Le script
Le but de cette étape est de construire le script en bash qui permet d'extraire et ensuite d'utiliser les données des liens récupérés auparavant.
Le script est construit selon les étapes suivantes (le schéma est récupéré sur le site du master TAL):
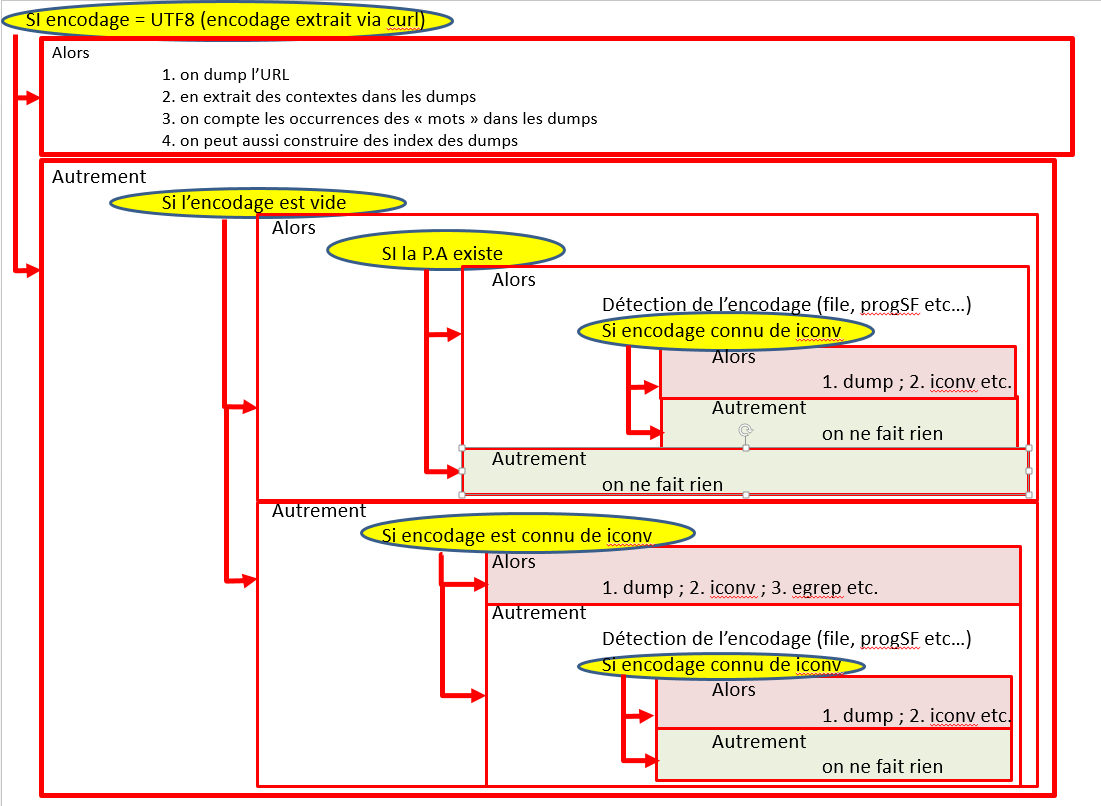
Le script construit permet de:
Le programme minigrep multilingue en perl a été utilisé pour construire le fichier du contexte au format html.
Vous pouvez trouver tous les détails, les commandes utilisées et les problèmes rencontrés sur le blog de ce projet.
La version finale du script est disponible ici.