Traitement - scripts
Dans cette partie nous abordons la structure du script ainsi que les étapes importantes de son élaboration. Celui-ci (ou plutôt ceux-ci) peut (peuvent) par ailleurs être récupéré ici (version commentée, qui fonctionne pour le français, l'anglais et l'espagnol) et là (version non commentée, qui fonctionne pour le coréen). Pourquoi deux versions? Parce que...
La rédaction du script qui permet le traitement automatisé du corpus se compose de plusieurs étapes que nous avons suivies tout au long du semestre, des étapes accompagnées de leur lot de découvertes et de difficultés:
- Création d'un tableau de liens en html
- Création d'un tableau de liens avec des liens externes vers les pages visées et des liens internes vers les pages correspondantes aspirées
- Extension du tableau de liens jusqu'à 3 colonnes (URL, fichier aspiré, dump) et traitement de l'encodage
- Multiplication du nombre de tableaux selon le nombre de langues étudiées
- Ajout de la colonne "contextes"
- Compte du nombre d'occurrences
A partir des instructions de chacune des étapes, on en arrive à construire un script structuré globalement de la manière suivante:
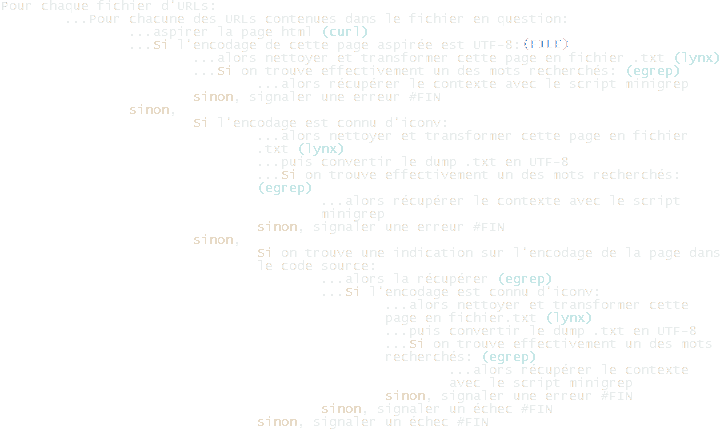
Il est aussi possible de suivre les étapes une à une en lisant les billets de notre "Journal de Bord", un blog sur lequel nous avons décrit en détail les nouvelles commandes apprises, ainsi que ce qui nous avait été demandé à chaque séance. On ne rappellera donc pas ici la fonction de chacune des commandes apprises.
En revanche il est important de s'arrêter sur l'une d'entre elles: file (4e ligne dans l'image).
La commande file
Cette commande a pour fonction principale dans notre script de récupérer l'encodage de la page aspirée, encodage que nous réutilisons par la suite pour d'abord savoir si il s'agit d'utf-8, et si ce n'est pas le cas de savoir s'il est connu de la commande iconv afin de lui spécifier un encodage de sortie pour la conversion.
[VU EN G.I.M.] Or, voici la description de la commande file dans son manuel d'utilisation:
[A file] is examined to see if it seems to be a text file. ASCII, ISO-8859-x, non-ISO 8-bit extended-ASCII character sets (such as those used on Macintosh and IBM PC systems), UTF-8-encoded Unicode, UTF-16-encoded Unicode, and EBCDIC character sets can be distinguished by the different ranges and sequences of bytes that constitute printable text in each set. If a file passes any of these tests, its character set is reported.
Autrement dit, file se base sur la structure des octets pour repérer l'encodage d'un fichier. Il peut dont déterminer de manière sûre s'il s'agit d'un fichier ASCII (tous les caractères doivent être sur un seul octet, sur 7 bits), ou bien UTF-8 (structure spéciale pour un caractère de 2 à 4 octets) ou UTF-16 (Byte Order Mark), ou aucun de ceux-là. Les autres encodages 8 bits ne se distingue pas au niveau des octets, ce qui ne permet pas à file d'aller plus loin...
... mais ne l'empêche pas d'essayer. En effet, lorsque l'on lance le script décrit ci-dessus sur les URLs coréennes, on constate que file renvoie toujours ISO-8859-1 alors qu'il est évidemment impossible d'écrire du coréen avec une telle table! Cette erreur de file fausse donc complètement le reste des traitements, de la conversion en utf-8 à l'extraction des contextes. C'est pour cela que dans notre second script, nous avons retiré la commande file, ce qui a pour incidence la recherche immédiate de l'encodage dans les métadonnées des pages html. Et heureusement, avec ça, ça marche!