Le Trameur
La deuxième phase du projet après la création du tableau html est d’effectuer l’analyse statistique des occurrences et des cooccurrences des formes du mot "mange" ou "nourriture" en anglais, français et arabe puis créer des nuages de ces mots. Nous effectuerons une analyse des mots les plus fréquemment employés à côté de notre motif ( = co-fréquents), en utilisant le logiciel Le Trameur.
Définition du Trameur
On peut pousser encore plus l'analyse de nos données finales grâce à la textométrie, qui nous permet de compter des éléments textuels contenus dans un de nos fichier. Pour ce faire, on vas utiliser un logiciel appelé Trameur développé par M. Fleury. Ce logiciel va tout d'abord considérer notre fichier texte comme un contenant qui regroupe des unités élémentaires, afin de relever des séquences de caractères organisées. On chargera dans le Trameur les fichiers CONTEXTES-GLOBAUX et DUMPS-GLOBAUX de nos trois langues.
Le trameur est un logiciel de textométrie qui fonctionne sur windows.
Le Trameur est composé de deux élément: la Trame et le Cadre. La
textométrie s’occupe du calcul des éléments (des contenus textuels) dans
certaines zones de texte ou parmi des unités d’un texte. La Trame est
un système de coordonnées sur le texte dans lequel chaque élément est
associé à un numéro d’ordre. Elle permet de repérer des zones textuelles
sur un corpus et de décrire les systèmes des zones (parties,
paragraphes, phrases, sections, etc.). Les descriptions sur ces systèmes
se trouvent dans une structure de données : le Cadre. Il faut aussi
mentionner que le Trameur intègre le Treetagger (étiquetage des
catégories grammaticales et lemmatisation).
Le trameur considère
le texte comme un ensemble de positions avec à chaque position une unité
à identifier, tout en ayant la possibilité d’ajouter à chaque position
une annotation (lemme, forme, catégorie,…)
Mode d'emploi
D'abord, il faut charger le texte à étudier via l'onglet 'Cadre',
et ensuite aller dans l’onglet « param » pour préciser au programme qu’on travaille en utf-8, pour choisir la langue de travail et pour rajouter le symbole $ dans les délimiteurs.
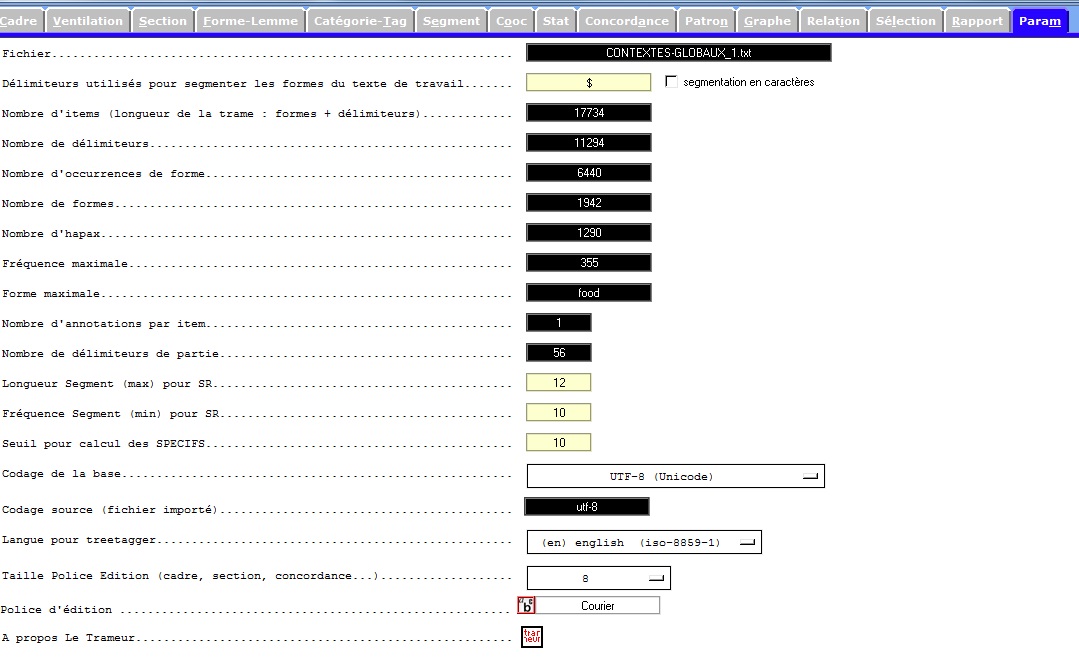
Le fichier global des contextes est le résultat d'une concaténation de lignes contenant les contextes du mot, extraites de plusieurs sites. Chaque ligne correspond à une ligne qui contient le motif. Mais il n'y a pas forécement de la continuation entre les lignes. Il serait erroné de considérer que le texte devrait s'analyser de façon intégrale, sans délimiteurs explicites entre chaque ligne. Ajouter un délimiteur sert à bloquer l'analyse travers les contextes, et à empêcher de trouver
des co-occurrents non pertinents.
Ici, par exemple, nous avons mis le signe “$” à la fin de chaque phrase pour
bloquer les contextes (en faisant attention d'éliminer tous les '$' du
texte avant de l'utiliser en tant que délimiteur).
Fichier Contexte Global Anglais>

Fichier contexte Global Français

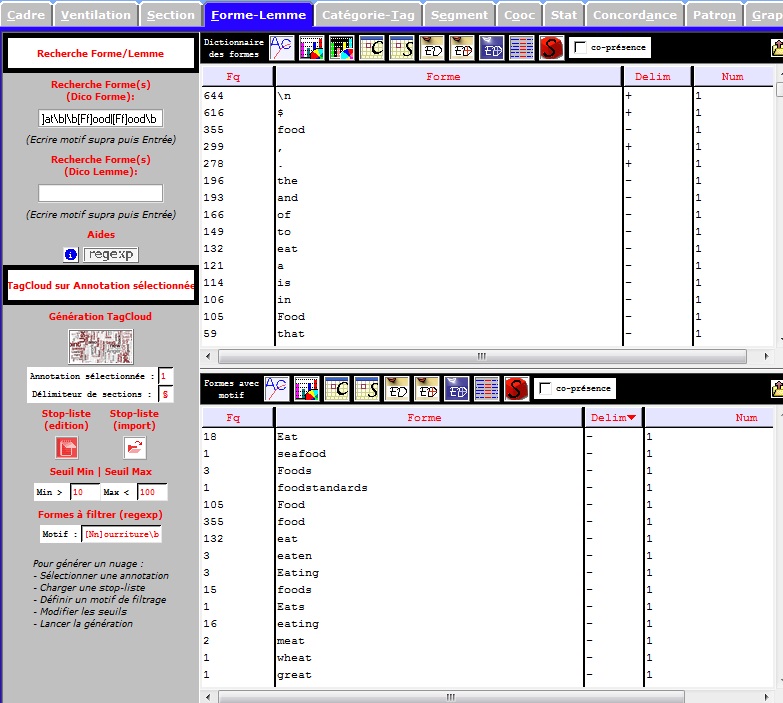
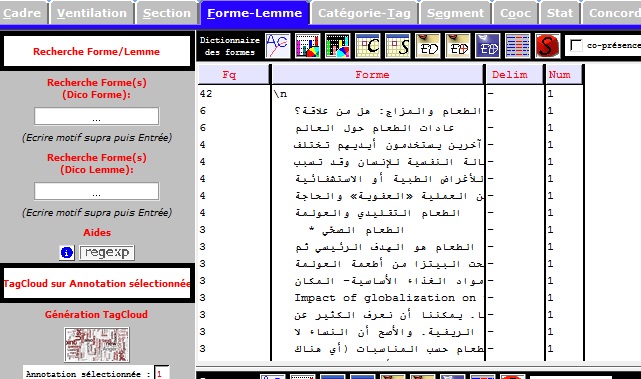
Dans l'onglet Forme-Lemme, dans la partie Recherche forme, on cherche les mots clefs ou le motif avec les regexp.
Le motif en anglais
On cherche les mots " eat" ou "food" ou "nutrition"
\b[Ee]at|[Ee]at\b|\b[Ff]ood|[Ff]ood\b
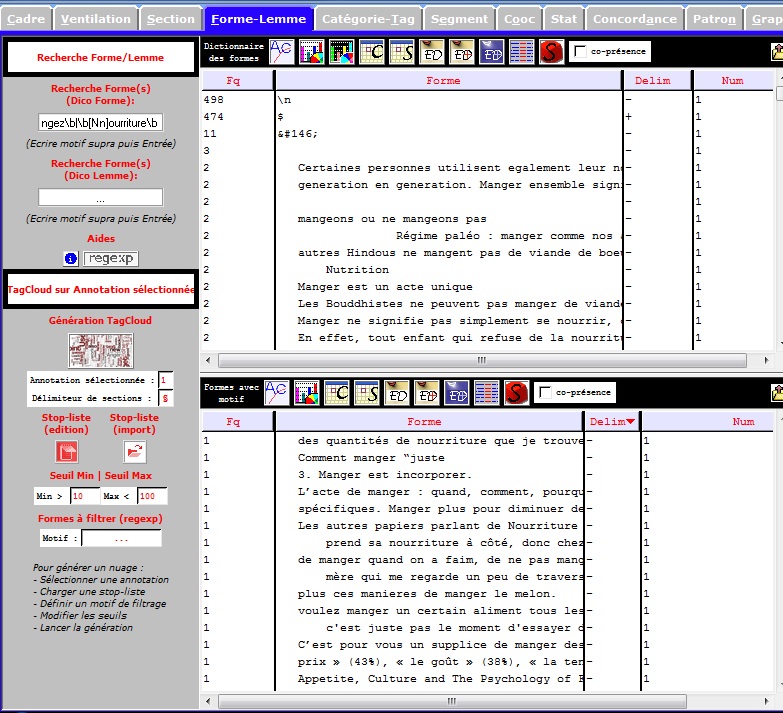
Le motif en français
On cherche les mots: "mange" ou "mangeons" ou "mangez" ou "manger" ou "aliments"
Le regexp est:
\b[Mm]ange\b|\b[Mm]anger\b|\b[Mm]angeons\b|\b[Mm]angez\b|\b[Nn]ourriture\b
Le motif en Arabe
On cherche les mots: "الطعام" ou "نأكل" ou "يأكل" ou "يأكلون"
Le regexp est:
\bنأكل|نأكل\b|\bيأكل|يأكل\b|\bالطعام|الطعام\b|\bيأكلون|يأكلون\b
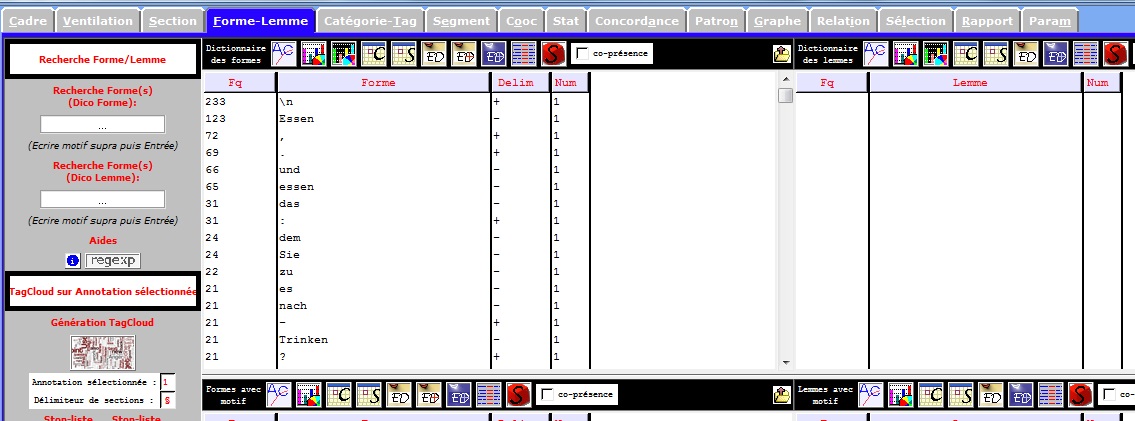
Le motif en Allemand
On cherche le mot: "essen"
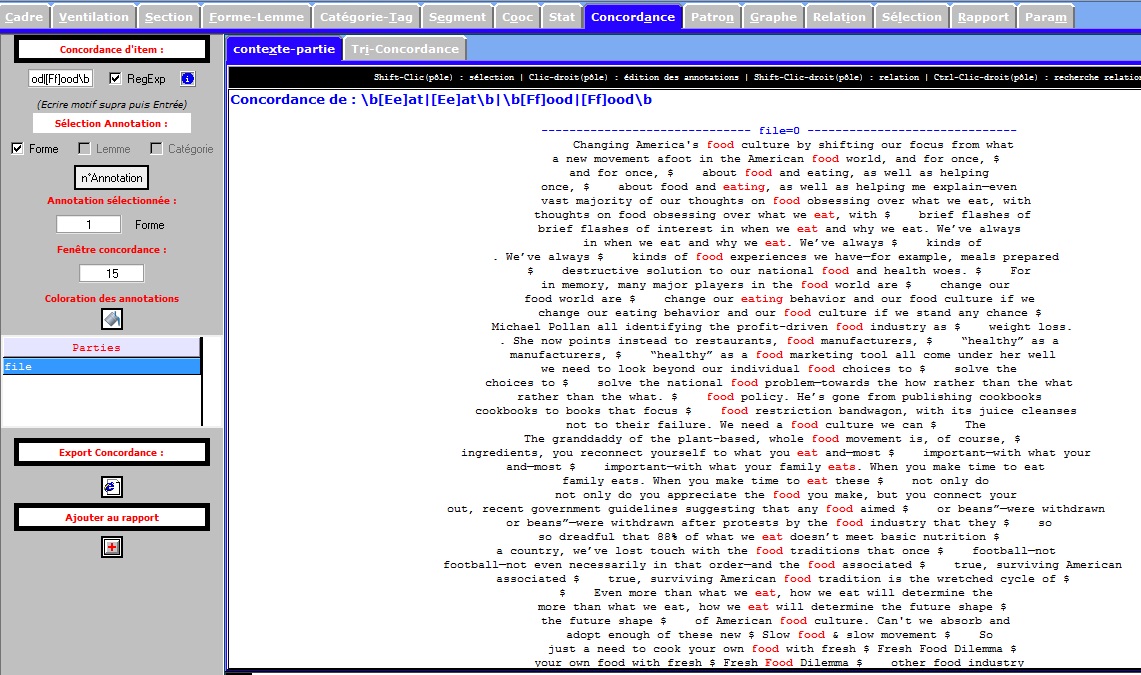
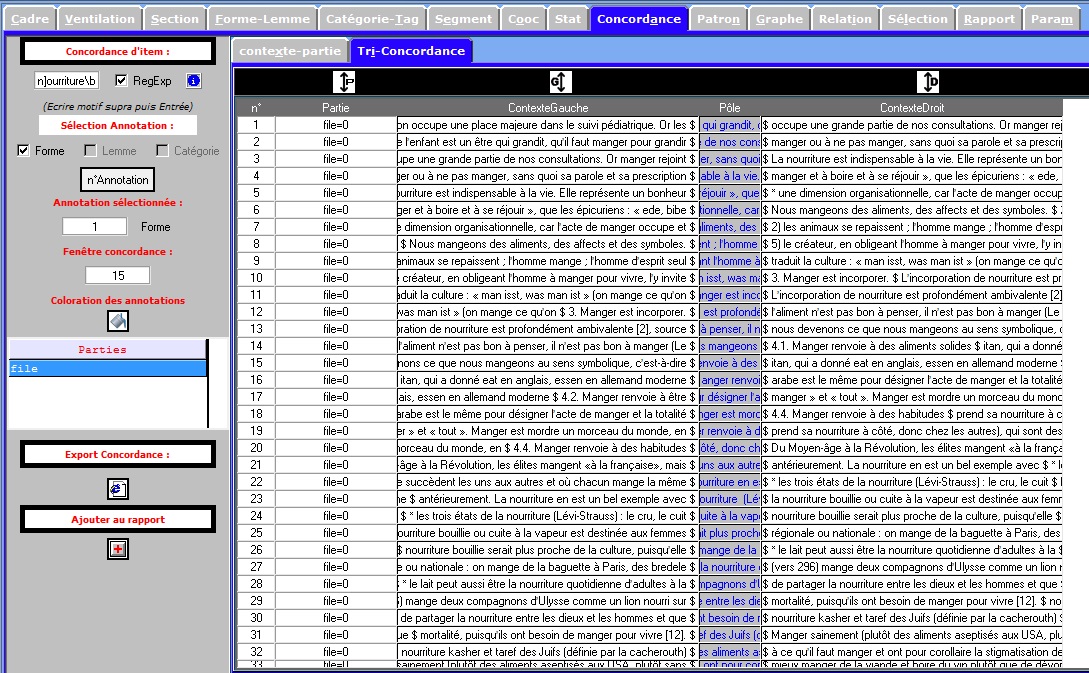
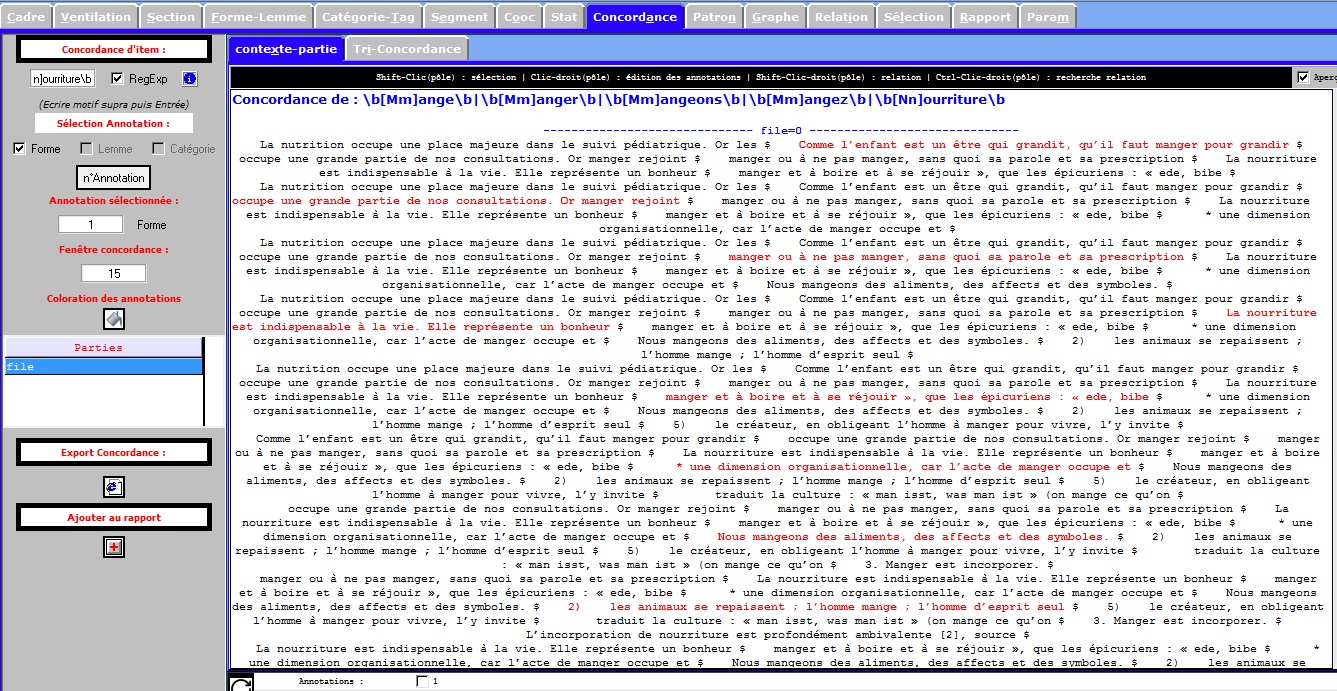
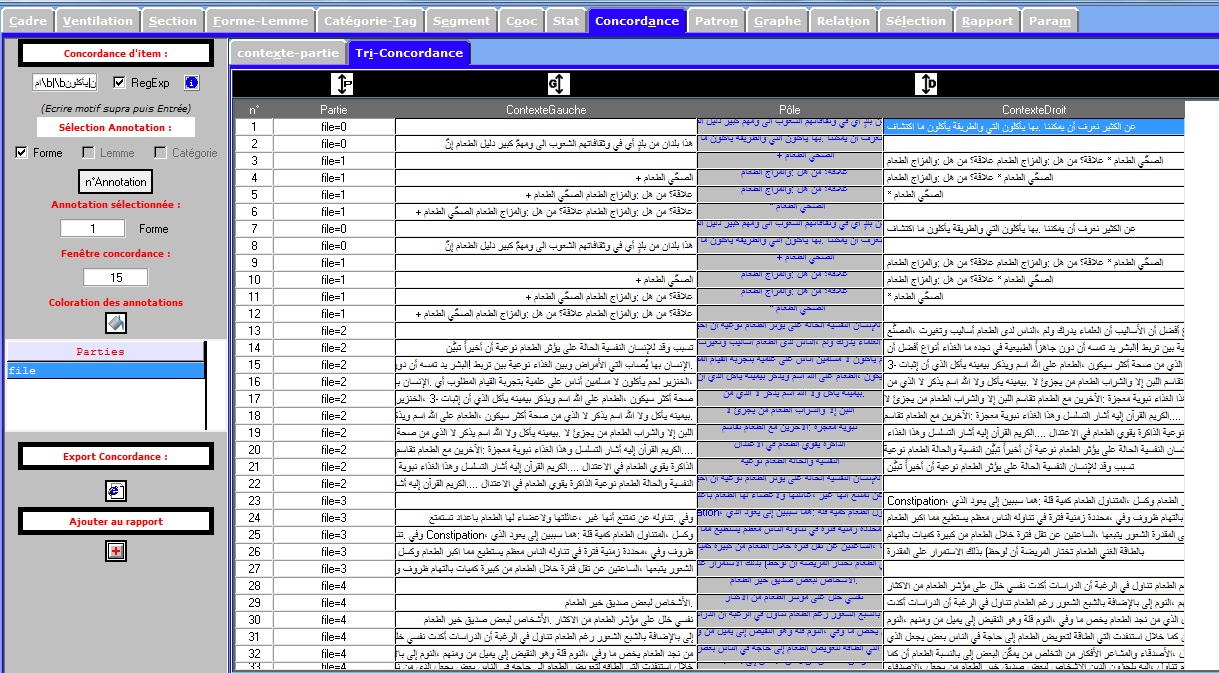
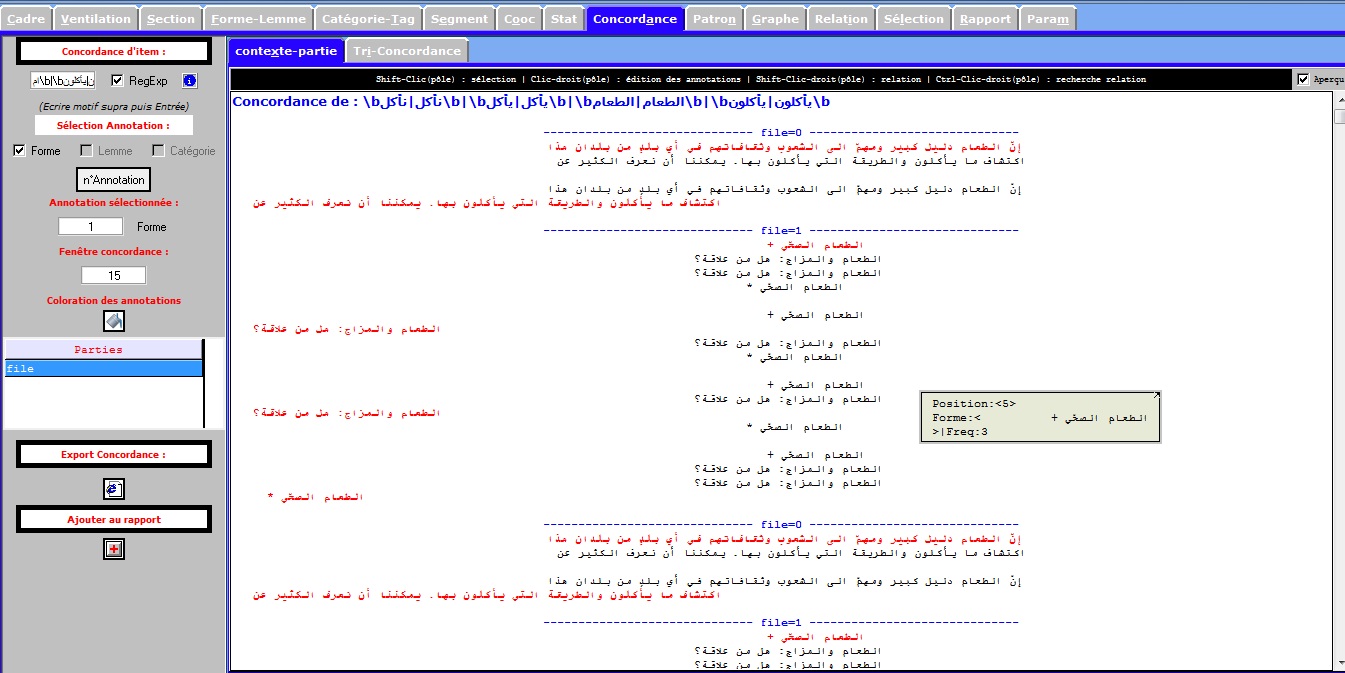
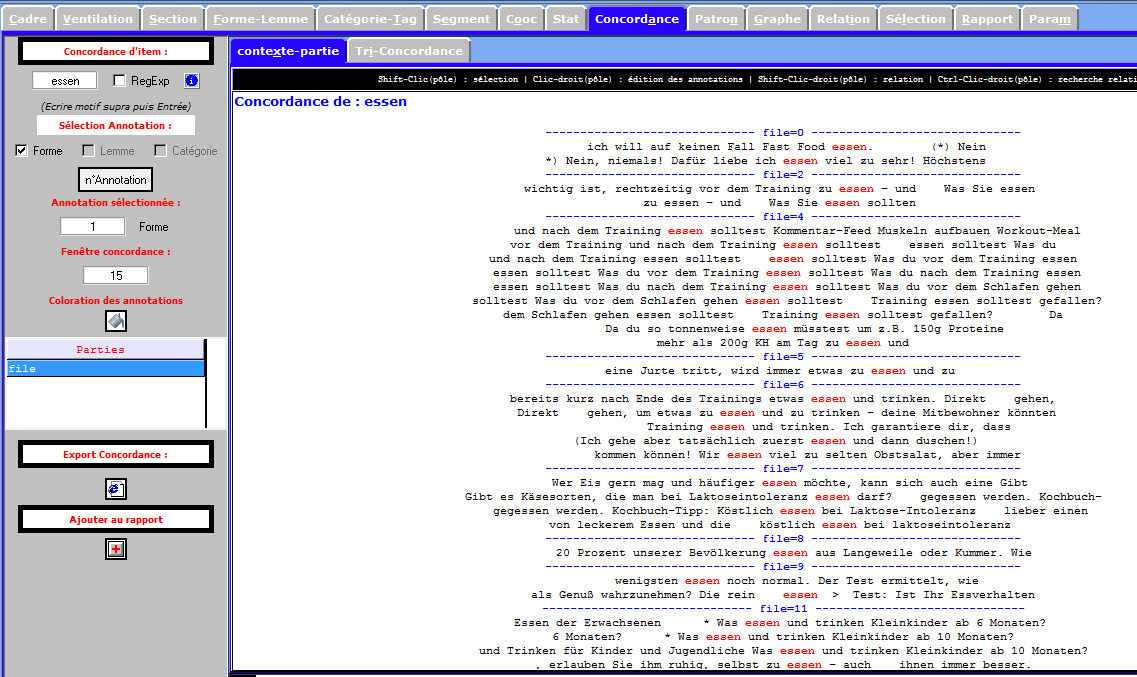
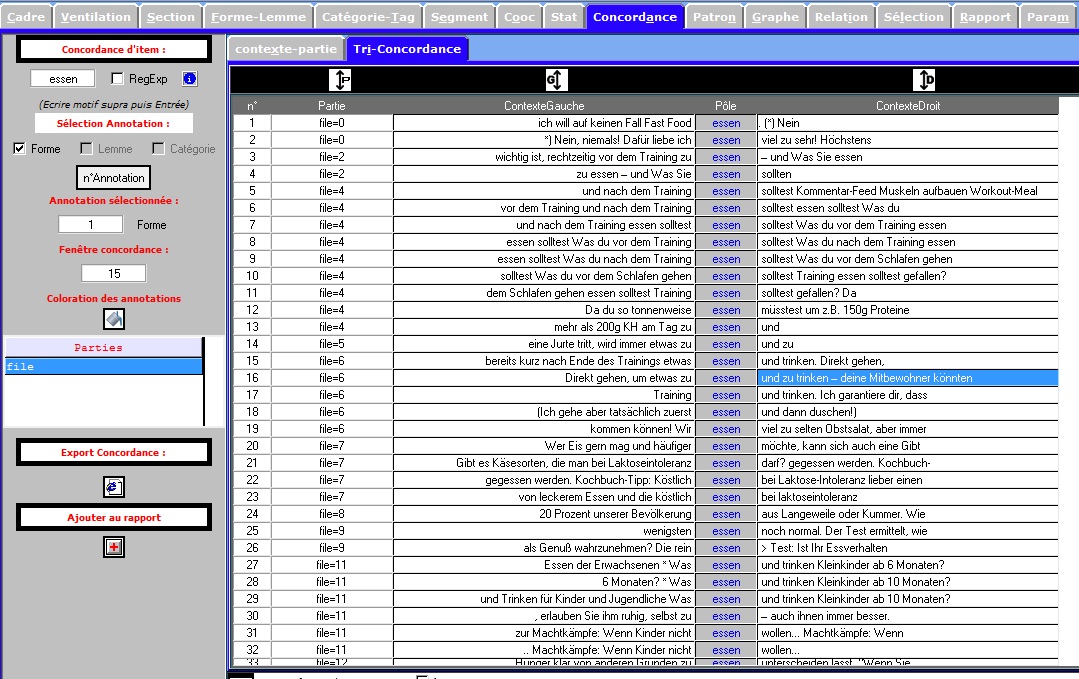
L’onglet CONCORDANCE permet d’afficher les concordances des différentes annotations disponibles sur chacun des items de la Trame forme, lemme, catégorie, annotations complémentaires. Les concordances produites sont disponibles dans 2 sous-onglets distincts: un sous-onglet avec édition des items de la concordance, un sous-onglet permettant de trier les contextes de la concordance.
On voit dans les figures suivantes l'affichage édition + affichage tri
Concordance du fichier Anglais
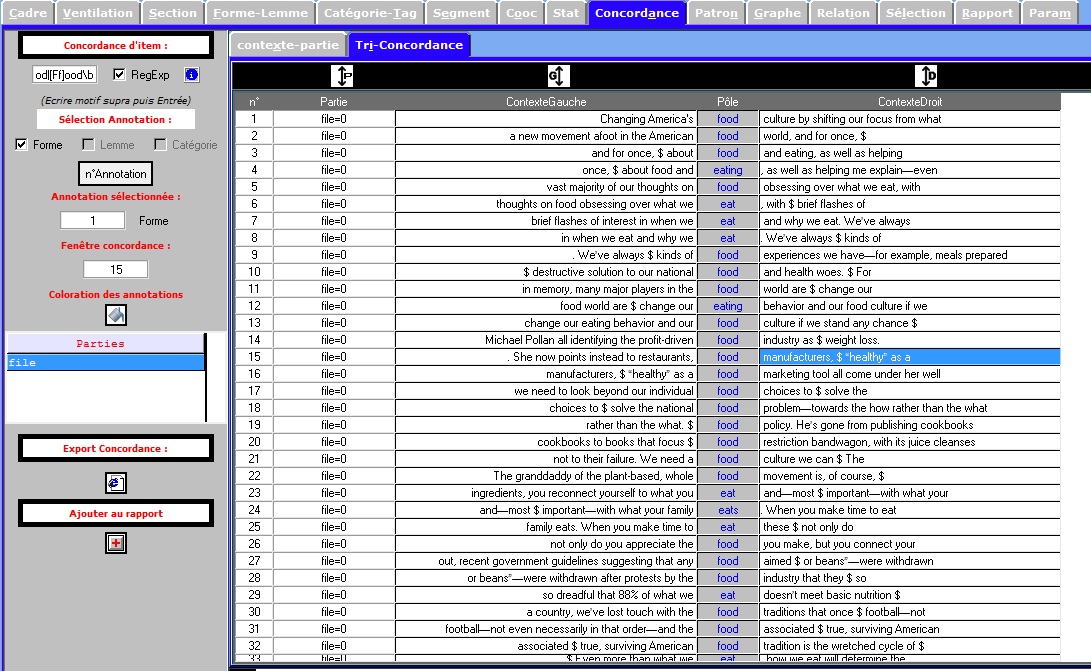
Concordance du fichier Français
Concordance du fichier Arabe
Concordance du fichier Allemand
Les Cooccurrences
Le trameur nous permet aussi d’extraire les co-occurrents : les mots qui viennent souvent autour du mot choisi. Pourtant, il faut définir les contextes (fenêtres) dans lesquels le trameur va chercher les
co-occurrents. Les contextes sont des phrases venant de l’extraction des lignes qui contiennent le pôle, mais comme nous avons vu, ces contextes sont une concaténation de phrases.
Donc il est important de modifier le fichier de départ en insérant le délimiteur de lignes, et le charger par l'onglet Cadre puis ajouter dans l'onglet "Param" le caractère choisi comme délimiteur, ici c'est le symbole $.
Ensuite, il faut aller dans l’onglet « cooc », taper le mot pôle et préciser un nombre pour la co-freq (retenir un mot qui existe nombre de fois avec le pôle) et le seuil (indice de spécificité qui indique le poids du pôle
dans le texte, les co-occurent les plus pertinents.) et enfin cliquer sur « calcul co-occurrents forme pôle ».
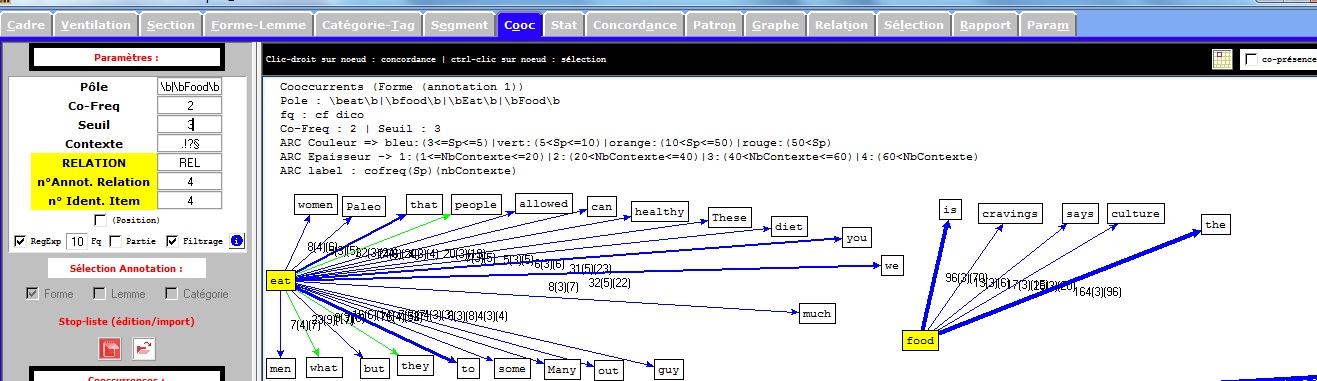
Cooccurrence en Anglais
Le résultat pour notre fichier anglais est comme suit :
On cherche le pôle en anglais avec regexp:
\beat\b|\bfood\b|\bEat\b|\bFood\b
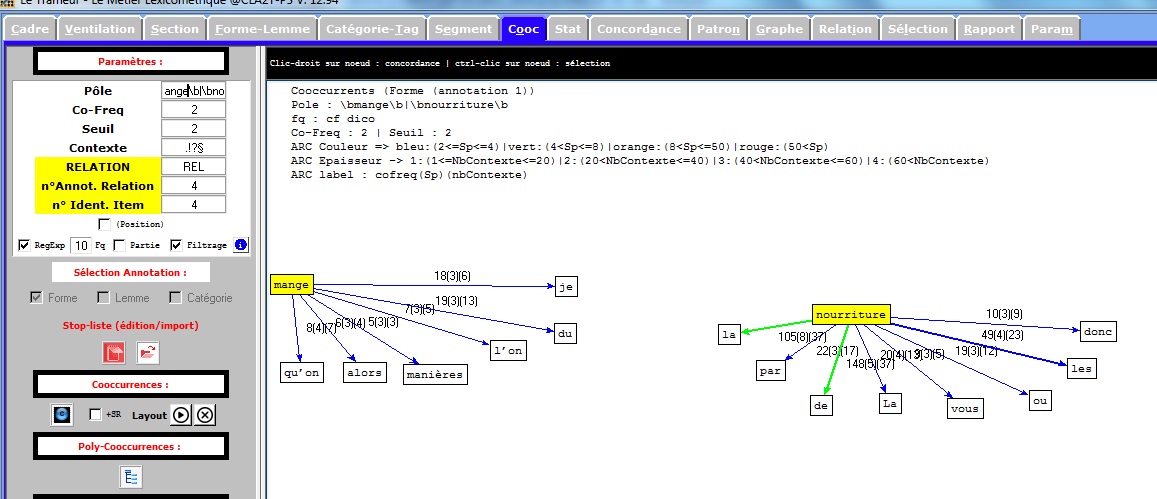
Cooccurrence en Français
Le résultat pour notre fichier français est comme suit :
On cherche le pôle en français avec regexp
\bmange\b|\bnourriture\b
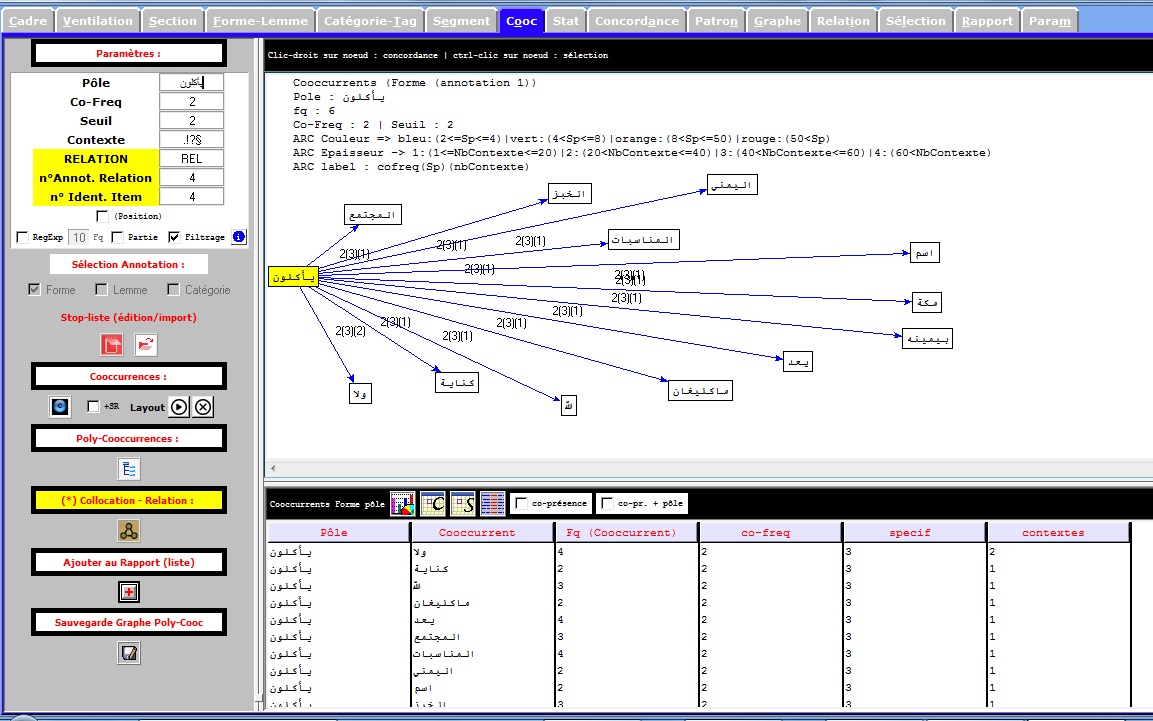
Cooccurrence en Arabe
Le résultat pour notre fichier Arabe est comme suit :
On cherche le pôle en Arabe
يأكلون
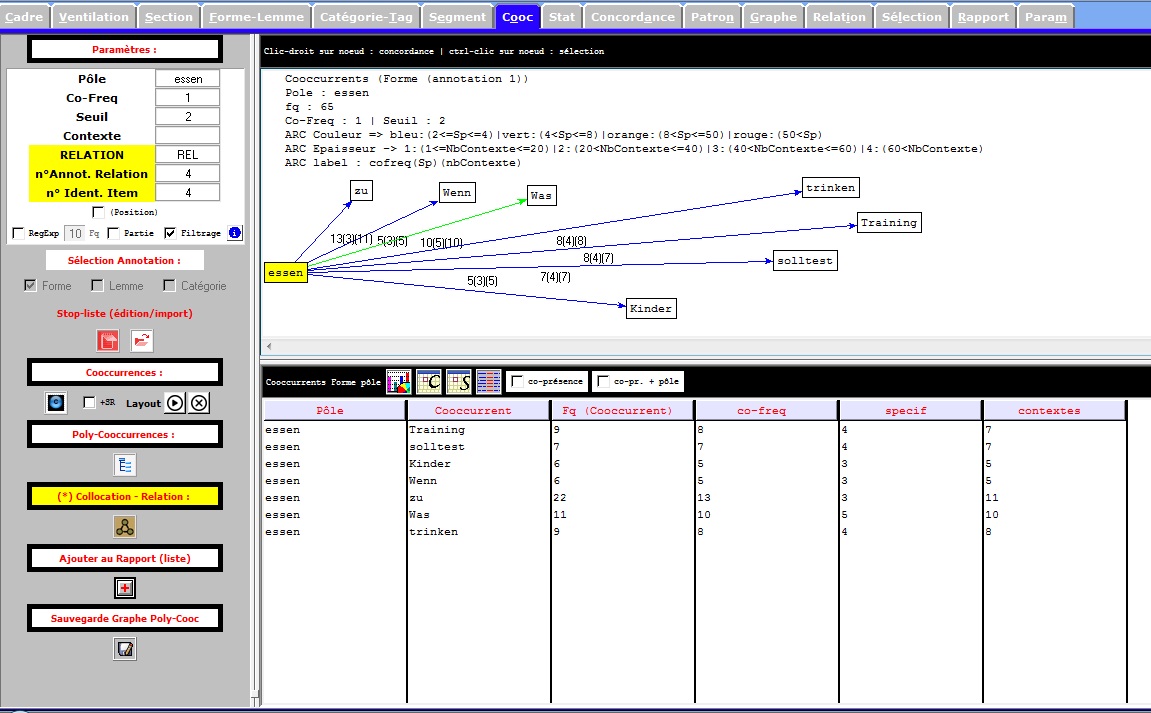
Cooccurrence en Allemand
Le résultat pour notre fichier Allemand est comme suit :
On cherche le pôle en Allemand
essen
Pour plus d'informations, cliquez ici