Le script bash
Pour télécharger le script et ses ressources, cliquez ici
Création de l'environnement de travail
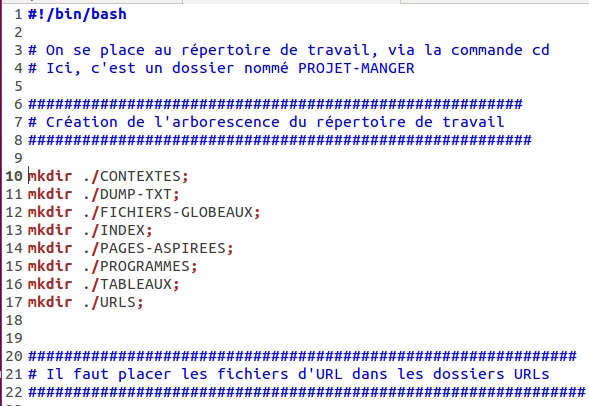
On se place dans notre répertoire de travail, via la commande cd. C'est un dossier nommé "PROJET-MANGER".
On crée l'arborescence du répertoire de travail via la commande mkdir.
Puis, il faut ensuite placer les fichiers d'URL dans les dossiers URLs
Création du tableau pour chaque langue
Lancement du script
Lecture du chemin des urls et du tableau à créer à partir d'un fichier input

Préparatifs
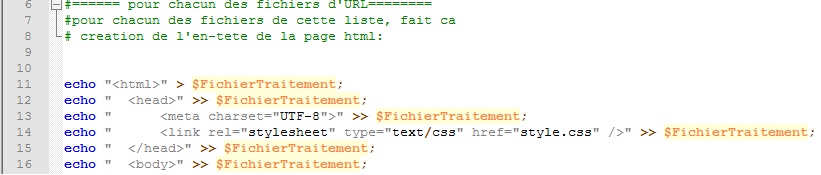
Pour chacun des fichiers d'URLs, on crée l'en-tête de la page HTML.
Boucles et conditons
Début des boucles et du tableau
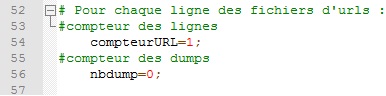
Démarrage d'une numérotation qui compte les fichier d'URLs.
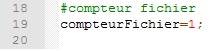
Démarrage d'une numérotation qui compte les lignes de chaque fichier d'URLs pour nommer les URLs aspirées dans le tableau.
Démarrage d'une numérotation qui compte les fichiers DUMP.
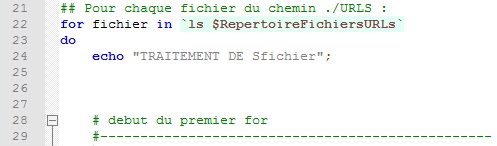
Première boucle : pour chaque dossier de langue présent dans le répertoire des URLs.
Problèmes rencontrés
Lors de l’exécution du script, on a remarque qu'un quatrième tableau a été créé . On a lance la commande ls dans le répertoire d'URLs et on a trouve un fichier teste qui se termine avec un tilde. Celui-ci est créé à chaque fois qu'on édite un fichier d'URLs. On a essayé le script suivant pour empêcher la création d'un quatrième tableau mais il ne marche pas.
# Arrêter le script si le nom du fichier se termine avec ~ tilde
if [ "$fichier" = "~" ]
then
break
fi
Il faut supprimer ce fichier manuellement avec la commande. rm
.
Remarque: Vous trouverez d'autres problèmes dans notre blog.
Le traitement de chaque fichier d'URL.
La création des colonnes du tableau

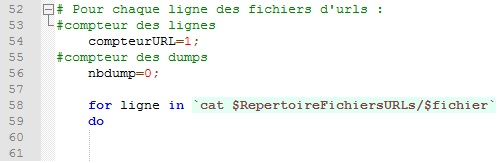
Deuxième boucle: Pour chaque ligne des fichiers d'urls, on fait le suivant:
Insertion des lignes et colonnes du tableau
Wget,lynx, iconv et file
Aspiration des URLs
On aspire le contenu des URLs de chaque fichier via la commande wget, puis on les stocke dans le répertoire PAGES ASPIREES et on les nomme grâce au compteur des lignes.

On essaie d'extraire l'encodage de la page aspirée grâce à la commande
file
et
egrep.
Si la page a été aspirée et qu'un encodage a été trouvé, on le sauvegarde dans la variable $encodage.
Si la page n'a pas été aspirée, on cherche le message d'erreur via egrep, on le copie dans la variable $contenuPageAspiree, on imprime le message d'erreur dans le tableau.
Si la page aspirée est en UTF-8, on peut récupérer directement le texte de chaque page aspirée puis on le stocke dans le répertoire DUMP-TXT et on le nomme grâce au compteur des lignes.
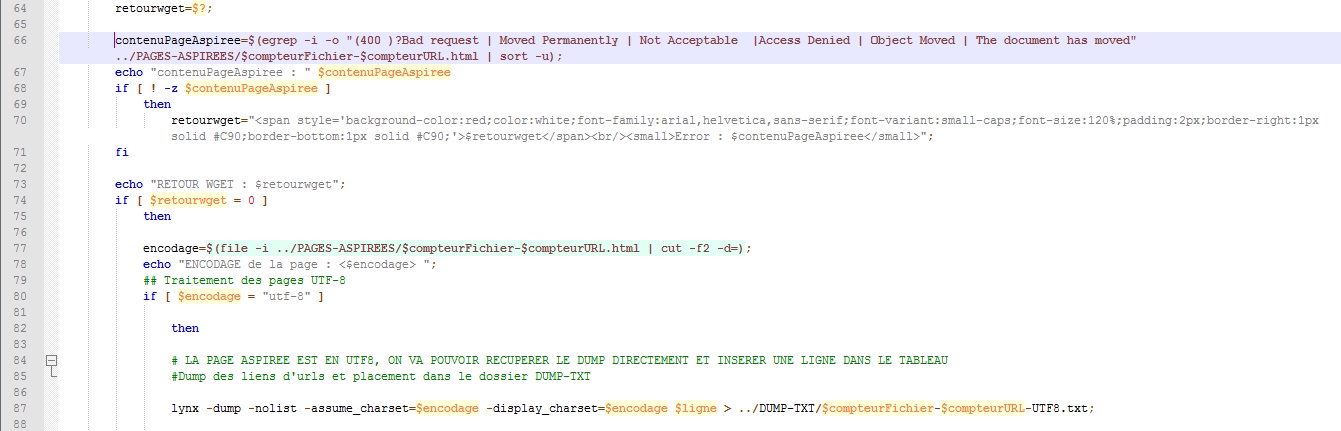
Si l'encodage n'a pas été trouvé, on commence par vérifier si l'encodage est connu par la commande iconv
.Si l'encodage n'est pas connu par iconv, on detecte un charset dans la page aspiree en utilisant egrep avec
les expressions régulières.
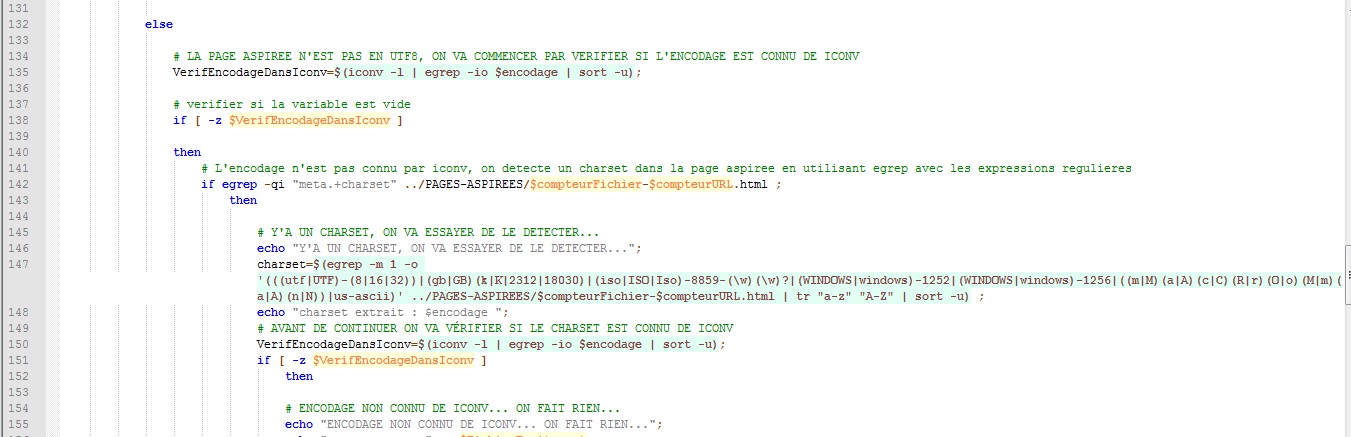
Si le Charset extrait est connu par iconv, on transforme l'encodage en UTF8 et on récupère le texte de chaque page aspirée puis on le stocke dans le répertoire DUMP-TXT.
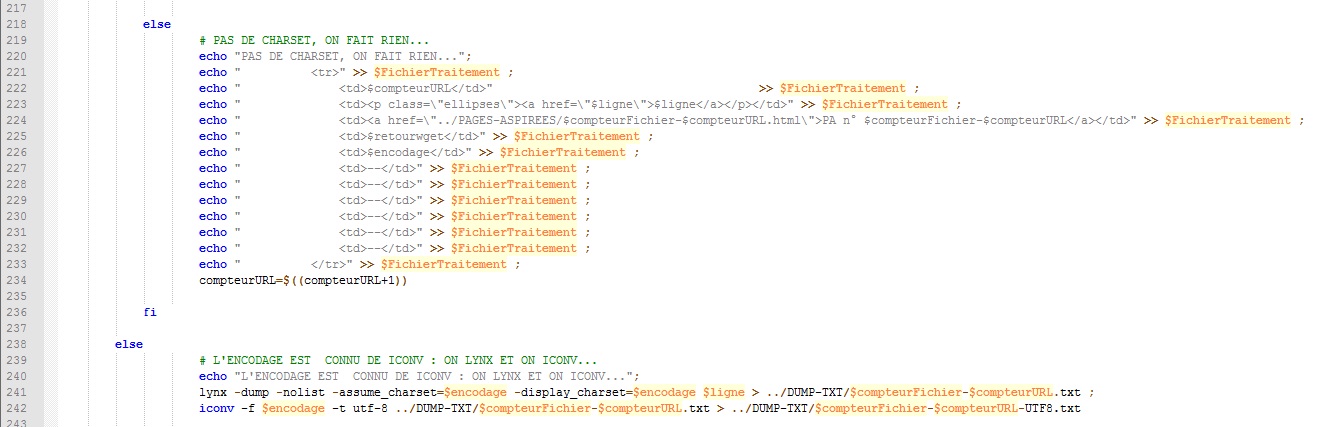
Si on ne trouve pas un charset dans la page aspirée, on ne fait rien.

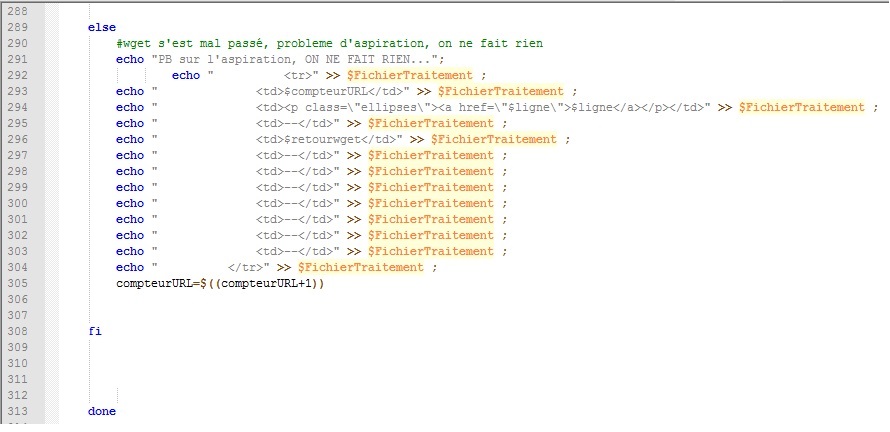
Si le wget est mal passé, on ne fait rien
Recherche du motif via egrep et les expressions réguliéres
On sélectionne les motifs à chercher en fonction de la langue et on les extrait via la commande egrep avec les expressions régulières. On place ces motifs dans le dossier CONTEXTE.

Extraction des contextes en html avec le programme minigrepmultilingue.

Le programme minigrepmultilingue RegExp.
Le minigrep est un programme développé par Serge Fleury et Pierre Marchal. L'objectif de ce programme perl est le filtrage dans des fichiers multilingues.
En entrée: un fichier à filtrer, le fichier DUMP-UTF8.txt
En sortie: un fichier au format HTML contenant les lignes du fichier DUMP-UTF8.txt contenant le motif visé.
Fichier Motif: fichier texte encodé en UTF-8.
Pour plus d'infos, cliquez ici
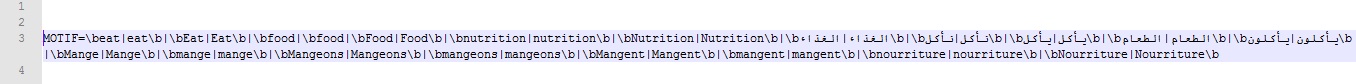
Fichier Motif de Minigrep.
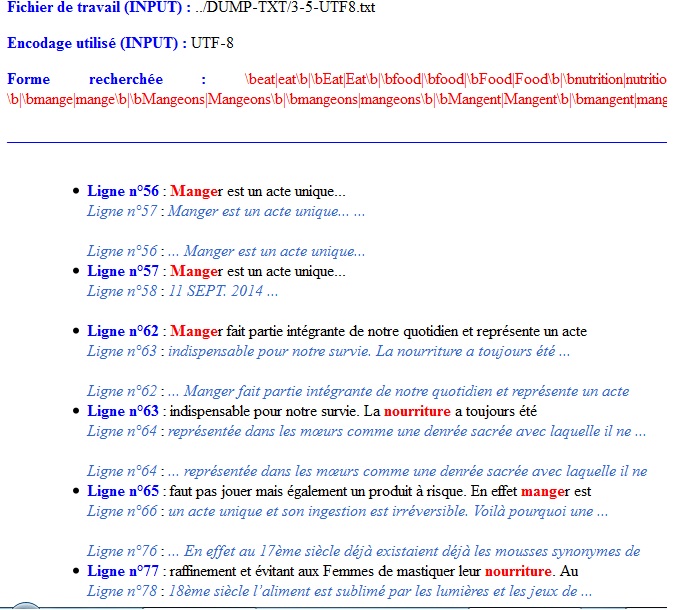
Résultat de Minigrep.
Fréquence du motif
On compte le nombre d'occurrences des mots cles ou des motifs dans chaque fichier DUMP.

Création du dictionnaire
Création d'un dictionnaire pour chaque fichier dump utf-8 dans le dossier INDEX.

Fichiers Globaux
On prépare les fichiers textuels qui serviront à la création des nuages et l'analyse de Trameur.
Concaténation de tous les fichiers dump, contextes et index dans des fichiers globaux.

Fin du script
Finalisation du tableau.
