Pour assurer l'intégrité du Projet, nous avons décidé d'écrire ce chapitre, mais son contenu provient entièrement de la section Projet encadré (accès restreint) sur Icampus, et les scripts et ressources utilisés sont fournis par M. Serge Fleury.
Ressources disponible :
- Après avoir extrait le texte d'un fil RSS, il faudra lui attribuer sa rubrique : pour rappel les rubriques sont décrites dans la présentation du projet
- On utilisera pour cela des rubriques déjà construites sur les fils RSS : rubriques-2017-2018-2019. Ces fichiers (un par rubrique) concatènent les données des années 2017, 2018 et 2019.
- Notre programme pourrait aussi utiliser une stop-liste : STOP-LISTE
- Le programme est disponible ici : Load-BAO4-classif-fil-full-NB.pl (via NaïveBayes)
Mode d'emploi :
Le programme se lance comme ci-dessous :
PROGRAMME [options] <REPFIL> <REPTRAIN> <REPTREETAGGER> [fichier-stop-list]
- REPFIL : répertoire contenant l'arborescence des fils RSS
- REPTRAIN : répertoire contenant les rubriques passées utilisées pour l'entraînement
- REPTREETAGGER : le nom du répertoire contenant les ressources pour treetagger
- fichier-stop-liste (optionnel) : le nom du fichier stop-liste
Le programme se lance comme ci-dessous :
perl Load-BAO4-classif-fil-full-NB.pl 2020 categorie-2018-sf ../distrib-treetagger stoplist.fr-etendue-utf8.txt
OPTIONS qu'on peut choisir :
- -h imprime le mode d'emploi de ce programme
- -e travail sur les lemmes après étiquetage avec treetagger
- -c travail sur les caractères
- fichier-stop-liste (optionnel) : le nom du fichier stop-liste
Le programme réalise les différentes étapes suivantes :
- Phase 0 : lecture des ressources
- Phase 1 : entraînement
- Phase 2 : traitement du corpus de fil RSS (parcours)
- Phase 4 : affichage de la synthèse des résultats de la classification
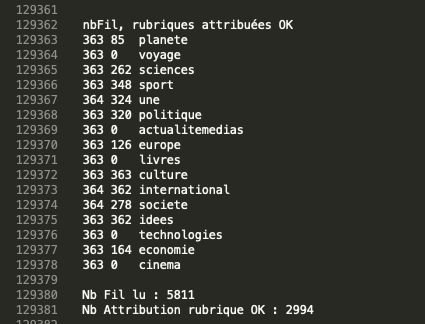
Exemple de sortie produite pour NaiveBayes : (le détail est disponible dans ce fichier logParcours.txt)