Documents Structurés
Site réalisé dans le cadre du cours de Documents Structurés par Kelly MASCLEF et Julie SAUVAGE.
Visiter le site
Site réalisé dans le cadre du cours de Documents Structurés par Kelly MASCLEF et Julie SAUVAGE.
Visiter le site
Programmation et Projet Encadré 1 du Semestre 1 par Kelly MASCLEF et Julie SAUVAGE (et avec Julie BELIAO).
Visiter le site
Programmation et Projet Encadré 1 du Semestre 1 par Ilaria TIDDI (avec Marcelo MATOSO et Camille DOUDANE).
Visiter le site



Le but de la deuxième boîte à outils est de procéder à l'étiquetage morpho-syntaxique de chaque token/mot des fils RSS récupérés. Pour cela, on dispose de deux étiqueteurs:
On ouvre dans Cordial le fichier texte que l'on a créé spécialement dans la BàO1 et qu'on avait sorti en ISO-8859-1
open (FILEOUTTXT,">:encoding(iso-8859-1)","SORTIE-$nomRub.txt")
On n'oublie surtout pas de modifier les paramètres pour obtenir le format désiré:
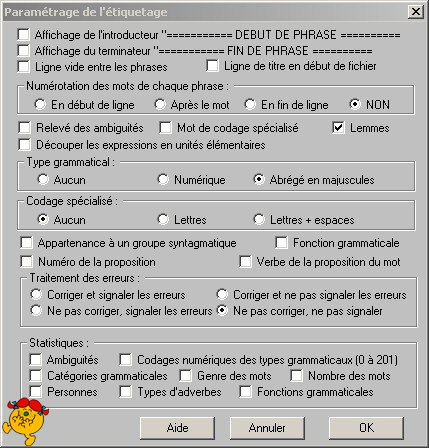
Pour visualiser le résultat, cliquez ici
Pour l'étiquetage avec TreeTagger, nous avons intégré au script à la loyale de BàO1 quelques lignes supplémentaires.
#-------CRÉATION DES FICHIERS EN SORTIE------- #On crée un fichier pour chaque sortie différente (TXT, XML) my $TXT4TT="Entrée_TreeTagger.txt"; my $TreeTagger="Sortie_TreeTagger.txt"; open (OUTXML,">:encoding(utf-8)",$TXT4TT);
#On écrit les sorties nécessaires dans les fichiers print OUTXML "$titre $resume";
sub etiquetage {
system("perl ./TreeTagger/cmd/tokenize.pl $TXT4TT |
./TreeTagger/bin/tree-tagger -token -lemma -no-unknown -sgml
./TreeTagger/lib/french-utf8.par > $TreeTagger");
system("perl ./treetagger2xml__modif.pl $TreeTagger");
}
La syntaxe de TreeTagger: tree-tagger [options] <paramètres> <textein> <texteout>
La commande system permet de lancer un processus à partir de Perl. On va d'abord lancer la tokenization sur le fichier, le résultat est ensuite envoyé à tree-tagger (auquel on a spécifié un fichier de configuration en français). Les différentes options permettent d'avoir l'étiquetage en tokens (mots), en lemmes, etc. L'option -no-unknown permet de ne pas avoir de catégorie UNKNOWN dans le fichier étiqueté. Enfin, l'option -sgml permet à TreeTagger de ne pas interpréter les balises!
Pour télécharger ce script, cliquez ici
Pour visualiser ce script, cliquez ici
Pour visualiser le résultat, cliquez ici
Une fois qu'on a obtenu un fichier au format texte brut contenant l'étiquetage, on peut le convertir au format XML via un autre script (qui nous a été fourni et que nous n'avons pas eu à modifier dans la mesure où le résultat obtenu est tout à fait satisfaisant).
&ouvre; &entete; &traitement; &fin; &ferme;
# Récupération des arguments et ouverture des tampons
sub ouvre {
$FichierEntree=$ARGV[0];
open(Entree,$FichierEntree);
$FichierSortie=$FichierEntree.".xml";
$FichierSortie=~ s/\.txt//;
open(Sortie,">$FichierSortie");
}
# En-tête de document XML
sub entete {
print Sortie "\n";
print Sortie "\n";
print Sortie "<document>\n";
print Sortie "<article>\n";
}
sub traitement {
while ($Ligne = <Entree>) {
if ($Ligne!~/\ô\¯\:\\ô\¯\:\\/) {
# Remplacement des guillemets par <![CDATA["]]>
#(évite erreur d'interprétation XML)
$Ligne=~s/\"/<![CDATA[\"]]>/g;
$Ligne=~s/([^\t]*)\t([^\t]*)\t(.*)/<element>
<data type=\"type\">$2<\/data>
<data type=\"lemma\">$3<\/data>
<data type=\"string\">$1<\/data> <\/element>/;
print Sortie $Ligne;
}
}
}
sub fin {
print Sortie "</article>\n";
print Sortie "</document>\n";
}
sub ferme {
close(Entree);
close(Sortie);
}
Pour télécharger ce script, cliquez ici
Pour visualiser ce script, cliquez ici
Pour visualiser le résultat, cliquez ici