Le script détaillé
Pour réaliser notre étude, nous avons créé un script Bash.
Sur cette page, vous trouverez une lecture de notre script ainsi qu'une présentation des différentes commandes que nous avons utilisées.
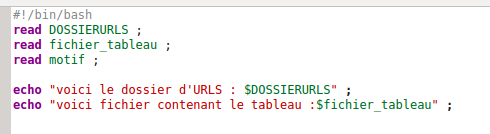
La première partie du script consiste à lire le dossier contenant les fichiers d'URLS, le fichier tableau ainsi que le motif grâce au fichier de paramètres.

Nous allons maintenant créer la structure des tableaux. Pour cela nous initialisons tout d'abord un compteur pour les tableaux (cpttableau). Nous créons ensuite une première boucle "for" (for fichier in `ls $DOSSIERURLS`) qui va nous permettre de prendre tour à tour chaque fichier d'urls qui se trouvent dans le dossier d'urls. Nous initialisons un deuxième compteur (compteur) permettant de compter chaque url contenues dans les fichiers d'urls. Enfin, nous créons, dans le fichier tableau, la structure de base du tableau à 10 colonnes que le programme viendra remplir lors de son exécution.
Rappel html:
- Balise "table" : création d'un tableau.
- Balise "tr" : création d'une ligne dans le tableau.
- Balise "td" : création d'une colonne dans le tableau.
- align="center" : alignement au centre.
- border="2" : épaisseur de la bordure du tableau, ici 2 pixels.
- colspan="10" : utilisé dans la balise "td" pour indiquer le nombre de colonnes qu'elle recouvre, ici 10 colonnes.
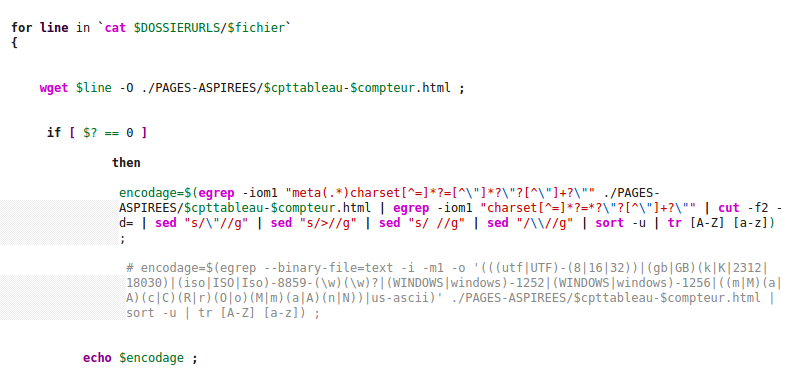
Nous créons ensuite une seconde boucle "for" (for line in `cat $DOSSIERURLS/$fichier`) qui va permettre de prendre une à une les lignes du fichier d'urls.
Nous pouvons a présent passer à l'aspiration des pages internet. Pour cela nous utilisons la commande wget. Nous lui demandons d'aspirer le contenu de chaque pages internet et de les enregistrer dans des fichier html.
Nous pouvons à présent chercher l'encodage de chaque pages aspirées. La commande file -i n'étant parfois pas très fiable, nous avons choisi de ne pas l'utiliser et d'utiliser à la place la commande egrep qui permet de rechercher une expression régulière et qui va nous permettre de trouver la balise "charset" ainsi que la valeur correspondante dans la page aspirée. Nous utilisons ensuite un cut afin de ne garder que l'encodage.
Nous pouvons voir sur l'image une seconde expression régulière en commantaire. Il s'agit de l'expression régulière que Meryl a choisi d'utiliser et qui fonctionne également très bien.
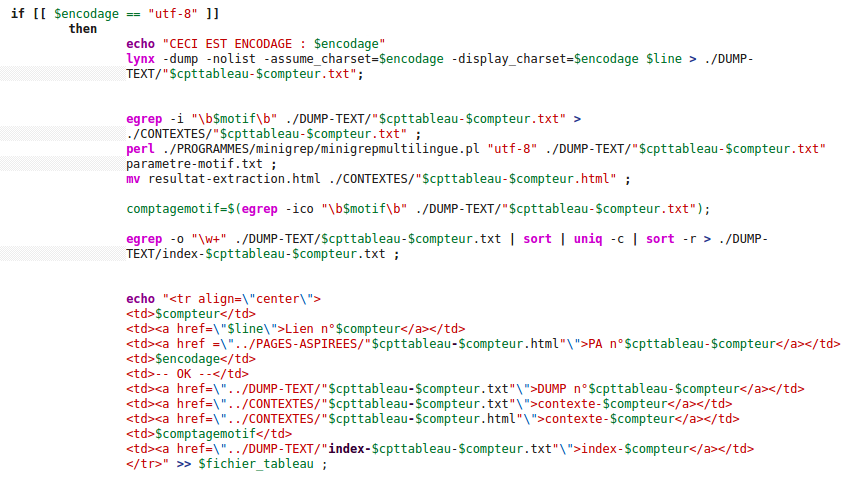
Si la page est encodée en UTF-8 tout va bien, nous pouvons dumper la page grace à la commande lynx -dump et enregistrer ce dump (copie brute) dans un fichier texte.
Grâce à ce dump nous pouvons rechercher le contexte d'un mots qui nous intéresse (motif) et l'enregistrer dans un fichier texte. Nous executons aussi le programme perl Minigrep qui va extraire les contextes dans un fichier au format html qui est bien plus lisible.
Nous comptons le nombre d'occurrences du motif recherché grace à la variable "comptagemotif".
Nous créons également un index du fichier dumpé à l'aide d'un egrep qui va rechercher tous les mots contenus dans le dump et compter le nombre de fois qu'ils apparaissent.
Enfin, nous importons tout cela dans le tableau.
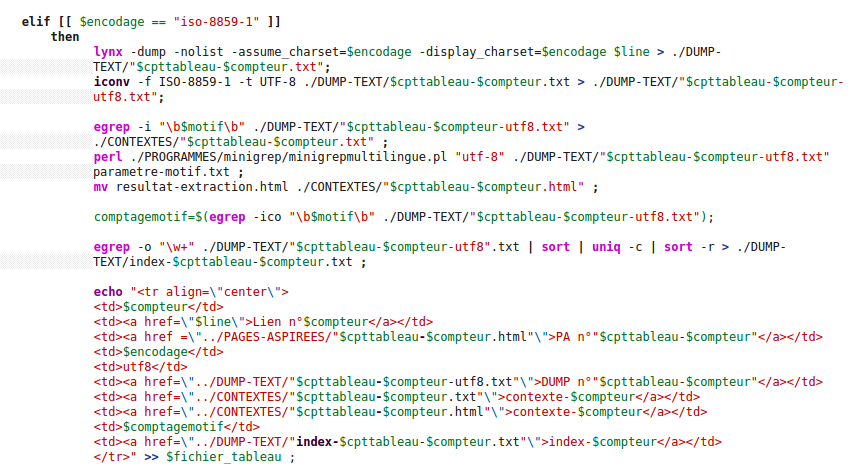
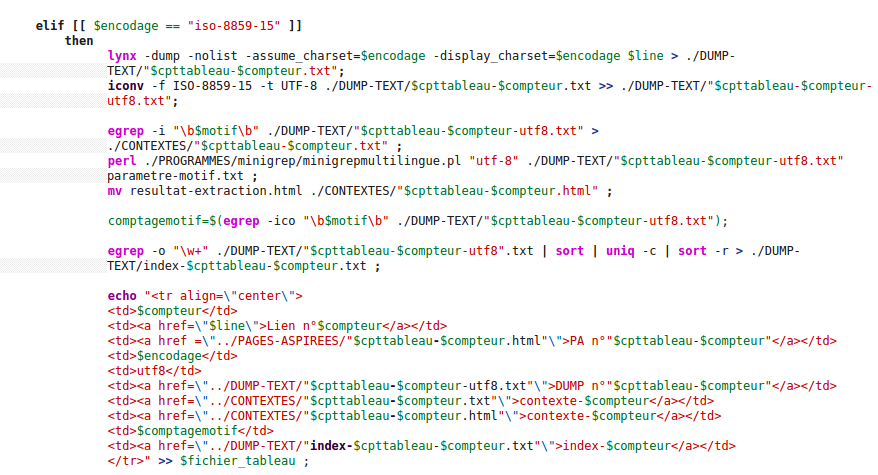
Si la page n'est pas encodée en utf-8 nous alons devoir la convertir en utf-8. Pour cela nous utilisons la commande iconv qui permet de convertir l'encodage d'une page. Ici nous avons convertit des pages encodées initialement en ISO-8859-1 et en ISO-8859-15, mais nous pouvons faire cela pour tous les encodages connus de iconv.
Une fois la conversion effectuée, nous pouvons continuer : extraction des contextes, comptage des occurrences et création de l'index, comme fait précédemment pour les pages en utf-8, puis nous ajontons tout cela à notre tableau.

Si nous ne parvenons pas à récupérer l'encodage de la page dumpé, nous indiquerons dans notre tableau que nous n'avons pas réussi à la convertir.
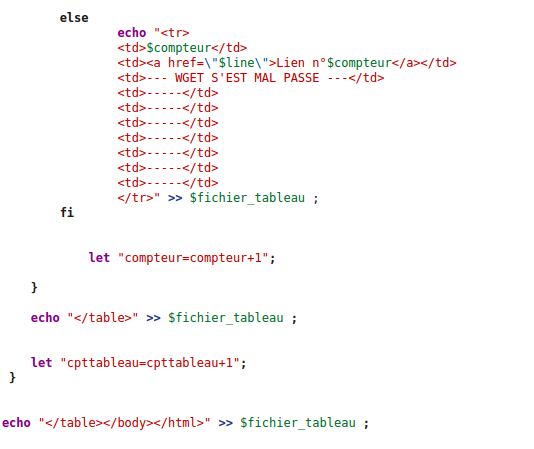
Si l'aspiration s'est mal passé, nous l'indiquons également dans notre tableau.
Enfin nous fermons les boucles et incrémentons les deux compteurs.