MÉTHODES
CORPUS
i. notions générales
1.1 Qu’est-ce qu'un corpus ?
La définition de corpus a fait l’objet d’une polémique depuis longtemps parmi des linguistes. Avant la construction de notre corpus, il convient de clarifier ce concept en tenant compte de différents opinions :
A collection of linguistic data, either written texts or a transcription of recorded speech, which can be used as a starting-point of linguistic description or as a means of verifying hypotheses about a language. (Crystal, 1991)
…selected and ordered according to explicit linguistic criteria in order to be used as a sample of the language (Sinclair, 1996)
A well-organized collection of data (McEnery, 2003)
un regroupement structuré de textes intégraux, documentés, éventuellement enrichis par des étiquetages, et rassemblés : (i) de manière théorique réflexive en tenant compte des discours et des genres, et (ii) de manière pratique en vue d’une gamme d’applications (Rastier, 2005)
There are many ways to define a corpus […] but there is an increasing consensus that a corpus is a collection of (1) machine readable (2) authentic texts (including transcripts of spoken data) which is (3) sampled to be (4) representative of a particular language or language variety. (McEnery et al., 2006)
La divergence d'opinions nous n’empêche pas de récupérer l’essentiel d’un corpus : d’être authentique, structuré, représentative et de bon échantillonnage pour un objectif précis.
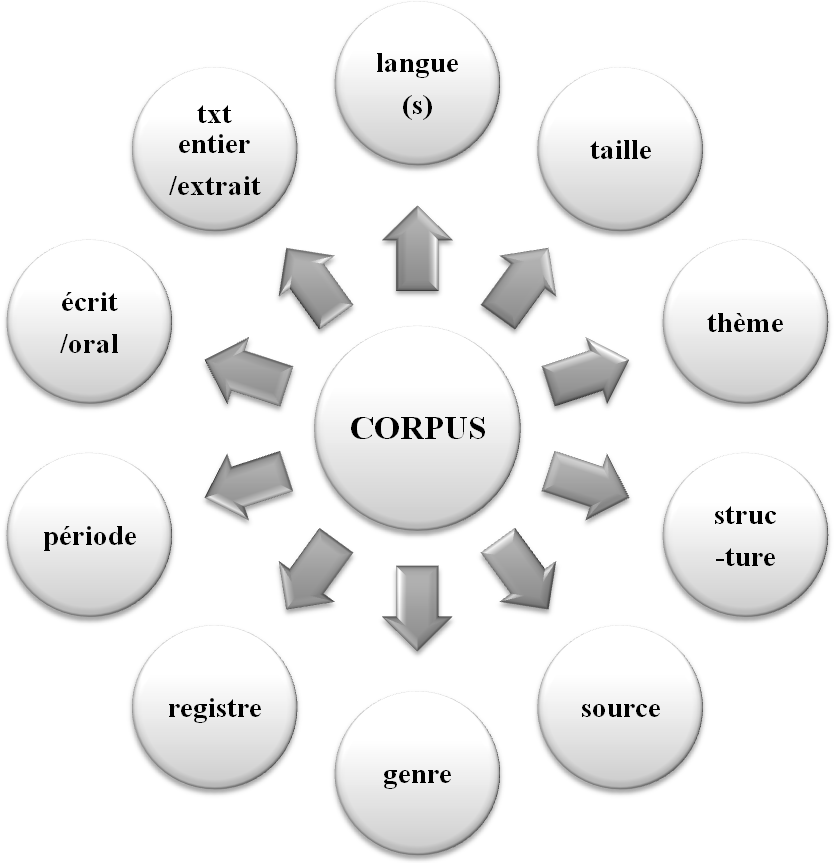
1.2 Typologie de corpus
Les corpus peuvent être classées selon plusieurs critères :

1.3 Caractéristiques de corpus
Plusieurs caractéristiques sont à prendre en compte pour la création d'un corpus bien formé :
ii. construction
2.1 Démarches de construction de corpus
Il s’agit des principaux enjeux concernant la construction de corpus et des étapes à suivre :
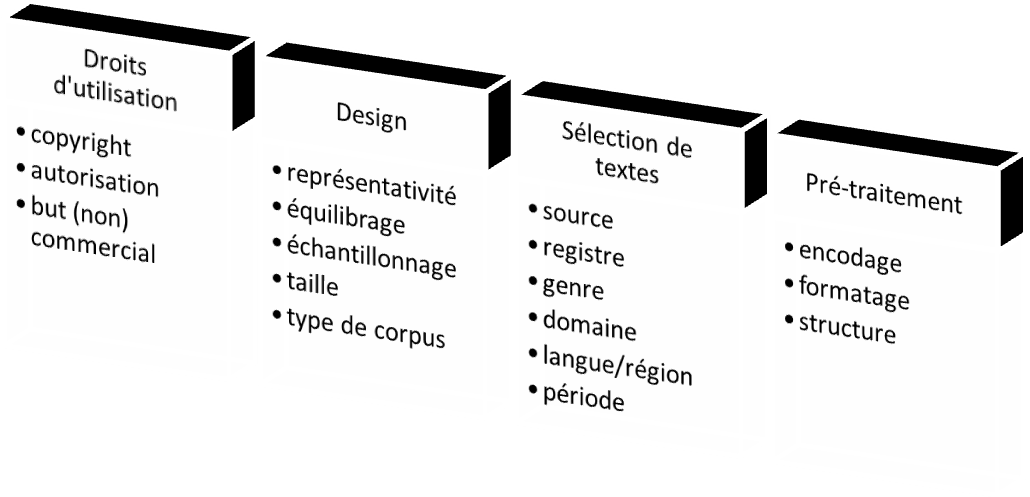
2.2 Design
Représentativité
A corpus is thought to be representative of the language variety it is supposed to represent if the findings based on its contents can be generalized to the said language variety (Leech, 1991)
Cependant, la représentativité est une notion assez fluide selon des objectifs de recherche. Un corpus pour représenter entièrement une certaine langue est par définition différent de celui pour analyser spécifiquement un phénomène vu dans la presse d’une langue.
La représentativité d’un corpus est déterminée par l’échantillonnage et l’équilibrage.
-
Echantillonnage
Les trois éléments fondamentaux d’échantillonnage :

2.3 Sélection de textes
-
Réseaux sociaux, forums, blogs, et presse : quelle source choisir pour le corpus ?
Selon la méthodologie de construction de corpus et les objectifs du projet, nous avons dans un premier temps délimité notre cadre général de travail : la presse, car des articles journalistiques sont assez homogènes au niveau de registre.
A propos d’autres types de ressources en ligne, tels que réseaux sociaux, forums, blogs, wiki, etc, il n’est pas facile de trouver des « équivalents » dans les trois langues de travail. Pour que le corpus soit « comparable » aux niveaux de registre et de genre, le choix était fait ainsi.
Il y a quand même un paradoxe : il est inévitable de faire une sélection pour constituer un corpus homogène et représentatif, mais la sélection entraîne des modifications sur des données observées.
-
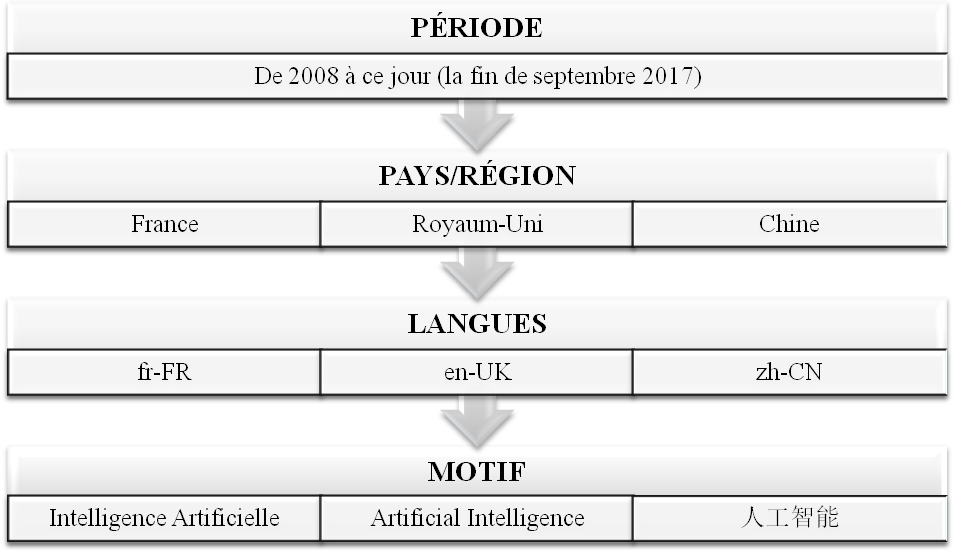
Quel pays/région ?
Chacun de nos trois langues de travail connaît de nombreuses variétés régionales.
Le français
Etudiant(e)s non francophone, nous trouvons le français de France le meilleur choix. Le Québec, le Belgie et la Suisse ont chacun au moins deux langues officielles. Cela nous poserait deux problèmes majeures : 1) il est probable que le français n’est pas la langue maternelle pour l’auteur d’un texte ; 2) il n’est pas évident si un texte est original ou traduit.
L’anglais
Nous avions hésité entre l’anglais américain et l’anglais britanique. Le choix était facilement fait car l’accès à la presse états-unienne (de qualité) en ligne était limité : payant, sous condition d’enregistrement, etc, alors que l’accès est assez libre au Royaume-Uni.
Le chinois
Il est évident que le chinois (simplifié) le plus représentatif et le plus vivant est en Chine continentale.
-
Quelle période ?
Nous avons utilisé Google Trends et Baidu Index pour déterminer la période des données brutes.
Voir ci-dessous les paramètres de recherche :
Voir ci-dessous les figures de recherche :
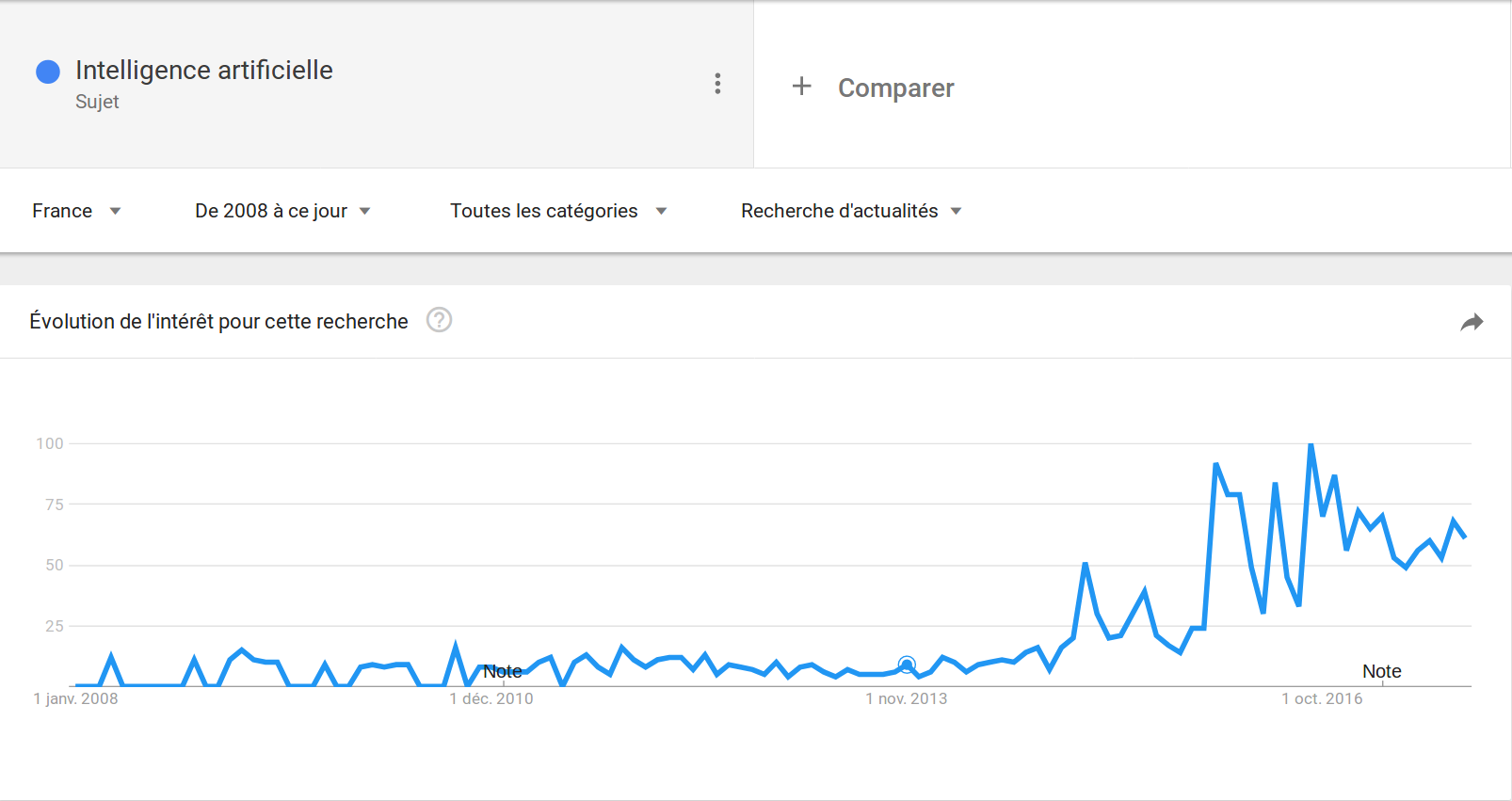
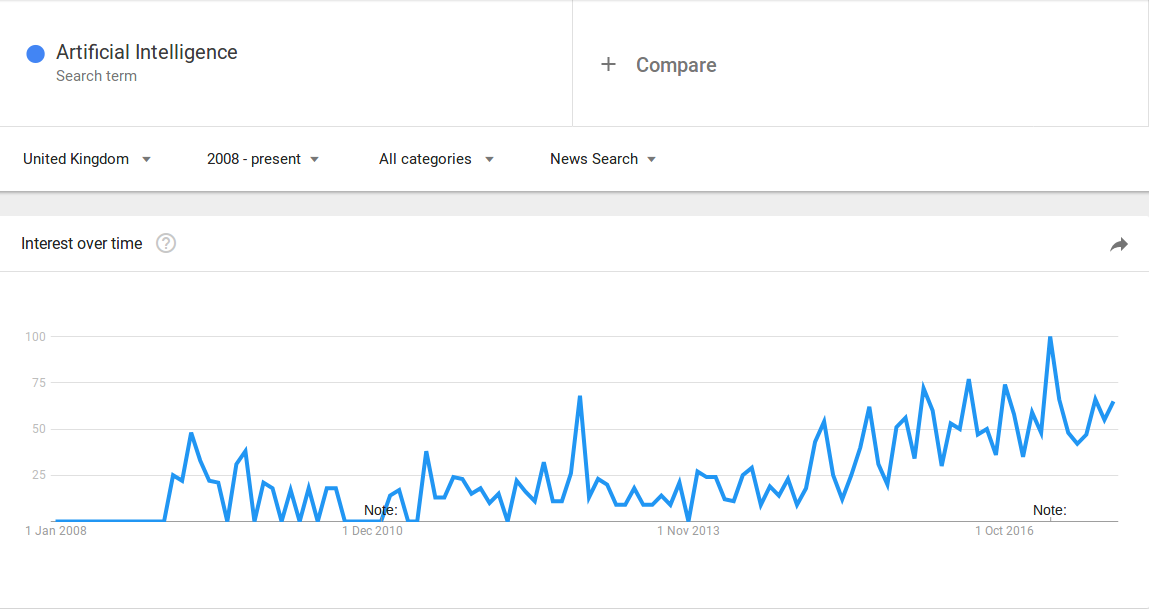
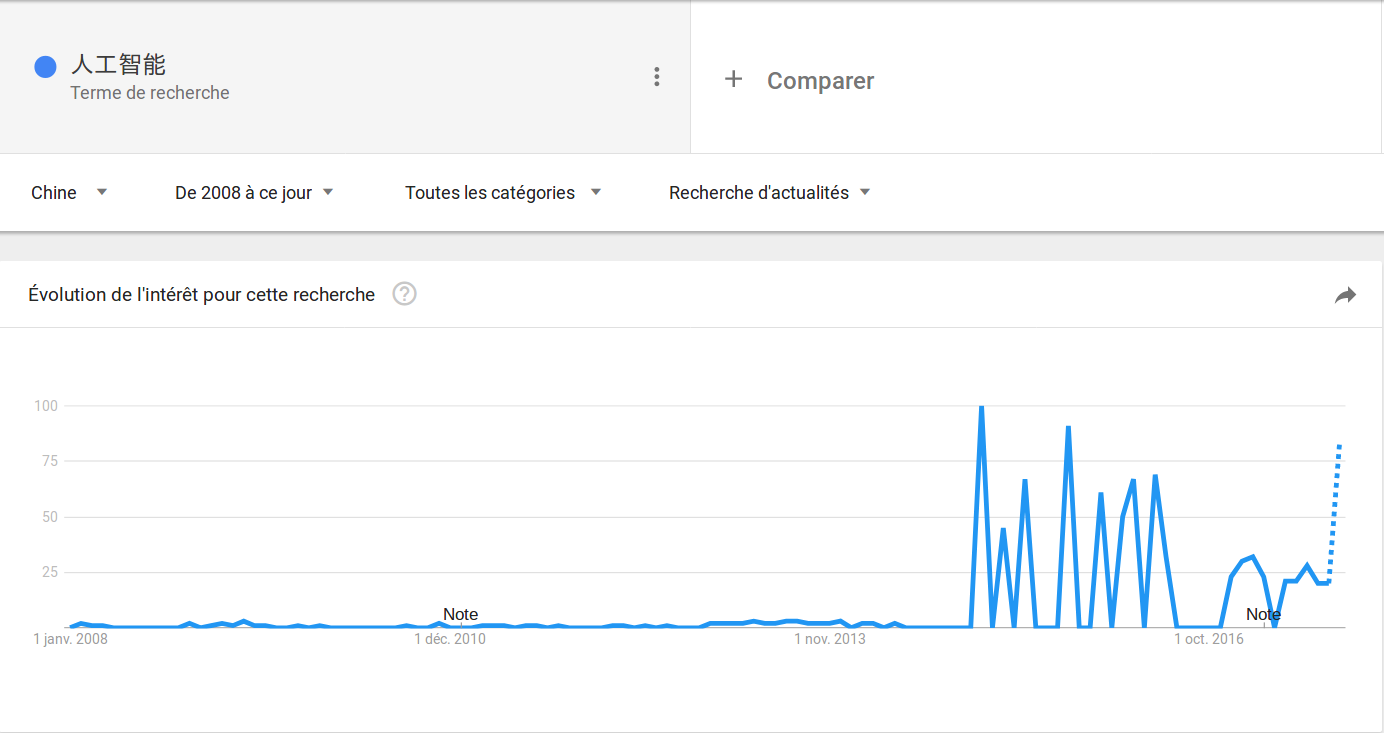
Grosso modo, l’intérêt pour ce thème en Google commençait en 2014, 2009 et 2014 respectivement en France, au Royaume-Uni et en Chine.
Mais, il est uncertain que le résultat pour le chinois soit fiable car le moteur de recherche le plus utilisé en Chine est Baidu au lieu de Google. Nous avons donc tésté cette requête avec Baidu Index (plus ou moin parail que Google Trends). Le résultat est similaire.
Voir ci-dessous la figure obtenue par Baidu Index :

La période est donc décidée : de 2014 à 23/09/2017 (le jour où nous avons commencé la collection des données).
-
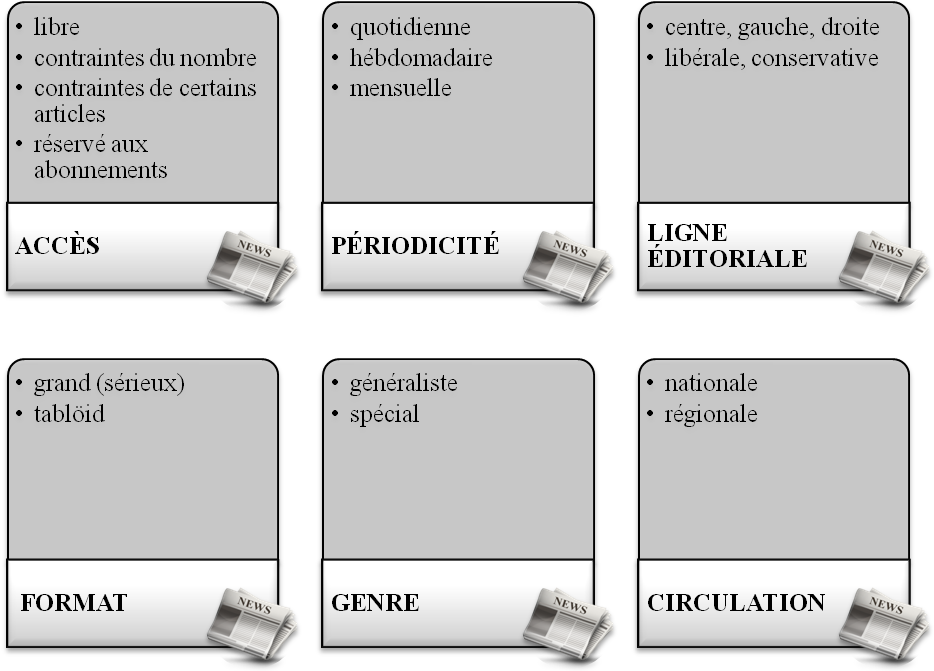
Quelle presse ?
Chaque presse a sa propre ligne éditoriale, et eventuellement son lectorat spécifique. Ainsi, elle a tendance à utiliser des tournures spécifiques sur certain thème, surtout les sujets controversés comme l’intelligence artificielle. Pour équilibrer nos données, nous avons choisi pour chaque langue trois sites de journaux. Voir ci-dessous les critères de nos choix :
-
Quelle distribution / taille ?
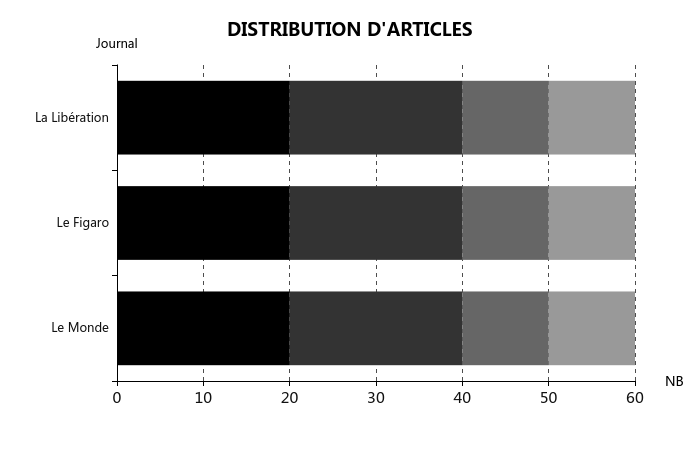
Nous avons distribué des poids pour des années différentes car l’intêret pour IA a tendence d’augementer. Il est logique que 2017 a un poids plus lourd que celui de 2014.
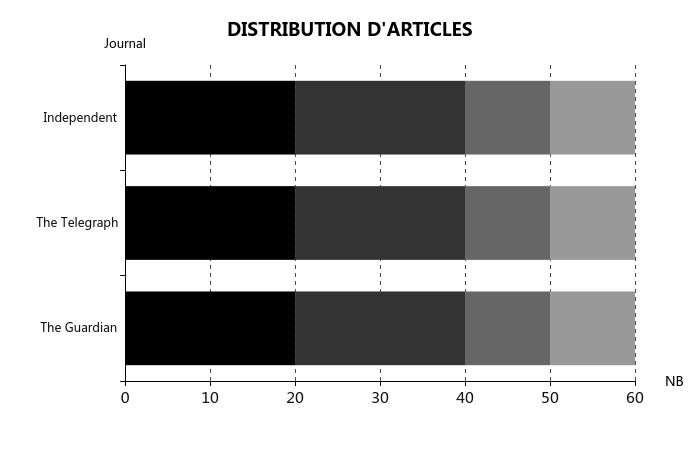
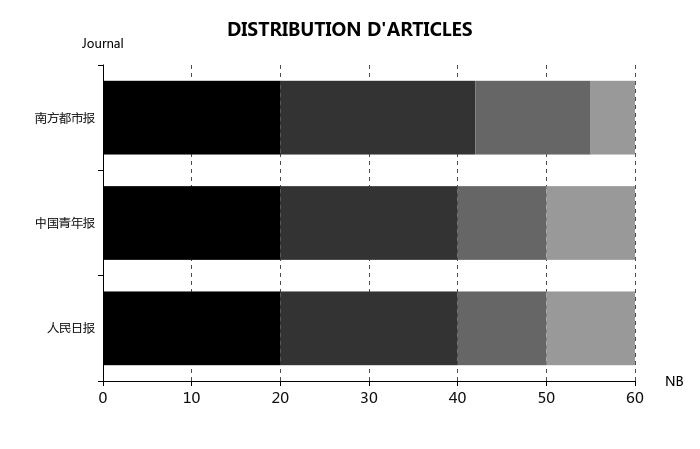
PROPORTION 2014 : 2015 : 2016 : 2017 = 1 : 1 : 2 : 2
Pour chaque journal, 10 unités pour 2014 est assez propre. Donc,
NOMBRE D'ARTICLES 2014 : 2015 : 2016 : 2017 = 10 : 10 : 20 : 20
Pour chaque langue,
NOMBRE D'ARTICLES 2014 : 2015 : 2016 : 2017 = 30 : 30 : 60 : 60
Nous avons 180 unités au total pour chaque langue. De plus, il faut essayer d’équilibrer au sein d’une année.
Voir ci-dessous la distribution d'articles :
2.4 Corpus brut
Dans cette partie, nous aimerons présenter les caractéristiques de notre corpus brut (ou plutôt de l’archive sans prétraitement).
| Journal | Accès | Périodicité | Ligne éditoriale | Format | Genre | Circulation |
|---|---|---|---|---|---|---|
| Le Monde | contraites de certains articles | quotidienne | centre-gauche | grand (sérieux) | généraliste | nationale |
| Le Figaro | contraites de certains articles | quotidienne | droite gaulliste, libérale, conservatrice | grand (sérieux) | généraliste | nationale |
| La Libération | contraites de certains articles | quotidienne | gauche | tablöid (mais sérieux) | généraliste | nationale |
| The Guardian | libre | quotidienne | social-libéralisme (centre-gauche) | grand (sérieux) | généraliste | nationale |
| The Daily Telegraph | libre | quotidienne | conservatrice (centre-droite) | grand (sérieux) | généraliste | nationale |
| Independent | libre | quotidienne | libérale (centre-gauche) | tablöid (mais sérieux) | généraliste | nationale |
| 人民日报 | libre | quotidienne | socialisme avec des caractéristiques chinoises | grand (sérieux) | généraliste | nationale |
| 中国青年报 | libre | quotidienne | non précise | grand (sérieux) | généraliste | nationale |
| 南方都市报 | libre | quotidienne | quasi-libérale | tablöid (mais sérieux) | généraliste | *régional |
2.5 Pré-traitement
Voir la partie SCRIPT.
iii. bibliographies et références
- Crystal, D. (1991). A dictionary of linguistics and phonetics
- Leech, G. (1991). "The state of the art in corpus linguistics", in Aijmer K. and Altenberg B. (eds.) English Corpus Linguistics: Studies in Honour of Jan Svartvik, pp 8-29. London: Longman.
- McEnery, T., & Wilson, A. (2003). Corpus linguistics. The Oxford Handbook of Computational Linguistics, S, 448-463.
- Rastier, F. (2005). Enjeux épistémologiques de la linguistique de corpus. La linguistique de corpus, 31-45.
- Sinclair, J. (1996). Preliminary recommendations on corpus typology. EAGLES Document TCWG-CTYP/P (available from http://www.ilc.pi.cnr.it/EAGLES/corpustyp/corpustyp.html).
- Tartier, A. Construction et exploitation de corpus. (disponiblesur http://francia2.unideb.hu/sites/default/files/diapos_corpus.pdf).
OUTILS
i. systèmes d'exploitation
Dualboot ou virtualisation?
Comme le projet porte sur le traitement de données en utilisant plusieurs outils, il nous faut alterner entre deux systèmes d’exploitation (Linux et Windows). Toutefois, il nous semble que nos ordinateurs n’assurent pas une performance satisfaisante de machine virtuelle. Nous avons donc décidé de travailler tous les deux en dual boot en raison de moins d’exigences du matériel. Donc, notre environement de travail est :
Linux (distribution:Ubuntu 16.04 LTS) + Windows 8.1 [DUAL BOOT]

ii. langage de script : BASH
![]()
iii. traitement des données
3.1 Tree-tagger
Afin de construire un index et de calculer le TTR, nous avons utilisé le tree-tagger pour lemmatizer des tokens.
3.2 Tokenizer de chinois : SCWS
La segmentation de textes chinois joue un rôle important dans le traitement automatique de la langue chinoise. Dans ce projet, visant à un corpus de qualité, nous avons testé et évalué plusieurs tokenizers de chinois.
Pour voir plus de tokenizers que nous avons testés, cliquez ici.
3.3 minigrepmultilingue
iv. Le Trameur
Nous avons utilisé Le Trameur pour traiter les données, analyser le corpus et présenter les résultats.
Voir la partie TRAMEUR.
Pour plus d'information concernant Le Trameur, veuillez consulter le site officiel.
v. Construction de site
5.1 Langages : HTML+CSS

5.2 Éditeur : Bluefish

5.3 Test de performance (sous divers navigateurs) : Browserling
Afin de tester notre site sur browserling, nous avons hébergé le site sur notre Github en utilisant Github Pages (https://win-gin.github.io/).
