Etape 1
Créer l'environnement de travail
Tout d'abord, nous avons créé l'arborescence dans le dossier personnel de nos machines en lançant le script prepare-environnement.sh. Ensuite, nous avons placé nos fichiers d'urls dans le dossier URLS et notre début de script ainsi qu'un fichier .txt contenant les chemins vers les fichiers d'urls et le tableau dans le dossier PROGRAMMES.
On évite pas mal de problèmes en se rappelant que pour écrire un chemin ./ signifie que l'on reste dans le répertoire courant alors que ../ nous ramène au répertoire 'supérieur'.

Etape 2
Aspiration des pages web
Nous utilisons deux boucles for pour demander au programme d'effectuer un traitement pour chaque ligne de chaque fichier contenu dans le dossier URL. Ce traitement consiste à aspirer les pages web correspondant aux urls et à produire un tableau html dans lequel classer les données extraites.
Nous avons utilisé la commande wget pour aspirer les pages web et avons beaucoup apprécié cette page qui liste à quoi correspondent les erreurs que renvoie wget (en particulier, l'erreur 4, qui rappelle subtilement qu'une connexion internet pour aspirer des pages web, c'est mieux) : erreurs wget.
Par ailleurs, s'assurer que les fichiers d'urls et le fichier input sont encodés en utf-8 sans BOM peut s'avérer utile.
Etape 3
Les problèmes d'encodage
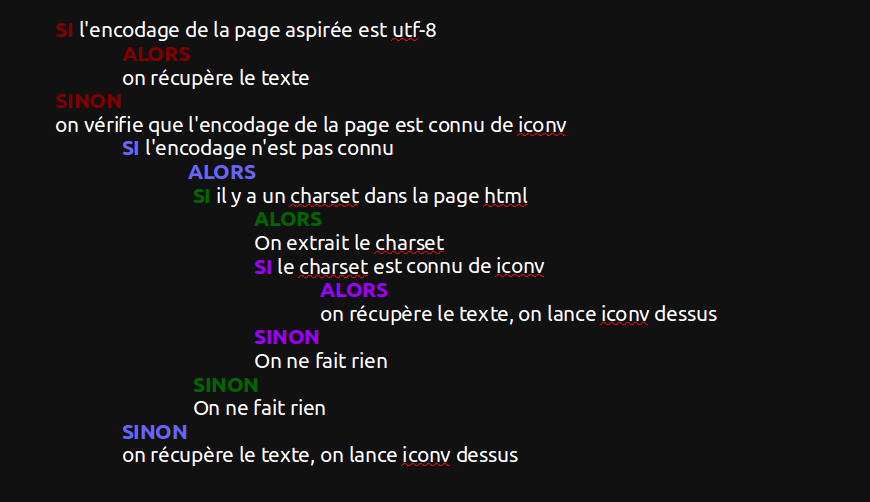
On souhaite traiter du texte encodé en utf-8, pour que cette condition soit remplie, nous avons utilisé l'emboîtement de "if" comme indiqué ci-contre.
La syntaxe de Bash peut varier d'un système à l'autre, en général l'erreur "opérateur unaire inattendu" est dû à un espace manquant ou un espace en trop dans les crochets d'une condition telle que if [ x=utf-8 ].

Etape 4
Récupération du texte des pages aspirées
On utilise lynx et on envoie le texte que cette commmande extrait dans le dossier DUMP. Une fois ces fichiers créés, on peut utiliser la commande egrep pour récupérer les motifs que l'on cherche à l'aide d'une expression régulière et envoyer les contextes récupérés dans le dossier CONTEXTES.
La commande lynx n'est pas toujours installée par défaut, lancer sudo apt-get install lynx, ça vous change la vie.
Etape 5
Concaténation dans des fichiers globaux (utiles pour les outils de textométrie)
On concatène, à l'aide de la commande cat, tous nos fichiers dump et tous nos fichiers de contextes dans deux fichiers globaux dont on se sert pour créer des nuages de mot par la suite.
La commande cat, elle fait plein de choses utiles : en savoir plus sur cat !

Etape 6
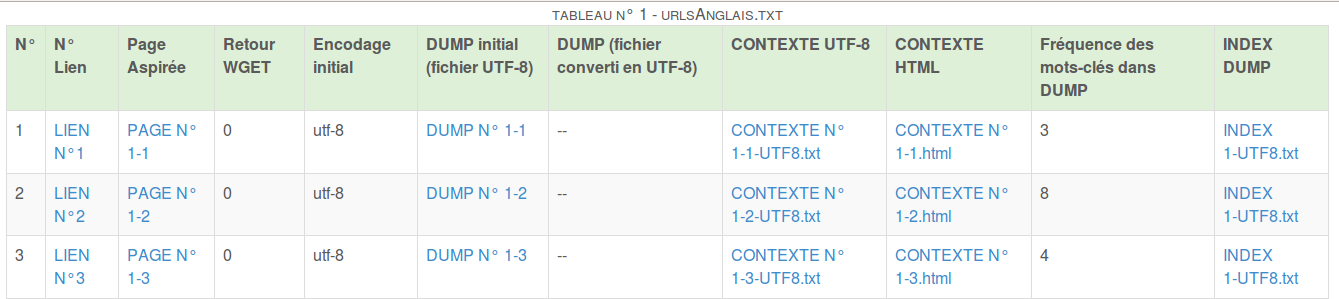
Création et remplissage des colonnes du tableau html
On utilise la commande echo pour écrire des balises dans notre fichier html (nommé dans le fichier input) permettant de créer un tableau (<table> pour le tableau, <tr> pour une ligne, <td> pour une colonne).