résultats
nuages
Français
Sans filtrage
Occurrence énorme de lexiques grammaticaux
- le
- les
- un
- et
- etc

Filtrage par le générateur de nuage
Encore occurrence importante de lexiques grammaticaux, le motif devient visible

Filtrage par l'antidictionnaire

Anglais
Sans filtrage
Occurrence énorme de lexiques grammaticaux
- and
- for
- be
- in
- etc

Filtrage par le générateur de nuage
Moins de lexiques grammaticaux, le motif devient visible

Filtrage par l'antidictionnaire
le motif et ses cooccurrents deviennent significatifs

Chinois
Sans filtrage
Certains mots vides sont enlevés automatiquement, tels que
- 的/地/得(particule structurelle/modale)
- 着(particule)
- 了(particule d'aspect/modale)
- etc
Occurrence de lexiques grammaticaux
- 一个(un + particule)
- 进行(entreprendre, mot très fréquent en chinois)
- etc

Filtrage par le générateur de nuage
Moins de lexiques grammaticaux, le motif devient significatif

Filtrage par l'antidictionnaire
le motif et ses cooccurrents deviennent significatifs

analyses
Après avoir récupéré et prétraité de 540 articles journalistiques dans les trois langues de travail, nous disposons d’un corpus multilingue que nous considérons comme un échantillon représentatif de la presse française (France), anglaise (Royaume-Uni) et chinoise (Chine continentale) dans le domaine de l’intelligence artificielle.
Nous nous permettons de procéder à une analyse comparative en profitant des résultats issus du prétraitement, des nuages et du Trameur. Il convient de commencer par une éclaircissement de certaines opérations que nous avons choisies au fil du projet ; nous nous pencherons ensuite sur une description statistique et sur une analyse linguitique.
Prétraitements
Les prétraitements comprennent le nettoyage de « meta-données », la segmentation de textes chinois, la formalisation des phrases, la normalisation des mots, ainsi que le filtrage des mots indésirables.
Nettoyage de « meta-données »
Il est indéniable que les textes provenant d’Internet sont assez difficile à « nettoyer » car il y existe de nombreuses informations hors sujet, telles que des noms de rubriques, des listes des articles récentes, des publicités, etc. La plupart de ces informations sont régulières et faciles à supprimer dans la phase de prétraitement (cf les fonctions que nous avons créées dans la partie SCRIPT) ; tandis que les meta-données « en fuite » sont enlevées au fur et à mesure dans les calculs de nuages et avec le Trameur. Il s’agit d’un processus par essai et erreur.
Segmentation de textes chinois
La segmentation de textes chinois joue un rôle important dans le traitement automatique de la langue chinoise. Dans notre projet, il est indispensable d’obtenir un « bon » corpus pour éviter le garbage in, garbage out.
Dans les langues telles que l'anglais ou le français, les mots sont généralement séparés par des espaces, ce qui simplifie la segmentation des phrases. Cependant, en chinois, la langue écrite est composée de caractères qui ne sont pas délimités, ce qui rend la symbolisation des mots difficile.
Nous optons pour le tokenizer SCWS pour en faire. Cet outil nous permet de paramétrer le dictionnaire en lui fournissant de nouveaux mots, leur étiquette selon le jeu d’étiquettes de l’Université de Pékin, et leur TF (term frequency) et IDF (inverse document frequency). Le détail, ainsi que d’autres outils de segmentation sont disponibles dans notre blog.
Formalisation des phrases
Les textes issus d’Internet comprennent des line wraps automatiques et prédéfinis. Cela parfois découpe notre motif en deux : le premier mot a la fin d’une ligne, et le suivant au début de la prochaine ; alors que les traitements en bash se limitent souvant au sein de lignes. Pour y résoudre et ne manquer aucune occurrence, nous découpons le texte « syntaxiquement », c’est-à-dire que nous modifions les passages à la ligne en considérant des signes de ponctuation de fin de phrase (cf les fonctions dans la partie SCRIPT).
Normalisation des mots
La normalisation des mots permet de les catégoriser sous leur forme sous-jacente. Il existe en général deux types : la racinisation et la lemmatisation.
Nous optons pour le dernier qui rend les mots sous leur forme à l’infinitif. Cela réduit la taille de notre vocabulaire. Nous l’avons réalisée dans la phase de prétraitement à l’aide de tree-tagger. Lors de l’analyse avec le Trameur, nous l’avons également utilisé.
Filtrage des mots indésirables
Selon la loi de Zipf, la plupart des mots les plus fréquents d’un corpus ne comportent peu d’information sur le sujet. Pour une analyse liée étroitement à notre thème, il convient de supprimer ces mots vides par un antidictionnaire.
Dans nos antidictionnaires, il existe deux types de mots vides : des mots indépendants du thèmes (le, de, par, etc) ; et des mots dans les domaines de site d’Internet (par exemple, BOUTON, RETURN) et de la presse (par exemple, le Monde, le Figaro, Jardinage, Orthographe).
Description statistique
| FRANÇAIS | ANGLAIS | CHINOIS | |
|---|---|---|---|
| Nombre d’unités | 180 | 180 | 180 |
| Nombre d’occurences formes | 78 060 | 59 084 | 152 646 |
| Nombre de formes | 9 886 | 7 140 | 11 243 |
| Nombre d’hapax | 5 211 | 3 166 | 3 254 |
| Forme maximal | de | the | 的(de, particule) |
| Forme maximale après filtrage | intelligence artificielle | artificial intelligence | 人工智能 |
Hapax / formes ratio
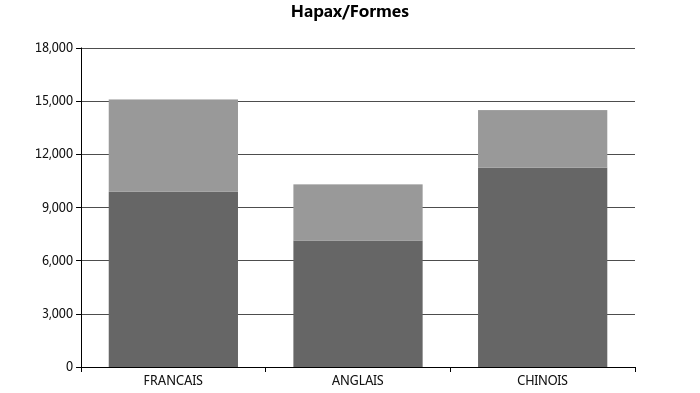
En vue, notre corpus chinois a une vocabulaire la plus riche, ce résultat est peu fiable car le nombre de formes et d’hapax du corpus chinois dépend de la granule prédéfinie par la segmentation.
Analyse linguistique
Dans cette partie, nous combinons les résultats du prétraitement, des nuages et du Trameur pour comparer non seulement entre les trois langues, mais aussi au sein d’une langue.
Equivalent
Au niveau lexique, nous constatons que beaucoup de mots/notions qui ont un nombre d’occurrences important portent le même sens. Il est interessant de voir que la presse dans les trois langues a tendence de discuter autour d’un même débat : la relation entre l’homme et la machine, ainsi que l’influence de robots sur l’emploi.
De plus, chaque langue parle de menace de robots en citant des arguments d’Elon Musk, selon nos analyses de (poly-)cooccurrence avec le Trameur.
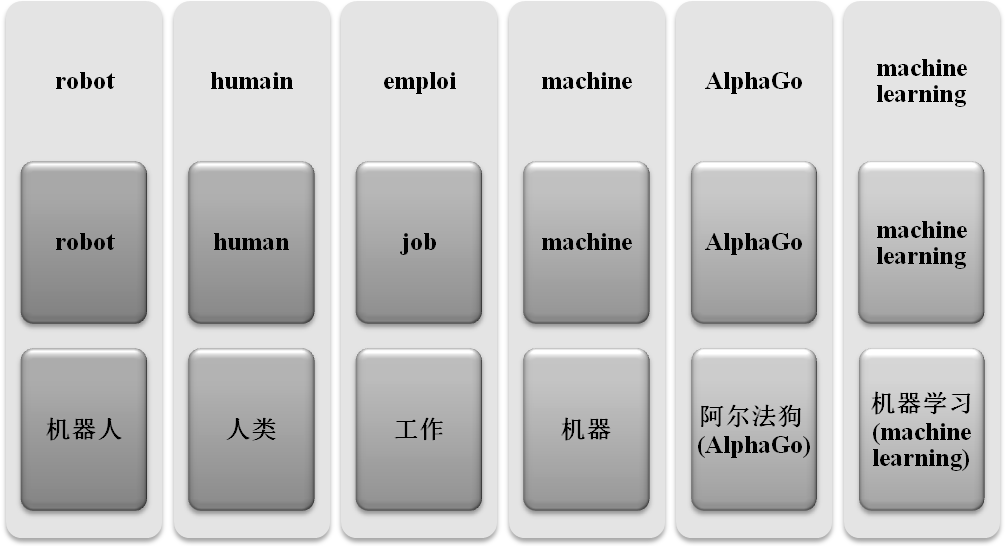
Similaire (dans le même champ lexical ou équivalent dans deux langues)
En anglais et en français, la presse couvre des actualités dans le monde, notamment aux Etats-Unis (sur AlphaGo, DeepMind, Facebook, etc), tandis qu’en chinois, la presse ajoute aussi beaucoup d’actualités en Chine, qui vise des géants technologiques chinois (Tencent, Baidu, Alibaba, etc) et la politique nationale du développment du domaine. La ventilation des sociétés que nous avons faite avec le Trameur peut démontrer cette constatation.
A propos de la technologie liée à l’intelligence artificielle, la presse anglaise et française porte surtout au niveau général (deep learning, machine learning) ; alors que la presse chinoise préfère aussi 语音识别(reconnaissance de paroles), 人脸识别(reconnaissance de visages), 移动互联网(web mobile), etc. De plus, en ce qui concerne le « 机器人 »(robot) en chinois, la cooccurrence nous montre que la presse s’intéresse aussi sur le domaine médical, que montrent les cooccurrents « 诊断 »(diagnostic) et « 癌症 »(cancer).

Divers
A part des variations thématiques, il existe bien sûr une différence qui est intrinsèque de la langue. Il s’agit notamment de l’occurrence de verbes et de la répétition de substantifs.
Selons nos observations des catégories grammaticales étiquettées par le tree-tagger dans le Trameur (français et anglais), le substantif est plus fréquent que le verbe. Théoriquement, le cas est au contraire en chinois, mais nous ne disposons pas de statistique sur ce trait (cela peut être réalisé en faisant une analyse morphosyntaxique de surface sur notre corpus avec d’autres outils et en ajoutant cette couche d’annotation dans le Trameur).
Par ailleurs, selon la ventilation sur le VER_futu (futur) et le VER_pres (présent) dans le corpus français, le Monde (le premier tiers des partitions) et la Libération (le troisième tiers) utilisent beaucoup plus de verbes dans le futur que dans le présent. Ce n’est pas tout à fait convaincant car il manque une analyse sur l’ensemble des verbes (cela est faisable aussi par une analyse morphosyntaxique de surface). Pourtant, cela ne veut pas dire que ce résultat soit inutile car il peut servir comme un trait à la classfication automatique (supervisée) des articles (par exemple, catégorisation par journal).