme poly-cooccurrence désigne les attractions lexicales au-delà de la cooccurrence binaire.
Le module de poly-cooccurrences intégré dans Trameur reprend lalgorithme décrit dans [Martinez, 2006] :
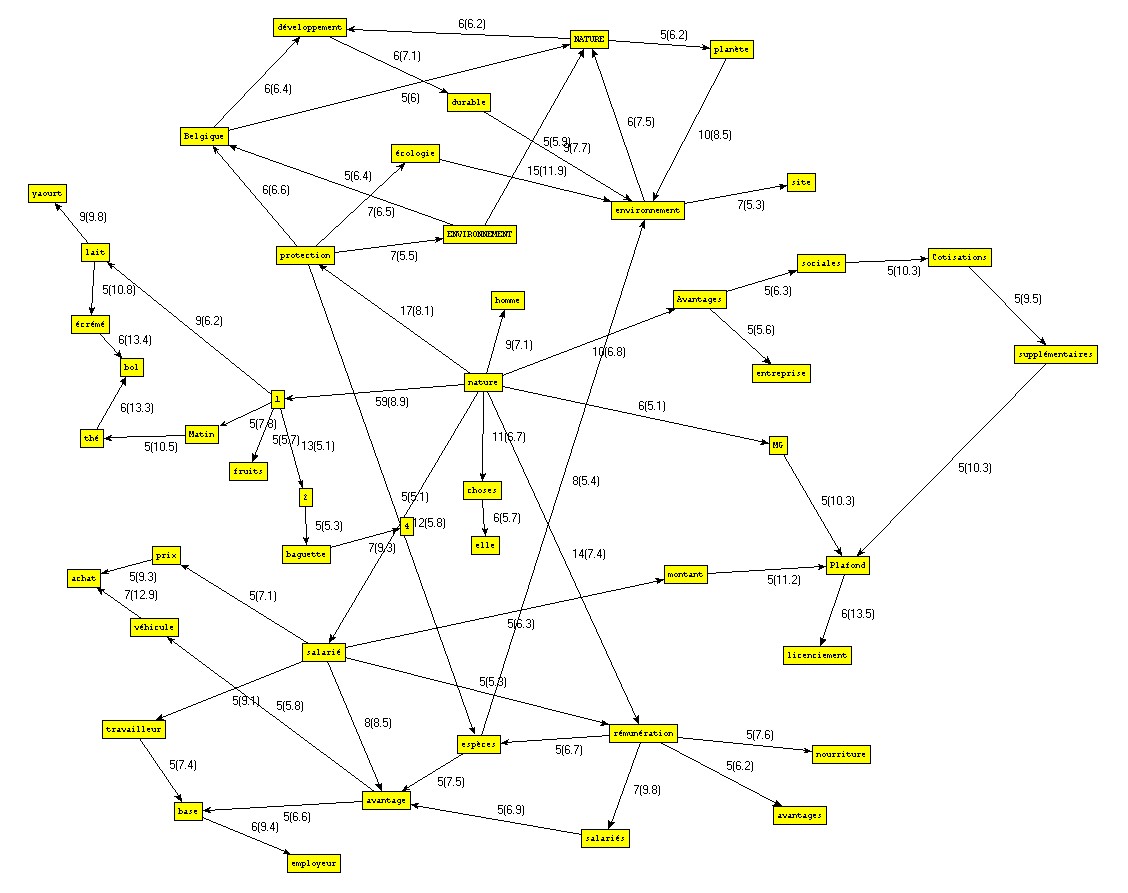
- On calcule pour le pôle A les cooccurrents spécifiques B, C et D
- Dans leurs contextes communs, on calcule pour les pôles A+B les cooccurrents spécifiques E et F
- Les pôles A+B+E ont pour cooccurrent spécifique H
- Les pôles A+B+E+H n'ont pas de cooccurrent spécifique et l'exploration s'interrompt pour ce chemin
- Les pôles A+B+F ont pour cooccurrents spécifiques I, etc.
- Durant lexploration, différents filtrages conditionnent l'épuisement des explorations contextuelles et réduisent le bruit dans les résultats pour privilégier linformation la plus spécifique : seuils maximaux de fréquence et de spécificité du cooccurrent.
[Martinez, Leblanc, 2006] William Martinez, Jean-Marc Leblanc. "L'analyse contrastive des réseaux de cooccurrence Le monde dans les discours des présidents de la Cinquième République", in Actes JADT2006, Journées Internationales d'Analyse Statistiques des Données Textuelles, Besançon.
Vous pourrez mettre en oeuvre cette solution sur les fichiers construits dans la première étape du projet : fichiers DUMPS concaténés par exemple.
Phase 4
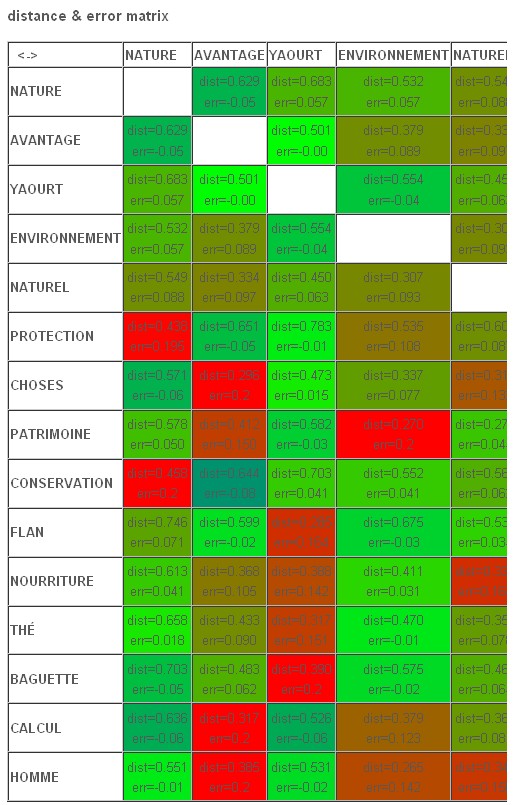
On pourra aussi regarder l'application en ligne Calculatrice Sémantique (développée par Hubert Wassner) qui permet de représenter des mini cartes sémantiques. Dans l'exemple qui suit, nous avons testé cette application sur une liste réduite de mots extraite du dictionnaire construit ci-dessus à partir des contextes de "nature".

Plurital 2011/2012. Cours
Projet Encadré.
J.M. Daube, S. Fleury, R. Belmouhoub. http://tal.univ-paris3.fr/plurital/