OBJECTIFS
Quand on a réussi à extraire les contenus textuels des balises <title> et <description> de tous les fichiers xml correspondant aux rubriques que nous avons choisies d'étudier, nous allons enrichir les deux sorties en réalisant un étiquetage morphosyntaxique à l’aide de TreeTagger pour la sortie XML et UDpipe pour la sortie TXT.
MÉTHODES
On intègre le programme d’étiquetage de TreeTagger et d’UDpipe dans le script construit pour la BàO 1 sous forme de sous-programme.
TREETAGGER
TreeTagger est un outil permettant d'annoter des textes avec des informations POS et lemma. Il a été développé par Helmut Schmid dans le cadre du projet TC de l'Institut de linguistique informatique de l'université de Stuttgart. TreeTagger a été utilisé avec succès pour baliser une vingtaine de langues, et peut être adapté à d'autres langues si un lexique et un corpus d'entraînement étiqueté manuellement sont disponibles.
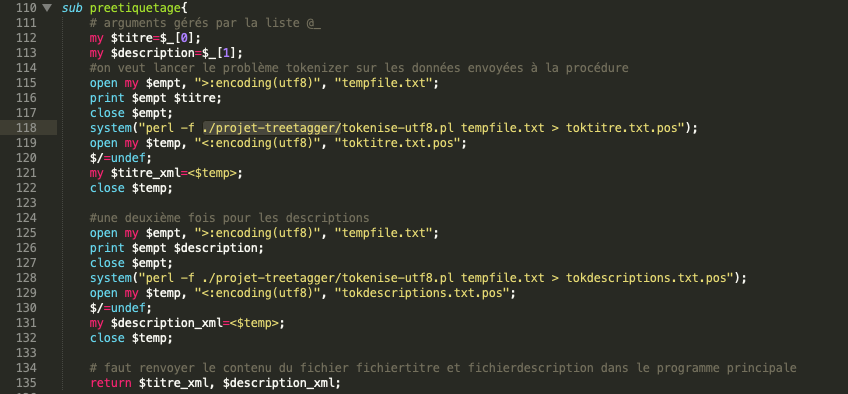
Dans la BàO1 (cf. boîte à outils 1), on a réussi à extraire le corpus sous deux formats grâce aux méthodes des expressions régulières ou de la bibliothèque XML::RSS. On va créer ici deux autres sous-programmes. L’un est pour tokeniser le texte et l’imprimer dans un fichier xml avec un mot par ligne, on le nomme preetiquetage. Dans ce sous-programme, grâce à la fonctionnalité system(), on tokenise les fichiers à l’aide du script tokenise-utf8.pl qui est fourni en cours.
- Application de tokenisation au sein des scriptssystem("perl ./projet-treetagger/tokenise-utf8.pl -f tempfile.txt > toktitre.txt.pos");
Un exemple de sous-programme et le résultat (cliquez dessus pour voir l'image en taille réelle)
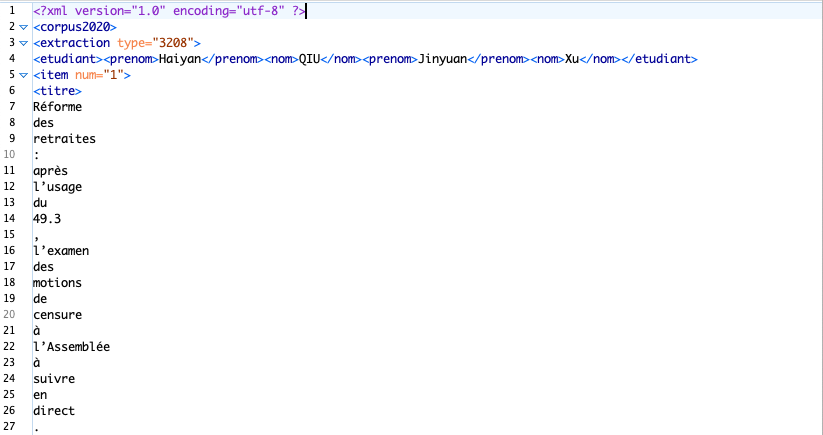
L’autre est pour étiqueter les fichiers xml tokenisés et les convertir en XML, on l’appelle etiquetageTT.
- Application de TreeTagger au sein des scripts : system("perl -f ./projet-treetagger/tokenise-utf8.pl ./sortie/sortiexml_$rubrique.xml | ./projet-treetagger/tree-tagger ./projet-treetagger/french-utf8.par -token -lemma -no-unknown -sgml > ./sortie/sortiexmlTT_$rubrique");
- Application de TreeTagger2XML au sein des scripts : system("perl -f ./projet-treetagger/treetagger2xml-utf8.pl ./sortie/sortiexmlTT_$rubrique utf8");
Dans le premier system(), on applique TreeTagger et nous stockons le texte étiqueté dans le fichier « sortiexmlTT_$rubrique ». Ensuite, dans le deuxième system(), on applique TreeTaggerXML2 grâce à treetagger2xml-utf8.pl (également fourni en cours), qui consiste à convertir le fichier étiqueté vers XML. On va stocker le résultat dans le fichier «sortiexmlTT_$rubriquel »
Les nouveaux scripts ainsi que les sorties contenant l'étiquetage (fichiers xml) sont disponibles ci-dessous.
N.B.1: Les fichiers XML sont volumineux (d'environ 22 à 36Mo), les navigateurs peuvent donc avoir du mal à les afficher. Si vous souhaitez les visionner sans problème, je vous conseille de les télécharger.
UDpipe
« UDPipe est un pipeline entraînable pour la tokénisation, le balisage, la lemmatisation et l'analyse des dépendances des fichiers CoNLL-U. UDPipe est indépendant de la langue et peut être entraîné à partir de données annotées au format CoNLL-U. Des modèles entraînés sont fournis pour presque toutes les banques d'arbres UD. UDPipe est disponible sous forme de binaire pour Linux/Windows/OS X. »
Avec les fichiers textes produits par les programmes, on se met à l’étiquetage en dépendances syntaxiques. Pour ce faire, on crée un nouveau sous-programme, nommé étiquetageUD, dans le même script.
- Application de UDpipe au sein des scripts : system("./distrib-udpipe-1.2.0-bin/udpipe-1.2.0-bin/bin-osx/udpipe --tokenize --tag --parse ./distrib-udpipe-1.2.0-bin/modeles/french-sequoia-ud-2.5-191206.udpipe ./sortie/sortietxt_$rubrique.txt > ./sortie/sortietxtUD_$rubrique.txt");
Les résultats d'UDpipe sont disponibles ci-dessous
Il est à noter que le temps d’exécution des deux scripts (Regex et XML:: RSS) est à peu près le même. Le premier est celui avec Regex, et le seconde est avec XML::RSS