A partir des fichiers étiquetés que l’on a obtenu dans la Boîte à outils 3, la Boîte à outils 4 a deux tâches principales et une tâche optionnelle à traiter. Pour les tâches principales : on établira d’abord une méthode nous permettant d'extraire des patrons syntaxiques, par exemple : Nom + Adjectif, ensuite une autre méthode pour extraire des relations de dépendance. Pour la tâche optionnelle, on établit une représentation graphique des listes produites dans les 2 tâches précédentes
Objectifs :
- 1. Extraction de patrons (avec Perl, XSLT et XQuery)
- 2. Extraction de relations de dépendance (avec XSLT et XQuery)
- 3. (optionnel) représentation graphique des listes produites dans les 2 tâches précédentes
1. Extraction de patrons
Pour cette première tâche, nous présentons ici plusieurs méthodes pour procéder avec différents formats de textes. La première utilisera le langage Perl sur les fichiers UDpipe, la seconde utilisera le langage XSLT sur les fichiers XML, la troisième utilisera le langage Xquery sur les fichiers XML. Les résultas sous forme de liste sont tels que ci-dessous :
- 1.1 Pure Perl pour l’étiquetage UDpipe
- 1.2 Feuille de style XSLT pour l’étiquetage TreeTagger et UDpipe
- 1.3 XQuery pour l’étiquetage TreeTagger et UDpipe
Les patrons à extraire sont:
- NOM ADP NOM ADP
- VERB DET NOM
- ADP ADV ADP
- ADP DET NOM
- NOM ADJ
- ADJ NOM
N.B.: les jeux d'étiquettes changent selon l'étiqueteur, par exemple, ADP se dit aussi PRP ou PREP
1.1 Pure Perl
En prenant en entrée des fichiers étiquetés par UDpipe, nous pouvons appliquer la méthode de pure perl pour extraire les patrons morphosyntaxiques grâce à un script perl. Ce script nécessite aussi un fichier de patrons : patrons.txt $. Dans lequel on peut mettre soit un patron, soit tous les patrons qui nous intéressent.
Le script d'extraction de patrons est disponible ci-dessous:
Le programme se lance comme suit :
Si on veut trier les résultats, on peut ajouter quelques commandes comme ci-dessous :
Comme il y a beaucoup de patrons, nous n'allons montrer que les aperçus des résultats obtenus de deux patrons : NOM-ADJ et NOM-PREP-NOM-PREP. Tous les autres sont disponibles à télécharger en cliquant sur les boutons qui se trouvent après les aperçus.
NOM-ADJ : 3208-À la Une, 3210-Internationale, 3246-Culture
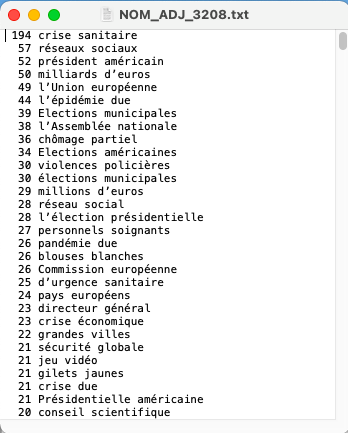
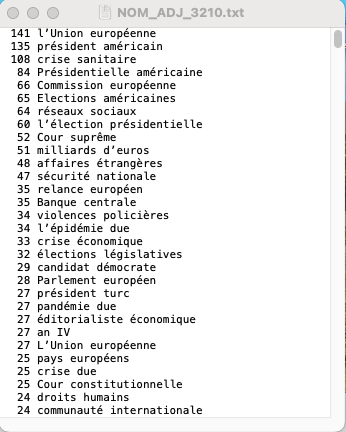
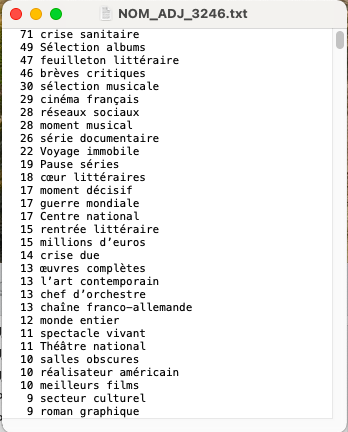
NOM-PREP-NOM-PREP : 3208-À la Une, 3210-Internationale, 3246-Culture
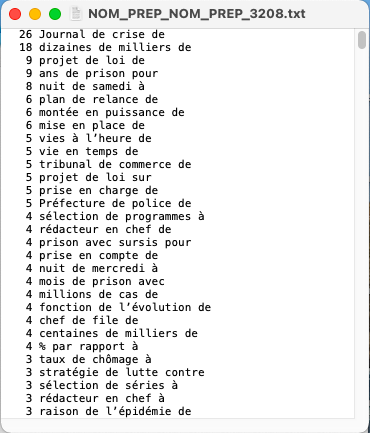


Les fichiers de patron et les résultats pour chaque rubrique sont disponibles ci-dessous.
1.2 Feuille de style XSLT (Treetagger et UDpipe)
Treetagger
Pour extraire des patrons des résultats XML, on peut utiliser des feuilles de styles XSLT. Il y a une feuille de style par patron. En choisissant la méthode de sortie texte et en utilisant la commande 'xsltproc' sur Terminal, on obtient des fichiers de résultats similaires à ceux vus précédemment (on a aussi enchaîné le lancement avec les commandes Bash pour trier et compter les résultats). La transformation xsl se lance donc comme suit :
Un exemple pour montrer à quoi ressemble les résultats :
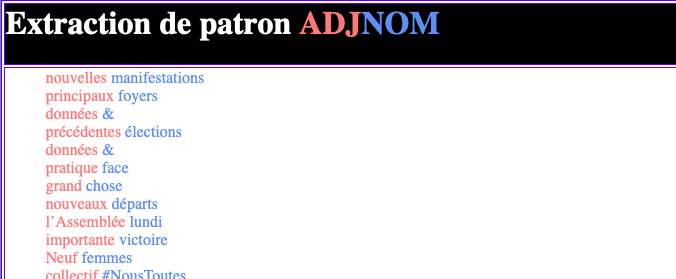
Les autres résultats sont disponibles à télécharger ci-dessous :
Les étiquettes utilisées ici sont un peu différentes que celles dans les patrons
UDpipe
Les résultats d'UDpipe sont disponibles à télécharger ci-dessous :
Ne pas oublier de convertir le fichier txt en xml avec le script udpipe2xml-version-sans-titrevsdescription-v2.pl
1.3 Requêtes XQuery
Une autre façon de fouiller les données des fichiers XML est de faire des requêtes XQuery, en passant par le logiciel BaseX. Pour l’extraction, on peut écrire une requête par un patron, mais on peut aussi combiner les différents patrons en utilisant 'or' qui permet de rendre compte de l'alternative dans le filtrage des résultats à renvoyer. L’avantage de Xquery est que l’on n’a pas besoin de changer à chaque fois la requête, on change juste le nom de fichier une fois que la requête est bonne, pour pouvoir traiter les autres fichiers. En plus, j’ai changé le nom des fichiers xml en pure chiffre (par exemple : XML-RSS_sortiexmlTT_3246 devient 3246) pour faciliter la modification.
Treetagger
- Requête pour extraire le patron NOM ADJ / ADJ NOM :for $titre in doc("3208")//titre for $element in $titre/element let $nextElement := $element/following-sibling::element[1] where ($element/data[1] = "NOM" and $nextElement/data[1] = "ADJ") or ($element/data[1] = "ADJ" and $nextElement/data[1] = "NOM") return (concat($element/data[3]/text()," ",$nextElement/data[3]/text()))
Les résultats triés et comptés de l'extraction sont disponibles ci-dessous.
- Requête pour extraire les patrons VERB DET NOM / ADP ADV ADP / ADP DET NOM :for $titre in doc("3208")//titre for $element in $titre/element let $nextElement := $element/following-sibling::element[1] let $thirdElement := $element/following-sibling::element[2] where ($element/data[1][contains(text(),"PRP")] and $nextElement/data[1][contains(text(),"DET")] and $thirdElement/data[1] = "NOM") or ($element/data[1][contains(text(),"PRP")] and $nextElement/data[1][contains(text(),"ADV")] and $thirdElement/data[1][contains(text(),"PRP")] or ($element/data[1][contains(text(),"VER")] and $nextElement/data[1][contains(text(),"DET")] and $thirdElement/data[1][contains(text(),"NOM")])) return (concat($element/data[3]/text()," ",$nextElement/data[3]/text()," ",$thirdElement/data[3]/text()))
Les résultats triés et comptés de l'extraction sont disponibles ci-dessous.
- Requête pour extraire le patron NOM PREP NOM PREP : for $titre in doc("3208")//titre for $element in $titre/element let $nextElement := $element/following-sibling::element[1] let $thirdElement := $element/following-sibling::element[2] let $fourthElement := $element/following-sibling::element[3] where ($element/data[1][contains(text(),"NOM")] and $nextElement/data[1][contains(text(),"PRP")] and $thirdElement/data[1] = "NOM" and $fourthElement/data[1][contains(text(),"PRP")]) return (concat($element/data[3]/text()," ",$nextElement/data[3]/text()," ",$thirdElement/data[3]/text()," ",$fourthElement/data[3]/text()))
Les résultats triés et comptés de l'extraction sont disponibles ci-dessous.
UDpipe
- Requête pour extraire le patron NOM ADJ / ADJ NOM :for $p in collection("sortieUDpipe3208")//p for $item in $p/item let $sonfrere := $item/following-sibling::item[1] where ($item/a[4] = "ADJ" and $sonfrere/a[4] = "NOUN") or ($item/a[4] = "NOUN" and $sonfrere/a[4] = "ADJ") return concat($item/a[2],' ',$sonfrere/a[2])
Les résultats triés et comptés de l'extraction sont disponibles ci-dessous.
- Requête pour extraire les patrons VERB DET NOM / ADP ADV ADP / ADP DET NOM :for $p in collection("sortieUDpipe3208")//p for $item in $p/item let $sonfrere := $item/following-sibling::item[1] let $secondfrere := $item/following-sibling::item[2] where ($item/a[4] = "ADP" and $sonfrere/a[4] = "ADV" and $secondfrere/a[4] = "ADP") or ($item/a[4] = "ADP" and $sonfrere/a[4] = "DET" and $secondfrere/a[4] = "ADP") or ($item/a[4] = "VERB" and $sonfrere/a[4] = "DET" and $secondfrere/a[4] = "NOUN") return concat($item/a[2],' ',$sonfrere/a[2],' ', $secondfrere/a[2])
Les résultats triés et comptés de l'extraction sont disponibles ci-dessous.
- Requête pour extraire le patron NOM PREP NOM PREP : for $p in collection("sortieUDpipe3208")//p for $item in $p/item let $sonfrere := $item/following-sibling::item[1] let $secondfrere := $item/following-sibling::item[2] let $thirdfrere := $item/following-sibling::item[3] where ($item/a[4] = "NOUN" and $sonfrere/a[4] = "ADP" and $secondfrere/a[4] = "NOUN"and $thirdfrere/a[4] = "ADP") return concat($item/a[2],' ',$sonfrere/a[2],' ', $secondfrere/a[2],' ', $thirdfrere/a[2])
Les résultats triés et comptés de l'extraction sont disponibles ci-dessous.
2. Extraction de relations de dépendance
Sur les données annotées en dépendance (udpipe), on essaiera de construire des ressources pour extraire les items connectés dans une relation de dépendance donnée (tous les mots connectés dans la relation OBJ). Pour cela, on doit d’abord convertir les fichiers txt en fichiers xml avec le script udpipe2xml-version-sans-titrevsdescription-v2.pl fournie en cours. Ce script se lance comme ci-dessous :
On a de nouveau trois solutions :
- 2.1 avec XSLT
- 2.2 avec XQuery
- 2.3 avec Perl
2.1 Avec XSLT
On construira une feuille de styles XSLT pour extraire la liste de mots connectés dans une relation de type OBJ. La relation portée par un item est située dans la septième balise . Pour savoir si un élément reçoit une relation 'OBJ' on regarde si 'a[8]' contient 'OBJ'. Si c'est le cas, on récupère le contenu de la balise a[7], le numéro de position du gouverneur et le contenu de la balise a[1], la position de l’objet lui même. Après, on peut comparer la position du gouverneur à celle de l'objet. Si le gouverneur est plus grand, c’est-à-dire qu’il est derrière l’objet, inversement, si le gouverneur est plus petit, il est alors avant l’objet. Dans le cas où le gouverneur est avant, on utilise 'preceding-sibling' pour aller le chercher, et dans l'autre cas, on utilise 'following-sibling'.
Sur le terminal, on lance la commande comme suit :
Les feuilles de styles et les résultats pour chaque rubrique sont disponibles ci-dessous.
2.2 Avec XQuery
Avec xquery, c’est à peu près la même idée que XSLT, on change juste le plateforme.
- La requête est comme ci-dessous : for $item in collection("sortieUDpipe3208")//item where contains($item/a[8]/text(),'obj') let $depforme:=$item/a[2]/text() let $positionSource:=$item/a[1] let $positionCible:=$item/a[7] let $noeudC:= if (number($positionCible) < number($positionSource)) then ($item/preceding-sibling::item[number(a[1])=number($positionCible)]/a[2]/text()) else ($item/following-sibling::item[number(a[1])=number($positionCible)]/a[2]/text()) let $preresu:= string-join(($noeudC,$depforme)," ") group by $g:=$preresu order by count($preresu) descending return string-join(($g,count($preresu))," ")
Les résultats pour chaque rubrique sont disponibles ci-dessous:
2.3 Avec Perl
Même façon que pour l’extraction de patrons. Le script et les résultats pour chaque rubrique sont disponibles ci-dessous:
Les résultats pour chaque rubrique sont disponibles ci-dessous:
3 Représentation graphique
On arrive enfin à la fin de cette tâche. À partir des données obtenues triées dans la BàO3, on sait quel sont les termes pertinents pour chaque rubrique. Grâce à cela, on peut réaliser la représentation graphique des différents fichiers à l'aide du programme patron2graphe fourni au cours. Ce programme existe sous plusieurs extensions, dont l’extension .exe n’est que pour windows, l’extension.pl marche sur tous les systèmes, et le fichier exec ne marche que sur unix ou macOS. Nous avons utilisé la version pour macOS.
Les graphes de mots permettent de compter et visualiser les contextes morphosyntaxiques d'un ou plusieurs mots. Ce qui est particulièrement utile pour interpréter les résultats. Comme démonstration, nous allons mettre en perspective un nom qui nous concerne trop cette année : 'épidémie'. Nous l'observerons avec le patron NOM_PRPE_NOM_PREP qui possèdent le plus de formes.
Pour lancer ce programme, ll nous avant besoin d'un fichier texte qui contient le motif, et dans lequel il est représenté par : MOTIF=\bépidémie (\b sert à marquer le début du mot).
La commande SHELL suivante sera appliquée sur chaque fichier pour un motif :
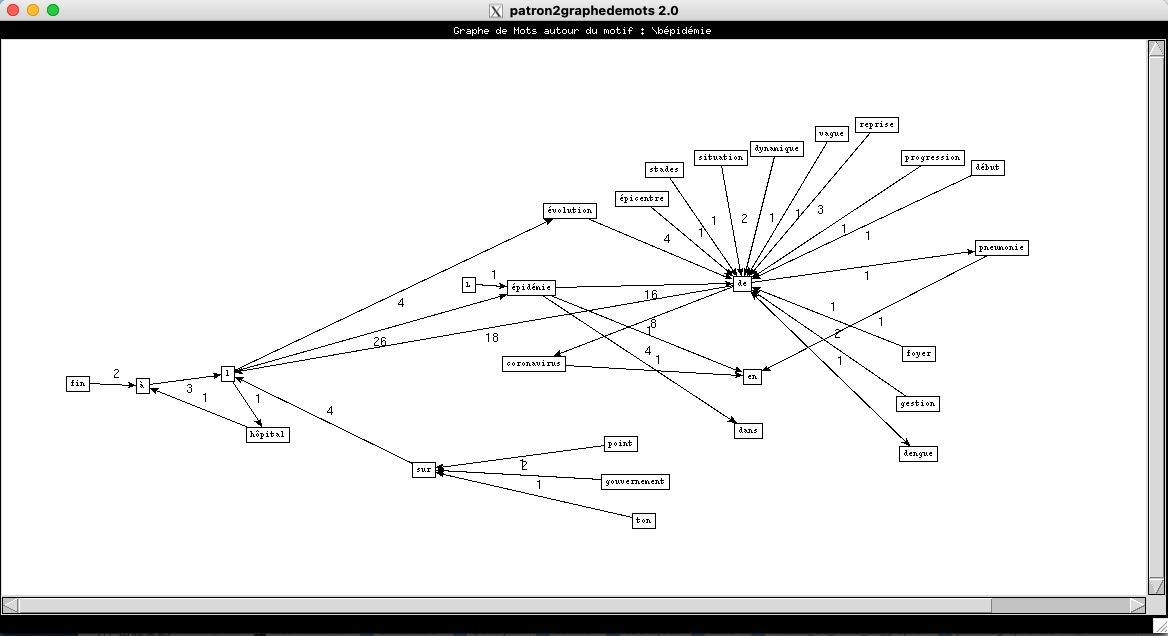
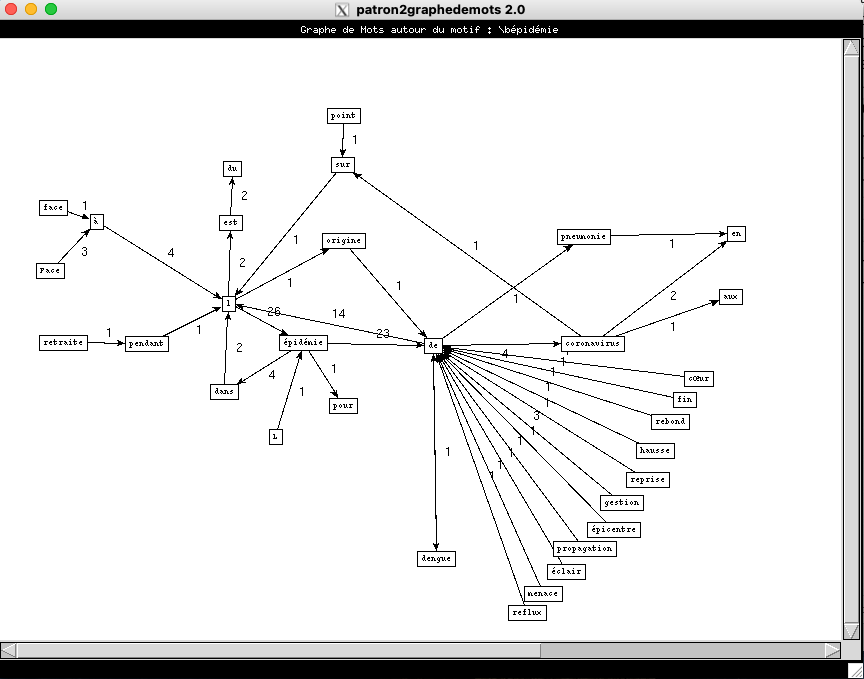
Visualisation pour les patrons NOM-PREP-NOM-PREP.
- Rubrique à la Une
- Rubrique Internationale
- Rubrique Culture
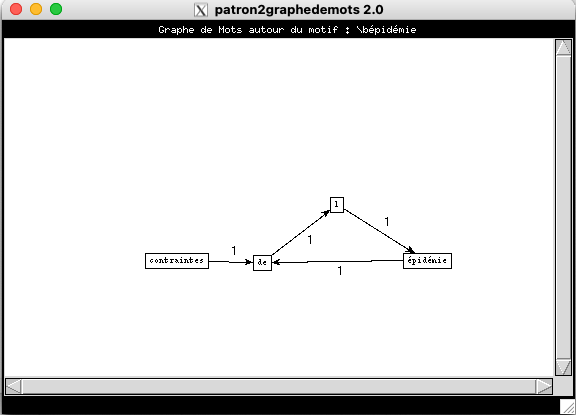
On voit que les résultats de la rubrique à la Une et Internationale se resemblent beaucoup, alors que les résultats de culture sont très peu nombreux.