Automate a process to extract and look at various lexical patterns within a large corpus.
Write a series of scripts in Perl that can be generalized and modified to work in a variety of contexts for similar goals.
Display results as a collection of graphs side by side with our interpretations.
Our raw data comes from an RSS 2014 news feed from French newspaper Le Monde. The files are in XML format and organized in folders by month.
Our first tool reads the files within their file structure and extracts everything between the <title> and <description> tags. This data is then cleaned to replace escaped characters, remove images, and other untreatable data.
This tool takes the output from Tool 1 and passes it to two different part-of-speech taggers: TreeTagger and Cordial.
Tool 3 is composed of two different scripts, one for each output from TreeTagger and Cordial. It searches within the outputs for specified morphosyntactic patterns (e.g.: noun-preposition-noun).
Our last tool uses the found patterns to create visual representations of how these phrases manifest within the text.
What does Tool 1 do?
Perl
Perl with XPATH
Pure Perl
Perl Modules
A sample

what does Tool 2 do?
The professor's method
Tool 2 & Tool 3 & Tool 4
Pure Perl
Perl modules
A sample
What does Tool 3 do?
Using Perl
Using XPATH
Modification of the scripts
Patterns used
Extracted phrases
How we create these graphs
noun-adjective
noun-prep-det-noun
PCTFORTE ":"
CONJUNCTION
What can we conclude?
We are first-year Masters students in a Natural Language Processing program at the Institut National des Langues et Civilisations Orientales (INALCO) in Paris, France. You can find a detailed description of our program (in French) here.
What does tool 1 do?

Tool 1 is a program that reads the files within the file structure of an RSS feed from the French newspaper “Le Monde”. The files are organized in a folder named after the year we are searching through (2014). Within that folder are more folders, one for each month, and then inside each month's folder the actual XML and TXT files containing the articles and their markups are organized by subject (Actualité à une, cinéma, culture, économie, Europe, idées, international, livres, médias, planète, politique, société, sport, technologies, vous et voyage.>) For our purposes we will be ignoring the TXT files and solely treating the XML files.
Here's an example of one of the XML files:
Tool 1 extracts everything between the <title> and <description> tags in each XML file. As the RSS feed can possibly have duplicate articles, we make sure in the code that we treat each one only once by ignoring any repetitions. This data is then cleaned to replace escaped characters, remove images, and other untreatable data.
An example of the <title> and <description> tags to show what kind of data cleaning we have to do:

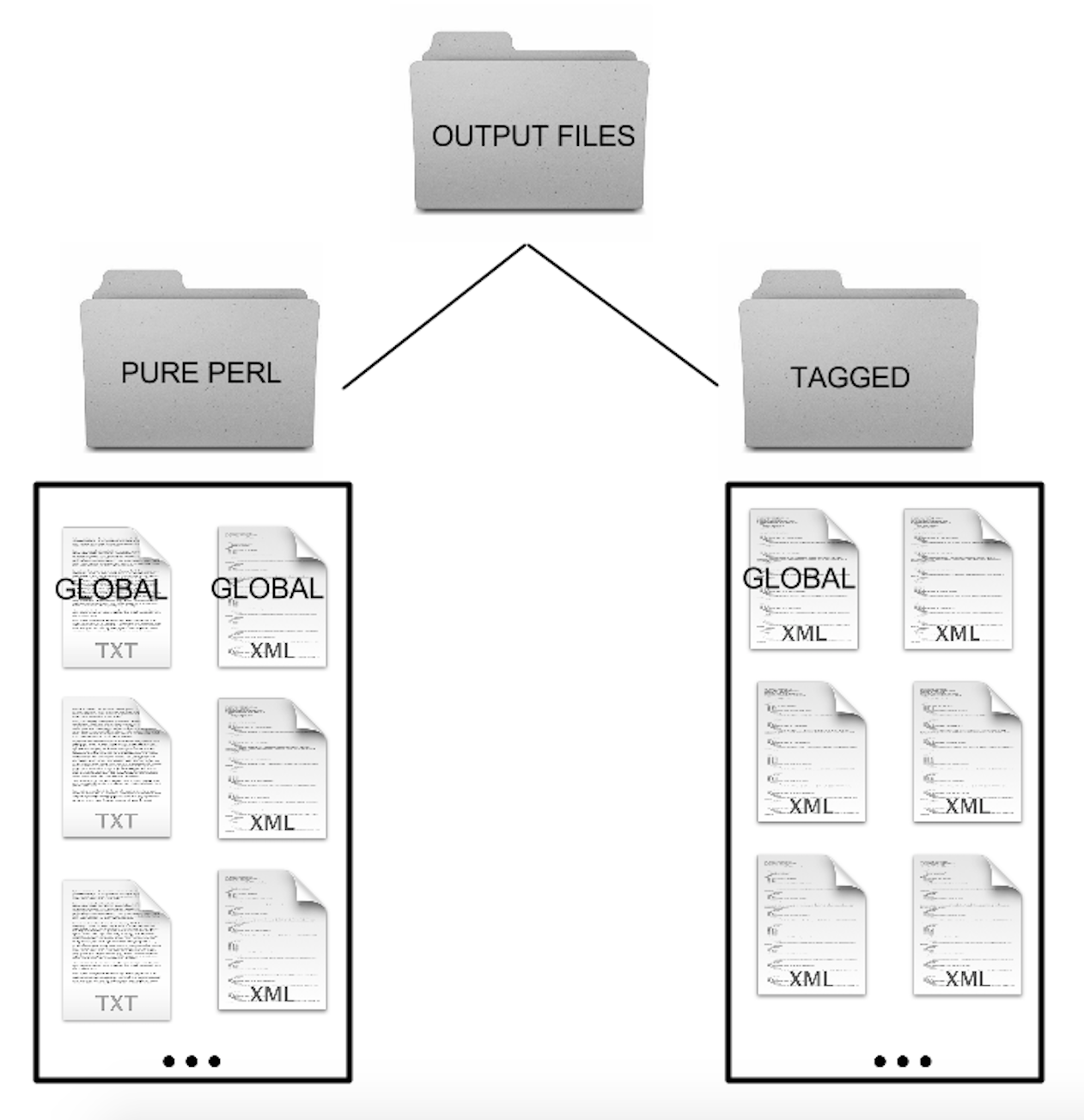
It produces two outputs: one in a TXT format and one in an XML format. The TXT format contains all the cleaned titles and descriptions in a file without tags or additional formatting information. The XML format retains the <title> and <description> tags so we can more easily see what text belongs to what category.
A diagram of the outputs from Tool 1

There are certain problems we need to look out for when writing our code, the first of which is encoding. The files might not necessarily all be encoded in the same way, we might have iso-8859-x or utf-8 for example, and we want all of our output to be in utf-8. A second issue is the formatting of the files, certain files contain the various tags on different lines and certain ones have them on the same line. We don't want to write two different scripts for these two cases so we had to find a way to treat both cases within the same script.
This step is extremely important to do correctly since it's creating the data set we'll be using and building upon in Tool 2, Tool 3, and Tool 4. Leaving a stray HTML entity in the data could have large consequences later on when we try to tag the word it contains.
Perl
A common theme you'll notice in our program categories is the classification of programs into two types: "pure Perl" or "Perl modules". In all cases, we're still using Perl (v5.xx.x) but in the programs that are labeled "pure Perl", we take a straight-forward approach. This means that all data treatment steps are clearly visible within the program and we don't use any of the externally written Perl programs (modules) available that may introduce unknown variables or destabilize the code. Instead, we use regular expressions to match the informations we're looking to extract.
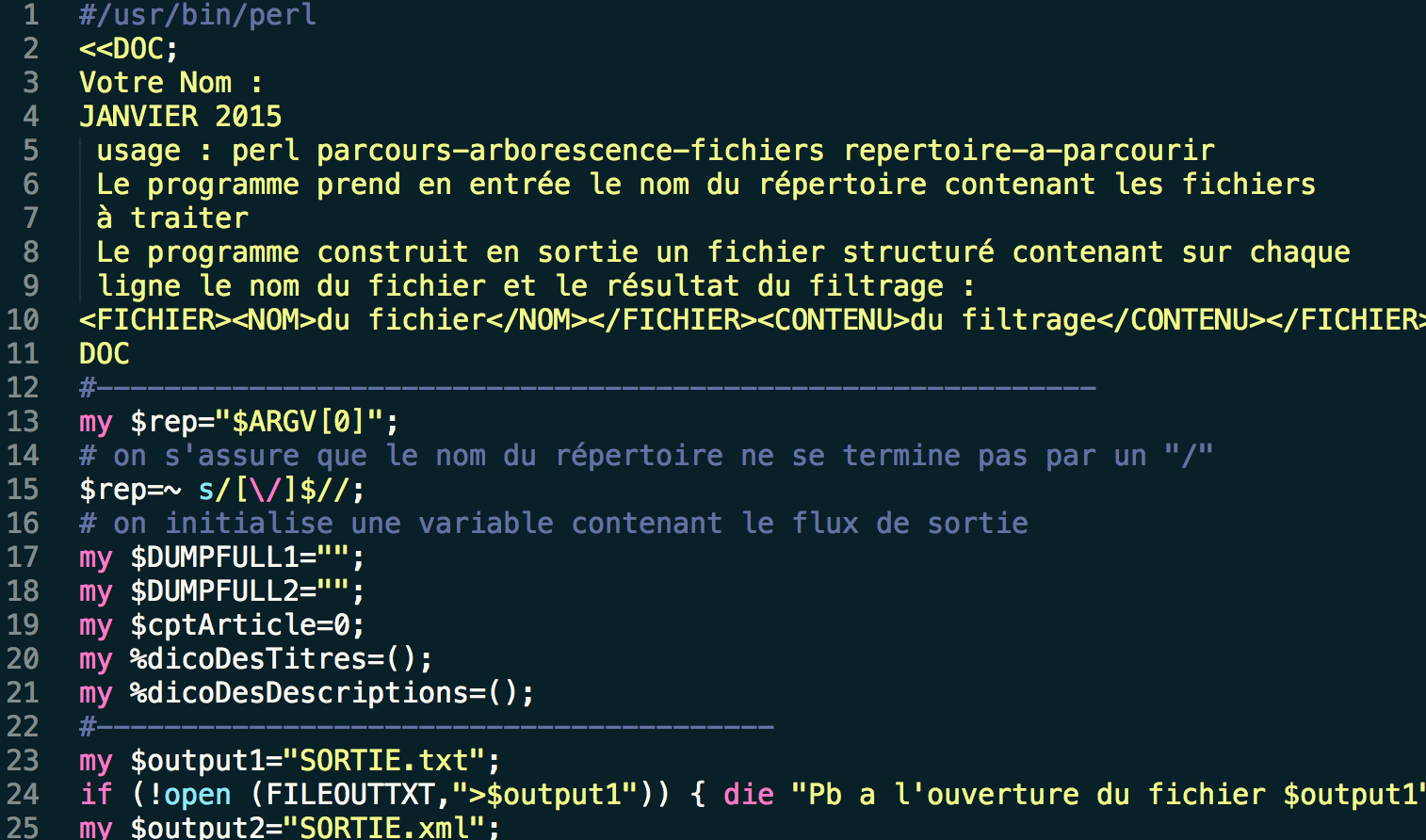
This script uses the "pure Perl" approach. To use this script you type "perl name_of_the_program.pl folder_of_files" into the command line. The program creates two outputs (TXT and XML, lines 23-26) and reads the file path to find the correct files with a recursive subroutine (line 28, function on lines 40-95).  This subroutine continues to call itself until it reaches the correct file. Then once it has the right file, it calls the subroutine for cleaning the text (lines 65 and 78)
This subroutine continues to call itself until it reaches the correct file. Then once it has the right file, it calls the subroutine for cleaning the text (lines 65 and 78)  and also verifies that we don't clean the same text two times by using a hash to store only one copy of each text. It also adds the XML tags when needed for the XML output. At the end of the program we print the outputs into their two files in the correct format (lines lines 33 and 36).
and also verifies that we don't clean the same text two times by using a hash to store only one copy of each text. It also adds the XML tags when needed for the XML output. At the end of the program we print the outputs into their two files in the correct format (lines lines 33 and 36).
- #/usr/bin/perl
- <<DOC;
- Votre Nom :
- JANVIER 2015
- usage : perl parcours-arborescence-fichiers repertoire-a-parcourir
- Le programme prend en entrée le nom du répertoire contenant les fichiers
- à traiter
- Le programme construit en sortie un fichier structuré contenant sur chaque
- ligne le nom du fichier et le résultat du filtrage :
- <FICHIER><NOM>du fichier</NOM></FICHIER><CONTENU>du filtrage</CONTENU></FICHIER>
- DOC
- #-----------------------------------------------------------
- my $rep="$ARGV[0]";
- # on s'assure que le nom du répertoire ne se termine pas par un "/"
- $rep=~ s/[\/]$//;
- # on initialise une variable contenant le flux de sortie
- my $DUMPFULL1="";
- my $DUMPFULL2="";
- my $cptArticle=0;
- my %dicoDesTitres=();
- my %dicoDesDescriptions=();
- #----------------------------------------
- my $output1="SORTIE.txt";
- if (!open (FILEOUTTXT,">$output1")) { die "Pb a l'ouverture du fichier $output1"};
- my $output2="SORTIE.xml";
- if (!open (FILEOUTXML,">$output2")) { die "Pb a l'ouverture du fichier $output2"};
- #----------------------------------------
- &parcoursarborescencefichiers($rep); #recurse!
- #----------------------------------------
- print FILEOUTXML "<?xml version=\"1.0\" encoding=\"iso-8859-1\" ?>\n";
- print FILEOUTXML "<PARCOURS>\n";
- print FILEOUTXML "<NOM>SF</NOM>\n";
- print FILEOUTXML "<FILTRAGE>".$DUMPFULL1."</FILTRAGE>\n";
- print FILEOUTXML "</PARCOURS>\n";
- close(FILEOUTXML);
- print FILEOUTTXT $DUMPFULL2;
- close(FILEOUTTXT);
- exit;
- #----------------------------------------------
- sub parcoursarborescencefichiers {
- my $path = shift(@_);
- opendir(DIR, $path) or die "can't open $path: $!\n";
- my @files = readdir(DIR);
- closedir(DIR);
- foreach my $file (@files) {
- next if $file =~ /^\.\.?$/;
- $file = $path."/".$file;
- if (-d $file) {
- &parcoursarborescencefichiers($file); #recurse!
- }
- if (-f $file) {
- if ($file=~/\.xml$/) {
- print $i++,"\n";
- open(FILEIN,$file);
- while (my $ligne=<FILEIN>) {
- if ($ligne=~/<\/item>/) {
- $DUMPFULL1.="</article>\n";
- }
- if ($ligne=~/<item>/) {
- $cptArticle++;
- $DUMPFULL1.="<article numero=\"$cptArticle\">\n";
- }
- if ($ligne=~/<description>(.+?)<\/description>/) {
- my $text=$1;
- $text=&nettoieText($text);
- if (!(exists($dicoDesDescriptions{$text}))) {
- $DUMPFULL1.="<description>$text</description>\n";
- $DUMPFULL2.=$text."\n";
- $dicoDesDescriptions{$text}++;
- }
- else {
- $dicoDesDescriptions{$text}++;
- $DUMPFULL1.="<description>-</description>\n";
- }
- }
- if ($ligne=~/<title>(.+?)<\/title>/) {
- my $text=$1;
- $text=&nettoieText($text);
- if (!(exists($dicoDesTitres{$text}))) {
- $DUMPFULL1.="<abstract>$text</abstract>\n";
- $DUMPFULL2.=$text."\n";
- $dicoDesTitres{$text}++;
- }
- else {
- $dicoDesTitres{$text}++;
- $DUMPFULL1.="<abstract>-</abstract>\n";
- }
- }
- }
- close(FILEIN);
- }
- }
- }
- }
- #----------------------------------------------
- sub nettoieText {
- my $texte=shift;
- $texte =~ s/</</g;
- $texte =~ s/>/>/g;
- $texte =~ s/<a href[^>]+>//g;
- $texte =~ s/<img[^>]+>//g;
- $texte =~ s/<\/a>//g;
- $texte =~ s/&#39;/'/g;
- $texte =~ s/&#34;/"/g;
- $texte =~ s/<[^>]+>//g;
- $texte =~ s/é/é/g;
- $texte =~ s/ê/ê/g;
- return $texte;
- }
#/usr/bin/perl
<<DOC;
Votre Nom :
JANVIER 2015
usage : perl parcours-arborescence-fichiers repertoire-a-parcourir
Le programme prend en entrée le nom du répertoire contenant les fichiers
à traiter
Le programme construit en sortie un fichier structuré contenant sur chaque
ligne le nom du fichier et le résultat du filtrage :
<FICHIER><NOM>du fichier</NOM></FICHIER><CONTENU>du filtrage</CONTENU></FICHIER>
DOC
#-----------------------------------------------------------
my $rep="$ARGV[0]";
# on s'assure que le nom du répertoire ne se termine pas par un "/"
$rep=~ s/[\/]$//;
# on initialise une variable contenant le flux de sortie
my $DUMPFULL1="";
my $DUMPFULL2="";
my $cptArticle=0;
my %dicoDesTitres=();
my %dicoDesDescriptions=();
#----------------------------------------
my $output1="SORTIE.txt";
if (!open (FILEOUTTXT,">$output1")) { die "Pb a l'ouverture du fichier $output1"};
my $output2="SORTIE.xml";
if (!open (FILEOUTXML,">$output2")) { die "Pb a l'ouverture du fichier $output2"};
#----------------------------------------
&parcoursarborescencefichiers($rep); #recurse!
#----------------------------------------
print FILEOUTXML "<?xml version=\"1.0\" encoding=\"iso-8859-1\" ?>\n";
print FILEOUTXML "<PARCOURS>\n";
print FILEOUTXML "<NOM>SF</NOM>\n";
print FILEOUTXML "<FILTRAGE>".$DUMPFULL1."</FILTRAGE>\n";
print FILEOUTXML "</PARCOURS>\n";
close(FILEOUTXML);
print FILEOUTTXT $DUMPFULL2;
close(FILEOUTTXT);
exit;
#----------------------------------------------
sub parcoursarborescencefichiers {
my $path = shift(@_);
opendir(DIR, $path) or die "can't open $path: $!\n";
my @files = readdir(DIR);
closedir(DIR);
foreach my $file (@files) {
next if $file =~ /^\.\.?$/;
$file = $path."/".$file;
if (-d $file) {
&parcoursarborescencefichiers($file); #recurse!
}
if (-f $file) {
if ($file=~/\.xml$/) {
print $i++,"\n";
open(FILEIN,$file);
while (my $ligne=<FILEIN>) {
if ($ligne=~/<\/item>/) {
$DUMPFULL1.="</article>\n";
}
if ($ligne=~/<item>/) {
$cptArticle++;
$DUMPFULL1.="<article numero=\"$cptArticle\">\n";
}
if ($ligne=~/<description>(.+?)<\/description>/) {
my $text=$1;
$text=&nettoieText($text);
if (!(exists($dicoDesDescriptions{$text}))) {
$DUMPFULL1.="<description>$text</description>\n";
$DUMPFULL2.=$text."\n";
$dicoDesDescriptions{$text}++;
}
else {
$dicoDesDescriptions{$text}++;
$DUMPFULL1.="<description>-</description>\n";
}
}
if ($ligne=~/<title>(.+?)<\/title>/) {
my $text=$1;
$text=&nettoieText($text);
if (!(exists($dicoDesTitres{$text}))) {
$DUMPFULL1.="<abstract>$text</abstract>\n";
$DUMPFULL2.=$text."\n";
$dicoDesTitres{$text}++;
}
else {
$dicoDesTitres{$text}++;
$DUMPFULL1.="<abstract>-</abstract>\n";
}
}
}
close(FILEIN);
}
}
}
}
#----------------------------------------------
sub nettoieText {
my $texte=shift;
$texte =~ s/</</g;
$texte =~ s/>/>/g;
$texte =~ s/<a href[^>]+>//g;
$texte =~ s/<img[^>]+>//g;
$texte =~ s/<\/a>//g;
$texte =~ s/&#39;/'/g;
$texte =~ s/&#34;/"/g;
$texte =~ s/<[^>]+>//g;
$texte =~ s/é/é/g;
$texte =~ s/ê/ê/g;
return $texte;
}
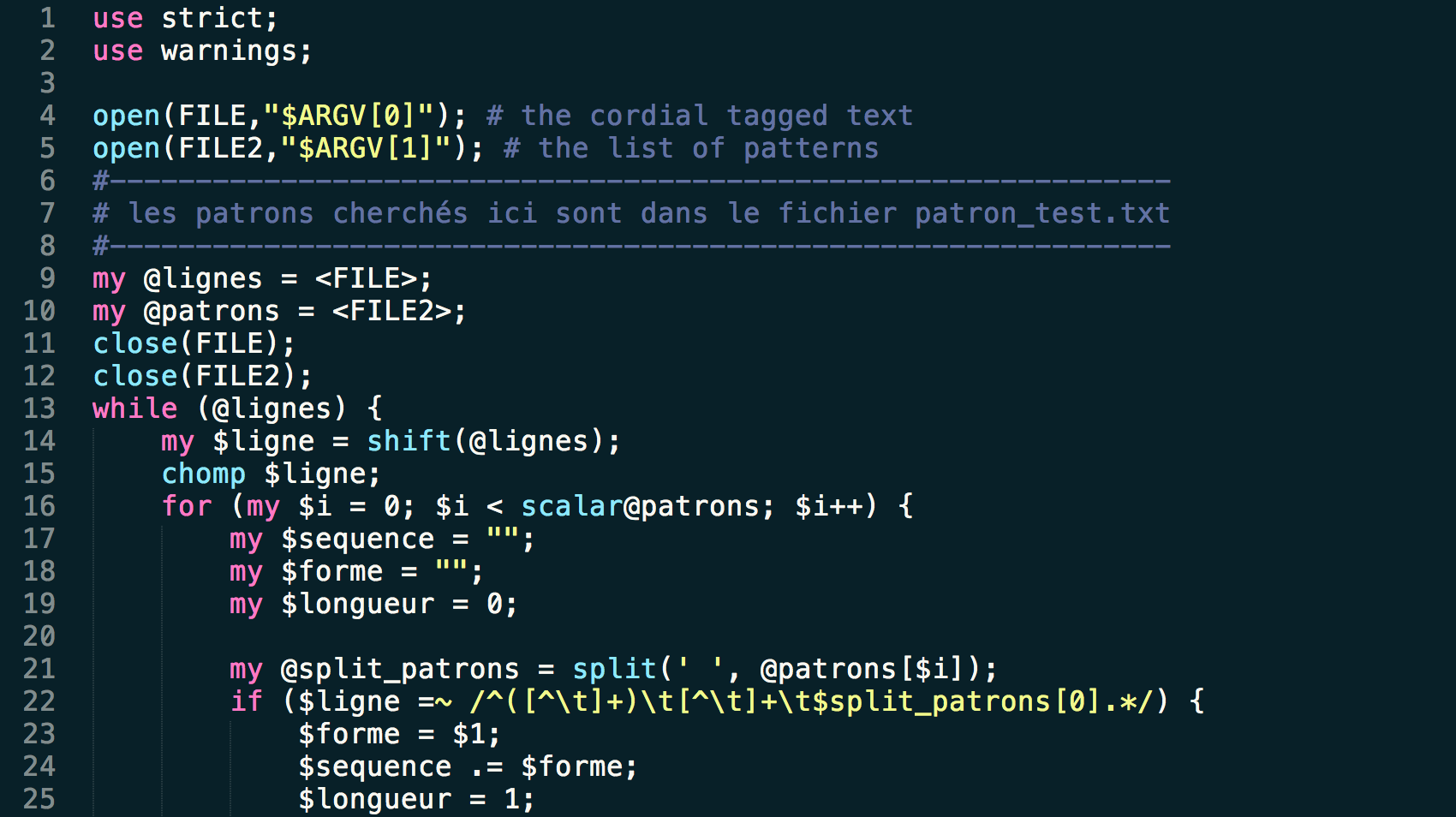
Continuing the contest between "pure Perl" vs. "Perl modules", here we have a second version of the first tool using one of the modules available in Perl. The reason we're making the distinction between these two categories is that the modules are additional pre-written programs in Perl that don't come with the original language and must be downloaded separately. This can be done in a variety of ways. Usually it's easiest to use an installer like cpanminus to take care of the downloading and installation for you but cpan and cpanplus are also options if you want to have more control over the configurations. If you're on Windows, Perl Package Manager is also an option for easy installations.
This script takes the "Perl modules" approach. For this script we downloaded the modules XML::RSS and Unicode::String (case is important!) so we could use them to parse the XML files and convert the text to utf8.  The script checks the encoding (in upper case using uc) in the first line against the string "UTF-8" and if they aren't the same, it uses the Unicode::String module to convert the file to utf-8. The other main difference from the first program is that instead of using the regular expressions to extract the title and description, it uses the features of XML::RSS to do so (lines 25-26). Otherwise, like the first program, it also makes sure to only treat each text one time and cleans the text using a subroutine containing a series of s///g in the nettoietexte() subroutine to substitute the undesired characters for the right ones.
The script checks the encoding (in upper case using uc) in the first line against the string "UTF-8" and if they aren't the same, it uses the Unicode::String module to convert the file to utf-8. The other main difference from the first program is that instead of using the regular expressions to extract the title and description, it uses the features of XML::RSS to do so (lines 25-26). Otherwise, like the first program, it also makes sure to only treat each text one time and cleans the text using a subroutine containing a series of s///g in the nettoietexte() subroutine to substitute the undesired characters for the right ones.
- #!/usr/bin/perl
- use XML::RSS;
- use Unicode::String qw(utf8);
- #----------------------------------------------------------
- my $encodagesortie="utf-8";
- my $encodage=`file -i $ARGV[0] | cut -d= -f2`;
- open(OUT1,">:encoding($encodagesortie)","sortie-textebrut-avec-xmlrss.txt");
- open(OUT2,">:encoding($encodagesortie)","sortie-textexml-avec-xmlrss.xml");
- print OUT2 "<?xml version=\"1.0\" encoding=\"$encodagesortie\" ?>\n";
- print OUT2 "<file>\n";
- print OUT2 "<name>$ARGV[0]</name>\n";
- #-----------------------------------------------------------
- my $file="$ARGV[0]";
- my $rss=new XML::RSS;
- #-----------------------------------------------------------
- eval {$rss->parsefile($file); };
- if( $@ ) {
- $@ =~ s/at \/.*?$//s; # remove module line number
- print STDERR "\nERROR in '$file':\n$@\n";
- } else {
- my $date=$rss->{'channel'}->{'pubDate'};
- print OUT2 "<date>$date</date>\n";
- print OUT2 "<items>\n";
- foreach my $item (@{$rss->{'items'}}) {
- my $titre=$item->{'title'};
- my $resume=$item->{'description'};
- $titre=&nettoietexte($titre);
- $resume=&nettoietexte($resume);
- if (uc($encodage) ne "UTF-8") {utf8($titre);utf8($resume);}
- print OUT1 "Titre : $titre \n";
- print OUT1 "Resume : $resume \n";;
- print OUT2
- "<item><title>$titre</title><abstract>$resume</abstract></item>\n";
- }
- }
- #----------------------------------------------------------
- print OUT2 "</items>\n</file>\n";
- close(OUT1);
- close(OUT2);
- close(FILE);
- exit;
- #----------------------------------------------------------
- #----------------------------------------------------------
- sub nettoietexte {
- my $texte=shift;
- $texte=~s/'/'/g;
- $texte=~s/"/"/g;
- $texte =~ s/</</g;
- $texte =~ s/>/>/g;
- $texte =~ s/<a href[^>]+>//g;
- $texte =~ s/<img[^>]+>//g;
- $texte =~ s/<\/a>//g;
- $texte =~ s/&#39;/'/g;
- $texte =~ s/&#34;/"/g;
- $texte =~ s/<[^>]+>//g;
- return $texte;
- }
#!/usr/bin/perl
use XML::RSS;
use Unicode::String qw(utf8);
#----------------------------------------------------------
my $encodagesortie="utf-8";
my $encodage=`file -i $ARGV[0] | cut -d= -f2`;
open(OUT1,">:encoding($encodagesortie)","sortie-textebrut-avec-xmlrss.txt");
open(OUT2,">:encoding($encodagesortie)","sortie-textexml-avec-xmlrss.xml");
print OUT2 "<?xml version=\"1.0\" encoding=\"$encodagesortie\" ?>\n";
print OUT2 "<file>\n";
print OUT2 "<name>$ARGV[0]</name>\n";
#-----------------------------------------------------------
my $file="$ARGV[0]";
my $rss=new XML::RSS;
#-----------------------------------------------------------
eval {$rss->parsefile($file); };
if( $@ ) {
$@ =~ s/at \/.*?$//s; # remove module line number
print STDERR "\nERROR in '$file':\n$@\n";
} else {
my $date=$rss->{'channel'}->{'pubDate'};
print OUT2 "<date>$date</date>\n";
print OUT2 "<items>\n";
foreach my $item (@{$rss->{'items'}}) {
my $titre=$item->{'title'};
my $resume=$item->{'description'};
$titre=&nettoietexte($titre);
$resume=&nettoietexte($resume);
if (uc($encodage) ne "UTF-8") {utf8($titre);utf8($resume);}
print OUT1 "Titre : $titre \n";
print OUT1 "Resume : $resume \n";;
print OUT2
"<item><title>$titre</title><abstract>$resume</abstract></item>\n";
}
}
#----------------------------------------------------------
print OUT2 "</items>\n</file>\n";
close(OUT1);
close(OUT2);
close(FILE);
exit;
#----------------------------------------------------------
#----------------------------------------------------------
sub nettoietexte {
my $texte=shift;
$texte=~s/'/'/g;
$texte=~s/"/"/g;
$texte =~ s/</</g;
$texte =~ s/>/>/g;
$texte =~ s/<a href[^>]+>//g;
$texte =~ s/<img[^>]+>//g;
$texte =~ s/<\/a>//g;
$texte =~ s/&#39;/'/g;
$texte =~ s/&#34;/"/g;
$texte =~ s/<[^>]+>//g;
return $texte;
}Perl with XPATH
This third version of the script uses a different module: XML::XPath. Using this module creates a script that looks much like the other script using XML::RSS except in this case, the module is using XPATH to parse the XML structure and find the elements contained within the desired tags. 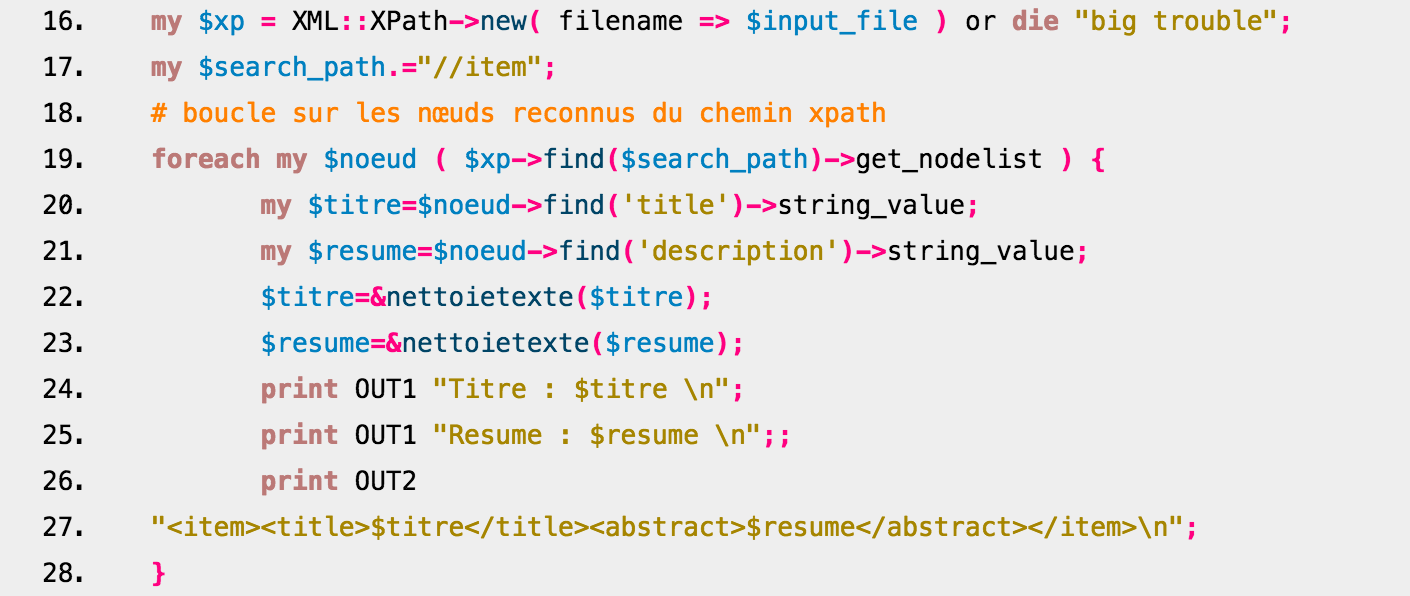 This script also creates two outputs (XML and TXT) and cleans the data using a subroutine to substitute undesired characters for the correct ones.
This script also creates two outputs (XML and TXT) and cleans the data using a subroutine to substitute undesired characters for the correct ones.
- #/usr/bin/perl
- use XML::XPath;
- # On vérifie le nombre d'arguments de l'appel au script ($0 : le nom du script)
- if($#ARGV!=0){
- print "usage : perl $0 fichier_tag fichier_motif";
- exit; }
- #----------------------------------------------------------------------------------
- -----------------------------------------------------------------
- my $encodagesortie="utf-8";
- open(OUT1,">:encoding($encodagesortie)","sortie-textebrut-avec-xmlxpath.txt");
- open(OUT2,">:encoding($encodagesortie)","sortie-textexml-avec-xmlxpath.xml");
- print OUT2 "<?xml version=\"1.0\" encoding=\"$encodagesortie\" ?>\n";
- print OUT2 "<file>\n";
- print OUT2 "<name>$ARGV[0]</name>\n";
- my $input_file= shift @ARGV;
- my $xp = XML::XPath->new( filename => $input_file ) or die "big trouble";
- my $search_path.="//item";
- # boucle sur les nœuds reconnus du chemin xpath
- foreach my $noeud ( $xp->find($search_path)->get_nodelist ) {
- my $titre=$noeud->find('title')->string_value;
- my $resume=$noeud->find('description')->string_value;
- $titre=&nettoietexte($titre);
- $resume=&nettoietexte($resume);
- print OUT1 "Titre : $titre \n";
- print OUT1 "Resume : $resume \n";;
- print OUT2
- "<item><title>$titre</title><abstract>$resume</abstract></item>\n";
- }
- #----------------------------------------------------------
- print OUT2 "</items>\n</file>\n";
- close(OUT1);
- close(OUT2);
- close(FILE);
- exit;
- sub nettoietexte {
- my $texte=shift;
- $texte=~s/'/'/g;
- $texte=~s/"/"/g;
- $texte =~ s/</</g;
- $texte =~ s/>/>/g;
- $texte =~ s/<a href[^>]+>//g;
- $texte =~ s/<img[^>]+>//g;
- $texte =~ s/<\/a>//g;
- $texte =~ s/&#39;/'/g;
- $texte =~ s/&#34;/"/g;
- $texte =~ s/<[^>]+>//g;
- return $texte;
- }
#/usr/bin/perl
use XML::XPath;
# On vérifie le nombre d'arguments de l'appel au script ($0 : le nom du script)
if($#ARGV!=0){
print "usage : perl $0 fichier_tag fichier_motif";
exit; }
#----------------------------------------------------------------------------------
-----------------------------------------------------------------
my $encodagesortie="utf-8";
open(OUT1,">:encoding($encodagesortie)","sortie-textebrut-avec-xmlxpath.txt");
open(OUT2,">:encoding($encodagesortie)","sortie-textexml-avec-xmlxpath.xml");
print OUT2 "<?xml version=\"1.0\" encoding=\"$encodagesortie\" ?>\n";
print OUT2 "<file>\n";
print OUT2 "<name>$ARGV[0]</name>\n";
my $input_file= shift @ARGV;
my $xp = XML::XPath->new( filename => $input_file ) or die "big trouble";
my $search_path.="//item";
# boucle sur les nœuds reconnus du chemin xpath
foreach my $noeud ( $xp->find($search_path)->get_nodelist ) {
my $titre=$noeud->find('title')->string_value;
my $resume=$noeud->find('description')->string_value;
$titre=&nettoietexte($titre);
$resume=&nettoietexte($resume);
print OUT1 "Titre : $titre \n";
print OUT1 "Resume : $resume \n";;
print OUT2
"<item><title>$titre</title><abstract>$resume</abstract></item>\n";
}
#----------------------------------------------------------
print OUT2 "</items>\n</file>\n";
close(OUT1);
close(OUT2);
close(FILE);
exit;
sub nettoietexte {
my $texte=shift;
$texte=~s/'/'/g;
$texte=~s/"/"/g;
$texte =~ s/</</g;
$texte =~ s/>/>/g;
$texte =~ s/<a href[^>]+>//g;
$texte =~ s/<img[^>]+>//g;
$texte =~ s/<\/a>//g;
$texte =~ s/&#39;/'/g;
$texte =~ s/&#34;/"/g;
$texte =~ s/<[^>]+>//g;
return $texte;
}Pure Perl
Our version does the same thing as the class version but in a slightly different way. As you can probably tell, our version is much longer. That's mostly because of the comments we added to the code but also due in part to our longer cleaning function (the nettoietexte()** subroutine). We noticed that there were still certain characters in the output that were not showing up correctly so we added more regular expressions to catch more of the exceptions. 
We also changed one more very important aspect to the code. We no longer have one global output that contains all the different subjects together. We made it so that each subject has its own output files (one XML and one TXT).  Having the data separated like this is especially important for Tool 3. Putting it in the code now simplifies our task later on.
Having the data separated like this is especially important for Tool 3. Putting it in the code now simplifies our task later on.
**You'll also notice that some variable names are different. The ideas are, however, the same.
***The code isn't 100% "pure Perl", we do use one module, Unicode::String, to convert text to utf8.
The code:
- #/usr/bin/perl
- use Unicode::String qw(utf8);
- #lire l'entrée standard
- my $rep="$ARGV[0]";
- # éliminier les possibles "/" à la fin du nom du dossier
- $rep=~ s/[\/]$//;
- # liste pour stocker les items déjà traités
- my %dictionnairedesitems = ();
- # liste pour stocker les rubriques déjà traités
- my %dictionnairesdesrubriques = ();
- # appeler la fonction extraire_rubrique() pour lire les dossiers et extraire les rubriques des fichiers
- &extraire_rubrique($rep);
- my @liste_rubriques = keys(%dictionnairesdesrubriques);
- # pour chaque rubrique, créer un fichier de sortie .xml et un fichier .txt
- foreach my $rub (@liste_rubriques) {
- my $output1= "SORTIE-extract-txt-".$rub.".xml";
- my $output2= "SORTIE-extract-txt-".$rub.".txt";
- # créer fichier .xml de sortie
- open (FILEOUTXML, ">:encoding(utf-8)", $output1) or die "Could not open file @output1!"; # open file for writing
- # créer fichier .txt de sortie
- open (FILEOUTTXT, ">:encoding(utf-8)", $output2) or die "Could not open file $output2!"; # open file for writing)
- # écrier déclaration d'en-tête du fichier xml
- print FILEOUTXML "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
- print FILEOUTXML "<PARCOURS>\n";
- #fermer les deux fichiers
- close(FILEOUTXML);
- close(FILEOUTTXT);
- print $output1;
- }
- # appeler lire_et_ecrire_xml() pour lire tous les fichiers xml et créer les sorties
- &lire_et_ecrire_xml($rep);
- foreach my $rub (@liste_rubriques)
- {
- my $output1="SORTIE-extract-txt-".$rub.".xml";
- if (!open (FILEOUTXML,">>:encoding(utf-8)", $output1))
- {
- die "Pb a l'ouverture du fichier $output1";
- }
- print FILEOUTXML "</PARCOURS>\n";
- close(FILEOUTXML);
- }
- exit;
- #########################################################################################################
- # #
- # cette fonction reçoit un nom de dossier comme argument et lit tous les fichiers .xml du dossier #
- # Pour chaque fichier lu, la fonction extrait les texte des balise <title> et <description>, ainsi que #
- # les dates présente en <pubDate> et <rubrique> #
- # Ce contenu insère dans des fichiers .xml et .txt de sortie de la rubrique correspondante #
- # #
- #########################################################################################################
- sub lire_et_ecrire_xml {
- # lire nom de dossier passé comme argument
- my $path = shift(@_);
- # ouvrir dossier
- opendir(DIR, $path) or die "can't open $path: $!\n";
- # lire itens dans le dossier
- my @files = readdir(DIR);
- closedir(DIR);
- # fermer dossier
- foreach my $file (@files)
- {
- # ignorer les items cachés
- next if $file =~ /^\.\.?$/;
- # construire le chemin complet avec le nom du dossier + item traité
- $file = $path."/".$file;
- # vérifier si l'item traité est dossier
- if (-d $file)
- {
- # si l'item qu'on est en train de traiter est un dossier, on recommence la procédure
- &lire_et_ecrire_xml($file);
- }
- # vérifier si l'item traité un fichier IF1
- if (-f $file)
- {
- # vérifier s'il s'agit d'un fichier .xml qui ne contient pas fil dans le nom iF2
- if (($file=~/\.xml$/) && ($file!~/\/fil.+\.xml$/))
- {
- # ouvrir fichier
- open(FILE, $file);
- # variable pour stocker le contenu du fichier
- my $texte="";
- #lire le contenu du fichier ligne à line
- while (my $ligne=<FILE>)
- {
- chomp $ligne;
- $texte .= $ligne;
- }
- # fermer fichier
- close(FILE);
- # regex pour capturer l'encodage du fichier
- $texte=~/encoding ?= ?[\'\"]([^\'\"]+)[\'\"]/i;
- # stocker l'encogade du fichier
- my $encodage=$1;
- # vérifier si l'encodage n'est pas vide pour traiter le contenu IF3
- if ($encodage ne "")
- {
- # la variable temptexteXML stocke les contenus prêts à être écrits dans fichier .xml de sortie
- my $tmptexteXML="<file>\n";
- # créer balise avec le nom du fichier
- $tmptexteXML.="<name>$file</name>\n";
- # éliminier les balises avec des espaces en blanc
- $texte =~ s/> *</></g;
- # regex pour capturer date
- $texte=~/<pubDate>([^<]+)<\/pubDate>/;
- # stocker la valeur de date capturée par la regex
- $tmptexteXML.="<date>$1</date>\n";
- # insérer la balise <items>
- $tmptexteXML.="<items>\n";
- my $tmptexteBRUT="";
- open(FILE,"<:encoding($encodage)", $file);
- $texte="";
- # lire le fichier ligne à ligne
- while (my $ligne=<FILE>)
- {
- chomp $ligne;
- $texte .= $ligne;
- }
- close(FILE);
- $texte=~s/> *</></g;
- # on recherche la rubrique
- $texte=~/<channel><title>([^<]+)<\/title>/;
- # nettoyer le string rubrique
- my $rub=$1;
- $rub =~ s/Toute l'actualité sur Le Monde.fr.//gi;
- $rub=~s/é/e/gi;
- $rub=~s/è/e/gi;
- $rub=~s/ê/e/gi;
- $rub=~s/à/a/gi;
- $rub=~ s/Le ?Monde.fr ?://;
- $rub=~ s/ //g;
- $rub=uc($rub);
- my $output1="SORTIE-extract-txt-".$rub.".xml";
- my $output2="SORTIE-extract-txt-".$rub.".txt";
- if (!open (FILEOUTXML,">>:encoding(utf-8)", $output1)) { die "Pb a l'ouverture du fichier $output1"};
- if (!open (FILEOUTTXT,">>:encoding(utf-8)", $output2)) { die "Pb a l'ouverture du fichier $output2"};
- # lire texte pour extraire contenu des balises <title> et <description>
- while ($texte =~ /<item><title>(.+?)<\/title>.+?<description>(.+?)<\/description>/g)
- {
- # capturer contenu de la regex pour titre
- my $titre=$1;
- # capturer contenu de la regex pour description
- my $resume=$2;
- #
- $titre = &nettoyer_texte($1);
- $resume = &nettoyer_texte($2);
- # si le fichier n'est pas en UTF-8, convertir le string $titre et $resume en UTF-8
- if (uc($encodage) ne "UTF-8")
- {
- utf8($titre);
- utf8($resume);
- }
- # si le contenu de $resume n'a pas encore été traite, on doit le traiter
- if (!(exists($dictionnairedesitems{$resume})))
- {
- # créer contenu le fichier .txt
- $tmptexteBRUT.="§ $titre \n";
- $tmptexteBRUT.="$resume \n";
- # créer contenu pour fichier .xml
- $tmptexteXML.="<item><title>$titre</title><abstract>$resume</abstract></item>\n";
- # inclure contenu de $resume dans liste
- $dictionnairedesitems{$resume}++;
- } else {
- $tmptexteXML.="<item><title>-</title><abstract>-</abstract></item>\n";
- }
- } # fin while
- # rajouter la fin des balise <items> et <file>
- $tmptexteXML.="</items>\n</file>\n";
- # écrire contenu dans le fichier .xml
- print FILEOUTXML $tmptexteXML;
- # écrire contenu dans le fichier .txt
- print FILEOUTTXT $tmptexteBRUT;
- # fermer fichiers
- close FILEOUTXML;
- close FILEOUTTXT;
- } else {
- #si l'encaodre est vide afficher message
- print "$file ==> $encodage \n";
- } # fin IF3
- } # fin IF 2
- } # fin IF 1
- } # fin FOR
- } # fin lire_et_ecrire_xml()
- sub nettoyer_texte {
- my $texte=shift;
- $texte =~ s/</</g;
- $texte =~ s/>/>/g;
- $texte =~ s/<a href[^>]+>//g;
- $texte =~ s/<img[^>]+>//g;
- $texte =~ s/<\/a>//g;
- $texte =~ s/&#39;/'/g;
- $texte =~ s/&#34;/"/g;
- $texte =~ s/é/é/g;
- $texte =~ s/ê/ê/g;
- $texte =~ s/<[^>]+>//g;
- $texte =~ s/ / /g;
- $texte=~s/'/'/g;
- $texte=~s/"/"/g;
- $texte=~s/&#39;/'/g;
- $texte=~s/&#34;/"/g;
- return $texte;
- }
- ####################################################################################################
- # #
- # cette fonction reçoit un nom de dossier comme argument et lit tous les fichiers .xml du dossier #
- # Pour chaque fichier lu, la fonction extrait les rubriques et crée des fichiers de sortie #
- # possédant le nom de la rubrique #
- # #
- ####################################################################################################
- sub extraire_rubrique {
- #lire le nom dossier passé comme argument
- my $path = shift(@_);
- #ouvrir le dossier
- opendir(DIR, $path) or die "can't open $path: $!\n";
- #lire la liste de fichier du dossier
- my @files = readdir(DIR);
- closedir(DIR);
- # lire un à un les items du dossier
- foreach my $file (@files)
- {
- # ignorer les items cachés
- next if $file =~ /^\.\.?$/;
- # construire le chemin complet avec le nom du dossier + item traité
- $file = $path."/".$file;
- # vérifier si l'item est un dossier
- if (-d $file)
- {
- # si l'item qu'on est en train de traiter est un dossier, on recommence la procédure
- &extraire_rubrique($file);
- }
- # vérifier si l'item est un fichier - IF1
- if (-f $file)
- {
- # tester si fichier possède l'extension .xml et ne contient pas la substring fil dans le nom - IF2
- if (($file =~ /\.xml$/) && ($file!~/\/fil.+\.xml$/))
- {
- #ouvrir fichier .xml
- open(FILE,$file);
- #variable pour stocker le contenu du fichier .xml
- my $texte="";
- #lire toutes les lignes du fichier .xml
- while (my $ligne=<FILE>)
- {
- # effacer les retours à la ligne
- chomp $ligne;
- # stocker le contenu de ligne lue
- $texte .= $ligne;
- }
- # fermer le fichier .xml
- close(FILE);
- # regex pour capture l`encodage du fichier
- $texte =~ /encoding ?= ?[\'\"]([^\'\"]+)[\'\"]/i;
- # stocker le contenu trouvé par la regex
- my $encodage=$1;
- # vérifier la contenu de regex n'est pas vide IF3
- if ($encodage ne "")
- {
- # reouvrir le fichier avec l'encogade correcte
- open(FILE,"<:encoding($encodage)", $file);
- # variables pour stocker le contenu du fichier lu
- $texte="";
- # lire le fichier .xml
- while (my $ligne=<FILE>)
- {
- # effacer les retours à la ligne
- chomp $ligne;
- # stocker le contenu de ligne lue
- $texte .= $ligne;
- }
- # fermer le fichier .xml
- close(FILE);
- # effacer les espaces en blanc
- $texte =~ s/> *</></g;
- # capturer le contenu à l'intérieur des balises <title> - IF4
- if ($texte=~ /<channel><title>([^>]+)<\/title>/)
- {
- print $texte;
- # stocker la valeur de rubrique trouvée par la regex
- my $rub=$1;
- # nettoyer les noms des rubriques
- $rub =~ s/Toute l'actualité sur Le Monde.fr.//gi;
- $rub=~s/é/e/gi;
- $rub=~s/è/e/gi;
- $rub=~s/ê/e/gi;
- $rub=~s/à/a/gi;
- $rub=~ s/Le ?Monde.fr ?://i;
- $rub=~ s/ //g;
- $rub=uc($rub);
- # stocker la rubrique dans le dictionnaire des rubriques
- $dictionnairesdesrubriques{$rub}++;
- } # fin IF4
- } # fin IF3
- } # fin IF2
- } # fin IF1
- } # fin FOR
- } # fin extraire_rubrique()
#/usr/bin/perl
use Unicode::String qw(utf8);
#lire l'entrée standard
my $rep="$ARGV[0]";
# éliminier les possibles "/" à la fin du nom du dossier
$rep=~ s/[\/]$//;
# liste pour stocker les items déjà traités
my %dictionnairedesitems = ();
# liste pour stocker les rubriques déjà traités
my %dictionnairesdesrubriques = ();
# appeler la fonction extraire_rubrique() pour lire les dossiers et extraire les rubriques des fichiers
&extraire_rubrique($rep);
my @liste_rubriques = keys(%dictionnairesdesrubriques);
# pour chaque rubrique, créer un fichier de sortie .xml et un fichier .txt
foreach my $rub (@liste_rubriques) {
my $output1= "SORTIE-extract-txt-".$rub.".xml";
my $output2= "SORTIE-extract-txt-".$rub.".txt";
# créer fichier .xml de sortie
open (FILEOUTXML, ">:encoding(utf-8)", $output1) or die "Could not open file @output1!"; # open file for writing
# créer fichier .txt de sortie
open (FILEOUTTXT, ">:encoding(utf-8)", $output2) or die "Could not open file $output2!"; # open file for writing)
# écrier déclaration d'en-tête du fichier xml
print FILEOUTXML "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print FILEOUTXML "<PARCOURS>\n";
#fermer les deux fichiers
close(FILEOUTXML);
close(FILEOUTTXT);
print $output1;
}
# appeler lire_et_ecrire_xml() pour lire tous les fichiers xml et créer les sorties
&lire_et_ecrire_xml($rep);
foreach my $rub (@liste_rubriques)
{
my $output1="SORTIE-extract-txt-".$rub.".xml";
if (!open (FILEOUTXML,">>:encoding(utf-8)", $output1))
{
die "Pb a l'ouverture du fichier $output1";
}
print FILEOUTXML "</PARCOURS>\n";
close(FILEOUTXML);
}
exit;
#########################################################################################################
# #
# cette fonction reçoit un nom de dossier comme argument et lit tous les fichiers .xml du dossier #
# Pour chaque fichier lu, la fonction extrait les texte des balise <title> et <description>, ainsi que #
# les dates présente en <pubDate> et <rubrique> #
# Ce contenu insère dans des fichiers .xml et .txt de sortie de la rubrique correspondante #
# #
#########################################################################################################
sub lire_et_ecrire_xml {
# lire nom de dossier passé comme argument
my $path = shift(@_);
# ouvrir dossier
opendir(DIR, $path) or die "can't open $path: $!\n";
# lire itens dans le dossier
my @files = readdir(DIR);
closedir(DIR);
# fermer dossier
foreach my $file (@files)
{
# ignorer les items cachés
next if $file =~ /^\.\.?$/;
# construire le chemin complet avec le nom du dossier + item traité
$file = $path."/".$file;
# vérifier si l'item traité est dossier
if (-d $file)
{
# si l'item qu'on est en train de traiter est un dossier, on recommence la procédure
&lire_et_ecrire_xml($file);
}
# vérifier si l'item traité un fichier IF1
if (-f $file)
{
# vérifier s'il s'agit d'un fichier .xml qui ne contient pas fil dans le nom iF2
if (($file=~/\.xml$/) && ($file!~/\/fil.+\.xml$/))
{
# ouvrir fichier
open(FILE, $file);
# variable pour stocker le contenu du fichier
my $texte="";
#lire le contenu du fichier ligne à line
while (my $ligne=<FILE>)
{
chomp $ligne;
$texte .= $ligne;
}
# fermer fichier
close(FILE);
# regex pour capturer l'encodage du fichier
$texte=~/encoding ?= ?[\'\"]([^\'\"]+)[\'\"]/i;
# stocker l'encogade du fichier
my $encodage=$1;
# vérifier si l'encodage n'est pas vide pour traiter le contenu IF3
if ($encodage ne "")
{
# la variable temptexteXML stocke les contenus prêts à être écrits dans fichier .xml de sortie
my $tmptexteXML="<file>\n";
# créer balise avec le nom du fichier
$tmptexteXML.="<name>$file</name>\n";
# éliminier les balises avec des espaces en blanc
$texte =~ s/> *</></g;
# regex pour capturer date
$texte=~/<pubDate>([^<]+)<\/pubDate>/;
# stocker la valeur de date capturée par la regex
$tmptexteXML.="<date>$1</date>\n";
# insérer la balise <items>
$tmptexteXML.="<items>\n";
my $tmptexteBRUT="";
open(FILE,"<:encoding($encodage)", $file);
$texte="";
# lire le fichier ligne à ligne
while (my $ligne=<FILE>)
{
chomp $ligne;
$texte .= $ligne;
}
close(FILE);
$texte=~s/> *</></g;
# on recherche la rubrique
$texte=~/<channel><title>([^<]+)<\/title>/;
# nettoyer le string rubrique
my $rub=$1;
$rub =~ s/Toute l'actualité sur Le Monde.fr.//gi;
$rub=~s/é/e/gi;
$rub=~s/è/e/gi;
$rub=~s/ê/e/gi;
$rub=~s/à/a/gi;
$rub=~ s/Le ?Monde.fr ?://;
$rub=~ s/ //g;
$rub=uc($rub);
my $output1="SORTIE-extract-txt-".$rub.".xml";
my $output2="SORTIE-extract-txt-".$rub.".txt";
if (!open (FILEOUTXML,">>:encoding(utf-8)", $output1)) { die "Pb a l'ouverture du fichier $output1"};
if (!open (FILEOUTTXT,">>:encoding(utf-8)", $output2)) { die "Pb a l'ouverture du fichier $output2"};
# lire texte pour extraire contenu des balises <title> et <description>
while ($texte =~ /<item><title>(.+?)<\/title>.+?<description>(.+?)<\/description>/g)
{
# capturer contenu de la regex pour titre
my $titre=$1;
# capturer contenu de la regex pour description
my $resume=$2;
#
$titre = &nettoyer_texte($1);
$resume = &nettoyer_texte($2);
# si le fichier n'est pas en UTF-8, convertir le string $titre et $resume en UTF-8
if (uc($encodage) ne "UTF-8")
{
utf8($titre);
utf8($resume);
}
# si le contenu de $resume n'a pas encore été traite, on doit le traiter
if (!(exists($dictionnairedesitems{$resume})))
{
# créer contenu le fichier .txt
$tmptexteBRUT.="§ $titre \n";
$tmptexteBRUT.="$resume \n";
# créer contenu pour fichier .xml
$tmptexteXML.="<item><title>$titre</title><abstract>$resume</abstract></item>\n";
# inclure contenu de $resume dans liste
$dictionnairedesitems{$resume}++;
} else {
$tmptexteXML.="<item><title>-</title><abstract>-</abstract></item>\n";
}
} # fin while
# rajouter la fin des balise <items> et <file>
$tmptexteXML.="</items>\n</file>\n";
# écrire contenu dans le fichier .xml
print FILEOUTXML $tmptexteXML;
# écrire contenu dans le fichier .txt
print FILEOUTTXT $tmptexteBRUT;
# fermer fichiers
close FILEOUTXML;
close FILEOUTTXT;
} else {
#si l'encaodre est vide afficher message
print "$file ==> $encodage \n";
} # fin IF3
} # fin IF 2
} # fin IF 1
} # fin FOR
} # fin lire_et_ecrire_xml()
sub nettoyer_texte {
my $texte=shift;
$texte =~ s/</</g;
$texte =~ s/>/>/g;
$texte =~ s/<a href[^>]+>//g;
$texte =~ s/<img[^>]+>//g;
$texte =~ s/<\/a>//g;
$texte =~ s/&#39;/'/g;
$texte =~ s/&#34;/"/g;
$texte =~ s/é/é/g;
$texte =~ s/ê/ê/g;
$texte =~ s/<[^>]+>//g;
$texte =~ s/ / /g;
$texte=~s/'/'/g;
$texte=~s/"/"/g;
$texte=~s/&#39;/'/g;
$texte=~s/&#34;/"/g;
return $texte;
}
####################################################################################################
# #
# cette fonction reçoit un nom de dossier comme argument et lit tous les fichiers .xml du dossier #
# Pour chaque fichier lu, la fonction extrait les rubriques et crée des fichiers de sortie #
# possédant le nom de la rubrique #
# #
####################################################################################################
sub extraire_rubrique {
#lire le nom dossier passé comme argument
my $path = shift(@_);
#ouvrir le dossier
opendir(DIR, $path) or die "can't open $path: $!\n";
#lire la liste de fichier du dossier
my @files = readdir(DIR);
closedir(DIR);
# lire un à un les items du dossier
foreach my $file (@files)
{
# ignorer les items cachés
next if $file =~ /^\.\.?$/;
# construire le chemin complet avec le nom du dossier + item traité
$file = $path."/".$file;
# vérifier si l'item est un dossier
if (-d $file)
{
# si l'item qu'on est en train de traiter est un dossier, on recommence la procédure
&extraire_rubrique($file);
}
# vérifier si l'item est un fichier - IF1
if (-f $file)
{
# tester si fichier possède l'extension .xml et ne contient pas la substring fil dans le nom - IF2
if (($file =~ /\.xml$/) && ($file!~/\/fil.+\.xml$/))
{
#ouvrir fichier .xml
open(FILE,$file);
#variable pour stocker le contenu du fichier .xml
my $texte="";
#lire toutes les lignes du fichier .xml
while (my $ligne=<FILE>)
{
# effacer les retours à la ligne
chomp $ligne;
# stocker le contenu de ligne lue
$texte .= $ligne;
}
# fermer le fichier .xml
close(FILE);
# regex pour capture l`encodage du fichier
$texte =~ /encoding ?= ?[\'\"]([^\'\"]+)[\'\"]/i;
# stocker le contenu trouvé par la regex
my $encodage=$1;
# vérifier la contenu de regex n'est pas vide IF3
if ($encodage ne "")
{
# reouvrir le fichier avec l'encogade correcte
open(FILE,"<:encoding($encodage)", $file);
# variables pour stocker le contenu du fichier lu
$texte="";
# lire le fichier .xml
while (my $ligne=<FILE>)
{
# effacer les retours à la ligne
chomp $ligne;
# stocker le contenu de ligne lue
$texte .= $ligne;
}
# fermer le fichier .xml
close(FILE);
# effacer les espaces en blanc
$texte =~ s/> *</></g;
# capturer le contenu à l'intérieur des balises <title> - IF4
if ($texte=~ /<channel><title>([^>]+)<\/title>/)
{
print $texte;
# stocker la valeur de rubrique trouvée par la regex
my $rub=$1;
# nettoyer les noms des rubriques
$rub =~ s/Toute l'actualité sur Le Monde.fr.//gi;
$rub=~s/é/e/gi;
$rub=~s/è/e/gi;
$rub=~s/ê/e/gi;
$rub=~s/à/a/gi;
$rub=~ s/Le ?Monde.fr ?://i;
$rub=~ s/ //g;
$rub=uc($rub);
# stocker la rubrique dans le dictionnaire des rubriques
$dictionnairesdesrubriques{$rub}++;
} # fin IF4
} # fin IF3
} # fin IF2
} # fin IF1
} # fin FOR
} # fin extraire_rubrique()
Perl Modules
This is our version using Perl modules. In this version we add to Unicode::String with XML::Entities, HTML::Entities, and XML::RSS. Unicode::String was added to take care of encoding conversions. The other two serve to replace XML and HTML entities withing the text. These entities are special characters that are used in the formatting of the files (for example: "<" and ">") and so must be escaped when we want to represent those literal characters in our files.

Modules in action:

For Tool 1, we came to the realization that there were image tags within the description tags and that they weren't normally formed tags. This posed a problem in that these image tags were extracted along with our other desired information. We solved this issue by decoding the entities in the description tags before going on to clean the XML file.
- #/usr/bin/perl
- use Unicode::String qw(utf8);
- use XML::Entities;
- use HTML::Entities;
- use XML::RSS;
- #lire l'entrée standard
- my $rep="$ARGV[0]";
- # éliminier les possibles "/" à la fin du nom du dossier
- $rep=~ s/[\/]$//;
- # liste pour stocker les items déjà traités
- my %dictionnairedesitems = ();
- # liste pour stocker les rubriques déjà traités
- my %dictionnairesdesrubriques = ();
- # appeler la fonction extraire_rubrique() pour lire les dossiers et extraire les rubriques des fichiers
- &extraire_rubrique($rep);
- my @liste_rubriques = keys(%dictionnairesdesrubriques);
- # pour chaque rubrique, créer un fichier de sortie .xml et un fichier .txt
- foreach my $rub (@liste_rubriques) {
- my $output1= "SORTIE-extract-txt-".$rub.".xml";
- my $output2= "SORTIE-extract-txt-".$rub.".txt";
- # créer fichier .xml de sortie
- open (FILEOUTXML, ">:encoding(utf-8)", $output1) or die "Could not open file @output1!"; # open file for writing
- # créer fichier .txt de sortie
- open (FILEOUTTXT, ">:encoding(utf-8)", $output2) or die "Could not open file $output2!"; # open file for writing)
- # écrier déclaration d'en-tête du fichier xml
- print FILEOUTXML "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
- print FILEOUTXML "<PARCOURS>\n";
- #fermer les deux fichiers
- close(FILEOUTXML);
- close(FILEOUTTXT);
- print $output1;
- }
- # appeler lire_et_ecrire_xml() pour lire tous les fichiers xml et créer les sorties
- &lire_et_ecrire_xml($rep);
- foreach my $rub (@liste_rubriques)
- {
- my $output1="SORTIE-extract-txt-".$rub.".xml";
- if (!open (FILEOUTXML,">>:encoding(utf-8)", $output1))
- {
- die "Pb a l'ouverture du fichier $output1";
- }
- print FILEOUTXML "</PARCOURS>\n";
- close(FILEOUTXML);
- }
- exit;
- #########################################################################################################
- # #
- # cette fonction reçoit un nom de dossier comme argument et lit tous les fichiers .xml du dossier #
- # Pour chaque fichier lu, la fonction extrait le texte des balises <title> et <description>, ainsi que #
- # les dates présentes entre <pubDate> et <rubrique> #
- # Ce contenu insère dans des fichiers de sortie .xml et .txt la rubrique correspondante #
- # #
- #########################################################################################################
- sub lire_et_ecrire_xml {
- # lire nom de dossier passé comme argument
- my $path = shift(@_);
- # ouvrir dossier
- opendir(DIR, $path) or die "can't open $path: $!\n";
- # lire items dans le dossier
- my @files = readdir(DIR);
- closedir(DIR);
- # fermer dossier
- foreach my $file (@files)
- {
- # ignorer les items cachés
- next if $file =~ /^\.\.?$/;
- # construire le chemin complet avec le nom du dossier + item traité
- $file = $path."/".$file;
- # vérifier si l'item traité est un dossier
- if (-d $file)
- {
- # si l'item qu'on est en train de traiter est un dossier, on recommence la procédure
- &lire_et_ecrire_xml($file);
- }
- # vérifier si l'item traité un fichier IF1
- if (-f $file)
- {
- # vérifier s'il s'agit d'un fichier .xml qui ne contient pas fil dans le nom iF2
- if (($file=~/\.xml$/) && ($file!~/\/fil.+\.xml$/))
- {
- # ouvrir fichier
- open(FILE, $file);
- # variable pour stocker le contenu du fichier
- my $texte="";
- #lire le contenu du fichier ligne à line
- while (my $ligne=<FILE>)
- {
- chomp $ligne;
- $texte .= $ligne;
- }
- # fermer fichier
- close(FILE);
- # regex pour capturer l'encodage du fichier
- $texte=~/encoding ?= ?[\'\"]([^\'\"]+)[\'\"]/i;
- # stocker l'encodage du fichier
- my $encodage=$1;
- # vérifier si l'encodage n'est pas vide pour traiter le contenu IF3
- if ($encodage ne "")
- {
- # la variable tmptexteXML stocke les contenus prêts à être écrits dans fichier .xml de sortie
- my $tmptexteXML="<file>\n";
- # créer balise avec le nom du fichier
- $tmptexteXML.="<name>$file</name>\n";
- # éliminier les balises avec des espaces en blanc
- $texte =~ s/> *</></g;
- # regex pour capturer date
- $texte=~/<pubDate>([^<]+)<\/pubDate>/;
- # stocker la valeur de date capturée par la regex
- $tmptexteXML.="<date>$1</date>\n";
- # insérer la balise <items>
- $tmptexteXML.="<items>\n";
- my $tmptexteBRUT="";
- open(FILE,"<:encoding($encodage)", $file);
- $texte="";
- # lire le fichier ligne à ligne
- while (my $ligne=<FILE>)
- {
- chomp $ligne;
- $texte .= $ligne;
- }
- close(FILE);
- $texte=~s/> *</></g;
- # on recherche la rubrique
- $texte=~/<channel><title>([^<]+)<\/title>/;
- # on met le contenu trouvé par la regex dans $rub
- my $rub=$1;
- # nettoyer le string rubrique
- $rub =~ s/Toute l'actualité sur Le Monde.fr.//gi;
- $rub =~ s/é/e/gi;
- $rub =~ s/è/e/gi;
- $rub =~ s/ê/e/gi;
- $rub =~ s/à/a/gi;
- $rub =~ s/Le ?Monde.fr ?://;
- $rub =~ s/ //g;
- $rub=uc($rub);
- my $output1="SORTIE-extract-txt-".$rub.".xml";
- my $output2="SORTIE-extract-txt-".$rub.".txt";
- if (!open (FILEOUTXML,">>:encoding(utf-8)", $output1)) { die "Pb a l'ouverture du fichier $output1"};
- if (!open (FILEOUTTXT,">>:encoding(utf-8)", $output2)) { die "Pb a l'ouverture du fichier $output2"};
- # lire texte pour extraire contenu des balises <title> et <description>
- while ($texte =~ /<item><title>(.+?)<\/title>.+?<description>(.+?)<\/description>/g)
- {
- # capturer contenu de la regex pour titre
- my $titre=$1;
- # capturer contenu de la regex pour description
- my $resume=$2;
- # utilisation des modules pour remplacer dans les fichiers les entités XML et HTML
- if (!(exists ($dictionnairedesitems{$titre})) and !(exists ($dictionnairedesitems{$resume})))
- {
- $dictionnairedesitems{$titre}++;
- $dictionnairedesitems{$resume}++;
- $titre = XML::Entities::decode('all', $titre);
- $resume = XML::Entities::decode('all', $resume);
- $titre = HTML::Entities::decode($titre);
- $resume = HTML::Entities::decode($resume);
- $tmptexteBRUT.="$titre \n";
- $tmptexteBRUT.="$resume \n";
- $tmptexteXML.="<item><title>$titre</title><description>$resume</description></item>\n";
- # nettoyage des balises <description> pour supprimer les balises superflues
- $tmptexteXML =~ s/<img.*?\/><\/description>/<\/description>/g;
- $tmptexteBRUT =~ s/<img.*?\/> \n/\n/g;
- }
- # si le fichier n'est pas en UTF-8, convertir le string $titre et $resume en UTF-8
- if (uc($encodage) ne "UTF-8")
- {
- utf8($titre);
- utf8($resume);
- }
- } # fin while
- # rajouter la fin des balises <items> et <file>
- $tmptexteXML.="</items>\n</file>\n";
- # écrire contenu dans le fichier .xml
- print FILEOUTXML $tmptexteXML;
- # écrire contenu dans le fichier .txt
- print FILEOUTTXT $tmptexteBRUT;
- # fermer fichiers
- close FILEOUTXML;
- close FILEOUTTXT;
- } else {
- #si l'encodage est vide afficher message
- print "$file ==> $encodage \n";
- } # fin IF3
- } # fin IF 2
- } # fin IF 1
- } # fin FOR
- } # fin lire_et_ecrire_xml()
- ####################################################################################################
- # #
- # cette fonction reçoit un nom de dossier comme argument et lit tous les fichiers .xml du dossier #
- # Pour chaque fichier lu, la fonction extrait les rubriques et crée des fichiers de sortie #
- # possédant le nom de la rubrique #
- # #
- ####################################################################################################
- sub extraire_rubrique {
- #lire le nom dossier passé comme argument
- my $path = shift(@_);
- #ouvrir le dossier
- opendir(DIR, $path) or die "can't open $path: $!\n";
- #lire la liste de fichier du dossier
- my @files = readdir(DIR);
- closedir(DIR);
- # lire un à un les items du dossier
- foreach my $file (@files)
- {
- # ignorer les items cachés
- next if $file =~ /^\.\.?$/;
- # construire le chemin complet avec le nom du dossier + item traité
- $file = $path."/".$file;
- # vérifier si l'item est un dossier
- if (-d $file)
- {
- # si l'item qu'on est en train de traiter est un dossier, on recommence la procédure
- &extraire_rubrique($file);
- }
- # vérifier si l'item est un fichier - IF1
- if (-f $file)
- {
- # tester si fichier possède l'extension .xml et ne contient pas la substring fil dans le nom - IF2
- if (($file =~ /\.xml$/) && ($file!~/\/fil.+\.xml$/))
- {
- #ouvrir fichier .xml
- open(FILE,$file);
- #variable pour stocker le contenu du fichier .xml
- my $texte="";
- #lire toutes les lignes du fichier .xml
- while (my $ligne=<FILE>)
- {
- # effacer les retours à la ligne
- chomp $ligne;
- # stocker le contenu de ligne lue
- $texte .= $ligne;
- }
- # fermer le fichier .xml
- close(FILE);
- # regex pour capture l`encodage du fichier
- $texte =~ /encoding ?= ?[\'\"]([^\'\"]+)[\'\"]/i;
- # stocker le contenu trouvé par la regex
- my $encodage=$1;
- # vérifier la contenu de regex n'est pas vide IF3
- if ($encodage ne "")
- {
- # reouvrir le fichier avec l'encogade correcte
- open(FILE,"<:encoding($encodage)", $file);
- # variables pour stocker le contenu du fichier lu
- $texte="";
- # lire le fichier .xml
- while (my $ligne=<FILE>)
- {
- # effacer les retours à la ligne
- chomp $ligne;
- # stocker le contenu de ligne lue
- $texte .= $ligne;
- }
- # fermer le fichier .xml
- close(FILE);
- # effacer les espaces en blanc
- $texte =~ s/> *</></g;
- # capturer le contenu à l'intérieur des balises <title> - IF4
- if ($texte=~ /<channel><title>([^>]+)<\/title>/)
- {
- print $texte;
- # stocker la valeur de rubrique trouvée par la regex
- my $rub=$1;
- # nettoyer les noms des rubriques
- $rub =~ s/Toute l'actualité sur Le Monde.fr.//gi;
- $rub =~ s/é/e/gi;
- $rub =~ s/è/e/gi;
- $rub =~ s/ê/e/gi;
- $rub =~ s/à/a/gi;
- $rub =~ s/Le ?Monde.fr ?://;
- $rub =~ s/ //g;
- $rub=uc($rub);
- # stocker la rubrique dans le dictionnaire des rubriques
- $dictionnairesdesrubriques{$rub}++;
- } # fin IF4
- } # fin IF3
- } # fin IF2
- } # fin IF1
- } # fin FOR
- } # fin extraire_rubrique()
#/usr/bin/perl
use Unicode::String qw(utf8);
use XML::Entities;
use HTML::Entities;
use XML::RSS;
#lire l'entrée standard
my $rep="$ARGV[0]";
# éliminier les possibles "/" à la fin du nom du dossier
$rep=~ s/[\/]$//;
# liste pour stocker les items déjà traités
my %dictionnairedesitems = ();
# liste pour stocker les rubriques déjà traités
my %dictionnairesdesrubriques = ();
# appeler la fonction extraire_rubrique() pour lire les dossiers et extraire les rubriques des fichiers
&extraire_rubrique($rep);
my @liste_rubriques = keys(%dictionnairesdesrubriques);
# pour chaque rubrique, créer un fichier de sortie .xml et un fichier .txt
foreach my $rub (@liste_rubriques) {
my $output1= "SORTIE-extract-txt-".$rub.".xml";
my $output2= "SORTIE-extract-txt-".$rub.".txt";
# créer fichier .xml de sortie
open (FILEOUTXML, ">:encoding(utf-8)", $output1) or die "Could not open file @output1!"; # open file for writing
# créer fichier .txt de sortie
open (FILEOUTTXT, ">:encoding(utf-8)", $output2) or die "Could not open file $output2!"; # open file for writing)
# écrier déclaration d'en-tête du fichier xml
print FILEOUTXML "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print FILEOUTXML "<PARCOURS>\n";
#fermer les deux fichiers
close(FILEOUTXML);
close(FILEOUTTXT);
print $output1;
}
# appeler lire_et_ecrire_xml() pour lire tous les fichiers xml et créer les sorties
&lire_et_ecrire_xml($rep);
foreach my $rub (@liste_rubriques)
{
my $output1="SORTIE-extract-txt-".$rub.".xml";
if (!open (FILEOUTXML,">>:encoding(utf-8)", $output1))
{
die "Pb a l'ouverture du fichier $output1";
}
print FILEOUTXML "</PARCOURS>\n";
close(FILEOUTXML);
}
exit;
#########################################################################################################
# #
# cette fonction reçoit un nom de dossier comme argument et lit tous les fichiers .xml du dossier #
# Pour chaque fichier lu, la fonction extrait le texte des balises <title> et <description>, ainsi que #
# les dates présentes entre <pubDate> et <rubrique> #
# Ce contenu insère dans des fichiers de sortie .xml et .txt la rubrique correspondante #
# #
#########################################################################################################
sub lire_et_ecrire_xml {
# lire nom de dossier passé comme argument
my $path = shift(@_);
# ouvrir dossier
opendir(DIR, $path) or die "can't open $path: $!\n";
# lire items dans le dossier
my @files = readdir(DIR);
closedir(DIR);
# fermer dossier
foreach my $file (@files)
{
# ignorer les items cachés
next if $file =~ /^\.\.?$/;
# construire le chemin complet avec le nom du dossier + item traité
$file = $path."/".$file;
# vérifier si l'item traité est un dossier
if (-d $file)
{
# si l'item qu'on est en train de traiter est un dossier, on recommence la procédure
&lire_et_ecrire_xml($file);
}
# vérifier si l'item traité un fichier IF1
if (-f $file)
{
# vérifier s'il s'agit d'un fichier .xml qui ne contient pas fil dans le nom iF2
if (($file=~/\.xml$/) && ($file!~/\/fil.+\.xml$/))
{
# ouvrir fichier
open(FILE, $file);
# variable pour stocker le contenu du fichier
my $texte="";
#lire le contenu du fichier ligne à line
while (my $ligne=<FILE>)
{
chomp $ligne;
$texte .= $ligne;
}
# fermer fichier
close(FILE);
# regex pour capturer l'encodage du fichier
$texte=~/encoding ?= ?[\'\"]([^\'\"]+)[\'\"]/i;
# stocker l'encodage du fichier
my $encodage=$1;
# vérifier si l'encodage n'est pas vide pour traiter le contenu IF3
if ($encodage ne "")
{
# la variable tmptexteXML stocke les contenus prêts à être écrits dans fichier .xml de sortie
my $tmptexteXML="<file>\n";
# créer balise avec le nom du fichier
$tmptexteXML.="<name>$file</name>\n";
# éliminier les balises avec des espaces en blanc
$texte =~ s/> *</></g;
# regex pour capturer date
$texte=~/<pubDate>([^<]+)<\/pubDate>/;
# stocker la valeur de date capturée par la regex
$tmptexteXML.="<date>$1</date>\n";
# insérer la balise <items>
$tmptexteXML.="<items>\n";
my $tmptexteBRUT="";
open(FILE,"<:encoding($encodage)", $file);
$texte="";
# lire le fichier ligne à ligne
while (my $ligne=<FILE>)
{
chomp $ligne;
$texte .= $ligne;
}
close(FILE);
$texte=~s/> *</></g;
# on recherche la rubrique
$texte=~/<channel><title>([^<]+)<\/title>/;
# on met le contenu trouvé par la regex dans $rub
my $rub=$1;
# nettoyer le string rubrique
$rub =~ s/Toute l'actualité sur Le Monde.fr.//gi;
$rub =~ s/é/e/gi;
$rub =~ s/è/e/gi;
$rub =~ s/ê/e/gi;
$rub =~ s/à/a/gi;
$rub =~ s/Le ?Monde.fr ?://;
$rub =~ s/ //g;
$rub=uc($rub);
my $output1="SORTIE-extract-txt-".$rub.".xml";
my $output2="SORTIE-extract-txt-".$rub.".txt";
if (!open (FILEOUTXML,">>:encoding(utf-8)", $output1)) { die "Pb a l'ouverture du fichier $output1"};
if (!open (FILEOUTTXT,">>:encoding(utf-8)", $output2)) { die "Pb a l'ouverture du fichier $output2"};
# lire texte pour extraire contenu des balises <title> et <description>
while ($texte =~ /<item><title>(.+?)<\/title>.+?<description>(.+?)<\/description>/g)
{
# capturer contenu de la regex pour titre
my $titre=$1;
# capturer contenu de la regex pour description
my $resume=$2;
# utilisation des modules pour remplacer dans les fichiers les entités XML et HTML
if (!(exists ($dictionnairedesitems{$titre})) and !(exists ($dictionnairedesitems{$resume})))
{
$dictionnairedesitems{$titre}++;
$dictionnairedesitems{$resume}++;
$titre = XML::Entities::decode('all', $titre);
$resume = XML::Entities::decode('all', $resume);
$titre = HTML::Entities::decode($titre);
$resume = HTML::Entities::decode($resume);
$tmptexteBRUT.="$titre \n";
$tmptexteBRUT.="$resume \n";
$tmptexteXML.="<item><title>$titre</title><description>$resume</description></item>\n";
# nettoyage des balises <description> pour supprimer les balises superflues
$tmptexteXML =~ s/<img.*?\/><\/description>/<\/description>/g;
$tmptexteBRUT =~ s/<img.*?\/> \n/\n/g;
}
# si le fichier n'est pas en UTF-8, convertir le string $titre et $resume en UTF-8
if (uc($encodage) ne "UTF-8")
{
utf8($titre);
utf8($resume);
}
} # fin while
# rajouter la fin des balises <items> et <file>
$tmptexteXML.="</items>\n</file>\n";
# écrire contenu dans le fichier .xml
print FILEOUTXML $tmptexteXML;
# écrire contenu dans le fichier .txt
print FILEOUTTXT $tmptexteBRUT;
# fermer fichiers
close FILEOUTXML;
close FILEOUTTXT;
} else {
#si l'encodage est vide afficher message
print "$file ==> $encodage \n";
} # fin IF3
} # fin IF 2
} # fin IF 1
} # fin FOR
} # fin lire_et_ecrire_xml()
####################################################################################################
# #
# cette fonction reçoit un nom de dossier comme argument et lit tous les fichiers .xml du dossier #
# Pour chaque fichier lu, la fonction extrait les rubriques et crée des fichiers de sortie #
# possédant le nom de la rubrique #
# #
####################################################################################################
sub extraire_rubrique {
#lire le nom dossier passé comme argument
my $path = shift(@_);
#ouvrir le dossier
opendir(DIR, $path) or die "can't open $path: $!\n";
#lire la liste de fichier du dossier
my @files = readdir(DIR);
closedir(DIR);
# lire un à un les items du dossier
foreach my $file (@files)
{
# ignorer les items cachés
next if $file =~ /^\.\.?$/;
# construire le chemin complet avec le nom du dossier + item traité
$file = $path."/".$file;
# vérifier si l'item est un dossier
if (-d $file)
{
# si l'item qu'on est en train de traiter est un dossier, on recommence la procédure
&extraire_rubrique($file);
}
# vérifier si l'item est un fichier - IF1
if (-f $file)
{
# tester si fichier possède l'extension .xml et ne contient pas la substring fil dans le nom - IF2
if (($file =~ /\.xml$/) && ($file!~/\/fil.+\.xml$/))
{
#ouvrir fichier .xml
open(FILE,$file);
#variable pour stocker le contenu du fichier .xml
my $texte="";
#lire toutes les lignes du fichier .xml
while (my $ligne=<FILE>)
{
# effacer les retours à la ligne
chomp $ligne;
# stocker le contenu de ligne lue
$texte .= $ligne;
}
# fermer le fichier .xml
close(FILE);
# regex pour capture l`encodage du fichier
$texte =~ /encoding ?= ?[\'\"]([^\'\"]+)[\'\"]/i;
# stocker le contenu trouvé par la regex
my $encodage=$1;
# vérifier la contenu de regex n'est pas vide IF3
if ($encodage ne "")
{
# reouvrir le fichier avec l'encogade correcte
open(FILE,"<:encoding($encodage)", $file);
# variables pour stocker le contenu du fichier lu
$texte="";
# lire le fichier .xml
while (my $ligne=<FILE>)
{
# effacer les retours à la ligne
chomp $ligne;
# stocker le contenu de ligne lue
$texte .= $ligne;
}
# fermer le fichier .xml
close(FILE);
# effacer les espaces en blanc
$texte =~ s/> *</></g;
# capturer le contenu à l'intérieur des balises <title> - IF4
if ($texte=~ /<channel><title>([^>]+)<\/title>/)
{
print $texte;
# stocker la valeur de rubrique trouvée par la regex
my $rub=$1;
# nettoyer les noms des rubriques
$rub =~ s/Toute l'actualité sur Le Monde.fr.//gi;
$rub =~ s/é/e/gi;
$rub =~ s/è/e/gi;
$rub =~ s/ê/e/gi;
$rub =~ s/à/a/gi;
$rub =~ s/Le ?Monde.fr ?://;
$rub =~ s/ //g;
$rub=uc($rub);
# stocker la rubrique dans le dictionnaire des rubriques
$dictionnairesdesrubriques{$rub}++;
} # fin IF4
} # fin IF3
} # fin IF2
} # fin IF1
} # fin FOR
} # fin extraire_rubrique()
A sample of results from tool 1
This is what our data looks like once the escaped and unreadable characters have been replaced. Note the characters with accents and lack of image links!
A sample of the XML output.

To make our results a bit easier to look at we linked the xml file to an xsl stylesheet which can be found here.
This is what our xml output looks like when it's linked to a xsl stylesheet.

The plain text output is really just that: plain text. Having an output that contains just the text with no additional formatting information is useful for the next step, where we use the annotator programs Cordial and TreeTagger to add part-of-speech information.
A sample of the TXT output.
What does Tool 2 do?
Tool 2 is a program that adds on to Tool 1 to pass the text contained within the <title> and <description> tags through two part-of-speech/lemma annotators, TreeTagger and Cordial.
There are multiple outputs from the program but they can be divided into two main groups: one is the same output from Tool 1, plain text files for each category and the XML output. The other group is the output from TreeTagger which is in XML format. It's organized by line and word. Each word in the line is associated with its part of speech tag and its lemma.
We also decided to create global files which contain all the category separated files concatenated together (aka - all the files).
The next part of Tool 2 is done manually. Each of the plain text files are converted to ISO-8859-15 (Latin 9) to be compatible with Cordial. The "œ" also needs to be replaced with "oe" as it's a character not supported in the version of Cordial we're using.
The Cordial output is a file, which when opened with a text editor, reveals three columns of words, parts-of-speech, and lemmas. For an example, please see the "Results" page.
TreeTagger is a free software developed by Helmut Schmid and can be downloaded here. Currently it can be used to tag texts in German, English, French, Italian, Dutch, Spanish, Bulgarian, Russian, Portuguese, Galician, Chinese, Swahili, Slovak, Latin, Estonian, Polish and old French.
Cordial is a paid software containing many writing/linguistic tools such as a spell-checker, a dictionary, and a translator. Cordial has a lot more functionality but is limited in terms of languages available for part-of-speech tagging. Generally we found that it's results are more accurate than those of TreeTagger. It can be found here.
The professor's method
This version doesn't exactly fit into the "Pure Perl" category as it does use one module ("Unicode::String") to convert the files to utf-8. This is the version seen in class which we try to improve upon in the "Our Results" pages.
- #/usr/bin/perl
- use Unicode::String qw(utf8);
- #-----------------------------------------------------------
- my $rep="$ARGV[0]";
- # on s'assure que le nom du répertoire ne se termine pas par un "/"
- $rep=~ s/[\/]$//;
- # on initialise une variable contenant le flux de sortie
- my %dictionnairedesitems=();
- my %dictionnairesdesrubriques=();
- #----------------------------------------
- &parcoursarborescencefichierspourrepererlesrubriques($rep); # on recupere les rubriques...
- #----------------------------------------
- my @liste_rubriques = keys(%dictionnairesdesrubriques);
- foreach my $rub (@liste_rubriques) {
- print $rub,"\n";
- #----------------------------------------
- my $output1="SORTIE/SORTIE-extract-txt-".$rub.".xml";
- my $output2="SORTIE/SORTIE-extract-txt-".$rub.".txt";
- my $output3="SORTIE/SORTIE-extract-txt-".$rub."-treetagger.xml";
- if (!open (FILEOUT1,">:encoding(utf-8)", $output1)) { die "Pb a l'ouverture du fichier $output1"};
- if (!open (FILEOUT2,">:encoding(utf-8)",$output2)) { die "Pb a l'ouverture du fichier $output2"};
- if (!open (FILEOUT3,">:encoding(utf-8)",$output3)) { die "Pb a l'ouverture du fichier $output3"};
- print FILEOUT1 "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
- print FILEOUT1 "<PARCOURS>\n";
- print FILEOUT3 "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
- print FILEOUT3 "<PARCOURS>\n";
- close(FILEOUT1);
- close(FILEOUT2);
- close(FILEOUT3);
- }
- #----------------------------------------
- &parcoursarborescencefichiers($rep); # on traite tous les fichiers
- #----------------------------------------
- foreach my $rub (@liste_rubriques) {
- my $output1="SORTIE/SORTIE-extract-txt-".$rub.".xml";
- my $output3="SORTIE/SORTIE-extract-txt-".$rub."-treetagger.xml";
- if (!open (FILEOUT1,">>:encoding(utf-8)", $output1)) { die "Pb a l'ouverture du fichier $output1"};
- if (!open (FILEOUT3,">>:encoding(utf-8)",$output3)) { die "Pb a l'ouverture du fichier $output3"};
- print FILEOUT1 "</PARCOURS>\n";
- print FILEOUT3 "</PARCOURS>\n";
- close(FILEOUT1);
- close(FILEOUT3);
- }
- exit;
- #----------------------------------------------
- #----------------------------------------------
- sub parcoursarborescencefichiers {
- my $path = shift(@_);
- opendir(DIR, $path) or die "can't open $path: $!\n";
- my @files = readdir(DIR);
- closedir(DIR);
- foreach my $file (@files) {
- next if $file =~ /^\.\.?$/;
- $file = $path."/".$file;
- if (-d $file) {
- &parcoursarborescencefichiers($file); #recurse!
- }
- if (-f $file) {
- if (($file=~/\.xml$/) && ($file!~/\/fil.+\.xml$/)) {
- open(FILE, $file);
- #print "Traitement de :\n$file\n";
- my $texte="";
- while (my $ligne=<FILE>) {
- $ligne =~ s/\n//g;
- $texte .= $ligne;
- }
- close(FILE);
- $texte=~/encoding ?= ?[\'\"]([^\'\"]+)[\'\"]/i;
- my $encodage=$1;
- #print "ENCODAGE : $encodage \n";
- if ($encodage ne "") {
- print "Extraction dans : $file \n";
- my $tmptexteXML="<file>\n";
- $tmptexteXML.="<name>$file</name>\n";
- my $tmptexteXMLtagger="<file>\n";
- $tmptexteXMLtagger.="<name>$file</name>\n";
- $texte =~ s/> *</></g;
- $texte=~/<pubDate>([^<]+)<\/pubDate>/;
- $tmptexteXML.="<date>$1</date>\n";
- $tmptexteXML.="<items>\n";
- $tmptexteXMLtagger.="<date>$1</date>\n";
- $tmptexteXMLtagger.="<items>\n";
- my $tmptexteBRUT="";
- open(FILE,"<:encoding($encodage)", $file);
- #print "Traitement de :\n$file\n";
- $texte="";
- while (my $ligne=<FILE>) {
- $ligne =~ s/\n//g;
- $texte .= $ligne;
- }
- close(FILE);
- $texte=~s/> *</></g;
- # on recherche la rubrique
- $texte=~/<channel><title>([^<]+)<\/title>/;
- my $rub=$1;
- $rub=~s/é/e/gi;
- $rub=~s/è/e/gi;
- $rub=~s/ê/e/gi;
- $rub=~s/à/a/gi;
- $rub=~ s/Le *Monde *\. *fr *://gi;
- $rub=~ s/ //g;
- $rub=~ s/s$//;
- $rub=uc($rub);
- #print $rub,"\n";
- #----------------------------------------
- my $output1="SORTIE/SORTIE-extract-txt-".$rub.".xml";
- my $output2="SORTIE/SORTIE-extract-txt-".$rub.".txt";
- my $output3="SORTIE/SORTIE-extract-txt-".$rub."-treetagger.xml";
- if (!open (FILEOUT1,">>:encoding(utf-8)", $output1)) { die "Pb a l'ouverture du fichier $output1"};
- if (!open (FILEOUT2,">>:encoding(utf-8)", $output2)) { die "Pb a l'ouverture du fichier $output2"};
- if (!open (FILEOUT3,">>:encoding(utf-8)", $output3)) { die "Pb a l'ouverture du fichier $output3"};
- #----------------------------------------
- my $compteurItem=0;
- my $compteurEtiquetage=0;
- while ($texte =~ /<item><title>(.+?)<\/title>.+?<description>(.+?)<\/description>/g) {
- my $titre=$1;
- my $resume=$2;
- #print "T : $titre \n R : $resume \n";
- if (uc($encodage) ne "UTF-8") {utf8($titre);utf8($resume);}
- $titre = &nettoietexte($1);
- $resume = &nettoietexte($2);
- $compteurItem++;
- if (!(exists($dictionnairedesitems{$resume}))) {
- $compteurEtiquetage++;
- print "Etiquetage (num : $compteurEtiquetage) sur item (num : $compteurItem) \n";
- my ($titreetiquete,$texteetiquete)=&etiquetageavectreetagger($titre,$resume);
- $tmptexteBRUT.="§ $titre \n";
- $tmptexteBRUT.="$resume \n";
- $tmptexteXML.="<item><title>$titre</title><abstract>$resume</abstract></item>\n";
- $tmptexteXMLtagger.="<item>\n<title>\n$titreetiquete</title>\n<abstract>\n$texteetiquete</abstract>\n</item>\n";
- $dictionnairedesitems{$resume}++;
- }
- else {
- $tmptexteXML.="<item><title>-</title><abstract>-</abstract></item>\n";
- }
- }
- $tmptexteXML.="</items>\n</file>\n";
- $tmptexteXMLtagger.="</items>\n</file>\n";
- print FILEOUT1 $tmptexteXML;
- print FILEOUT2 $tmptexteBRUT;
- print FILEOUT3 $tmptexteXMLtagger;
- close FILEOUT1;
- close FILEOUT2;
- close FILEOUT3;
- }
- else {
- print "$file ==> $encodage \n";
- }
- }
- }
- }
- }
- #----------------------------------------------------
- sub nettoietexte {
- my $texte=shift;
- $texte =~ s/</</g;
- $texte =~ s/>/>/g;
- $texte =~ s/<a href[^>]+>//g;
- $texte =~ s/<img[^>]+>//g;
- $texte =~ s/<\/a>//g;
- $texte =~ s/&#39;/'/g;
- $texte =~ s/&#34;/"/g;
- $texte =~ s/é/é/g;
- $texte =~ s/ê/ê/g;
- $texte =~ s/<[^>]+>//g;
- $texte =~ s/ / /g;
- $texte=~s/'/'/g;
- $texte=~s/"/"/g;
- $texte=~s/&#39;/'/g;
- $texte=~s/&#34;/"/g;
- return $texte;
- }
- #-----------------------------------------------------------------------------------
- sub parcoursarborescencefichierspourrepererlesrubriques {
- my $path = shift(@_);
- opendir(DIR, $path) or die "can't open $path: $!\n";
- my @files = readdir(DIR);
- closedir(DIR);
- foreach my $file (@files) {
- next if $file =~ /^\.\.?$/;
- $file = $path."/".$file;
- if (-d $file) {
- &parcoursarborescencefichierspourrepererlesrubriques($file); #recurse!
- }
- if (-f $file) {
- if (($file=~/\.xml$/) && ($file!~/\/fil.+\.xml$/)) {
- open(FILE,$file);
- #print "Traitement de :\n$file\n";
- my $texte="";
- while (my $ligne=<FILE>) {
- $ligne =~ s/\n//g;
- $texte .= $ligne;
- }
- close(FILE);
- $texte=~/encoding ?= ?[\'\"]([^\'\"]+)[\'\"]/i;
- my $encodage=$1;
- if ($encodage ne "") {
- open(FILE,"<:encoding($encodage)", $file);
- #print "Traitement de :\n$file\n";
- $texte="";
- while (my $ligne=<FILE>) {
- $ligne =~ s/\n//g;
- $texte .= $ligne;
- }
- close(FILE);
- $texte =~ s/> *</></g;
- if ($texte=~ /<channel><title>([^>]+)<\/title>/) {
- my $rub=$1;
- $rub=~s/é/e/gi;
- $rub=~s/è/e/gi;
- $rub=~s/ê/e/gi;
- $rub=~s/à/a/gi;
- $rub=~ s/Le *Monde *\. *fr *://gi;
- $rub=~ s/ //g;
- $rub=~ s/s$//;
- $rub=uc($rub);
- $dictionnairesdesrubriques{$rub}++;
- }
- }
- else {
- #print "$file ==> $encodage \n";
- }
- }
- }
- }
- }
- sub etiquetageavectreetagger {
- my ($titre,$texte)=@_;
- #----- le titre
- my $codage="utf-8";
- my $tmptag="texteaetiqueter.txt";
- open (TMPFILE,">:encoding(utf-8)", $tmptag);
- print TMPFILE $titre,"\n";
- close(TMPFILE);
- system("perl ./treetagger-win32/cmd/tokenise-fr.pl $tmptag | tree-tagger.exe ./treetagger-win32/lib/french-utf8.par -lemma -token -no-unknown -sgml > treetagger.txt");
- system("perl ./treetagger-win32/cmd/treetagger2xml-utf8.pl treetagger.txt $codage ");
- # lecture du resultat tagge en xml :
- open(OUT,"<:encoding(utf-8)","treetagger.txt.xml");
- my $fistline=<OUT>;
- my $titreetiquete="";
- while (my $l=<OUT>) {
- $titreetiquete.=$l;
- }
- close(OUT);
- #----- le resume
- open (TMPFILE,">:encoding(utf-8)", $tmptag);
- print TMPFILE $texte,"\n";
- close(TMPFILE);
- system("perl ./treetagger-win32/cmd/tokenise-fr.pl $tmptag | tree-tagger.exe ./treetagger-win32/lib/french-utf8.par -lemma -token -no-unknown -sgml > treetagger.txt");
- system("perl ./treetagger-win32/cmd/treetagger2xml-utf8.pl treetagger.txt $codage");
- # lecture du resultat tagge en xml :
- open(OUT,"<:encoding(utf-8)","treetagger.txt.xml");
- my $fistline=<OUT>;
- my $texteetiquete="";
- while (my $l=<OUT>) {
- $texteetiquete.=$l;
- }
- close(OUT);
- # on renvoie les resultats :
- return ($titreetiquete,$texteetiquete);
- }
#/usr/bin/perl
use Unicode::String qw(utf8);
#-----------------------------------------------------------
my $rep="$ARGV[0]";
# on s'assure que le nom du répertoire ne se termine pas par un "/"
$rep=~ s/[\/]$//;
# on initialise une variable contenant le flux de sortie
my %dictionnairedesitems=();
my %dictionnairesdesrubriques=();
#----------------------------------------
&parcoursarborescencefichierspourrepererlesrubriques($rep); # on recupere les rubriques...
#----------------------------------------
my @liste_rubriques = keys(%dictionnairesdesrubriques);
foreach my $rub (@liste_rubriques) {
print $rub,"\n";
#----------------------------------------
my $output1="SORTIE/SORTIE-extract-txt-".$rub.".xml";
my $output2="SORTIE/SORTIE-extract-txt-".$rub.".txt";
my $output3="SORTIE/SORTIE-extract-txt-".$rub."-treetagger.xml";
if (!open (FILEOUT1,">:encoding(utf-8)", $output1)) { die "Pb a l'ouverture du fichier $output1"};
if (!open (FILEOUT2,">:encoding(utf-8)",$output2)) { die "Pb a l'ouverture du fichier $output2"};
if (!open (FILEOUT3,">:encoding(utf-8)",$output3)) { die "Pb a l'ouverture du fichier $output3"};
print FILEOUT1 "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print FILEOUT1 "<PARCOURS>\n";
print FILEOUT3 "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print FILEOUT3 "<PARCOURS>\n";
close(FILEOUT1);
close(FILEOUT2);
close(FILEOUT3);
}
#----------------------------------------
&parcoursarborescencefichiers($rep); # on traite tous les fichiers
#----------------------------------------
foreach my $rub (@liste_rubriques) {
my $output1="SORTIE/SORTIE-extract-txt-".$rub.".xml";
my $output3="SORTIE/SORTIE-extract-txt-".$rub."-treetagger.xml";
if (!open (FILEOUT1,">>:encoding(utf-8)", $output1)) { die "Pb a l'ouverture du fichier $output1"};
if (!open (FILEOUT3,">>:encoding(utf-8)",$output3)) { die "Pb a l'ouverture du fichier $output3"};
print FILEOUT1 "</PARCOURS>\n";
print FILEOUT3 "</PARCOURS>\n";
close(FILEOUT1);
close(FILEOUT3);
}
exit;
#----------------------------------------------
#----------------------------------------------
sub parcoursarborescencefichiers {
my $path = shift(@_);
opendir(DIR, $path) or die "can't open $path: $!\n";
my @files = readdir(DIR);
closedir(DIR);
foreach my $file (@files) {
next if $file =~ /^\.\.?$/;
$file = $path."/".$file;
if (-d $file) {
&parcoursarborescencefichiers($file); #recurse!
}
if (-f $file) {
if (($file=~/\.xml$/) && ($file!~/\/fil.+\.xml$/)) {
open(FILE, $file);
#print "Traitement de :\n$file\n";
my $texte="";
while (my $ligne=<FILE>) {
$ligne =~ s/\n//g;
$texte .= $ligne;
}
close(FILE);
$texte=~/encoding ?= ?[\'\"]([^\'\"]+)[\'\"]/i;
my $encodage=$1;
#print "ENCODAGE : $encodage \n";
if ($encodage ne "") {
print "Extraction dans : $file \n";
my $tmptexteXML="<file>\n";
$tmptexteXML.="<name>$file</name>\n";
my $tmptexteXMLtagger="<file>\n";
$tmptexteXMLtagger.="<name>$file</name>\n";
$texte =~ s/> *</></g;
$texte=~/<pubDate>([^<]+)<\/pubDate>/;
$tmptexteXML.="<date>$1</date>\n";
$tmptexteXML.="<items>\n";
$tmptexteXMLtagger.="<date>$1</date>\n";
$tmptexteXMLtagger.="<items>\n";
my $tmptexteBRUT="";
open(FILE,"<:encoding($encodage)", $file);
#print "Traitement de :\n$file\n";
$texte="";
while (my $ligne=<FILE>) {
$ligne =~ s/\n//g;
$texte .= $ligne;
}
close(FILE);
$texte=~s/> *</></g;
# on recherche la rubrique
$texte=~/<channel><title>([^<]+)<\/title>/;
my $rub=$1;
$rub=~s/é/e/gi;
$rub=~s/è/e/gi;
$rub=~s/ê/e/gi;
$rub=~s/à/a/gi;
$rub=~ s/Le *Monde *\. *fr *://gi;
$rub=~ s/ //g;
$rub=~ s/s$//;
$rub=uc($rub);
#print $rub,"\n";
#----------------------------------------
my $output1="SORTIE/SORTIE-extract-txt-".$rub.".xml";
my $output2="SORTIE/SORTIE-extract-txt-".$rub.".txt";
my $output3="SORTIE/SORTIE-extract-txt-".$rub."-treetagger.xml";
if (!open (FILEOUT1,">>:encoding(utf-8)", $output1)) { die "Pb a l'ouverture du fichier $output1"};
if (!open (FILEOUT2,">>:encoding(utf-8)", $output2)) { die "Pb a l'ouverture du fichier $output2"};
if (!open (FILEOUT3,">>:encoding(utf-8)", $output3)) { die "Pb a l'ouverture du fichier $output3"};
#----------------------------------------
my $compteurItem=0;
my $compteurEtiquetage=0;
while ($texte =~ /<item><title>(.+?)<\/title>.+?<description>(.+?)<\/description>/g) {
my $titre=$1;
my $resume=$2;
#print "T : $titre \n R : $resume \n";
if (uc($encodage) ne "UTF-8") {utf8($titre);utf8($resume);}
$titre = &nettoietexte($1);
$resume = &nettoietexte($2);
$compteurItem++;
if (!(exists($dictionnairedesitems{$resume}))) {
$compteurEtiquetage++;
print "Etiquetage (num : $compteurEtiquetage) sur item (num : $compteurItem) \n";
my ($titreetiquete,$texteetiquete)=&etiquetageavectreetagger($titre,$resume);
$tmptexteBRUT.="§ $titre \n";
$tmptexteBRUT.="$resume \n";
$tmptexteXML.="<item><title>$titre</title><abstract>$resume</abstract></item>\n";
$tmptexteXMLtagger.="<item>\n<title>\n$titreetiquete</title>\n<abstract>\n$texteetiquete</abstract>\n</item>\n";
$dictionnairedesitems{$resume}++;
}
else {
$tmptexteXML.="<item><title>-</title><abstract>-</abstract></item>\n";
}
}
$tmptexteXML.="</items>\n</file>\n";
$tmptexteXMLtagger.="</items>\n</file>\n";
print FILEOUT1 $tmptexteXML;
print FILEOUT2 $tmptexteBRUT;
print FILEOUT3 $tmptexteXMLtagger;
close FILEOUT1;
close FILEOUT2;
close FILEOUT3;
}
else {
print "$file ==> $encodage \n";
}
}
}
}
}
#----------------------------------------------------
sub nettoietexte {
my $texte=shift;
$texte =~ s/</</g;
$texte =~ s/>/>/g;
$texte =~ s/<a href[^>]+>//g;
$texte =~ s/<img[^>]+>//g;
$texte =~ s/<\/a>//g;
$texte =~ s/&#39;/'/g;
$texte =~ s/&#34;/"/g;
$texte =~ s/é/é/g;
$texte =~ s/ê/ê/g;
$texte =~ s/<[^>]+>//g;
$texte =~ s/ / /g;
$texte=~s/'/'/g;
$texte=~s/"/"/g;
$texte=~s/&#39;/'/g;
$texte=~s/&#34;/"/g;
return $texte;
}
#-----------------------------------------------------------------------------------
sub parcoursarborescencefichierspourrepererlesrubriques {
my $path = shift(@_);
opendir(DIR, $path) or die "can't open $path: $!\n";
my @files = readdir(DIR);
closedir(DIR);
foreach my $file (@files) {
next if $file =~ /^\.\.?$/;
$file = $path."/".$file;
if (-d $file) {
&parcoursarborescencefichierspourrepererlesrubriques($file); #recurse!
}
if (-f $file) {
if (($file=~/\.xml$/) && ($file!~/\/fil.+\.xml$/)) {
open(FILE,$file);
#print "Traitement de :\n$file\n";
my $texte="";
while (my $ligne=<FILE>) {
$ligne =~ s/\n//g;
$texte .= $ligne;
}
close(FILE);
$texte=~/encoding ?= ?[\'\"]([^\'\"]+)[\'\"]/i;
my $encodage=$1;
if ($encodage ne "") {
open(FILE,"<:encoding($encodage)", $file);
#print "Traitement de :\n$file\n";
$texte="";
while (my $ligne=<FILE>) {
$ligne =~ s/\n//g;
$texte .= $ligne;
}
close(FILE);
$texte =~ s/> *</></g;
if ($texte=~ /<channel><title>([^>]+)<\/title>/) {
my $rub=$1;
$rub=~s/é/e/gi;
$rub=~s/è/e/gi;
$rub=~s/ê/e/gi;
$rub=~s/à/a/gi;
$rub=~ s/Le *Monde *\. *fr *://gi;
$rub=~ s/ //g;
$rub=~ s/s$//;
$rub=uc($rub);
$dictionnairesdesrubriques{$rub}++;
}
}
else {
#print "$file ==> $encodage \n";
}
}
}
}
}
sub etiquetageavectreetagger {
my ($titre,$texte)=@_;
#----- le titre
my $codage="utf-8";
my $tmptag="texteaetiqueter.txt";
open (TMPFILE,">:encoding(utf-8)", $tmptag);
print TMPFILE $titre,"\n";
close(TMPFILE);
system("perl ./treetagger-win32/cmd/tokenise-fr.pl $tmptag | tree-tagger.exe ./treetagger-win32/lib/french-utf8.par -lemma -token -no-unknown -sgml > treetagger.txt");
system("perl ./treetagger-win32/cmd/treetagger2xml-utf8.pl treetagger.txt $codage ");
# lecture du resultat tagge en xml :
open(OUT,"<:encoding(utf-8)","treetagger.txt.xml");
my $fistline=<OUT>;
my $titreetiquete="";
while (my $l=<OUT>) {
$titreetiquete.=$l;
}
close(OUT);
#----- le resume
open (TMPFILE,">:encoding(utf-8)", $tmptag);
print TMPFILE $texte,"\n";
close(TMPFILE);
system("perl ./treetagger-win32/cmd/tokenise-fr.pl $tmptag | tree-tagger.exe ./treetagger-win32/lib/french-utf8.par -lemma -token -no-unknown -sgml > treetagger.txt");
system("perl ./treetagger-win32/cmd/treetagger2xml-utf8.pl treetagger.txt $codage");
# lecture du resultat tagge en xml :
open(OUT,"<:encoding(utf-8)","treetagger.txt.xml");
my $fistline=<OUT>;
my $texteetiquete="";
while (my $l=<OUT>) {
$texteetiquete.=$l;
}
close(OUT);
# on renvoie les resultats :
return ($titreetiquete,$texteetiquete);
}
Tool 2 & Tool 3 & Tool 4
A bonus part of this section was to use a textometric analysis program called Le Trameur to tag the text using the built-in TreeTagger function, extract morphosyntactic sequences and then visualize the results in a series of graphs. Essentially, the program is capable of replacing Tool 2, Tool 3 and Tool 4.
Not being on Windows, we found a way to still use Le Trameur, (Wine), but certain functionalities don't quite work as well as they might on Windows. TreeTagger is one of those functions so this bonus step was not completed.

A full description of Le Trameur's functions can be found at this page.
Pure Perl
As we've mentioned, our Pure Perl version of our program doesn't use modules to deal with the file cleaning aspect. We've therefore written our own versions of what the modules do, but more specific to our script.
To replace the HTML entities with their readable equivalents, we created a cleaning subroutine. This subroutine is called "nettoyerTexte" and is as complete as we could make it. We have a separate cleaning routine for our sections ("rubriques") that is more specifically targeted to what we know is in each of the section titles.
To create our TXT and XML outputs we wrote our own method rather than use the XML::RSS module.
In contrast with the in-class version, we reorganized our outputs into different folders. We also create a "global file" in each category (TXT, XML) which contains all the other files concatenated together.
- #!/usr/bin/perl
- <<DOC;
- Votre Nom : Bienvenue, Poadey, Cavalcante
- MARS 2015
- usage : perl parcours-arborescence-fichiers repertoire-a-parcourir
- Le programme prend en entrée le nom du répertoire contenant les fichiers
- à traiter
- Le programme construit en sortie des fichiers structurés : en format XML
- et en format TXT
- DOC
- use Unicode::String qw(utf8);
- use utf8;
- # pour pouvoir afficher la date
- use Time::localtime;
- #------------------------------------------------------------------------------
- # des compteurs pour le nombre des items
- my $nb_filesIN = 0;
- my $nb_itemsIN = 0;
- my $nb_itemsOUT = 0;
- #------------------------------------------------------------------------------
- # le répertoire d'entrée
- my $rep = "$ARGV[0]";
- # enlever le slash à la fin du répertoire
- $rep =~ s/[\/]$//;
- #------------------------------------------------------------------------------
- # des hash tables pour vérifier qu'on n'a pas deux fois les même infos
- my %dico_titre = ();
- my %dico_description = ();
- # cet hash nous permet de juste traiter une fois chaque texte
- my %dico_files = ();
- # creer l`objet date pour ecrire les dates dans le log
- my $date_time = ctime();
- #------------------------------------------------------------------------------
- # creation des dossiers de sortie
- my $res = "./Sorties/";
- if (! -e $res) {
- mkdir($res) or die ("Problème avec la création du répertoire de $rep : $!");
- }
- $res = "./Sorties/Sorties_PurePerl/";
- if (! -e $res) {
- mkdir($res) or die ("Problème avec la création du répertoire de $rep : $!\n");
- }
- #------------------------------------------------------------------------------
- # sorties etiquetées
- my $resBAO2 = "./Sorties/Sorties_Tagged/";
- if (! -e $resBAO2) {
- mkdir($resBAO2) or die ("Problème avec la création du répertoire de $rep : $!\n");
- }
- #------------------------------------------------------------------------------
- # sortie globale txt
- open(FILEGLOBALTXT,">:encoding(UTF-8)", $res."SortieGlobale1.txt");
- #------------------------------------------------------------------------------
- &parcoursarborescencefichiers($rep); #recurse!
- #------------------------------------------------------------------------------
- close FILEGLOBALTXT;
- #------------------------------------------------------------------------------
- # création de la sortie globale xml
- open(FILEGLOBALXML, ">:encoding(UTF-8)", $res."SortieGlobale1.xml");
- print FILEGLOBALXML "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
- print FILEGLOBALXML "<PARCOURS>\n";
- print FILEGLOBALXML "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
- print FILEGLOBALXML "<FILTRAGE>";
- #------------------------------------------------------------------------------
- # écrire contenu de la sortie globale xml
- opendir(DIR, $res) or die "Erreur d'ouverture du repertoire: $!\n";
- my @sorties = readdir(DIR);
- closedir(DIR);
- foreach my $sortie (@sorties) {
- if ($sortie=~/(.+?)\.xml$/ && $1 != "SortieGlobale1") {
- my $rub=$1;
- open(FILE,">>:encoding(UTF-8)", $res.$sortie);
- print FILE "</".$rub.">\n";;
- print FILE "</PARCOURS>\n";
- close(FILE);
- print FILEGLOBALXML "<$rub>\n";
- print FILEGLOBALXML ${"DumpXML".$rub};
- print FILEGLOBALXML "</$rub>";
- }
- }
- print FILEGLOBALXML "</FILTRAGE>\n";
- print FILEGLOBALXML "</PARCOURS>\n";
- close(FILEGLOBALXML);
- #------------------------------------------------------------------------------
- open(FILEGLOBALXML, ">:encoding(UTF-8)", $resBAO2."SortieGlobale2.xml");
- print FILEGLOBALXML "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
- print FILEGLOBALXML "<PARCOURS>\n";
- print FILEGLOBALXML "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
- print FILEGLOBALXML "<FILTRAGE>";
- #------------------------------------------------------------------------------
- opendir(DIR, $resBAO2) or die "Erreur d'ouverture de repertoire: $!\n";
- @sorties = readdir(DIR);
- closedir(DIR);
- foreach my $sortie (@sorties) {
- # se fait sur chaque sortie xml dans chaque rubrique
- if ($sortie=~/(.+?)\.xml$/ && $1 != "SortieGlobale2") {
- my $rub = $1;
- open(FILE,">>:encoding(UTF-8)", $resBAO2.$sortie);
- print FILE "</".$rub.">\n";;
- print FILE "</PARCOURS>\n";
- close FILE;
- print FILEGLOBALXML "<$rub>\n";
- print FILEGLOBALXML ${"DumpXML2_Tagged".$rub};
- print FILEGLOBALXML "</$rub>";
- }
- }
- #------------------------------------------------------------------------------
- print FILEGLOBALXML "</FILTRAGE>\n";
- print FILEGLOBALXML "</PARCOURS>\n";
- close(FILEGLOBALXML);
- #------------------------------------------------------------------------------
- # imprime le nombre des infos à la fin du programme
- print "\n" . "files IN = $nb_filesIN\n";
- print "items IN = $nb_itemsIN\n";
- print "items OUT = $nb_itemsOUT\n";
- print "fin.\n";
- exit;
- # fin du main programme
- #------------------------------------------------------------------------------
- #------------------------------------------------------------------------------
- # commencement des subroutines
- #------------------------------------------------------------------------------
- # subroutine pour parcourir l'aborescence
- sub parcoursarborescencefichiers {
- my $path = shift(@_); # chemin vers le dossier en entrée
- opendir(DIR, $path) or die "Probleme d'ouverture du dossier: $!\n";
- my @files = readdir(DIR);
- closedir(DIR);
- #--------------------------------------------
- foreach my $file (@files) {
- next if $file =~ /^\.\.?$/; #si . ou ..
- $file = $path."/".$file;
- #si $file est un dossier
- if (-d $file) {
- &parcoursarborescencefichiers($file); #recurse!
- }
- # faire le traitement si $file est un fichier
- if (-f $file) {
- # traiter les fichiers xml seulement
- if ($file=~/^[^(fil)]+?\.xml$/) {
- $nb_filesIN++;
- print $file,"\n";
- #lire le fichier xml
- open(FILE,$file);
- my $firstLine = <FILE>;
- my $encodage = "";
- #vérifier encodage du fichier xml
- if($firstLine =~ /encoding= ?['"]([^\'"]+)['"]/) {
- $encodage = $1; #extraire l'encodage
- }
- close(FILE);
- # si on trouve l'encodage, le fichier est reouvert avec l'encodage correcte
- if (!($encodage eq "")) {
- open(FILE,"<:encoding($encodage)",$file);
- my $texte = "";
- #éliminer les retours à ligne dans le fichier [ \n et \r ]
- while (my $ligne = <FILE>) {
- $ligne =~ s/\n//g;
- $ligne =~ s/\r//g;
- $texte .= $ligne;
- }
- close FILE;
- $texte =~ s/> *?</></g; # coller les balises
- #-----------------------------------------
- # extraire rubrique, date et nom
- $texte =~ /<channel>.*?<title>(.*?)<\/title>.*?<pubDate>(.+?)<\/pubDate>.*?<\/channel>/;
- # nettoyer les rubriques
- my $rubrique = &nettoyerRubriques($1);
- print "RUBRIQUE : $rubrique\n";
- # extraire la date
- my $date = &nettoyerRubriques($2);
- # nom du fichier
- my $name = $file;
- # uniquement les fichiers XML contenant les mises à jour
- $name =~ s/.*?(20.*)/$1/;
- #------------------------------------------
- # ouvre des balises et écrire dans des fichiers de sortie
- my $cheminXML=$res.$rubrique.".xml";
- # si on n'a pas encore vu le rubrique on doit le créer
- if (! -e $cheminXML) {
- # créer un fichier
- if (!open (FILEOUT,">:encoding(UTF-8)",$cheminXML)) {
- die "Probleme a la creation du fichier $cheminXML : $!";
- }
- # ouverture des balises XML du début du fichier
- print FILEOUT "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
- print FILEOUT "<PARCOURS>\n";
- print FILEOUT "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
- print FILEOUT "<$rubrique>\n";
- print FILEOUT "<file>";
- print FILEOUT "<name>$name</name>";
- print FILEOUT "<date>$date</date>";
- print FILEOUT "<items>";
- close(FILEOUT);
- ${"DumpXML"."$rubrique"}="";
- }
- # si le fichier existe déjà
- else {
- if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML)) {
- die "Problème a l'ouverture du fichier $cheminXML : $!\n";
- }
- print FILEOUT "<file>";
- print FILEOUT "<name>$name</name>";
- print FILEOUT "<date>$date</date>";
- print FILEOUT "<items>";
- close(FILEOUT);
- }
- #-------------------------------------------
- my $cheminXML_BAO2=$resBAO2.$rubrique.".xml";
- # si on n'a pas encore vu le rubrique
- if (! -e $cheminXML_BAO2) {
- # créer un fichier
- if (!open (FILEOUT,">:encoding(UTF-8)",$cheminXML_BAO2)) {
- die "Probleme a la creation du fichier $cheminXML_BAO2 : $!\n";
- }
- # ouverture des balises XML du début du fichier
- print FILEOUT "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
- print FILEOUT "<PARCOURS>\n";
- print FILEOUT "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
- print FILEOUT "<$rubrique>\n";
- print FILEOUT "<file>";
- print FILEOUT "<name>$name</name>";
- print FILEOUT "<date>$date</date>";
- print FILEOUT "<items>";
- close(FILEOUT);
- ${"DumpXML_tagged"."$rubrique"}="";
- }
- # si le fichier existe déjà
- else {
- if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML_BAO2)) {
- die "Problème a l'ouverture du fichier $cheminXML_BAO2 : $!\n";
- }
- print FILEOUT "<file>";
- print FILEOUT "<name>$file</name>";
- print FILEOUT "<date>$date</date>";
- print FILEOUT "<items>";
- close(FILEOUT);
- }
- #---------------------------------------------
- # extractions des titres et descriptions
- while ($texte =~ /<item>.*?<title>(.*?)<\/title>.*?<description>(.*?)<\/description>/g)
- {
- my $titre = $1;
- my $description = $2;
- $nb_itemsIN++;
- #-----------------------------------------
- # nettoyer le texte
- $titre = &nettoyerTexte($titre);
- $description = &nettoyerTexte($description);
- if (!(($titre eq "") or ($description eq ""))) {
- #-----------------------------------------
- # convertir si besoin en utf-8
- if (uc($encodage) ne "UTF-8") {
- utf8($titre);
- utf8($description);
- }
- #----------------------------------------------
- # regarde si on a déjà vu le texte
- if (!((exists $dico_titre{$rubrique . $titre}) && (exists $dico_description{$rubrique . $description})))
- {
- $dico_titre{$rubrique . $titre} = "1";
- $dico_description{$rubrique . $description} = "1";
- $nb_itemsOUT++;
- #------------------------------------------
- # faire l'etiquetage
- my $titre_tagged = &treetagger($titre);
- my $description_tagged = &treetagger($description);
- open(LOG, ">>", "log_bao2.txt");
- if(exists $dico_files{$file}){
- $count_file = int($dico_files{$file});
- $count_file++;
- %dico_files = ($file => $count_file);
- } else {
- %dico_files = ($file => 1);
- }
- #creer l`objet date pour ecrire les dates dans le log
- my $date_time = ctime();
- #ecrire le fichier de log avec le nom du fichier et l`heure de lecture
- print LOG $file." ".$dico_files{$file}."\t\t read on ".$date_time."\n";
- # mettre dans les sorties xml
- if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML)) {
- die "Problème a l'ouverture du fichier $cheminXML : $!\n";
- }
- print FILEOUT "<item>\n";
- print FILEOUT "<titre>" . $titre . "</titre>\n<description>" . $description . "</description>\n";
- print FILEOUT "</item>\n";
- close(FILEOUT);
- #----------------------------------------------
- # créer un dump pour chaque rubrique
- ${"DumpXML" . $rubrique} .= "<item>\n<titre>" . $titre . "</titre>\n<description>" . $description . "</description>\n</item>\n";
- #----------------------------------------------
- # partie de sorties txt
- my $cheminTXT = $res . $rubrique . ".txt";
- # si on n'a pas encore vu la rubrique
- if (! -e $cheminTXT) {
- if (!open (FILEGLOBALTXT,">>:encoding(iso-8859-15)",$cheminTXT)) {
- die "Problème a l'ouverture du fichier $cheminTXT : $!\n";
- }
- # écrire dans le sortie txt
- print FILEGLOBALTXT "$titre." . " $description.\n";
- close(FILEGLOBALTXT);
- }
- # si on a déjà vu la rubrique
- else {
- if (!open (FILEGLOBALTXT,">>:encoding(iso-8859-15)",$cheminTXT)) {
- die "Problème a l'ouverture du fichier $cheminTXT : $!\n";
- }
- # écrire dans le sortie txt
- print FILEGLOBALTXT "$titre." . " $description.";
- close(FILEGLOBALTXT);
- }
- if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML_BAO2)) {
- die "Problème a l'ouverture du fichier $cheminXML_BAO2 : $!\n";
- }
- print FILEOUT "<item>\n";
- print FILEOUT "<titre>".$titre_tagged."</titre>\n<description>".$description_tagged."</description>\n";
- print FILEOUT "</item>\n";
- close(FILEOUT);
- # créer un dump pour chaque rubrique
- ${"DumpXML2_Tagged".$rubrique}.="<item>\n<titre>".$titre_tagged."</titre>\n<description>".$description_tagged."</description>\n</item>\n";
- }
- }
- }
- # fermer la balise file pour chaque fichier xml
- if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML))
- {
- die "Problème a l'ouverture du fichier .$cheminXML : $!\n";
- }
- print FILEOUT "</items>";
- print FILEOUT "</file>";
- close(FILEOUT);
- # fermer la balise les fichier xml etiqutée
- if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML_BAO2)) {
- die "Problème a l'ouverture du fichier .$cheminXML_BAO2 : $!\n";
- }
- print FILEOUT "</items>";
- print FILEOUT "</file>";
- close(FILEOUT);
- }
- }
- }
- }
- }
- #------------------------------------------------------------------------------
- # subroutine pour nettoyer le texte
- #------------------------------------------------------------------------------
- sub nettoyerTexte {
- my $tx = $_[0];
- $tx =~ s/&/&/g;
- $tx =~ s/&/&/g;
- $tx =~ s/"/"/g;
- $tx =~ s/"/"/g;
- $tx =~ s/'/'/g;
- $tx =~ s/'/'/g;
- $tx =~ s/</</g;
- $tx =~ s/</</g;
- $tx =~ s/>/>/g;
- $tx =~ s/>/>/g;
- $tx =~ s/ //g;
- $tx =~ s/ //g;
- $tx =~ s/£/£/g;
- $tx =~ s/£/£/g;
- $tx =~ s/©/©/g;
- $tx =~ s/«/«/g;
- $tx =~ s/«/«/g;
- $tx =~ s/»/»/g;
- $tx =~ s/»//g;
- $tx =~ s/É/É/g;
- $tx =~ s/É/É/g;
- $tx =~ s/í/î/g;
- $tx =~ s/î/î/g;
- $tx =~ s/ï/ï/g;
- $tx =~ s/ï/ï/g;
- $tx =~ s/à/à/g;
- $tx =~ s/à/à/g;
- $tx =~ s/â/â/g;
- $tx =~ s/â/â/g;
- $tx =~ s/ç/ç/g;
- $tx =~ s/ç/ç/g;
- $tx =~ s/è/è/g;
- $tx =~ s/è/è/g;
- $tx =~ s/é/é/g;
- $tx =~ s/é/é/g;
- $tx =~ s/ê/ê/g;
- $tx =~ s/ê/ê/g;
- $tx =~ s/ô/ô/g;
- $tx =~ s/ô/ô/g;
- $tx =~ s/û/û/g;
- $tx =~ s/û/û/g;
- $tx =~ s/ü/ü/g;
- $tx =~ s/ü/ü/g;
- $tx =~ s/\x9c/œ/g;
- $tx =~ s/<br\/\>//g;
- $tx =~ s/<img.*?\/>//g;
- $tx =~ s/<.+?>//sg;
- $tx =~ s/<a.*?>.*?<\/a>//g;
- $tx =~ s/<![CDATA[(.*?)]]>/$1/g;
- $tx =~ s/<[^>]>//g;
- $tx =~ s/\.$//;
- $tx =~ s/&/et/g;
- return $tx;
- }
- #------------------------------------------------------------------------------
- # subroutine pour nettoyer des rubriques
- #------------------------------------------------------------------------------
- sub nettoyerRubriques {
- my $rubrique = shift;
- $rubrique =~ s/Le Monde.fr//g;
- $rubrique =~ s/LeMonde.fr//g;
- $rubrique =~ s/: Toute l'actualité sur//g;
- $rubrique =~ s/É/e/g;
- $rubrique =~ s/é/e/g;
- $rubrique =~ s/è/e/g;
- $rubrique =~ s/ê/a/g;
- $rubrique =~ s/ë/e/g;
- $rubrique =~ s/ï/i/g;
- $rubrique =~ s/î/i/g;
- $rubrique =~ s/à/a/g;
- $rubrique =~ s/ô/o/g;
- $rubrique =~ s/,/_/g;
- $rubrique = uc($rubrique);
- $rubrique =~ s/ //g;
- $rubrique =~ s/[\.\:;\'\"\-]+//g;
- return $rubrique;
- }
- #------------------------------------------------------------------------------
- # subroutine pour le tokenisation et etiquetage
- #------------------------------------------------------------------------------
- sub treetagger {
- my $texte = shift;
- my $temptag;
- # créer un fichier temporaire pour tagger des morceaux de texte
- open($temptag, ">:encoding(UTF-8)", "./temptag.txt");
- print $temptag $texte;
- close($temptag);
- system("perl tokenise-utf8.pl ./temptag.txt | /home/alexandre/tree-tagger/bin/tree-tagger -lemma -token -no-unknown -sgml /home/alexandre/tree-tagger/models/french.par > treetagger.txt");
- system("perl ./treetagger2xml-utf8.pl treetagger.txt utf-8");
- open(TaggedOUT,"<:encoding(utf-8)","treetagger.txt.xml");
- my $tagged_text = "";
- #lire la ligne d'en tête du fichier xml étiqueté, pour éviter que cette
- # ligne soit inclue dans le nouveau fichier xml
- my $line_den_tete = <TaggedOUT>;
- while (my $l = <TaggedOUT>) {
- $tagged_text .= $l;
- }
- close(TaggedOUT);
- return $tagged_text;
- }
- # fin des subroutines
- #------------------------------------------------------------------------------
- #------------------------------------------------------------------------------
#!/usr/bin/perl
<<DOC;
Votre Nom : Bienvenue, Poadey, Cavalcante
MARS 2015
usage : perl parcours-arborescence-fichiers repertoire-a-parcourir
Le programme prend en entrée le nom du répertoire contenant les fichiers
à traiter
Le programme construit en sortie des fichiers structurés : en format XML
et en format TXT
DOC
use Unicode::String qw(utf8);
use utf8;
# pour pouvoir afficher la date
use Time::localtime;
#------------------------------------------------------------------------------
# des compteurs pour le nombre des items
my $nb_filesIN = 0;
my $nb_itemsIN = 0;
my $nb_itemsOUT = 0;
#------------------------------------------------------------------------------
# le répertoire d'entrée
my $rep = "$ARGV[0]";
# enlever le slash à la fin du répertoire
$rep =~ s/[\/]$//;
#------------------------------------------------------------------------------
# des hash tables pour vérifier qu'on n'a pas deux fois les même infos
my %dico_titre = ();
my %dico_description = ();
# cet hash nous permet de juste traiter une fois chaque texte
my %dico_files = ();
# creer l`objet date pour ecrire les dates dans le log
my $date_time = ctime();
#------------------------------------------------------------------------------
# creation des dossiers de sortie
my $res = "./Sorties/";
if (! -e $res) {
mkdir($res) or die ("Problème avec la création du répertoire de $rep : $!");
}
$res = "./Sorties/Sorties_PurePerl/";
if (! -e $res) {
mkdir($res) or die ("Problème avec la création du répertoire de $rep : $!\n");
}
#------------------------------------------------------------------------------
# sorties etiquetées
my $resBAO2 = "./Sorties/Sorties_Tagged/";
if (! -e $resBAO2) {
mkdir($resBAO2) or die ("Problème avec la création du répertoire de $rep : $!\n");
}
#------------------------------------------------------------------------------
# sortie globale txt
open(FILEGLOBALTXT,">:encoding(UTF-8)", $res."SortieGlobale1.txt");
#------------------------------------------------------------------------------
&parcoursarborescencefichiers($rep); #recurse!
#------------------------------------------------------------------------------
close FILEGLOBALTXT;
#------------------------------------------------------------------------------
# création de la sortie globale xml
open(FILEGLOBALXML, ">:encoding(UTF-8)", $res."SortieGlobale1.xml");
print FILEGLOBALXML "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print FILEGLOBALXML "<PARCOURS>\n";
print FILEGLOBALXML "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
print FILEGLOBALXML "<FILTRAGE>";
#------------------------------------------------------------------------------
# écrire contenu de la sortie globale xml
opendir(DIR, $res) or die "Erreur d'ouverture du repertoire: $!\n";
my @sorties = readdir(DIR);
closedir(DIR);
foreach my $sortie (@sorties) {
if ($sortie=~/(.+?)\.xml$/ && $1 != "SortieGlobale1") {
my $rub=$1;
open(FILE,">>:encoding(UTF-8)", $res.$sortie);
print FILE "</".$rub.">\n";;
print FILE "</PARCOURS>\n";
close(FILE);
print FILEGLOBALXML "<$rub>\n";
print FILEGLOBALXML ${"DumpXML".$rub};
print FILEGLOBALXML "</$rub>";
}
}
print FILEGLOBALXML "</FILTRAGE>\n";
print FILEGLOBALXML "</PARCOURS>\n";
close(FILEGLOBALXML);
#------------------------------------------------------------------------------
open(FILEGLOBALXML, ">:encoding(UTF-8)", $resBAO2."SortieGlobale2.xml");
print FILEGLOBALXML "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print FILEGLOBALXML "<PARCOURS>\n";
print FILEGLOBALXML "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
print FILEGLOBALXML "<FILTRAGE>";
#------------------------------------------------------------------------------
opendir(DIR, $resBAO2) or die "Erreur d'ouverture de repertoire: $!\n";
@sorties = readdir(DIR);
closedir(DIR);
foreach my $sortie (@sorties) {
# se fait sur chaque sortie xml dans chaque rubrique
if ($sortie=~/(.+?)\.xml$/ && $1 != "SortieGlobale2") {
my $rub = $1;
open(FILE,">>:encoding(UTF-8)", $resBAO2.$sortie);
print FILE "</".$rub.">\n";;
print FILE "</PARCOURS>\n";
close FILE;
print FILEGLOBALXML "<$rub>\n";
print FILEGLOBALXML ${"DumpXML2_Tagged".$rub};
print FILEGLOBALXML "</$rub>";
}
}
#------------------------------------------------------------------------------
print FILEGLOBALXML "</FILTRAGE>\n";
print FILEGLOBALXML "</PARCOURS>\n";
close(FILEGLOBALXML);
#------------------------------------------------------------------------------
# imprime le nombre des infos à la fin du programme
print "\n" . "files IN = $nb_filesIN\n";
print "items IN = $nb_itemsIN\n";
print "items OUT = $nb_itemsOUT\n";
print "fin.\n";
exit;
# fin du main programme
#------------------------------------------------------------------------------
#------------------------------------------------------------------------------
# commencement des subroutines
#------------------------------------------------------------------------------
# subroutine pour parcourir l'aborescence
sub parcoursarborescencefichiers {
my $path = shift(@_); # chemin vers le dossier en entrée
opendir(DIR, $path) or die "Probleme d'ouverture du dossier: $!\n";
my @files = readdir(DIR);
closedir(DIR);
#--------------------------------------------
foreach my $file (@files) {
next if $file =~ /^\.\.?$/; #si . ou ..
$file = $path."/".$file;
#si $file est un dossier
if (-d $file) {
&parcoursarborescencefichiers($file); #recurse!
}
# faire le traitement si $file est un fichier
if (-f $file) {
# traiter les fichiers xml seulement
if ($file=~/^[^(fil)]+?\.xml$/) {
$nb_filesIN++;
print $file,"\n";
#lire le fichier xml
open(FILE,$file);
my $firstLine = <FILE>;
my $encodage = "";
#vérifier encodage du fichier xml
if($firstLine =~ /encoding= ?['"]([^\'"]+)['"]/) {
$encodage = $1; #extraire l'encodage
}
close(FILE);
# si on trouve l'encodage, le fichier est reouvert avec l'encodage correcte
if (!($encodage eq "")) {
open(FILE,"<:encoding($encodage)",$file);
my $texte = "";
#éliminer les retours à ligne dans le fichier [ \n et \r ]
while (my $ligne = <FILE>) {
$ligne =~ s/\n//g;
$ligne =~ s/\r//g;
$texte .= $ligne;
}
close FILE;
$texte =~ s/> *?</></g; # coller les balises
#-----------------------------------------
# extraire rubrique, date et nom
$texte =~ /<channel>.*?<title>(.*?)<\/title>.*?<pubDate>(.+?)<\/pubDate>.*?<\/channel>/;
# nettoyer les rubriques
my $rubrique = &nettoyerRubriques($1);
print "RUBRIQUE : $rubrique\n";
# extraire la date
my $date = &nettoyerRubriques($2);
# nom du fichier
my $name = $file;
# uniquement les fichiers XML contenant les mises à jour
$name =~ s/.*?(20.*)/$1/;
#------------------------------------------
# ouvre des balises et écrire dans des fichiers de sortie
my $cheminXML=$res.$rubrique.".xml";
# si on n'a pas encore vu le rubrique on doit le créer
if (! -e $cheminXML) {
# créer un fichier
if (!open (FILEOUT,">:encoding(UTF-8)",$cheminXML)) {
die "Probleme a la creation du fichier $cheminXML : $!";
}
# ouverture des balises XML du début du fichier
print FILEOUT "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print FILEOUT "<PARCOURS>\n";
print FILEOUT "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
print FILEOUT "<$rubrique>\n";
print FILEOUT "<file>";
print FILEOUT "<name>$name</name>";
print FILEOUT "<date>$date</date>";
print FILEOUT "<items>";
close(FILEOUT);
${"DumpXML"."$rubrique"}="";
}
# si le fichier existe déjà
else {
if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML)) {
die "Problème a l'ouverture du fichier $cheminXML : $!\n";
}
print FILEOUT "<file>";
print FILEOUT "<name>$name</name>";
print FILEOUT "<date>$date</date>";
print FILEOUT "<items>";
close(FILEOUT);
}
#-------------------------------------------
my $cheminXML_BAO2=$resBAO2.$rubrique.".xml";
# si on n'a pas encore vu le rubrique
if (! -e $cheminXML_BAO2) {
# créer un fichier
if (!open (FILEOUT,">:encoding(UTF-8)",$cheminXML_BAO2)) {
die "Probleme a la creation du fichier $cheminXML_BAO2 : $!\n";
}
# ouverture des balises XML du début du fichier
print FILEOUT "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print FILEOUT "<PARCOURS>\n";
print FILEOUT "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
print FILEOUT "<$rubrique>\n";
print FILEOUT "<file>";
print FILEOUT "<name>$name</name>";
print FILEOUT "<date>$date</date>";
print FILEOUT "<items>";
close(FILEOUT);
${"DumpXML_tagged"."$rubrique"}="";
}
# si le fichier existe déjà
else {
if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML_BAO2)) {
die "Problème a l'ouverture du fichier $cheminXML_BAO2 : $!\n";
}
print FILEOUT "<file>";
print FILEOUT "<name>$file</name>";
print FILEOUT "<date>$date</date>";
print FILEOUT "<items>";
close(FILEOUT);
}
#---------------------------------------------
# extractions des titres et descriptions
while ($texte =~ /<item>.*?<title>(.*?)<\/title>.*?<description>(.*?)<\/description>/g)
{
my $titre = $1;
my $description = $2;
$nb_itemsIN++;
#-----------------------------------------
# nettoyer le texte
$titre = &nettoyerTexte($titre);
$description = &nettoyerTexte($description);
if (!(($titre eq "") or ($description eq ""))) {
#-----------------------------------------
# convertir si besoin en utf-8
if (uc($encodage) ne "UTF-8") {
utf8($titre);
utf8($description);
}
#----------------------------------------------
# regarde si on a déjà vu le texte
if (!((exists $dico_titre{$rubrique . $titre}) && (exists $dico_description{$rubrique . $description})))
{
$dico_titre{$rubrique . $titre} = "1";
$dico_description{$rubrique . $description} = "1";
$nb_itemsOUT++;
#------------------------------------------
# faire l'etiquetage
my $titre_tagged = &treetagger($titre);
my $description_tagged = &treetagger($description);
open(LOG, ">>", "log_bao2.txt");
if(exists $dico_files{$file}){
$count_file = int($dico_files{$file});
$count_file++;
%dico_files = ($file => $count_file);
} else {
%dico_files = ($file => 1);
}
#creer l`objet date pour ecrire les dates dans le log
my $date_time = ctime();
#ecrire le fichier de log avec le nom du fichier et l`heure de lecture
print LOG $file." ".$dico_files{$file}."\t\t read on ".$date_time."\n";
# mettre dans les sorties xml
if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML)) {
die "Problème a l'ouverture du fichier $cheminXML : $!\n";
}
print FILEOUT "<item>\n";
print FILEOUT "<titre>" . $titre . "</titre>\n<description>" . $description . "</description>\n";
print FILEOUT "</item>\n";
close(FILEOUT);
#----------------------------------------------
# créer un dump pour chaque rubrique
${"DumpXML" . $rubrique} .= "<item>\n<titre>" . $titre . "</titre>\n<description>" . $description . "</description>\n</item>\n";
#----------------------------------------------
# partie de sorties txt
my $cheminTXT = $res . $rubrique . ".txt";
# si on n'a pas encore vu la rubrique
if (! -e $cheminTXT) {
if (!open (FILEGLOBALTXT,">>:encoding(iso-8859-15)",$cheminTXT)) {
die "Problème a l'ouverture du fichier $cheminTXT : $!\n";
}
# écrire dans le sortie txt
print FILEGLOBALTXT "$titre." . " $description.\n";
close(FILEGLOBALTXT);
}
# si on a déjà vu la rubrique
else {
if (!open (FILEGLOBALTXT,">>:encoding(iso-8859-15)",$cheminTXT)) {
die "Problème a l'ouverture du fichier $cheminTXT : $!\n";
}
# écrire dans le sortie txt
print FILEGLOBALTXT "$titre." . " $description.";
close(FILEGLOBALTXT);
}
if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML_BAO2)) {
die "Problème a l'ouverture du fichier $cheminXML_BAO2 : $!\n";
}
print FILEOUT "<item>\n";
print FILEOUT "<titre>".$titre_tagged."</titre>\n<description>".$description_tagged."</description>\n";
print FILEOUT "</item>\n";
close(FILEOUT);
# créer un dump pour chaque rubrique
${"DumpXML2_Tagged".$rubrique}.="<item>\n<titre>".$titre_tagged."</titre>\n<description>".$description_tagged."</description>\n</item>\n";
}
}
}
# fermer la balise file pour chaque fichier xml
if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML))
{
die "Problème a l'ouverture du fichier .$cheminXML : $!\n";
}
print FILEOUT "</items>";
print FILEOUT "</file>";
close(FILEOUT);
# fermer la balise les fichier xml etiqutée
if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML_BAO2)) {
die "Problème a l'ouverture du fichier .$cheminXML_BAO2 : $!\n";
}
print FILEOUT "</items>";
print FILEOUT "</file>";
close(FILEOUT);
}
}
}
}
}
#------------------------------------------------------------------------------
# subroutine pour nettoyer le texte
#------------------------------------------------------------------------------
sub nettoyerTexte {
my $tx = $_[0];
$tx =~ s/&/&/g;
$tx =~ s/&/&/g;
$tx =~ s/"/"/g;
$tx =~ s/"/"/g;
$tx =~ s/'/'/g;
$tx =~ s/'/'/g;
$tx =~ s/</</g;
$tx =~ s/</</g;
$tx =~ s/>/>/g;
$tx =~ s/>/>/g;
$tx =~ s/ //g;
$tx =~ s/ //g;
$tx =~ s/£/£/g;
$tx =~ s/£/£/g;
$tx =~ s/©/©/g;
$tx =~ s/«/«/g;
$tx =~ s/«/«/g;
$tx =~ s/»/»/g;
$tx =~ s/»//g;
$tx =~ s/É/É/g;
$tx =~ s/É/É/g;
$tx =~ s/í/î/g;
$tx =~ s/î/î/g;
$tx =~ s/ï/ï/g;
$tx =~ s/ï/ï/g;
$tx =~ s/à/à/g;
$tx =~ s/à/à/g;
$tx =~ s/â/â/g;
$tx =~ s/â/â/g;
$tx =~ s/ç/ç/g;
$tx =~ s/ç/ç/g;
$tx =~ s/è/è/g;
$tx =~ s/è/è/g;
$tx =~ s/é/é/g;
$tx =~ s/é/é/g;
$tx =~ s/ê/ê/g;
$tx =~ s/ê/ê/g;
$tx =~ s/ô/ô/g;
$tx =~ s/ô/ô/g;
$tx =~ s/û/û/g;
$tx =~ s/û/û/g;
$tx =~ s/ü/ü/g;
$tx =~ s/ü/ü/g;
$tx =~ s/\x9c/œ/g;
$tx =~ s/<br\/\>//g;
$tx =~ s/<img.*?\/>//g;
$tx =~ s/<.+?>//sg;
$tx =~ s/<a.*?>.*?<\/a>//g;
$tx =~ s/<![CDATA[(.*?)]]>/$1/g;
$tx =~ s/<[^>]>//g;
$tx =~ s/\.$//;
$tx =~ s/&/et/g;
return $tx;
}
#------------------------------------------------------------------------------
# subroutine pour nettoyer des rubriques
#------------------------------------------------------------------------------
sub nettoyerRubriques {
my $rubrique = shift;
$rubrique =~ s/Le Monde.fr//g;
$rubrique =~ s/LeMonde.fr//g;
$rubrique =~ s/: Toute l'actualité sur//g;
$rubrique =~ s/É/e/g;
$rubrique =~ s/é/e/g;
$rubrique =~ s/è/e/g;
$rubrique =~ s/ê/a/g;
$rubrique =~ s/ë/e/g;
$rubrique =~ s/ï/i/g;
$rubrique =~ s/î/i/g;
$rubrique =~ s/à/a/g;
$rubrique =~ s/ô/o/g;
$rubrique =~ s/,/_/g;
$rubrique = uc($rubrique);
$rubrique =~ s/ //g;
$rubrique =~ s/[\.\:;\'\"\-]+//g;
return $rubrique;
}
#------------------------------------------------------------------------------
# subroutine pour le tokenisation et etiquetage
#------------------------------------------------------------------------------
sub treetagger {
my $texte = shift;
my $temptag;
# créer un fichier temporaire pour tagger des morceaux de texte
open($temptag, ">:encoding(UTF-8)", "./temptag.txt");
print $temptag $texte;
close($temptag);
system("perl tokenise-utf8.pl ./temptag.txt | /home/alexandre/tree-tagger/bin/tree-tagger -lemma -token -no-unknown -sgml /home/alexandre/tree-tagger/models/french.par > treetagger.txt");
system("perl ./treetagger2xml-utf8.pl treetagger.txt utf-8");
open(TaggedOUT,"<:encoding(utf-8)","treetagger.txt.xml");
my $tagged_text = "";
#lire la ligne d'en tête du fichier xml étiqueté, pour éviter que cette
# ligne soit inclue dans le nouveau fichier xml
my $line_den_tete = <TaggedOUT>;
while (my $l = <TaggedOUT>) {
$tagged_text .= $l;
}
close(TaggedOUT);
return $tagged_text;
}
# fin des subroutines
#------------------------------------------------------------------------------
#------------------------------------------------------------------------------Perl modules
We wrote scripts in Perl using the two modules : XML ::Entities and HTML::Entities. One of the scripts using these modules is for Tool 1 and the other is for Tool 2.
For this version using modules for Tool 2, we use the same system as was used in Tool 1 for cleaning the XML files after having decoded the XML and HTML entities.
Once again, this is where we include the modules:
And this is where they are used:
- #!/usr/bin/perl -w
- <<DOC;
- Votre Nom : Bienvenue, Poadey, Cavalcante
- MARS 2015
- usage : perl parcours-arborescence-fichiers repertoire-a-parcourir
- Le programme prend en entrée le nom du répertoire contenant les fichiers
- à traiter
- Le programme construit en sortie un fichier structuré contenant sur chaque
- ligne le nom du fichier et le résultat du filtrage :
- <FICHIER><NOM>du fichier</NOM></FICHIER><CONTENU>du filtrage</CONTENU></FICHIER>
- DOC
- use Unicode::String qw(utf8);
- use utf8;
- use Time::localtime;
- use XML::Entities;
- use HTML::Entities;
- #------------------------------------------------------------------------------
- # des compteurs pour le nombre des items
- my $nb_filesIN = 0;
- my $nb_itemsIN = 0;
- my $nb_itemsOUT = 0;
- #------------------------------------------------------------------------------
- # le répertoire d'entrée contenant les fichiers xml
- my $rep = "$ARGV[0]";
- # regex enlever le slash à la fin du nom du répertoire
- $rep =~ s/[\/]$//;
- #------------------------------------------------------------------------------
- # des hash tables pour vérifier qu'on n'a pas deux fois les même infos
- my %dicoTitre = ();
- my %dicoDescription = ();
- # cet hash controle le nombre de fois que le fichier a ete lu pour ecrire le fichier de log
- my %dico_files = ();
- #creer l`objet date pour ecire la date et l'heure de lecture des fichiers xml dans le fichier de log
- my $date_time = ctime();
- #------------------------------------------------------------------------------
- # creation des dossiers de sortie
- my $res = "../Sorties/";
- if (! -e $res) {
- mkdir($res) or die ("Problème avec la création du répertoire de $rep : $!");
- }
- $res = "../Sorties/1_Sorties_PurePerl/";
- if (! -e $res) {
- mkdir($res) or die ("Problème avec la création du répertoire de $rep : $!\n");
- }
- #------------------------------------------------------------------------------
- # sorties etiquetées
- my $resBAO2 = "../Sorties/2_Sorties_Etiquetees/";
- if (! -e $resBAO2) {
- mkdir($resBAO2) or die ("Problème avec la création du répertoire de $rep : $!\n");
- }
- #------------------------------------------------------------------------------
- # sortie globale txt
- open(FILEGLOBALTXT,">:encoding(UTF-8)", $res."1_SortieGlobale.txt");
- #------------------------------------------------------------------------------
- &parcoursarborescencefichiers($rep); #recurse!
- #------------------------------------------------------------------------------
- close FILEGLOBALTXT;
- #------------------------------------------------------------------------------
- # création de la sortie globale xml
- open(FILEGLOBALXML, ">:encoding(UTF-8)", $res."1_SortieGlobale.xml");
- print FILEGLOBALXML "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
- print FILEGLOBALXML "<PARCOURS>\n";
- print FILEGLOBALXML "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
- print FILEGLOBALXML "<FILTRAGE>";
- #------------------------------------------------------------------------------
- # écrire contenu de la sortie globale xml
- opendir(DIR, $res) or die "Erreur d'ouverture du repertoire: $!\n";
- my @sorties = readdir(DIR);
- closedir(DIR);
- foreach my $sortie (@sorties) {
- if ($sortie=~/(.+?)\.xml$/ && $1 != "1_SortieGlobale") {
- my $rub=$1;
- open(FILE,">>:encoding(UTF-8)", $res.$sortie);
- print FILE "</".$rub.">\n";;
- print FILE "</PARCOURS>\n";
- close(FILE);
- print FILEGLOBALXML "<$rub>\n";
- print FILEGLOBALXML ${"DumpXML".$rub};
- print FILEGLOBALXML "</$rub>";
- }
- }
- print FILEGLOBALXML "</FILTRAGE>\n";
- print FILEGLOBALXML "</PARCOURS>\n";
- close(FILEGLOBALXML);
- #------------------------------------------------------------------------------
- open(FILEGLOBALXML, ">:encoding(UTF-8)", $resBAO2."2_SortieGlobale.xml");
- print FILEGLOBALXML "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
- print FILEGLOBALXML "<PARCOURS>\n";
- print FILEGLOBALXML "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
- print FILEGLOBALXML "<FILTRAGE>";
- #------------------------------------------------------------------------------
- opendir(DIR, $resBAO2) or die "Erreur d'ouverture de repertoire: $!\n";
- @sorties = readdir(DIR);
- closedir(DIR);
- foreach my $sortie (@sorties) {
- # se fait sur chaque sortie xml dans chaque rubrique
- if ($sortie=~/(.+?)\.xml$/ && $1 != "2_SortieGlobale") {
- my $rub = $1;
- open(FILE,">>:encoding(UTF-8)", $resBAO2.$sortie);
- print FILE "</".$rub.">\n";;
- print FILE "</PARCOURS>\n";
- close FILE;
- print FILEGLOBALXML "<$rub>\n";
- print FILEGLOBALXML ${"DumpXML2_Tagged".$rub};
- print FILEGLOBALXML "</$rub>";
- }
- }
- #------------------------------------------------------------------------------
- print FILEGLOBALXML "</FILTRAGE>\n";
- print FILEGLOBALXML "</PARCOURS>\n";
- close(FILEGLOBALXML);
- #------------------------------------------------------------------------------
- # imprime le nombre des infos à la fin du programme
- print "\n" . "nbr files IN = $nb_filesIN\n";
- print "nbr items IN = $nb_itemsIN\n";
- print "nbr items OUT = $nb_itemsOUT\n";
- print "fin du programme.\n";
- exit;
- # fin du main programme
- #------------------------------------------------------------------------------
- #------------------------------------------------------------------------------
- # commencement des subroutines
- #------------------------------------------------------------------------------
- # subroutine pour parcourir l'aborescence
- sub parcoursarborescencefichiers {
- my $path = shift(@_); # chemin vers le dossier en entrée
- opendir(DIR, $path) or die "Probleme d'ouverture du dossier: $!\n";
- my @files = readdir(DIR);
- closedir(DIR);
- #------------------------------------------------------------------------------
- foreach my $file (@files) {
- next if $file =~ /^\.\.?$/; #si . ou ..
- $file = $path."/".$file;
- #si $file est un dossier
- if (-d $file) {
- &parcoursarborescencefichiers($file); #recurse!
- }
- # faire le traitement si $file est un fichier
- if (-f $file) {
- # traiter les fichiers xml seulement
- if ($file=~/^[^(fil)]+?\.xml$/) {
- $nb_filesIN++;
- print $file,"\n";
- #lire le fichier xml
- open(FILE,$file);
- my $firstLine = <FILE>;
- my $encodage = "";
- #vérifier encodage du fichier xml
- if($firstLine =~ /encoding= ?['"]([^\'"]+)['"]/) {
- $encodage = $1; #extraire l'encodage
- }
- close(FILE);
- # si on trouve l'encodage, le fichier est reouvert avec l'encodage correcte
- if (!($encodage eq "")) {
- open(FILE,"<:encoding($encodage)",$file);
- my $texte = "";
- #éliminer les retours à ligne dans le fichier [ \n et \r ]
- while (my $ligne = <FILE>) {
- $ligne =~ s/\n//g;
- $ligne =~ s/\r//g;
- $texte .= $ligne;
- }
- close FILE;
- $texte =~ s/> *?</></g; # coller les balises
- #------------------------------------------------------------------------------
- # extraire rubrique, date et nom
- $texte =~ /<channel>.*?<title>(.*?)<\/title>.*?<pubDate>(.+?)<\/pubDate>.*?<\/channel>/;
- # nettoyer les rubriques
- my $rubrique = &nettoyerRubriques($1);
- print "RUBRIQUE : $rubrique\n";
- # extraire la date
- my $date = &nettoyerRubriques($2);
- # nom du fichier
- my $name = $file;
- # uniquement les fichiers XML contenant les mises à jour
- $name =~ s/.*?(20.*)/$1/;
- #------------------------------------------------------------------------------
- # ouvre des balises et écrire dans des fichiers de sortie
- my $cheminXML=$res.$rubrique.".xml";
- # si on n'a pas encore vu le rubrique on doit le créer
- if (! -e $cheminXML) {
- # créer un fichier
- if (!open (FILEOUT,">:encoding(UTF-8)",$cheminXML)) {
- die "Probleme a la creation du fichier $cheminXML : $!";
- }
- # ouverture des balises XML du début du fichier
- print FILEOUT "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
- print FILEOUT "<PARCOURS>\n";
- print FILEOUT "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
- print FILEOUT "<$rubrique>\n";
- print FILEOUT "<file>";
- print FILEOUT "<name>$name</name>";
- print FILEOUT "<date>$date</date>";
- print FILEOUT "<items>";
- close(FILEOUT);
- ${"DumpXML"."$rubrique"}="";
- }
- # si le fichier existe déjà
- else {
- if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML)) {
- die "Problème a l'ouverture du fichier $cheminXML : $!\n";
- }
- print FILEOUT "<file>";
- print FILEOUT "<name>$name</name>";
- print FILEOUT "<date>$date</date>";
- print FILEOUT "<items>";
- close(FILEOUT);
- }
- #------------------------------------------------------------------------------
- my $cheminXML_BAO2=$resBAO2.$rubrique.".xml";
- # si on n'a pas encore vu le rubrique
- if (! -e $cheminXML_BAO2) {
- # créer un fichier
- if (!open (FILEOUT,">:encoding(UTF-8)",$cheminXML_BAO2)) {
- die "Probleme a la creation du fichier $cheminXML_BAO2 : $!\n";
- }
- # ouverture des balises XML du début du fichier
- print FILEOUT "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
- print FILEOUT "<PARCOURS>\n";
- print FILEOUT "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
- print FILEOUT "<$rubrique>\n";
- print FILEOUT "<file>";
- print FILEOUT "<name>$name</name>";
- print FILEOUT "<date>$date</date>";
- print FILEOUT "<items>";
- close(FILEOUT);
- ${"DumpXML_tagged"."$rubrique"}="";
- }
- # si le fichier existe déjà
- else {
- if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML_BAO2)) {
- die "Problème a l'ouverture du fichier $cheminXML_BAO2 : $!\n";
- }
- print FILEOUT "<file>";
- print FILEOUT "<name>$file</name>";
- print FILEOUT "<date>$date</date>";
- print FILEOUT "<items>";
- close(FILEOUT);
- }
- #------------------------------------------------------------------------------
- # extractions des titres et descriptions
- while ($texte =~ /<item>.*?<title>(.*?)<\/title>.*?<description>(.*?)<\/description>/g)
- {
- my $titre = $1;
- my $description = $2;
- $nb_itemsIN++;
- #------------------------------------------------------------------------------
- # nettoyer le texte
- if (!(exists ($dicoTitre{$titre})) and !(exists ($dicoDescription{$description})))
- {
- $dicoTitre{$titre}++;
- $dicoDescription{$description}++;
- $titre = XML::Entities::decode('all', $titre);
- $descritpion = XML::Entities::decode('all', $description);
- $titre = HTML::Entities::decode($titre);
- $description = HTML::Entities::decode($description);
- $tmptexteBRUT.="$titre \n";
- $tmptexteBRUT.="$description \n";
- $tmptexteXML.="<item><title>$titre</title><description>$description</description></item>\n";
- #--------------------------------------------------------------------------------------
- # nettoyage des balises <description> pour supprimer les balises superflues
- $tmptexteXML =~ s/<img.*?\/><\/description>/<\/description>/g;
- $tmptexteBRUT =~ s/<img.*?\/> \n/\n/g;
- }
- if (!(($titre eq "") or ($description eq ""))) {
- #------------------------------------------------------------------------------
- # convertir si besoin en utf-8
- if (uc($encodage) ne "UTF-8") {
- utf8($titre);
- utf8($description);
- }
- #------------------------------------------------------------------------------
- # regarde si on a déjà vu le texte
- if (!((exists $dicoTitre{$rubrique . $titre}) && (exists $dicoDescription{$rubrique . $description})))
- {
- $dicoTitre{$rubrique . $titre} = "1";
- $dicoDescription{$rubrique . $description} = "1";
- $nb_itemsOUT++;
- #------------------------------------------------------------------------------
- # faire l'etiquetage
- my $titre_tagged = &treetagger($titre);
- my $description_tagged = &treetagger($description);
- open(LOG, ">>", "log_bao2.txt");
- if(exists $dico_files{$file}){
- $count_file = int($dico_files{$file});
- $count_file++;
- %dico_files = ($file => $count_file);
- } else {
- %dico_files = ($file => 1);
- }
- #creer l`objet date pour ecire les date dans le fichier de log
- my $date_time = ctime();
- #ecrire le fichier de log avec le nom du fichier et l`heure de lecture
- print LOG $file." ".$dico_files{$file}."\t\t read on ".$date_time."\n";
- # mettre dans les sorties xml
- if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML)) {
- die "Problème a l'ouverture du fichier $cheminXML : $!\n";
- }
- print FILEOUT "<item>\n";
- print FILEOUT $tmptexteXML;
- print FILEOUT "</item>\n";
- close(FILEOUT);
- #------------------------------------------------------------------------------
- # créer un dump pour chaque rubrique
- ${"DumpXML" . $rubrique} .= $tmptexteXML."\n";
- #------------------------------------------------------------------------------
- # partie de sorties txt
- my $cheminTXT = $res . $rubrique . ".txt";
- # si on n'a pas encore vu la rubrique
- if (! -e $cheminTXT) {
- if (!open (FILEGLOBALTXT,">:encoding(iso-8859-15)",$cheminTXT)) {
- die "Problème a l'ouverture du fichier $cheminTXT : $!\n";
- }
- # écrire dans le sortie txt
- print FILEGLOBALTXT $tmptexteBRUT;
- close(FILEGLOBALTXT);
- }
- # si on a déjà vu la rubrique
- else {
- if (!open (FILEGLOBALTXT,">>:encoding(iso-8859-15)",$cheminTXT)) {
- die "Problème a l'ouverture du fichier $cheminTXT : $!\n";
- }
- # écrire dans la sortie txt
- print FILEGLOBALTXT $tmptexteBRUT;
- close(FILEGLOBALTXT);
- }
- if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML_BAO2)) {
- die "Problème a l'ouverture du fichier $cheminXML_BAO2 : $!\n";
- }
- print FILEOUT "<item>\n";
- print FILEOUT $tmptexteXML;
- print FILEOUT "</item>\n";
- close(FILEOUT);
- # créer un dump pour chaque rubrique
- ${"DumpXML2_Tagged".$rubrique}.= $tmptexteXML."\n";
- }
- }
- }
- # fermer la balise file pour chaque fichier xml
- if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML))
- {
- die "Problème a l'ouverture du fichier .$cheminXML : $!\n";
- }
- print FILEOUT "</items>";
- print FILEOUT "</file>";
- close(FILEOUT);
- # fermer la balise les fichier xml etiqutée
- if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML_BAO2)) {
- die "Problème a l'ouverture du fichier .$cheminXML_BAO2 : $!\n";
- }
- print FILEOUT "</items>";
- print FILEOUT "</file>";
- close(FILEOUT);
- }
- }
- }
- }
- }
- #------------------------------------------------------------------------------
- # subroutine pour nettoyer des rubriques
- #------------------------------------------------------------------------------
- sub nettoyerRubriques {
- my $rubrique = shift;
- $rubrique =~ s/Le Monde.fr//g;
- $rubrique =~ s/LeMonde.fr//g;
- $rubrique =~ s/: Toute l'actualité sur//g;
- $rubrique =~ s/É/e/g;
- $rubrique =~ s/é/e/g;
- $rubrique =~ s/è/e/g;
- $rubrique =~ s/ê/a/g;
- $rubrique =~ s/ë/e/g;
- $rubrique =~ s/ï/i/g;
- $rubrique =~ s/î/i/g;
- $rubrique =~ s/à/a/g;
- $rubrique =~ s/ô/o/g;
- $rubrique =~ s/,/_/g;
- $rubrique = uc($rubrique);
- $rubrique =~ s/ //g;
- $rubrique =~ s/[\.\:;\'\"\-]+//g;
- return $rubrique;
- }
- #------------------------------------------------------------------------------
- # subroutine pour tokenisation et etiquetage
- #------------------------------------------------------------------------------
- sub treetagger {
- my $texte = shift;
- my $temptag;
- # créer un fichier temporaire pour tagger des morceaux de texte
- open($temptag, ">:encoding(UTF-8)", "./temptag.txt");
- print $temptag $texte;
- close($temptag);
- system("perl tokenise-utf8.pl ./temptag.txt | tree-tagger.exe -lemma -token -no-unknown -sgml ./french.par > treetagger.txt");
- system("perl treetagger2xml-utf8.pl treetagger.txt utf-8");
- open(TaggedOUT,"<:encoding(utf-8)","treetagger.txt.xml");
- my $tagged_text = "";
- #lire la ligne d'en tête du fichier xml étiqueté, pour éviter que cette ligne soit incluse dans le nouveau fichier xml
- my $line_den_tete = <TaggedOUT>;
- while (my $l = <TaggedOUT>) {
- $tagged_text .= $l;
- }
- close(TaggedOUT);
- return $tagged_text;
- }
- # fin des subroutines
- #------------------------------------------------------------------------------
- #------------------------------------------------------------------------------
#!/usr/bin/perl -w
<<DOC;
Votre Nom : Bienvenue, Poadey, Cavalcante
MARS 2015
usage : perl parcours-arborescence-fichiers repertoire-a-parcourir
Le programme prend en entrée le nom du répertoire contenant les fichiers
à traiter
Le programme construit en sortie un fichier structuré contenant sur chaque
ligne le nom du fichier et le résultat du filtrage :
<FICHIER><NOM>du fichier</NOM></FICHIER><CONTENU>du filtrage</CONTENU></FICHIER>
DOC
use Unicode::String qw(utf8);
use utf8;
use Time::localtime;
use XML::Entities;
use HTML::Entities;
#------------------------------------------------------------------------------
# des compteurs pour le nombre des items
my $nb_filesIN = 0;
my $nb_itemsIN = 0;
my $nb_itemsOUT = 0;
#------------------------------------------------------------------------------
# le répertoire d'entrée contenant les fichiers xml
my $rep = "$ARGV[0]";
# regex enlever le slash à la fin du nom du répertoire
$rep =~ s/[\/]$//;
#------------------------------------------------------------------------------
# des hash tables pour vérifier qu'on n'a pas deux fois les même infos
my %dicoTitre = ();
my %dicoDescription = ();
# cet hash controle le nombre de fois que le fichier a ete lu pour ecrire le fichier de log
my %dico_files = ();
#creer l`objet date pour ecire la date et l'heure de lecture des fichiers xml dans le fichier de log
my $date_time = ctime();
#------------------------------------------------------------------------------
# creation des dossiers de sortie
my $res = "../Sorties/";
if (! -e $res) {
mkdir($res) or die ("Problème avec la création du répertoire de $rep : $!");
}
$res = "../Sorties/1_Sorties_PurePerl/";
if (! -e $res) {
mkdir($res) or die ("Problème avec la création du répertoire de $rep : $!\n");
}
#------------------------------------------------------------------------------
# sorties etiquetées
my $resBAO2 = "../Sorties/2_Sorties_Etiquetees/";
if (! -e $resBAO2) {
mkdir($resBAO2) or die ("Problème avec la création du répertoire de $rep : $!\n");
}
#------------------------------------------------------------------------------
# sortie globale txt
open(FILEGLOBALTXT,">:encoding(UTF-8)", $res."1_SortieGlobale.txt");
#------------------------------------------------------------------------------
&parcoursarborescencefichiers($rep); #recurse!
#------------------------------------------------------------------------------
close FILEGLOBALTXT;
#------------------------------------------------------------------------------
# création de la sortie globale xml
open(FILEGLOBALXML, ">:encoding(UTF-8)", $res."1_SortieGlobale.xml");
print FILEGLOBALXML "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print FILEGLOBALXML "<PARCOURS>\n";
print FILEGLOBALXML "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
print FILEGLOBALXML "<FILTRAGE>";
#------------------------------------------------------------------------------
# écrire contenu de la sortie globale xml
opendir(DIR, $res) or die "Erreur d'ouverture du repertoire: $!\n";
my @sorties = readdir(DIR);
closedir(DIR);
foreach my $sortie (@sorties) {
if ($sortie=~/(.+?)\.xml$/ && $1 != "1_SortieGlobale") {
my $rub=$1;
open(FILE,">>:encoding(UTF-8)", $res.$sortie);
print FILE "</".$rub.">\n";;
print FILE "</PARCOURS>\n";
close(FILE);
print FILEGLOBALXML "<$rub>\n";
print FILEGLOBALXML ${"DumpXML".$rub};
print FILEGLOBALXML "</$rub>";
}
}
print FILEGLOBALXML "</FILTRAGE>\n";
print FILEGLOBALXML "</PARCOURS>\n";
close(FILEGLOBALXML);
#------------------------------------------------------------------------------
open(FILEGLOBALXML, ">:encoding(UTF-8)", $resBAO2."2_SortieGlobale.xml");
print FILEGLOBALXML "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print FILEGLOBALXML "<PARCOURS>\n";
print FILEGLOBALXML "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
print FILEGLOBALXML "<FILTRAGE>";
#------------------------------------------------------------------------------
opendir(DIR, $resBAO2) or die "Erreur d'ouverture de repertoire: $!\n";
@sorties = readdir(DIR);
closedir(DIR);
foreach my $sortie (@sorties) {
# se fait sur chaque sortie xml dans chaque rubrique
if ($sortie=~/(.+?)\.xml$/ && $1 != "2_SortieGlobale") {
my $rub = $1;
open(FILE,">>:encoding(UTF-8)", $resBAO2.$sortie);
print FILE "</".$rub.">\n";;
print FILE "</PARCOURS>\n";
close FILE;
print FILEGLOBALXML "<$rub>\n";
print FILEGLOBALXML ${"DumpXML2_Tagged".$rub};
print FILEGLOBALXML "</$rub>";
}
}
#------------------------------------------------------------------------------
print FILEGLOBALXML "</FILTRAGE>\n";
print FILEGLOBALXML "</PARCOURS>\n";
close(FILEGLOBALXML);
#------------------------------------------------------------------------------
# imprime le nombre des infos à la fin du programme
print "\n" . "nbr files IN = $nb_filesIN\n";
print "nbr items IN = $nb_itemsIN\n";
print "nbr items OUT = $nb_itemsOUT\n";
print "fin du programme.\n";
exit;
# fin du main programme
#------------------------------------------------------------------------------
#------------------------------------------------------------------------------
# commencement des subroutines
#------------------------------------------------------------------------------
# subroutine pour parcourir l'aborescence
sub parcoursarborescencefichiers {
my $path = shift(@_); # chemin vers le dossier en entrée
opendir(DIR, $path) or die "Probleme d'ouverture du dossier: $!\n";
my @files = readdir(DIR);
closedir(DIR);
#------------------------------------------------------------------------------
foreach my $file (@files) {
next if $file =~ /^\.\.?$/; #si . ou ..
$file = $path."/".$file;
#si $file est un dossier
if (-d $file) {
&parcoursarborescencefichiers($file); #recurse!
}
# faire le traitement si $file est un fichier
if (-f $file) {
# traiter les fichiers xml seulement
if ($file=~/^[^(fil)]+?\.xml$/) {
$nb_filesIN++;
print $file,"\n";
#lire le fichier xml
open(FILE,$file);
my $firstLine = <FILE>;
my $encodage = "";
#vérifier encodage du fichier xml
if($firstLine =~ /encoding= ?['"]([^\'"]+)['"]/) {
$encodage = $1; #extraire l'encodage
}
close(FILE);
# si on trouve l'encodage, le fichier est reouvert avec l'encodage correcte
if (!($encodage eq "")) {
open(FILE,"<:encoding($encodage)",$file);
my $texte = "";
#éliminer les retours à ligne dans le fichier [ \n et \r ]
while (my $ligne = <FILE>) {
$ligne =~ s/\n//g;
$ligne =~ s/\r//g;
$texte .= $ligne;
}
close FILE;
$texte =~ s/> *?</></g; # coller les balises
#------------------------------------------------------------------------------
# extraire rubrique, date et nom
$texte =~ /<channel>.*?<title>(.*?)<\/title>.*?<pubDate>(.+?)<\/pubDate>.*?<\/channel>/;
# nettoyer les rubriques
my $rubrique = &nettoyerRubriques($1);
print "RUBRIQUE : $rubrique\n";
# extraire la date
my $date = &nettoyerRubriques($2);
# nom du fichier
my $name = $file;
# uniquement les fichiers XML contenant les mises à jour
$name =~ s/.*?(20.*)/$1/;
#------------------------------------------------------------------------------
# ouvre des balises et écrire dans des fichiers de sortie
my $cheminXML=$res.$rubrique.".xml";
# si on n'a pas encore vu le rubrique on doit le créer
if (! -e $cheminXML) {
# créer un fichier
if (!open (FILEOUT,">:encoding(UTF-8)",$cheminXML)) {
die "Probleme a la creation du fichier $cheminXML : $!";
}
# ouverture des balises XML du début du fichier
print FILEOUT "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print FILEOUT "<PARCOURS>\n";
print FILEOUT "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
print FILEOUT "<$rubrique>\n";
print FILEOUT "<file>";
print FILEOUT "<name>$name</name>";
print FILEOUT "<date>$date</date>";
print FILEOUT "<items>";
close(FILEOUT);
${"DumpXML"."$rubrique"}="";
}
# si le fichier existe déjà
else {
if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML)) {
die "Problème a l'ouverture du fichier $cheminXML : $!\n";
}
print FILEOUT "<file>";
print FILEOUT "<name>$name</name>";
print FILEOUT "<date>$date</date>";
print FILEOUT "<items>";
close(FILEOUT);
}
#------------------------------------------------------------------------------
my $cheminXML_BAO2=$resBAO2.$rubrique.".xml";
# si on n'a pas encore vu le rubrique
if (! -e $cheminXML_BAO2) {
# créer un fichier
if (!open (FILEOUT,">:encoding(UTF-8)",$cheminXML_BAO2)) {
die "Probleme a la creation du fichier $cheminXML_BAO2 : $!\n";
}
# ouverture des balises XML du début du fichier
print FILEOUT "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print FILEOUT "<PARCOURS>\n";
print FILEOUT "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
print FILEOUT "<$rubrique>\n";
print FILEOUT "<file>";
print FILEOUT "<name>$name</name>";
print FILEOUT "<date>$date</date>";
print FILEOUT "<items>";
close(FILEOUT);
${"DumpXML_tagged"."$rubrique"}="";
}
# si le fichier existe déjà
else {
if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML_BAO2)) {
die "Problème a l'ouverture du fichier $cheminXML_BAO2 : $!\n";
}
print FILEOUT "<file>";
print FILEOUT "<name>$file</name>";
print FILEOUT "<date>$date</date>";
print FILEOUT "<items>";
close(FILEOUT);
}
#------------------------------------------------------------------------------
# extractions des titres et descriptions
while ($texte =~ /<item>.*?<title>(.*?)<\/title>.*?<description>(.*?)<\/description>/g)
{
my $titre = $1;
my $description = $2;
$nb_itemsIN++;
#------------------------------------------------------------------------------
# nettoyer le texte
if (!(exists ($dicoTitre{$titre})) and !(exists ($dicoDescription{$description})))
{
$dicoTitre{$titre}++;
$dicoDescription{$description}++;
$titre = XML::Entities::decode('all', $titre);
$descritpion = XML::Entities::decode('all', $description);
$titre = HTML::Entities::decode($titre);
$description = HTML::Entities::decode($description);
$tmptexteBRUT.="$titre \n";
$tmptexteBRUT.="$description \n";
$tmptexteXML.="<item><title>$titre</title><description>$description</description></item>\n";
#--------------------------------------------------------------------------------------
# nettoyage des balises <description> pour supprimer les balises superflues
$tmptexteXML =~ s/<img.*?\/><\/description>/<\/description>/g;
$tmptexteBRUT =~ s/<img.*?\/> \n/\n/g;
}
if (!(($titre eq "") or ($description eq ""))) {
#------------------------------------------------------------------------------
# convertir si besoin en utf-8
if (uc($encodage) ne "UTF-8") {
utf8($titre);
utf8($description);
}
#------------------------------------------------------------------------------
# regarde si on a déjà vu le texte
if (!((exists $dicoTitre{$rubrique . $titre}) && (exists $dicoDescription{$rubrique . $description})))
{
$dicoTitre{$rubrique . $titre} = "1";
$dicoDescription{$rubrique . $description} = "1";
$nb_itemsOUT++;
#------------------------------------------------------------------------------
# faire l'etiquetage
my $titre_tagged = &treetagger($titre);
my $description_tagged = &treetagger($description);
open(LOG, ">>", "log_bao2.txt");
if(exists $dico_files{$file}){
$count_file = int($dico_files{$file});
$count_file++;
%dico_files = ($file => $count_file);
} else {
%dico_files = ($file => 1);
}
#creer l`objet date pour ecire les date dans le fichier de log
my $date_time = ctime();
#ecrire le fichier de log avec le nom du fichier et l`heure de lecture
print LOG $file." ".$dico_files{$file}."\t\t read on ".$date_time."\n";
# mettre dans les sorties xml
if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML)) {
die "Problème a l'ouverture du fichier $cheminXML : $!\n";
}
print FILEOUT "<item>\n";
print FILEOUT $tmptexteXML;
print FILEOUT "</item>\n";
close(FILEOUT);
#------------------------------------------------------------------------------
# créer un dump pour chaque rubrique
${"DumpXML" . $rubrique} .= $tmptexteXML."\n";
#------------------------------------------------------------------------------
# partie de sorties txt
my $cheminTXT = $res . $rubrique . ".txt";
# si on n'a pas encore vu la rubrique
if (! -e $cheminTXT) {
if (!open (FILEGLOBALTXT,">:encoding(iso-8859-15)",$cheminTXT)) {
die "Problème a l'ouverture du fichier $cheminTXT : $!\n";
}
# écrire dans le sortie txt
print FILEGLOBALTXT $tmptexteBRUT;
close(FILEGLOBALTXT);
}
# si on a déjà vu la rubrique
else {
if (!open (FILEGLOBALTXT,">>:encoding(iso-8859-15)",$cheminTXT)) {
die "Problème a l'ouverture du fichier $cheminTXT : $!\n";
}
# écrire dans la sortie txt
print FILEGLOBALTXT $tmptexteBRUT;
close(FILEGLOBALTXT);
}
if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML_BAO2)) {
die "Problème a l'ouverture du fichier $cheminXML_BAO2 : $!\n";
}
print FILEOUT "<item>\n";
print FILEOUT $tmptexteXML;
print FILEOUT "</item>\n";
close(FILEOUT);
# créer un dump pour chaque rubrique
${"DumpXML2_Tagged".$rubrique}.= $tmptexteXML."\n";
}
}
}
# fermer la balise file pour chaque fichier xml
if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML))
{
die "Problème a l'ouverture du fichier .$cheminXML : $!\n";
}
print FILEOUT "</items>";
print FILEOUT "</file>";
close(FILEOUT);
# fermer la balise les fichier xml etiqutée
if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML_BAO2)) {
die "Problème a l'ouverture du fichier .$cheminXML_BAO2 : $!\n";
}
print FILEOUT "</items>";
print FILEOUT "</file>";
close(FILEOUT);
}
}
}
}
}
#------------------------------------------------------------------------------
# subroutine pour nettoyer des rubriques
#------------------------------------------------------------------------------
sub nettoyerRubriques {
my $rubrique = shift;
$rubrique =~ s/Le Monde.fr//g;
$rubrique =~ s/LeMonde.fr//g;
$rubrique =~ s/: Toute l'actualité sur//g;
$rubrique =~ s/É/e/g;
$rubrique =~ s/é/e/g;
$rubrique =~ s/è/e/g;
$rubrique =~ s/ê/a/g;
$rubrique =~ s/ë/e/g;
$rubrique =~ s/ï/i/g;
$rubrique =~ s/î/i/g;
$rubrique =~ s/à/a/g;
$rubrique =~ s/ô/o/g;
$rubrique =~ s/,/_/g;
$rubrique = uc($rubrique);
$rubrique =~ s/ //g;
$rubrique =~ s/[\.\:;\'\"\-]+//g;
return $rubrique;
}
#------------------------------------------------------------------------------
# subroutine pour tokenisation et etiquetage
#------------------------------------------------------------------------------
sub treetagger {
my $texte = shift;
my $temptag;
# créer un fichier temporaire pour tagger des morceaux de texte
open($temptag, ">:encoding(UTF-8)", "./temptag.txt");
print $temptag $texte;
close($temptag);
system("perl tokenise-utf8.pl ./temptag.txt | tree-tagger.exe -lemma -token -no-unknown -sgml ./french.par > treetagger.txt");
system("perl treetagger2xml-utf8.pl treetagger.txt utf-8");
open(TaggedOUT,"<:encoding(utf-8)","treetagger.txt.xml");
my $tagged_text = "";
#lire la ligne d'en tête du fichier xml étiqueté, pour éviter que cette ligne soit incluse dans le nouveau fichier xml
my $line_den_tete = <TaggedOUT>;
while (my $l = <TaggedOUT>) {
$tagged_text .= $l;
}
close(TaggedOUT);
return $tagged_text;
}
# fin des subroutines
#------------------------------------------------------------------------------
#------------------------------------------------------------------------------
A sample of results from Tool 2
The results from Tool 2 take many forms: .xml, .txt, and .cnr (Cordial's output)
An example of TreeTagger's output in XML format.
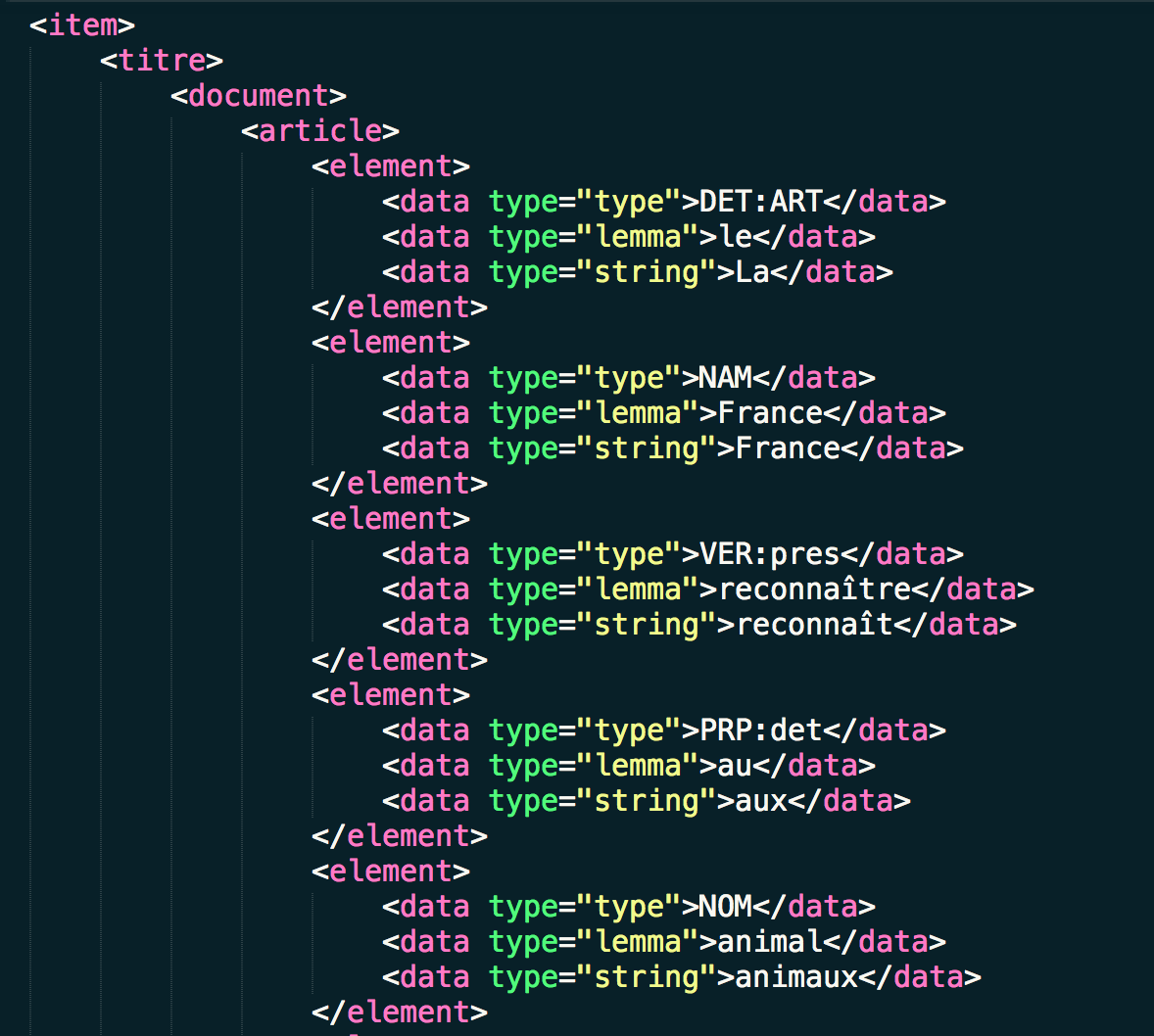
An example of the TXT output (Same as from Tool 1)
An example of Cordials's output in CNR format.

What does Tool 3 do?
Tool 3 is composed of two* different scripts, one for each output from TreeTagger and Cordial. The programs search within the outputs for specified morphosyntactic patterns (e.g.: noun-preposition-noun).
A recap of the results that Tool 3 is working with:
An example of TreeTagger's output
An example of Cordials's output
For this program, we consider many different approaches. Some of the programs written require an external TXT file containing the morphosyntactic patterns we're searching for and some have them built directly into the script. In our final versions you can see that we went with the first option. Our reasoning was that having the patterns in an external file makes it much easier to modify what we're looking for without going through to rewrite sections of code.
This section also contains two XSL files that contain no Perl but achieve the same or a very similar result as the other Perl scripts. XSL stands for Extensible Stylesheet Language. The two files we have are stylesheets for our XML files that allow us to display the elements contained within the desired tags.
Our basic script algorithm looks at each item in the third column (the part-of-speech) and decided whether or not matches the first item in our desired pattern. If no, it continues to the next item in the file. If yes, if continues to try to match the next item in the file to the next item in our pattern until we have no more items in our pattern. If it successfully matches until the end of the pattern, the first column in the file (associated to the third column of matched items), is extracted and considered a "match". A basic diagram, read from left to right and up to down, illustrating this procedure is found below.
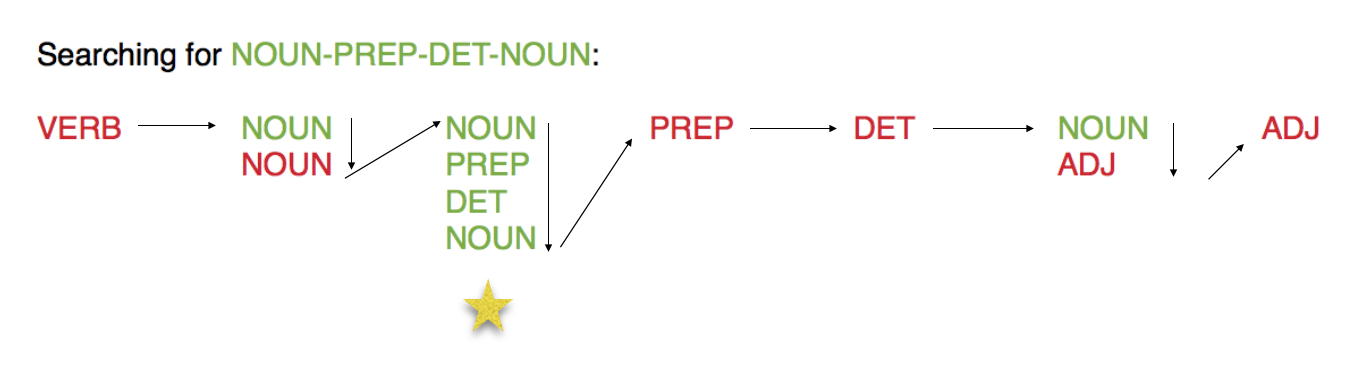
*We could probably write a single script that would treat both cases but in this case it's better to have two and keep things separate and clean. Nevertheless, the scripts are very similar.
Three professors' methods for extracting morphosyntactic sequences from the Cordial and TreeTagger results
Extract morphosyntactic sequences from the Cordial results
- #!/usr/bin/perl
- <<DOC;
- prend en entrée un fichier issu de treetagger
- et un fichier de patrons morphosyntaxiques et
- extrait suites de tokens correspondant aux patrons morpho-syntaxiques
- DOC
- open(FIC, $ARGV[0]) or die "impossible ouvrir $ARGV[0] : $!";
- print "choisis nom de fichier pour contenir termes extraits\n";
- my $fic=<STDIN>;
- open(FIC1, ">$fic");
- my $i=0;
- my $j=0;
- my $k=0;
- my @token=();
- while (<FIC>)
- {
- my $ligne=$_;
- chomp $ligne;
- my @liste=split(/\t/,$ligne);
- push(@token, $liste[$i++]." ");
- push(@lemme, "$liste[$i++]" ." ");
- push(@patron, "$liste[$i++]" ." ");
- $i=0;
- }
- #on a 3 listes @token, @lemme, @patron
- @sous_patron=();
- while (defined($element_patron=shift(@patron)))
- {
- $element_patron=~s/\n//;
- if ($element_patron !~ "PCTFORTE")
- {
- push(@sous_patron, $element_patron);
- $j++;
- next;
- }
- my @sous_token=@token[$k..$j-1];
- &cherche_patron(@sous_patron);
- @sous_patron=();
- $k=$j+1;
- #print "tape return pour continuer";
- #my $reponse=<STDIN>;
- $j++;
- }
- #=============================================
- sub cherche_patron
- {
- my @liste=@_;
- my $suite_de_patrons=join("",@liste);
- $z=0;
- $nb=0;
- open(FIC, "$ARGV[1]");
- while(<FIC>)
- {
- $nb=0;
- $ligne=$_;
- chomp $ligne;
- #print "voici le patron traité : $ligne\n";
- while ($ligne=~m/ /g) {$nb++};
- $nb++;
- while ($suite_de_patrons=~m/$ligne/g)
- {
- my $avant=substr ($suite_de_patrons, 0, pos($suite_de_patrons)-length($&));
- while ($avant=~m/ /g) {$z++};
- print FIC1 "@token[$k+$z..$k+$z+$nb-1]\n";
- #print "tape sur return pour continuer\n";
- #my $reponse=<STDIN>;
- $z=0;
- }
- }
- }
#!/usr/bin/perl
<<DOC;
prend en entrée un fichier issu de treetagger
et un fichier de patrons morphosyntaxiques et
extrait suites de tokens correspondant aux patrons morpho-syntaxiques
DOC
open(FIC, $ARGV[0]) or die "impossible ouvrir $ARGV[0] : $!";
print "choisis nom de fichier pour contenir termes extraits\n";
my $fic=<STDIN>;
open(FIC1, ">$fic");
my $i=0;
my $j=0;
my $k=0;
my @token=();
while (<FIC>)
{
my $ligne=$_;
chomp $ligne;
my @liste=split(/\t/,$ligne);
push(@token, $liste[$i++]." ");
push(@lemme, "$liste[$i++]" ." ");
push(@patron, "$liste[$i++]" ." ");
$i=0;
}
#on a 3 listes @token, @lemme, @patron
@sous_patron=();
while (defined($element_patron=shift(@patron)))
{
$element_patron=~s/\n//;
if ($element_patron !~ "PCTFORTE")
{
push(@sous_patron, $element_patron);
$j++;
next;
}
my @sous_token=@token[$k..$j-1];
&cherche_patron(@sous_patron);
@sous_patron=();
$k=$j+1;
#print "tape return pour continuer";
#my $reponse=<STDIN>;
$j++;
}
#=============================================
sub cherche_patron
{
my @liste=@_;
my $suite_de_patrons=join("",@liste);
$z=0;
$nb=0;
open(FIC, "$ARGV[1]");
while(<FIC>)
{
$nb=0;
$ligne=$_;
chomp $ligne;
#print "voici le patron traité : $ligne\n";
while ($ligne=~m/ /g) {$nb++};
$nb++;
while ($suite_de_patrons=~m/$ligne/g)
{
my $avant=substr ($suite_de_patrons, 0, pos($suite_de_patrons)-length($&));
while ($avant=~m/ /g) {$z++};
print FIC1 "@token[$k+$z..$k+$z+$nb-1]\n";
#print "tape sur return pour continuer\n";
#my $reponse=<STDIN>;
$z=0;
}
}
}
Two scripts to extract morphosyntactic sequences from the TreeTagger and Cordial results
This first script extracts all the noun-adjective sequences from the TreeTagger results.
- open(FILE,"$ARGV[0]");
- #--------------------------------------------
- # le patron cherché ici est du type NOM ADJ"
- #--------------------------------------------
- my @lignes = <FILE>;
- close(FILE);
- while (@lignes) {
- my $ligne = shift(@lignes);
- chomp $ligne;
- my $sequence = "";
- my $longueur = 0;
- if ( $ligne =~ /<element><data type=\"type\">NOM<\/data><data type=\"lemma\">[^<]+<\/data><data type=\"string\">([^<]+)<\/data><\/element>/) {
- my $forme = $1;
- $sequence .= $forme;
- $longueur = 1;
- my $nextligne = $lignes[0];
- if ( $nextligne =~ /<element><data type=\"type\">ADJ<\/data><data type=\"lemma\">[^<]+<\/data><data type=\"string\">([^<]+)<\/data><\/element>/) {
- my $forme = $1;
- $sequence .= " " . $forme;
- $longueur = 2;
- }
- }
- if ($longueur == 2) {
- print $sequence . "\n";
- }
- }
open(FILE,"$ARGV[0]");
#--------------------------------------------
# le patron cherché ici est du type NOM ADJ"
#--------------------------------------------
my @lignes = <FILE>;
close(FILE);
while (@lignes) {
my $ligne = shift(@lignes);
chomp $ligne;
my $sequence = "";
my $longueur = 0;
if ( $ligne =~ /<element><data type=\"type\">NOM<\/data><data type=\"lemma\">[^<]+<\/data><data type=\"string\">([^<]+)<\/data><\/element>/) {
my $forme = $1;
$sequence .= $forme;
$longueur = 1;
my $nextligne = $lignes[0];
if ( $nextligne =~ /<element><data type=\"type\">ADJ<\/data><data type=\"lemma\">[^<]+<\/data><data type=\"string\">([^<]+)<\/data><\/element>/) {
my $forme = $1;
$sequence .= " " . $forme;
$longueur = 2;
}
}
if ($longueur == 2) {
print $sequence . "\n";
}
}
This second script extracts all the noun-preposition-noun sequences from the Cordial results.
- open(FILE,"$ARGV[0]");
- #--------------------------------------------
- # le patron cherché ici est du type NOM PREP NOM
- #--------------------------------------------
- my @lignes = <FILE>;
- close(FILE);
- while (@lignes) {
- my $ligne = shift(@lignes);
- chomp $ligne;
- my $sequence = "";
- my $longueur = 0;
- if ( $ligne =~ /^([^\t]+)\t[^\t]+\tNC.*/) {
- my $forme = $1;
- $sequence .= $forme;
- $longueur = 1;
- my $nextligne = $lignes[0];
- if ( $nextligne =~ /^([^\t]+)\t[^\t]+\tPREP.*/) {
- my $forme = $1;
- $sequence .= " " . $forme;
- $longueur = 2;
- my $next_nextligne = $lignes[1];
- if ( $next_nextligne =~ /^([^\t]+)\t[^\t]+\tNC.*/) {
- my $forme = $1;
- $sequence .= " " . $forme;
- $longueur = 3;
- }
- }
- }
- if ($longueur == 3) {
- print $sequence . "\n";
- }
- }
open(FILE,"$ARGV[0]");
#--------------------------------------------
# le patron cherché ici est du type NOM PREP NOM
#--------------------------------------------
my @lignes = <FILE>;
close(FILE);
while (@lignes) {
my $ligne = shift(@lignes);
chomp $ligne;
my $sequence = "";
my $longueur = 0;
if ( $ligne =~ /^([^\t]+)\t[^\t]+\tNC.*/) {
my $forme = $1;
$sequence .= $forme;
$longueur = 1;
my $nextligne = $lignes[0];
if ( $nextligne =~ /^([^\t]+)\t[^\t]+\tPREP.*/) {
my $forme = $1;
$sequence .= " " . $forme;
$longueur = 2;
my $next_nextligne = $lignes[1];
if ( $next_nextligne =~ /^([^\t]+)\t[^\t]+\tNC.*/) {
my $forme = $1;
$sequence .= " " . $forme;
$longueur = 3;
}
}
}
if ($longueur == 3) {
print $sequence . "\n";
}
}
Extract morphosyntactic sequences from the TreeTagger results
- #/usr/bin/perl
- <<DOC;
- Nom : Rachid Belmouhoub
- Avril 2012
- usage : perl bao3_rb_new.pl fichier_tag fichier_motif
- DOC
- use strict;
- use utf8;
- use XML::LibXML;
- # Définition globale des encodage d'entrée et sortie du script à utf8
- binmode STDIN, ':encoding(utf8)';
- binmode STDOUT, ':encoding(utf8)';
- # On vérifie le nombre d'arguments de l'appel au script ($0 : le nom du script)
- if($#ARGV!=1){print "usage : perl $0 fichier_tag fichier_motif";exit;}
- # Enregistrement des arguments de la ligne de commande dans les variables idoines
- my $tag_file= shift @ARGV;
- my $patterns_file = shift @ARGV;
- # création de l'objet XML::XPath pour explorer le fichier de sortie tree-tagger XML
- my $xp = XML::LibXML->new(XML_LIBXML_RECOVER => 2);
- $xp->recover_silently(1);
- my $dom = $xp->load_xml( location => $tag_file );
- my $root = $dom->getDocumentElement();
- my $xpc = XML::LibXML::XPathContext->new($root);
- # Ouverture du fichiers de motifs
- open(PATTERNSFILE, $patterns_file) or die "can't open $patterns_file: $!\n";
- # lecture du fichier contenant les motifs, un motif par ligne (par exemple : NOM ADJ)
- while (my $ligne = <PATTERNSFILE>) {
- # Appel à la procédure d'extraction des motifs
- &extract_pattern($ligne);
- }
- # Fermeture du fichiers de motifs
- close(PATTERNSFILE);
- # routine de construction des chemins XPath
- sub construit_XPath{
- # On récupère la ligne du motif recherché
- my $local_ligne=shift @_;
- # initialisation du chemin XPath
- my $search_path="";
- # on supprime avec la fonction chomp un éventuel retour à la ligne
- chomp($local_ligne);
- # on élimine un éveltuel retour chariot hérité de windows
- $local_ligne=~ s/\r$//;
- # Construction au moyen de la fonction split d'un tableau dont chaque élément a pour valeur un élément du motif recherché
- my @tokens=split(/ /,$local_ligne);
- # On commence ici la construction du chemin XPath
- # Ce chemin correspond au premier noeud "element" de l'arbre XML qui répond au motif cherché
- $search_path="//element[contains(data[\@type=\"type\"],\"$tokens[0]\")]";
- # Initialisation du compteur pour la boucle de construction du chemin XPath
- my $i=1;
- while ($i < $#tokens) {
- $search_path.="[following-sibling::element[1][contains(data[\@type=\"type\"],\"$tokens[$i]\")]";
- $i++;
- }
- my $search_path_suffix="]";
- # on utilise l'opérateur x qui permet de répéter la chaine de caractère à sa gauche autant de fois que l'entier à sa droite,
- # soit $i fois $search_path_suffix
- $search_path_suffix=$search_path_suffix x $i;
- # le chemin XPath final
- $search_path.="[following-sibling::element[1][contains(data[\@type=\"type\"],\"".$tokens[$#tokens]."\")]"
- .$search_path_suffix;
- # print "$search_path\n";
- # on renvoie à la procédure appelante le chein XPath et le tableau des éléments du motif
- return ($search_path,@tokens);
- }
- # routine d'extraction du motif
- sub extract_pattern{
- # On récupère la ligne du motif recherché
- my $ext_pat_ligne= shift @_;
- # Appel de la fonction construit_XPath pour le motif lu à la ligne courrante du fichier de motif
- my ($search_path,@tokens) = &construit_XPath($ext_pat_ligne);
- # définition du nom du fichier de résultats pour le motif en utilisant la fonction join
- my $match_file = "res_extract-".join('_', @tokens).".txt";
- # Ouverture du fichiers de résultats encodé en UTF-8
- open(MATCHFILE,">:encoding(UTF-8)", "$match_file") or die "can't open $match_file: $!\n";
- # création de l'objet XML::XPath pour explorer le fichier de sortie tree-tagger XML
- # Parcours des noeuds du ficher XML correspondant au motif, au moyen de la méthode findnodes
- # qui prend pour argument le chemin XPath construit précédement
- # avec la fonction "construit_XPath"
- my @nodes=$root->findnodes($search_path);
- foreach my $noeud ( @nodes) {
- # Initialisation du chemin XPath relatif du noeud "data" contenant
- # la forme correspondant au premier élément du motif
- # Ce chemin est relatif au premier noeud "element" du bloc retourné
- # et pointe sur le troisième noeud "data" fils du noeud "element"
- # en l'identifiant par la valeur "string" de son attribut "type"
- my $form_xpath="";
- $form_xpath="./data[\@type=\"string\"]";
- # Initialisation du compteur pour la boucle d'éxtraction des formes correspondants
- # aux éléments suivants du motif
- my $following=0;
- # Recherche du noeud data contenant la forme correspondant au premier élément du motif
- # au moyen de la fonction "find" qui prend pour arguments:
- # 1. le chemin XPath relatif du noeud "data"
- # 2. le noeud en cours de traitement dans cette boucle foreach
- # la fonction "find" retourne par défaut une liste de noeuds, dans notre cas cette liste
- # ne contient qu'un seul élément que nous récupérons avec la fonction "get_node"
- # enfin nous en imprimons le contenu textuel au moyen de la méthode string_value
- print MATCHFILE $xpc->findvalue($form_xpath,$noeud);
- # Boucle d'éxtraction des formes correspondants aux éléments suivants du motif
- # On descend dans chaque noeud element du bloc
- while ( $following < $#tokens) {
- # Incrémentation du compteur $following de cette boucle d'éxtraction des formes
- $following++;
- # Construction du chemin XPath relatif du noeud "data" contenant
- # la forme correspondant à l'élément suivant du motif
- # Notez bien l'utilisation du compteur $folowing tant dans la condition de la boucle ci-dessus
- # que dans la construction du chemin relatif XPath
- my $following_elmt="following-sibling::element[".$following."]";
- $form_xpath=$following_elmt."/data[\@type=\"string\"]";
- # Impression du contenu textuel du noeud data contenant la forme correspondant à l'élément suivant du motif
- print MATCHFILE " ",$xpc->findvalue($form_xpath,$noeud);
- # Incrémentation du compteur $following de cette boucle d'éxtraction des formes
- # $following++;
- }
- print MATCHFILE "\n";
- }
- # Fermeture du fichiers de motifs
- close(MATCHFILE);
- }
#/usr/bin/perl
<<DOC;
Nom : Rachid Belmouhoub
Avril 2012
usage : perl bao3_rb_new.pl fichier_tag fichier_motif
DOC
use strict;
use utf8;
use XML::LibXML;
# Définition globale des encodage d'entrée et sortie du script à utf8
binmode STDIN, ':encoding(utf8)';
binmode STDOUT, ':encoding(utf8)';
# On vérifie le nombre d'arguments de l'appel au script ($0 : le nom du script)
if($#ARGV!=1){print "usage : perl $0 fichier_tag fichier_motif";exit;}
# Enregistrement des arguments de la ligne de commande dans les variables idoines
my $tag_file= shift @ARGV;
my $patterns_file = shift @ARGV;
# création de l'objet XML::XPath pour explorer le fichier de sortie tree-tagger XML
my $xp = XML::LibXML->new(XML_LIBXML_RECOVER => 2);
$xp->recover_silently(1);
my $dom = $xp->load_xml( location => $tag_file );
my $root = $dom->getDocumentElement();
my $xpc = XML::LibXML::XPathContext->new($root);
# Ouverture du fichiers de motifs
open(PATTERNSFILE, $patterns_file) or die "can't open $patterns_file: $!\n";
# lecture du fichier contenant les motifs, un motif par ligne (par exemple : NOM ADJ)
while (my $ligne = <PATTERNSFILE>) {
# Appel à la procédure d'extraction des motifs
&extract_pattern($ligne);
}
# Fermeture du fichiers de motifs
close(PATTERNSFILE);
# routine de construction des chemins XPath
sub construit_XPath{
# On récupère la ligne du motif recherché
my $local_ligne=shift @_;
# initialisation du chemin XPath
my $search_path="";
# on supprime avec la fonction chomp un éventuel retour à la ligne
chomp($local_ligne);
# on élimine un éveltuel retour chariot hérité de windows
$local_ligne=~ s/\r$//;
# Construction au moyen de la fonction split d'un tableau dont chaque élément a pour valeur un élément du motif recherché
my @tokens=split(/ /,$local_ligne);
# On commence ici la construction du chemin XPath
# Ce chemin correspond au premier noeud "element" de l'arbre XML qui répond au motif cherché
$search_path="//element[contains(data[\@type=\"type\"],\"$tokens[0]\")]";
# Initialisation du compteur pour la boucle de construction du chemin XPath
my $i=1;
while ($i < $#tokens) {
$search_path.="[following-sibling::element[1][contains(data[\@type=\"type\"],\"$tokens[$i]\")]";
$i++;
}
my $search_path_suffix="]";
# on utilise l'opérateur x qui permet de répéter la chaine de caractère à sa gauche autant de fois que l'entier à sa droite,
# soit $i fois $search_path_suffix
$search_path_suffix=$search_path_suffix x $i;
# le chemin XPath final
$search_path.="[following-sibling::element[1][contains(data[\@type=\"type\"],\"".$tokens[$#tokens]."\")]"
.$search_path_suffix;
# print "$search_path\n";
# on renvoie à la procédure appelante le chein XPath et le tableau des éléments du motif
return ($search_path,@tokens);
}
# routine d'extraction du motif
sub extract_pattern{
# On récupère la ligne du motif recherché
my $ext_pat_ligne= shift @_;
# Appel de la fonction construit_XPath pour le motif lu à la ligne courrante du fichier de motif
my ($search_path,@tokens) = &construit_XPath($ext_pat_ligne);
# définition du nom du fichier de résultats pour le motif en utilisant la fonction join
my $match_file = "res_extract-".join('_', @tokens).".txt";
# Ouverture du fichiers de résultats encodé en UTF-8
open(MATCHFILE,">:encoding(UTF-8)", "$match_file") or die "can't open $match_file: $!\n";
# création de l'objet XML::XPath pour explorer le fichier de sortie tree-tagger XML
# Parcours des noeuds du ficher XML correspondant au motif, au moyen de la méthode findnodes
# qui prend pour argument le chemin XPath construit précédement
# avec la fonction "construit_XPath"
my @nodes=$root->findnodes($search_path);
foreach my $noeud ( @nodes) {
# Initialisation du chemin XPath relatif du noeud "data" contenant
# la forme correspondant au premier élément du motif
# Ce chemin est relatif au premier noeud "element" du bloc retourné
# et pointe sur le troisième noeud "data" fils du noeud "element"
# en l'identifiant par la valeur "string" de son attribut "type"
my $form_xpath="";
$form_xpath="./data[\@type=\"string\"]";
# Initialisation du compteur pour la boucle d'éxtraction des formes correspondants
# aux éléments suivants du motif
my $following=0;
# Recherche du noeud data contenant la forme correspondant au premier élément du motif
# au moyen de la fonction "find" qui prend pour arguments:
# 1. le chemin XPath relatif du noeud "data"
# 2. le noeud en cours de traitement dans cette boucle foreach
# la fonction "find" retourne par défaut une liste de noeuds, dans notre cas cette liste
# ne contient qu'un seul élément que nous récupérons avec la fonction "get_node"
# enfin nous en imprimons le contenu textuel au moyen de la méthode string_value
print MATCHFILE $xpc->findvalue($form_xpath,$noeud);
# Boucle d'éxtraction des formes correspondants aux éléments suivants du motif
# On descend dans chaque noeud element du bloc
while ( $following < $#tokens) {
# Incrémentation du compteur $following de cette boucle d'éxtraction des formes
$following++;
# Construction du chemin XPath relatif du noeud "data" contenant
# la forme correspondant à l'élément suivant du motif
# Notez bien l'utilisation du compteur $folowing tant dans la condition de la boucle ci-dessus
# que dans la construction du chemin relatif XPath
my $following_elmt="following-sibling::element[".$following."]";
$form_xpath=$following_elmt."/data[\@type=\"string\"]";
# Impression du contenu textuel du noeud data contenant la forme correspondant à l'élément suivant du motif
print MATCHFILE " ",$xpc->findvalue($form_xpath,$noeud);
# Incrémentation du compteur $following de cette boucle d'éxtraction des formes
# $following++;
}
print MATCHFILE "\n";
}
# Fermeture du fichiers de motifs
close(MATCHFILE);
}
Instead of using Perl, we can also use XPATH to extract our sequences
To create an HTML page showing the sequences, you can use xsltproc in the following command:
xsltproc stylesheet.xsl xml_file.xml > sequence.html
This is a stylesheet that allows you to extract all the noun-preposition-noun sequences using XPATH.
- <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
- <xsl:output method="html"/>
- <xsl:template match="/">
- <html>
- <body bgcolor="#81808E">
- <table align="center" bgcolor="white" border="1" bordercolor="#3300FF" width="50%">
- <tr bgcolor="black">
- <td valign="top" width="90%">
- <font color="white">
- <h1>Extraction de patron
- <font color="red">
- <b>NOM</b></font>
- <xsl:text/>
- <font color="blue">
- <b>PRP</b>
- </font>
- <xsl:text/>
- <font color="red">
- <b>NOM</b>
- </font>
- </h1>
- </font>
- </td>
- </tr>
- <tr>
- <td>
- <blockquote>
- <xsl:apply-templates select="PARCOURS/ETIQUETAGE/file"/>
- </blockquote>
- </td>
- </tr>
- </table>
- </body>
- </html>
- </xsl:template>
- <xsl:template match="file">
- <xsl:for-each select="element">
- <xsl:if test="(./data[contains(text(),'NOM')])">
- <xsl:variable name="p1" select="./data[3]/text()"/>
- <xsl:if test="following-sibling::element[1][./data[contains(text(),'PRP')]]">
- <xsl:variable name="p2" select="following-sibling::element[1]/data[3]/text()"/>
- <xsl:if test="following-sibling::element[2][./data[contains(text(),'NOM')]]">
- <xsl:variable name="p3" select="following-sibling::element[2]/data[3]/text()"/>
- <font color="red">
- <xsl:value-of select="$p1"/>
- </font>
- <xsl:text/>
- <font color="blue">
- <xsl:value-of select="$p2"/>
- </font>
- <xsl:text/>
- <font color="red">
- <xsl:value-of select="$p3"/>
- </font>
- <br/>
- <xsl:text/>
- </xsl:if>
- </xsl:if>
- </xsl:if>
- </xsl:for-each>
- </xsl:template>
- </xsl:stylesheet>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="html"/>
<xsl:template match="/">
<html>
<body bgcolor="#81808E">
<table align="center" bgcolor="white" border="1" bordercolor="#3300FF" width="50%">
<tr bgcolor="black">
<td valign="top" width="90%">
<font color="white">
<h1>Extraction de patron
<font color="red">
<b>NOM</b></font>
<xsl:text/>
<font color="blue">
<b>PRP</b>
</font>
<xsl:text/>
<font color="red">
<b>NOM</b>
</font>
</h1>
</font>
</td>
</tr>
<tr>
<td>
<blockquote>
<xsl:apply-templates select="PARCOURS/ETIQUETAGE/file"/>
</blockquote>
</td>
</tr>
</table>
</body>
</html>
</xsl:template>
<xsl:template match="file">
<xsl:for-each select="element">
<xsl:if test="(./data[contains(text(),'NOM')])">
<xsl:variable name="p1" select="./data[3]/text()"/>
<xsl:if test="following-sibling::element[1][./data[contains(text(),'PRP')]]">
<xsl:variable name="p2" select="following-sibling::element[1]/data[3]/text()"/>
<xsl:if test="following-sibling::element[2][./data[contains(text(),'NOM')]]">
<xsl:variable name="p3" select="following-sibling::element[2]/data[3]/text()"/>
<font color="red">
<xsl:value-of select="$p1"/>
</font>
<xsl:text/>
<font color="blue">
<xsl:value-of select="$p2"/>
</font>
<xsl:text/>
<font color="red">
<xsl:value-of select="$p3"/>
</font>
<br/>
<xsl:text/>
</xsl:if>
</xsl:if>
</xsl:if>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>This is a stylesheet that allows you to extract all the noun-adjectives sequences using XPATH.
- <xsl:stylesheet version="2.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
- <xsl:output method="html"/>
- <xsl:template match="/">
- <html>
- <body bgcolor="#81808E">
- <table align="center" bgcolor="white" border="1" bordercolor="#3300FF" width="50%">
- <tr bgcolor="black">
- <td valign="top" width="90%">
- <font color="white">
- <h1>Extraction de patron
- <font color="red">
- <b>NOM</b></font>
- <font color="blue">
- <b>ADJ</b>
- </font>
- </h1>
- </font>
- </td>
- </tr>
- <tr>
- <td>
- <blockquote>
- <xsl:apply-templates select="./PARCOURS/ETIQUETAGE/file/element"/>
- </blockquote>
- </td>
- </tr>
- </table>
- </body>
- </html>
- </xsl:template>
- <xsl:template match="element">
- <xsl:choose>
- <xsl:when test="(./data[contains(text(),'NOM')]) and (following-sibling::element[1][./data[contains(text(),'ADJ')]])">
- <font color="red">
- <xsl:value-of select="./data[3]"/>
- </font>
- <xsl:text/>
- </xsl:when>
- <xsl:when test="(./data[contains(text(),'ADJ')]) and (preceding-sibling::element[1][./data[contains(text(),'NOM')]])">
- <font color="blue">
- <xsl:value-of select="./data[3]"/>
- </font>
- <br/>
- </xsl:when>
- </xsl:choose>
- </xsl:template>
- </xsl:stylesheet>
<xsl:stylesheet version="2.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="html"/>
<xsl:template match="/">
<html>
<body bgcolor="#81808E">
<table align="center" bgcolor="white" border="1" bordercolor="#3300FF" width="50%">
<tr bgcolor="black">
<td valign="top" width="90%">
<font color="white">
<h1>Extraction de patron
<font color="red">
<b>NOM</b></font>
<font color="blue">
<b>ADJ</b>
</font>
</h1>
</font>
</td>
</tr>
<tr>
<td>
<blockquote>
<xsl:apply-templates select="./PARCOURS/ETIQUETAGE/file/element"/>
</blockquote>
</td>
</tr>
</table>
</body>
</html>
</xsl:template>
<xsl:template match="element">
<xsl:choose>
<xsl:when test="(./data[contains(text(),'NOM')]) and (following-sibling::element[1][./data[contains(text(),'ADJ')]])">
<font color="red">
<xsl:value-of select="./data[3]"/>
</font>
<xsl:text/>
</xsl:when>
<xsl:when test="(./data[contains(text(),'ADJ')]) and (preceding-sibling::element[1][./data[contains(text(),'NOM')]])">
<font color="blue">
<xsl:value-of select="./data[3]"/>
</font>
<br/>
</xsl:when>
</xsl:choose>
</xsl:template>
</xsl:stylesheet>Scripts based off those of the professors to improve the extraction of morpho-syntacitc patterns from the results of TreeTagger and Cordial.
In class we saw three ways using Perl of extracting the desired phrases. These three scripts all work in a similar way by writing the desired pattern into the scripts and searching explicitly for a single pattern.
Here we propose two very similar scripts of our own making. These scripts are different from those of the professors' in that we can search for any number of patterns and those patterns can be of any length.
- use strict;
- use warnings;
- #--------------------------------------------------------------
- # This script allows the user to search for as many morphosyntactic patterns
- # (of any/varying length) as desired from the Cordial results of tool 2
- # usage: perl ourversion1.pl patron_test.txt
- #--------------------------------------------------------------
- open(FILE,"$ARGV[0]"); # the cordial tagged text
- open(FILE2,"$ARGV[1]"); # the list of patterns
- #--------------------------------------------------------------
- # the patterns searched for are in the file patron_test.txt
- #--------------------------------------------------------------
- my @lignes = <FILE>;
- my @patrons = <FILE2>;
- close(FILE);
- close(FILE2);
- while (@lignes) {
- my $ligne = shift(@lignes);
- chomp $ligne;
- for (my $i = 0; $i < scalar@patrons; $i++) {
- my $sequence = "";
- my $forme = "";
- my $longueur = 0;
- my @split_patrons = split(' ', @patrons[$i]);
- if ($ligne =~ /^([^\t]+)\t[^\t]+\t$split_patrons[0].*/) {
- $forme = $1;
- $sequence .= $forme;
- $longueur = 1;
- for (my $j = 1; $j < scalar@split_patrons; $j++) {
- if ($lignes[$j-1] =~ /^([^\t]+)\t[^\t]+\t$split_patrons[$j].*/) {
- $forme = $1;
- $sequence .= " " . $forme;
- $longueur++;
- }
- }
- }
- if ($longueur == scalar@split_patrons) {
- print "\n[" . $sequence . "]\n";
- }
- }
- }
- close FILE;
- close FILE2;
use strict;
use warnings;
#--------------------------------------------------------------
# This script allows the user to search for as many morphosyntactic patterns
# (of any/varying length) as desired from the Cordial results of tool 2
# usage: perl ourversion1.pl patron_test.txt
#--------------------------------------------------------------
open(FILE,"$ARGV[0]"); # the cordial tagged text
open(FILE2,"$ARGV[1]"); # the list of patterns
#--------------------------------------------------------------
# the patterns searched for are in the file patron_test.txt
#--------------------------------------------------------------
my @lignes = <FILE>;
my @patrons = <FILE2>;
close(FILE);
close(FILE2);
while (@lignes) {
my $ligne = shift(@lignes);
chomp $ligne;
for (my $i = 0; $i < scalar@patrons; $i++) {
my $sequence = "";
my $forme = "";
my $longueur = 0;
my @split_patrons = split(' ', @patrons[$i]);
if ($ligne =~ /^([^\t]+)\t[^\t]+\t$split_patrons[0].*/) {
$forme = $1;
$sequence .= $forme;
$longueur = 1;
for (my $j = 1; $j < scalar@split_patrons; $j++) {
if ($lignes[$j-1] =~ /^([^\t]+)\t[^\t]+\t$split_patrons[$j].*/) {
$forme = $1;
$sequence .= " " . $forme;
$longueur++;
}
}
}
if ($longueur == scalar@split_patrons) {
print "\n[" . $sequence . "]\n";
}
}
}
close FILE;
close FILE2;
A second option:
- #! /usr/bin/perl
- use strict;
- open(PATRONS, "$ARGV[0]");
- open(CORDIAL, "$ARGV[1]");
- open(CORDIAL_BKP, "$ARGV[1]");
- # créer fichier de résultats
- open my $final_result, '>>', "results.txt";
- my $terme;
- my @tags;
- # lire lignes du fichier de patrons
- while(chomp($terme=<PATRONS>)){
- # séparer les patrons de la ligne lue
- @tags = split(" ", $terme);
- my @LISTE;
- # lire le fichier étiquetté
- while(@LISTE = split(/\t/, <CORDIAL>)){
- # comparer les patrons du texte avec la patrons recherché
- if($LISTE[2] =~ m/$tags[0]/){
- # repérer position où le premier patron a été trouvé
- my $position = tell(CORDIAL);
- # continuer lecture à partir de $position
- seek(CORDIAL_BKP, $position, 0);
- my $compteur = 0;
- my $result="";
- # lire la séquence de patrons
- foreach my $tag (@tags){
- if($LISTE[2]=~ m/$tag/){
- # stocker résultat
- $result .= $LISTE[0]." ";
- # lire ligne suivant
- @LISTE = split(/\t/, <CORDIAL_BKP>);
- $compteur++;
- # si vrai, l`analyse est finie
- if($compteur == @tags){
- # écrire résultat
- print $final_result $result."\n";
- }
- }
- }
- }
- }
- seek(CORDIAL, 0, 0);
- }
- close(CORDIAL);
- close(PATRONS);
#! /usr/bin/perl
use strict;
open(PATRONS, "$ARGV[0]");
open(CORDIAL, "$ARGV[1]");
open(CORDIAL_BKP, "$ARGV[1]");
# créer fichier de résultats
open my $final_result, '>>', "results.txt";
my $terme;
my @tags;
# lire lignes du fichier de patrons
while(chomp($terme=<PATRONS>)){
# séparer les patrons de la ligne lue
@tags = split(" ", $terme);
my @LISTE;
# lire le fichier étiquetté
while(@LISTE = split(/\t/, <CORDIAL>)){
# comparer les patrons du texte avec la patrons recherché
if($LISTE[2] =~ m/$tags[0]/){
# repérer position où le premier patron a été trouvé
my $position = tell(CORDIAL);
# continuer lecture à partir de $position
seek(CORDIAL_BKP, $position, 0);
my $compteur = 0;
my $result="";
# lire la séquence de patrons
foreach my $tag (@tags){
if($LISTE[2]=~ m/$tag/){
# stocker résultat
$result .= $LISTE[0]." ";
# lire ligne suivant
@LISTE = split(/\t/, <CORDIAL_BKP>);
$compteur++;
# si vrai, l`analyse est finie
if($compteur == @tags){
# écrire résultat
print $final_result $result."\n";
}
}
}
}
}
seek(CORDIAL, 0, 0);
}
close(CORDIAL);
close(PATRONS);Patterns used for phrase extraction
We used many different patterns with ":" . Here are a few:
NPMS PCTFORTE NCMS PREP ADJIND NCMIN
VINF DETDMS NCMS PCTFORTE DETDPIG NCFP DETDMS ADJNUM NCMIN
NPI PCTFORTE DETDMS NCMS ADV VINDP3S ADV COO VINDP3S
The full list is here.
Pattern used: N[A-Z]+ ADJ[A-Z]+
Pattern used: N[A-Z]+ PREP DET[A-Z]+ N[A-Z]+
Pattern used: .*?que.*
Extracted phrases
We used many different patterns with ":" . Here are a few:
NPMS PCTFORTE NCMS PREP ADJIND NCMIN
VINF DETDMS NCMS PCTFORTE DETDPIG NCFP DETDMS ADJNUM NCMIN
NPI PCTFORTE DETDMS NCMS ADV VINDP3S ADV COO VINDP3S
The full list is here.
List of results with ":" .
Pattern used: N[A-Z]+ ADJ[A-Z]+
List of NOUN-ADJ results.
Pattern used: N[A-Z]+ PREP DET[A-Z]+ N[A-Z]+
List of NOUN-PREP-DET_NOM results.
Pattern used: .*?que.*
List of VERB-CONJUNCTION results.
How we create these graphs
Toolbox Programs draws to a close with this final step.Tool 4 uses an externally written program for Windows* that allows us to create graphs using the results from Tool 3. These graphs help us visualize the patterns found within the text.
These patterns are the morpho-syntactic sequences we searched for earlier with Tool 3: NOUN-ADJ, NOUN-PREP-DET-NOUN, PCTFORTE ":", and VERB-CONJ. They were chosen because they showed the greatest range of interesting results that we found when looking at possible patterns.
The visualization provided by these graphs gives us a clear notion of how each of the elements in our patterns links together. We can, for example, use the graph to highlight the relations maintained by a given form at the syntactic and paradigmatic levels.
Take for example the graph below from the Politics section. We chose to look at sequences where the name of the French President François Hollande appears. To make understanding the graph easier, we simplified it by stripping away many of the sentences.
The red arrows indicate negative statements and the green arrows indicate positive statements. The purple arrow indicates possible transitions on the paradigmatic axis.
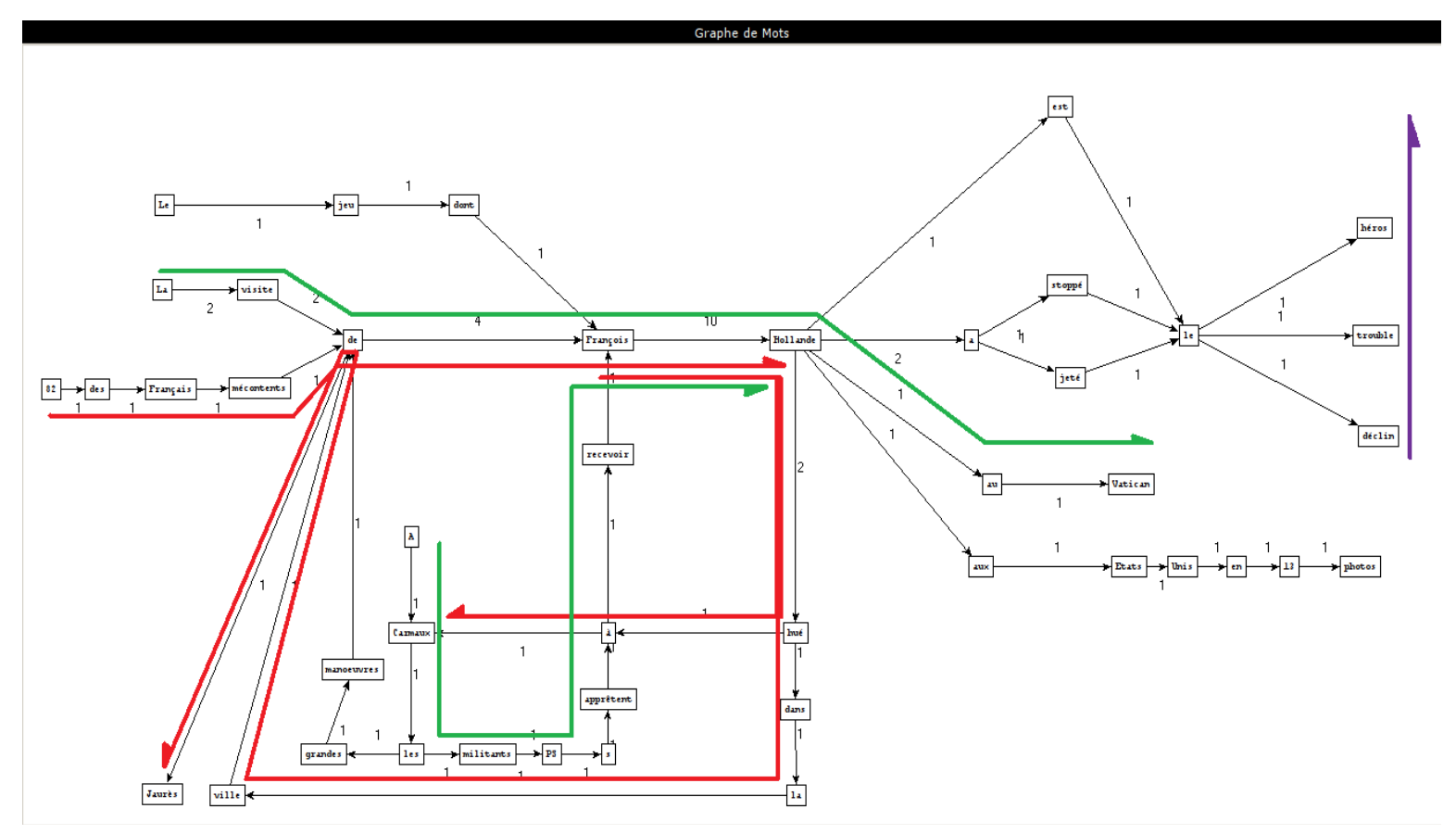
A brief analysis of one one of these graphs can identify several interesting syntactic constructions. For example, we can see that by changing the paradigmatic axis, we create "strange" but not ungrammatical statements.
We can have a little fun creating new phrases by following the different paths of the arrows. We just need to change directions when we come across a fork in the path.
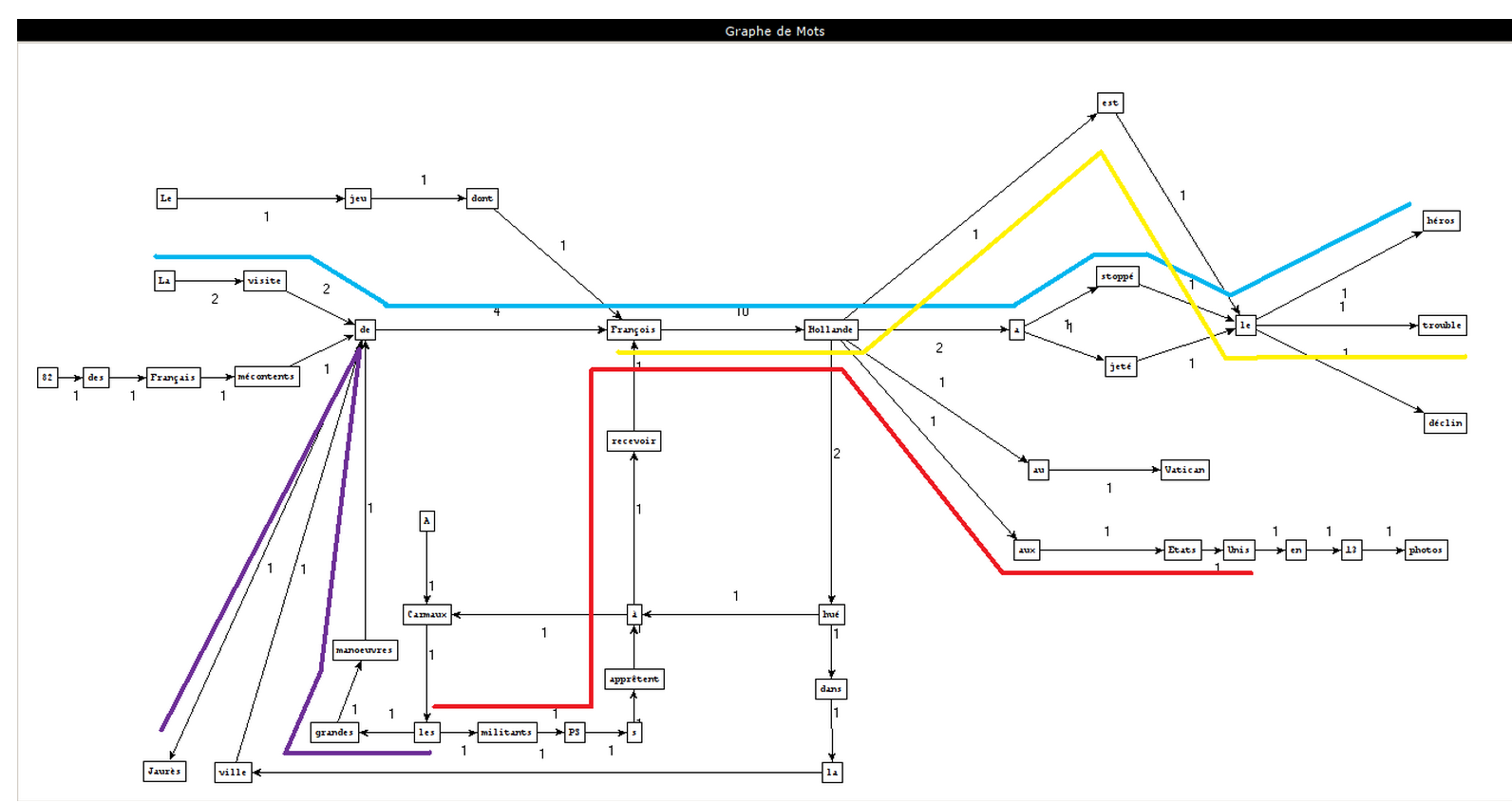
(These phrases were just created for fun and don't represent our political positions...)
This experiment does not yield the same results as when we change the the syntactic axis. The reversal of neighboring forms on this axis in most cases causes either ungrammatical statements or phrases with different semantics.
This is explained by the the fact that the parallel constructions on the paradigmatic axis mainly belong to the same grammatical category.
In the graph, these types of structure are often aligned with arrows that go in the same direction as we can see in the examples below:
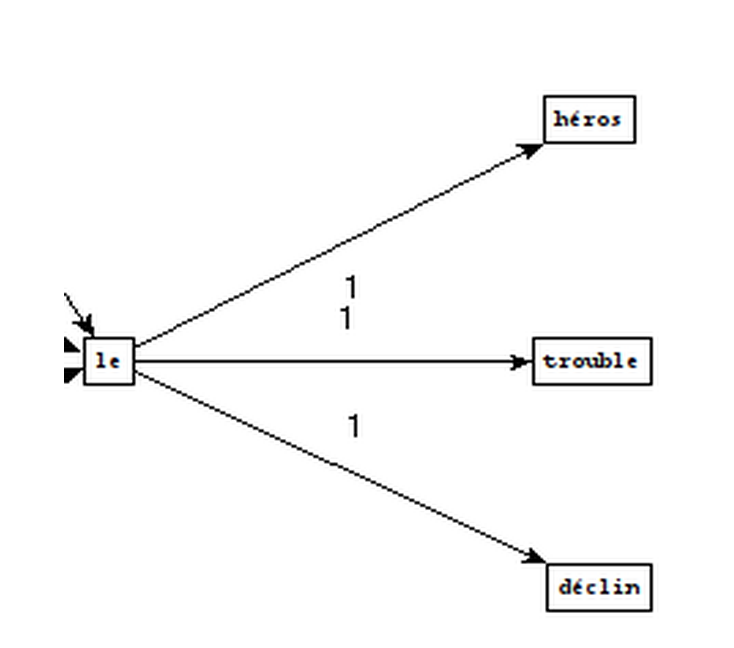

It must also be said that a paradigmatic alignment can also contain elements of a distinct type, in which case, switching them around is impossible.
For example:
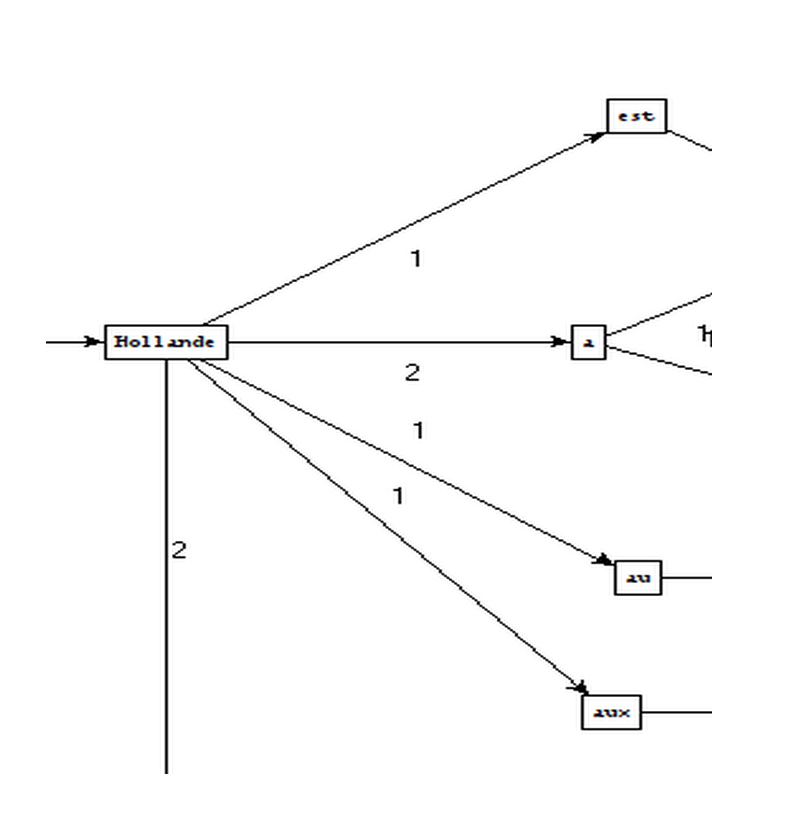
*Since we're not all using Windows, we used Wine to launch the program.
noun-adj
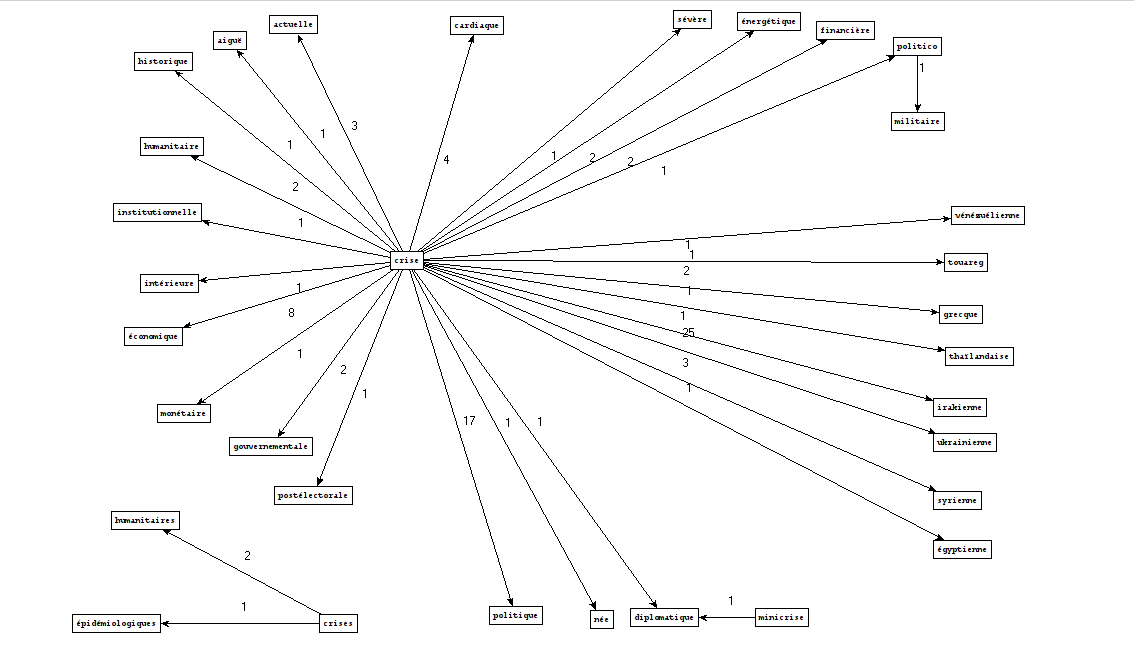
We chose to run Tool 3 in the INTERNATIONAL section of our results with the pattern NOUN-ADJ to extract all the morpho-syntactic sequences that contain a noun followed by an adjective.
Then, in Tool 4 we chose to look more closely at our pattern using the word "crise" as our NOUN. We hypothesized that, given the current global economic context, we would find a high number of occurrences of the type "crise économique". As we can see in the graph above, there are eight occurrences of this sequence in the International section. This however pales in comparison to the number of occurrences of "crise ukrainienne". In 2014 the situation in Ukraine was very prominent in the news, so this result comes as no surprise.
Even without looking at the context from which these sequences were extracted, we notice that the pattern of "crise" + nationality is much more common than "crise" + "économique". This is not what we expected to see. Journalists are more likely to say where the "crise" is taking place rather than what kind of "crise" it is. From what we can see in our results, almost all the sequences belong in a political or economic context.
Nevertheless, we were surprised to find four occurrences of "crise cardiaque" in our graph. We weren't expecting to see medical results in the International section. Without needing to verify in the corpus, we can suppose that someone of international import suffered a heart attack sometime in 2014.
We also found three plural cases ("crises") that don't belong to an economic or political domain either. Their associated adjectives were "épidémiologiques" from the medical domain, and "humanitaires", likely from a humanitarian/social domain. The number of occurrences in plural was insignificant when compared to the entire year so we did not conduct a further analysis.
noun-prep-det-noun
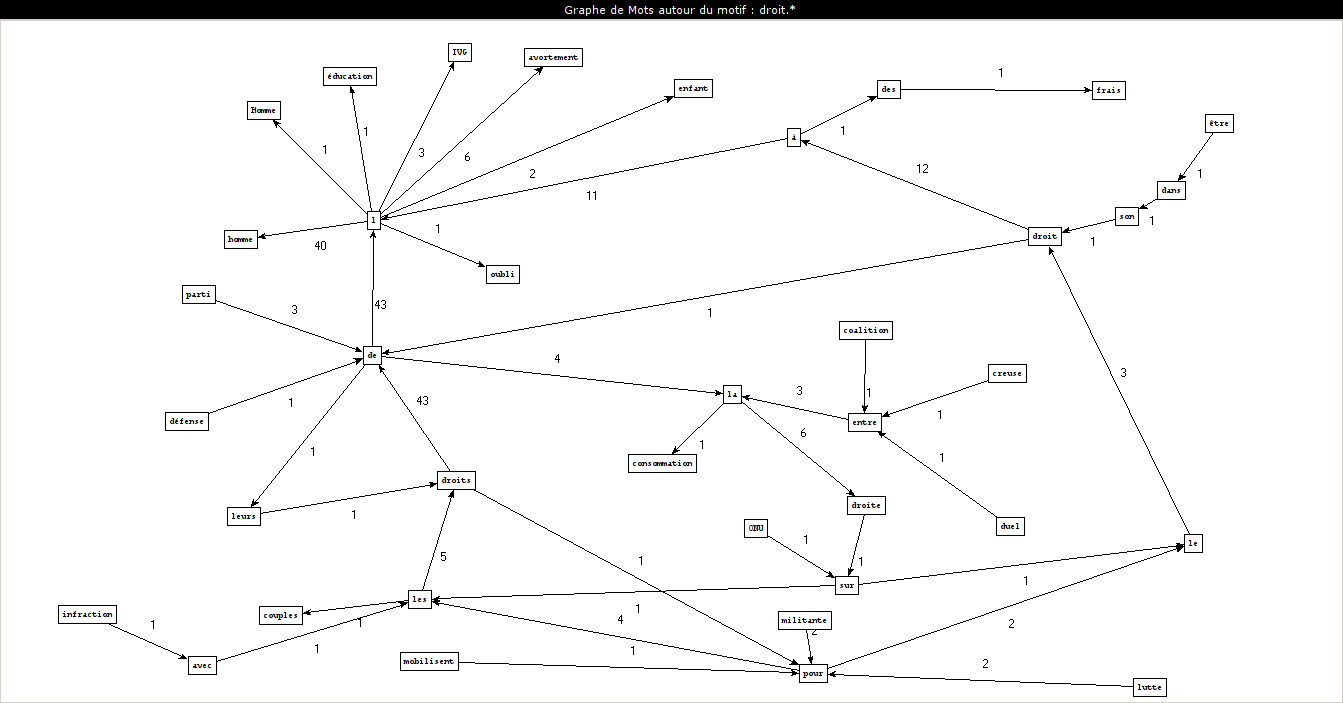
We searched though the results we obtained with the pattern noun-prep-det-noun in the International section for those that contained "droit" as the noun. We used the regular expression droit.* to encompass the feminine and plural forms of the word in our results. We can see that the phrase "droits de l’homme" appears 41 times (not differentiating between uppercase and lowercase). The vast majority of our occurrences contained "droit" in the first noun and a small handful contained "droit" in the second noun in the sequence such as "être dans son droit" or "lutte pour le droit".
In the first case ("droit" in the first noun), we are usually referencing legislative matters. In the second case, we are mostly in a political context where there is some sort of movement to get or increase the rights of a population.
PCTFORTE ":"
On Le Monde's website we noticed a strong correlation between the use of a colon and key words from the article.


As we observed, this type of punctuation is very prevalent at Le Monde. In fact, the [noun phrase] ":" [noun phrase][phrase]* structure is a characteristic way for journalists to create article titles.
Here are a few examples of the same structure in other French publications:



We can see that certain publications reuse nearly the same title, with the same structure.
Libération
"Egypt: l'ex-président islamiste Mohamed Morsi condamné à mort"
La Tribune
"Egypt: l'ex-président islamiste Mohamed Morsi condamné à mort"
Le Figaro
"Egypt: l'ex-président Mohamed Morsi condamné à mort"
Métro News
"Egypt: Mohamed Morsi condamné à mort"
This doesn't mean however, that journalists are lacking in creativity. It is a journalistic technique used to make the reader want to read the article associated with the title. In fact, the title gives away the main topic while still not revealing all the pertinent information, luring the reader into reading the article.
For example, from the titles above we can conclude that Mr. Mohamed Morsi was sentenced to death. In light of this information the reader could wonder: "Why was he sentenced to death?", "When will it happen?", or even "Who is Mohamed Morsi?".
This type of phrase gives you the essential news without necessarily telling you "why", "when", "who", "where", etc.
In Cordial the symbols ';' , '!' , '?' and '.' are marked as PTCFORTE as well as ':'. A simple search with a pattern like:
N[A-Z]+ PCTFORTE N[A-Z]+ V[A-Z]+ PREP N[A-Z]+
can give us a variety of sentences we don't want, like:
To avoid this problem and try to find out whether this type of structure is recurrent, we created a script in Python. The script is Trouver_Patrons.py and it reads a group of tagged files looking for specific tags or tokens the user has indicated. It outputs a file that contains all the patterns that include the tag or token the user chose.
Here are the results from Trouver_Patrons.py :
CINEMA section : total number of phrases - 1927
| True Positives | 91 |
| False Positives | 19 |
| True Negatives | 1836 |
| False Negatives | 5 |
| Recall | 0,947 | 94% |
| Precision | 0,827 | 82% |
| F-Measure | 0,87 | 87% |
With these results, despite the variety of forms, it is possible to identify types of statements. Given that the phrases that contain this structure also contain key words, the type identification could be very useful.
Here are the graphs created with the script for the CINEMA section:
(To make the results more clear, the number of phrases was reduced.)
The symbol ':' is represented by the token 'pct'
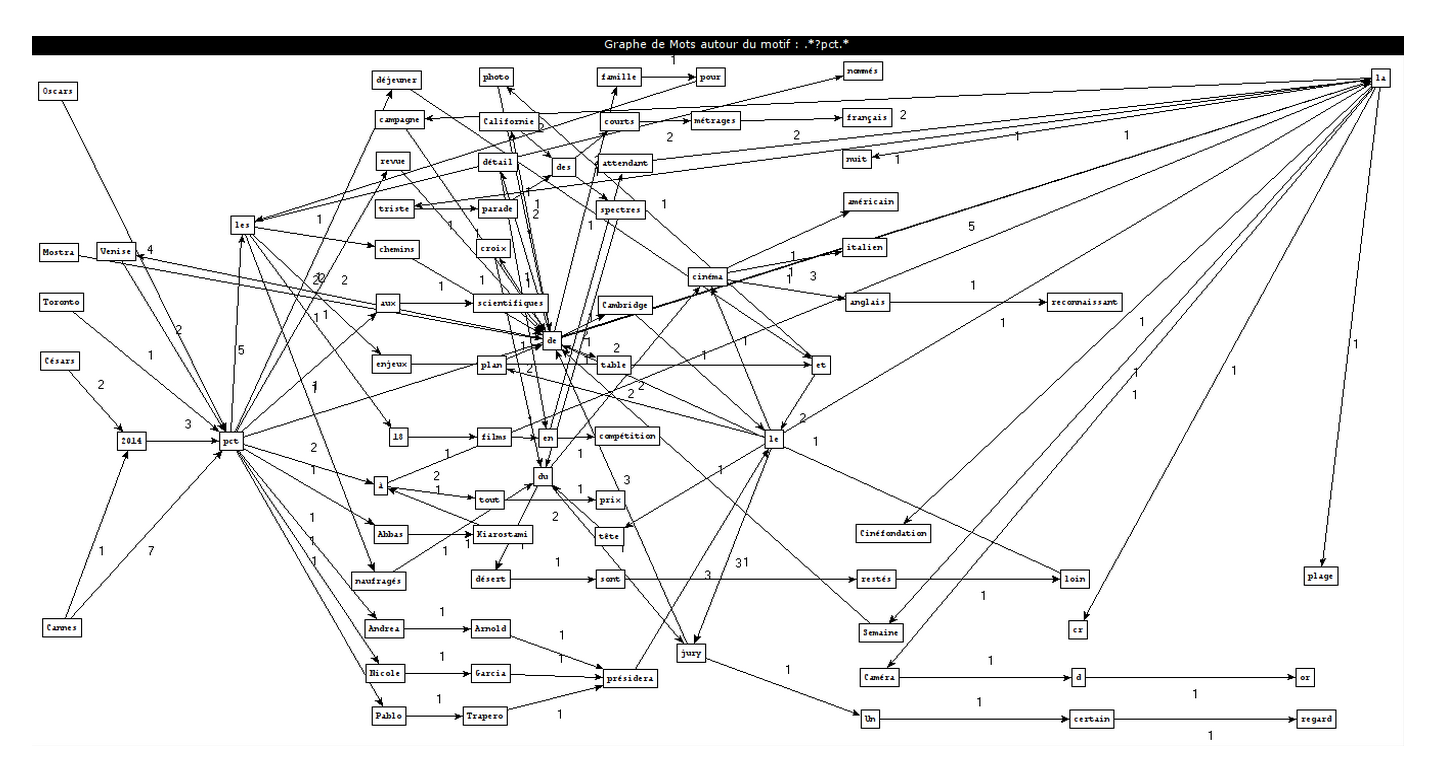
Examples of statements extracted with Tool 3 using the patterns produced by Trouver_Patrons.py:
The key words:

Semantically empty words have the greatest number of occurrences. This is represented in the graphs by an agglomeration of nodes, along with the searched-for pattern.
Here's the same graph filtered by a stop-list:

In these graphs we can observe that the words 'cinéma' and 'jury' are often connected. We found this surprising given the section we were searching in - CINEMA.
CONJUNCTION
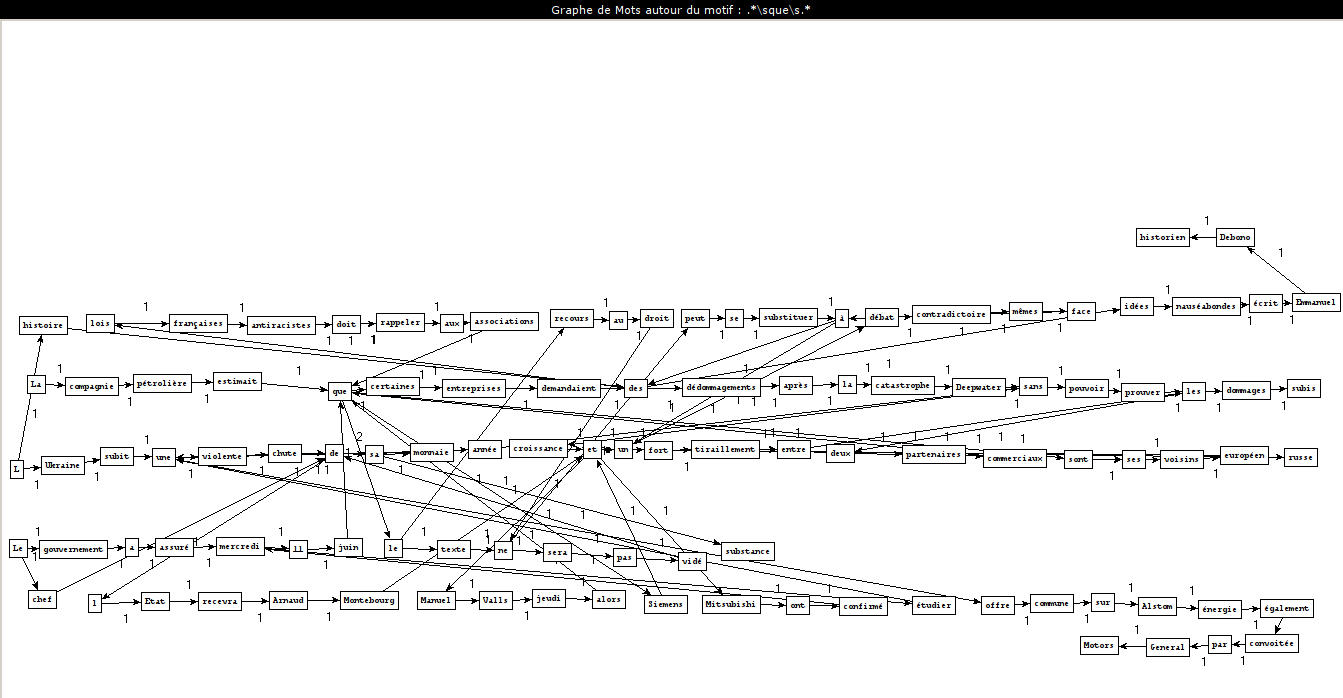
We tried to create a graph showing conjunctions but the problem is that the results we obtained were dense and difficult to interpret. This is due to the fact that most phrases containing a conjunction were very long which cluttered up the graph. Thanks to our file of results that contain all the phrases with the searched-for pattern, we were able to separate the phrases containing "que". We ended up with the five following phrases:
Our results come only from what was found in the <description> tags due to the length of the pattern used to create the graph. Since article titles are relatively short, it's understandable that none of the structures were matched there.
What can we conclude?
In conclusion we can conclude that there are a variety of interesting morpho-syntacic phrases to look at in the writings of Le Monde. We chose four that we thought gave us the largest range of visible results in the graphs made.
This type of analysis gives us great insight into what the corpus is talking about, without ever actually needing to read through the corpus. Once we knew the type of event to look for, it became much easier to analyze and find similar events. This can be generalized to other sorts of publications. If we were to look though the writings of Le Figaro or L'Humanité, although they are very different papers, we would be able to analyze them in the same way.



