L'objectif de ce projet est de "[mettre] en œuvre une chaîne de traitement textuel semi-automatique, depuis la récupération des données jusqu'à leur présentation". Plus précisément, le but sera de pouvoir extraire des terminologies de notre corpus et de comparer différentes rubriques.
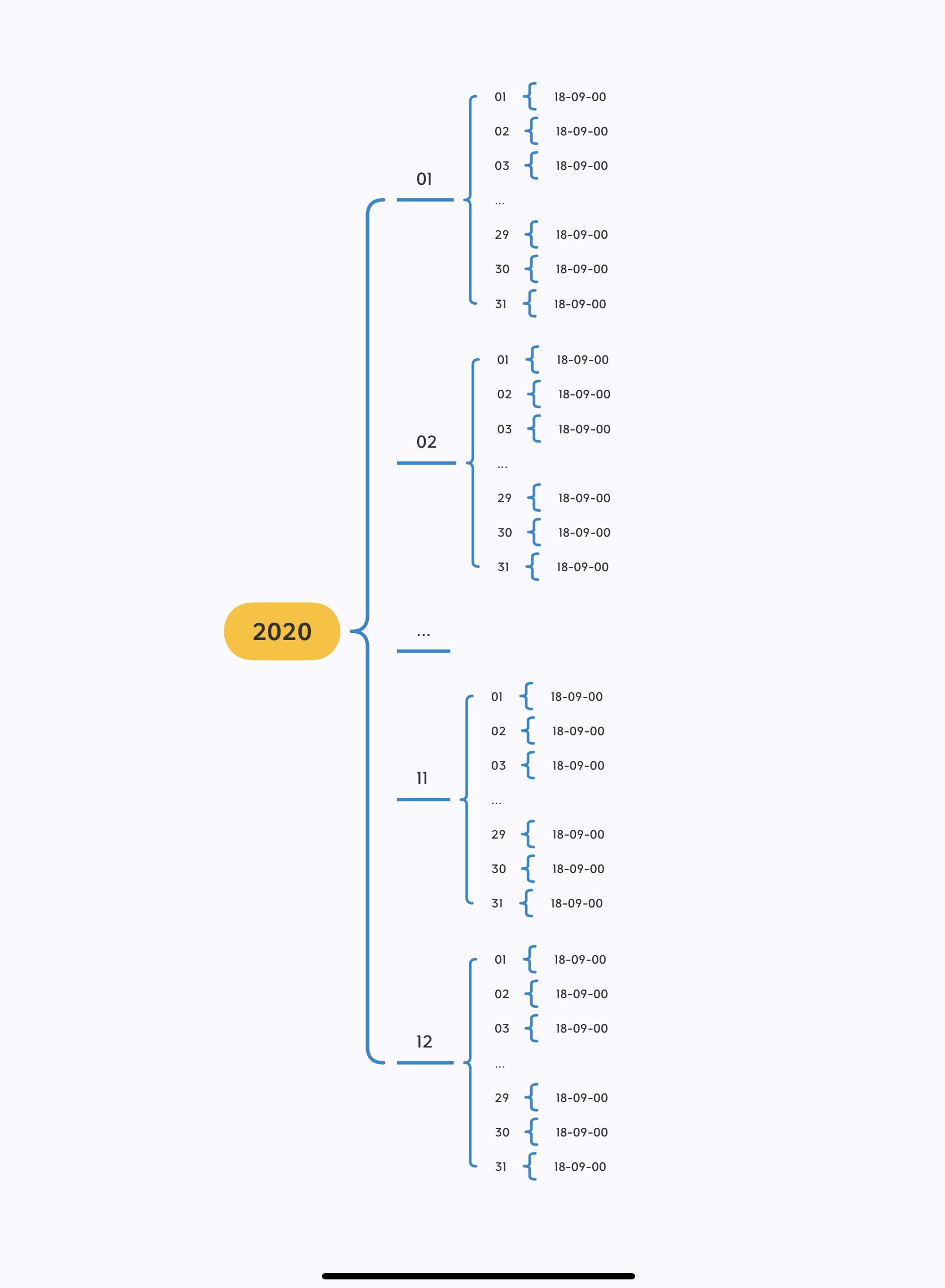
Notre corpus de travail est une arborescence de fils RSS du journal Le Monde, recueillis tous les jours de l'année 2020 à 19h (certains sont à 18h). L'arborescence contient un répertoire pour chaque mois de l'année, dans lesquels se trouvent autant de dossiers que de jours. Au sein de ces répertoires de jour, on trouve les fichiers qui nous intéressent : les flux RSS de chaque rubrique, au format .xml. Les différentes rubriques sont celles du Monde (à la une, international, culture etc.) et ont chacune un identifiant, ce qui permet d'identifier aisément les différents fichiers de flux RSS.
Les schémas ci-dessous présentent le répertoire de corpus et les fils RSS avec sa rubrique correspondante. Le graphe se trouvant à gauche montre le chemin de dossier à traiter (avant les fils RSS), dont le format est: Année/Mois/Jour/Heure, par exemple, 2020/01/01/18-09-00. Le schéma à droite explique précisément que chaque rubrique du journal est nommée avec un identifiant numérique, les chiffres au milieu (après 0,2-) distinguent les rubriques entre elles. Par exemple, « 3208 » représente la rubrique "À la une". Chaque rubrique contient un fichier TXT et un fichier XML.
Structure des données
Pour voir les images présentées ci-dessous en taille réelle, cliquez dessus.
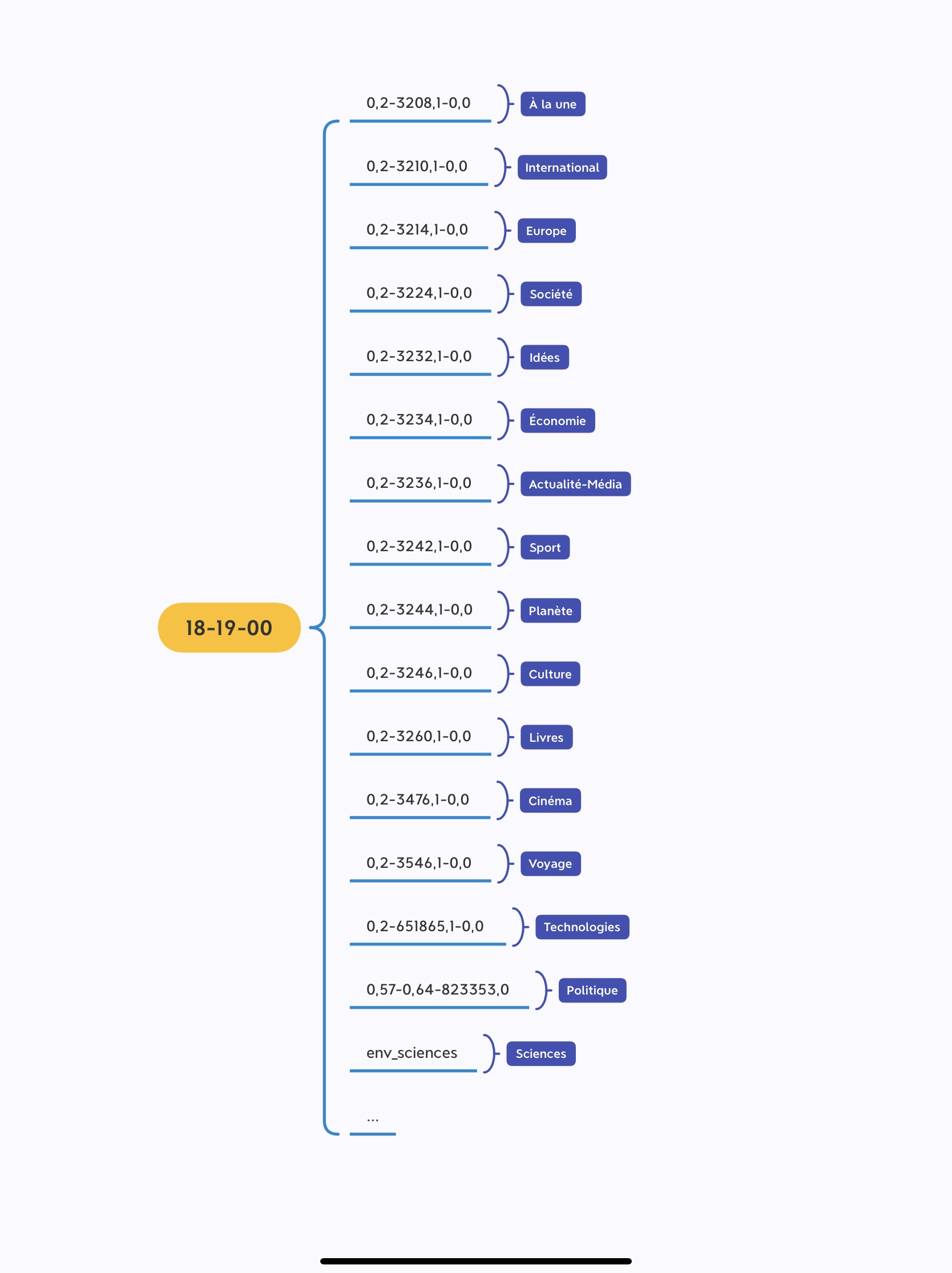
Les rubriques que nous avons choisi sont : "A la une" (identifiant 3208), "International" (identifiant 3210) et "Culture"(identifiant 3246).
Pour réaliser notre projet, plusieurs étapes sont nécessaires. Chaque étape est associée à une "boîte à outils" :
- Boîte à outils 1 : extraction de contenu textuel. Le but est d'arriver à parcourir l'arborescence pour extraire les données textuelles qui nous intéressent.
- Boîte à outils 2 : étiquetage. Une fois les données textuelles obtenues, il faut les étiqueter (forme, POS, lemme) pour pouvoir les traiter de manière syntaxique (TreeTagger pour le fichier xml et UDpipe pour le fichier txt ).
- Boîte à outils 3 : recherche et extraction de patrons syntaxiques ou de relations de dépendances. Éventuellement la représentation graphique des listes produites dans les 2 tâches précédentes.
- Boîte à outils 4 : classification automatique des fils RSS. La dernière étape consiste à mettre en oeuvre un processus de classification automatique des fils RSS traités dans les BàO précédente.
Processus en image
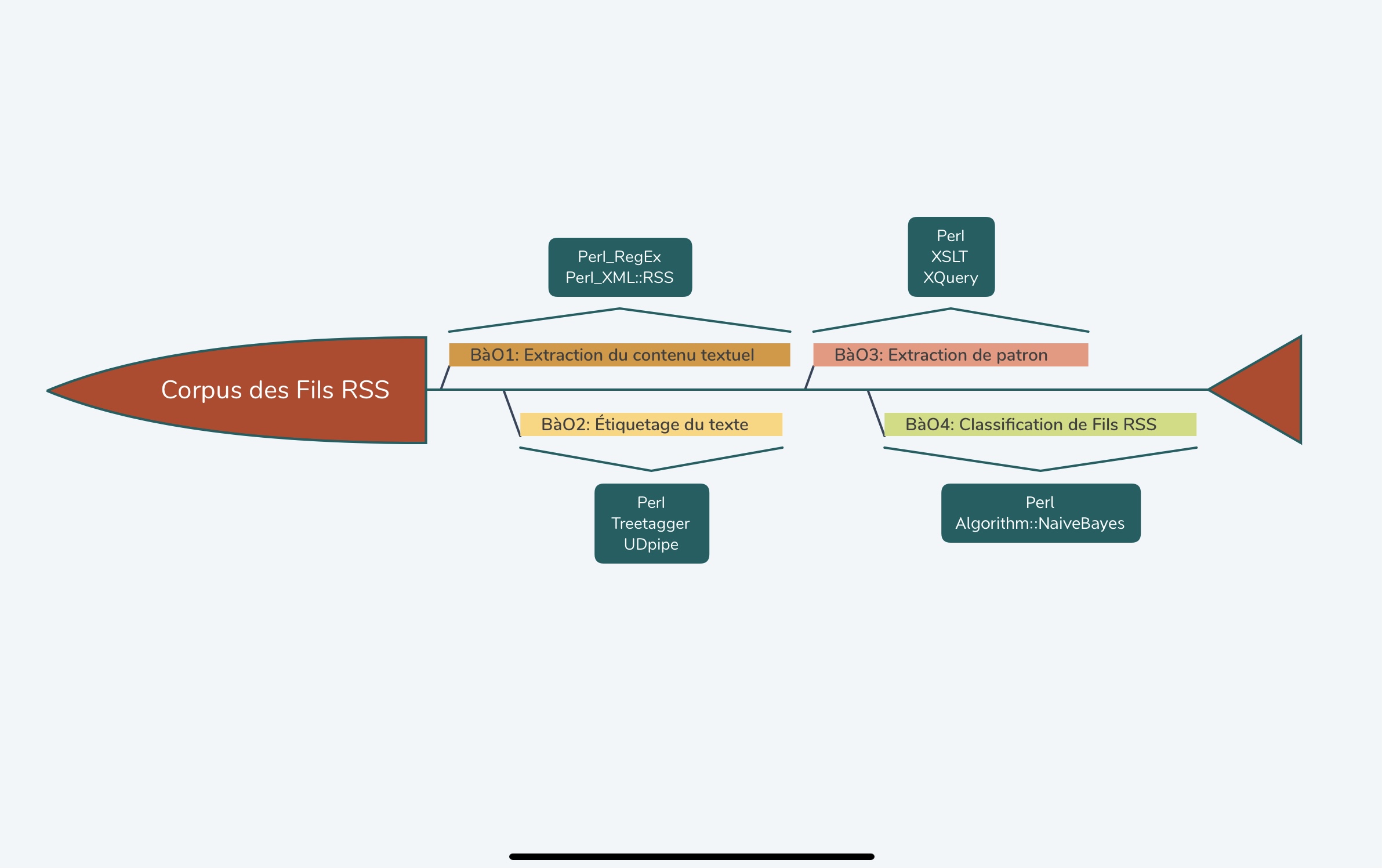
N.B.: Pour la plupart de ces étapes, plusieurs outils, plusieurs méthodes ont été utilisées. Elles seront détaillées dans les onglets du site qui y sont consacrés.