LE TRAMEUR
Le Trameur est
Programme de génération puis de gestion de la Trame et du Cadre d’un texte (i.e découpage en unité et partitionnement du texte : le métier textométrique) pour des opérations textométriques (ventilation des unités, carte des sections, cooccurrence, spécificité, AFC...). (Serge FLEURY)
Dans cette partie, nous nous servons du Trameur pour faire une exploration textométique de nos corpus ; d’ailleurs, certaines sont réalisées à l’aide de iTrameur, version en ligne.
Le détail d’analyses est intégré dans la partie RÉSULTATS pour que notre étude soit structurée et complète.
Le travail sur chaque langue est organisée par l’ordre suivant :
- Principes caractérisques lexicométriques de corpus :
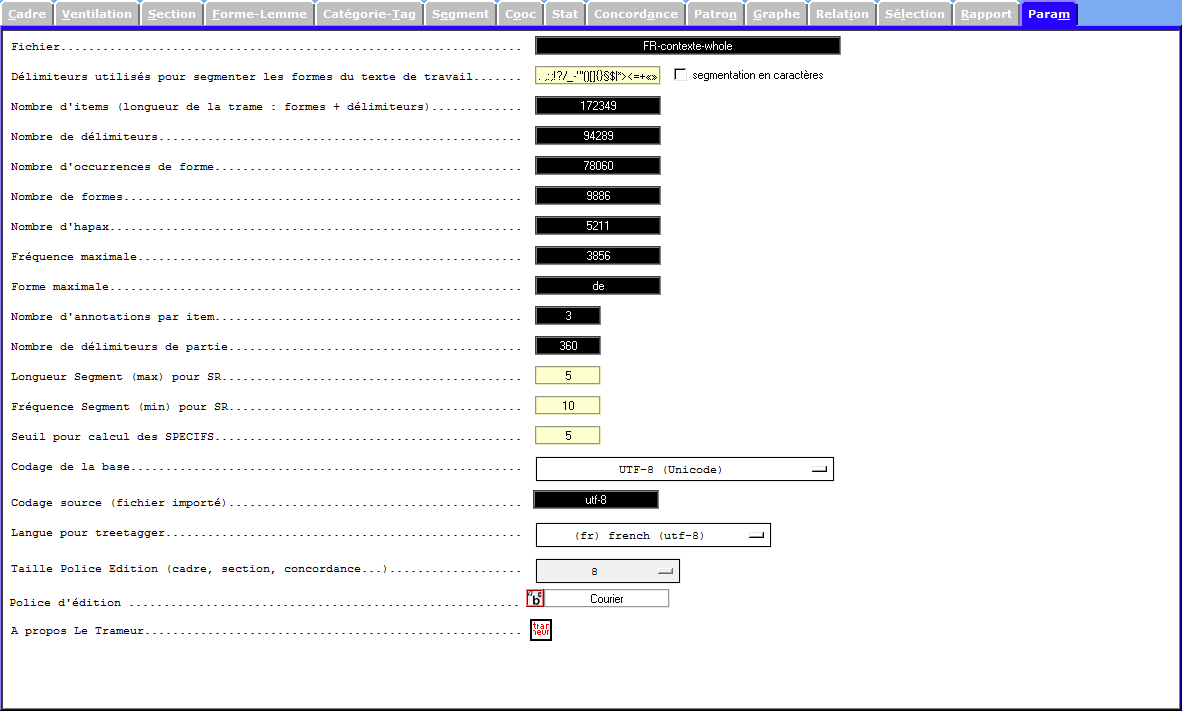
- Nombre d’items
- Nombre d’occurences de formes
- Nombre de formes
- Nombre d’hapax
- etc;
- Examen de formes-lemmes et de catégories grammaticales (par idems et par segments)
- Ventilation
- Concordance
- Cooccurrence et poly-cooccurrence des pôles
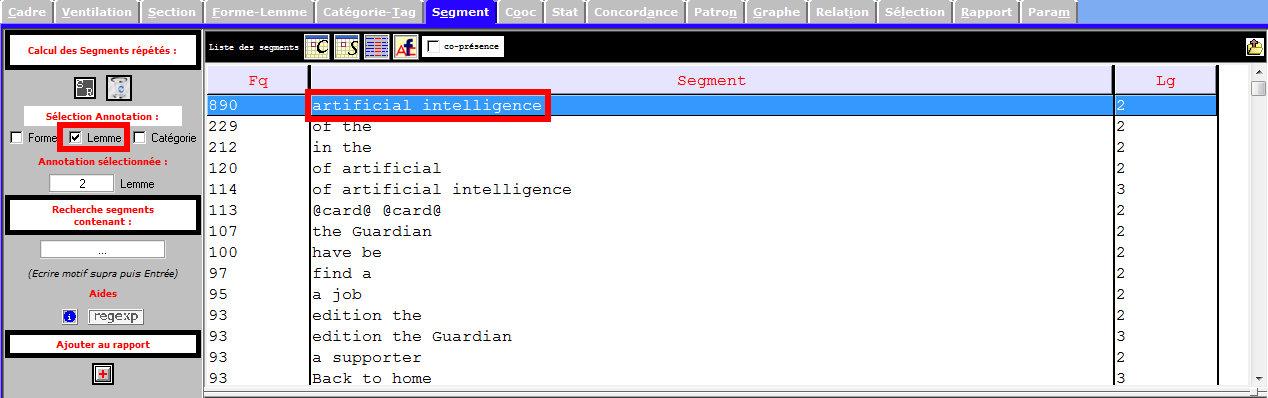
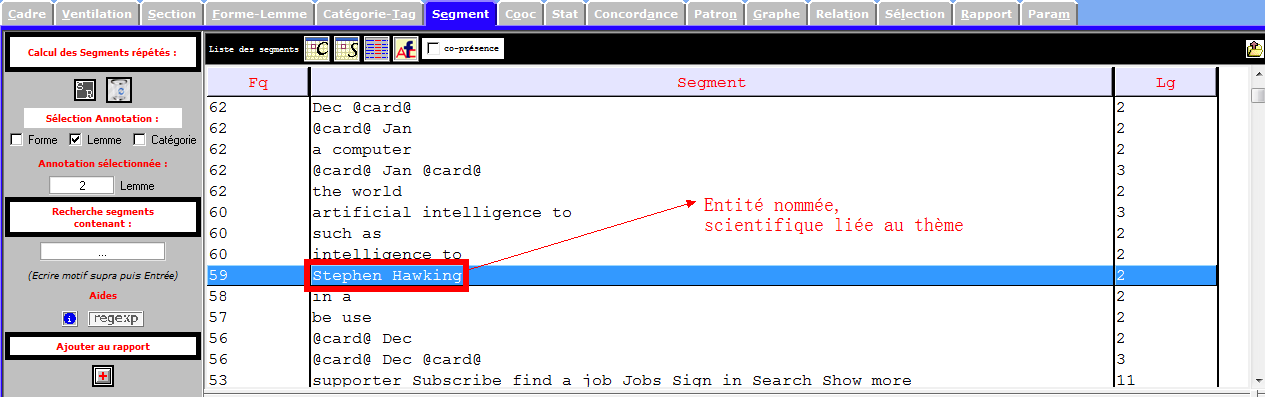
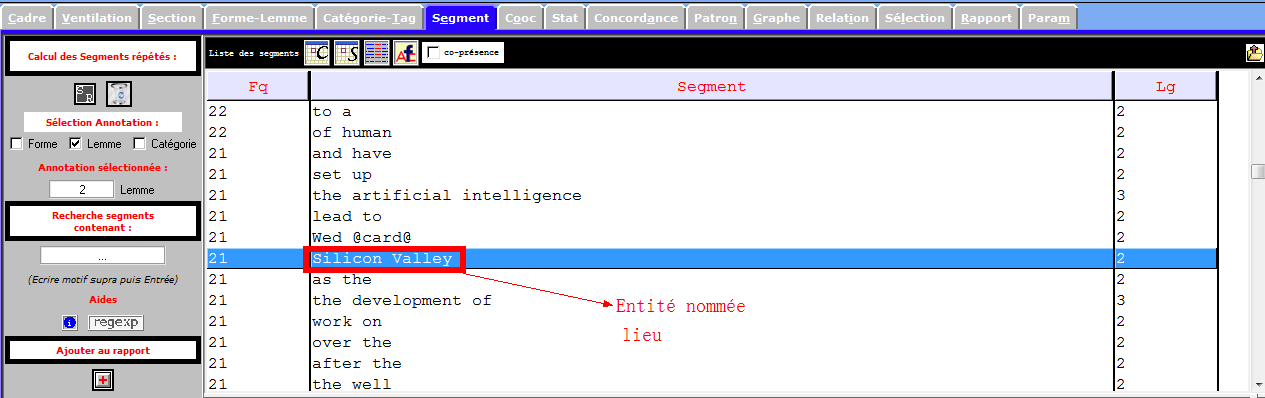
Les segments nous permettent de récupérer des ngrams pertinents, notamment des entités nommées, des mots polylexicaux, des mots composés sans délimiteur (trait d’union, apostrophe), ou bien des notions importantes.
La ventilation nous permet d’examiner par diagramme des répartition de certaines unités dans son ensemble. Nous pouvons l’utiliser pour une comparaison non seulement entre les trois corpus, mais aussi entre les parties d’un corpus.
La concordance sert à trouver les contextes immédiats (à gauche et à droite) d’un pôle (ceci peut être une forme, un lemme, une catégorie,etc). Nous nous en servons pour confirmer (plutôt pour infirmer) certaines observations.
La concordance n’est pas toujours suffisant car les textes sont organisés linéaires. Nous ne voyons que les contextes immédiats d’un certain motif. Par contre, la (poly-)cooccurrence permet de l’examiner dans son environnement, un sens plus large.
Principes caractérisques lexicométriques de corpus
FRANÇAIS
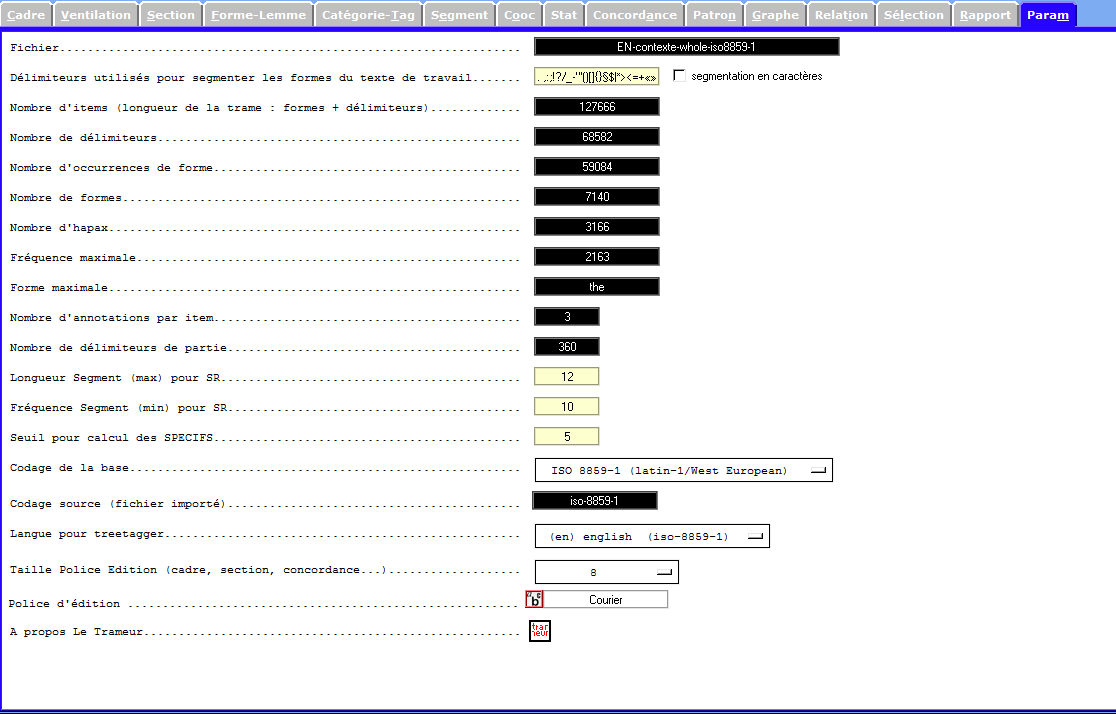
ANGLAIS
Avant de charger un corpus d’anglais dans le Trameur, il est impératif pour nous de transcoder le corpus en iso-8859-1 pour qu’il soit correctement traité avec le tree-tagger.
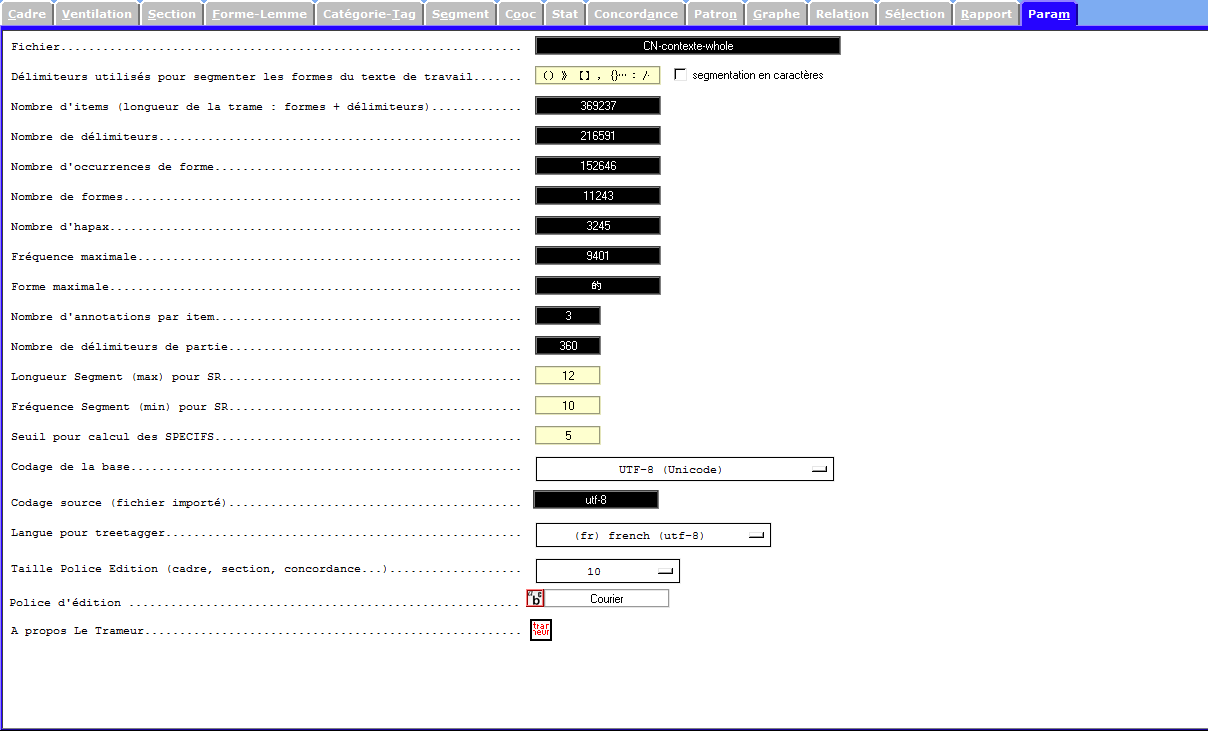
CHINOIS
Le module tree-tagger dans le Trameur ne dispose pas de traitement pour le chinois. Nous avons cependant tenté le jeu d’étiquettes français. Au pire, ce dernier ne marche pas, car il ne pose aucune influence sur les formes, et les lemmes chinois sont identiques que leur forme.
Examen de formes-lemmes et de catégories grammaticales (par idems et par segments)
FRANÇAIS
Issus de sources variées, certains mots, notamment des entités nommées, ne sont pas homogènes. De plus, nous ne pouvons non plus les contrôler dans la phase de prétraitement de corpus. Grâce à une fonctionnalité dans le Trameur, nous pouvons les modifier à la main pour que le résultat soit plus pertinent. Voir un exemple ci-dessous :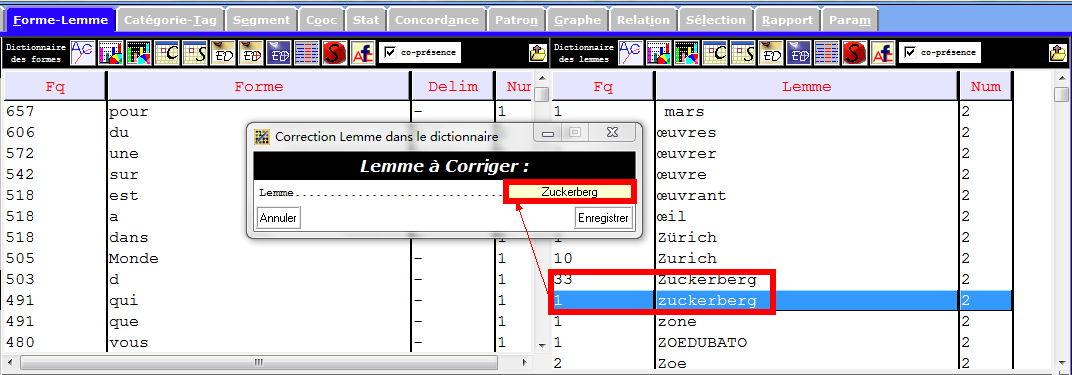
Lemmes et formes (par idems et par segments)
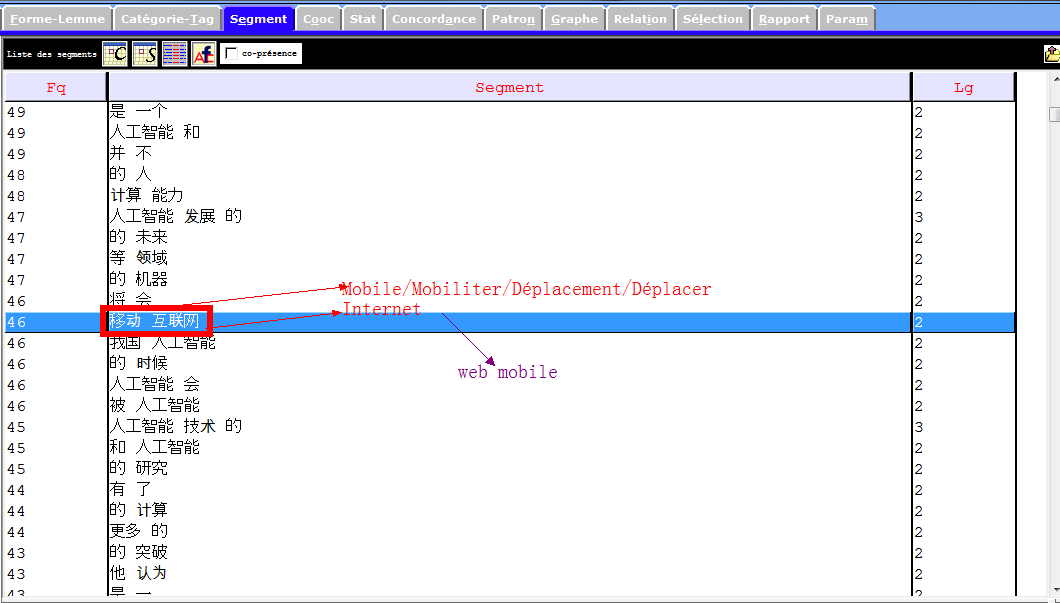
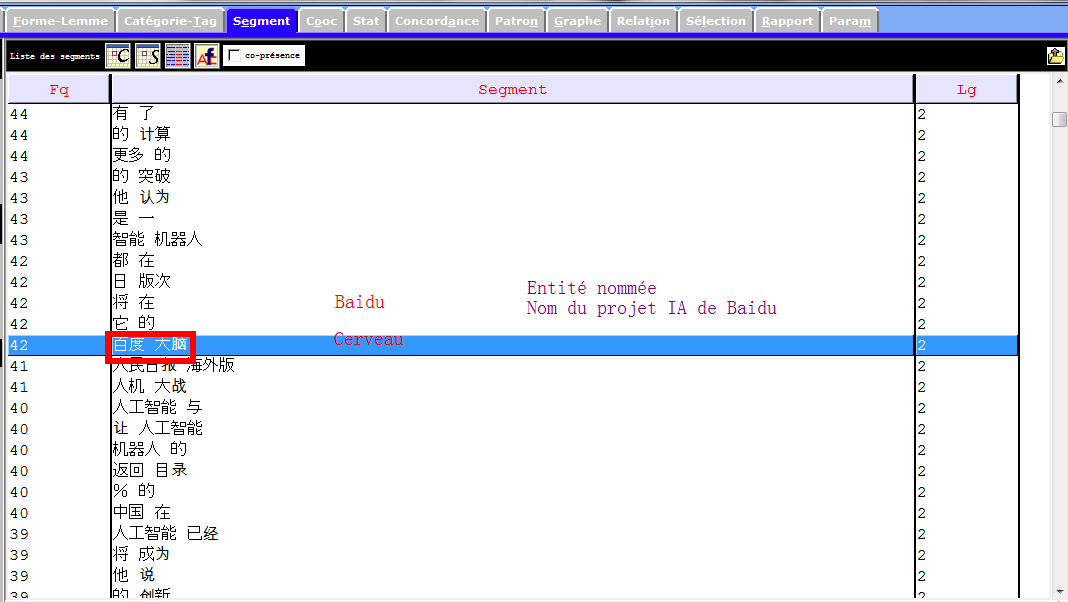
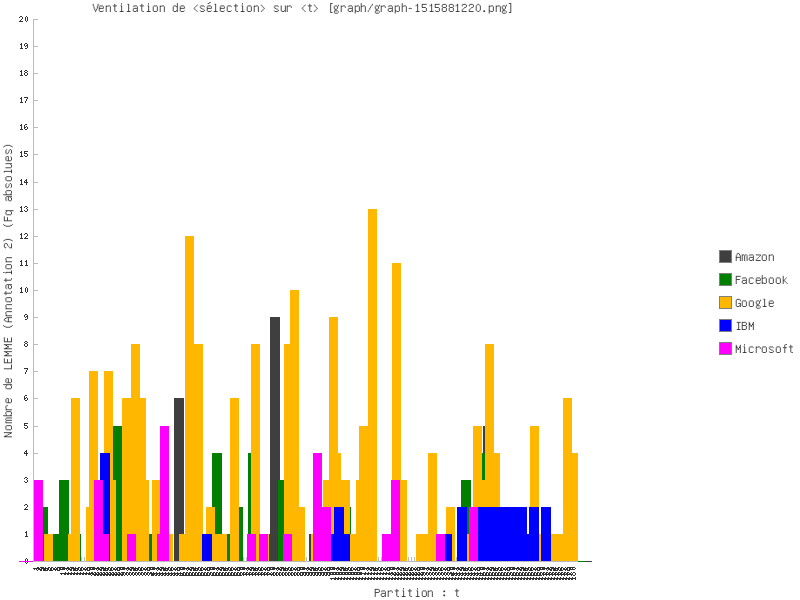
Les images infra montrent une partie des entités nommés et des notions importantes que récupèrent la rubrique Segment, et qui sont liées à notre sujet de recherche. Nous nous en inspirons pour les prochaines étapes du travail.
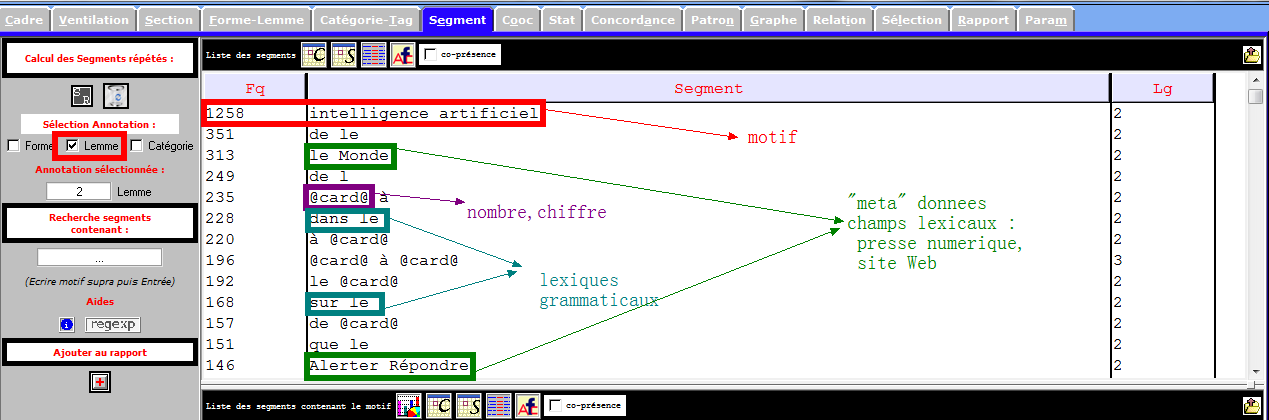
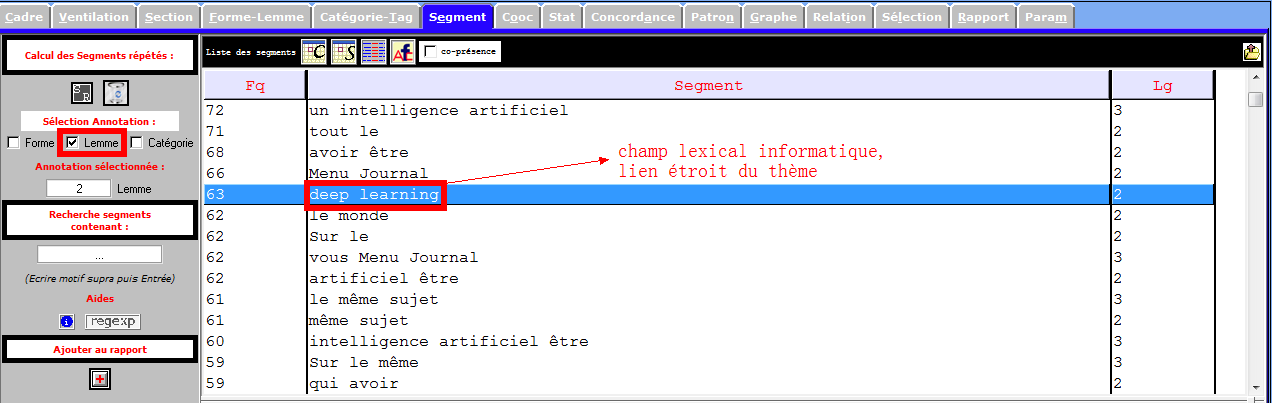
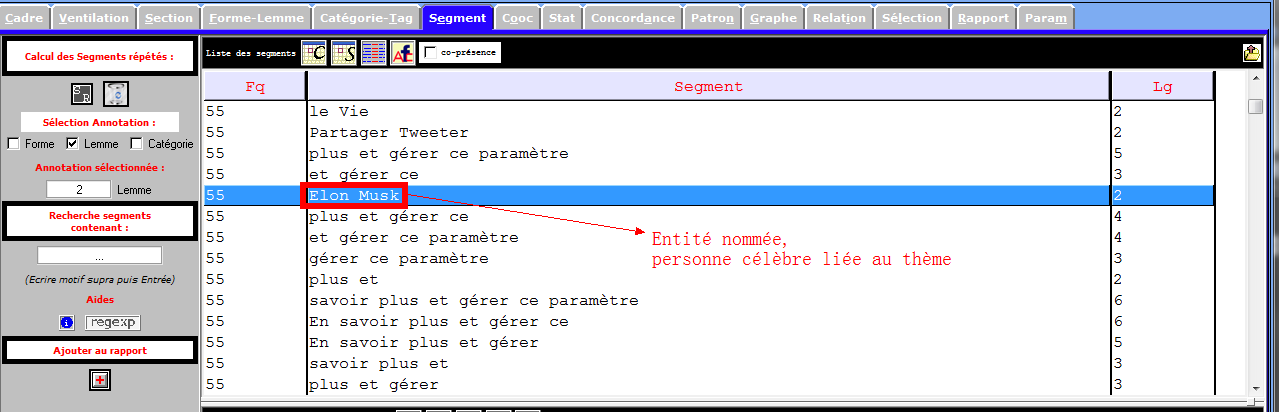
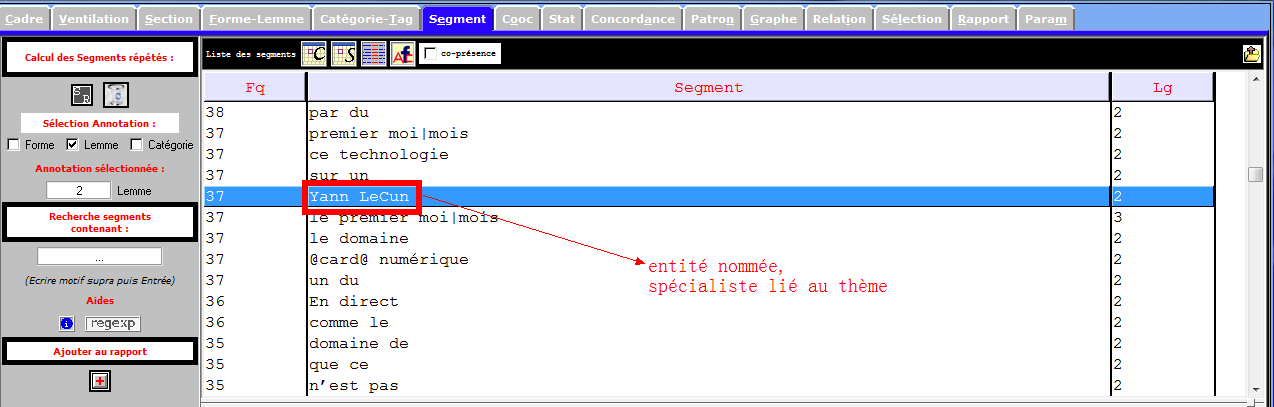
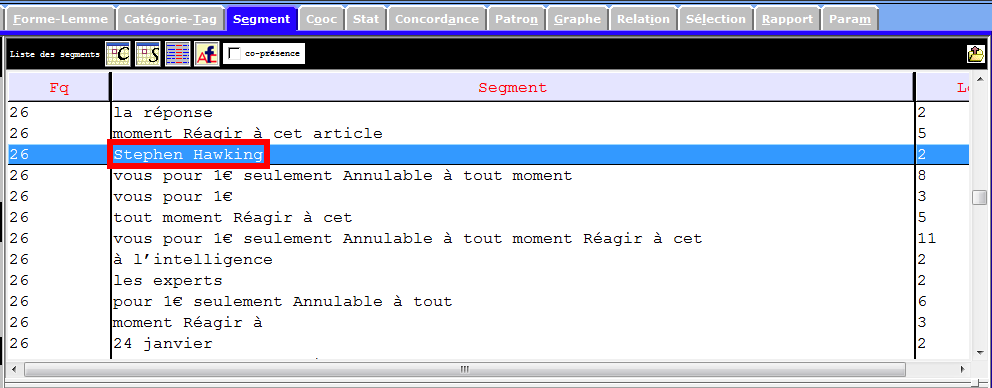
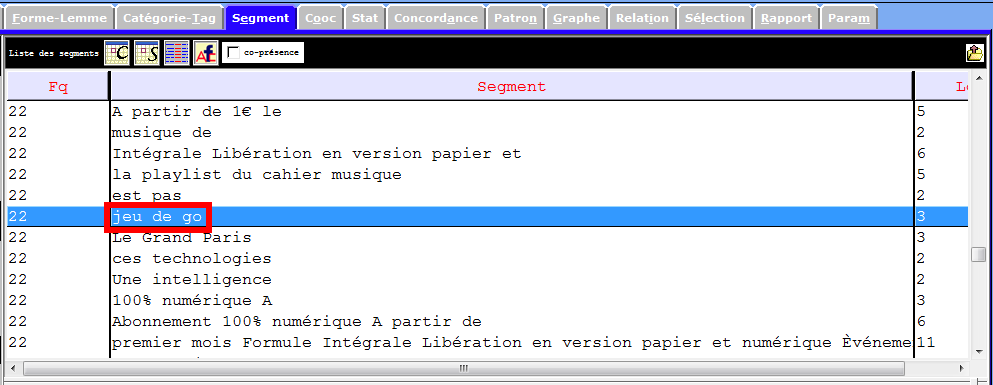
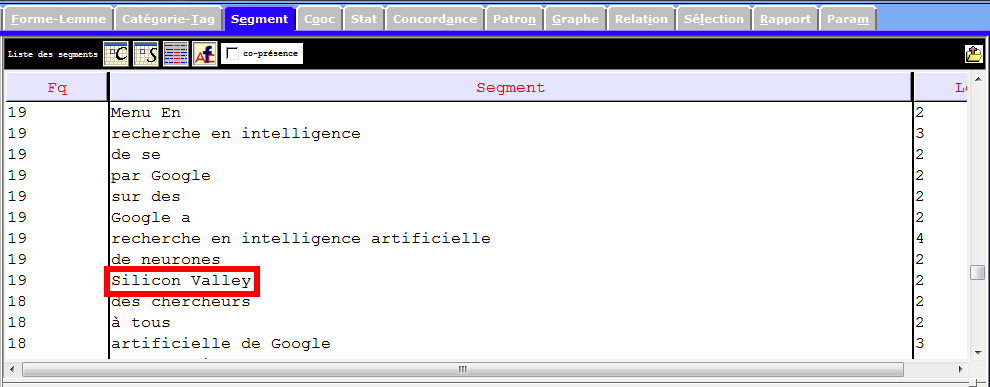
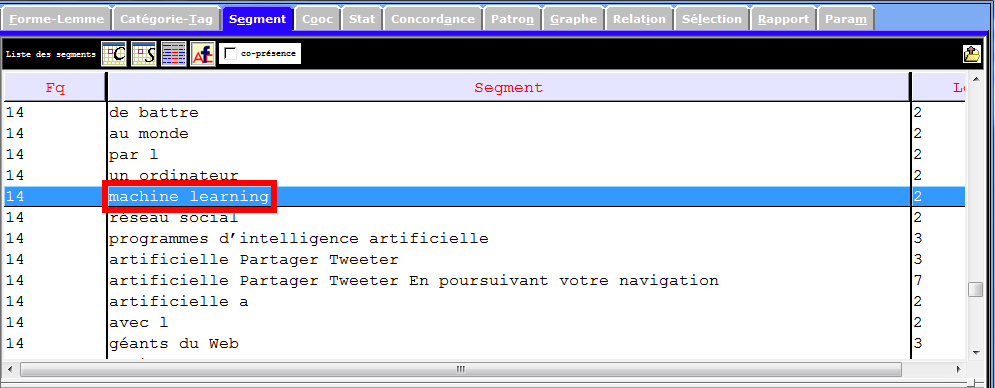
Catégories Grammaticales
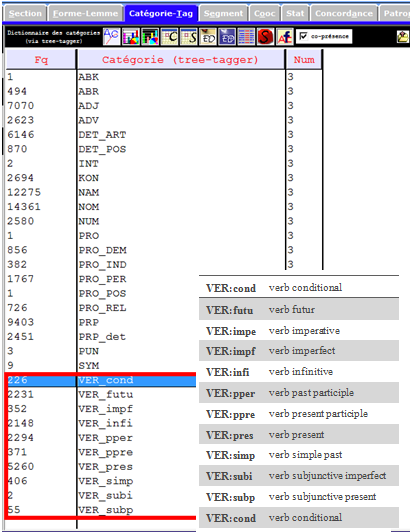
Dans le corpus français, les verbes sont moins fréquents que les substantifs, selon les images infra.
Le jeu d’étiquettes français complet est disponible sur le site du tree-tagger.
ANGLAIS
En nous inspirant des résultats obtenus du corpus français, nous adoptons la même démarche, à savoir examiner des segments de lemmes et de catégories.
Lemmes et formes (par idems et par segments)
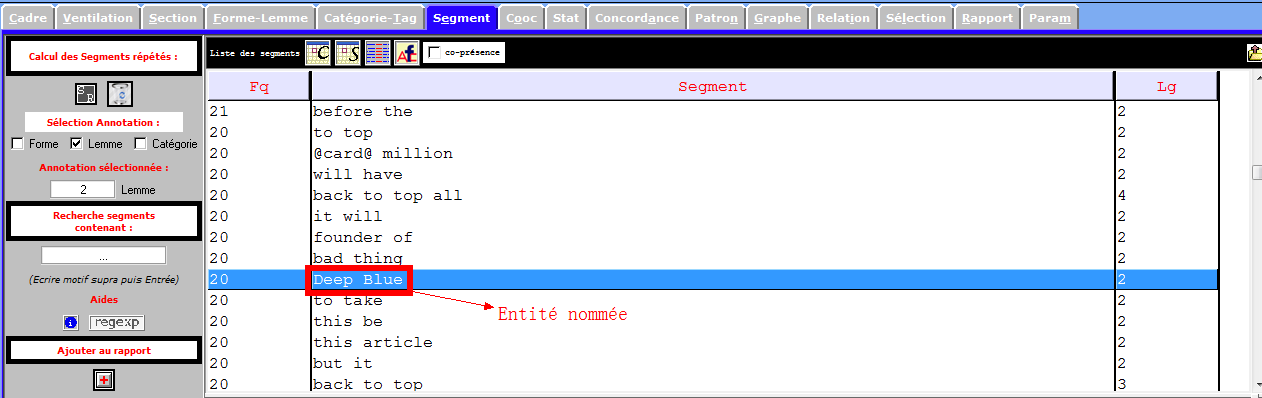
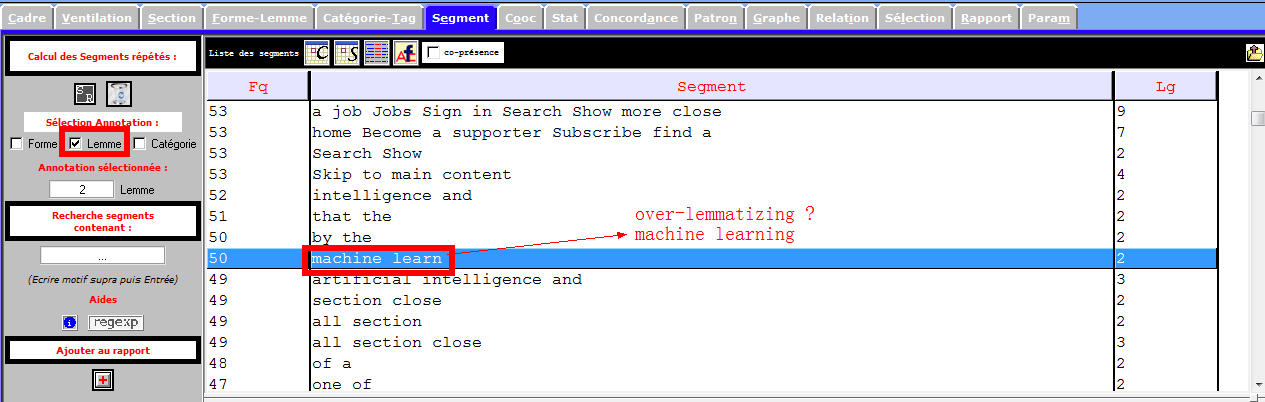
l’image infra démontre le « danger » de tree-tagger : sur-lemmatiser. La notion machine learning (apprentissage automatique) devient machine learn .
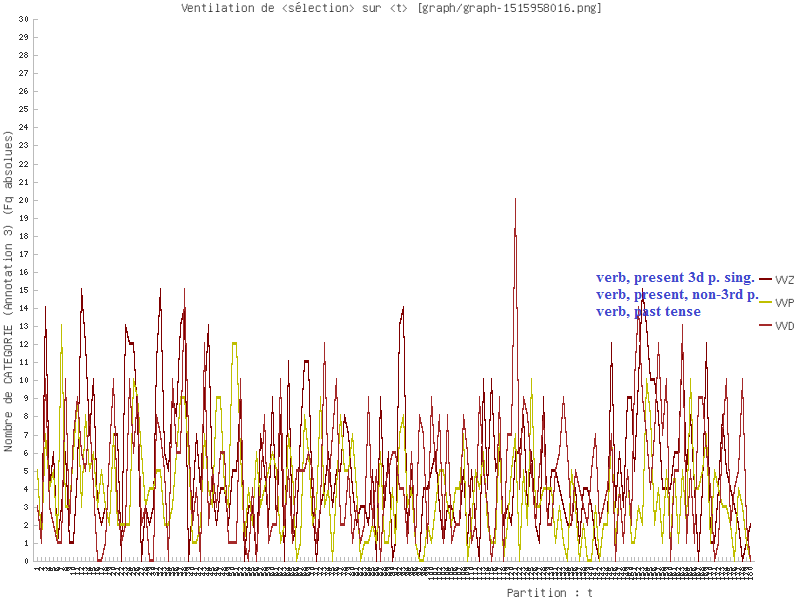
Catégories Grammaticales
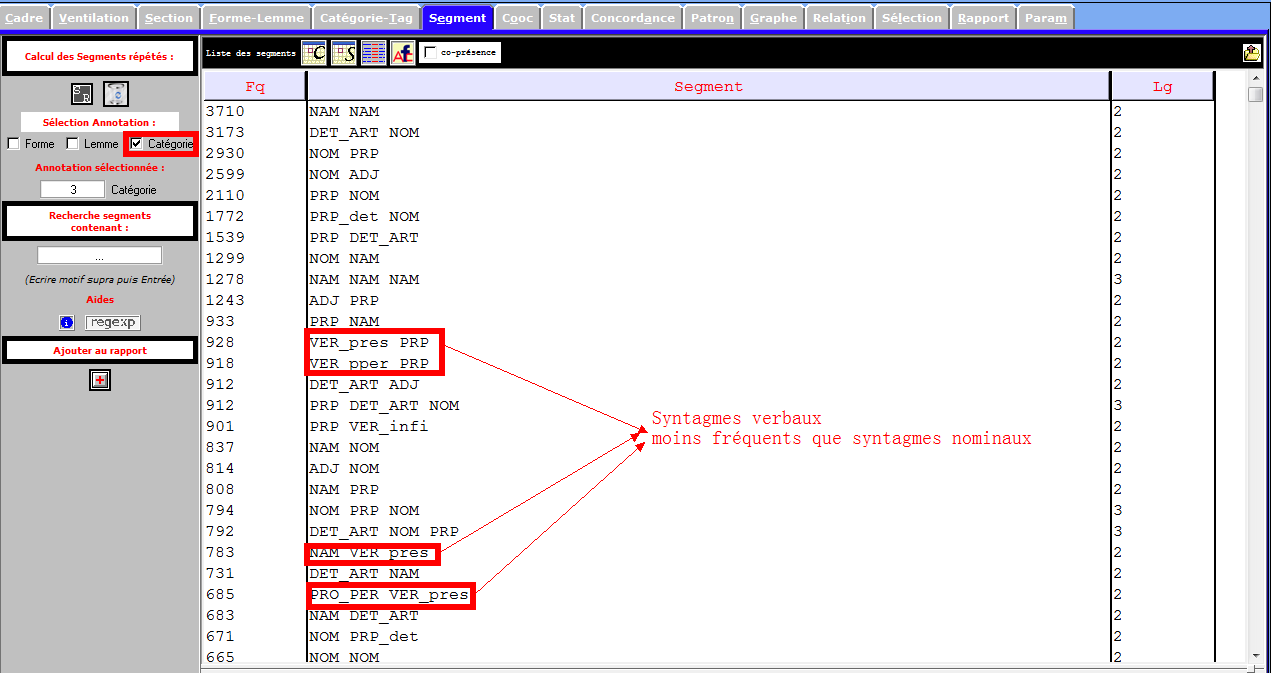
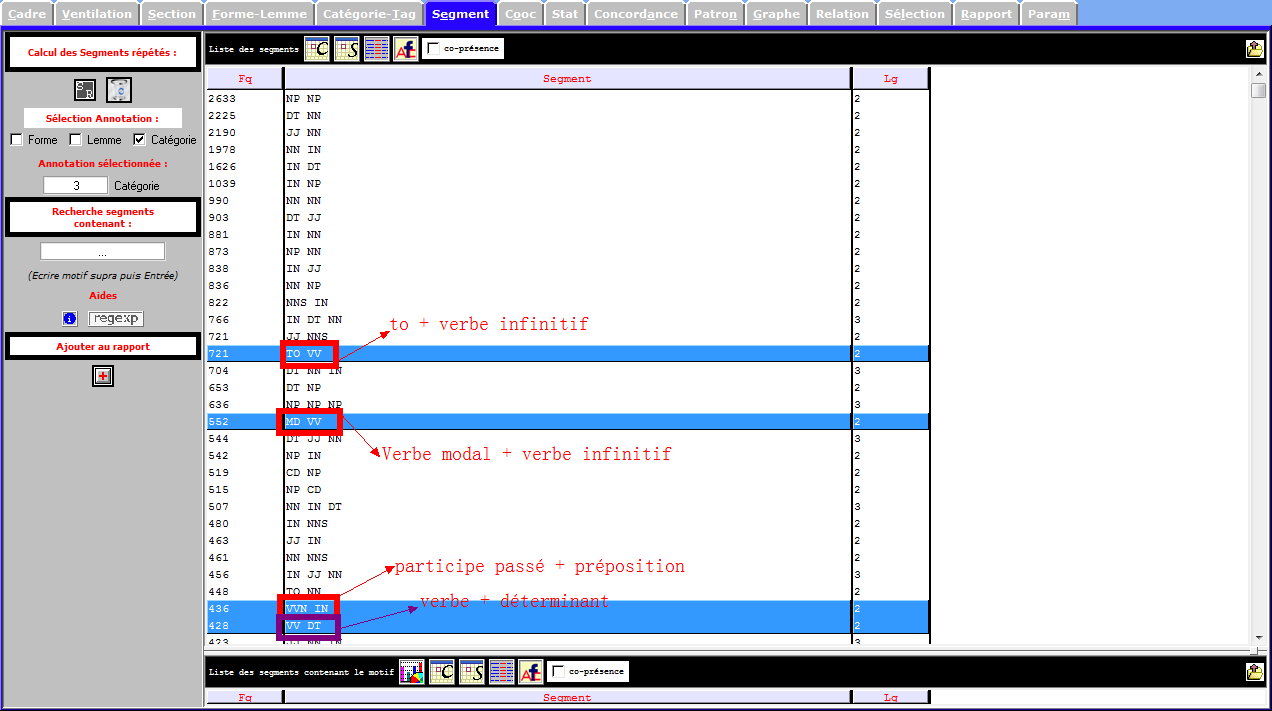
L’image ci-dessous montre une partition faible des syntagmes verbaux.
CHINOIS
Etant donné le résulat satisfaisant de la segmentation de textes chinois que nous avons réalisée dans la phase prétraitement, nous pouvons nous concenter sur des segments venant du Trameur.
Lemmes et formes (par segments)
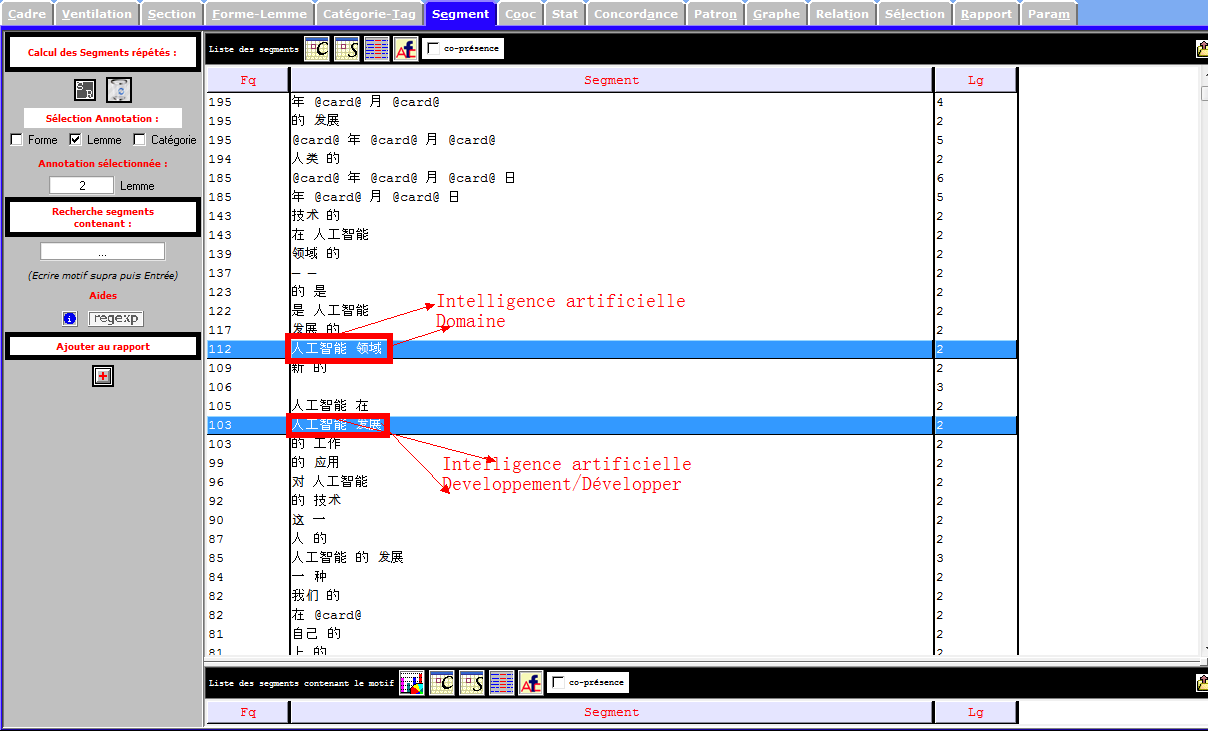
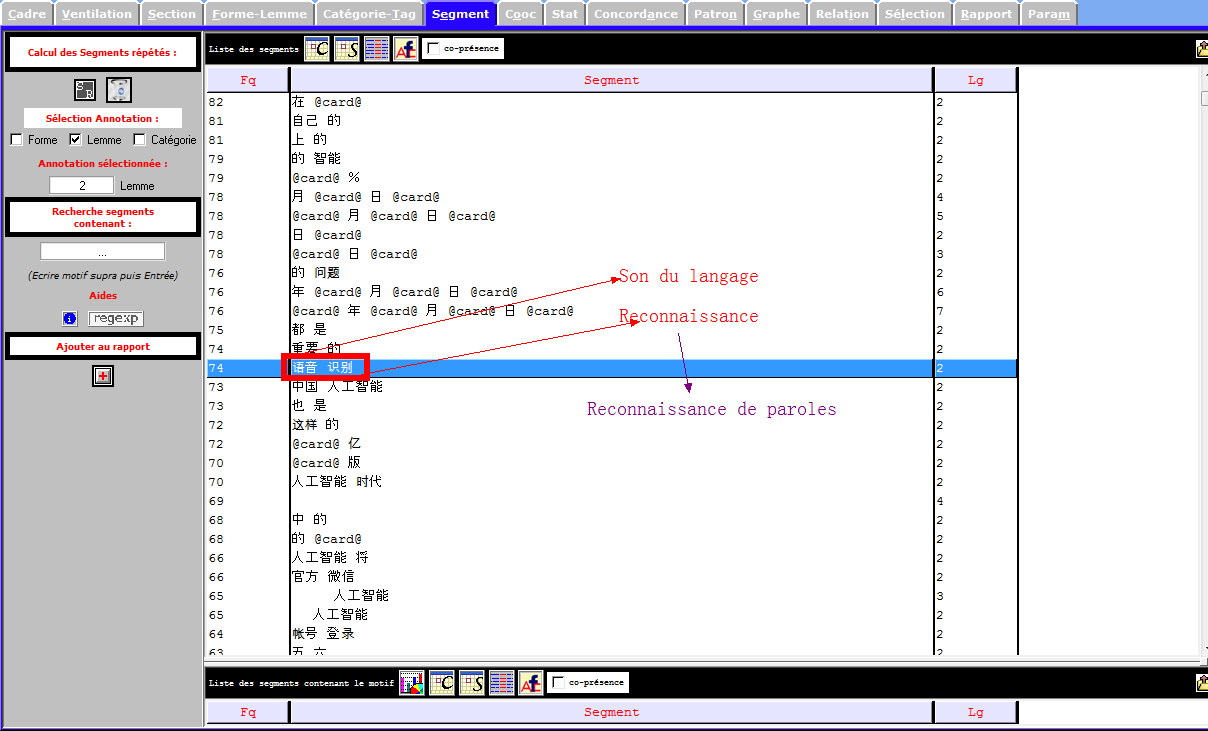

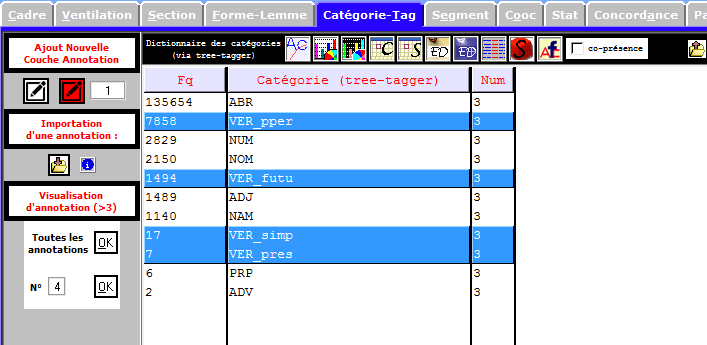
Catégories Grammaticales
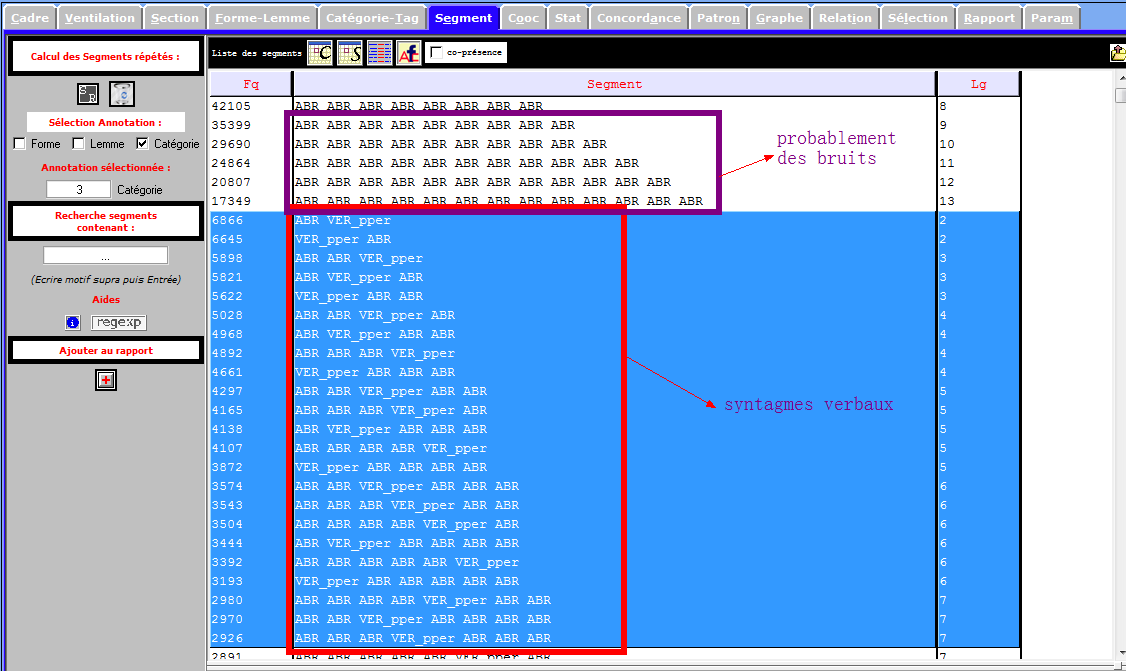
En vue, les verbes représentent une proportion importante selon les deux images ci-dessous, et il semble que cette partition soit juste pour la langue chinoise. Est-ce vraiment le cas dans notre corpus? Les prochaines étapes désapprouvent cette constatation.
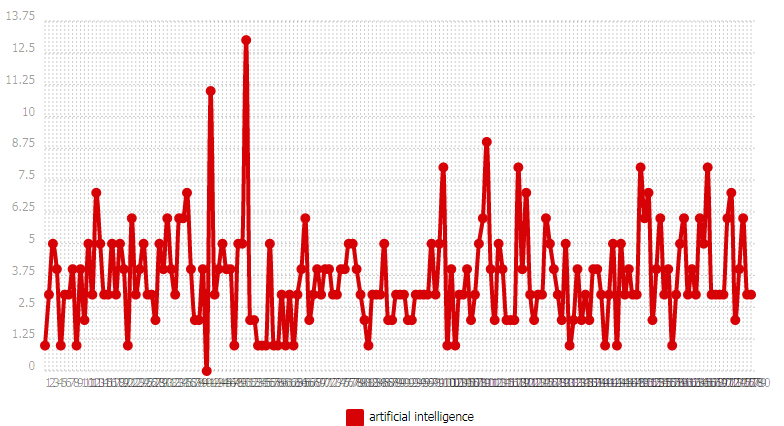
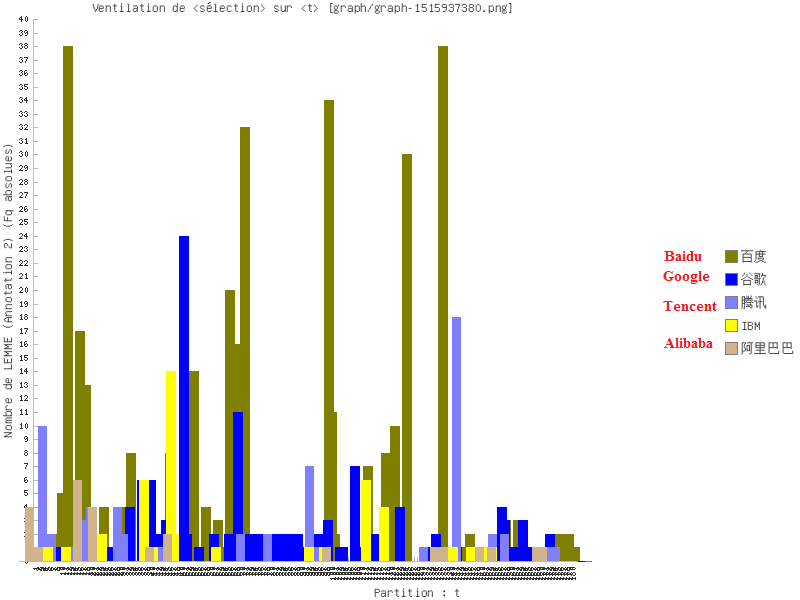
Ventilation
Nous montrons deux directions possibles dans cette partie : une sur un seul pôle, et une autre sur plusieurs.
Nous commençons par notre motif. Ensuite nous examinons des entités nommées (noms d’entreprise technologique par exemple). Nous terminons par une comparaison de syntagmes verbaux.
Certaines démarches sont réalisées par iTrameur à cause de la performance de nos machines.
FRANÇAIS
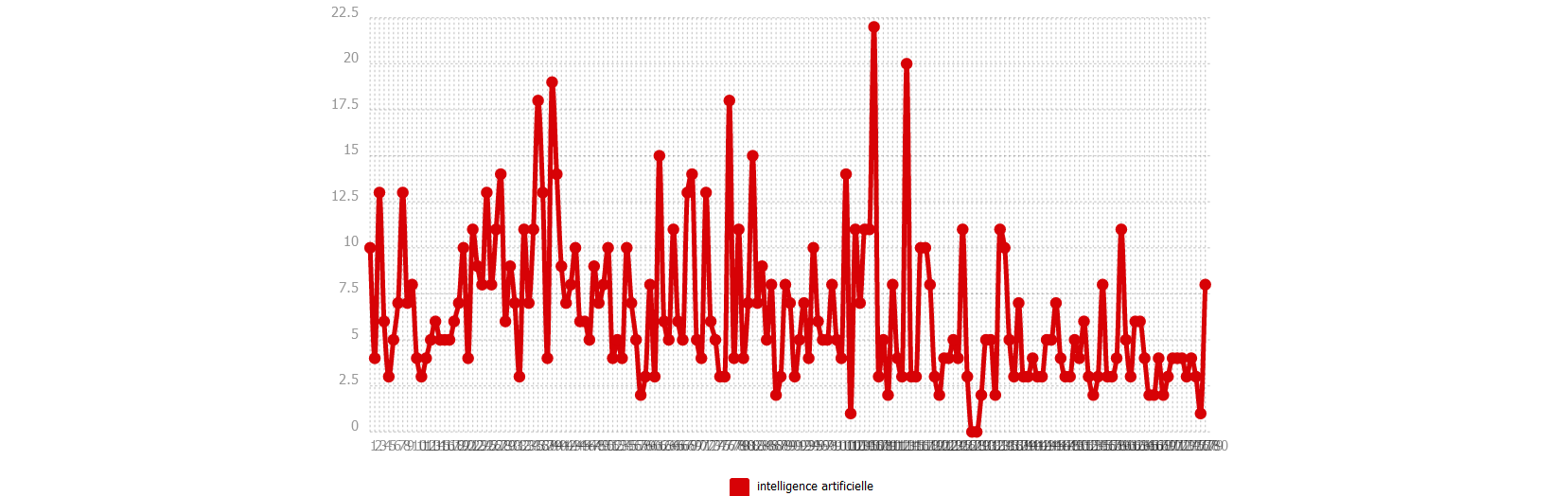
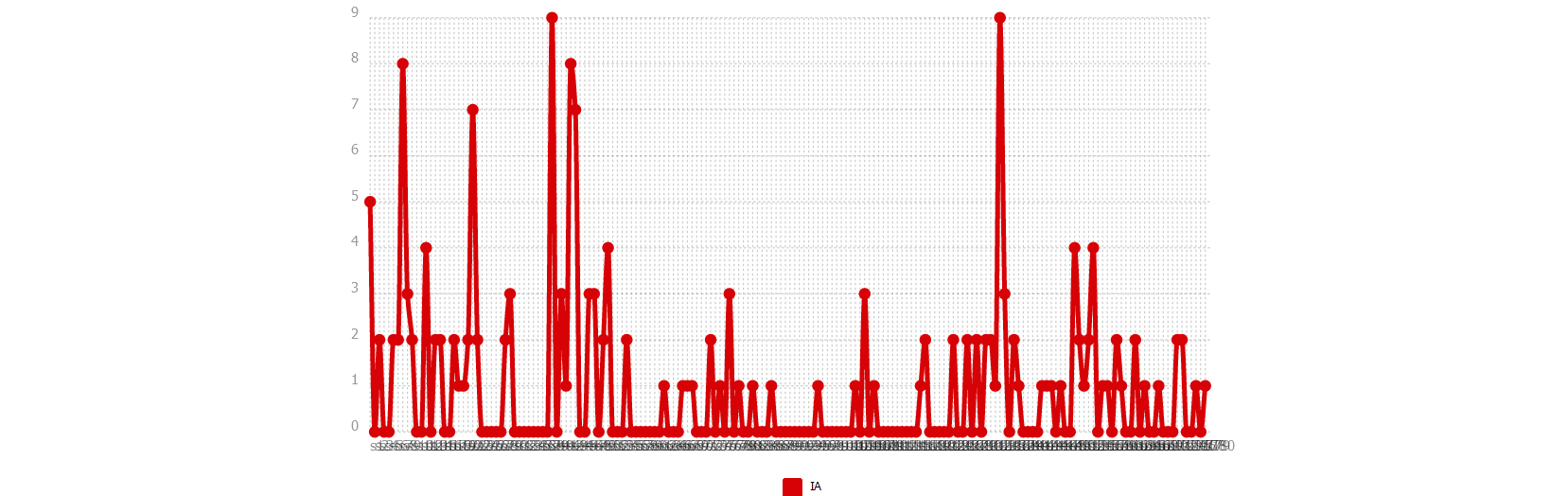
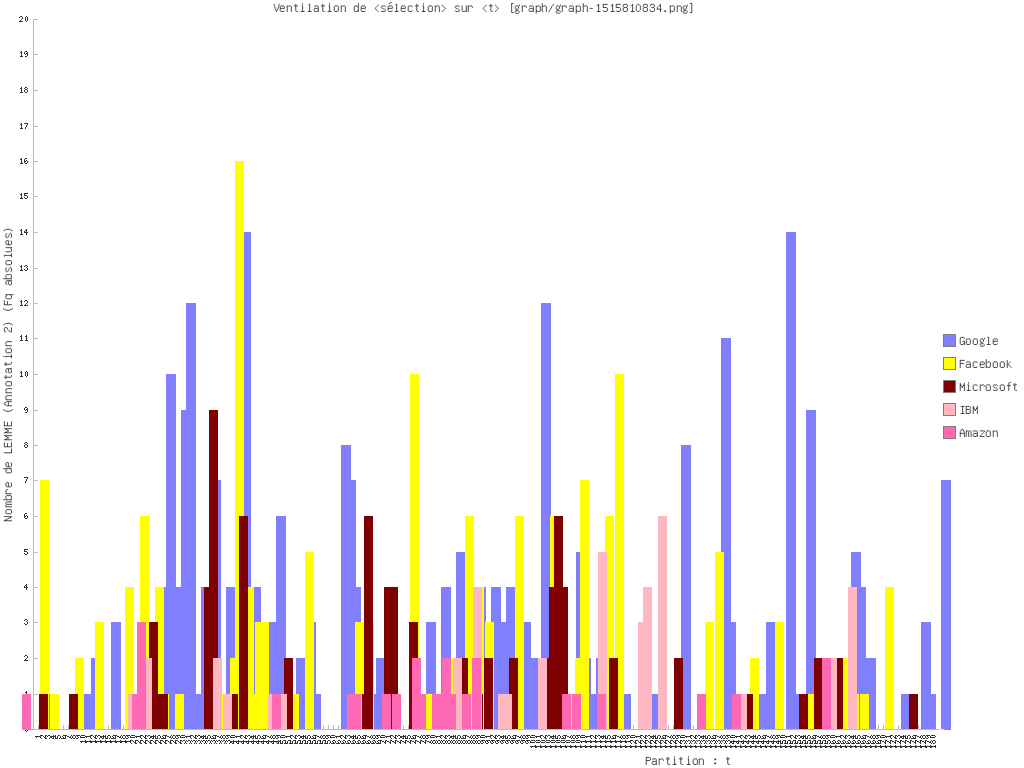
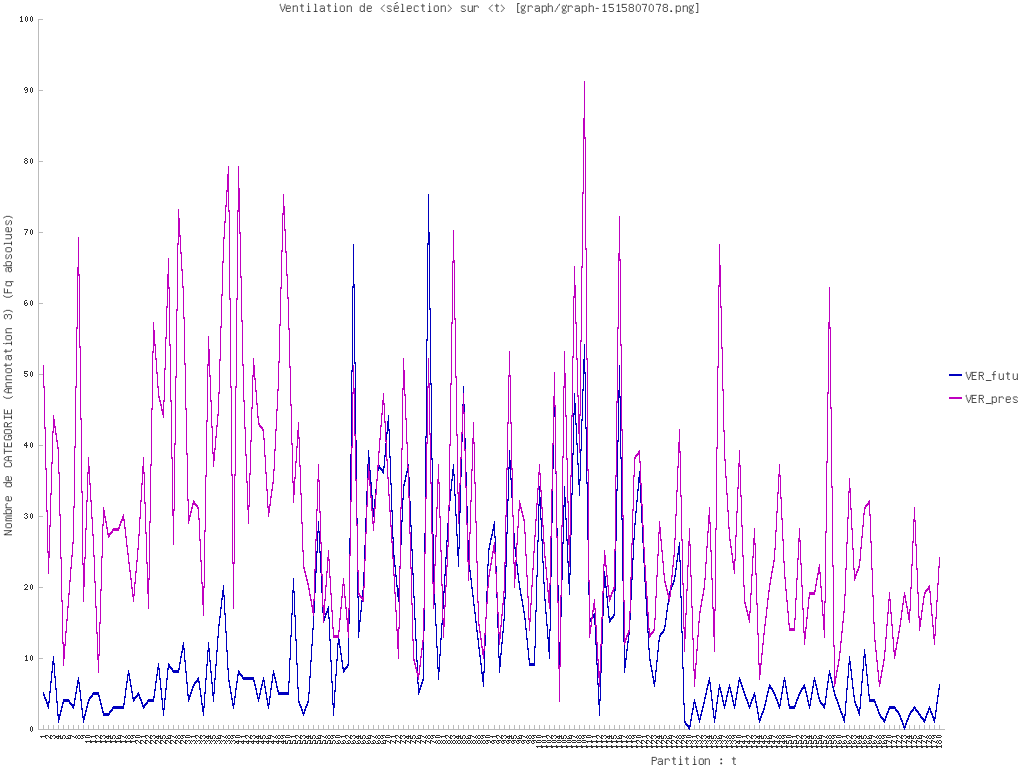
ANGLAIS
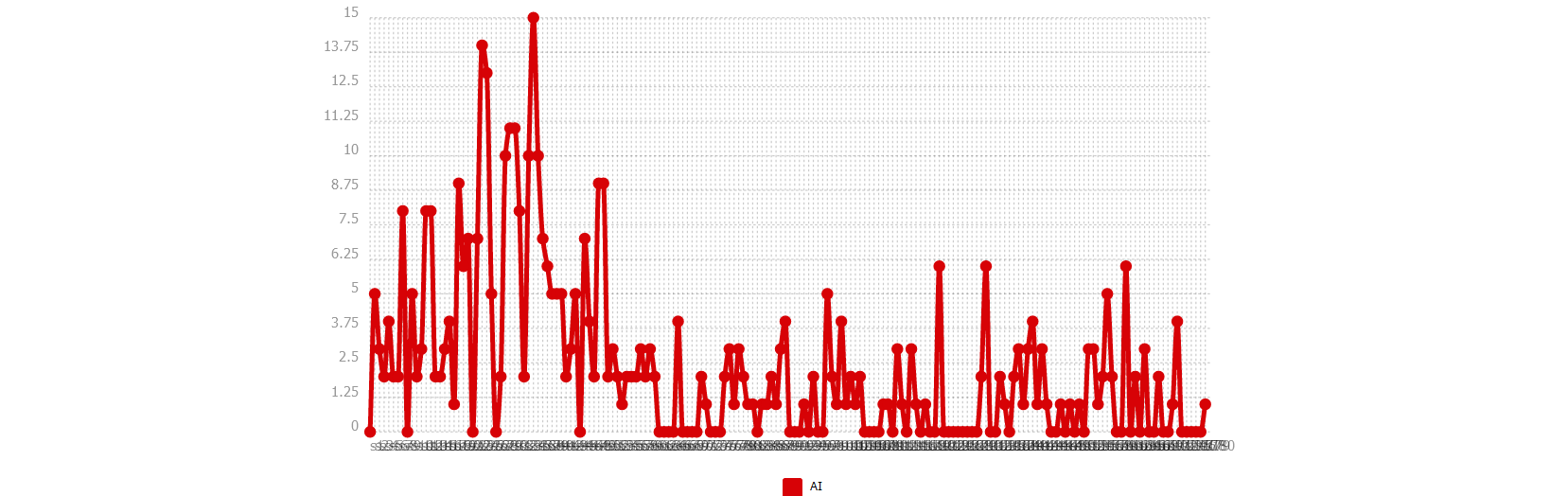
CHINOIS
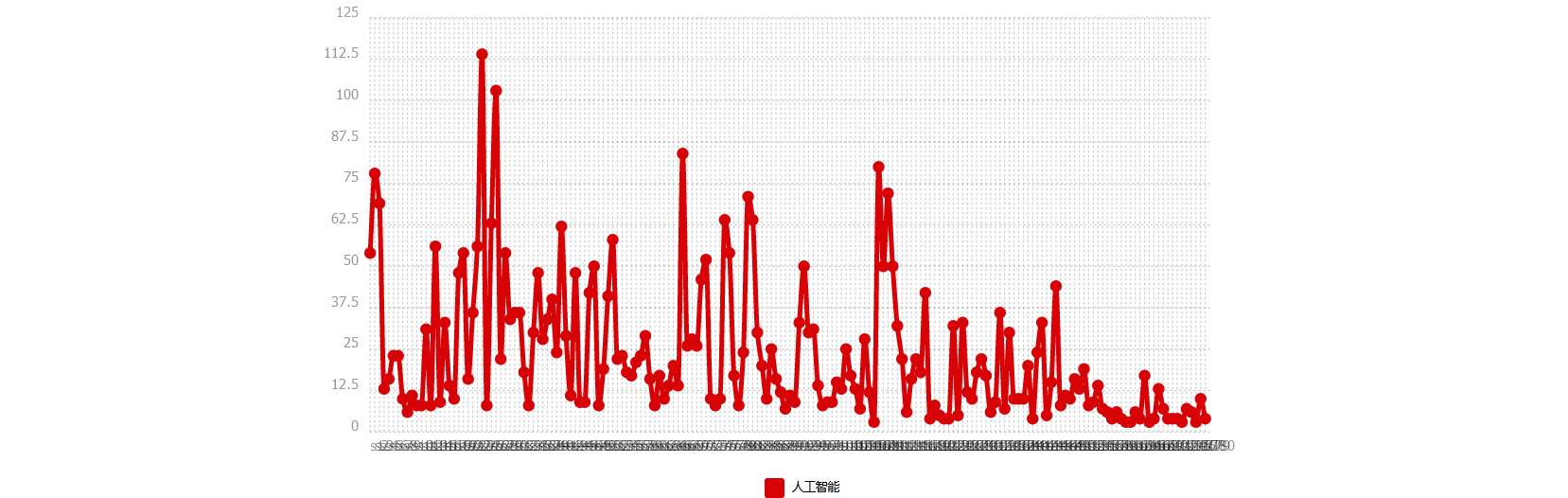
Concordance
Nous craignions que la proportion importante d’occurrences des verbes n’ait été un résultat de bruits dans le corpus chinois. La rubrique Concordance nous permet d’infirmer cette surreprésentation : l’étiquetage n’est pas bon. Nous rejetons l’analyse des catégories gramaticales du corpus chinois.
CHINOIS
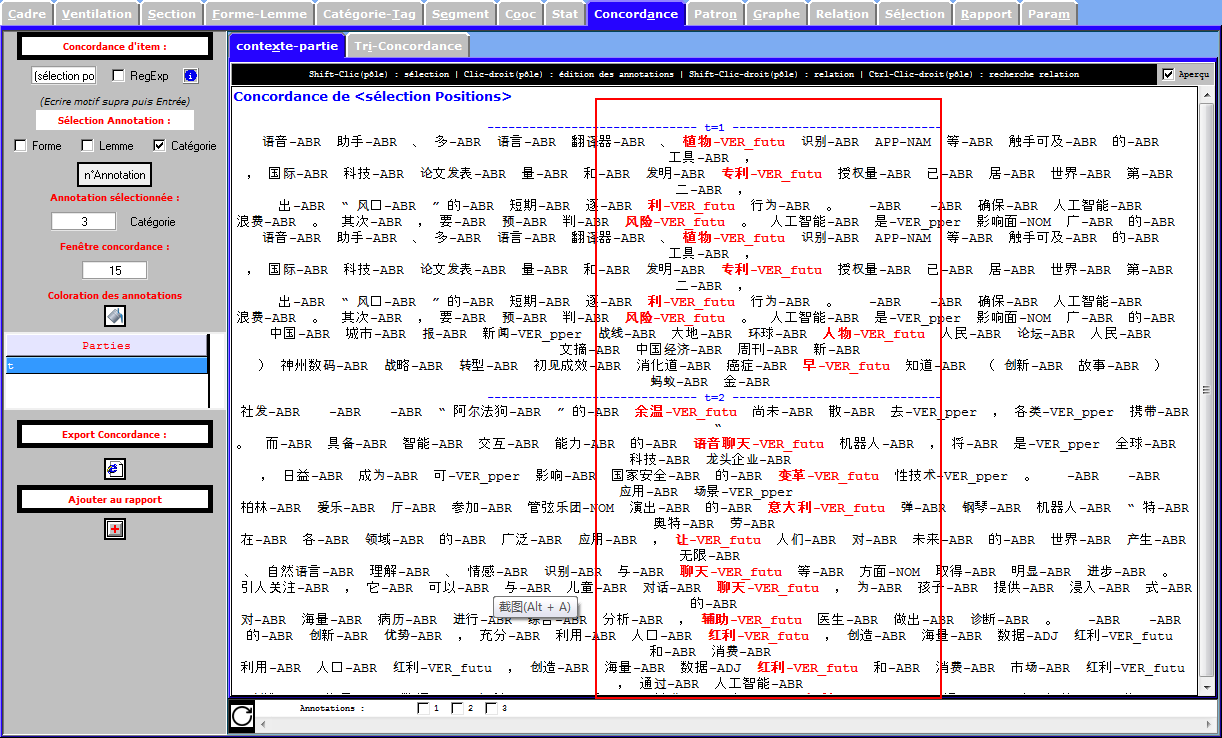
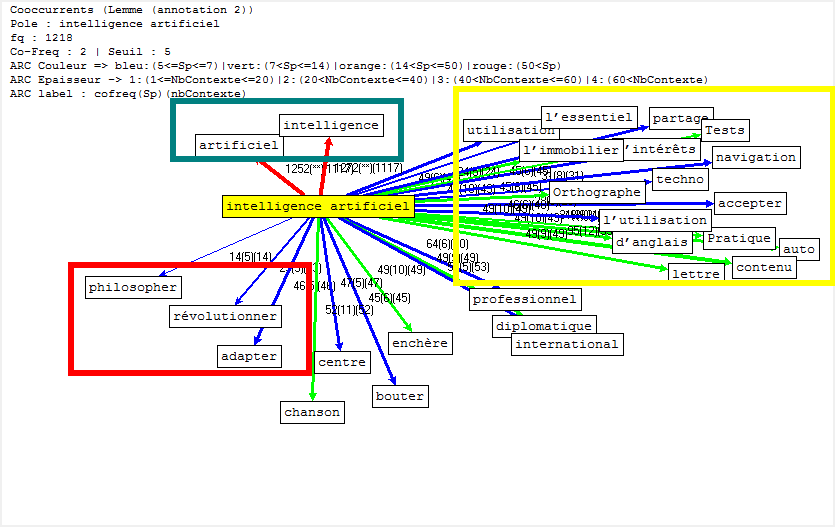
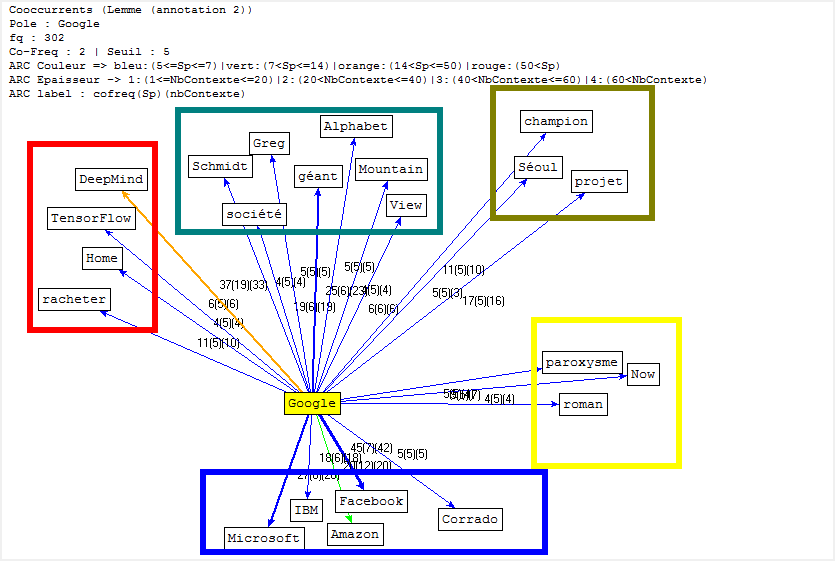
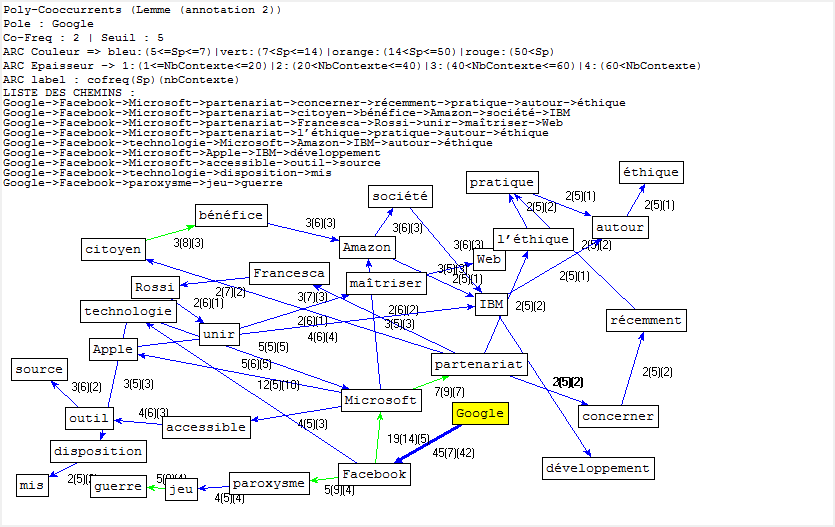
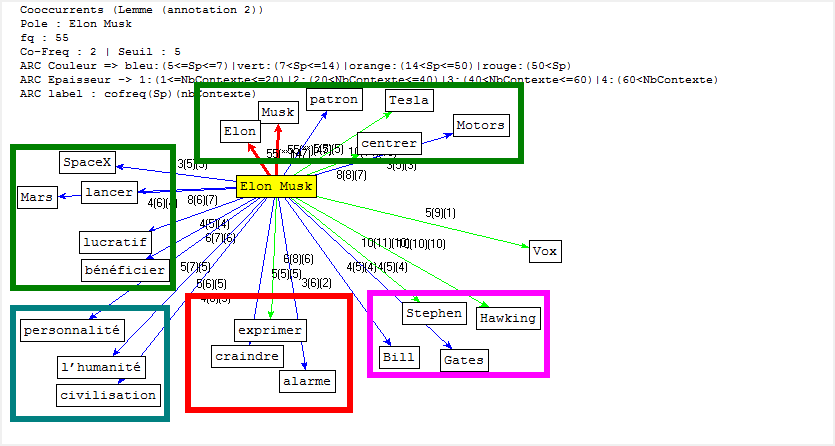
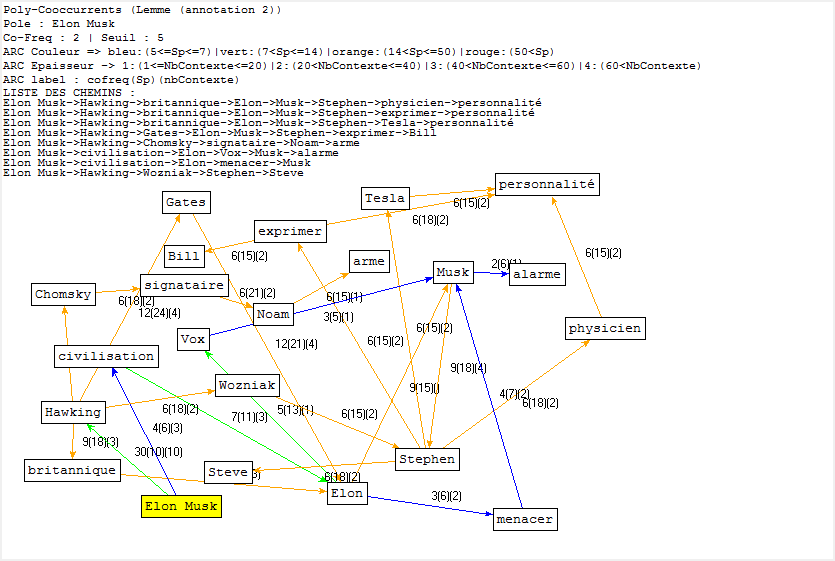
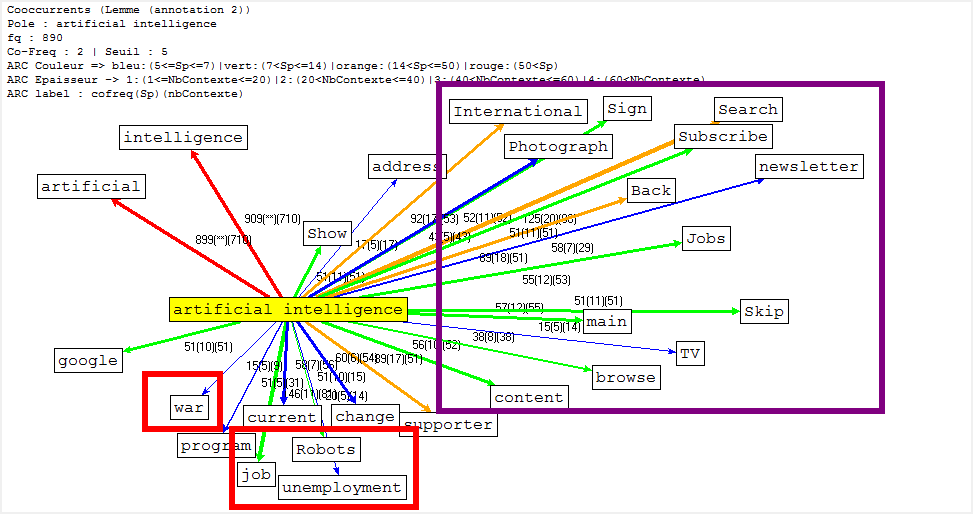
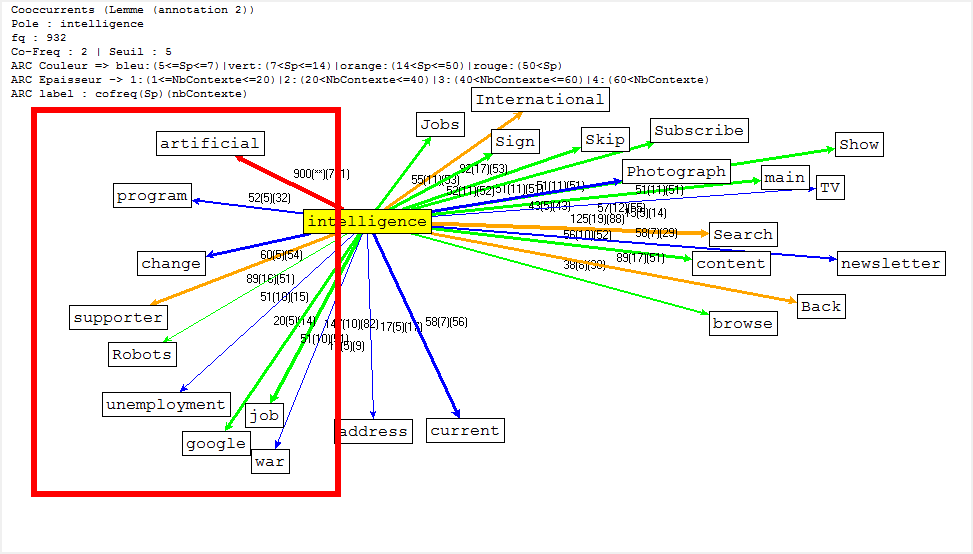
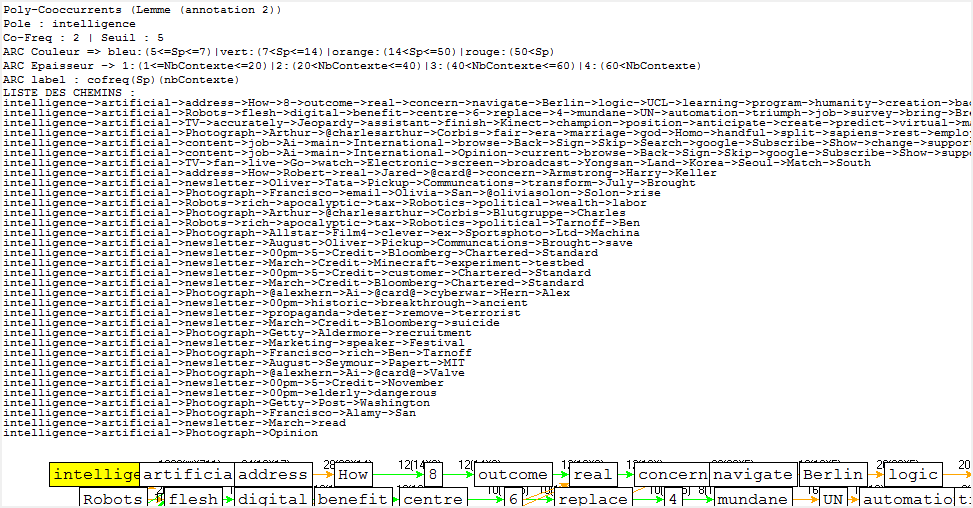
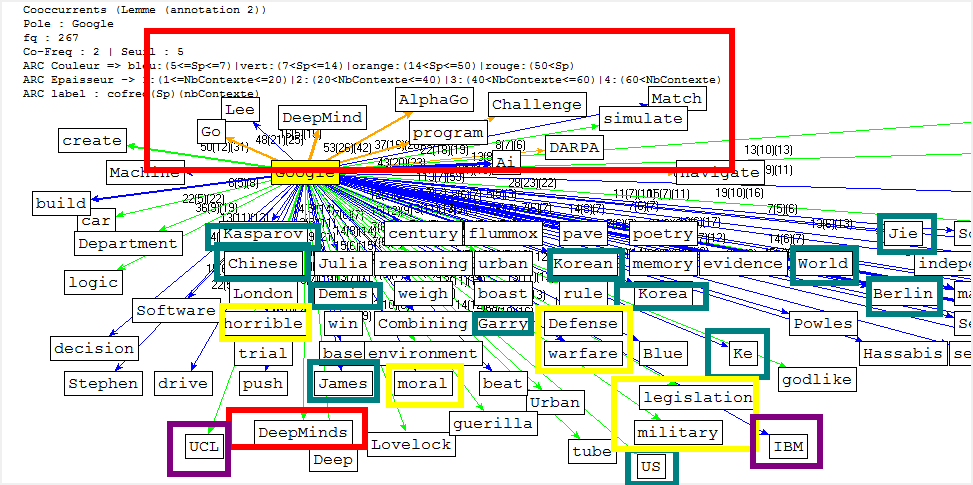
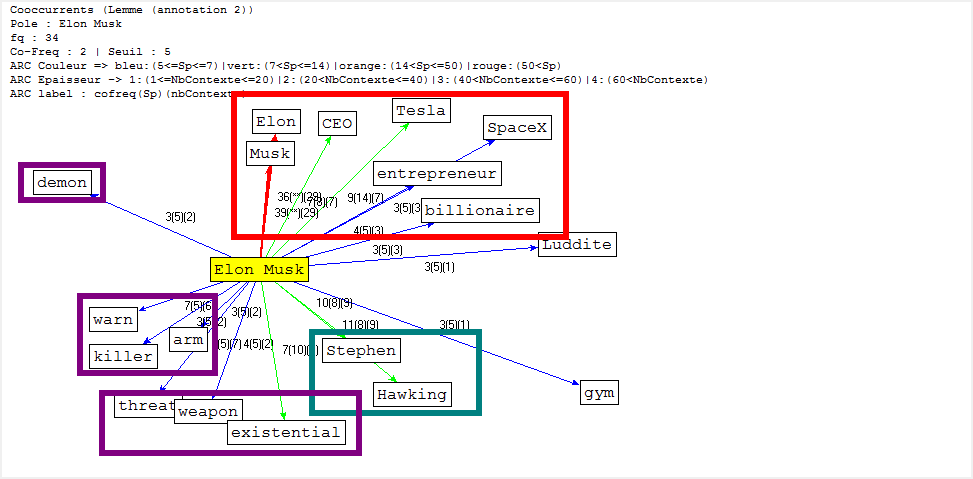
Cooccurrence et Poly-Cooccurrence
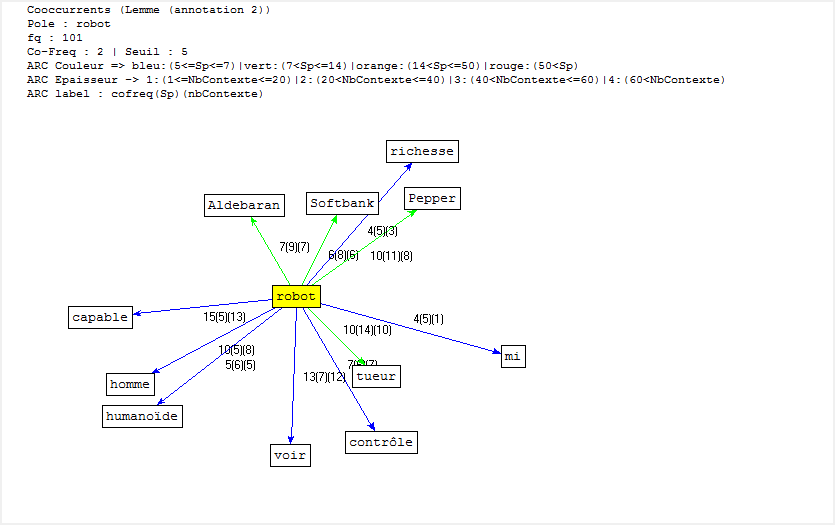
Dans cette partie, nous montrons la cooccurrence et la poly-cooccurrence de notre motif, deux entités nommées (nom d’entreprise, et nom de personne), ainsi que le mot « robot » qui a aussi une fréquence significative dans nos corpus. De plus, une tentative préliminaire nous montre qu’il existe encore de nombreux bruits à nettoyer, malgré nos travaux dans la phase de prétraitement. Il y a tout de même un remède : augmenter la taille de nos antidictionnaires bien qu’il ait de perte d’informations éventuelle. Nous nous rebattrons sur cette méthode (mais non abus).
Concernant le motif en anglais et en français, qui comporte deux mots, nous adoptons deux moyens :
- grâce à la rubrique Segment, le motif est récupéré sous forme de 2gram, qui peut nous servir directement ; ou
- nous pouvons tout d’abord trouver la cooccurrence du lemme « intelligcence » et ensuite utiliser sa cooccurrence de lemme « artificiel » (artificial en anglais) pour calculer la poly-cooccurrence.
Il s’agit d’un jeu délicat en ce qui concerne la deuxième méthode, car « intelligence » et « artificiel » cooccurées ne veulent pas dire que ces deux lemmes soient collés. Le résultat des calculs serait différent selon ces deux schémas.
FRANÇAIS
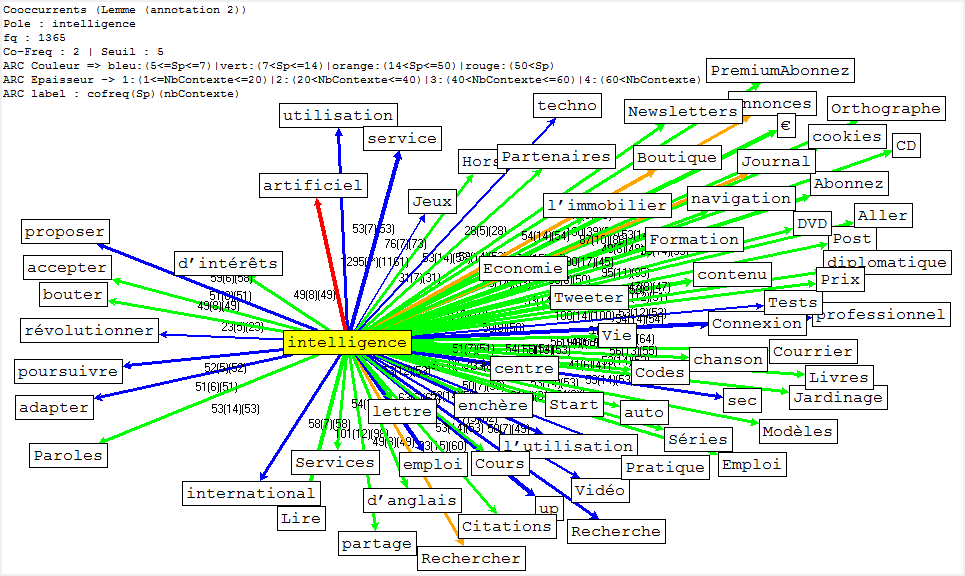
ANGLAIS

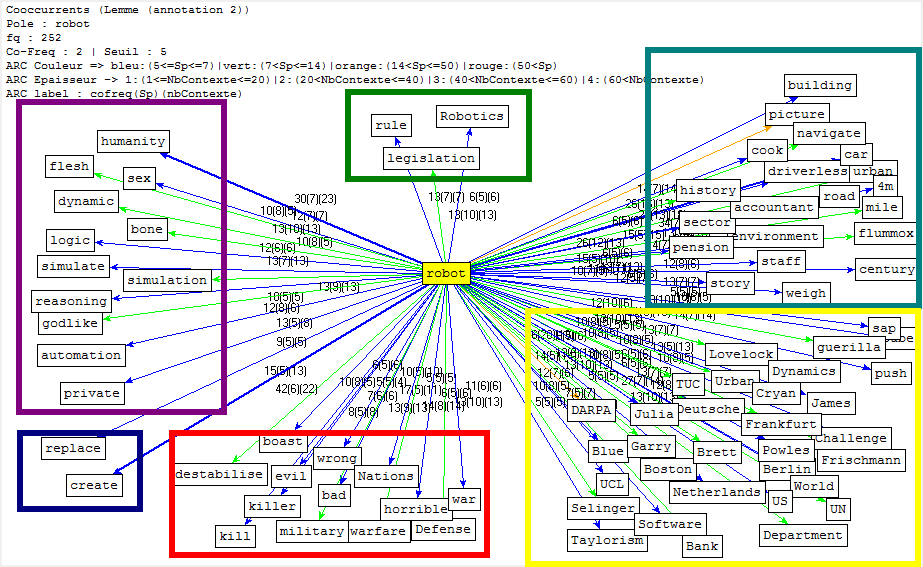
CHINOIS
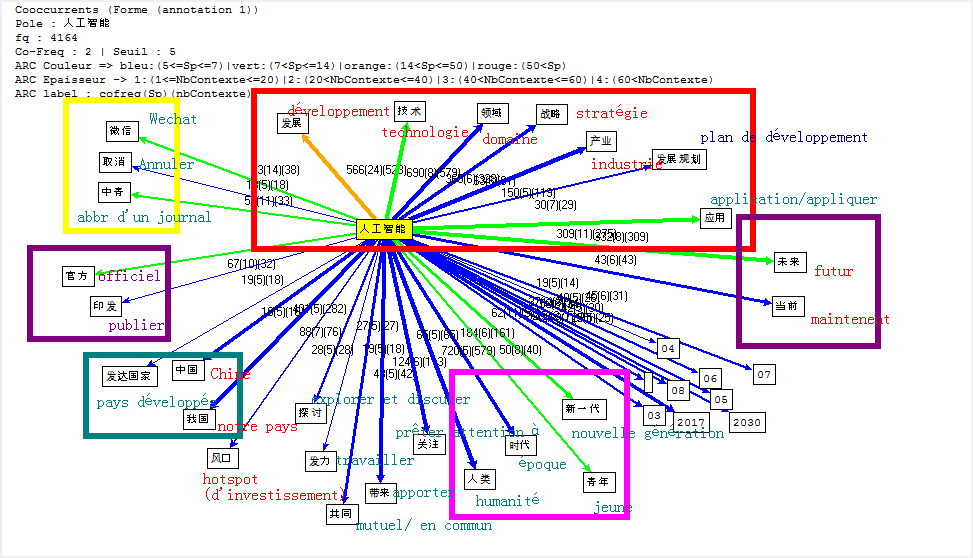
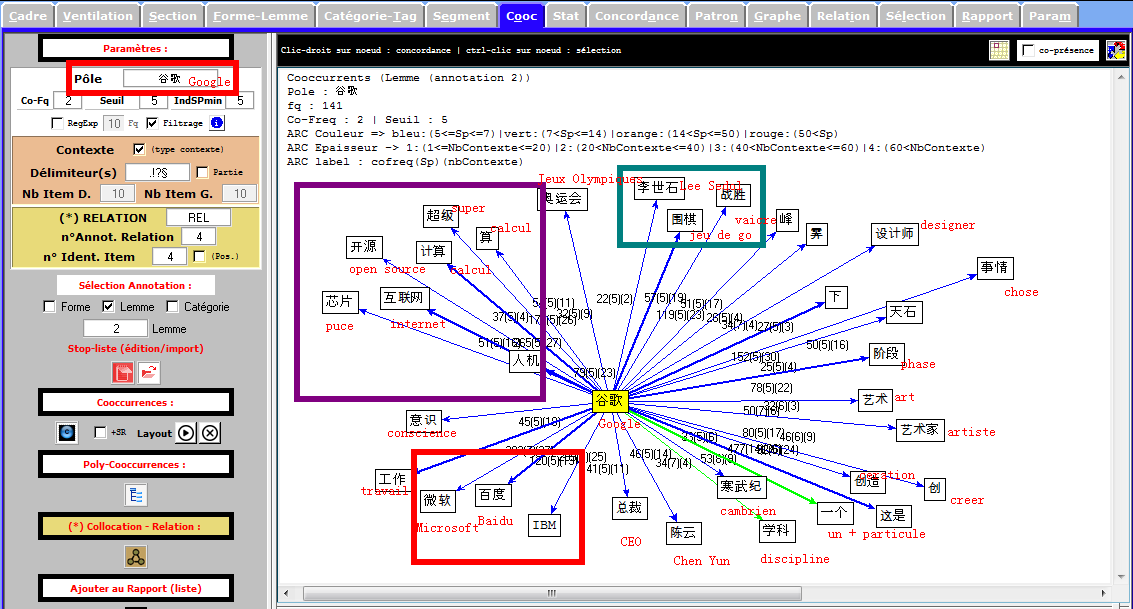
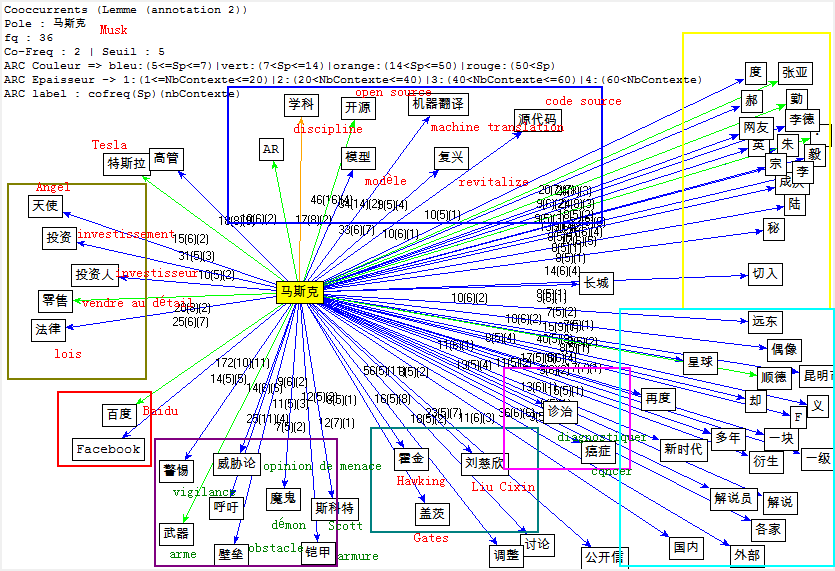
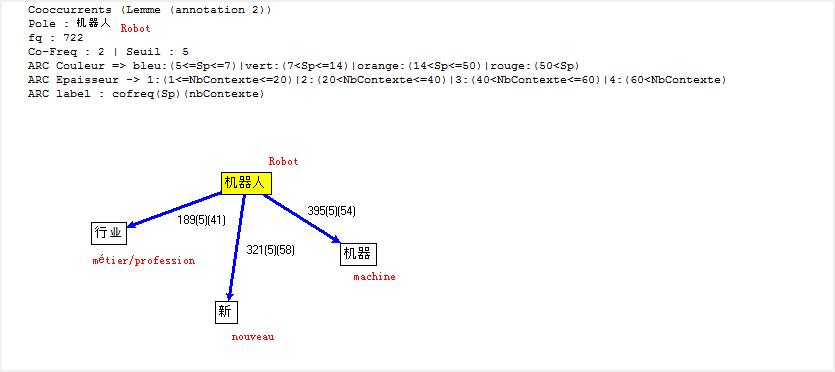
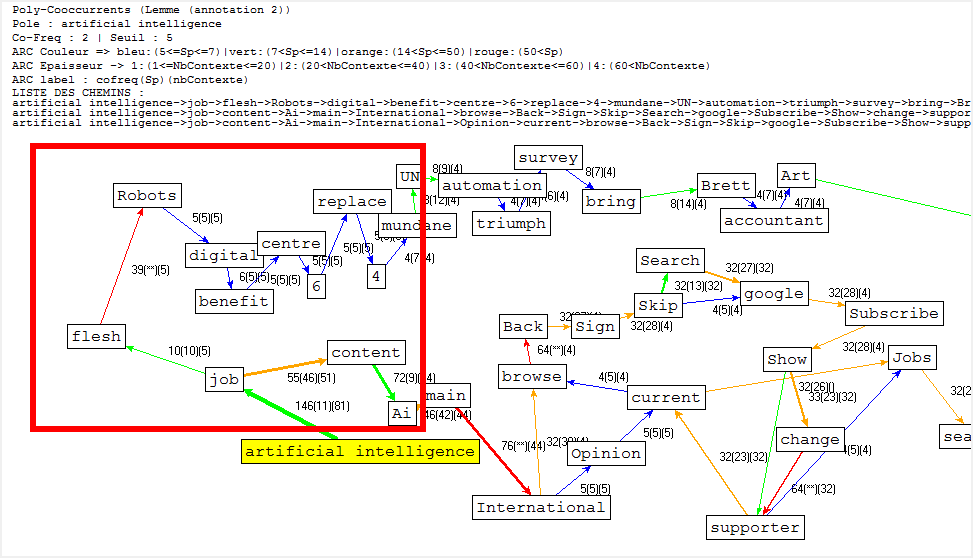
Faute de performance de machines, il nous manque malheuresement le calcul de certaines poly-cooccurrences.