Détails du script
Voici notre script en téléchargement dans sa forme finale : Script bash. Nous allons le reprendre ici en expliquant les différentes commandes utilisées.
Tout d'abord voici, d'un point de vue algorithmique ce qu'il fallait réaliser :
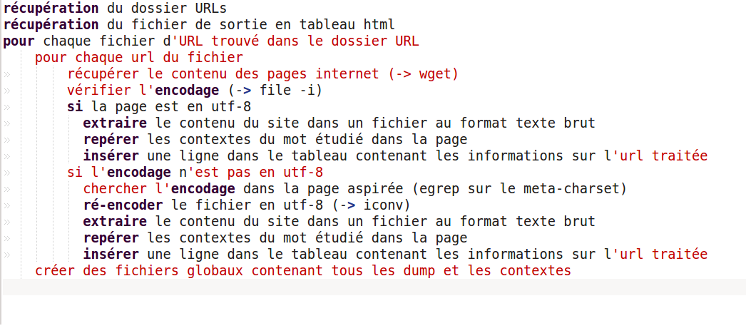
Lecture des fichiers d'entrée et redirection vers le fichier de sortie
Comme nous devons afficher tous les résultats dans un tableau, nous allons d'abord devoir rediriger toutes les sorties et créer un fichier pour contenir notre tableau. De même, il faudra que tous nos résultats soient récupérés dans ce tableau, pour cela nous lui attribuons une variable $tableau et nous redirigeons les données de cette façon :
- echo "résultats" >> $tableau
Il faut aussi récupérer les fichiers contenant les url dans leur dossier spécifique. Pour faire ces deux actions : avoir le nom et le chemin du dossier des fichier url et le nom et l'emplacement du fichier de notre tableau, nous utilisons la commande read. Notez que notre programme se situe dans le dossier PROGRAMMES de notre environnement de travail. Nous lançons le programme à partir de ce dossier, il faut donc toujours indiquer où se trouvent les éléments du script et les fichiers utilisés. Pour une meilleure automatisation, nous n'utilisons que des chemins relatifs, cela est utile pour pouvoir réutiliser le programme pour un autre mot (cf Pour aller plus loin) :
read dossierurl
read tableau
Pour ne pas avoir à taper à la main le chemin des fichiers url et le chemin et le nom du fichier tableau, nous créons un fichier de paramètres, la première ligne contient le chemin relatif du dossier des fichiers url et la deuxième ligne contient le chemin et le nom du fichier tableau de sortie, ainsi on peut lancer le script en lui indiquant le fichier paramètre comme input et il assignera automatiquement la première ligne à la variable $dossierurl et la deuxième ligne à la variable $tableau, notre commande de lancement du programme devient alors :
- bash script.sh < fichier_parametres.txt
Nous allons pouvoir réutiliser ces deux variables dans notre programme donc sans plus attendre ... Let's bash !
Réalisation du tableau pour l'url traitée, un peu d'html ...
Nous l'avons dit, nous voulons à la fin, un tableau contenant le numéro du lien, les liens vers le site, vers la page aspirée, vers le dump et vers le fichier de contexte. Pour cela, nous devons d'abord créer un fichier html qui contiendra notre tableau. C'est la commande echo qui sert à imprimer un texte que l'on va rediriger vers le fichier tableau (nous avons créé la variable $tableau contenant le nom de notre fichier et son chemin plus haut, nous allons la réutiliser !).
En html, la balise "<"table">" permet de commencer un tableau, au milieu, nous ajoutons les lignes avec "<"tr">" et les colonnes avec "<"td">". Pour ajouter la première ligne du tableau, on écrit donc :
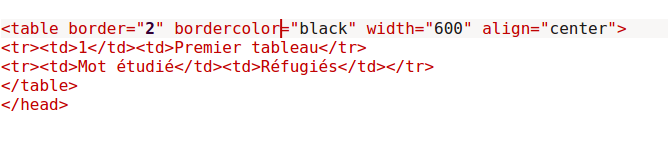
Après ajout des balises qui feront du ficher un vrai fichier html, c'est à dire les balises html, head, body ainsi que le meta charset, nous devrions obtenir quelque chose comme ça :

Enfin, quand nous ajoutons le code de cette page html dans un script bash, nous le mettons après une commande echo et une redirection de flux pour que tout cela soit ajouté dans le fichier tableau.
- echo "<table><tr><td>Premier tableau</td></tr></table>" >> $tableau
Ceci ne donne qu'un tableau à une ligne et une colonne, donc une boîte mais voilà le principe pour construire un tableau en html à partir d'un script bash ! Reste à remplir avec les informations que l'on veut, nous allons d'abord aller chercher ces informations.
La commande Wget
Nous traitons donc le premier fichier contenu dans le dossier URLs et dans ce fichier nous traitons la première url, nous devons récupérer le contenu du site, pour cela nous utilisons la commande wget. C'est en fait un programme qui peut s'utiliser en ligne de commande justement pour télécharger du contenu depuis le web. La syntaxe est la suivante :
- wget [option] [url]
La commande wget possède de nombreuses options. Il y en a une qui nous intéresse particulièrement : -O. Elle permet d'enregistrer le contenu de la page dans un fichier. L'option -O est donc suivie du nom du fichier html dans lequel enregistrer le contenu de la page. Voilà le résultat :
- wget url -O nom_fichier.html
Lynx : formatage en texte brut
Cela étant fait, nous voulons transformer ce fichier html en texte brut pour pouvoir le traiter par la suite. Pour cela nous faisons appel à un navigateur qui s'utilise en ligne de commande : lynx. Avec certaines options, il permet d'extraire le contenu de la page web. Cette première option s'appelle dump, on ajoute à celle-ci une option -nolist qui va supprimer tous les liens contenus dans la page, c'est une première étape de nettoyage du fichier obtenu. En effet, l'ensemble des liens n'est pas pertinent dans l'analyse qui va suivre. On obtient donc la ligne de commande suivante :
- lynx -dump -nolist url
Enfin on ajoute les options display_charset et assume_charset, qui, respectivement, forcent l'encodage de départ des pages qui n'en spécifient aucun et encode le fichier d'arrivée. Pour définir le fameux fichier d'arrivée, on ajoute la redirection de flux vers le nom du fichier cette fois-ci au format txt :
- lynx -dump -nolist -assume_charset=encodage -display_charset=encodagesortie url > nom_fichier.txt
Recherche des contextes
Une fois le contenu de la page récupéré, nous allons chercher dans le site les contextes dans lesquels sont utilisés notre mot, "réfugiés". Pour cela, on utilise une expression régulière avec la commande egrep (quelques explications ici) à laquelle on ajoute différentes options.
La première option est -i qui permet d'ignorer la casse, ainsi on pourra trouver aussi bien "réfugiés" que "Réfugiés" que "RéFugIs" si besoin est. Ensuite on ajoute l'option -o, seuls les matchs trouvés sont affichés (et non le fichier entier avec les matchs en surbrillance), un sur chaque ligne.
- egrep -i -o "mot" > fichiercontexte.txt
Pour avoir le nombre d'occurence du mot dans le tableau, on va ajouter l'option -c (count) pour qu'il nous indique combien de fois il a trouvé le mot dans le site en question, on reprend donc la même expression régulière, mais en ajoutant -c. Notez qu'on peut regrouper les options ainsi :
- egrep -ioc "mot" > fichiercontexte.txt
Avec tout ça, on obtient la ligne du tableau concernant une url, donc quelque chose comme ça :
| Tableau 1 | |||||||
| N° | URLs | Pages aspirées | Encodage d'origine | Encodage final | Dumps | Contextes | |
| 1 | Lien n°1 | Page aspirée 1 | utf-8 | utf-8 | Dump 1-1 | Contexte | |
La prochaine étape est donc de pouvoir faire cela automatiquement pour chaque fichier d'url et ensuite pour chaque url, on va mettre en place des boucles !
Généralisation pour chaque url et chaque fichier
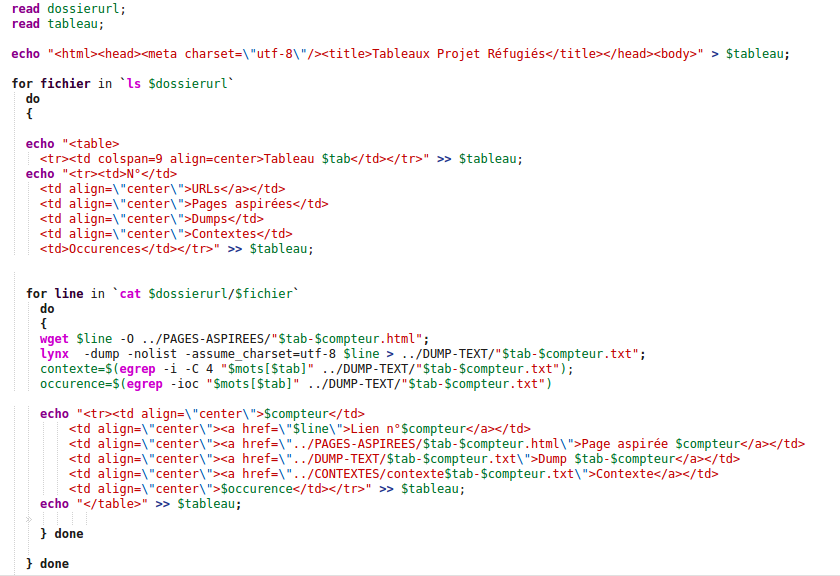
La première boucle va nous permettre de parcourir tous les fichiers du dossier. On utilise une boucle for à laquelle on donne une première variable $fichier et ensuite la commande ls pour traiter tous les fichiers contenus dans le dossier $dossierurl dont on a parlé plus haut. La syntaxe est donc la suivante :
- for line in `ls $dossierurl`
La variable $line ne s'affiche pas comme une commande dans le script mais c'est normal, inutile de paniquer comme nous l'avons fait ! Il faudra bien entendu fermer la boucle à la fin du script et indiquer quelle est finie avec le mot done. Voilà donc le traitement pour une url.
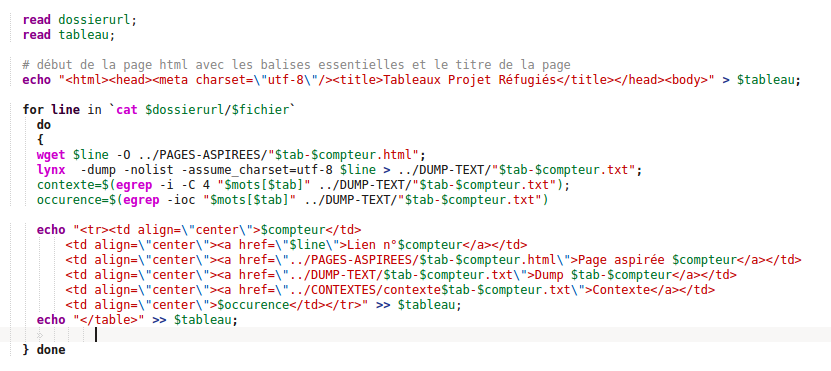
Nous devons maintenant, à l'intérieur de chaque fichier traiter chaque url. Chaque url se trouve sur une ligne différente du fichier, on va donc refaire une nouvelle boucle (toujours une boucle for) pour chaque ligne du fichier. Cette fois ce n'est pas ls que nous allons utiliser mais cat qui permet de parcourir le contenu d'un fichier. La deuxième boucle ressemble donc à ça :
- for fichier in `cat $dossierurl/$fichier`
Comme pour la boucle précédente on créé la variable fichier, et on indique ensuite dans cat le chemin relatif du fichier que l'on souhaite. C'est aussi dans cette boucle qu'on va inclure l'ouverture des balises table et la première ligne du tableau, puisqu'on réalise un tableau par fichier, un tableau pour toutes les urls de chaque langue et une ligne de tableau pour chaque url.
Réalisation des dumps et contextes globaux
Pour le traitement final nous avons besoin de fichiers rassemblant tous les dumps, nous allons aussi réaliser un fichier contenant tous les contextes. Ce sont les commandes echo et cat combinées qui vont nous permettre d'inclure le contenu du fichier dump que l'on vient de créer dans un fichier global.
- echo `cat ../DUMP-TEXT/"$tab-$compteur` >> ../FICHIERSGLOBAUX/"dumpglobaux-$tab"
Pour les contextes, on créé d'abord la variable contexte qu'on va ensuite ajouter dans le fichier global. Pour la variable des contextes on utilise de nouveau egrep mais cette fois on utilise l'option -C suivie d'un nombre qui indique le nombre de ligne que l'on veut prendre avant et après l'expression régulière. On pourrait aussi utiliser les options -A et -B qui permettent de choisir le nombre de ligne avant (-B, before) et le nombre de ligne après (-A, after).
- contexte=$(egrep -i -C 4 "$mots[$tab]" ../DUMP-TEXT/"$tab-$compteur")
- echo "$contexte" >> ../FICHIERSGLOBAUX/"contextesglobaux-$tab"
On créé aussi un fichier pour chaque contexte, c'est exactement comme pour la création des fichiers dumps :
- echo "$contexte" >> ../CONTEXTES/"$tab-$compteur"
Enfin n'oublions pas d'ajouter tout cela dans le tableau ! Nous reprendrons tout cela à la fin du script.
Problèmes d'encodage
Voilà le point le plus difficile du projet, gérer l'encodage des pages de départ et maîtriser l'encodage final des dumps et contextes. Pour commencer, nous avons choisi d'utiliser la commande file. Elle détecte l'encodage d'un fichier avec l'option -i. Le résultat est sous cette forme : text/plain; charset=encodage. On ne veut que l'encodage, d'où l'utilisation du cut avec les options -f (field) qui indique quel champ retenir et -d pour définir le délimiteur de champ. Dans cette expression le délimiteur le plus évident est le =, ce qui fait de l'encodage le champ n°2, enfin on va mettre tout ça dans une variable encodage et le tout donne :
- encodage=$(file -i "$mots[$tab]" ../PAGES-ASPIREES/"$tab-$compteur" | cut -f2 -d=)
Le problème vient du fait que file ne reconnaît pas tous les encodages. Loin de là ... (Explications complémentaires ici) Il faut donc trouver une autre solution pour les pages que file ne reconnaît pas. Nous retrouvons (encore !) la commande egrep pour trouver le charset indiqué dans la page html par une expression régulière et sur le résultat on évalue l'expression avec la commande expr pour ne retenir que ce que l'on veut c'est à dire un nom d'encodage du type "utf-8" ou "iso-8859-1" qu'on va pouvoir réutiliser. Nous finissons avec un sed pour supprimer les guillements qui pourraient rester.
- charset_line=$(egrep-m 1 "charset=.*\"" ../PAGES-ASPIREES/"$tab-$compteur.html")
- charset=$(expr"$charset_line" : '.*=\(.*\)\"' | sed 's/\"//g' )
Il faut donc insérer une condition, si le résultat du file n'est pas satisfaisant, il faut passer à la recherche du charset, la boucle if rentre en jeu ainsi que ses copains : elif et else. En effet deux encodages sont ressortis de nos recherches utf-8 et iso-8859-1, on les a utilisé dans des if spécifiques et c'est dans le else qu'on insère la recherche du charset pour les autres. Nous avons décidé de rajouter le cas où, dans le charset, nous retrouvons utf-8 mais la page est en fait écrite dans un autre encodage et donc file n'a pas trouvé utf-8, alors de nouveau on lance le traitement de la page normalement sinon, on va convertir l'encodage.
- if [[ "$encodage" == "utf-8" ]]
- elif [[ "$encodage" == "iso-8859-1" ]]
- else
- if [[ "$charset" == "utf-8" ]]
- else
Enfin, pourquoi chercher ces encodages ? Une fois les dumps et contextes (globaux ou non) récupérés, pour les utiliser dans le Trameur, il ne faut pas avoir dans certains cas "réfugiés" et dans d'autres "r&!fugi&!s", Le Trameur ne reconnaîtrait pas ces deux occurences mais une seule des deux. Pour convertir ces fichiers afin d'avoir un corpus entièrement en utf-8 nous allons faire appel à la commande iconv. Elle nous a réservé des surprises ...
Une fois l'encodage défini dans la variable $encodage ou $charset on utilise cette variable dans iconv. Les options -f (from) et -t (to) vont donner les encodages de départ et d'arrivée du fichier.
- iconv -f $encodage/$charset -t UTF8 ../DUMP-TEXT/$tab-$compteur.txt > ../DUMP-TEXT/"$tab-$compteur.txt"
Dans notre programme, nous avons trouvé beaucoup d'url espagnoles encodées en iso-8859-1 et pour ces urls, iconv ne semble pas accepter la conversion. Nous n'avons malheureusement pas trouvé de solution pour ces urls mais nous savons aussi que Firefox choisi automatiquement un encodage Occidentla et no nUnicode pour plusieurs de nos fichiers, lors de l'affichge des dumps à partir du tableau, il suffit parfois simplement de forcer Firefox à choisir un affichage en Unicode et tous les problèmes d'accents disparaissent ! Nous n'avons pas noté de problèmes particuliers d'affichage des résultats lors de notre analyse ultérieure.
Ajout des balises "contexte" dans les fichiers de contextes globaux
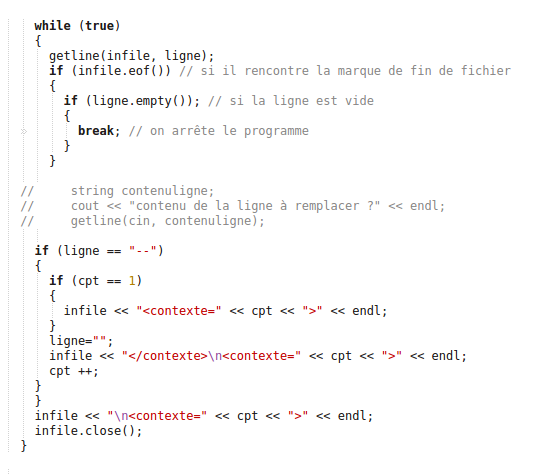
Nous avons voulu ajouter une balise contexte dans les fichiers globaux des contextes pour pouvoir faire des comparaisons entre l'utilisation du mot "réfugiés" pour chaque site mais aussi phrase par phrase donc contexte par contexte. Cependant, comme nous avons dans certains cas plusieurs occurences pour chaque site, il nous fallait insérer une nouvelle balise. Pour cela nous avons créé un nouveau programme, cette fois en c++ qui recherche le délimiteur de contexte rendu par le egrep pour les remplacer par des balises comprises par le Trameur. Voici le lien vers le programme : Programme c++ mais voilà son contenu (partiel) en aperçu :
Bonus : Pimp my table
Pour donner un air un peu plus sympa à notre tableau, nous avons utilisé différentes options des balises html. D'abord l'option border pour donner la largeur des bordures du tableau, leur couleur avec border-color et bgcolor pout définir la couleur du fond de la cellule. Les balises de couleur en html acceptent des noms de couleurs (les plus courantes, black, red, green) non modifiables, nous ne pouvons pas choisir la profondeur du rouge ni sa clarté, etc, nous avons utilisé le site Colorpicker qui donne un numéro pour chaque couleur qu'on peut ensuite placer dans les balises précédées d'un dièse #. Ainsi on maîtrise beaucoup mieux et avec plus de finesse les couleurs du site.