Traitements
Ici nous allons rappeler les principales étapes de la première partie de notre projet. Pour voir en détail l’avancement de ces parties, il faut plutôt aller consulter notre blog.
Les principales étapes du script
La structure générale du script se présente comme ceci :
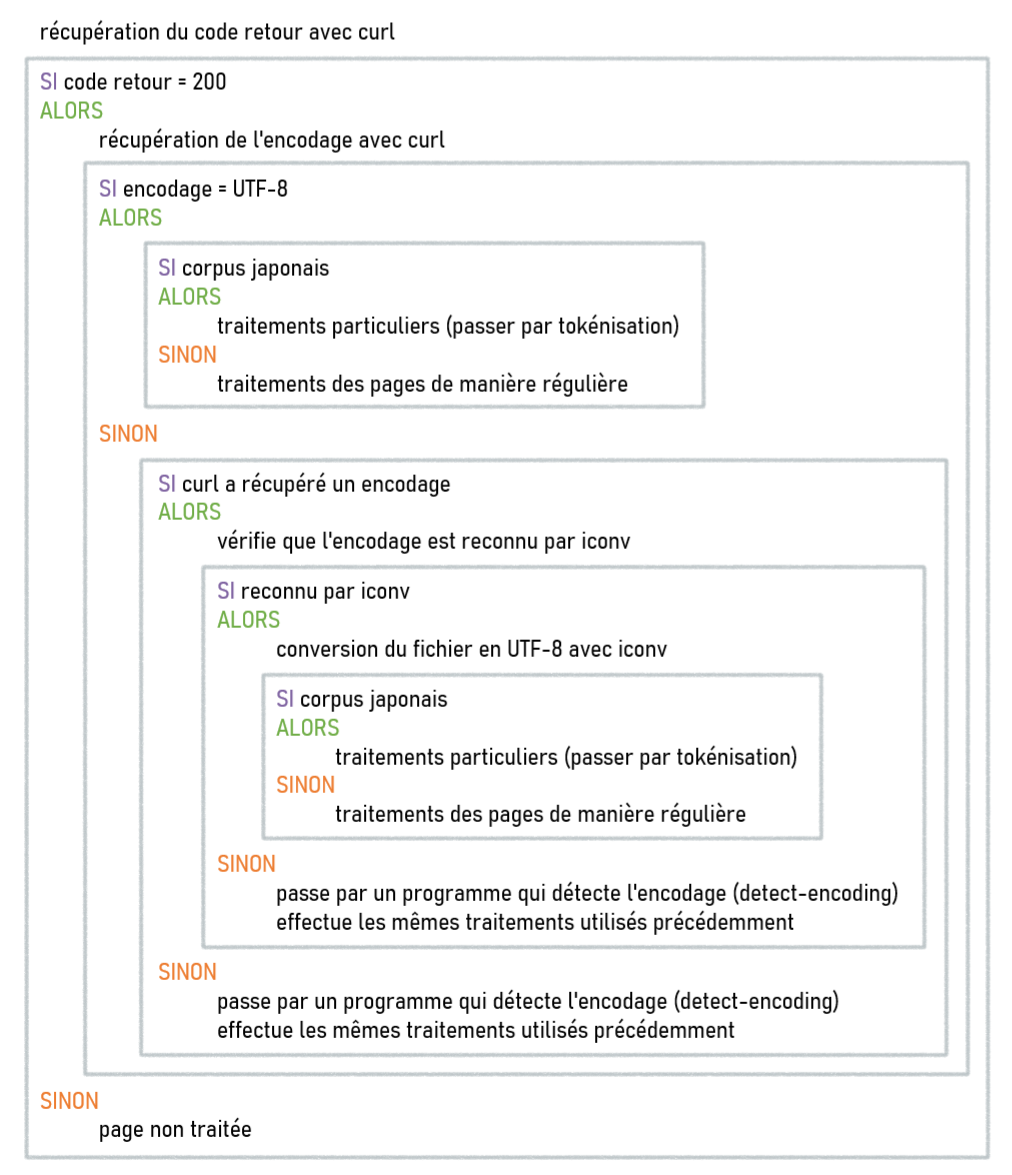
Comme vous pouvez le voir, certaines manipulations sont présentes plusieurs fois dans différentes parties du script. Ne maîtrisant pas très bien les fonctions en bash, nous avons décidé de diviser notre script de base en plusieurs scripts. En effet, nous avons placé les bouts de programme qui se répétaient dans des scripts à part, que nous appellerons depuis le script principal.
Notre « script final » est donc décomposé en 4 scripts :
Tous nos scripts sont disponibles ci-dessous:
Script principal
#!/usr/bin/bash
#
#----------------------------------------------------------------------
#---------------------------------------------------------------------
# MODE D'EMPLOI DU PROGRAMME :
# 1. on se place dans le dossier PROJET-MOT-SUR-LE-WEB
# 2. puis on lance le programme comme ceci :
# bash ./PROGRAMMES/projet_principal.sh ./URLS ./TABLEAUX/tableau.html "motif" (danc notre cas "trans|트랜스|トランス|性同一性障害")
# Le motif contient la chaîne de caractères correspondant aux mots choisis...
#---------------------------------------------------------------------
# input du programme : le nom du DOSSIER contenant les fichiers d'URLs est donné en premier argument
# output du programme : le nom du tableau HTML de sortie est donné en second argument
#----------------------------------------------------------------------
#----------------------------------------------------------------------
#
# PROGRAMME PRINCIPAL
#
#---------------------------------------------------------
#
# On récupère les arguments du programme et on les stocke dans des variables
dossierURL=$1;
montableau=$2;
motif=$3;
echo "<$dossierURL><$montableau><$motif>";
echo "C'est parti... return...";
#
#-----------------------------------------------------------------------
# Ecriture début du fichier HTML de sortie
echo "<html><head><meta charset=\"utf-8\" /></head><style>
body {
font-family:helvetica;
}
table {
border:3px solid #2d4059;
border-collapse:collapse;
width:95%;
margin:auto;
}
th {
font-family:helvetica;
border:1px dashed #2d4059;
padding:5px;
background-color:#d9ecf2;
text-align: center;
color: #2d4059;
}
td {
font-family:helvetica;
font-size:90%;
border:1px solid #2d4059;
padding:5px;
text-align:left;
text-align: center;
}
</style><body>" > $montableau ;
#
# Le compteur des fichiers d'URL et des tableaux associés
compteur_tableau=1;
#
# Parcours des fichiers d'urls contenus dans le dossiers URLS
for fichier in $(ls $dossierURL)
do
# Pour chaque fichier d'url, on va créé un nouveau tableau
echo $fichier;
echo "<table align=\"center\" border=\"6px\" bordercolor=\"#6a759b\">" >> $montableau;
compteur=1; # compteur d'URL
echo "<tr><th colspan=\"11\">TABLEAU $compteur_tableau</th></tr>" >> $montableau;
echo "<tr><th colspan=\"11\">MOTIF : $motif</th></tr>" >> $montableau;
echo "<tr><td>CPT</td><td>HTTP</td><td>Encodage</td><td>URL</td><td>P.A</td><td>DUMP</td><td>CPT MOTIF</td><td>Contextes txt</td><td>Contextes html</td><td>Index</td><td>bigrammes</td></tr>" >> $montableau;
#
# Puis lire ligne à ligne le fichier d'URL
while read ligne
do
#
# Chaque URL lue est traitée et permet de remplir le tableau HTML de sortie
echo "-----------------------------------------------------------";
echo "TRAITEMENT DE URL : $ligne";
#
# S'assurer que la commande curl se passe bien en créant une variable qui va récupérer la valeur http_code générée par curl
codeHttp=$(curl -A "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:83.0) Gecko/20100101 Firefox/83.0" -L -o ./PAGES-ASPIREES/"$compteur_tableau-$compteur".html $ligne -w %{http_code}) ;
#
# --------------------------------------------------------------------
# Tester la valeur de codeHttp
if [[ $codeHttp == 200 ]]
then
#---------------------------------------------------------
# Ici, le code retour est 200 donc nous pouvons effectuer le traitement de la page, selon son encodage
#---------------------------------------------------------
encodageURL=$(curl -L -I $ligne | egrep -i "charset" | cut -f2 -d= | tr [a-z] [A-Z] | tr -d "\r" | tr -d "\n" | tr -d "\"" | tr -d " ");
echo "<$encodageURL>";
# Test de l'encodage
if [[ $encodageURL == "UTF-8" ]]
then
#---------------------------------------------------------
# Ici l'encodage reconnu par curl est bon : UTF-8
#---------------------------------------------------------
#
echo "HTTP OK UTF8 ----------------------------------"
echo "<$compteur_tableau><$compteur><$ligne><$codeHttp><$encodageURL>";
#---------------------------------------------------------
# EFFECTUER LES 5 TRAITEMENTS
#---------------------------------------------------------
#
# 1ER TRAITEMENT : récupérer le contenu de la page
#
# via la commande lynx : ici on choisit de dumper la page aspirée...
lynx -dump -nolist -assume_charset="UTF-8" -display_charset="UTF-8" ./PAGES-ASPIREES/"$compteur_tableau-$compteur".html > ./DUMP-TEXT/utf8_"$compteur_tableau-$compteur".txt;
# Concaténation dans le corpus des dumps.
#
#---------------------------------------------------------
#
# 2EME TRAITEMENT : compter les occurrences du motif
#
compteurMotif=$(egrep -o -i $motif ./DUMP-TEXT/utf8_"$compteur_tableau-$compteur".txt | wc -l);
#
#---------------------------------------------------------
# Pour notre corpus, il faut passer par une étape de tokenization pour le japonais avec JANOME
#
# Vérifier si c'est le fichier japonais
if [[ $fichier == "japanese.txt" ]]
then
# Ce fichier en cours de traitement est en japonais
# Il nécessite un pré-traitement (tokénisation) donc on lance le script du traitement avec tokénisation (avec encodage récupéré par curl)
#
bash ./PROGRAMMES/projet_traitement_jap.sh $compteur_tableau $compteur $motif;
#---------------------------------------------------------
# ECRITURE DANS LE TABLEAU FINAL :
echo "<tr><td>$compteur</td>
<td><span style=\"background-color:#F4BBD3\">$codeHttp</span></td>
<td><span style=\"background-color:#F4BBD3\">$encodageURL</span><br/>via curl</td>
<td><a target=\"_blank\" href=\"$ligne\">$ligne</a></td>
<td><a href=\"../PAGES-ASPIREES/$compteur_tableau-$compteur.html\">P.A n°$compteur</a></td>
<td><a href=\"../DUMP-TEXT/jap_$compteur_tableau-$compteur.txt\">DUMP n°$compteur</a></td>
<td>$compteurMotif</td>
<td><a href=\"../CONTEXTES/utf8_$compteur_tableau-$compteur.txt\">contexte $compteur</a></td>
<td><a href=\"../CONTEXTES/$compteur_tableau-$compteur.html\">contexte $compteur</a></td>
<td><a href=\"../DUMP-TEXT/index_$compteur_tableau-$compteur.txt\">index $compteur</a></td>
<td><a href=\"../DUMP-TEXT/bigramme_$compteur_tableau-$compteur.txt\">bigramme $compteur</a></td>
<tr>" >> $montableau;
else
# Ce fichier en cours de traitement n'est pas en japonais
# Par conséquent, il ne nécessite pas de pré-traitement (tokénisation) donc on lance le script du traitement des fichiers (encodage récupéré par curl)
#
bash ./PROGRAMMES/projet_traitement.sh $compteur_tableau $compteur $motif;
#---------------------------------------------------------
# ECRITURE DANS LE TABLEAU FINAL :
echo "<tr><td>$compteur</td>
<td><span style=\"background-color:#F4BBD3\">$codeHttp</span></td>
<td><span style=\"background-color:#F4BBD3\">$encodageURL</span><br/>via curl</td>
<td><a target=\"_blank\" href=\"$ligne\">$ligne</a></td>
<td><a href=\"../PAGES-ASPIREES/$compteur_tableau-$compteur.html\">P.A n°$compteur</a></td>
<td><a href=\"../DUMP-TEXT/utf8_$compteur_tableau-$compteur.txt\">DUMP n°$compteur</a></td>
<td>$compteurMotif</td>
<td><a href=\"../CONTEXTES/utf8_$compteur_tableau-$compteur.txt\">contexte $compteur</a></td>
<td><a href=\"../CONTEXTES/$compteur_tableau-$compteur.html\">contexte $compteur</a></td>
<td><a href=\"../DUMP-TEXT/index_$compteur_tableau-$compteur.txt\">index $compteur</a></td>
<td><a href=\"../DUMP-TEXT/bigramme_$compteur_tableau-$compteur.txt\">bigramme $compteur</a></td>
<tr>" >> $montableau;
fi
#---------------------------------------------------------
else
if [[ $encodageURL != "" ]]
then
#---------------------------------------------------------
# Ici, le code retour est bien 200 mais l'encodage récupéré par curl n'est pas UTF-8
#---------------------------------------------------------
echo "HTTP OK mais encodage pas en UTF8 ----------------------------------"
echo "<$compteur_tableau><$compteur><$ligne><$codeHttp><$encodageURL>";
reponse=$(iconv -l | egrep "$encodageURL") ;
if [[ $reponse != "" ]]
then
#---------------------------------------------------------
# L'encodage récupéré par curl est connu par iconv
# Donc il suffit de faire les traitements en générant de l'UTF-8 (via iconv : convertir l'encodage)
#---------------------------------------------------------
#
# 1E TRAITEMENT : récupérer le contenu de la page
lynx -dump -nolist -assume-charset=$encodageURL -display-charset=$encodageURL ./PAGES-ASPIREES/"$compteur_tableau-$compteur".html > ./DUMP-TEXT/not_utf8_"$compteur_tableau-$compteur".txt;
#
# TRAITEMENT INTERMEDIAIRE : CONVERSION D'ENCODAGE
iconv -f $encodageURL -t UTF-8 ./DUMP-TEXT/not_utf8_"$compteur_tableau-$compteur".txt > ./DUMP-TEXT/utf8_"$compteur_tableau-$compteur".txt ;
#
# 2EME TRAITEMENT : compter les occurrences du motif
compteurMotif=$(egrep -o -i $motif ./DUMP-TEXT/utf8_"$compteur_tableau-$compteur".txt | wc -l);
#
if [[ $fichier == "japanese.txt" ]]
then
# Ce fichier en cours de traitement est en japonais
# Il nécessite un pré-traitement (tokénisation) donc on lance le script du traitement avec tokénisation (avec encodage récupéré par curl)
#
bash ./PROGRAMMES/projet_traitement_jap.sh $compteur_tableau $compteur $motif;
#---------------------------------------------------------
# ECRITURE DANS LE TABLEAU FINAL :
echo "<tr><td>$compteur</td>
<td><span style=\"background-color:#c3aed6\">$codeHttp</span></td>
<td><span style=\"background-color:#c3aed6\">$encodageURL</span><br/>via curl</td>
<td><a target=\"_blank\" href=\"$ligne\">$ligne</a></td>
<td><a href=\"../PAGES-ASPIREES/$compteur_tableau-$compteur.html\">P.A n°$compteur</a></td>
<td><a href=\"../DUMP-TEXT/jap_$compteur_tableau-$compteur.txt\">DUMP n°$compteur</a></td>
<td>$compteurMotif</td>
<td><a href=\"../CONTEXTES/utf8_$compteur_tableau-$compteur.txt\">contexte $compteur</a></td>
<td><a href=\"../CONTEXTES/$compteur_tableau-$compteur.html\">contexte $compteur</a></td>
<td><a href=\"../DUMP-TEXT/index_$compteur_tableau-$compteur.txt\">index $compteur</a></td>
<td><a href=\"../DUMP-TEXT/bigramme_$compteur_tableau-$compteur.txt\">bigramme $compteur</a></td>
<tr>" >> $montableau;
else
# Ce fichier en cours de traitement n'est pas en japonais
# Par conséquent, il ne nécessite pas de pré-traitement (tokénisation) donc on lance le script du traitement des fichiers (encodage récupéré par curl)
#
bash ./PROGRAMMES/projet_traitement.sh $compteur_tableau $compteur $motif;
#---------------------------------------------------------
# ECRITURE DANS LE TABLEAU FINAL :
echo "<tr><td>$compteur</td>
<td><span style=\"background-color:#c3aed6\">$codeHttp</span></td>
<td><span style=\"background-color:#c3aed6\">$encodageURL</span><br/>via curl</td>
<td><a target=\"_blank\" href=\"$ligne\">$ligne</a></td>
<td><a href=\"../PAGES-ASPIREES/$compteur_tableau-$compteur.html\">P.A n°$compteur</a></td>
<td><a href=\"../DUMP-TEXT/utf8_$compteur_tableau-$compteur.txt\">DUMP n°$compteur</a></td>
<td>$compteurMotif</td>
<td><a href=\"../CONTEXTES/utf8_$compteur_tableau-$compteur.txt\">contexte $compteur</a></td>
<td><a href=\"../CONTEXTES/$compteur_tableau-$compteur.html\">contexte $compteur</a></td>
<td><a href=\"../DUMP-TEXT/index_$compteur_tableau-$compteur.txt\">index $compteur</a></td>
<td><a href=\"../DUMP-TEXT/bigramme_$compteur_tableau-$compteur.txt\">bigramme $compteur</a></td>
<tr>" >> $montableau;
fi
#---------------------------------------------------------
else
#---------------------------------------------------------
# L'encodage récupéré par curl n'est pas connu de iconv
# Mais peut-on tout de même l'extraire dans la page aspirée ?
#---------------------------------------------------------
# On lance le script qui permet de récupérer l'encodage par extract-decoding
#
bash ./PROGRAMMES/projet_detect_encoding_script.sh $compteur_tableau $compteur $motif $fichier $codeHttp $ligne $montableau $compteurMotif;
fi
#---------------------------------------------------------
else
#---------------------------------------------------------
# Ici, le code retour est bien 200 mais l'encodage récupéré par curl est vide
# Mais peut-on tout de même l'extraire dans la page aspirée ?
# Nous essayons une nouvelle fois de récupérer l'encodage avec extract-decoding
#---------------------------------------------------------
# On lance le script qui permet de récupérer l'encodage par extract-decoding
#
bash ./PROGRAMMES/projet_detect_encoding_script.sh $compteur_tableau $compteur $motif $fichier $codeHttp $ligne $montableau $compteurMotif;
fi
#---------------------------------------------------------
fi
#---------------------------------------------------------
else
#---------------------------------------------------------
# Ici, le code retour n'est 200
# Nous ne traitons pas la page
#---------------------------------------------------------
# ECRITURE DANS LE TABLEAU FINAL : RIEN
echo "PB HTTP ----------------------------------"
echo "<$compteur_tableau><$compteur><$ligne><$codeHttp>";
echo "<tr><td>$compteur</td><td>$codeHttp</td><td>-</td>
<td><a target=\"_blank\" href=\"$ligne\">$ligne</a></td>
<td>-</td><td>-</td><td>-</td><td>-</td><td>-</td><td>-</td><td>-</td><tr>" >> $montableau;
fi
#---------------------------------------------------------------------
# On passe au fichier (donc à la ligne) suivante
#
compteur=$((compteur + 1)); # On incrémente le compteur d'URLs
done < $dossierURL/$fichier # ATTENTION AU CHEMIN pour le fichier d'URL
#---------------------------------------------------------------------
# Fin de la boucle while :
# On a atteint la fin du fichier d'urls
#
echo "</table>" >> $montableau; # On ferme de tableau
echo "<p><br><hr color=\"#d9ecf2\"><br></p>" >> $montableau;
compteur_tableau=$((compteur_tableau + 1)); # On incrémente le compteur de tableau
#---------------------------------------------------------------------
# Fin de la boucle for :
# Si le fichier courant n'est pas le dernier du répertoire URLS, on passe au prochain fichier
#
done
#
# Fin des traitements, on finit la sortie HTML
#
echo "</body></html>" >> $montableau;
#
#
#----------------------------------------------------------------------
#
# FIN DU PROGRAMME PRINCIPAL
#
#----------------------------------------------------------------------
Script detect-encoding
#!/usr/bin/bash
#
#----------------------------------------------------------------------
#---------------------------------------------------------------------
# MODE D'EMPLOI DU PROGRAMME : PROGRAMME qui traite les pages selon l'encodage trouvé avec detect-encoding
# on lance le programme comme ceci :
# bash ./PROGRAMMES/projet_detect_encoding_script.sh $compteur_tableau $compteur $motif $fichier $codeHttp $ligne $montableau $compteurMotif
#----------------------------------------------------------------------
#----------------------------------------------------------------------
#
# On récupère les arguments du programme principal et on les stocke dans des variables
compteur_tableau=$1;
compteur=$2;
motif=$3;
fichier=$4;
codeHttp=$5;
ligne=$6;
montableau=$7;
compteurMotif=$8;
#
#----------------------------------------------------------------------
#
# PROGRAMME AVEC ENCODAGE EXTRAIT PAR DETECT-ENCODING
#
#----------------------------------------------------------------------
#
# Exécution du programme perl "detect-encoding.pl" : Récupération de l'encodage
encodageExtrait=$(perl ./PROGRAMMES/detect-encoding.pl ./PAGES-ASPIREES/"$compteur_tableau-$compteur".html | tr -d "\n" | tr -d "\r");
echo "ENCODAGE EXTRAIT : $encodageExtrait";
reponse=$(iconv -l | egrep "$encodageExtrait") ;
if [[ $reponse != "" ]]
then
#---------------------------------------------------------
# Ici, l'encodage est bon (reconnu par iconv) donc il suffit de faire les traitements en générant de l'UTF-8 si besoin
#---------------------------------------------------------
#
# 1E TRAITEMENT : récupérer le contenu de la page
lynx -dump -nolist -assume-charset=$encodageExtrait -display-charset=$encodageExtrait ./PAGES-ASPIREES/"$compteur_tableau-$compteur".html > ./DUMP-TEXT/encoding_"$compteur_tableau-$compteur".txt;
#
if [[ $encodageExtrait == "UTF-8" ]]
then
#---------------------------------------------------------
# L'encodage récupéré est bien UTF-8 donc pas besoin d'utiliser iconv
#---------------------------------------------------------
# On renomme le fichier DUMP pour uniformiser les données
mv ./DUMP-TEXT/encoding_"$compteur_tableau-$compteur".txt ./DUMP-TEXT/utf8_"$compteur_tableau-$compteur".txt ;
#
# 2EME TRAITEMENT : compter les occurrences du motif
compteurMotif=$(egrep -o -i $motif ./DUMP-TEXT/utf8_"$compteur_tableau-$compteur".txt | wc -l);
#
# Pour notre corpus, il faut passer par une étape de tokenization pour le japonais avec JANOME
# Donc nous vérifions si le fichier courant est le fichier japonais
#
if [[ $fichier == "japanese.txt" ]]
then
# Ce fichier en cours de traitement est en japonais
# Il nécessite un pré-traitement (tokénisation) donc on lance le script du traitement avec tokénisation
# des fichiers dont l'encodage a été récupéré par detect-encoding
#
bash ./PROGRAMMES/projet_traitement_jap.sh $compteur_tableau $compteur $motif;
#---------------------------------------------------------
# ECRITURE DANS LE TABLEAU FINAL :
echo "<tr><td>$compteur</td>
<td><span style=\"background-color:#AED4E6\">$codeHttp</span></td>
<td><span style=\"background-color:#AED4E6\">$encodageExtrait</span><br/>via detect</td>
<td><a target=\"_blank\" href=\"$ligne\">$ligne</a></td>
<td><a href=\"../PAGES-ASPIREES/$compteur_tableau-$compteur.html\">P.A n°$compteur</a></td>
<td><a href=\"../DUMP-TEXT/jap_$compteur_tableau-$compteur.txt\">DUMP n°$compteur</a></td>
<td>$compteurMotif</td>
<td><a href=\"../CONTEXTES/utf8_$compteur_tableau-$compteur.txt\">contexte $compteur</a></td>
<td><a href=\"../CONTEXTES/$compteur_tableau-$compteur.html\">contexte $compteur</a></td>
<td><a href=\"../DUMP-TEXT/index_$compteur_tableau-$compteur.txt\">index $compteur</a></td>
<td><a href=\"../DUMP-TEXT/bigramme_$compteur_tableau-$compteur.txt\">bigramme $compteur</a></td>
<tr>" >> $montableau;
else
# Ce fichier en cours de traitement n'est pas en japonais
# Par conséquent, il ne nécessite pas de pré-traitement (tokénisation) donc on lance le script du traitement des fichiers
# dont l'encodage a été récupéré par detect-encoding
#
bash ./PROGRAMMES/projet_traitement.sh $compteur_tableau $compteur $motif;
#---------------------------------------------------------
# ECRITURE DANS LE TABLEAU FINAL :
echo "<tr><td>$compteur</td>
<td><span style=\"background-color:#AED4E6\">$codeHttp</span></td>
<td><span style=\"background-color:#AED4E6\">$encodageExtrait</span><br/>via detect</td>
<td><a target=\"_blank\" href=\"$ligne\">$ligne</a></td>
<td><a href=\"../PAGES-ASPIREES/$compteur_tableau-$compteur.html\">P.A n°$compteur</a></td>
<td><a href=\"../DUMP-TEXT/utf8_$compteur_tableau-$compteur.txt\">DUMP n°$compteur</a></td>
<td>$compteurMotif</td>
<td><a href=\"../CONTEXTES/utf8_$compteur_tableau-$compteur.txt\">contexte $compteur</a></td>
<td><a href=\"../CONTEXTES/$compteur_tableau-$compteur.html\">contexte $compteur</a></td>
<td><a href=\"../DUMP-TEXT/index_$compteur_tableau-$compteur.txt\">index $compteur</a></td>
<td><a href=\"../DUMP-TEXT/bigramme_$compteur_tableau-$compteur.txt\">bigramme $compteur</a></td>
<tr>" >> $montableau;
fi
#---------------------------------------------------------
else
#---------------------------------------------------------
# Ici, l'encodage extrait avec detect-encoding n'est pas de l'UTF-8.
# Il faut donc employer iconv pour générer de l'UTF-8
#---------------------------------------------------------
iconv -f $encodageExtrait -t UTF-8 ./DUMP-TEXT/encoding_"$compteur_tableau-$compteur".txt > ./DUMP-TEXT/utf8_"$compteur_tableau-$compteur".txt ;
#---------------------------------------------------------
# 2EME TRAITEMENT : compter les occurrences du motif
compteurMotif=$(egrep -o -i $motif ./DUMP-TEXT/utf8_"$compteur_tableau-$compteur".txt | wc -l);
#
# Pour notre corpus, il faut passer par une étape de tokenization pour le japonais avec JANOME
# Donc nous vérifions si le fichier courant est le fichier japonais
#
if [[ $fichier == "japanese.txt" ]]
then
# Ce fichier en cours de traitement est en japonais
# Il nécessite un pré-traitement (tokénisation) donc on lance le script du traitement avec tokénisation
# des fichiers dont l'encodage a été récupéré par detect-encoding
#
bash ./PROGRAMMES/projet_traitement_jap.sh $compteur_tableau $compteur $motif;
#---------------------------------------------------------
# ECRITURE DANS LE TABLEAU FINAL :
echo "<tr><td>$compteur</td>
<td><span style=\"background-color:#AED4E6\">$codeHttp</span></td>
<td><span style=\"background-color:#AED4E6\">$encodageExtrait</span><br/>via detect</td>
<td><a target=\"_blank\" href=\"$ligne\">$ligne</a></td>
<td><a href=\"../PAGES-ASPIREES/$compteur_tableau-$compteur.html\">P.A n°$compteur</a></td>
<td><a href=\"../DUMP-TEXT/jap_$compteur_tableau-$compteur.txt\">DUMP n°$compteur</a></td>
<td>$compteurMotif</td>
<td><a href=\"../CONTEXTES/utf8_$compteur_tableau-$compteur.txt\">contexte $compteur</a></td>
<td><a href=\"../CONTEXTES/$compteur_tableau-$compteur.html\">contexte $compteur</a></td>
<td><a href=\"../DUMP-TEXT/index_$compteur_tableau-$compteur.txt\">index $compteur</a></td>
<td><a href=\"../DUMP-TEXT/bigramme_$compteur_tableau-$compteur.txt\">bigramme $compteur</a></td>
<tr>" >> $montableau;
else
# Ce fichier en cours de traitement n'est pas en japonais
# Par conséquent, il ne nécessite pas de pré-traitement (tokénisation) donc on lance le script du traitement des fichiers
# dont l'encodage a été récupéré par detect-encoding
#
bash ./PROGRAMMES/projet_traitement.sh $compteur_tableau $compteur $motif;
#---------------------------------------------------------
# ECRITURE DANS LE TABLEAU FINAL :
echo "<tr><td>$compteur</td>
<td><span style=\"background-color:#AED4E6\">$codeHttp</span></td>
<td><span style=\"background-color:#AED4E6\">$encodageExtrait</span><br/>via detect</td>
<td><a target=\"_blank\" href=\"$ligne\">$ligne</a></td>
<td><a href=\"../PAGES-ASPIREES/$compteur_tableau-$compteur.html\">P.A n°$compteur</a></td>
<td><a href=\"../DUMP-TEXT/utf8_$compteur_tableau-$compteur.txt\">DUMP n°$compteur</a></td>
<td>$compteurMotif</td>
<td><a href=\"../CONTEXTES/utf8_$compteur_tableau-$compteur.txt\">contexte $compteur</a></td>
<td><a href=\"../CONTEXTES/$compteur_tableau-$compteur.html\">contexte $compteur</a></td>
<td><a href=\"../DUMP-TEXT/index_$compteur_tableau-$compteur.txt\">index $compteur</a></td>
<td><a href=\"../DUMP-TEXT/bigramme_$compteur_tableau-$compteur.txt\">bigramme $compteur</a></td>
<tr>" >> $montableau;
fi
#---------------------------------------------------------
fi
#---------------------------------------------------------
else
# L'encodage trouvé avec detect-encoding n'est pas connu de iconv
# ==> On ne lance pas les traitements et affichage des résultats vides dans la tableau
#---------------------------------------------------------
# ECRITURE DANS LE TABLEAU FINAL : on ne peut rien faire...
echo "<tr><td>$compteur</td>
<td><span style=\"background-color:lightgrey\">$codeHttp</span></td>
<td><span style=\"background-color:lightgrey\">$encodageExtrait</span></td>
<td><a target=\"_blank\" href=\"$ligne\">$ligne</a></td>
<td><a href=\"../PAGES-ASPIREES/$compteur_tableau-$compteur.html\">P.A n°$compteur</a></td>
<td>-</td><td>-</td><td>-</td><td>-</td><td>-</td><td>-</td>
<tr>" >> $montableau;
#---------------------------------------------------------
fi
#
#
#----------------------------------------------------------------------
#
# FIN DU PROGRAMME AVEC ENCODAGE EXTRAIT PAR DETECT-ENCODING
#
#----------------------------------------------------------------------
Script traitement du corpus japonais
#!/usr/bin/bash
#
#---------------------------------------------------------------------
#---------------------------------------------------------------------
# MODE D'EMPLOI DU PROGRAMME : TRAITEMENT des pages du corpus japonais
# on lance le programme comme ceci :
# bash ./PROGRAMMES/projet_traitement_jap.sh $compteur_tableau $compteur $motif
#----------------------------------------------------------------------
#----------------------------------------------------------------------
#
# On récupère les arguments du programme parent
# et on les stocke dans des variables
compteur_tableau=$1;
compteur=$2;
motif=$3;
#
#
#---------------------------------------------------------
#
# TRAITEMENT INTERMEDIAIRE (VERSION JAPONAIS) : tokenisation avec lancement du script Python
#
python3 ./PROGRAMMES/script_jp.py ./DUMP-TEXT/utf8_"$compteur_tableau-$compteur".txt ./DUMP-TEXT/jap_"$compteur_tableau-$compteur".txt;
#
#---------------------------------------------------------
#
#
# SUITE DES TRAITEMENTS : Contextes, Index hiérarchique, Bigramme
#
#
#---------------------------------------------------------
#
# 3EME TRAITEMENT : extraire des contextes réduits au motif (1 ligne avant et 1 ligne après)
# 2 méthodes : egrep + mingrep
#
# 1. construire des morceaux de corpus
egrep -C 2 -i "$motif" ./DUMP-TEXT/jap_"$compteur_tableau-$compteur".txt > ./CONTEXTES/utf8_"$compteur_tableau-$compteur".txt;
#
# 2. donner à voir ces contextes au format HTML
perl ./PROGRAMMES/minigrepmultilingue-v2.2-regexp/minigrepmultilingue.pl "UTF-8" ./DUMP-TEXT/jap_"$compteur_tableau-$compteur".txt ./PROGRAMMES/minigrepmultilingue-v2.2-regexp/motif-2020.txt ;
# attention il faut "sauvegarder" le résultat
mv resultat-extraction.html ./CONTEXTES/"$compteur_tableau-$compteur".html;
#
#---------------------------------------------------------
#
# 4EME TRAITEMENT : index hiérarchique de chaque DUMP (commande déjà vue en cours)
egrep -i -o "\w+" ./DUMP-TEXT/jap_"$compteur_tableau-$compteur".txt | sort | uniq -c | sort -r -n -s -k 1,1 > ./DUMP-TEXT/index_"$compteur_tableau-$compteur".txt ;
#
# IMPORTANT : regardez bien les critères de tri du dernier SORT (cf https://superuser.com/questions/33362/how-to-unix-sort-by-one-column-only)
#
#---------------------------------------------------------
#
# 5EME TRAITEMENT : calcul de bigramme (séquence de 2 mots consécutifs)
tr " " "\n" < ./DUMP-TEXT/jap_"$compteur_tableau-$compteur".txt | tr -s "\n" | egrep -v "^$" > index1.txt ;
tail -n +2 index1.txt > index2.txt;
paste index1.txt index2.txt | sort | uniq -c | sort -r -n -s -k 1,1 -r > ./DUMP-TEXT/bigramme_"$compteur_tableau-$compteur".txt ;
#
#----------------------------------------------------------------------
#
# FIN DES TRAITEMENTS (3 à 5) (VERSION JAPONAIS)
#
#----------------------------------------------------------------------
Script traitement des autres corpus
#!/usr/bin/bash
#
#---------------------------------------------------------------------
#---------------------------------------------------------------------
# MODE D'EMPLOI DU PROGRAMME : TRAITEMENT des pages du corpus (autre que japonais)
# on lance le programme comme ceci :
# bash ./PROGRAMMES/projet_traitement.sh $compteur_tableau $compteur $motif
#----------------------------------------------------------------------
#----------------------------------------------------------------------
#
# On récupère les arguments du programme parent
# et on les stocke dans des variables
compteur_tableau=$1;
compteur=$2;
motif=$3;
#
#---------------------------------------------------------
#
#
# SUITE DES TRAITEMENTS : Contextes, Index hiérarchique, Bigramme
#
#
#---------------------------------------------------------
#
# 3EME TRAITEMENT : extraire des contextes réduits au motif (1 ligne avant et 1 ligne après)
# 2 méthodes : egrep + mingrep
#
# 1. construire des morceaux de corpus
egrep -C 2 -i "$motif" ./DUMP-TEXT/utf8_"$compteur_tableau-$compteur".txt > ./CONTEXTES/utf8_"$compteur_tableau-$compteur".txt;
#
# 2. donner à voir ces contextes au format HTML
perl ./PROGRAMMES/minigrepmultilingue-v2.2-regexp/minigrepmultilingue.pl "UTF-8" ./DUMP-TEXT/utf8_"$compteur_tableau-$compteur".txt ./PROGRAMMES/minigrepmultilingue-v2.2-regexp/motif-2020.txt ;
# attention il faut "sauvegarder" le résultat
mv resultat-extraction.html ./CONTEXTES/"$compteur_tableau-$compteur".html;
#
#---------------------------------------------------------
#
# 4EME TRAITEMENT : index hiérarchique de chaque DUMP (commande déjà vue en cours)
egrep -i -o "\w+" ./DUMP-TEXT/utf8_"$compteur_tableau-$compteur".txt | sort | uniq -c | sort -r -n -s -k 1,1 > ./DUMP-TEXT/index_"$compteur_tableau-$compteur".txt ;
#
# IMPORTANT : regardez bien les critères de tri du dernier SORT (cf https://superuser.com/questions/33362/how-to-unix-sort-by-one-column-only)
#
#---------------------------------------------------------
#
# 5EME TRAITEMENT : calcul de bigramme (séquence de 2 mots consécutifs)
tr " " "\n" < ./DUMP-TEXT/utf8_"$compteur_tableau-$compteur".txt | tr -s "\n" | egrep -v "^$" > index1.txt ;
tail -n +2 index1.txt > index2.txt;
paste index1.txt index2.txt | sort | uniq -c | sort -r -n -s -k 1,1 -r > ./DUMP-TEXT/bigramme_"$compteur_tableau-$compteur".txt ;
#
#----------------------------------------------------------------------
#
# FIN DES TRAITEMENTS (3 à 5)
#
#----------------------------------------------------------------------
Le cas du japonais
Comme expliqué dans le blog, le japonais a demandé une étape supplémentaire par rapport aux autres langues lors du traitement: celle de la tokenisation, car le japonais ne possède pas d’espace.
Nous n’allons pas revenir en détail là dessus, vu que le processus a d’ores et déjà été expliqué dans le blog; néanmoins nous n’avions pas montré le script final, modifié pour être intégré dans le script principal. Le voici donc:
Script janome pour tokeniser
#!/usr/bin/env python 3
#Coding: UTF-8
#Python Janome
#Pour utiliser des arguments
import sys
#Import du tokenizer janome
from janome.tokenizer import Tokenizer
t = Tokenizer()
chemin = str(sys.argv[1])
#En entrée, le fichier du texte à segmenter
entree = open(sys.argv[1], 'r', encoding='UTF-8')
#En sortie, le fichier qui va contenir le texte segmenté
sortie = open(sys.argv[2], 'w', encoding='UTF-8')
for token in t.tokenize(entree.read(), wakati=True):
sortie.write(token + ' ')
La modification réside dans le remplacement des ouvertures de fichiers: au lieu d’entrer un nom de fichier en particulier, nous faisons appel à des arguments, matérialisés par sys.argv[1] et sys.argv[2], respectivement le fichier d’entrée et de sortie. A noter qu’il faut importer la librairie sys pour pouvoir utiliser ces arguments. Faire ceci nous permet donc de faire fonctionner le script pour n’importe quel texte sans avoir à modifier le programme à chaque fois.
Présentation des résultats
Le graphique ci-dessous résume le résultat de la récupération des URLs de nos corpus. Il suffit de passer la souris sur chaque part pour avoir le nombre exact d'URLs. Pour plus de détail lien par lien, il faut plutôt regarder le tableau html.
Difficultées rencontrées
Malgré l’utilisation d’options ajoutées à la commande curl, plusieurs pages ne sont pas du tout traitées car le code retour ne correspond toujours pas à 200.
Certaines pages, dont le code retour est bien 200, ne sont toujours pas récupérées. Leurs données sont sûrement très bien protégées (par exemple, le site du washingtonpost).
Des pages en coréen affichent un encodage en UTF-8. Les traitements sont réalisés sans problème mais l’affichage du DUMP TEXT, depuis le tableau, ne se fait pas correctement (n° 16 et 35). Cela est très bizarre vu que dans les contextes, les index et les bigrammes (issus du DUMP TEXT), les caractères coréen sont parfaitement affichés.
Néanmoins, le nombre de pages n’ayant pas pu être récupérées ni traitées reste minime par rapport au ratio du corpus entier : environ 10 pages sur 200.