Parcours de Travail
Les étapes initiales
1- Recherche du motPour commencer notre travail, il nous fallait un Mot. L’idée était de trouver un terme afin d’en distinguer les différents contextes d’utilisation.
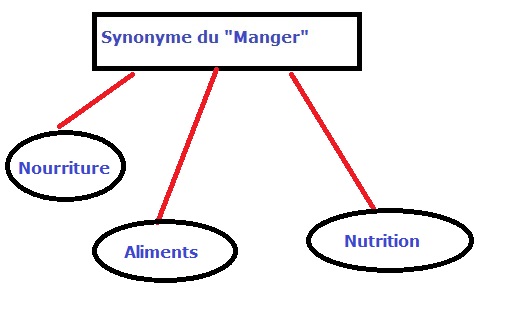
On a décidé de choisir le mot "manger" et ses significations ou les mots qui ont le même sens, on a sélectionné le mot "nourriture" comme synonyme. Après plusieurs réflexions et recherches, on a découvert que le verbe "manger" est utilisé fréquemment au présent sur Internet alors il faut chercher aussi "mange", "mangeons", "mangez" et "mangent".
Pour limiter le corpus dans la jungle du Web, on est parvenu a l’idée de chercher le verbe "manger" au présent et son synonyme "nourriture" dans les deux domaines culturel et psychologique.
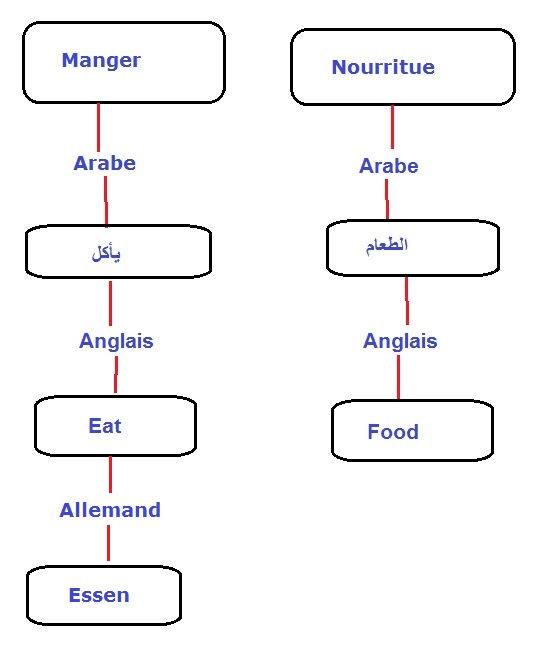
On a commencé après l’étape de traduction:
Traduction vers l'anglais: eat, food
Traduction vers l'arabe: يأكل، يأكلون، نأكل، طعام
Traduction vers l'allemand: essen, gegessen
2- Recherche d'URLs
Pour réaliser la détection automatique des contextes linguistiques où apparaissent les différents sens de nos mots, nous avons cherché des URLs contenant de termes associés.
On a défini les domaines de la recherce d'URLs qui sont les deux domaines culturel et psychologique.
On a diversifié le type de pages Web récupérées : articles, blogs, forums… etc. On a utilisé le fidèle moteur de recherche Google: "Google is always my best friend".
Après avoir trouvé nos URLs, on les a regroupés dans un fichier texte.
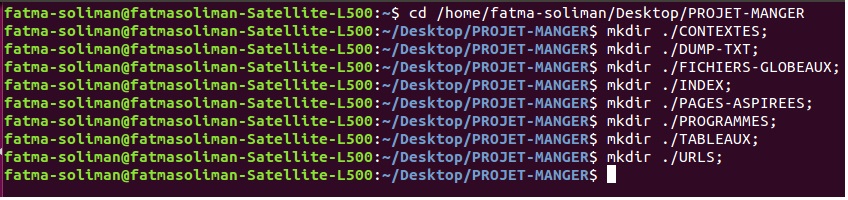
3- Création de l'environnement de travail
La commandes mkdir située au début de notre script, nous a permis de créer notre arborescence de travail:
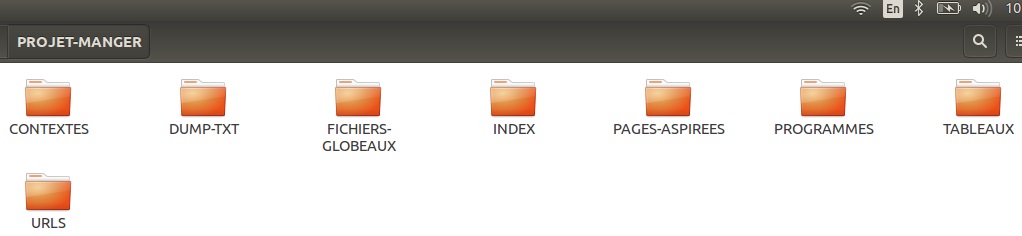
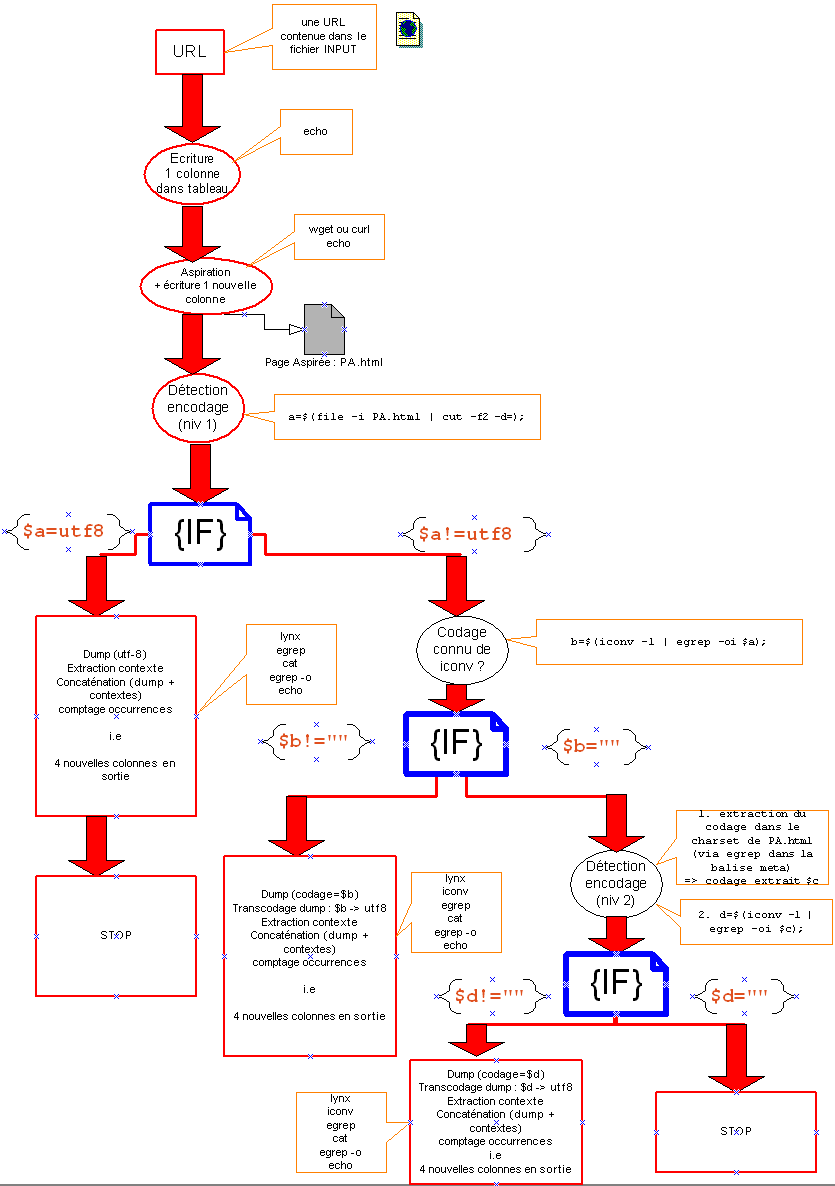
Après avoir créé notre arborescence, nous sommes passés à la création du script qui nous permettra de présenter dans les différentes langues, sous forme de tableaux en HTML, les liens cliquables des URLs, des pages aspirées, des textes brut ou dump et des contextes du mot.
Notre sript bash contient les étapes suivantes:
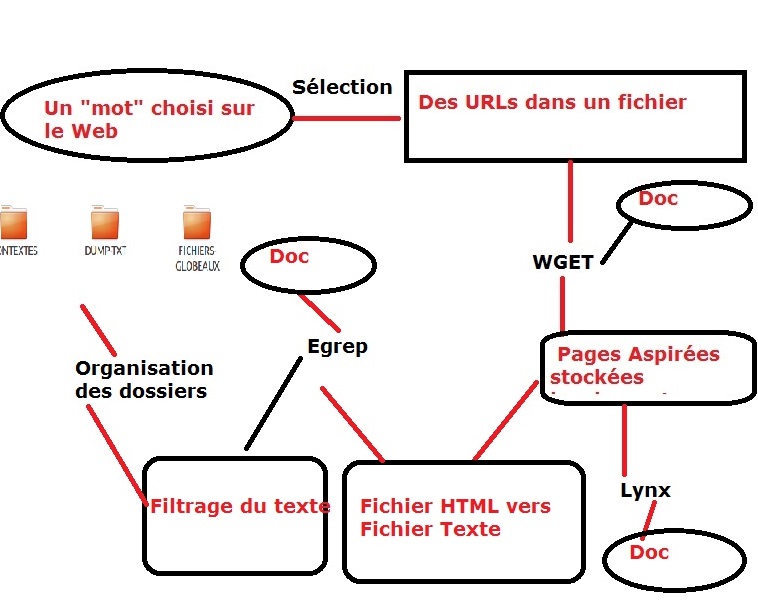
- Aspiration locale des pages: WGET
Après avoir redirigé le lien de chaque URL ligne par ligne, la commande wget nous a permis d’aspirer les pages des différentes URLs choisis et de les enregistrer dans le répertoire PAGES-ASPIREES.
Pour savoir l’encodage des caractères, nous avons utilisé la commande egrep pour récupérer l’encodage utilisé dans la page aspirée.
Si l'encodage n'est pas en UTF-8 ou n'est pas connu, nous utilisons la commande egrep pour chercher le charset (character encoding standard) défini dans le code source de la page HTML aspirée.
- Récupération du texte brut des pages ("DUMP"): LYNX
La commande lynx permet de récupérer le contenu textuel de la page aspirée et le rediriger vers un fichier texte sauvegardé dans le répertoire DUMP-TXT.
Avant de lancer la commande lynx, on doit s'assurer que l'encodage de la page aspirée est en UTF-8 pour avoir un fichier de text brut en UTF-8 aussi, si l'encodage n'est pas en UTF-8, on utilise la commande iconv
- Recherche du motif ou du contexte des mots clefs dans le texte brut: EGREP
Avant de récupérer les contextes, nous avons utilisé la commande egrep -i avec les expressions régulières pour chercher les mots clefs en différentes langues:
Lest motifs sont:
Français: ( Mange | mange )|( Manger | manger )|( Mangeons | mangeons )|( Mangent | mangent )|( nourriture | Nourriture )
Anglais: ( Eat | eat )|( food | Food )
Arabe: ( الطعام )|( يأكلون )|( يأكل )|( نأكل )|( الغذاء )
Allemand: ( Essen | essen )|( Gegessen | gegessen )
Puis nous avons créé deux types de fichiers de résultats : l’un en texte brut, qui nous servira pour les nuages de mots, et l’autre en HTML.
- Création du dico
On a créé un dictionnaire pour chaque fichier dump utf-8 dans le dossier INDEX.
- Concaténation des fichiers Contexte, Dump et Index dans "Fichiers Globaux"
On a concaténé tous les fichiers dump, contextes et index et les sauvegardés dans le dossier FICHIERS-GLOBAUX. Ces fichiers nous serviront à la création des nuages et l'analyse de Trameur.
5-Création d’un tableau en HTML
Pour classer les résultats, on a créé pour chaque langue un tableau en HTML; à
l’intérieur de notre script bash.
Chaque tableau contient 8 colonnes:
La 1ère contient la numérotation des lignes.
La 2ème rassemble l'URLs regroupés dans des fichiers par
langue.
La 3ème regroupe les pages aspirées localement.
La 4ème regroupe le retour de la commande wget.
La 5ème regroupe l'encodage initial de la page aspirée.
La 6éme et la 7ème regroupent le contenu textuel brut de chaque page aspiré ou le DUMP.
La 8ème et la 9ème regroupent les contextes des mots "manger, mange, mangeons, mangez, mangent et nourriture" en format texte et en format HTML pour les rendre plus lisibles.
La 10ème regroupe la fréquence des mots clefs dans les fichiers DUMP.
La 11ème regroupe le dictionnaire.
6- La recherchedes occurrences et des cooccurrences des formes du motif via Le Trameur
Ce logiciel a pour objectif de compter les éléments (mots ou groupes de mots) d’un texte qu’il annote pour construire un système de coordonnées sur la séquence textuelle sous forme arborée. On l'a utilisé pour chercher les occureces et les coocurrences de nos mots clefs.
7- Création des nuages de mots
Afin de créer les nuages de mots, il nous fallait concaténer les fichiers dump et les fichiers texte des contextes où apparaît les mots clefs. A partir de ces concaténations, on voit le contraste entre les nuages de mots du contexte et ceux qui regroupe tous les mots de la page Web. On a utilisé plusieurs applications disponibles en ligne pour faire les nuages de mots comme TreeCloud, TagCrowd, WordItOut et Wordle.
