Automatisar um processo de coleta e análise de padrões lexicais de um corpus texto.
Criar vários script em Perl que possam ser modificidos e adaptados para trabalhar com diversos contextos diferentes, mas com objetivos similares.
Exibir os resultados em forma de gráficos acompanhados de nossa interpretação.
Os dados são compostos de feeds RSS de 2014 do jornal Le Monde. Os arquivos encontram-se em formato XML e organizados em pastas separadas por mês de publicação.
Nosso primeiro script percorre a estrutura de arquivos e extrai todo conteúdo presente nas balisas <title> e <description>. Esses dados são em seguida tratados para que seja feita a substituição des caractères especiais, a exclusão das imagens e de outros dados que não serão tratados.
Esta ferramenta coleta a saída do script 1 e utilisa dos etiquetadores de parte do discurso (POS Tagger) diferentes: TreeTagger e Cordial.
A ferramenta 3 é composta de dois scripts diferentes; um para tratar a saída feita por TreeTagger e outro para tratar a saída Cordial. O objetivo é buscar padrões morfosintáticos específicos nesses dois resultados (ex. substantivo-preposição-substantivo)
Nossa última ferramenta utiliza as sequência encontradas para criar um representação visual desses syntagmas dentro do texto.
O que a ferramenta 1 faz?
Perl
Perl com XPATH
Perl Puro
Módulos do Perl
Exemplo

O que a ferramenta 2 faz?
O método do professor
Ferramenta 2 & Ferramenta 3 & Ferramenta 4
Pure Perl
Módulos do Perl
Exemplo
O que a ferramenta 3 faz?
Perl
XPATH
Modificação dos scripts
Padrões utilizados
Frases extraídas
Como criar os gráficos
substantivo-adjetivo
substantivo-preposição-artigo-substantivo
PCTFORTE ":"
Conjunção
O que nós podemos concluir?
Nós somos estudantes do primeiro ano de mestrado du curso Tratamento Automático de Línguas Naturais oferecido pelo Institut National des Langues et Civilisations Orientales (INALCO) em Paris, França. Mais informações sobre a nossa formação podem ser encontradas neste link (textos em Francês).
Que fait l'outil 1 ?

O projeto Caixa de Ferramentas 1 é composto por um programa que lê a estrutura dos feeds RSS do jornal Le Monde. Os arquivos estão organizados em uma pasta nomeada 2014 (o ano no qual nos realizamos a pesquisa). Esta pasta contém subpastas, um para cada mês, dentros das quais estão estocadso arquivos XML e TXT, contendo os artigos e as tags. Todo esse material encontra-se organizado par tema (Política, Cultura, etc.). Para o nosso projeto, nós utilizamos somente os arquivos XML.
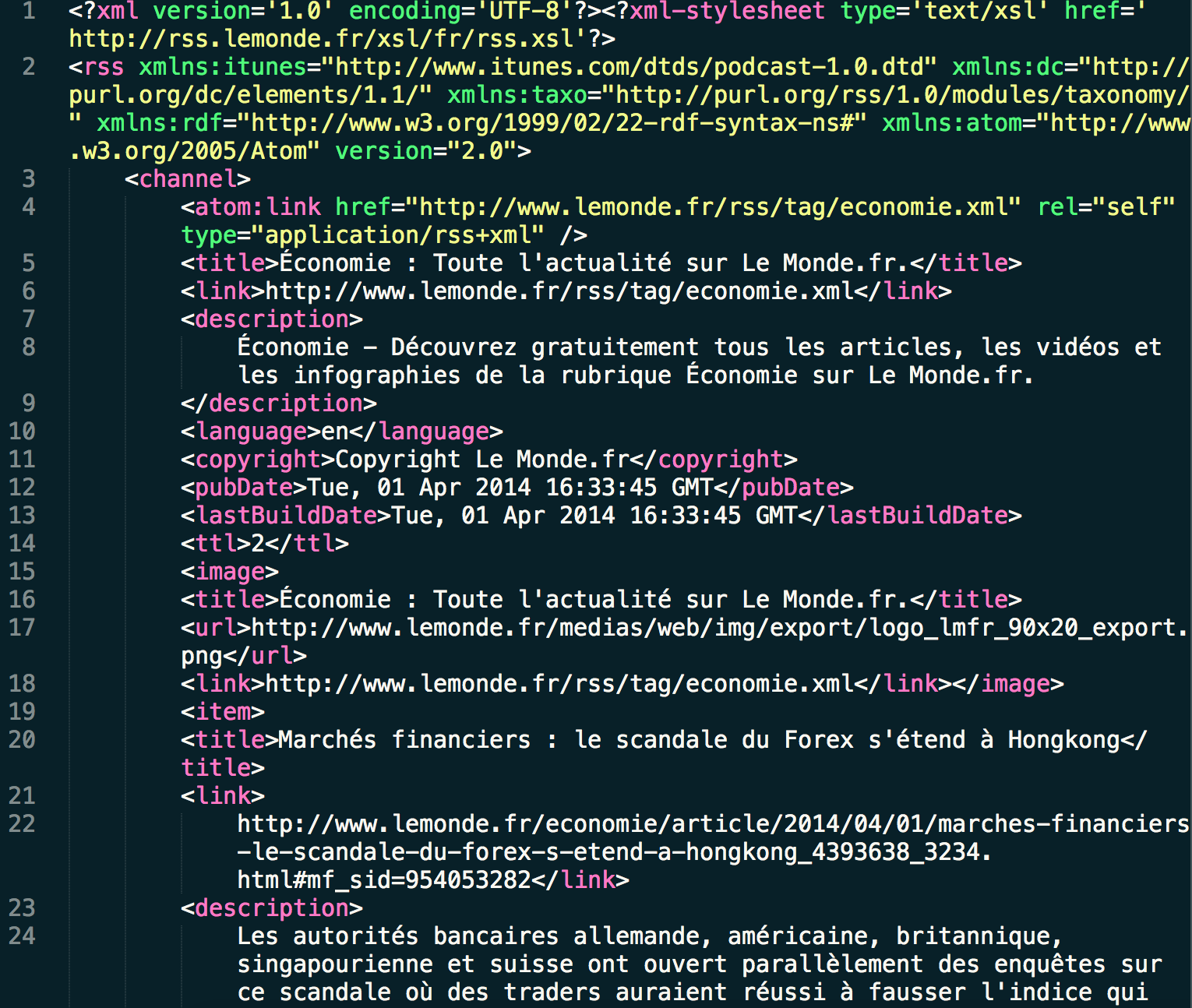
Exemplo de um arquivo XML utilizado no projeto:
Nosso programa extrai todo conteúdo presente entre as tag <title> e <description> de cada arquivo XML. Como existe a possibilidade de haver feeds RSS repetidos é importante se assegurar que cada arquivo será tratado somente uma única vez. Os dados são em seguida tratados para realizar a substituição dos caracteres especiais e a exclusão das imagens e outros dados que não são tratados pelo programa.
Exemplo das tags <title> e <description> para verificar qual o tipo de limpeza devemos efetuar:

Duas saídas são produzidas: Uma no formato TXT e outra no formato XML. O Formato TXT contém descrições antes de cada título (ex. Title: L'Unedic a versé 756 millions d'euros d'allocations chômage à tort en 2013 § Description:L'Unedic, qui gère les allocations chômage, estime que « le poids des indus rapportés aux dépenses d'indemnisation est resté stable, à 2,52 % ». §) e formato XML mantém as tags <title> e <description>.
Saída da Ferramenta 1

Ao escrever nosso programa nós tivemos que contornar alguns problemas. O primeiro deles foi a diferença de codificação dos caracteres. Os arquivos não possuem codificações diferentes. Nós podemos encontrar arquivos codificados em iso-8859-x ou utf-8, por exemplo. Porém, nós queríamos que todos as saídas de resultado estivessem codificados em utf-8. Um outro problema diz respeito à formatação dos arquivos, pois alguns deles contêm tag em linha diferentes e outros na mesma linha. Como nós não queríamos ter escrever dois script diferentes para cada caso, nós tivemos então que encontrar um meio para tratá-los com um único script.
A realização correta desta etapa foi muito importante, pois os resultados produzidos pela Caixa de Ferramentas 1 são reutilizados pelas CdF 2, CdF 3 e CdF 4. Deixar tags HTML nos arquivos, por exemplo, poderia ter uma consequência grave no momento de realizar a etiquetagem das partes do discurso.
Perl
Vocês irão perceber que nossos programas são classificados de duas distintas: "Puro Perl" e "Módulos Perl". Nos dois casos, nós utilizamos a linguagem Perl (v5.xx.x), porém nos programas que nós chamamos "Perl Puro" nós utilizamos uma abordagem direta. Isto quer dizer que todas as etapas realizadas no tratamento dos dados são visíveis no programa e não há nenhum programa externo em Perl (módulos) que poderiam introduzir variáveis externas não declaradas capazes de desestabilizar o programa. Neste caso, nós utilzamos expressões regulares (regex) para encontrar as informações que nós gostaríamos de extrair.
Este script utilizar uma abordagem "Perl puro". Para executar o script, é necessário utilizar o comando "perl nome_do_progama.p pasta_de_arquivos" no terminal. Este programa cria duas saídas(TXT e XML, linhas 23-26) e lê o caminho do arquivo para encontrar os arquivos corretos com auxílio de uma função recursiva (linha 28, função linha 40-95).  Esta função chama a função responsável pela limpeza do texto (linhas 65 e 78)
Esta função chama a função responsável pela limpeza do texto (linhas 65 e 78)  e verifica também se nós não tratamos várias vez o mesmo texto, utilizando um hash para armazenar apenas uma cópia de cada texto. Nós incluímos também as tags XML no arquivo de saída. Por fim, nós escrevemos os resultados nos dois arquivos (linhas 33 e 36).
e verifica também se nós não tratamos várias vez o mesmo texto, utilizando um hash para armazenar apenas uma cópia de cada texto. Nós incluímos também as tags XML no arquivo de saída. Por fim, nós escrevemos os resultados nos dois arquivos (linhas 33 e 36).
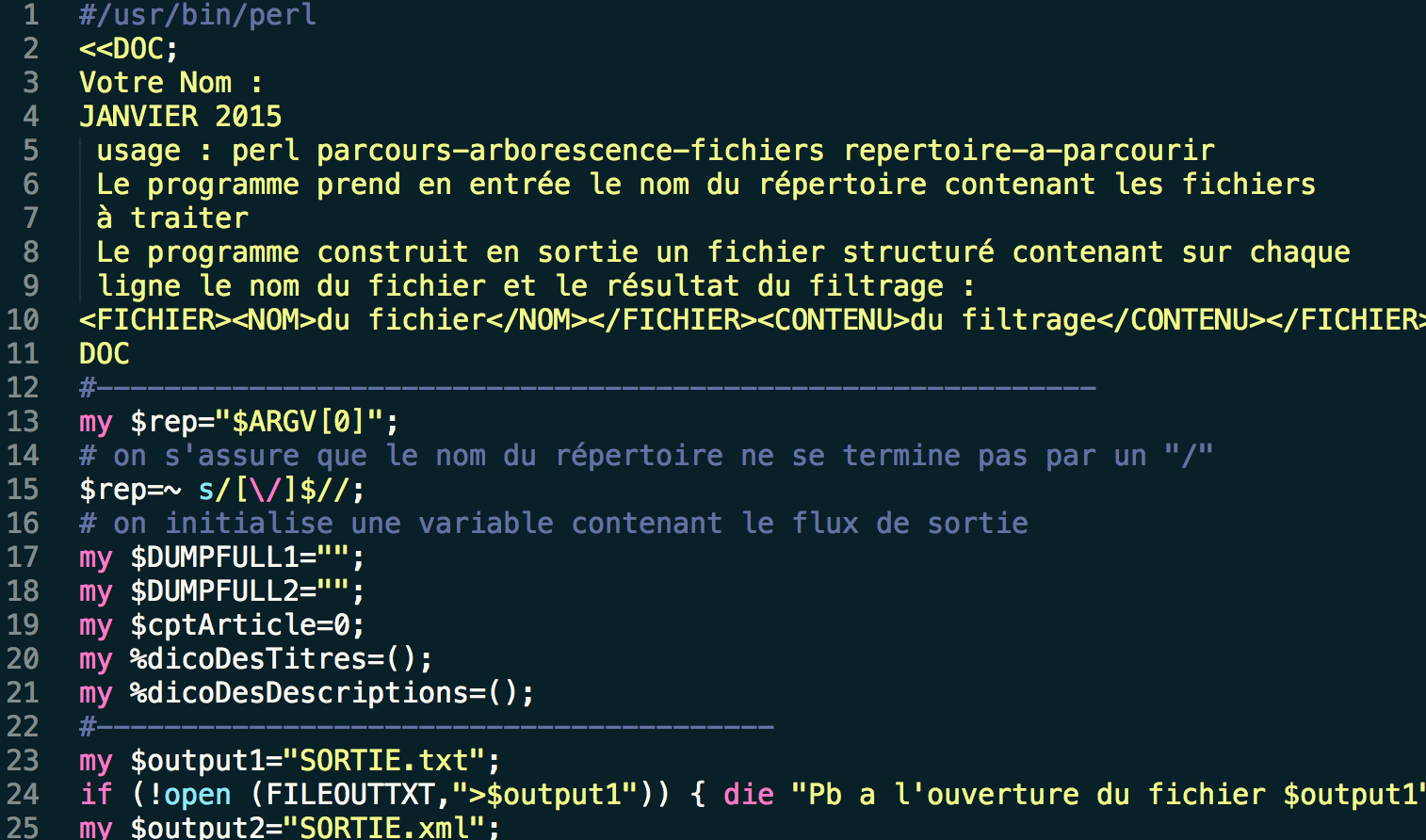
- #/usr/bin/perl
- <<DOC;
- Seu nome :
- JANVIER 2015
- utilização : perl parcours-arborescence-fichiers repertoire-a-parcourir
- O programa recebe como argumento de entrada o nome da pasta contendo os arquivos a serem tratados
- O programa constrói na saída um arquivo estruturado contendo em cada linha
- o nome do arquivo e o resultado da filtragem :
- <FICHIER><NOM>du fichier</NOM></FICHIER><CONTENU>du filtrage</CONTENU></FICHIER>
- DOC
- #-----------------------------------------------------------
- my $rep="$ARGV[0]";
- # on s'assure que le nom du répertoire ne se termine pas par un "/"
- $rep=~ s/[\/]$//;
- # on initialise une variable contenant le flux de sortie
- my $DUMPFULL1="";
- my $DUMPFULL2="";
- my $cptArticle=0;
- my %dicoDesTitres=();
- my %dicoDesDescriptions=();
- #----------------------------------------
- my $output1="SORTIE.txt";
- if (!open (FILEOUTTXT,">$output1")) { die "Pb a l'ouverture du fichier $output1"};
- my $output2="SORTIE.xml";
- if (!open (FILEOUTXML,">$output2")) { die "Pb a l'ouverture du fichier $output2"};
- #----------------------------------------
- &parcoursarborescencefichiers($rep); #recurse!
- #----------------------------------------
- print FILEOUTXML "<?xml version=\"1.0\" encoding=\"iso-8859-1\" ?>\n";
- print FILEOUTXML "<PARCOURS>\n";
- print FILEOUTXML "<NOM>SF</NOM>\n";
- print FILEOUTXML "<FILTRAGE>".$DUMPFULL1."</FILTRAGE>\n";
- print FILEOUTXML "</PARCOURS>\n";
- close(FILEOUTXML);
- print FILEOUTTXT $DUMPFULL2;
- close(FILEOUTTXT);
- exit;
- #----------------------------------------------
- sub parcoursarborescencefichiers {
- my $path = shift(@_);
- opendir(DIR, $path) or die "can't open $path: $!\n";
- my @files = readdir(DIR);
- closedir(DIR);
- foreach my $file (@files) {
- next if $file =~ /^\.\.?$/;
- $file = $path."/".$file;
- if (-d $file) {
- &parcoursarborescencefichiers($file); #recurse!
- }
- if (-f $file) {
- if ($file=~/\.xml$/) {
- print $i++,"\n";
- open(FILEIN,$file);
- while (my $ligne=<FILEIN>) {
- if ($ligne=~/<\/item>/) {
- $DUMPFULL1.="</article>\n";
- }
- if ($ligne=~/<item>/) {
- $cptArticle++;
- $DUMPFULL1.="<article numero=\"$cptArticle\">\n";
- }
- if ($ligne=~/<description>(.+?)<\/description>/) {
- my $text=$1;
- $text=&nettoieText($text);
- if (!(exists($dicoDesDescriptions{$text}))) {
- $DUMPFULL1.="<description>$text</description>\n";
- $DUMPFULL2.=$text."\n";
- $dicoDesDescriptions{$text}++;
- }
- else {
- $dicoDesDescriptions{$text}++;
- $DUMPFULL1.="<description>-</description>\n";
- }
- }
- if ($ligne=~/<title>(.+?)<\/title>/) {
- my $text=$1;
- $text=&nettoieText($text);
- if (!(exists($dicoDesTitres{$text}))) {
- $DUMPFULL1.="<abstract>$text</abstract>\n";
- $DUMPFULL2.=$text."\n";
- $dicoDesTitres{$text}++;
- }
- else {
- $dicoDesTitres{$text}++;
- $DUMPFULL1.="<abstract>-</abstract>\n";
- }
- }
- }
- close(FILEIN);
- }
- }
- }
- }
- #----------------------------------------------
- sub nettoieText {
- my $texte=shift;
- $texte =~ s/</</g;
- $texte =~ s/>/>/g;
- $texte =~ s/<a href[^>]+>//g;
- $texte =~ s/<img[^>]+>//g;
- $texte =~ s/<\/a>//g;
- $texte =~ s/&#39;/'/g;
- $texte =~ s/&#34;/"/g;
- $texte =~ s/<[^>]+>//g;
- $texte =~ s/é/é/g;
- $texte =~ s/ê/ê/g;
- return $texte;
- }
#/usr/bin/perl
<<DOC;
Votre Nom :
JANVIER 2015
usage : perl parcours-arborescence-fichiers repertoire-a-parcourir
Le programme prend en entrée le nom du répertoire contenant les fichiers
à traiter
Le programme construit en sortie un fichier structuré contenant sur chaque
ligne le nom du fichier et le résultat du filtrage :
<FICHIER><NOM>du fichier</NOM></FICHIER><CONTENU>du filtrage</CONTENU></FICHIER>
DOC
#-----------------------------------------------------------
my $rep="$ARGV[0]";
# on s'assure que le nom du répertoire ne se termine pas par un "/"
$rep=~ s/[\/]$//;
# on initialise une variable contenant le flux de sortie
my $DUMPFULL1="";
my $DUMPFULL2="";
my $cptArticle=0;
my %dicoDesTitres=();
my %dicoDesDescriptions=();
#----------------------------------------
my $output1="SORTIE.txt";
if (!open (FILEOUTTXT,">$output1")) { die "Pb a l'ouverture du fichier $output1"};
my $output2="SORTIE.xml";
if (!open (FILEOUTXML,">$output2")) { die "Pb a l'ouverture du fichier $output2"};
#----------------------------------------
&parcoursarborescencefichiers($rep); #recurse!
#----------------------------------------
print FILEOUTXML "<?xml version=\"1.0\" encoding=\"iso-8859-1\" ?>\n";
print FILEOUTXML "<PARCOURS>\n";
print FILEOUTXML "<NOM>SF</NOM>\n";
print FILEOUTXML "<FILTRAGE>".$DUMPFULL1."</FILTRAGE>\n";
print FILEOUTXML "</PARCOURS>\n";
close(FILEOUTXML);
print FILEOUTTXT $DUMPFULL2;
close(FILEOUTTXT);
exit;
#----------------------------------------------
sub parcoursarborescencefichiers {
my $path = shift(@_);
opendir(DIR, $path) or die "can't open $path: $!\n";
my @files = readdir(DIR);
closedir(DIR);
foreach my $file (@files) {
next if $file =~ /^\.\.?$/;
$file = $path."/".$file;
if (-d $file) {
&parcoursarborescencefichiers($file); #recurse!
}
if (-f $file) {
if ($file=~/\.xml$/) {
print $i++,"\n";
open(FILEIN,$file);
while (my $ligne=<FILEIN>) {
if ($ligne=~/<\/item>/) {
$DUMPFULL1.="</article>\n";
}
if ($ligne=~/<item>/) {
$cptArticle++;
$DUMPFULL1.="<article numero=\"$cptArticle\">\n";
}
if ($ligne=~/<description>(.+?)<\/description>/) {
my $text=$1;
$text=&nettoieText($text);
if (!(exists($dicoDesDescriptions{$text}))) {
$DUMPFULL1.="<description>$text</description>\n";
$DUMPFULL2.=$text."\n";
$dicoDesDescriptions{$text}++;
}
else {
$dicoDesDescriptions{$text}++;
$DUMPFULL1.="<description>-</description>\n";
}
}
if ($ligne=~/<title>(.+?)<\/title>/) {
my $text=$1;
$text=&nettoieText($text);
if (!(exists($dicoDesTitres{$text}))) {
$DUMPFULL1.="<abstract>$text</abstract>\n";
$DUMPFULL2.=$text."\n";
$dicoDesTitres{$text}++;
}
else {
$dicoDesTitres{$text}++;
$DUMPFULL1.="<abstract>-</abstract>\n";
}
}
}
close(FILEIN);
}
}
}
}
#----------------------------------------------
sub nettoieText {
my $texte=shift;
$texte =~ s/</</g;
$texte =~ s/>/>/g;
$texte =~ s/<a href[^>]+>//g;
$texte =~ s/<img[^>]+>//g;
$texte =~ s/<\/a>//g;
$texte =~ s/&#39;/'/g;
$texte =~ s/&#34;/"/g;
$texte =~ s/<[^>]+>//g;
$texte =~ s/é/é/g;
$texte =~ s/ê/ê/g;
return $texte;
}
Nós apresentamos aqui uma segunda versão de CdF 1 que utiliza um dos módulos disponíveis em Perl. A razão pela qual nós distinguimos essas duas categorias é devido ao fato de que os módulos são programas adicionais já escritos em Perl que sevem ser baixados separadamanente. Isto pode ser feito feitos de várias maneiras diferentes que váriam em função do sistema operacional utilizado. Normalmente, a maneira fácil é utilizar um gerenciado de pacotes (como Homebrew para MacOs, Chocolatey para Windows, etc.) para poder baixar e instalar corretamente esses módulos com apenas alguns cliques.
Este script utiliza a abordagem "Módulos Perl". Nós utilizamos neste script os módulos XML::RSS e Unicode::String (atenção à diferença entre letras maiúsculas e minúsculas!). Desta forma nós podemos utilizar os analizadores (parser) de arquivos XML e converter o texto em utf-8.  O script verifica a codificafação (em maiúsculo uc) na primeira linha da string "UTF-8" e caso ela não seja a mesma, nós utilizamos o módulo Unicode::String para converter o arquivo em utf-8. A outra grande diferença em relação ao outro programa onde nós utilizamos expressões regulares (regex) para extrair os títulos e as descrições, aqui nós utilizamos XML::RSS para fazê-lo (linhas 25-26). Ou seja, como no primeiro programa, nós nos certificamos que nós tratamos cada texto apenas uma vez e o texto é limpo, utilizando uma função que contém vários s///g para substituir os caracteres indesejáveis pelos seus equivalentes.
O script verifica a codificafação (em maiúsculo uc) na primeira linha da string "UTF-8" e caso ela não seja a mesma, nós utilizamos o módulo Unicode::String para converter o arquivo em utf-8. A outra grande diferença em relação ao outro programa onde nós utilizamos expressões regulares (regex) para extrair os títulos e as descrições, aqui nós utilizamos XML::RSS para fazê-lo (linhas 25-26). Ou seja, como no primeiro programa, nós nos certificamos que nós tratamos cada texto apenas uma vez e o texto é limpo, utilizando uma função que contém vários s///g para substituir os caracteres indesejáveis pelos seus equivalentes.
- #!/usr/bin/perl
- use XML::RSS;
- use Unicode::String qw(utf8);
- #----------------------------------------------------------
- my $encodagesortie="utf-8";
- my $encodage=`file -i $ARGV[0] | cut -d= -f2`;
- open(OUT1,">:encoding($encodagesortie)","sortie-textebrut-avec-xmlrss.txt");
- open(OUT2,">:encoding($encodagesortie)","sortie-textexml-avec-xmlrss.xml");
- print OUT2 "<?xml version=\"1.0\" encoding=\"$encodagesortie\" ?>\n";
- print OUT2 "<file>\n";
- print OUT2 "<name>$ARGV[0]</name>\n";
- #-----------------------------------------------------------
- my $file="$ARGV[0]";
- my $rss=new XML::RSS;
- #-----------------------------------------------------------
- eval {$rss->parsefile($file); };
- if( $@ ) {
- $@ =~ s/at \/.*?$//s; # remove module line number
- print STDERR "\nERROR in '$file':\n$@\n";
- } else {
- my $date=$rss->{'channel'}->{'pubDate'};
- print OUT2 "<date>$date</date>\n";
- print OUT2 "<items>\n";
- foreach my $item (@{$rss->{'items'}}) {
- my $titre=$item->{'title'};
- my $resume=$item->{'description'};
- $titre=&nettoietexte($titre);
- $resume=&nettoietexte($resume);
- if (uc($encodage) ne "UTF-8") {utf8($titre);utf8($resume);}
- print OUT1 "Titre : $titre \n";
- print OUT1 "Resume : $resume \n";;
- print OUT2
- "<item><title>$titre</title><abstract>$resume</abstract></item>\n";
- }
- }
- #----------------------------------------------------------
- print OUT2 "</items>\n</file>\n";
- close(OUT1);
- close(OUT2);
- close(FILE);
- exit;
- #----------------------------------------------------------
- #----------------------------------------------------------
- sub nettoietexte {
- my $texte=shift;
- $texte=~s/'/'/g;
- $texte=~s/"/"/g;
- $texte =~ s/</</g;
- $texte =~ s/>/>/g;
- $texte =~ s/<a href[^>]+>//g;
- $texte =~ s/<img[^>]+>//g;
- $texte =~ s/<\/a>//g;
- $texte =~ s/&#39;/'/g;
- $texte =~ s/&#34;/"/g;
- $texte =~ s/<[^>]+>//g;
- return $texte;
- }
#!/usr/bin/perl
use XML::RSS;
use Unicode::String qw(utf8);
#----------------------------------------------------------
my $encodagesortie="utf-8";
my $encodage=`file -i $ARGV[0] | cut -d= -f2`;
open(OUT1,">:encoding($encodagesortie)","sortie-textebrut-avec-xmlrss.txt");
open(OUT2,">:encoding($encodagesortie)","sortie-textexml-avec-xmlrss.xml");
print OUT2 "<?xml version=\"1.0\" encoding=\"$encodagesortie\" ?>\n";
print OUT2 "<file>\n";
print OUT2 "<name>$ARGV[0]</name>\n";
#-----------------------------------------------------------
my $file="$ARGV[0]";
my $rss=new XML::RSS;
#-----------------------------------------------------------
eval {$rss->parsefile($file); };
if( $@ ) {
$@ =~ s/at \/.*?$//s; # remove module line number
print STDERR "\nERROR in '$file':\n$@\n";
} else {
my $date=$rss->{'channel'}->{'pubDate'};
print OUT2 "<date>$date</date>\n";
print OUT2 "<items>\n";
foreach my $item (@{$rss->{'items'}}) {
my $titre=$item->{'title'};
my $resume=$item->{'description'};
$titre=&nettoietexte($titre);
$resume=&nettoietexte($resume);
if (uc($encodage) ne "UTF-8") {utf8($titre);utf8($resume);}
print OUT1 "Titre : $titre \n";
print OUT1 "Resume : $resume \n";;
print OUT2
"<item><title>$titre</title><abstract>$resume</abstract></item>\n";
}
}
#----------------------------------------------------------
print OUT2 "</items>\n</file>\n";
close(OUT1);
close(OUT2);
close(FILE);
exit;
#----------------------------------------------------------
#----------------------------------------------------------
sub nettoietexte {
my $texte=shift;
$texte=~s/'/'/g;
$texte=~s/"/"/g;
$texte =~ s/</</g;
$texte =~ s/>/>/g;
$texte =~ s/<a href[^>]+>//g;
$texte =~ s/<img[^>]+>//g;
$texte =~ s/<\/a>//g;
$texte =~ s/&#39;/'/g;
$texte =~ s/&#34;/"/g;
$texte =~ s/<[^>]+>//g;
return $texte;
}Perl com XPATH
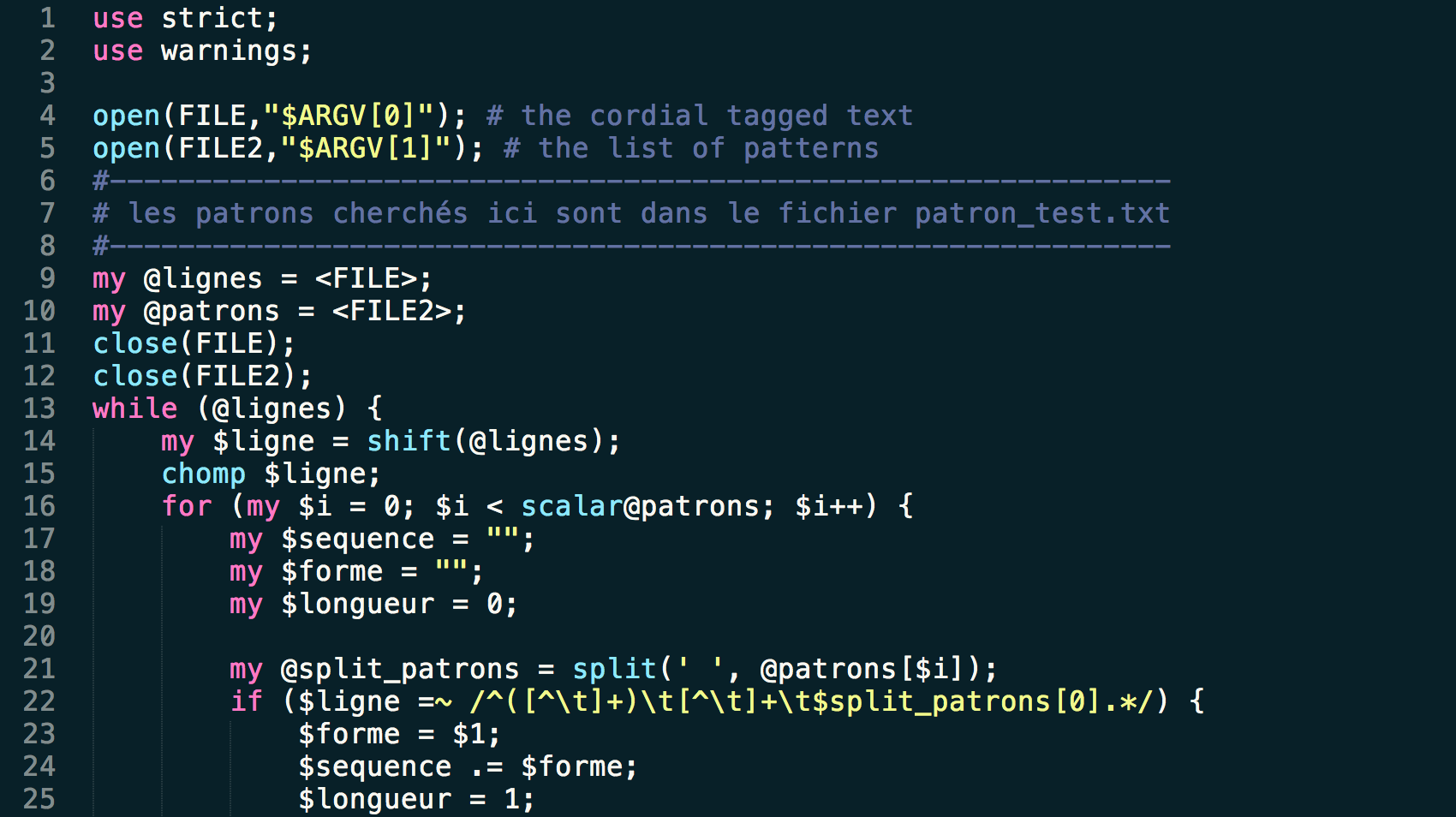
A terceira versão do script utiliza um módulo diferente: XML::XPath. Com a utilização desse módulo, nós temos um script que se assemelha mais com o script qui utiliza XML::RSS, exceto na diferença entre maiúsculas e minúsculas, o módulo utiliza XPath para analizar a estrutura XML e encontrar os elementos contidos nas tags buscadas. 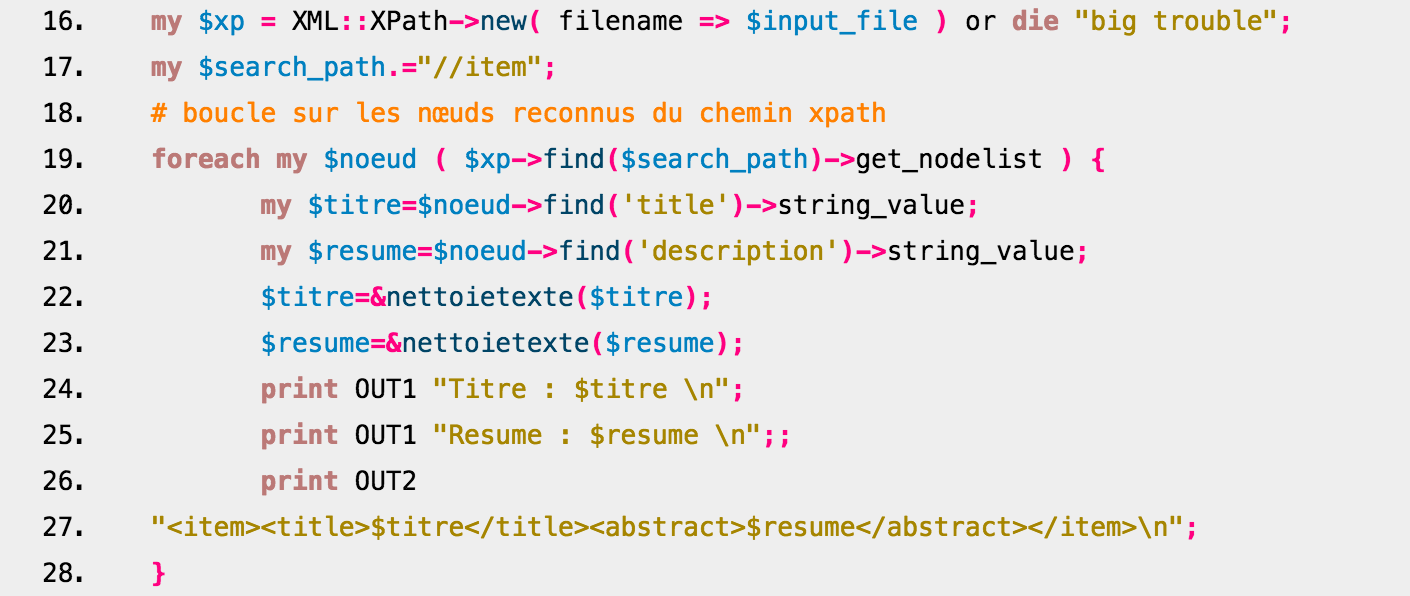 Este script cria igualmente duas saídas (XML e TXT) e limpa os dados com auxílio de uma função que substitui os caracteres indesejáveis por seus equivalentes.
Este script cria igualmente duas saídas (XML e TXT) e limpa os dados com auxílio de uma função que substitui os caracteres indesejáveis por seus equivalentes.
- #/usr/bin/perl
- use XML::XPath;
- # On vérifie le nombre d'arguments de l'appel au script ($0 : le nom du script)
- if($#ARGV!=0){
- print "usage : perl $0 fichier_tag fichier_motif";
- exit; }
- #----------------------------------------------------------------------------------
- -----------------------------------------------------------------
- my $encodagesortie="utf-8";
- open(OUT1,">:encoding($encodagesortie)","sortie-textebrut-avec-xmlxpath.txt");
- open(OUT2,">:encoding($encodagesortie)","sortie-textexml-avec-xmlxpath.xml");
- print OUT2 "<?xml version=\"1.0\" encoding=\"$encodagesortie\" ?>\n";
- print OUT2 "<file>\n";
- print OUT2 "<name>$ARGV[0]</name>\n";
- my $input_file= shift @ARGV;
- my $xp = XML::XPath->new( filename => $input_file ) or die "big trouble";
- my $search_path.="//item";
- # boucle sur les nœuds reconnus du chemin xpath
- foreach my $noeud ( $xp->find($search_path)->get_nodelist ) {
- my $titre=$noeud->find('title')->string_value;
- my $resume=$noeud->find('description')->string_value;
- $titre=&nettoietexte($titre);
- $resume=&nettoietexte($resume);
- print OUT1 "Titre : $titre \n";
- print OUT1 "Resume : $resume \n";;
- print OUT2
- "<item><title>$titre</title><abstract>$resume</abstract></item>\n";
- }
- #----------------------------------------------------------
- print OUT2 "</items>\n</file>\n";
- close(OUT1);
- close(OUT2);
- close(FILE);
- exit;
- sub nettoietexte {
- my $texte=shift;
- $texte=~s/'/'/g;
- $texte=~s/"/"/g;
- $texte =~ s/</</g;
- $texte =~ s/>/>/g;
- $texte =~ s/<a href[^>]+>//g;
- $texte =~ s/<img[^>]+>//g;
- $texte =~ s/<\/a>//g;
- $texte =~ s/&#39;/'/g;
- $texte =~ s/&#34;/"/g;
- $texte =~ s/<[^>]+>//g;
- return $texte;
- }
#/usr/bin/perl
use XML::XPath;
# On vérifie le nombre d'arguments de l'appel au script ($0 : le nom du script)
if($#ARGV!=0){
print "usage : perl $0 fichier_tag fichier_motif";
exit; }
#----------------------------------------------------------------------------------
-----------------------------------------------------------------
my $encodagesortie="utf-8";
open(OUT1,">:encoding($encodagesortie)","sortie-textebrut-avec-xmlxpath.txt");
open(OUT2,">:encoding($encodagesortie)","sortie-textexml-avec-xmlxpath.xml");
print OUT2 "<?xml version=\"1.0\" encoding=\"$encodagesortie\" ?>\n";
print OUT2 "<file>\n";
print OUT2 "<name>$ARGV[0]</name>\n";
my $input_file= shift @ARGV;
my $xp = XML::XPath->new( filename => $input_file ) or die "big trouble";
my $search_path.="//item";
# boucle sur les nœuds reconnus du chemin xpath
foreach my $noeud ( $xp->find($search_path)->get_nodelist ) {
my $titre=$noeud->find('title')->string_value;
my $resume=$noeud->find('description')->string_value;
$titre=&nettoietexte($titre);
$resume=&nettoietexte($resume);
print OUT1 "Titre : $titre \n";
print OUT1 "Resume : $resume \n";;
print OUT2
"<item><title>$titre</title><abstract>$resume</abstract></item>\n";
}
#----------------------------------------------------------
print OUT2 "</items>\n</file>\n";
close(OUT1);
close(OUT2);
close(FILE);
exit;
sub nettoietexte {
my $texte=shift;
$texte=~s/'/'/g;
$texte=~s/"/"/g;
$texte =~ s/</</g;
$texte =~ s/>/>/g;
$texte =~ s/<a href[^>]+>//g;
$texte =~ s/<img[^>]+>//g;
$texte =~ s/<\/a>//g;
$texte =~ s/&#39;/'/g;
$texte =~ s/&#34;/"/g;
$texte =~ s/<[^>]+>//g;
return $texte;
}Puro Perl
Nossa versão realiza as mesma tarefa, mas de uma maneira ligeiramente diferente. Como vocês podem notar, nossa versão é muito mais longa.Isso é em parte devido aos comentários que nós inserimos no código, mas também pela nossa função de limpeza (nettoietexte()**). Nós percebemos que haviam certos caracteres na saída que não estavam sendo exibidos corretamente. Portanto, nós adicionamos mais algumas expressões regulares para capturas essas exceções. 
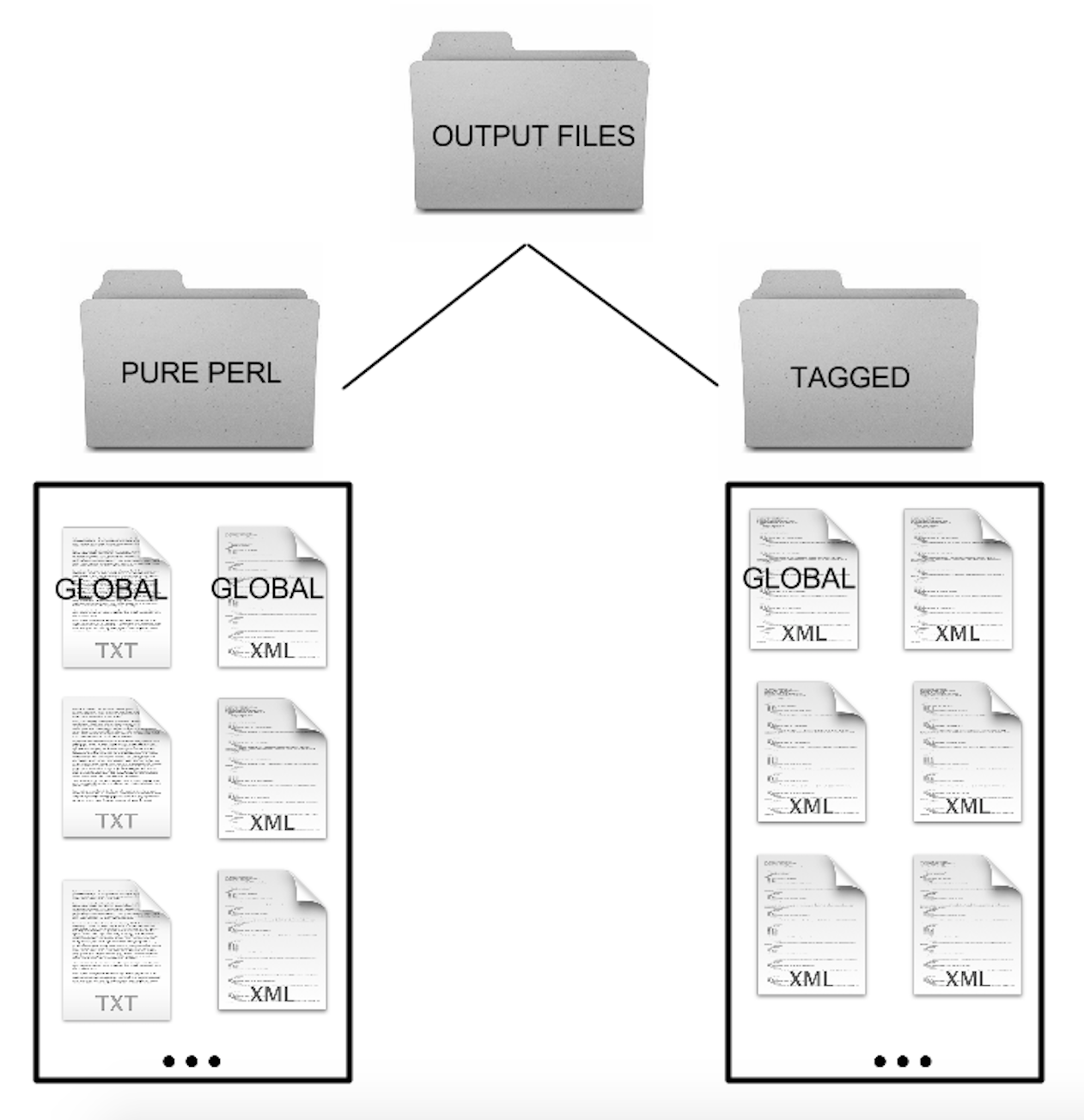
Nós também modificamos um aspecto mais importante do código. Nós excluímos a saída global que continha todos os temas juntos. Nós fizemos isso para cada tema possui o seu próprio arquivo(um XML e outro TXT)  A separação dos dados dessa forma é especialmente importante para CdF 3. Colocar essa funcionalidade no código agora, simplifica a nossa tarefa mais adiante.
A separação dos dados dessa forma é especialmente importante para CdF 3. Colocar essa funcionalidade no código agora, simplifica a nossa tarefa mais adiante.
** Você perceberá que oo nomes de algumas variaveis são diferentes. A ideia, no entanto, é a mesma.
***O código não é 100% "Puro Perl", nós utilizamos o módulo Unicode::String para converter o texto em utf-8.
O código :
- #/usr/bin/perl
- use Unicode::String qw(utf8);
- #lire l'entrée standard
- my $rep="$ARGV[0]";
- # éliminier les possibles "/" à la fin du nom du dossier
- $rep=~ s/[\/]$//;
- # liste pour stocker les items déjà traités
- my %dictionnairedesitems = ();
- # liste pour stocker les rubriques déjà traités
- my %dictionnairesdesrubriques = ();
- # appeler la fonction extraire_rubrique() pour lire les dossiers et extraire les rubriques des fichiers
- &extraire_rubrique($rep);
- my @liste_rubriques = keys(%dictionnairesdesrubriques);
- # pour chaque rubrique, créer un fichier de sortie .xml et un fichier .txt
- foreach my $rub (@liste_rubriques) {
- my $output1= "SORTIE-extract-txt-".$rub.".xml";
- my $output2= "SORTIE-extract-txt-".$rub.".txt";
- # créer fichier .xml de sortie
- open (FILEOUTXML, ">:encoding(utf-8)", $output1) or die "Could not open file @output1!"; # open file for writing
- # créer fichier .txt de sortie
- open (FILEOUTTXT, ">:encoding(utf-8)", $output2) or die "Could not open file $output2!"; # open file for writing)
- # écrier déclaration d'en-tête du fichier xml
- print FILEOUTXML "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
- print FILEOUTXML "<PARCOURS>\n";
- #fermer les deux fichiers
- close(FILEOUTXML);
- close(FILEOUTTXT);
- print $output1;
- }
- # appeler lire_et_ecrire_xml() pour lire tous les fichiers xml et créer les sorties
- &lire_et_ecrire_xml($rep);
- foreach my $rub (@liste_rubriques)
- {
- my $output1="SORTIE-extract-txt-".$rub.".xml";
- if (!open (FILEOUTXML,">>:encoding(utf-8)", $output1))
- {
- die "Pb a l'ouverture du fichier $output1";
- }
- print FILEOUTXML "</PARCOURS>\n";
- close(FILEOUTXML);
- }
- exit;
- #########################################################################################################
- # #
- # cette fonction reçoit un nom de dossier comme argument et lit tous les fichiers .xml du dossier #
- # Pour chaque fichier lu, la fonction extrait les texte des balise <title> et <description>, ainsi que #
- # les dates présente en <pubDate> et <rubrique> #
- # Ce contenu insère dans des fichiers .xml et .txt de sortie de la rubrique correspondante #
- # #
- #########################################################################################################
- sub lire_et_ecrire_xml {
- # lire nom de dossier passé comme argument
- my $path = shift(@_);
- # ouvrir dossier
- opendir(DIR, $path) or die "can't open $path: $!\n";
- # lire itens dans le dossier
- my @files = readdir(DIR);
- closedir(DIR);
- # fermer dossier
- foreach my $file (@files)
- {
- # ignorer les items cachés
- next if $file =~ /^\.\.?$/;
- # construire le chemin complet avec le nom du dossier + item traité
- $file = $path."/".$file;
- # vérifier si l'item traité est dossier
- if (-d $file)
- {
- # si l'item qu'on est en train de traiter est un dossier, on recommence la procédure
- &lire_et_ecrire_xml($file);
- }
- # vérifier si l'item traité un fichier IF1
- if (-f $file)
- {
- # vérifier s'il s'agit d'un fichier .xml qui ne contient pas fil dans le nom iF2
- if (($file=~/\.xml$/) && ($file!~/\/fil.+\.xml$/))
- {
- # ouvrir fichier
- open(FILE, $file);
- # variable pour stocker le contenu du fichier
- my $texte="";
- #lire le contenu du fichier ligne à line
- while (my $ligne=<FILE>)
- {
- chomp $ligne;
- $texte .= $ligne;
- }
- # fermer fichier
- close(FILE);
- # regex pour capturer l'encodage du fichier
- $texte=~/encoding ?= ?[\'\"]([^\'\"]+)[\'\"]/i;
- # stocker l'encogade du fichier
- my $encodage=$1;
- # vérifier si l'encodage n'est pas vide pour traiter le contenu IF3
- if ($encodage ne "")
- {
- # la variable temptexteXML stocke les contenus prêts à être écrits dans fichier .xml de sortie
- my $tmptexteXML="<file>\n";
- # créer balise avec le nom du fichier
- $tmptexteXML.="<name>$file</name>\n";
- # éliminier les balises avec des espaces en blanc
- $texte =~ s/> *</></g;
- # regex pour capturer date
- $texte=~/<pubDate>([^<]+)<\/pubDate>/;
- # stocker la valeur de date capturée par la regex
- $tmptexteXML.="<date>$1</date>\n";
- # insérer la balise <items>
- $tmptexteXML.="<items>\n";
- my $tmptexteBRUT="";
- open(FILE,"<:encoding($encodage)", $file);
- $texte="";
- # lire le fichier ligne à ligne
- while (my $ligne=<FILE>)
- {
- chomp $ligne;
- $texte .= $ligne;
- }
- close(FILE);
- $texte=~s/> *</></g;
- # on recherche la rubrique
- $texte=~/<channel><title>([^<]+)<\/title>/;
- # nettoyer le string rubrique
- my $rub=$1;
- $rub =~ s/Toute l'actualité sur Le Monde.fr.//gi;
- $rub=~s/é/e/gi;
- $rub=~s/è/e/gi;
- $rub=~s/ê/e/gi;
- $rub=~s/à/a/gi;
- $rub=~ s/Le ?Monde.fr ?://;
- $rub=~ s/ //g;
- $rub=uc($rub);
- my $output1="SORTIE-extract-txt-".$rub.".xml";
- my $output2="SORTIE-extract-txt-".$rub.".txt";
- if (!open (FILEOUTXML,">>:encoding(utf-8)", $output1)) { die "Pb a l'ouverture du fichier $output1"};
- if (!open (FILEOUTTXT,">>:encoding(utf-8)", $output2)) { die "Pb a l'ouverture du fichier $output2"};
- # lire texte pour extraire contenu des balises <title> et <description>
- while ($texte =~ /<item><title>(.+?)<\/title>.+?<description>(.+?)<\/description>/g)
- {
- # capturer contenu de la regex pour titre
- my $titre=$1;
- # capturer contenu de la regex pour description
- my $resume=$2;
- #
- $titre = &nettoyer_texte($1);
- $resume = &nettoyer_texte($2);
- # si le fichier n'est pas en UTF-8, convertir le string $titre et $resume en UTF-8
- if (uc($encodage) ne "UTF-8")
- {
- utf8($titre);
- utf8($resume);
- }
- # si le contenu de $resume n'a pas encore été traite, on doit le traiter
- if (!(exists($dictionnairedesitems{$resume})))
- {
- # créer contenu le fichier .txt
- $tmptexteBRUT.="§ $titre \n";
- $tmptexteBRUT.="$resume \n";
- # créer contenu pour fichier .xml
- $tmptexteXML.="<item><title>$titre</title><abstract>$resume</abstract></item>\n";
- # inclure contenu de $resume dans liste
- $dictionnairedesitems{$resume}++;
- } else {
- $tmptexteXML.="<item><title>-</title><abstract>-</abstract></item>\n";
- }
- } # fin while
- # rajouter la fin des balise <items> et <file>
- $tmptexteXML.="</items>\n</file>\n";
- # écrire contenu dans le fichier .xml
- print FILEOUTXML $tmptexteXML;
- # écrire contenu dans le fichier .txt
- print FILEOUTTXT $tmptexteBRUT;
- # fermer fichiers
- close FILEOUTXML;
- close FILEOUTTXT;
- } else {
- #si l'encaodre est vide afficher message
- print "$file ==> $encodage \n";
- } # fin IF3
- } # fin IF 2
- } # fin IF 1
- } # fin FOR
- } # fin lire_et_ecrire_xml()
- sub nettoyer_texte {
- my $texte=shift;
- $texte =~ s/</</g;
- $texte =~ s/>/>/g;
- $texte =~ s/<a href[^>]+>//g;
- $texte =~ s/<img[^>]+>//g;
- $texte =~ s/<\/a>//g;
- $texte =~ s/&#39;/'/g;
- $texte =~ s/&#34;/"/g;
- $texte =~ s/é/é/g;
- $texte =~ s/ê/ê/g;
- $texte =~ s/<[^>]+>//g;
- $texte =~ s/ / /g;
- $texte=~s/'/'/g;
- $texte=~s/"/"/g;
- $texte=~s/&#39;/'/g;
- $texte=~s/&#34;/"/g;
- return $texte;
- }
- ####################################################################################################
- # #
- # cette fonction reçoit un nom de dossier comme argument et lit tous les fichiers .xml du dossier #
- # Pour chaque fichier lu, la fonction extrait les rubriques et crée des fichiers de sortie #
- # possédant le nom de la rubrique #
- # #
- ####################################################################################################
- sub extraire_rubrique {
- #lire le nom dossier passé comme argument
- my $path = shift(@_);
- #ouvrir le dossier
- opendir(DIR, $path) or die "can't open $path: $!\n";
- #lire la liste de fichier du dossier
- my @files = readdir(DIR);
- closedir(DIR);
- # lire un à un les items du dossier
- foreach my $file (@files)
- {
- # ignorer les items cachés
- next if $file =~ /^\.\.?$/;
- # construire le chemin complet avec le nom du dossier + item traité
- $file = $path."/".$file;
- # vérifier si l'item est un dossier
- if (-d $file)
- {
- # si l'item qu'on est en train de traiter est un dossier, on recommence la procédure
- &extraire_rubrique($file);
- }
- # vérifier si l'item est un fichier - IF1
- if (-f $file)
- {
- # tester si fichier possède l'extension .xml et ne contient pas la substring fil dans le nom - IF2
- if (($file =~ /\.xml$/) && ($file!~/\/fil.+\.xml$/))
- {
- #ouvrir fichier .xml
- open(FILE,$file);
- #variable pour stocker le contenu du fichier .xml
- my $texte="";
- #lire toutes les lignes du fichier .xml
- while (my $ligne=<FILE>)
- {
- # effacer les retours à la ligne
- chomp $ligne;
- # stocker le contenu de ligne lue
- $texte .= $ligne;
- }
- # fermer le fichier .xml
- close(FILE);
- # regex pour capture l`encodage du fichier
- $texte =~ /encoding ?= ?[\'\"]([^\'\"]+)[\'\"]/i;
- # stocker le contenu trouvé par la regex
- my $encodage=$1;
- # vérifier la contenu de regex n'est pas vide IF3
- if ($encodage ne "")
- {
- # reouvrir le fichier avec l'encogade correcte
- open(FILE,"<:encoding($encodage)", $file);
- # variables pour stocker le contenu du fichier lu
- $texte="";
- # lire le fichier .xml
- while (my $ligne=<FILE>)
- {
- # effacer les retours à la ligne
- chomp $ligne;
- # stocker le contenu de ligne lue
- $texte .= $ligne;
- }
- # fermer le fichier .xml
- close(FILE);
- # effacer les espaces en blanc
- $texte =~ s/> *</></g;
- # capturer le contenu à l'intérieur des balises <title> - IF4
- if ($texte=~ /<channel><title>([^>]+)<\/title>/)
- {
- print $texte;
- # stocker la valeur de rubrique trouvée par la regex
- my $rub=$1;
- # nettoyer les noms des rubriques
- $rub =~ s/Toute l'actualité sur Le Monde.fr.//gi;
- $rub=~s/é/e/gi;
- $rub=~s/è/e/gi;
- $rub=~s/ê/e/gi;
- $rub=~s/à/a/gi;
- $rub=~ s/Le ?Monde.fr ?://i;
- $rub=~ s/ //g;
- $rub=uc($rub);
- # stocker la rubrique dans le dictionnaire des rubriques
- $dictionnairesdesrubriques{$rub}++;
- } # fin IF4
- } # fin IF3
- } # fin IF2
- } # fin IF1
- } # fin FOR
- } # fin extraire_rubrique()
#/usr/bin/perl
use Unicode::String qw(utf8);
#lire l'entrée standard
my $rep="$ARGV[0]";
# éliminier les possibles "/" à la fin du nom du dossier
$rep=~ s/[\/]$//;
# liste pour stocker les items déjà traités
my %dictionnairedesitems = ();
# liste pour stocker les rubriques déjà traités
my %dictionnairesdesrubriques = ();
# appeler la fonction extraire_rubrique() pour lire les dossiers et extraire les rubriques des fichiers
&extraire_rubrique($rep);
my @liste_rubriques = keys(%dictionnairesdesrubriques);
# pour chaque rubrique, créer un fichier de sortie .xml et un fichier .txt
foreach my $rub (@liste_rubriques) {
my $output1= "SORTIE-extract-txt-".$rub.".xml";
my $output2= "SORTIE-extract-txt-".$rub.".txt";
# créer fichier .xml de sortie
open (FILEOUTXML, ">:encoding(utf-8)", $output1) or die "Could not open file @output1!"; # open file for writing
# créer fichier .txt de sortie
open (FILEOUTTXT, ">:encoding(utf-8)", $output2) or die "Could not open file $output2!"; # open file for writing)
# écrier déclaration d'en-tête du fichier xml
print FILEOUTXML "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print FILEOUTXML "<PARCOURS>\n";
#fermer les deux fichiers
close(FILEOUTXML);
close(FILEOUTTXT);
print $output1;
}
# appeler lire_et_ecrire_xml() pour lire tous les fichiers xml et créer les sorties
&lire_et_ecrire_xml($rep);
foreach my $rub (@liste_rubriques)
{
my $output1="SORTIE-extract-txt-".$rub.".xml";
if (!open (FILEOUTXML,">>:encoding(utf-8)", $output1))
{
die "Pb a l'ouverture du fichier $output1";
}
print FILEOUTXML "</PARCOURS>\n";
close(FILEOUTXML);
}
exit;
#########################################################################################################
# #
# cette fonction reçoit un nom de dossier comme argument et lit tous les fichiers .xml du dossier #
# Pour chaque fichier lu, la fonction extrait les texte des balise <title> et <description>, ainsi que #
# les dates présente en <pubDate> et <rubrique> #
# Ce contenu insère dans des fichiers .xml et .txt de sortie de la rubrique correspondante #
# #
#########################################################################################################
sub lire_et_ecrire_xml {
# lire nom de dossier passé comme argument
my $path = shift(@_);
# ouvrir dossier
opendir(DIR, $path) or die "can't open $path: $!\n";
# lire itens dans le dossier
my @files = readdir(DIR);
closedir(DIR);
# fermer dossier
foreach my $file (@files)
{
# ignorer les items cachés
next if $file =~ /^\.\.?$/;
# construire le chemin complet avec le nom du dossier + item traité
$file = $path."/".$file;
# vérifier si l'item traité est dossier
if (-d $file)
{
# si l'item qu'on est en train de traiter est un dossier, on recommence la procédure
&lire_et_ecrire_xml($file);
}
# vérifier si l'item traité un fichier IF1
if (-f $file)
{
# vérifier s'il s'agit d'un fichier .xml qui ne contient pas fil dans le nom iF2
if (($file=~/\.xml$/) && ($file!~/\/fil.+\.xml$/))
{
# ouvrir fichier
open(FILE, $file);
# variable pour stocker le contenu du fichier
my $texte="";
#lire le contenu du fichier ligne à line
while (my $ligne=<FILE>)
{
chomp $ligne;
$texte .= $ligne;
}
# fermer fichier
close(FILE);
# regex pour capturer l'encodage du fichier
$texte=~/encoding ?= ?[\'\"]([^\'\"]+)[\'\"]/i;
# stocker l'encogade du fichier
my $encodage=$1;
# vérifier si l'encodage n'est pas vide pour traiter le contenu IF3
if ($encodage ne "")
{
# la variable temptexteXML stocke les contenus prêts à être écrits dans fichier .xml de sortie
my $tmptexteXML="<file>\n";
# créer balise avec le nom du fichier
$tmptexteXML.="<name>$file</name>\n";
# éliminier les balises avec des espaces en blanc
$texte =~ s/> *</></g;
# regex pour capturer date
$texte=~/<pubDate>([^<]+)<\/pubDate>/;
# stocker la valeur de date capturée par la regex
$tmptexteXML.="<date>$1</date>\n";
# insérer la balise <items>
$tmptexteXML.="<items>\n";
my $tmptexteBRUT="";
open(FILE,"<:encoding($encodage)", $file);
$texte="";
# lire le fichier ligne à ligne
while (my $ligne=<FILE>)
{
chomp $ligne;
$texte .= $ligne;
}
close(FILE);
$texte=~s/> *</></g;
# on recherche la rubrique
$texte=~/<channel><title>([^<]+)<\/title>/;
# nettoyer le string rubrique
my $rub=$1;
$rub =~ s/Toute l'actualité sur Le Monde.fr.//gi;
$rub=~s/é/e/gi;
$rub=~s/è/e/gi;
$rub=~s/ê/e/gi;
$rub=~s/à/a/gi;
$rub=~ s/Le ?Monde.fr ?://;
$rub=~ s/ //g;
$rub=uc($rub);
my $output1="SORTIE-extract-txt-".$rub.".xml";
my $output2="SORTIE-extract-txt-".$rub.".txt";
if (!open (FILEOUTXML,">>:encoding(utf-8)", $output1)) { die "Pb a l'ouverture du fichier $output1"};
if (!open (FILEOUTTXT,">>:encoding(utf-8)", $output2)) { die "Pb a l'ouverture du fichier $output2"};
# lire texte pour extraire contenu des balises <title> et <description>
while ($texte =~ /<item><title>(.+?)<\/title>.+?<description>(.+?)<\/description>/g)
{
# capturer contenu de la regex pour titre
my $titre=$1;
# capturer contenu de la regex pour description
my $resume=$2;
#
$titre = &nettoyer_texte($1);
$resume = &nettoyer_texte($2);
# si le fichier n'est pas en UTF-8, convertir le string $titre et $resume en UTF-8
if (uc($encodage) ne "UTF-8")
{
utf8($titre);
utf8($resume);
}
# si le contenu de $resume n'a pas encore été traite, on doit le traiter
if (!(exists($dictionnairedesitems{$resume})))
{
# créer contenu le fichier .txt
$tmptexteBRUT.="§ $titre \n";
$tmptexteBRUT.="$resume \n";
# créer contenu pour fichier .xml
$tmptexteXML.="<item><title>$titre</title><abstract>$resume</abstract></item>\n";
# inclure contenu de $resume dans liste
$dictionnairedesitems{$resume}++;
} else {
$tmptexteXML.="<item><title>-</title><abstract>-</abstract></item>\n";
}
} # fin while
# rajouter la fin des balise <items> et <file>
$tmptexteXML.="</items>\n</file>\n";
# écrire contenu dans le fichier .xml
print FILEOUTXML $tmptexteXML;
# écrire contenu dans le fichier .txt
print FILEOUTTXT $tmptexteBRUT;
# fermer fichiers
close FILEOUTXML;
close FILEOUTTXT;
} else {
#si l'encaodre est vide afficher message
print "$file ==> $encodage \n";
} # fin IF3
} # fin IF 2
} # fin IF 1
} # fin FOR
} # fin lire_et_ecrire_xml()
sub nettoyer_texte {
my $texte=shift;
$texte =~ s/</</g;
$texte =~ s/>/>/g;
$texte =~ s/<a href[^>]+>//g;
$texte =~ s/<img[^>]+>//g;
$texte =~ s/<\/a>//g;
$texte =~ s/&#39;/'/g;
$texte =~ s/&#34;/"/g;
$texte =~ s/é/é/g;
$texte =~ s/ê/ê/g;
$texte =~ s/<[^>]+>//g;
$texte =~ s/ / /g;
$texte=~s/'/'/g;
$texte=~s/"/"/g;
$texte=~s/&#39;/'/g;
$texte=~s/&#34;/"/g;
return $texte;
}
####################################################################################################
# #
# cette fonction reçoit un nom de dossier comme argument et lit tous les fichiers .xml du dossier #
# Pour chaque fichier lu, la fonction extrait les rubriques et crée des fichiers de sortie #
# possédant le nom de la rubrique #
# #
####################################################################################################
sub extraire_rubrique {
#lire le nom dossier passé comme argument
my $path = shift(@_);
#ouvrir le dossier
opendir(DIR, $path) or die "can't open $path: $!\n";
#lire la liste de fichier du dossier
my @files = readdir(DIR);
closedir(DIR);
# lire un à un les items du dossier
foreach my $file (@files)
{
# ignorer les items cachés
next if $file =~ /^\.\.?$/;
# construire le chemin complet avec le nom du dossier + item traité
$file = $path."/".$file;
# vérifier si l'item est un dossier
if (-d $file)
{
# si l'item qu'on est en train de traiter est un dossier, on recommence la procédure
&extraire_rubrique($file);
}
# vérifier si l'item est un fichier - IF1
if (-f $file)
{
# tester si fichier possède l'extension .xml et ne contient pas la substring fil dans le nom - IF2
if (($file =~ /\.xml$/) && ($file!~/\/fil.+\.xml$/))
{
#ouvrir fichier .xml
open(FILE,$file);
#variable pour stocker le contenu du fichier .xml
my $texte="";
#lire toutes les lignes du fichier .xml
while (my $ligne=<FILE>)
{
# effacer les retours à la ligne
chomp $ligne;
# stocker le contenu de ligne lue
$texte .= $ligne;
}
# fermer le fichier .xml
close(FILE);
# regex pour capture l`encodage du fichier
$texte =~ /encoding ?= ?[\'\"]([^\'\"]+)[\'\"]/i;
# stocker le contenu trouvé par la regex
my $encodage=$1;
# vérifier la contenu de regex n'est pas vide IF3
if ($encodage ne "")
{
# reouvrir le fichier avec l'encogade correcte
open(FILE,"<:encoding($encodage)", $file);
# variables pour stocker le contenu du fichier lu
$texte="";
# lire le fichier .xml
while (my $ligne=<FILE>)
{
# effacer les retours à la ligne
chomp $ligne;
# stocker le contenu de ligne lue
$texte .= $ligne;
}
# fermer le fichier .xml
close(FILE);
# effacer les espaces en blanc
$texte =~ s/> *</></g;
# capturer le contenu à l'intérieur des balises <title> - IF4
if ($texte=~ /<channel><title>([^>]+)<\/title>/)
{
print $texte;
# stocker la valeur de rubrique trouvée par la regex
my $rub=$1;
# nettoyer les noms des rubriques
$rub =~ s/Toute l'actualité sur Le Monde.fr.//gi;
$rub=~s/é/e/gi;
$rub=~s/è/e/gi;
$rub=~s/ê/e/gi;
$rub=~s/à/a/gi;
$rub=~ s/Le ?Monde.fr ?://i;
$rub=~ s/ //g;
$rub=uc($rub);
# stocker la rubrique dans le dictionnaire des rubriques
$dictionnairesdesrubriques{$rub}++;
} # fin IF4
} # fin IF3
} # fin IF2
} # fin IF1
} # fin FOR
} # fin extraire_rubrique()
Módulos Perl
A utilização dos módulos XML::Entities e HTML::Entities serve para modificar as entidades XML e HTML, códigos especiais que permitem a exibição de caracteres reservados em função do formato do documento (no nosso caso XML e HTML) nas suas representações gráficas reais. Por exemplo, "<" é um caracter especial em HTML e em XML que indica a aberta de uma tag. Para evitar que ele seja confundido com a abertura de uma tag no arquivo, nós dispomos das entidade. Desta forma ele não é interpretado de maneira incorreta, o que geraria o um arquivo mal formado. É por isso que vários outros caracteres "<" são indicados por "‹" no arquivo. Isso permite a distinção entre o que faz parte da estrura e aquilo faz parte do conteúdo do arquivo.
A utilização desses módulos nos script em Perl é feita da mesma maneira, XML::Entities sendo baseado em HTML::Entities. Para decodificar as entidades, só precisamos declarar os módulos da seguinte maneira:

A utilização é feita de seguinte maneira:

Para a ferramenta 1, nós escrevemos scripts em Perl utilizando as funções para excluir as entidades existentes nos arquivos, mas também os módulos XML::Entities e HTML::Entites. Nós temos dois scripts para Ferramenta 1 e Ferramenta 2, ou seja com e sem os módulos.
Nós percebemos que haviam tags de imagens dentros das tags de descrição. Mas o problema é que essas tags não estavam em codificadas como tags. Portanto, nós terminávamos por encontrar essas tags na saída final, o que é não era interessante para nosso resultado. Nós tivemos, então, que realizar um limpeza dos arquivos de resultado após a decodificação das entidades das tags de descrição.
- #/usr/bin/perl
- use Unicode::String qw(utf8);
- use XML::Entities;
- use HTML::Entities;
- use XML::RSS;
- #lire l'entrée standard
- my $rep="$ARGV[0]";
- # éliminier les possibles "/" à la fin du nom du dossier
- $rep=~ s/[\/]$//;
- # liste pour stocker les items déjà traités
- my %dictionnairedesitems = ();
- # liste pour stocker les rubriques déjà traités
- my %dictionnairesdesrubriques = ();
- # appeler la fonction extraire_rubrique() pour lire les dossiers et extraire les rubriques des fichiers
- &extraire_rubrique($rep);
- my @liste_rubriques = keys(%dictionnairesdesrubriques);
- # pour chaque rubrique, créer un fichier de sortie .xml et un fichier .txt
- foreach my $rub (@liste_rubriques) {
- my $output1= "SORTIE-extract-txt-".$rub.".xml";
- my $output2= "SORTIE-extract-txt-".$rub.".txt";
- # créer fichier .xml de sortie
- open (FILEOUTXML, ">:encoding(utf-8)", $output1) or die "Could not open file @output1!"; # open file for writing
- # créer fichier .txt de sortie
- open (FILEOUTTXT, ">:encoding(utf-8)", $output2) or die "Could not open file $output2!"; # open file for writing)
- # écrier déclaration d'en-tête du fichier xml
- print FILEOUTXML "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
- print FILEOUTXML "<PARCOURS>\n";
- #fermer les deux fichiers
- close(FILEOUTXML);
- close(FILEOUTTXT);
- print $output1;
- }
- # appeler lire_et_ecrire_xml() pour lire tous les fichiers xml et créer les sorties
- &lire_et_ecrire_xml($rep);
- foreach my $rub (@liste_rubriques)
- {
- my $output1="SORTIE-extract-txt-".$rub.".xml";
- if (!open (FILEOUTXML,">>:encoding(utf-8)", $output1))
- {
- die "Pb a l'ouverture du fichier $output1";
- }
- print FILEOUTXML "</PARCOURS>\n";
- close(FILEOUTXML);
- }
- exit;
- #########################################################################################################
- # #
- # cette fonction reçoit un nom de dossier comme argument et lit tous les fichiers .xml du dossier #
- # Pour chaque fichier lu, la fonction extrait le texte des balises <title> et <description>, ainsi que #
- # les dates présentes entre <pubDate> et <rubrique> #
- # Ce contenu insère dans des fichiers de sortie .xml et .txt la rubrique correspondante #
- # #
- #########################################################################################################
- sub lire_et_ecrire_xml {
- # lire nom de dossier passé comme argument
- my $path = shift(@_);
- # ouvrir dossier
- opendir(DIR, $path) or die "can't open $path: $!\n";
- # lire items dans le dossier
- my @files = readdir(DIR);
- closedir(DIR);
- # fermer dossier
- foreach my $file (@files)
- {
- # ignorer les items cachés
- next if $file =~ /^\.\.?$/;
- # construire le chemin complet avec le nom du dossier + item traité
- $file = $path."/".$file;
- # vérifier si l'item traité est un dossier
- if (-d $file)
- {
- # si l'item qu'on est en train de traiter est un dossier, on recommence la procédure
- &lire_et_ecrire_xml($file);
- }
- # vérifier si l'item traité un fichier IF1
- if (-f $file)
- {
- # vérifier s'il s'agit d'un fichier .xml qui ne contient pas fil dans le nom iF2
- if (($file=~/\.xml$/) && ($file!~/\/fil.+\.xml$/))
- {
- # ouvrir fichier
- open(FILE, $file);
- # variable pour stocker le contenu du fichier
- my $texte="";
- #lire le contenu du fichier ligne à line
- while (my $ligne=<FILE>)
- {
- chomp $ligne;
- $texte .= $ligne;
- }
- # fermer fichier
- close(FILE);
- # regex pour capturer l'encodage du fichier
- $texte=~/encoding ?= ?[\'\"]([^\'\"]+)[\'\"]/i;
- # stocker l'encodage du fichier
- my $encodage=$1;
- # vérifier si l'encodage n'est pas vide pour traiter le contenu IF3
- if ($encodage ne "")
- {
- # la variable tmptexteXML stocke les contenus prêts à être écrits dans fichier .xml de sortie
- my $tmptexteXML="<file>\n";
- # créer balise avec le nom du fichier
- $tmptexteXML.="<name>$file</name>\n";
- # éliminier les balises avec des espaces en blanc
- $texte =~ s/> *</></g;
- # regex pour capturer date
- $texte=~/<pubDate>([^<]+)<\/pubDate>/;
- # stocker la valeur de date capturée par la regex
- $tmptexteXML.="<date>$1</date>\n";
- # insérer la balise <items>
- $tmptexteXML.="<items>\n";
- my $tmptexteBRUT="";
- open(FILE,"<:encoding($encodage)", $file);
- $texte="";
- # lire le fichier ligne à ligne
- while (my $ligne=<FILE>)
- {
- chomp $ligne;
- $texte .= $ligne;
- }
- close(FILE);
- $texte=~s/> *</></g;
- # on recherche la rubrique
- $texte=~/<channel><title>([^<]+)<\/title>/;
- # on met le contenu trouvé par la regex dans $rub
- my $rub=$1;
- # nettoyer le string rubrique
- $rub =~ s/Toute l'actualité sur Le Monde.fr.//gi;
- $rub =~ s/é/e/gi;
- $rub =~ s/è/e/gi;
- $rub =~ s/ê/e/gi;
- $rub =~ s/à/a/gi;
- $rub =~ s/Le ?Monde.fr ?://;
- $rub =~ s/ //g;
- $rub=uc($rub);
- my $output1="SORTIE-extract-txt-".$rub.".xml";
- my $output2="SORTIE-extract-txt-".$rub.".txt";
- if (!open (FILEOUTXML,">>:encoding(utf-8)", $output1)) { die "Pb a l'ouverture du fichier $output1"};
- if (!open (FILEOUTTXT,">>:encoding(utf-8)", $output2)) { die "Pb a l'ouverture du fichier $output2"};
- # lire texte pour extraire contenu des balises <title> et <description>
- while ($texte =~ /<item><title>(.+?)<\/title>.+?<description>(.+?)<\/description>/g)
- {
- # capturer contenu de la regex pour titre
- my $titre=$1;
- # capturer contenu de la regex pour description
- my $resume=$2;
- # utilisation des modules pour remplacer dans les fichiers les entités XML et HTML
- if (!(exists ($dictionnairedesitems{$titre})) and !(exists ($dictionnairedesitems{$resume})))
- {
- $dictionnairedesitems{$titre}++;
- $dictionnairedesitems{$resume}++;
- $titre = XML::Entities::decode('all', $titre);
- $resume = XML::Entities::decode('all', $resume);
- $titre = HTML::Entities::decode($titre);
- $resume = HTML::Entities::decode($resume);
- $tmptexteBRUT.="$titre \n";
- $tmptexteBRUT.="$resume \n";
- $tmptexteXML.="<item><title>$titre</title><description>$resume</description></item>\n";
- # nettoyage des balises <description> pour supprimer les balises superflues
- $tmptexteXML =~ s/<img.*?\/><\/description>/<\/description>/g;
- $tmptexteBRUT =~ s/<img.*?\/> \n/\n/g;
- }
- # si le fichier n'est pas en UTF-8, convertir le string $titre et $resume en UTF-8
- if (uc($encodage) ne "UTF-8")
- {
- utf8($titre);
- utf8($resume);
- }
- } # fin while
- # rajouter la fin des balises <items> et <file>
- $tmptexteXML.="</items>\n</file>\n";
- # écrire contenu dans le fichier .xml
- print FILEOUTXML $tmptexteXML;
- # écrire contenu dans le fichier .txt
- print FILEOUTTXT $tmptexteBRUT;
- # fermer fichiers
- close FILEOUTXML;
- close FILEOUTTXT;
- } else {
- #si l'encodage est vide afficher message
- print "$file ==> $encodage \n";
- } # fin IF3
- } # fin IF 2
- } # fin IF 1
- } # fin FOR
- } # fin lire_et_ecrire_xml()
- ####################################################################################################
- # #
- # cette fonction reçoit un nom de dossier comme argument et lit tous les fichiers .xml du dossier #
- # Pour chaque fichier lu, la fonction extrait les rubriques et crée des fichiers de sortie #
- # possédant le nom de la rubrique #
- # #
- ####################################################################################################
- sub extraire_rubrique {
- #lire le nom dossier passé comme argument
- my $path = shift(@_);
- #ouvrir le dossier
- opendir(DIR, $path) or die "can't open $path: $!\n";
- #lire la liste de fichier du dossier
- my @files = readdir(DIR);
- closedir(DIR);
- # lire un à un les items du dossier
- foreach my $file (@files)
- {
- # ignorer les items cachés
- next if $file =~ /^\.\.?$/;
- # construire le chemin complet avec le nom du dossier + item traité
- $file = $path."/".$file;
- # vérifier si l'item est un dossier
- if (-d $file)
- {
- # si l'item qu'on est en train de traiter est un dossier, on recommence la procédure
- &extraire_rubrique($file);
- }
- # vérifier si l'item est un fichier - IF1
- if (-f $file)
- {
- # tester si fichier possède l'extension .xml et ne contient pas la substring fil dans le nom - IF2
- if (($file =~ /\.xml$/) && ($file!~/\/fil.+\.xml$/))
- {
- #ouvrir fichier .xml
- open(FILE,$file);
- #variable pour stocker le contenu du fichier .xml
- my $texte="";
- #lire toutes les lignes du fichier .xml
- while (my $ligne=<FILE>)
- {
- # effacer les retours à la ligne
- chomp $ligne;
- # stocker le contenu de ligne lue
- $texte .= $ligne;
- }
- # fermer le fichier .xml
- close(FILE);
- # regex pour capture l`encodage du fichier
- $texte =~ /encoding ?= ?[\'\"]([^\'\"]+)[\'\"]/i;
- # stocker le contenu trouvé par la regex
- my $encodage=$1;
- # vérifier la contenu de regex n'est pas vide IF3
- if ($encodage ne "")
- {
- # reouvrir le fichier avec l'encogade correcte
- open(FILE,"<:encoding($encodage)", $file);
- # variables pour stocker le contenu du fichier lu
- $texte="";
- # lire le fichier .xml
- while (my $ligne=<FILE>)
- {
- # effacer les retours à la ligne
- chomp $ligne;
- # stocker le contenu de ligne lue
- $texte .= $ligne;
- }
- # fermer le fichier .xml
- close(FILE);
- # effacer les espaces en blanc
- $texte =~ s/> *</></g;
- # capturer le contenu à l'intérieur des balises <title> - IF4
- if ($texte=~ /<channel><title>([^>]+)<\/title>/)
- {
- print $texte;
- # stocker la valeur de rubrique trouvée par la regex
- my $rub=$1;
- # nettoyer les noms des rubriques
- $rub =~ s/Toute l'actualité sur Le Monde.fr.//gi;
- $rub =~ s/é/e/gi;
- $rub =~ s/è/e/gi;
- $rub =~ s/ê/e/gi;
- $rub =~ s/à/a/gi;
- $rub =~ s/Le ?Monde.fr ?://;
- $rub =~ s/ //g;
- $rub=uc($rub);
- # stocker la rubrique dans le dictionnaire des rubriques
- $dictionnairesdesrubriques{$rub}++;
- } # fin IF4
- } # fin IF3
- } # fin IF2
- } # fin IF1
- } # fin FOR
- } # fin extraire_rubrique()
#/usr/bin/perl
use Unicode::String qw(utf8);
use XML::Entities;
use HTML::Entities;
use XML::RSS;
#lire l'entrée standard
my $rep="$ARGV[0]";
# éliminier les possibles "/" à la fin du nom du dossier
$rep=~ s/[\/]$//;
# liste pour stocker les items déjà traités
my %dictionnairedesitems = ();
# liste pour stocker les rubriques déjà traités
my %dictionnairesdesrubriques = ();
# appeler la fonction extraire_rubrique() pour lire les dossiers et extraire les rubriques des fichiers
&extraire_rubrique($rep);
my @liste_rubriques = keys(%dictionnairesdesrubriques);
# pour chaque rubrique, créer un fichier de sortie .xml et un fichier .txt
foreach my $rub (@liste_rubriques) {
my $output1= "SORTIE-extract-txt-".$rub.".xml";
my $output2= "SORTIE-extract-txt-".$rub.".txt";
# créer fichier .xml de sortie
open (FILEOUTXML, ">:encoding(utf-8)", $output1) or die "Could not open file @output1!"; # open file for writing
# créer fichier .txt de sortie
open (FILEOUTTXT, ">:encoding(utf-8)", $output2) or die "Could not open file $output2!"; # open file for writing)
# écrier déclaration d'en-tête du fichier xml
print FILEOUTXML "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print FILEOUTXML "<PARCOURS>\n";
#fermer les deux fichiers
close(FILEOUTXML);
close(FILEOUTTXT);
print $output1;
}
# appeler lire_et_ecrire_xml() pour lire tous les fichiers xml et créer les sorties
&lire_et_ecrire_xml($rep);
foreach my $rub (@liste_rubriques)
{
my $output1="SORTIE-extract-txt-".$rub.".xml";
if (!open (FILEOUTXML,">>:encoding(utf-8)", $output1))
{
die "Pb a l'ouverture du fichier $output1";
}
print FILEOUTXML "</PARCOURS>\n";
close(FILEOUTXML);
}
exit;
#########################################################################################################
# #
# cette fonction reçoit un nom de dossier comme argument et lit tous les fichiers .xml du dossier #
# Pour chaque fichier lu, la fonction extrait le texte des balises <title> et <description>, ainsi que #
# les dates présentes entre <pubDate> et <rubrique> #
# Ce contenu insère dans des fichiers de sortie .xml et .txt la rubrique correspondante #
# #
#########################################################################################################
sub lire_et_ecrire_xml {
# lire nom de dossier passé comme argument
my $path = shift(@_);
# ouvrir dossier
opendir(DIR, $path) or die "can't open $path: $!\n";
# lire items dans le dossier
my @files = readdir(DIR);
closedir(DIR);
# fermer dossier
foreach my $file (@files)
{
# ignorer les items cachés
next if $file =~ /^\.\.?$/;
# construire le chemin complet avec le nom du dossier + item traité
$file = $path."/".$file;
# vérifier si l'item traité est un dossier
if (-d $file)
{
# si l'item qu'on est en train de traiter est un dossier, on recommence la procédure
&lire_et_ecrire_xml($file);
}
# vérifier si l'item traité un fichier IF1
if (-f $file)
{
# vérifier s'il s'agit d'un fichier .xml qui ne contient pas fil dans le nom iF2
if (($file=~/\.xml$/) && ($file!~/\/fil.+\.xml$/))
{
# ouvrir fichier
open(FILE, $file);
# variable pour stocker le contenu du fichier
my $texte="";
#lire le contenu du fichier ligne à line
while (my $ligne=<FILE>)
{
chomp $ligne;
$texte .= $ligne;
}
# fermer fichier
close(FILE);
# regex pour capturer l'encodage du fichier
$texte=~/encoding ?= ?[\'\"]([^\'\"]+)[\'\"]/i;
# stocker l'encodage du fichier
my $encodage=$1;
# vérifier si l'encodage n'est pas vide pour traiter le contenu IF3
if ($encodage ne "")
{
# la variable tmptexteXML stocke les contenus prêts à être écrits dans fichier .xml de sortie
my $tmptexteXML="<file>\n";
# créer balise avec le nom du fichier
$tmptexteXML.="<name>$file</name>\n";
# éliminier les balises avec des espaces en blanc
$texte =~ s/> *</></g;
# regex pour capturer date
$texte=~/<pubDate>([^<]+)<\/pubDate>/;
# stocker la valeur de date capturée par la regex
$tmptexteXML.="<date>$1</date>\n";
# insérer la balise <items>
$tmptexteXML.="<items>\n";
my $tmptexteBRUT="";
open(FILE,"<:encoding($encodage)", $file);
$texte="";
# lire le fichier ligne à ligne
while (my $ligne=<FILE>)
{
chomp $ligne;
$texte .= $ligne;
}
close(FILE);
$texte=~s/> *</></g;
# on recherche la rubrique
$texte=~/<channel><title>([^<]+)<\/title>/;
# on met le contenu trouvé par la regex dans $rub
my $rub=$1;
# nettoyer le string rubrique
$rub =~ s/Toute l'actualité sur Le Monde.fr.//gi;
$rub =~ s/é/e/gi;
$rub =~ s/è/e/gi;
$rub =~ s/ê/e/gi;
$rub =~ s/à/a/gi;
$rub =~ s/Le ?Monde.fr ?://;
$rub =~ s/ //g;
$rub=uc($rub);
my $output1="SORTIE-extract-txt-".$rub.".xml";
my $output2="SORTIE-extract-txt-".$rub.".txt";
if (!open (FILEOUTXML,">>:encoding(utf-8)", $output1)) { die "Pb a l'ouverture du fichier $output1"};
if (!open (FILEOUTTXT,">>:encoding(utf-8)", $output2)) { die "Pb a l'ouverture du fichier $output2"};
# lire texte pour extraire contenu des balises <title> et <description>
while ($texte =~ /<item><title>(.+?)<\/title>.+?<description>(.+?)<\/description>/g)
{
# capturer contenu de la regex pour titre
my $titre=$1;
# capturer contenu de la regex pour description
my $resume=$2;
# utilisation des modules pour remplacer dans les fichiers les entités XML et HTML
if (!(exists ($dictionnairedesitems{$titre})) and !(exists ($dictionnairedesitems{$resume})))
{
$dictionnairedesitems{$titre}++;
$dictionnairedesitems{$resume}++;
$titre = XML::Entities::decode('all', $titre);
$resume = XML::Entities::decode('all', $resume);
$titre = HTML::Entities::decode($titre);
$resume = HTML::Entities::decode($resume);
$tmptexteBRUT.="$titre \n";
$tmptexteBRUT.="$resume \n";
$tmptexteXML.="<item><title>$titre</title><description>$resume</description></item>\n";
# nettoyage des balises <description> pour supprimer les balises superflues
$tmptexteXML =~ s/<img.*?\/><\/description>/<\/description>/g;
$tmptexteBRUT =~ s/<img.*?\/> \n/\n/g;
}
# si le fichier n'est pas en UTF-8, convertir le string $titre et $resume en UTF-8
if (uc($encodage) ne "UTF-8")
{
utf8($titre);
utf8($resume);
}
} # fin while
# rajouter la fin des balises <items> et <file>
$tmptexteXML.="</items>\n</file>\n";
# écrire contenu dans le fichier .xml
print FILEOUTXML $tmptexteXML;
# écrire contenu dans le fichier .txt
print FILEOUTTXT $tmptexteBRUT;
# fermer fichiers
close FILEOUTXML;
close FILEOUTTXT;
} else {
#si l'encodage est vide afficher message
print "$file ==> $encodage \n";
} # fin IF3
} # fin IF 2
} # fin IF 1
} # fin FOR
} # fin lire_et_ecrire_xml()
####################################################################################################
# #
# cette fonction reçoit un nom de dossier comme argument et lit tous les fichiers .xml du dossier #
# Pour chaque fichier lu, la fonction extrait les rubriques et crée des fichiers de sortie #
# possédant le nom de la rubrique #
# #
####################################################################################################
sub extraire_rubrique {
#lire le nom dossier passé comme argument
my $path = shift(@_);
#ouvrir le dossier
opendir(DIR, $path) or die "can't open $path: $!\n";
#lire la liste de fichier du dossier
my @files = readdir(DIR);
closedir(DIR);
# lire un à un les items du dossier
foreach my $file (@files)
{
# ignorer les items cachés
next if $file =~ /^\.\.?$/;
# construire le chemin complet avec le nom du dossier + item traité
$file = $path."/".$file;
# vérifier si l'item est un dossier
if (-d $file)
{
# si l'item qu'on est en train de traiter est un dossier, on recommence la procédure
&extraire_rubrique($file);
}
# vérifier si l'item est un fichier - IF1
if (-f $file)
{
# tester si fichier possède l'extension .xml et ne contient pas la substring fil dans le nom - IF2
if (($file =~ /\.xml$/) && ($file!~/\/fil.+\.xml$/))
{
#ouvrir fichier .xml
open(FILE,$file);
#variable pour stocker le contenu du fichier .xml
my $texte="";
#lire toutes les lignes du fichier .xml
while (my $ligne=<FILE>)
{
# effacer les retours à la ligne
chomp $ligne;
# stocker le contenu de ligne lue
$texte .= $ligne;
}
# fermer le fichier .xml
close(FILE);
# regex pour capture l`encodage du fichier
$texte =~ /encoding ?= ?[\'\"]([^\'\"]+)[\'\"]/i;
# stocker le contenu trouvé par la regex
my $encodage=$1;
# vérifier la contenu de regex n'est pas vide IF3
if ($encodage ne "")
{
# reouvrir le fichier avec l'encogade correcte
open(FILE,"<:encoding($encodage)", $file);
# variables pour stocker le contenu du fichier lu
$texte="";
# lire le fichier .xml
while (my $ligne=<FILE>)
{
# effacer les retours à la ligne
chomp $ligne;
# stocker le contenu de ligne lue
$texte .= $ligne;
}
# fermer le fichier .xml
close(FILE);
# effacer les espaces en blanc
$texte =~ s/> *</></g;
# capturer le contenu à l'intérieur des balises <title> - IF4
if ($texte=~ /<channel><title>([^>]+)<\/title>/)
{
print $texte;
# stocker la valeur de rubrique trouvée par la regex
my $rub=$1;
# nettoyer les noms des rubriques
$rub =~ s/Toute l'actualité sur Le Monde.fr.//gi;
$rub =~ s/é/e/gi;
$rub =~ s/è/e/gi;
$rub =~ s/ê/e/gi;
$rub =~ s/à/a/gi;
$rub =~ s/Le ?Monde.fr ?://;
$rub =~ s/ //g;
$rub=uc($rub);
# stocker la rubrique dans le dictionnaire des rubriques
$dictionnairesdesrubriques{$rub}++;
} # fin IF4
} # fin IF3
} # fin IF2
} # fin IF1
} # fin FOR
} # fin extraire_rubrique()
Exemplo dos resultados da ferramenta 1
Este é nosso resultado, uma vez que os caracteres reservados foram substituídos. Perceba que nós temos caracteres acentuados e não há tags de imagem!
Exemplo de uma saída XML.

Para facilitar a leitura dos resultados nós criamos uma folha de estilos xsl que pode ser encontrada aqui.
Este é o nosso resultado com exibição promovida pela folha de estilos.

O texto bruto contém apenas isso: texto. Ter um resultado com apenas texto sem nenhuma informação adicional de formatação é muito útil para a próxima etapa, onde nós utilizaremos o etiquetados (POS Tagger) Cordial e TreeTagger.
Exemplo de um resultado TXT.
O que a ferramenta 2 faz?
A ferramenta 2 é um programa que adiciona à ferramenta 1 o texto contido nas tags <title> e <description> com auxílio dos etiquetadores TreeTagger e Cordial.
O programa possui várias saídas, mas elas podem ser divididas em dois grupos principais. Um que é o mesmo resultado da ferramenta 1, texto bruto para cada categoria e arquivo XML. O outro grupo contém a saída etiquetada pelo TreeTagger convertida em um formato XML. Esse arquivo é organizado por linhas e palavras. Cada palavra presente em uma linha está associada com a sua etiqueta morfosintática e o seu lema.
Nós criamos também um arquivo global, conteando todas as categorias diferentes concatenadas nos mesmo arquivos.
A segunda parte da ferramenta 2 é feita manualmente. Cada um dos arquivos de texto bruto é convertido para iso-8859-15 (Latin 9) para ser compatível com Cordial. Observe que o caracter "œ" precisa ser substituído por "oe", já que ele não é suportado pela versão do Cordial utilizada para a realização do projeto.
O arquivo de saída do Cordial, quando aberto em um editor de texto, exibe três coluna distintas. Uma para as palavras, outra para etiquetas morfosintáticas e outra para os lemas. Um exemplo pode ser visto na página "Resultados".
O TreeTagger é um software gratuíto desenvolvido por Helmut Schmid e está disponível para download nestelink. Ele pode ser utilizado para etiquetar textos em Alemão, Inglês, Francês, Italiano, Espanhol, Búlgaro, Russo, Português, Galiciano, Chinês, Suaília, Eslovaco, Latim, Estoniano, Polonês e Francês antigo.
Cordial é um software pago que possui muitas ferramentas para o tratamento linguístico como um dicionário e um tradutor. Ele possui muitas funcionlidades, porém é mais limitado em termos de línguas suportadas para etiquetagem morfosintática. Em geral, nós achamos que os resultados são mais precisos do que aqueles pelo TreeTagger. Você pode ler mais sobre o Cordial neste link.
O método do professor
Esta versão encadra perfeitamente na categoria "Puro Perl", já que ela utiliza um módulo (Unicode::String) para converter os arquivos utf-8. Trata-se de uma versão vista em aula que nós tentamos melhorar disponível nas páginas "Nossos Resultados".
- #/usr/bin/perl
- use Unicode::String qw(utf8);
- #-----------------------------------------------------------
- my $rep="$ARGV[0]";
- # on s'assure que le nom du répertoire ne se termine pas par un "/"
- $rep=~ s/[\/]$//;
- # on initialise une variable contenant le flux de sortie
- my %dictionnairedesitems=();
- my %dictionnairesdesrubriques=();
- #----------------------------------------
- &parcoursarborescencefichierspourrepererlesrubriques($rep); # on recupere les rubriques...
- #----------------------------------------
- my @liste_rubriques = keys(%dictionnairesdesrubriques);
- foreach my $rub (@liste_rubriques) {
- print $rub,"\n";
- #----------------------------------------
- my $output1="SORTIE/SORTIE-extract-txt-".$rub.".xml";
- my $output2="SORTIE/SORTIE-extract-txt-".$rub.".txt";
- my $output3="SORTIE/SORTIE-extract-txt-".$rub."-treetagger.xml";
- if (!open (FILEOUT1,">:encoding(utf-8)", $output1)) { die "Pb a l'ouverture du fichier $output1"};
- if (!open (FILEOUT2,">:encoding(utf-8)",$output2)) { die "Pb a l'ouverture du fichier $output2"};
- if (!open (FILEOUT3,">:encoding(utf-8)",$output3)) { die "Pb a l'ouverture du fichier $output3"};
- print FILEOUT1 "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
- print FILEOUT1 "<PARCOURS>\n";
- print FILEOUT3 "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
- print FILEOUT3 "<PARCOURS>\n";
- close(FILEOUT1);
- close(FILEOUT2);
- close(FILEOUT3);
- }
- #----------------------------------------
- &parcoursarborescencefichiers($rep); # on traite tous les fichiers
- #----------------------------------------
- foreach my $rub (@liste_rubriques) {
- my $output1="SORTIE/SORTIE-extract-txt-".$rub.".xml";
- my $output3="SORTIE/SORTIE-extract-txt-".$rub."-treetagger.xml";
- if (!open (FILEOUT1,">>:encoding(utf-8)", $output1)) { die "Pb a l'ouverture du fichier $output1"};
- if (!open (FILEOUT3,">>:encoding(utf-8)",$output3)) { die "Pb a l'ouverture du fichier $output3"};
- print FILEOUT1 "</PARCOURS>\n";
- print FILEOUT3 "</PARCOURS>\n";
- close(FILEOUT1);
- close(FILEOUT3);
- }
- exit;
- #----------------------------------------------
- #----------------------------------------------
- sub parcoursarborescencefichiers {
- my $path = shift(@_);
- opendir(DIR, $path) or die "can't open $path: $!\n";
- my @files = readdir(DIR);
- closedir(DIR);
- foreach my $file (@files) {
- next if $file =~ /^\.\.?$/;
- $file = $path."/".$file;
- if (-d $file) {
- &parcoursarborescencefichiers($file); #recurse!
- }
- if (-f $file) {
- if (($file=~/\.xml$/) && ($file!~/\/fil.+\.xml$/)) {
- open(FILE, $file);
- #print "Traitement de :\n$file\n";
- my $texte="";
- while (my $ligne=<FILE>) {
- $ligne =~ s/\n//g;
- $texte .= $ligne;
- }
- close(FILE);
- $texte=~/encoding ?= ?[\'\"]([^\'\"]+)[\'\"]/i;
- my $encodage=$1;
- #print "ENCODAGE : $encodage \n";
- if ($encodage ne "") {
- print "Extraction dans : $file \n";
- my $tmptexteXML="<file>\n";
- $tmptexteXML.="<name>$file</name>\n";
- my $tmptexteXMLtagger="<file>\n";
- $tmptexteXMLtagger.="<name>$file</name>\n";
- $texte =~ s/> *</></g;
- $texte=~/<pubDate>([^<]+)<\/pubDate>/;
- $tmptexteXML.="<date>$1</date>\n";
- $tmptexteXML.="<items>\n";
- $tmptexteXMLtagger.="<date>$1</date>\n";
- $tmptexteXMLtagger.="<items>\n";
- my $tmptexteBRUT="";
- open(FILE,"<:encoding($encodage)", $file);
- #print "Traitement de :\n$file\n";
- $texte="";
- while (my $ligne=<FILE>) {
- $ligne =~ s/\n//g;
- $texte .= $ligne;
- }
- close(FILE);
- $texte=~s/> *</></g;
- # on recherche la rubrique
- $texte=~/<channel><title>([^<]+)<\/title>/;
- my $rub=$1;
- $rub=~s/é/e/gi;
- $rub=~s/è/e/gi;
- $rub=~s/ê/e/gi;
- $rub=~s/à/a/gi;
- $rub=~ s/Le *Monde *\. *fr *://gi;
- $rub=~ s/ //g;
- $rub=~ s/s$//;
- $rub=uc($rub);
- #print $rub,"\n";
- #----------------------------------------
- my $output1="SORTIE/SORTIE-extract-txt-".$rub.".xml";
- my $output2="SORTIE/SORTIE-extract-txt-".$rub.".txt";
- my $output3="SORTIE/SORTIE-extract-txt-".$rub."-treetagger.xml";
- if (!open (FILEOUT1,">>:encoding(utf-8)", $output1)) { die "Pb a l'ouverture du fichier $output1"};
- if (!open (FILEOUT2,">>:encoding(utf-8)", $output2)) { die "Pb a l'ouverture du fichier $output2"};
- if (!open (FILEOUT3,">>:encoding(utf-8)", $output3)) { die "Pb a l'ouverture du fichier $output3"};
- #----------------------------------------
- my $compteurItem=0;
- my $compteurEtiquetage=0;
- while ($texte =~ /<item><title>(.+?)<\/title>.+?<description>(.+?)<\/description>/g) {
- my $titre=$1;
- my $resume=$2;
- #print "T : $titre \n R : $resume \n";
- if (uc($encodage) ne "UTF-8") {utf8($titre);utf8($resume);}
- $titre = &nettoietexte($1);
- $resume = &nettoietexte($2);
- $compteurItem++;
- if (!(exists($dictionnairedesitems{$resume}))) {
- $compteurEtiquetage++;
- print "Etiquetage (num : $compteurEtiquetage) sur item (num : $compteurItem) \n";
- my ($titreetiquete,$texteetiquete)=&etiquetageavectreetagger($titre,$resume);
- $tmptexteBRUT.="§ $titre \n";
- $tmptexteBRUT.="$resume \n";
- $tmptexteXML.="<item><title>$titre</title><abstract>$resume</abstract></item>\n";
- $tmptexteXMLtagger.="<item>\n<title>\n$titreetiquete</title>\n<abstract>\n$texteetiquete</abstract>\n</item>\n";
- $dictionnairedesitems{$resume}++;
- }
- else {
- $tmptexteXML.="<item><title>-</title><abstract>-</abstract></item>\n";
- }
- }
- $tmptexteXML.="</items>\n</file>\n";
- $tmptexteXMLtagger.="</items>\n</file>\n";
- print FILEOUT1 $tmptexteXML;
- print FILEOUT2 $tmptexteBRUT;
- print FILEOUT3 $tmptexteXMLtagger;
- close FILEOUT1;
- close FILEOUT2;
- close FILEOUT3;
- }
- else {
- print "$file ==> $encodage \n";
- }
- }
- }
- }
- }
- #----------------------------------------------------
- sub nettoietexte {
- my $texte=shift;
- $texte =~ s/</</g;
- $texte =~ s/>/>/g;
- $texte =~ s/<a href[^>]+>//g;
- $texte =~ s/<img[^>]+>//g;
- $texte =~ s/<\/a>//g;
- $texte =~ s/&#39;/'/g;
- $texte =~ s/&#34;/"/g;
- $texte =~ s/é/é/g;
- $texte =~ s/ê/ê/g;
- $texte =~ s/<[^>]+>//g;
- $texte =~ s/ / /g;
- $texte=~s/'/'/g;
- $texte=~s/"/"/g;
- $texte=~s/&#39;/'/g;
- $texte=~s/&#34;/"/g;
- return $texte;
- }
- #-----------------------------------------------------------------------------------
- sub parcoursarborescencefichierspourrepererlesrubriques {
- my $path = shift(@_);
- opendir(DIR, $path) or die "can't open $path: $!\n";
- my @files = readdir(DIR);
- closedir(DIR);
- foreach my $file (@files) {
- next if $file =~ /^\.\.?$/;
- $file = $path."/".$file;
- if (-d $file) {
- &parcoursarborescencefichierspourrepererlesrubriques($file); #recurse!
- }
- if (-f $file) {
- if (($file=~/\.xml$/) && ($file!~/\/fil.+\.xml$/)) {
- open(FILE,$file);
- #print "Traitement de :\n$file\n";
- my $texte="";
- while (my $ligne=<FILE>) {
- $ligne =~ s/\n//g;
- $texte .= $ligne;
- }
- close(FILE);
- $texte=~/encoding ?= ?[\'\"]([^\'\"]+)[\'\"]/i;
- my $encodage=$1;
- if ($encodage ne "") {
- open(FILE,"<:encoding($encodage)", $file);
- #print "Traitement de :\n$file\n";
- $texte="";
- while (my $ligne=<FILE>) {
- $ligne =~ s/\n//g;
- $texte .= $ligne;
- }
- close(FILE);
- $texte =~ s/> *</></g;
- if ($texte=~ /<channel><title>([^>]+)<\/title>/) {
- my $rub=$1;
- $rub=~s/é/e/gi;
- $rub=~s/è/e/gi;
- $rub=~s/ê/e/gi;
- $rub=~s/à/a/gi;
- $rub=~ s/Le *Monde *\. *fr *://gi;
- $rub=~ s/ //g;
- $rub=~ s/s$//;
- $rub=uc($rub);
- $dictionnairesdesrubriques{$rub}++;
- }
- }
- else {
- #print "$file ==> $encodage \n";
- }
- }
- }
- }
- }
- sub etiquetageavectreetagger {
- my ($titre,$texte)=@_;
- #----- le titre
- my $codage="utf-8";
- my $tmptag="texteaetiqueter.txt";
- open (TMPFILE,">:encoding(utf-8)", $tmptag);
- print TMPFILE $titre,"\n";
- close(TMPFILE);
- system("perl ./treetagger-win32/cmd/tokenise-fr.pl $tmptag | tree-tagger.exe ./treetagger-win32/lib/french-utf8.par -lemma -token -no-unknown -sgml > treetagger.txt");
- system("perl ./treetagger-win32/cmd/treetagger2xml-utf8.pl treetagger.txt $codage ");
- # lecture du resultat tagge en xml :
- open(OUT,"<:encoding(utf-8)","treetagger.txt.xml");
- my $fistline=<OUT>;
- my $titreetiquete="";
- while (my $l=<OUT>) {
- $titreetiquete.=$l;
- }
- close(OUT);
- #----- le resume
- open (TMPFILE,">:encoding(utf-8)", $tmptag);
- print TMPFILE $texte,"\n";
- close(TMPFILE);
- system("perl ./treetagger-win32/cmd/tokenise-fr.pl $tmptag | tree-tagger.exe ./treetagger-win32/lib/french-utf8.par -lemma -token -no-unknown -sgml > treetagger.txt");
- system("perl ./treetagger-win32/cmd/treetagger2xml-utf8.pl treetagger.txt $codage");
- # lecture du resultat tagge en xml :
- open(OUT,"<:encoding(utf-8)","treetagger.txt.xml");
- my $fistline=<OUT>;
- my $texteetiquete="";
- while (my $l=<OUT>) {
- $texteetiquete.=$l;
- }
- close(OUT);
- # on renvoie les resultats :
- return ($titreetiquete,$texteetiquete);
- }
#/usr/bin/perl
use Unicode::String qw(utf8);
#-----------------------------------------------------------
my $rep="$ARGV[0]";
# on s'assure que le nom du répertoire ne se termine pas par un "/"
$rep=~ s/[\/]$//;
# on initialise une variable contenant le flux de sortie
my %dictionnairedesitems=();
my %dictionnairesdesrubriques=();
#----------------------------------------
&parcoursarborescencefichierspourrepererlesrubriques($rep); # on recupere les rubriques...
#----------------------------------------
my @liste_rubriques = keys(%dictionnairesdesrubriques);
foreach my $rub (@liste_rubriques) {
print $rub,"\n";
#----------------------------------------
my $output1="SORTIE/SORTIE-extract-txt-".$rub.".xml";
my $output2="SORTIE/SORTIE-extract-txt-".$rub.".txt";
my $output3="SORTIE/SORTIE-extract-txt-".$rub."-treetagger.xml";
if (!open (FILEOUT1,">:encoding(utf-8)", $output1)) { die "Pb a l'ouverture du fichier $output1"};
if (!open (FILEOUT2,">:encoding(utf-8)",$output2)) { die "Pb a l'ouverture du fichier $output2"};
if (!open (FILEOUT3,">:encoding(utf-8)",$output3)) { die "Pb a l'ouverture du fichier $output3"};
print FILEOUT1 "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print FILEOUT1 "<PARCOURS>\n";
print FILEOUT3 "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print FILEOUT3 "<PARCOURS>\n";
close(FILEOUT1);
close(FILEOUT2);
close(FILEOUT3);
}
#----------------------------------------
&parcoursarborescencefichiers($rep); # on traite tous les fichiers
#----------------------------------------
foreach my $rub (@liste_rubriques) {
my $output1="SORTIE/SORTIE-extract-txt-".$rub.".xml";
my $output3="SORTIE/SORTIE-extract-txt-".$rub."-treetagger.xml";
if (!open (FILEOUT1,">>:encoding(utf-8)", $output1)) { die "Pb a l'ouverture du fichier $output1"};
if (!open (FILEOUT3,">>:encoding(utf-8)",$output3)) { die "Pb a l'ouverture du fichier $output3"};
print FILEOUT1 "</PARCOURS>\n";
print FILEOUT3 "</PARCOURS>\n";
close(FILEOUT1);
close(FILEOUT3);
}
exit;
#----------------------------------------------
#----------------------------------------------
sub parcoursarborescencefichiers {
my $path = shift(@_);
opendir(DIR, $path) or die "can't open $path: $!\n";
my @files = readdir(DIR);
closedir(DIR);
foreach my $file (@files) {
next if $file =~ /^\.\.?$/;
$file = $path."/".$file;
if (-d $file) {
&parcoursarborescencefichiers($file); #recurse!
}
if (-f $file) {
if (($file=~/\.xml$/) && ($file!~/\/fil.+\.xml$/)) {
open(FILE, $file);
#print "Traitement de :\n$file\n";
my $texte="";
while (my $ligne=<FILE>) {
$ligne =~ s/\n//g;
$texte .= $ligne;
}
close(FILE);
$texte=~/encoding ?= ?[\'\"]([^\'\"]+)[\'\"]/i;
my $encodage=$1;
#print "ENCODAGE : $encodage \n";
if ($encodage ne "") {
print "Extraction dans : $file \n";
my $tmptexteXML="<file>\n";
$tmptexteXML.="<name>$file</name>\n";
my $tmptexteXMLtagger="<file>\n";
$tmptexteXMLtagger.="<name>$file</name>\n";
$texte =~ s/> *</></g;
$texte=~/<pubDate>([^<]+)<\/pubDate>/;
$tmptexteXML.="<date>$1</date>\n";
$tmptexteXML.="<items>\n";
$tmptexteXMLtagger.="<date>$1</date>\n";
$tmptexteXMLtagger.="<items>\n";
my $tmptexteBRUT="";
open(FILE,"<:encoding($encodage)", $file);
#print "Traitement de :\n$file\n";
$texte="";
while (my $ligne=<FILE>) {
$ligne =~ s/\n//g;
$texte .= $ligne;
}
close(FILE);
$texte=~s/> *</></g;
# on recherche la rubrique
$texte=~/<channel><title>([^<]+)<\/title>/;
my $rub=$1;
$rub=~s/é/e/gi;
$rub=~s/è/e/gi;
$rub=~s/ê/e/gi;
$rub=~s/à/a/gi;
$rub=~ s/Le *Monde *\. *fr *://gi;
$rub=~ s/ //g;
$rub=~ s/s$//;
$rub=uc($rub);
#print $rub,"\n";
#----------------------------------------
my $output1="SORTIE/SORTIE-extract-txt-".$rub.".xml";
my $output2="SORTIE/SORTIE-extract-txt-".$rub.".txt";
my $output3="SORTIE/SORTIE-extract-txt-".$rub."-treetagger.xml";
if (!open (FILEOUT1,">>:encoding(utf-8)", $output1)) { die "Pb a l'ouverture du fichier $output1"};
if (!open (FILEOUT2,">>:encoding(utf-8)", $output2)) { die "Pb a l'ouverture du fichier $output2"};
if (!open (FILEOUT3,">>:encoding(utf-8)", $output3)) { die "Pb a l'ouverture du fichier $output3"};
#----------------------------------------
my $compteurItem=0;
my $compteurEtiquetage=0;
while ($texte =~ /<item><title>(.+?)<\/title>.+?<description>(.+?)<\/description>/g) {
my $titre=$1;
my $resume=$2;
#print "T : $titre \n R : $resume \n";
if (uc($encodage) ne "UTF-8") {utf8($titre);utf8($resume);}
$titre = &nettoietexte($1);
$resume = &nettoietexte($2);
$compteurItem++;
if (!(exists($dictionnairedesitems{$resume}))) {
$compteurEtiquetage++;
print "Etiquetage (num : $compteurEtiquetage) sur item (num : $compteurItem) \n";
my ($titreetiquete,$texteetiquete)=&etiquetageavectreetagger($titre,$resume);
$tmptexteBRUT.="§ $titre \n";
$tmptexteBRUT.="$resume \n";
$tmptexteXML.="<item><title>$titre</title><abstract>$resume</abstract></item>\n";
$tmptexteXMLtagger.="<item>\n<title>\n$titreetiquete</title>\n<abstract>\n$texteetiquete</abstract>\n</item>\n";
$dictionnairedesitems{$resume}++;
}
else {
$tmptexteXML.="<item><title>-</title><abstract>-</abstract></item>\n";
}
}
$tmptexteXML.="</items>\n</file>\n";
$tmptexteXMLtagger.="</items>\n</file>\n";
print FILEOUT1 $tmptexteXML;
print FILEOUT2 $tmptexteBRUT;
print FILEOUT3 $tmptexteXMLtagger;
close FILEOUT1;
close FILEOUT2;
close FILEOUT3;
}
else {
print "$file ==> $encodage \n";
}
}
}
}
}
#----------------------------------------------------
sub nettoietexte {
my $texte=shift;
$texte =~ s/</</g;
$texte =~ s/>/>/g;
$texte =~ s/<a href[^>]+>//g;
$texte =~ s/<img[^>]+>//g;
$texte =~ s/<\/a>//g;
$texte =~ s/&#39;/'/g;
$texte =~ s/&#34;/"/g;
$texte =~ s/é/é/g;
$texte =~ s/ê/ê/g;
$texte =~ s/<[^>]+>//g;
$texte =~ s/ / /g;
$texte=~s/'/'/g;
$texte=~s/"/"/g;
$texte=~s/&#39;/'/g;
$texte=~s/&#34;/"/g;
return $texte;
}
#-----------------------------------------------------------------------------------
sub parcoursarborescencefichierspourrepererlesrubriques {
my $path = shift(@_);
opendir(DIR, $path) or die "can't open $path: $!\n";
my @files = readdir(DIR);
closedir(DIR);
foreach my $file (@files) {
next if $file =~ /^\.\.?$/;
$file = $path."/".$file;
if (-d $file) {
&parcoursarborescencefichierspourrepererlesrubriques($file); #recurse!
}
if (-f $file) {
if (($file=~/\.xml$/) && ($file!~/\/fil.+\.xml$/)) {
open(FILE,$file);
#print "Traitement de :\n$file\n";
my $texte="";
while (my $ligne=<FILE>) {
$ligne =~ s/\n//g;
$texte .= $ligne;
}
close(FILE);
$texte=~/encoding ?= ?[\'\"]([^\'\"]+)[\'\"]/i;
my $encodage=$1;
if ($encodage ne "") {
open(FILE,"<:encoding($encodage)", $file);
#print "Traitement de :\n$file\n";
$texte="";
while (my $ligne=<FILE>) {
$ligne =~ s/\n//g;
$texte .= $ligne;
}
close(FILE);
$texte =~ s/> *</></g;
if ($texte=~ /<channel><title>([^>]+)<\/title>/) {
my $rub=$1;
$rub=~s/é/e/gi;
$rub=~s/è/e/gi;
$rub=~s/ê/e/gi;
$rub=~s/à/a/gi;
$rub=~ s/Le *Monde *\. *fr *://gi;
$rub=~ s/ //g;
$rub=~ s/s$//;
$rub=uc($rub);
$dictionnairesdesrubriques{$rub}++;
}
}
else {
#print "$file ==> $encodage \n";
}
}
}
}
}
sub etiquetageavectreetagger {
my ($titre,$texte)=@_;
#----- le titre
my $codage="utf-8";
my $tmptag="texteaetiqueter.txt";
open (TMPFILE,">:encoding(utf-8)", $tmptag);
print TMPFILE $titre,"\n";
close(TMPFILE);
system("perl ./treetagger-win32/cmd/tokenise-fr.pl $tmptag | tree-tagger.exe ./treetagger-win32/lib/french-utf8.par -lemma -token -no-unknown -sgml > treetagger.txt");
system("perl ./treetagger-win32/cmd/treetagger2xml-utf8.pl treetagger.txt $codage ");
# lecture du resultat tagge en xml :
open(OUT,"<:encoding(utf-8)","treetagger.txt.xml");
my $fistline=<OUT>;
my $titreetiquete="";
while (my $l=<OUT>) {
$titreetiquete.=$l;
}
close(OUT);
#----- le resume
open (TMPFILE,">:encoding(utf-8)", $tmptag);
print TMPFILE $texte,"\n";
close(TMPFILE);
system("perl ./treetagger-win32/cmd/tokenise-fr.pl $tmptag | tree-tagger.exe ./treetagger-win32/lib/french-utf8.par -lemma -token -no-unknown -sgml > treetagger.txt");
system("perl ./treetagger-win32/cmd/treetagger2xml-utf8.pl treetagger.txt $codage");
# lecture du resultat tagge en xml :
open(OUT,"<:encoding(utf-8)","treetagger.txt.xml");
my $fistline=<OUT>;
my $texteetiquete="";
while (my $l=<OUT>) {
$texteetiquete.=$l;
}
close(OUT);
# on renvoie les resultats :
return ($titreetiquete,$texteetiquete);
}
Ferramenta 2 & Ferramenta 3 & Ferramenta 4
Uma parte bonus desta seção tratava-ze de utilizar o programa Le Trameur para etiquetar o texto utilizando a função imbutida TreeTagger, extrair sequências morfosintáticas para em seguida visualizar os resultados em uma série de gráficos. De uma maneira geral, o programa é capaz de substituir as Ferramentas 2, 3, e 4.
Caso você não utilize Windows, ainda assim existe um meio de utilizar Le Trameur. Trata-se do (Wine). No entanto, algumas funcionalidades não estão disponíveis na utilizaçao do Le Trameur com o Wine. TreeTagger, por exemplo, é uma das funções que não pode ser realizada bônus, utilizando Wine.

Uma descrição completa das funões do Le Trameur podem ser encontradas nesta página.
Puro Perl
Como nós já indicamos anteriormente, nossa versão Puro Perl consiste em não utilizar módulos Perl no nosso programa. Nós desenvolvemos nós mesmos todas as funções necessárias ao bom funcionamento do script.
Para os tratamento das entidades; nós criamos uma função que as modifica por caracteres equivalentes. Nós tivemos que enumerá-las uma a uma afim de obtermos a lista mais completa possível. Essa função se chama "nettoyerTexte". Nós realizamos também uma outra limpeza para os temas. Porém, neste caso não se trata de entidades, mas de caracteres acentuados que nós substituímos por caracteres não acentuadso de modo a obter nomes de arquivos sem acentos, sinais de pontuação ou URL.
Para a criação dos nossos arquivos de resultados, nós não utilizamos o módulo XML::RSS. As saídas XML e TXT foram criadas por nós mesmos.
Ao contrário da versão feita em aula, nós criamos um repertório de saída que é subdivido em dois repertórios; um reúne os arquivos etiquetados por TreeTagger e o outro, os títulos e as descrição em arquivo TXT. Para isso nós utilizamos a recursividade da função "parcoursarborescencefichiers", afim de recuperar os desejados.
- #!/usr/bin/perl
- <<DOC;
- Votre Nom : Bienvenue, Poadey, Cavalcante
- MARS 2015
- usage : perl parcours-arborescence-fichiers repertoire-a-parcourir
- Le programme prend en entrée le nom du répertoire contenant les fichiers
- à traiter
- Le programme construit en sortie des fichiers structurés : en format XML
- et en format TXT
- DOC
- use Unicode::String qw(utf8);
- use utf8;
- # pour pouvoir afficher la date
- use Time::localtime;
- #------------------------------------------------------------------------------
- # des compteurs pour le nombre des items
- my $nb_filesIN = 0;
- my $nb_itemsIN = 0;
- my $nb_itemsOUT = 0;
- #------------------------------------------------------------------------------
- # le répertoire d'entrée
- my $rep = "$ARGV[0]";
- # enlever le slash à la fin du répertoire
- $rep =~ s/[\/]$//;
- #------------------------------------------------------------------------------
- # des hash tables pour vérifier qu'on n'a pas deux fois les même infos
- my %dico_titre = ();
- my %dico_description = ();
- # cet hash nous permet de juste traiter une fois chaque texte
- my %dico_files = ();
- # creer l`objet date pour ecrire les dates dans le log
- my $date_time = ctime();
- #------------------------------------------------------------------------------
- # creation des dossiers de sortie
- my $res = "./Sorties/";
- if (! -e $res) {
- mkdir($res) or die ("Problème avec la création du répertoire de $rep : $!");
- }
- $res = "./Sorties/Sorties_PurePerl/";
- if (! -e $res) {
- mkdir($res) or die ("Problème avec la création du répertoire de $rep : $!\n");
- }
- #------------------------------------------------------------------------------
- # sorties etiquetées
- my $resBAO2 = "./Sorties/Sorties_Tagged/";
- if (! -e $resBAO2) {
- mkdir($resBAO2) or die ("Problème avec la création du répertoire de $rep : $!\n");
- }
- #------------------------------------------------------------------------------
- # sortie globale txt
- open(FILEGLOBALTXT,">:encoding(UTF-8)", $res."SortieGlobale1.txt");
- #------------------------------------------------------------------------------
- &parcoursarborescencefichiers($rep); #recurse!
- #------------------------------------------------------------------------------
- close FILEGLOBALTXT;
- #------------------------------------------------------------------------------
- # création de la sortie globale xml
- open(FILEGLOBALXML, ">:encoding(UTF-8)", $res."SortieGlobale1.xml");
- print FILEGLOBALXML "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
- print FILEGLOBALXML "<PARCOURS>\n";
- print FILEGLOBALXML "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
- print FILEGLOBALXML "<FILTRAGE>";
- #------------------------------------------------------------------------------
- # écrire contenu de la sortie globale xml
- opendir(DIR, $res) or die "Erreur d'ouverture du repertoire: $!\n";
- my @sorties = readdir(DIR);
- closedir(DIR);
- foreach my $sortie (@sorties) {
- if ($sortie=~/(.+?)\.xml$/ && $1 != "SortieGlobale1") {
- my $rub=$1;
- open(FILE,">>:encoding(UTF-8)", $res.$sortie);
- print FILE "</".$rub.">\n";;
- print FILE "</PARCOURS>\n";
- close(FILE);
- print FILEGLOBALXML "<$rub>\n";
- print FILEGLOBALXML ${"DumpXML".$rub};
- print FILEGLOBALXML "</$rub>";
- }
- }
- print FILEGLOBALXML "</FILTRAGE>\n";
- print FILEGLOBALXML "</PARCOURS>\n";
- close(FILEGLOBALXML);
- #------------------------------------------------------------------------------
- open(FILEGLOBALXML, ">:encoding(UTF-8)", $resBAO2."SortieGlobale2.xml");
- print FILEGLOBALXML "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
- print FILEGLOBALXML "<PARCOURS>\n";
- print FILEGLOBALXML "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
- print FILEGLOBALXML "<FILTRAGE>";
- #------------------------------------------------------------------------------
- opendir(DIR, $resBAO2) or die "Erreur d'ouverture de repertoire: $!\n";
- @sorties = readdir(DIR);
- closedir(DIR);
- foreach my $sortie (@sorties) {
- # se fait sur chaque sortie xml dans chaque rubrique
- if ($sortie=~/(.+?)\.xml$/ && $1 != "SortieGlobale2") {
- my $rub = $1;
- open(FILE,">>:encoding(UTF-8)", $resBAO2.$sortie);
- print FILE "</".$rub.">\n";;
- print FILE "</PARCOURS>\n";
- close FILE;
- print FILEGLOBALXML "<$rub>\n";
- print FILEGLOBALXML ${"DumpXML2_Tagged".$rub};
- print FILEGLOBALXML "</$rub>";
- }
- }
- #------------------------------------------------------------------------------
- print FILEGLOBALXML "</FILTRAGE>\n";
- print FILEGLOBALXML "</PARCOURS>\n";
- close(FILEGLOBALXML);
- #------------------------------------------------------------------------------
- # imprime le nombre des infos à la fin du programme
- print "\n" . "files IN = $nb_filesIN\n";
- print "items IN = $nb_itemsIN\n";
- print "items OUT = $nb_itemsOUT\n";
- print "fin.\n";
- exit;
- # fin du main programme
- #------------------------------------------------------------------------------
- #------------------------------------------------------------------------------
- # commencement des subroutines
- #------------------------------------------------------------------------------
- # subroutine pour parcourir l'aborescence
- sub parcoursarborescencefichiers {
- my $path = shift(@_); # chemin vers le dossier en entrée
- opendir(DIR, $path) or die "Probleme d'ouverture du dossier: $!\n";
- my @files = readdir(DIR);
- closedir(DIR);
- #--------------------------------------------
- foreach my $file (@files) {
- next if $file =~ /^\.\.?$/; #si . ou ..
- $file = $path."/".$file;
- #si $file est un dossier
- if (-d $file) {
- &parcoursarborescencefichiers($file); #recurse!
- }
- # faire le traitement si $file est un fichier
- if (-f $file) {
- # traiter les fichiers xml seulement
- if ($file=~/^[^(fil)]+?\.xml$/) {
- $nb_filesIN++;
- print $file,"\n";
- #lire le fichier xml
- open(FILE,$file);
- my $firstLine = <FILE>;
- my $encodage = "";
- #vérifier encodage du fichier xml
- if($firstLine =~ /encoding= ?['"]([^\'"]+)['"]/) {
- $encodage = $1; #extraire l'encodage
- }
- close(FILE);
- # si on trouve l'encodage, le fichier est reouvert avec l'encodage correcte
- if (!($encodage eq "")) {
- open(FILE,"<:encoding($encodage)",$file);
- my $texte = "";
- #éliminer les retours à ligne dans le fichier [ \n et \r ]
- while (my $ligne = <FILE>) {
- $ligne =~ s/\n//g;
- $ligne =~ s/\r//g;
- $texte .= $ligne;
- }
- close FILE;
- $texte =~ s/> *?</></g; # coller les balises
- #-----------------------------------------
- # extraire rubrique, date et nom
- $texte =~ /<channel>.*?<title>(.*?)<\/title>.*?<pubDate>(.+?)<\/pubDate>.*?<\/channel>/;
- # nettoyer les rubriques
- my $rubrique = &nettoyerRubriques($1);
- print "RUBRIQUE : $rubrique\n";
- # extraire la date
- my $date = &nettoyerRubriques($2);
- # nom du fichier
- my $name = $file;
- # uniquement les fichiers XML contenant les mises à jour
- $name =~ s/.*?(20.*)/$1/;
- #------------------------------------------
- # ouvre des balises et écrire dans des fichiers de sortie
- my $cheminXML=$res.$rubrique.".xml";
- # si on n'a pas encore vu le rubrique on doit le créer
- if (! -e $cheminXML) {
- # créer un fichier
- if (!open (FILEOUT,">:encoding(UTF-8)",$cheminXML)) {
- die "Probleme a la creation du fichier $cheminXML : $!";
- }
- # ouverture des balises XML du début du fichier
- print FILEOUT "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
- print FILEOUT "<PARCOURS>\n";
- print FILEOUT "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
- print FILEOUT "<$rubrique>\n";
- print FILEOUT "<file>";
- print FILEOUT "<name>$name</name>";
- print FILEOUT "<date>$date</date>";
- print FILEOUT "<items>";
- close(FILEOUT);
- ${"DumpXML"."$rubrique"}="";
- }
- # si le fichier existe déjà
- else {
- if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML)) {
- die "Problème a l'ouverture du fichier $cheminXML : $!\n";
- }
- print FILEOUT "<file>";
- print FILEOUT "<name>$name</name>";
- print FILEOUT "<date>$date</date>";
- print FILEOUT "<items>";
- close(FILEOUT);
- }
- #-------------------------------------------
- my $cheminXML_BAO2=$resBAO2.$rubrique.".xml";
- # si on n'a pas encore vu le rubrique
- if (! -e $cheminXML_BAO2) {
- # créer un fichier
- if (!open (FILEOUT,">:encoding(UTF-8)",$cheminXML_BAO2)) {
- die "Probleme a la creation du fichier $cheminXML_BAO2 : $!\n";
- }
- # ouverture des balises XML du début du fichier
- print FILEOUT "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
- print FILEOUT "<PARCOURS>\n";
- print FILEOUT "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
- print FILEOUT "<$rubrique>\n";
- print FILEOUT "<file>";
- print FILEOUT "<name>$name</name>";
- print FILEOUT "<date>$date</date>";
- print FILEOUT "<items>";
- close(FILEOUT);
- ${"DumpXML_tagged"."$rubrique"}="";
- }
- # si le fichier existe déjà
- else {
- if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML_BAO2)) {
- die "Problème a l'ouverture du fichier $cheminXML_BAO2 : $!\n";
- }
- print FILEOUT "<file>";
- print FILEOUT "<name>$file</name>";
- print FILEOUT "<date>$date</date>";
- print FILEOUT "<items>";
- close(FILEOUT);
- }
- #---------------------------------------------
- # extractions des titres et descriptions
- while ($texte =~ /<item>.*?<title>(.*?)<\/title>.*?<description>(.*?)<\/description>/g)
- {
- my $titre = $1;
- my $description = $2;
- $nb_itemsIN++;
- #-----------------------------------------
- # nettoyer le texte
- $titre = &nettoyerTexte($titre);
- $description = &nettoyerTexte($description);
- if (!(($titre eq "") or ($description eq ""))) {
- #-----------------------------------------
- # convertir si besoin en utf-8
- if (uc($encodage) ne "UTF-8") {
- utf8($titre);
- utf8($description);
- }
- #----------------------------------------------
- # regarde si on a déjà vu le texte
- if (!((exists $dico_titre{$rubrique . $titre}) && (exists $dico_description{$rubrique . $description})))
- {
- $dico_titre{$rubrique . $titre} = "1";
- $dico_description{$rubrique . $description} = "1";
- $nb_itemsOUT++;
- #------------------------------------------
- # faire l'etiquetage
- my $titre_tagged = &treetagger($titre);
- my $description_tagged = &treetagger($description);
- open(LOG, ">>", "log_bao2.txt");
- if(exists $dico_files{$file}){
- $count_file = int($dico_files{$file});
- $count_file++;
- %dico_files = ($file => $count_file);
- } else {
- %dico_files = ($file => 1);
- }
- #creer l`objet date pour ecrire les dates dans le log
- my $date_time = ctime();
- #ecrire le fichier de log avec le nom du fichier et l`heure de lecture
- print LOG $file." ".$dico_files{$file}."\t\t read on ".$date_time."\n";
- # mettre dans les sorties xml
- if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML)) {
- die "Problème a l'ouverture du fichier $cheminXML : $!\n";
- }
- print FILEOUT "<item>\n";
- print FILEOUT "<titre>" . $titre . "</titre>\n<description>" . $description . "</description>\n";
- print FILEOUT "</item>\n";
- close(FILEOUT);
- #----------------------------------------------
- # créer un dump pour chaque rubrique
- ${"DumpXML" . $rubrique} .= "<item>\n<titre>" . $titre . "</titre>\n<description>" . $description . "</description>\n</item>\n";
- #----------------------------------------------
- # partie de sorties txt
- my $cheminTXT = $res . $rubrique . ".txt";
- # si on n'a pas encore vu la rubrique
- if (! -e $cheminTXT) {
- if (!open (FILEGLOBALTXT,">>:encoding(iso-8859-15)",$cheminTXT)) {
- die "Problème a l'ouverture du fichier $cheminTXT : $!\n";
- }
- # écrire dans le sortie txt
- print FILEGLOBALTXT "$titre." . " $description.\n";
- close(FILEGLOBALTXT);
- }
- # si on a déjà vu la rubrique
- else {
- if (!open (FILEGLOBALTXT,">>:encoding(iso-8859-15)",$cheminTXT)) {
- die "Problème a l'ouverture du fichier $cheminTXT : $!\n";
- }
- # écrire dans le sortie txt
- print FILEGLOBALTXT "$titre." . " $description.";
- close(FILEGLOBALTXT);
- }
- if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML_BAO2)) {
- die "Problème a l'ouverture du fichier $cheminXML_BAO2 : $!\n";
- }
- print FILEOUT "<item>\n";
- print FILEOUT "<titre>".$titre_tagged."</titre>\n<description>".$description_tagged."</description>\n";
- print FILEOUT "</item>\n";
- close(FILEOUT);
- # créer un dump pour chaque rubrique
- ${"DumpXML2_Tagged".$rubrique}.="<item>\n<titre>".$titre_tagged."</titre>\n<description>".$description_tagged."</description>\n</item>\n";
- }
- }
- }
- # fermer la balise file pour chaque fichier xml
- if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML))
- {
- die "Problème a l'ouverture du fichier .$cheminXML : $!\n";
- }
- print FILEOUT "</items>";
- print FILEOUT "</file>";
- close(FILEOUT);
- # fermer la balise les fichier xml etiqutée
- if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML_BAO2)) {
- die "Problème a l'ouverture du fichier .$cheminXML_BAO2 : $!\n";
- }
- print FILEOUT "</items>";
- print FILEOUT "</file>";
- close(FILEOUT);
- }
- }
- }
- }
- }
- #------------------------------------------------------------------------------
- # subroutine pour nettoyer le texte
- #------------------------------------------------------------------------------
- sub nettoyerTexte {
- my $tx = $_[0];
- $tx =~ s/&/&/g;
- $tx =~ s/&/&/g;
- $tx =~ s/"/"/g;
- $tx =~ s/"/"/g;
- $tx =~ s/'/'/g;
- $tx =~ s/'/'/g;
- $tx =~ s/</</g;
- $tx =~ s/</</g;
- $tx =~ s/>/>/g;
- $tx =~ s/>/>/g;
- $tx =~ s/ //g;
- $tx =~ s/ //g;
- $tx =~ s/£/£/g;
- $tx =~ s/£/£/g;
- $tx =~ s/©/©/g;
- $tx =~ s/«/«/g;
- $tx =~ s/«/«/g;
- $tx =~ s/»/»/g;
- $tx =~ s/»//g;
- $tx =~ s/É/É/g;
- $tx =~ s/É/É/g;
- $tx =~ s/í/î/g;
- $tx =~ s/î/î/g;
- $tx =~ s/ï/ï/g;
- $tx =~ s/ï/ï/g;
- $tx =~ s/à/à/g;
- $tx =~ s/à/à/g;
- $tx =~ s/â/â/g;
- $tx =~ s/â/â/g;
- $tx =~ s/ç/ç/g;
- $tx =~ s/ç/ç/g;
- $tx =~ s/è/è/g;
- $tx =~ s/è/è/g;
- $tx =~ s/é/é/g;
- $tx =~ s/é/é/g;
- $tx =~ s/ê/ê/g;
- $tx =~ s/ê/ê/g;
- $tx =~ s/ô/ô/g;
- $tx =~ s/ô/ô/g;
- $tx =~ s/û/û/g;
- $tx =~ s/û/û/g;
- $tx =~ s/ü/ü/g;
- $tx =~ s/ü/ü/g;
- $tx =~ s/\x9c/œ/g;
- $tx =~ s/<br\/\>//g;
- $tx =~ s/<img.*?\/>//g;
- $tx =~ s/<.+?>//sg;
- $tx =~ s/<a.*?>.*?<\/a>//g;
- $tx =~ s/<![CDATA[(.*?)]]>/$1/g;
- $tx =~ s/<[^>]>//g;
- $tx =~ s/\.$//;
- $tx =~ s/&/et/g;
- return $tx;
- }
- #------------------------------------------------------------------------------
- # subroutine pour nettoyer des rubriques
- #------------------------------------------------------------------------------
- sub nettoyerRubriques {
- my $rubrique = shift;
- $rubrique =~ s/Le Monde.fr//g;
- $rubrique =~ s/LeMonde.fr//g;
- $rubrique =~ s/: Toute l'actualité sur//g;
- $rubrique =~ s/É/e/g;
- $rubrique =~ s/é/e/g;
- $rubrique =~ s/è/e/g;
- $rubrique =~ s/ê/a/g;
- $rubrique =~ s/ë/e/g;
- $rubrique =~ s/ï/i/g;
- $rubrique =~ s/î/i/g;
- $rubrique =~ s/à/a/g;
- $rubrique =~ s/ô/o/g;
- $rubrique =~ s/,/_/g;
- $rubrique = uc($rubrique);
- $rubrique =~ s/ //g;
- $rubrique =~ s/[\.\:;\'\"\-]+//g;
- return $rubrique;
- }
- #------------------------------------------------------------------------------
- # subroutine pour le tokenisation et etiquetage
- #------------------------------------------------------------------------------
- sub treetagger {
- my $texte = shift;
- my $temptag;
- # créer un fichier temporaire pour tagger des morceaux de texte
- open($temptag, ">:encoding(UTF-8)", "./temptag.txt");
- print $temptag $texte;
- close($temptag);
- system("perl tokenise-utf8.pl ./temptag.txt | /home/alexandre/tree-tagger/bin/tree-tagger -lemma -token -no-unknown -sgml /home/alexandre/tree-tagger/models/french.par > treetagger.txt");
- system("perl ./treetagger2xml-utf8.pl treetagger.txt utf-8");
- open(TaggedOUT,"<:encoding(utf-8)","treetagger.txt.xml");
- my $tagged_text = "";
- #lire la ligne d'en tête du fichier xml étiqueté, pour éviter que cette
- # ligne soit inclue dans le nouveau fichier xml
- my $line_den_tete = <TaggedOUT>;
- while (my $l = <TaggedOUT>) {
- $tagged_text .= $l;
- }
- close(TaggedOUT);
- return $tagged_text;
- }
- # fin des subroutines
- #------------------------------------------------------------------------------
- #------------------------------------------------------------------------------
#!/usr/bin/perl
<<DOC;
Votre Nom : Bienvenue, Poadey, Cavalcante
MARS 2015
usage : perl parcours-arborescence-fichiers repertoire-a-parcourir
Le programme prend en entrée le nom du répertoire contenant les fichiers
à traiter
Le programme construit en sortie des fichiers structurés : en format XML
et en format TXT
DOC
use Unicode::String qw(utf8);
use utf8;
# pour pouvoir afficher la date
use Time::localtime;
#------------------------------------------------------------------------------
# des compteurs pour le nombre des items
my $nb_filesIN = 0;
my $nb_itemsIN = 0;
my $nb_itemsOUT = 0;
#------------------------------------------------------------------------------
# le répertoire d'entrée
my $rep = "$ARGV[0]";
# enlever le slash à la fin du répertoire
$rep =~ s/[\/]$//;
#------------------------------------------------------------------------------
# des hash tables pour vérifier qu'on n'a pas deux fois les même infos
my %dico_titre = ();
my %dico_description = ();
# cet hash nous permet de juste traiter une fois chaque texte
my %dico_files = ();
# creer l`objet date pour ecrire les dates dans le log
my $date_time = ctime();
#------------------------------------------------------------------------------
# creation des dossiers de sortie
my $res = "./Sorties/";
if (! -e $res) {
mkdir($res) or die ("Problème avec la création du répertoire de $rep : $!");
}
$res = "./Sorties/Sorties_PurePerl/";
if (! -e $res) {
mkdir($res) or die ("Problème avec la création du répertoire de $rep : $!\n");
}
#------------------------------------------------------------------------------
# sorties etiquetées
my $resBAO2 = "./Sorties/Sorties_Tagged/";
if (! -e $resBAO2) {
mkdir($resBAO2) or die ("Problème avec la création du répertoire de $rep : $!\n");
}
#------------------------------------------------------------------------------
# sortie globale txt
open(FILEGLOBALTXT,">:encoding(UTF-8)", $res."SortieGlobale1.txt");
#------------------------------------------------------------------------------
&parcoursarborescencefichiers($rep); #recurse!
#------------------------------------------------------------------------------
close FILEGLOBALTXT;
#------------------------------------------------------------------------------
# création de la sortie globale xml
open(FILEGLOBALXML, ">:encoding(UTF-8)", $res."SortieGlobale1.xml");
print FILEGLOBALXML "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print FILEGLOBALXML "<PARCOURS>\n";
print FILEGLOBALXML "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
print FILEGLOBALXML "<FILTRAGE>";
#------------------------------------------------------------------------------
# écrire contenu de la sortie globale xml
opendir(DIR, $res) or die "Erreur d'ouverture du repertoire: $!\n";
my @sorties = readdir(DIR);
closedir(DIR);
foreach my $sortie (@sorties) {
if ($sortie=~/(.+?)\.xml$/ && $1 != "SortieGlobale1") {
my $rub=$1;
open(FILE,">>:encoding(UTF-8)", $res.$sortie);
print FILE "</".$rub.">\n";;
print FILE "</PARCOURS>\n";
close(FILE);
print FILEGLOBALXML "<$rub>\n";
print FILEGLOBALXML ${"DumpXML".$rub};
print FILEGLOBALXML "</$rub>";
}
}
print FILEGLOBALXML "</FILTRAGE>\n";
print FILEGLOBALXML "</PARCOURS>\n";
close(FILEGLOBALXML);
#------------------------------------------------------------------------------
open(FILEGLOBALXML, ">:encoding(UTF-8)", $resBAO2."SortieGlobale2.xml");
print FILEGLOBALXML "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print FILEGLOBALXML "<PARCOURS>\n";
print FILEGLOBALXML "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
print FILEGLOBALXML "<FILTRAGE>";
#------------------------------------------------------------------------------
opendir(DIR, $resBAO2) or die "Erreur d'ouverture de repertoire: $!\n";
@sorties = readdir(DIR);
closedir(DIR);
foreach my $sortie (@sorties) {
# se fait sur chaque sortie xml dans chaque rubrique
if ($sortie=~/(.+?)\.xml$/ && $1 != "SortieGlobale2") {
my $rub = $1;
open(FILE,">>:encoding(UTF-8)", $resBAO2.$sortie);
print FILE "</".$rub.">\n";;
print FILE "</PARCOURS>\n";
close FILE;
print FILEGLOBALXML "<$rub>\n";
print FILEGLOBALXML ${"DumpXML2_Tagged".$rub};
print FILEGLOBALXML "</$rub>";
}
}
#------------------------------------------------------------------------------
print FILEGLOBALXML "</FILTRAGE>\n";
print FILEGLOBALXML "</PARCOURS>\n";
close(FILEGLOBALXML);
#------------------------------------------------------------------------------
# imprime le nombre des infos à la fin du programme
print "\n" . "files IN = $nb_filesIN\n";
print "items IN = $nb_itemsIN\n";
print "items OUT = $nb_itemsOUT\n";
print "fin.\n";
exit;
# fin du main programme
#------------------------------------------------------------------------------
#------------------------------------------------------------------------------
# commencement des subroutines
#------------------------------------------------------------------------------
# subroutine pour parcourir l'aborescence
sub parcoursarborescencefichiers {
my $path = shift(@_); # chemin vers le dossier en entrée
opendir(DIR, $path) or die "Probleme d'ouverture du dossier: $!\n";
my @files = readdir(DIR);
closedir(DIR);
#--------------------------------------------
foreach my $file (@files) {
next if $file =~ /^\.\.?$/; #si . ou ..
$file = $path."/".$file;
#si $file est un dossier
if (-d $file) {
&parcoursarborescencefichiers($file); #recurse!
}
# faire le traitement si $file est un fichier
if (-f $file) {
# traiter les fichiers xml seulement
if ($file=~/^[^(fil)]+?\.xml$/) {
$nb_filesIN++;
print $file,"\n";
#lire le fichier xml
open(FILE,$file);
my $firstLine = <FILE>;
my $encodage = "";
#vérifier encodage du fichier xml
if($firstLine =~ /encoding= ?['"]([^\'"]+)['"]/) {
$encodage = $1; #extraire l'encodage
}
close(FILE);
# si on trouve l'encodage, le fichier est reouvert avec l'encodage correcte
if (!($encodage eq "")) {
open(FILE,"<:encoding($encodage)",$file);
my $texte = "";
#éliminer les retours à ligne dans le fichier [ \n et \r ]
while (my $ligne = <FILE>) {
$ligne =~ s/\n//g;
$ligne =~ s/\r//g;
$texte .= $ligne;
}
close FILE;
$texte =~ s/> *?</></g; # coller les balises
#-----------------------------------------
# extraire rubrique, date et nom
$texte =~ /<channel>.*?<title>(.*?)<\/title>.*?<pubDate>(.+?)<\/pubDate>.*?<\/channel>/;
# nettoyer les rubriques
my $rubrique = &nettoyerRubriques($1);
print "RUBRIQUE : $rubrique\n";
# extraire la date
my $date = &nettoyerRubriques($2);
# nom du fichier
my $name = $file;
# uniquement les fichiers XML contenant les mises à jour
$name =~ s/.*?(20.*)/$1/;
#------------------------------------------
# ouvre des balises et écrire dans des fichiers de sortie
my $cheminXML=$res.$rubrique.".xml";
# si on n'a pas encore vu le rubrique on doit le créer
if (! -e $cheminXML) {
# créer un fichier
if (!open (FILEOUT,">:encoding(UTF-8)",$cheminXML)) {
die "Probleme a la creation du fichier $cheminXML : $!";
}
# ouverture des balises XML du début du fichier
print FILEOUT "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print FILEOUT "<PARCOURS>\n";
print FILEOUT "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
print FILEOUT "<$rubrique>\n";
print FILEOUT "<file>";
print FILEOUT "<name>$name</name>";
print FILEOUT "<date>$date</date>";
print FILEOUT "<items>";
close(FILEOUT);
${"DumpXML"."$rubrique"}="";
}
# si le fichier existe déjà
else {
if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML)) {
die "Problème a l'ouverture du fichier $cheminXML : $!\n";
}
print FILEOUT "<file>";
print FILEOUT "<name>$name</name>";
print FILEOUT "<date>$date</date>";
print FILEOUT "<items>";
close(FILEOUT);
}
#-------------------------------------------
my $cheminXML_BAO2=$resBAO2.$rubrique.".xml";
# si on n'a pas encore vu le rubrique
if (! -e $cheminXML_BAO2) {
# créer un fichier
if (!open (FILEOUT,">:encoding(UTF-8)",$cheminXML_BAO2)) {
die "Probleme a la creation du fichier $cheminXML_BAO2 : $!\n";
}
# ouverture des balises XML du début du fichier
print FILEOUT "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print FILEOUT "<PARCOURS>\n";
print FILEOUT "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
print FILEOUT "<$rubrique>\n";
print FILEOUT "<file>";
print FILEOUT "<name>$name</name>";
print FILEOUT "<date>$date</date>";
print FILEOUT "<items>";
close(FILEOUT);
${"DumpXML_tagged"."$rubrique"}="";
}
# si le fichier existe déjà
else {
if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML_BAO2)) {
die "Problème a l'ouverture du fichier $cheminXML_BAO2 : $!\n";
}
print FILEOUT "<file>";
print FILEOUT "<name>$file</name>";
print FILEOUT "<date>$date</date>";
print FILEOUT "<items>";
close(FILEOUT);
}
#---------------------------------------------
# extractions des titres et descriptions
while ($texte =~ /<item>.*?<title>(.*?)<\/title>.*?<description>(.*?)<\/description>/g)
{
my $titre = $1;
my $description = $2;
$nb_itemsIN++;
#-----------------------------------------
# nettoyer le texte
$titre = &nettoyerTexte($titre);
$description = &nettoyerTexte($description);
if (!(($titre eq "") or ($description eq ""))) {
#-----------------------------------------
# convertir si besoin en utf-8
if (uc($encodage) ne "UTF-8") {
utf8($titre);
utf8($description);
}
#----------------------------------------------
# regarde si on a déjà vu le texte
if (!((exists $dico_titre{$rubrique . $titre}) && (exists $dico_description{$rubrique . $description})))
{
$dico_titre{$rubrique . $titre} = "1";
$dico_description{$rubrique . $description} = "1";
$nb_itemsOUT++;
#------------------------------------------
# faire l'etiquetage
my $titre_tagged = &treetagger($titre);
my $description_tagged = &treetagger($description);
open(LOG, ">>", "log_bao2.txt");
if(exists $dico_files{$file}){
$count_file = int($dico_files{$file});
$count_file++;
%dico_files = ($file => $count_file);
} else {
%dico_files = ($file => 1);
}
#creer l`objet date pour ecrire les dates dans le log
my $date_time = ctime();
#ecrire le fichier de log avec le nom du fichier et l`heure de lecture
print LOG $file." ".$dico_files{$file}."\t\t read on ".$date_time."\n";
# mettre dans les sorties xml
if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML)) {
die "Problème a l'ouverture du fichier $cheminXML : $!\n";
}
print FILEOUT "<item>\n";
print FILEOUT "<titre>" . $titre . "</titre>\n<description>" . $description . "</description>\n";
print FILEOUT "</item>\n";
close(FILEOUT);
#----------------------------------------------
# créer un dump pour chaque rubrique
${"DumpXML" . $rubrique} .= "<item>\n<titre>" . $titre . "</titre>\n<description>" . $description . "</description>\n</item>\n";
#----------------------------------------------
# partie de sorties txt
my $cheminTXT = $res . $rubrique . ".txt";
# si on n'a pas encore vu la rubrique
if (! -e $cheminTXT) {
if (!open (FILEGLOBALTXT,">>:encoding(iso-8859-15)",$cheminTXT)) {
die "Problème a l'ouverture du fichier $cheminTXT : $!\n";
}
# écrire dans le sortie txt
print FILEGLOBALTXT "$titre." . " $description.\n";
close(FILEGLOBALTXT);
}
# si on a déjà vu la rubrique
else {
if (!open (FILEGLOBALTXT,">>:encoding(iso-8859-15)",$cheminTXT)) {
die "Problème a l'ouverture du fichier $cheminTXT : $!\n";
}
# écrire dans le sortie txt
print FILEGLOBALTXT "$titre." . " $description.";
close(FILEGLOBALTXT);
}
if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML_BAO2)) {
die "Problème a l'ouverture du fichier $cheminXML_BAO2 : $!\n";
}
print FILEOUT "<item>\n";
print FILEOUT "<titre>".$titre_tagged."</titre>\n<description>".$description_tagged."</description>\n";
print FILEOUT "</item>\n";
close(FILEOUT);
# créer un dump pour chaque rubrique
${"DumpXML2_Tagged".$rubrique}.="<item>\n<titre>".$titre_tagged."</titre>\n<description>".$description_tagged."</description>\n</item>\n";
}
}
}
# fermer la balise file pour chaque fichier xml
if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML))
{
die "Problème a l'ouverture du fichier .$cheminXML : $!\n";
}
print FILEOUT "</items>";
print FILEOUT "</file>";
close(FILEOUT);
# fermer la balise les fichier xml etiqutée
if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML_BAO2)) {
die "Problème a l'ouverture du fichier .$cheminXML_BAO2 : $!\n";
}
print FILEOUT "</items>";
print FILEOUT "</file>";
close(FILEOUT);
}
}
}
}
}
#------------------------------------------------------------------------------
# subroutine pour nettoyer le texte
#------------------------------------------------------------------------------
sub nettoyerTexte {
my $tx = $_[0];
$tx =~ s/&/&/g;
$tx =~ s/&/&/g;
$tx =~ s/"/"/g;
$tx =~ s/"/"/g;
$tx =~ s/'/'/g;
$tx =~ s/'/'/g;
$tx =~ s/</</g;
$tx =~ s/</</g;
$tx =~ s/>/>/g;
$tx =~ s/>/>/g;
$tx =~ s/ //g;
$tx =~ s/ //g;
$tx =~ s/£/£/g;
$tx =~ s/£/£/g;
$tx =~ s/©/©/g;
$tx =~ s/«/«/g;
$tx =~ s/«/«/g;
$tx =~ s/»/»/g;
$tx =~ s/»//g;
$tx =~ s/É/É/g;
$tx =~ s/É/É/g;
$tx =~ s/í/î/g;
$tx =~ s/î/î/g;
$tx =~ s/ï/ï/g;
$tx =~ s/ï/ï/g;
$tx =~ s/à/à/g;
$tx =~ s/à/à/g;
$tx =~ s/â/â/g;
$tx =~ s/â/â/g;
$tx =~ s/ç/ç/g;
$tx =~ s/ç/ç/g;
$tx =~ s/è/è/g;
$tx =~ s/è/è/g;
$tx =~ s/é/é/g;
$tx =~ s/é/é/g;
$tx =~ s/ê/ê/g;
$tx =~ s/ê/ê/g;
$tx =~ s/ô/ô/g;
$tx =~ s/ô/ô/g;
$tx =~ s/û/û/g;
$tx =~ s/û/û/g;
$tx =~ s/ü/ü/g;
$tx =~ s/ü/ü/g;
$tx =~ s/\x9c/œ/g;
$tx =~ s/<br\/\>//g;
$tx =~ s/<img.*?\/>//g;
$tx =~ s/<.+?>//sg;
$tx =~ s/<a.*?>.*?<\/a>//g;
$tx =~ s/<![CDATA[(.*?)]]>/$1/g;
$tx =~ s/<[^>]>//g;
$tx =~ s/\.$//;
$tx =~ s/&/et/g;
return $tx;
}
#------------------------------------------------------------------------------
# subroutine pour nettoyer des rubriques
#------------------------------------------------------------------------------
sub nettoyerRubriques {
my $rubrique = shift;
$rubrique =~ s/Le Monde.fr//g;
$rubrique =~ s/LeMonde.fr//g;
$rubrique =~ s/: Toute l'actualité sur//g;
$rubrique =~ s/É/e/g;
$rubrique =~ s/é/e/g;
$rubrique =~ s/è/e/g;
$rubrique =~ s/ê/a/g;
$rubrique =~ s/ë/e/g;
$rubrique =~ s/ï/i/g;
$rubrique =~ s/î/i/g;
$rubrique =~ s/à/a/g;
$rubrique =~ s/ô/o/g;
$rubrique =~ s/,/_/g;
$rubrique = uc($rubrique);
$rubrique =~ s/ //g;
$rubrique =~ s/[\.\:;\'\"\-]+//g;
return $rubrique;
}
#------------------------------------------------------------------------------
# subroutine pour le tokenisation et etiquetage
#------------------------------------------------------------------------------
sub treetagger {
my $texte = shift;
my $temptag;
# créer un fichier temporaire pour tagger des morceaux de texte
open($temptag, ">:encoding(UTF-8)", "./temptag.txt");
print $temptag $texte;
close($temptag);
system("perl tokenise-utf8.pl ./temptag.txt | /home/alexandre/tree-tagger/bin/tree-tagger -lemma -token -no-unknown -sgml /home/alexandre/tree-tagger/models/french.par > treetagger.txt");
system("perl ./treetagger2xml-utf8.pl treetagger.txt utf-8");
open(TaggedOUT,"<:encoding(utf-8)","treetagger.txt.xml");
my $tagged_text = "";
#lire la ligne d'en tête du fichier xml étiqueté, pour éviter que cette
# ligne soit inclue dans le nouveau fichier xml
my $line_den_tete = <TaggedOUT>;
while (my $l = <TaggedOUT>) {
$tagged_text .= $l;
}
close(TaggedOUT);
return $tagged_text;
}
# fin des subroutines
#------------------------------------------------------------------------------
#------------------------------------------------------------------------------Módulos Perl
Nós criamos scripts Perl para as Ferramentas, utilizando as funções para excluir as entidades dos arquivos, mas também utilizando os módulos XML::Entities e HTML::Entities. Nós temos então dois scripts diferentes para a Ferramenta 2, ou seja, com e sem módulos do Perl.
Para a Ferramenta 2, nós implementamos o mesmo sistema que para CdF 1, nós limpamos o arquivo XML após a decodificação das entidades.
A inclusão dos módulos:
A utilização dos módulos:
- #!/usr/bin/perl -w
- <<DOC;
- Votre Nom : Bienvenue, Poadey, Cavalcante
- MARS 2015
- usage : perl parcours-arborescence-fichiers repertoire-a-parcourir
- Le programme prend en entrée le nom du répertoire contenant les fichiers
- à traiter
- Le programme construit en sortie un fichier structuré contenant sur chaque
- ligne le nom du fichier et le résultat du filtrage :
- <FICHIER><NOM>du fichier</NOM></FICHIER><CONTENU>du filtrage</CONTENU></FICHIER>
- DOC
- use Unicode::String qw(utf8);
- use utf8;
- use Time::localtime;
- use XML::Entities;
- use HTML::Entities;
- #------------------------------------------------------------------------------
- # des compteurs pour le nombre des items
- my $nb_filesIN = 0;
- my $nb_itemsIN = 0;
- my $nb_itemsOUT = 0;
- #------------------------------------------------------------------------------
- # le répertoire d'entrée contenant les fichiers xml
- my $rep = "$ARGV[0]";
- # regex enlever le slash à la fin du nom du répertoire
- $rep =~ s/[\/]$//;
- #------------------------------------------------------------------------------
- # des hash tables pour vérifier qu'on n'a pas deux fois les même infos
- my %dicoTitre = ();
- my %dicoDescription = ();
- # cet hash controle le nombre de fois que le fichier a ete lu pour ecrire le fichier de log
- my %dico_files = ();
- #creer l`objet date pour ecire la date et l'heure de lecture des fichiers xml dans le fichier de log
- my $date_time = ctime();
- #------------------------------------------------------------------------------
- # creation des dossiers de sortie
- my $res = "../Sorties/";
- if (! -e $res) {
- mkdir($res) or die ("Problème avec la création du répertoire de $rep : $!");
- }
- $res = "../Sorties/1_Sorties_PurePerl/";
- if (! -e $res) {
- mkdir($res) or die ("Problème avec la création du répertoire de $rep : $!\n");
- }
- #------------------------------------------------------------------------------
- # sorties etiquetées
- my $resBAO2 = "../Sorties/2_Sorties_Etiquetees/";
- if (! -e $resBAO2) {
- mkdir($resBAO2) or die ("Problème avec la création du répertoire de $rep : $!\n");
- }
- #------------------------------------------------------------------------------
- # sortie globale txt
- open(FILEGLOBALTXT,">:encoding(UTF-8)", $res."1_SortieGlobale.txt");
- #------------------------------------------------------------------------------
- &parcoursarborescencefichiers($rep); #recurse!
- #------------------------------------------------------------------------------
- close FILEGLOBALTXT;
- #------------------------------------------------------------------------------
- # création de la sortie globale xml
- open(FILEGLOBALXML, ">:encoding(UTF-8)", $res."1_SortieGlobale.xml");
- print FILEGLOBALXML "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
- print FILEGLOBALXML "<PARCOURS>\n";
- print FILEGLOBALXML "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
- print FILEGLOBALXML "<FILTRAGE>";
- #------------------------------------------------------------------------------
- # écrire contenu de la sortie globale xml
- opendir(DIR, $res) or die "Erreur d'ouverture du repertoire: $!\n";
- my @sorties = readdir(DIR);
- closedir(DIR);
- foreach my $sortie (@sorties) {
- if ($sortie=~/(.+?)\.xml$/ && $1 != "1_SortieGlobale") {
- my $rub=$1;
- open(FILE,">>:encoding(UTF-8)", $res.$sortie);
- print FILE "</".$rub.">\n";;
- print FILE "</PARCOURS>\n";
- close(FILE);
- print FILEGLOBALXML "<$rub>\n";
- print FILEGLOBALXML ${"DumpXML".$rub};
- print FILEGLOBALXML "</$rub>";
- }
- }
- print FILEGLOBALXML "</FILTRAGE>\n";
- print FILEGLOBALXML "</PARCOURS>\n";
- close(FILEGLOBALXML);
- #------------------------------------------------------------------------------
- open(FILEGLOBALXML, ">:encoding(UTF-8)", $resBAO2."2_SortieGlobale.xml");
- print FILEGLOBALXML "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
- print FILEGLOBALXML "<PARCOURS>\n";
- print FILEGLOBALXML "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
- print FILEGLOBALXML "<FILTRAGE>";
- #------------------------------------------------------------------------------
- opendir(DIR, $resBAO2) or die "Erreur d'ouverture de repertoire: $!\n";
- @sorties = readdir(DIR);
- closedir(DIR);
- foreach my $sortie (@sorties) {
- # se fait sur chaque sortie xml dans chaque rubrique
- if ($sortie=~/(.+?)\.xml$/ && $1 != "2_SortieGlobale") {
- my $rub = $1;
- open(FILE,">>:encoding(UTF-8)", $resBAO2.$sortie);
- print FILE "</".$rub.">\n";;
- print FILE "</PARCOURS>\n";
- close FILE;
- print FILEGLOBALXML "<$rub>\n";
- print FILEGLOBALXML ${"DumpXML2_Tagged".$rub};
- print FILEGLOBALXML "</$rub>";
- }
- }
- #------------------------------------------------------------------------------
- print FILEGLOBALXML "</FILTRAGE>\n";
- print FILEGLOBALXML "</PARCOURS>\n";
- close(FILEGLOBALXML);
- #------------------------------------------------------------------------------
- # imprime le nombre des infos à la fin du programme
- print "\n" . "nbr files IN = $nb_filesIN\n";
- print "nbr items IN = $nb_itemsIN\n";
- print "nbr items OUT = $nb_itemsOUT\n";
- print "fin du programme.\n";
- exit;
- # fin du main programme
- #------------------------------------------------------------------------------
- #------------------------------------------------------------------------------
- # commencement des subroutines
- #------------------------------------------------------------------------------
- # subroutine pour parcourir l'aborescence
- sub parcoursarborescencefichiers {
- my $path = shift(@_); # chemin vers le dossier en entrée
- opendir(DIR, $path) or die "Probleme d'ouverture du dossier: $!\n";
- my @files = readdir(DIR);
- closedir(DIR);
- #------------------------------------------------------------------------------
- foreach my $file (@files) {
- next if $file =~ /^\.\.?$/; #si . ou ..
- $file = $path."/".$file;
- #si $file est un dossier
- if (-d $file) {
- &parcoursarborescencefichiers($file); #recurse!
- }
- # faire le traitement si $file est un fichier
- if (-f $file) {
- # traiter les fichiers xml seulement
- if ($file=~/^[^(fil)]+?\.xml$/) {
- $nb_filesIN++;
- print $file,"\n";
- #lire le fichier xml
- open(FILE,$file);
- my $firstLine = <FILE>;
- my $encodage = "";
- #vérifier encodage du fichier xml
- if($firstLine =~ /encoding= ?['"]([^\'"]+)['"]/) {
- $encodage = $1; #extraire l'encodage
- }
- close(FILE);
- # si on trouve l'encodage, le fichier est reouvert avec l'encodage correcte
- if (!($encodage eq "")) {
- open(FILE,"<:encoding($encodage)",$file);
- my $texte = "";
- #éliminer les retours à ligne dans le fichier [ \n et \r ]
- while (my $ligne = <FILE>) {
- $ligne =~ s/\n//g;
- $ligne =~ s/\r//g;
- $texte .= $ligne;
- }
- close FILE;
- $texte =~ s/> *?</></g; # coller les balises
- #------------------------------------------------------------------------------
- # extraire rubrique, date et nom
- $texte =~ /<channel>.*?<title>(.*?)<\/title>.*?<pubDate>(.+?)<\/pubDate>.*?<\/channel>/;
- # nettoyer les rubriques
- my $rubrique = &nettoyerRubriques($1);
- print "RUBRIQUE : $rubrique\n";
- # extraire la date
- my $date = &nettoyerRubriques($2);
- # nom du fichier
- my $name = $file;
- # uniquement les fichiers XML contenant les mises à jour
- $name =~ s/.*?(20.*)/$1/;
- #------------------------------------------------------------------------------
- # ouvre des balises et écrire dans des fichiers de sortie
- my $cheminXML=$res.$rubrique.".xml";
- # si on n'a pas encore vu le rubrique on doit le créer
- if (! -e $cheminXML) {
- # créer un fichier
- if (!open (FILEOUT,">:encoding(UTF-8)",$cheminXML)) {
- die "Probleme a la creation du fichier $cheminXML : $!";
- }
- # ouverture des balises XML du début du fichier
- print FILEOUT "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
- print FILEOUT "<PARCOURS>\n";
- print FILEOUT "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
- print FILEOUT "<$rubrique>\n";
- print FILEOUT "<file>";
- print FILEOUT "<name>$name</name>";
- print FILEOUT "<date>$date</date>";
- print FILEOUT "<items>";
- close(FILEOUT);
- ${"DumpXML"."$rubrique"}="";
- }
- # si le fichier existe déjà
- else {
- if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML)) {
- die "Problème a l'ouverture du fichier $cheminXML : $!\n";
- }
- print FILEOUT "<file>";
- print FILEOUT "<name>$name</name>";
- print FILEOUT "<date>$date</date>";
- print FILEOUT "<items>";
- close(FILEOUT);
- }
- #------------------------------------------------------------------------------
- my $cheminXML_BAO2=$resBAO2.$rubrique.".xml";
- # si on n'a pas encore vu le rubrique
- if (! -e $cheminXML_BAO2) {
- # créer un fichier
- if (!open (FILEOUT,">:encoding(UTF-8)",$cheminXML_BAO2)) {
- die "Probleme a la creation du fichier $cheminXML_BAO2 : $!\n";
- }
- # ouverture des balises XML du début du fichier
- print FILEOUT "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
- print FILEOUT "<PARCOURS>\n";
- print FILEOUT "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
- print FILEOUT "<$rubrique>\n";
- print FILEOUT "<file>";
- print FILEOUT "<name>$name</name>";
- print FILEOUT "<date>$date</date>";
- print FILEOUT "<items>";
- close(FILEOUT);
- ${"DumpXML_tagged"."$rubrique"}="";
- }
- # si le fichier existe déjà
- else {
- if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML_BAO2)) {
- die "Problème a l'ouverture du fichier $cheminXML_BAO2 : $!\n";
- }
- print FILEOUT "<file>";
- print FILEOUT "<name>$file</name>";
- print FILEOUT "<date>$date</date>";
- print FILEOUT "<items>";
- close(FILEOUT);
- }
- #------------------------------------------------------------------------------
- # extractions des titres et descriptions
- while ($texte =~ /<item>.*?<title>(.*?)<\/title>.*?<description>(.*?)<\/description>/g)
- {
- my $titre = $1;
- my $description = $2;
- $nb_itemsIN++;
- #------------------------------------------------------------------------------
- # nettoyer le texte
- if (!(exists ($dicoTitre{$titre})) and !(exists ($dicoDescription{$description})))
- {
- $dicoTitre{$titre}++;
- $dicoDescription{$description}++;
- $titre = XML::Entities::decode('all', $titre);
- $descritpion = XML::Entities::decode('all', $description);
- $titre = HTML::Entities::decode($titre);
- $description = HTML::Entities::decode($description);
- $tmptexteBRUT.="$titre \n";
- $tmptexteBRUT.="$description \n";
- $tmptexteXML.="<item><title>$titre</title><description>$description</description></item>\n";
- #--------------------------------------------------------------------------------------
- # nettoyage des balises <description> pour supprimer les balises superflues
- $tmptexteXML =~ s/<img.*?\/><\/description>/<\/description>/g;
- $tmptexteBRUT =~ s/<img.*?\/> \n/\n/g;
- }
- if (!(($titre eq "") or ($description eq ""))) {
- #------------------------------------------------------------------------------
- # convertir si besoin en utf-8
- if (uc($encodage) ne "UTF-8") {
- utf8($titre);
- utf8($description);
- }
- #------------------------------------------------------------------------------
- # regarde si on a déjà vu le texte
- if (!((exists $dicoTitre{$rubrique . $titre}) && (exists $dicoDescription{$rubrique . $description})))
- {
- $dicoTitre{$rubrique . $titre} = "1";
- $dicoDescription{$rubrique . $description} = "1";
- $nb_itemsOUT++;
- #------------------------------------------------------------------------------
- # faire l'etiquetage
- my $titre_tagged = &treetagger($titre);
- my $description_tagged = &treetagger($description);
- open(LOG, ">>", "log_bao2.txt");
- if(exists $dico_files{$file}){
- $count_file = int($dico_files{$file});
- $count_file++;
- %dico_files = ($file => $count_file);
- } else {
- %dico_files = ($file => 1);
- }
- #creer l`objet date pour ecire les date dans le fichier de log
- my $date_time = ctime();
- #ecrire le fichier de log avec le nom du fichier et l`heure de lecture
- print LOG $file." ".$dico_files{$file}."\t\t read on ".$date_time."\n";
- # mettre dans les sorties xml
- if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML)) {
- die "Problème a l'ouverture du fichier $cheminXML : $!\n";
- }
- print FILEOUT "<item>\n";
- print FILEOUT $tmptexteXML;
- print FILEOUT "</item>\n";
- close(FILEOUT);
- #------------------------------------------------------------------------------
- # créer un dump pour chaque rubrique
- ${"DumpXML" . $rubrique} .= $tmptexteXML."\n";
- #------------------------------------------------------------------------------
- # partie de sorties txt
- my $cheminTXT = $res . $rubrique . ".txt";
- # si on n'a pas encore vu la rubrique
- if (! -e $cheminTXT) {
- if (!open (FILEGLOBALTXT,">:encoding(iso-8859-15)",$cheminTXT)) {
- die "Problème a l'ouverture du fichier $cheminTXT : $!\n";
- }
- # écrire dans le sortie txt
- print FILEGLOBALTXT $tmptexteBRUT;
- close(FILEGLOBALTXT);
- }
- # si on a déjà vu la rubrique
- else {
- if (!open (FILEGLOBALTXT,">>:encoding(iso-8859-15)",$cheminTXT)) {
- die "Problème a l'ouverture du fichier $cheminTXT : $!\n";
- }
- # écrire dans la sortie txt
- print FILEGLOBALTXT $tmptexteBRUT;
- close(FILEGLOBALTXT);
- }
- if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML_BAO2)) {
- die "Problème a l'ouverture du fichier $cheminXML_BAO2 : $!\n";
- }
- print FILEOUT "<item>\n";
- print FILEOUT $tmptexteXML;
- print FILEOUT "</item>\n";
- close(FILEOUT);
- # créer un dump pour chaque rubrique
- ${"DumpXML2_Tagged".$rubrique}.= $tmptexteXML."\n";
- }
- }
- }
- # fermer la balise file pour chaque fichier xml
- if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML))
- {
- die "Problème a l'ouverture du fichier .$cheminXML : $!\n";
- }
- print FILEOUT "</items>";
- print FILEOUT "</file>";
- close(FILEOUT);
- # fermer la balise les fichier xml etiqutée
- if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML_BAO2)) {
- die "Problème a l'ouverture du fichier .$cheminXML_BAO2 : $!\n";
- }
- print FILEOUT "</items>";
- print FILEOUT "</file>";
- close(FILEOUT);
- }
- }
- }
- }
- }
- #------------------------------------------------------------------------------
- # subroutine pour nettoyer des rubriques
- #------------------------------------------------------------------------------
- sub nettoyerRubriques {
- my $rubrique = shift;
- $rubrique =~ s/Le Monde.fr//g;
- $rubrique =~ s/LeMonde.fr//g;
- $rubrique =~ s/: Toute l'actualité sur//g;
- $rubrique =~ s/É/e/g;
- $rubrique =~ s/é/e/g;
- $rubrique =~ s/è/e/g;
- $rubrique =~ s/ê/a/g;
- $rubrique =~ s/ë/e/g;
- $rubrique =~ s/ï/i/g;
- $rubrique =~ s/î/i/g;
- $rubrique =~ s/à/a/g;
- $rubrique =~ s/ô/o/g;
- $rubrique =~ s/,/_/g;
- $rubrique = uc($rubrique);
- $rubrique =~ s/ //g;
- $rubrique =~ s/[\.\:;\'\"\-]+//g;
- return $rubrique;
- }
- #------------------------------------------------------------------------------
- # subroutine pour tokenisation et etiquetage
- #------------------------------------------------------------------------------
- sub treetagger {
- my $texte = shift;
- my $temptag;
- # créer un fichier temporaire pour tagger des morceaux de texte
- open($temptag, ">:encoding(UTF-8)", "./temptag.txt");
- print $temptag $texte;
- close($temptag);
- system("perl tokenise-utf8.pl ./temptag.txt | tree-tagger.exe -lemma -token -no-unknown -sgml ./french.par > treetagger.txt");
- system("perl treetagger2xml-utf8.pl treetagger.txt utf-8");
- open(TaggedOUT,"<:encoding(utf-8)","treetagger.txt.xml");
- my $tagged_text = "";
- #lire la ligne d'en tête du fichier xml étiqueté, pour éviter que cette ligne soit incluse dans le nouveau fichier xml
- my $line_den_tete = <TaggedOUT>;
- while (my $l = <TaggedOUT>) {
- $tagged_text .= $l;
- }
- close(TaggedOUT);
- return $tagged_text;
- }
- # fin des subroutines
- #------------------------------------------------------------------------------
- #------------------------------------------------------------------------------
#!/usr/bin/perl -w
<<DOC;
Votre Nom : Bienvenue, Poadey, Cavalcante
MARS 2015
usage : perl parcours-arborescence-fichiers repertoire-a-parcourir
Le programme prend en entrée le nom du répertoire contenant les fichiers
à traiter
Le programme construit en sortie un fichier structuré contenant sur chaque
ligne le nom du fichier et le résultat du filtrage :
<FICHIER><NOM>du fichier</NOM></FICHIER><CONTENU>du filtrage</CONTENU></FICHIER>
DOC
use Unicode::String qw(utf8);
use utf8;
use Time::localtime;
use XML::Entities;
use HTML::Entities;
#------------------------------------------------------------------------------
# des compteurs pour le nombre des items
my $nb_filesIN = 0;
my $nb_itemsIN = 0;
my $nb_itemsOUT = 0;
#------------------------------------------------------------------------------
# le répertoire d'entrée contenant les fichiers xml
my $rep = "$ARGV[0]";
# regex enlever le slash à la fin du nom du répertoire
$rep =~ s/[\/]$//;
#------------------------------------------------------------------------------
# des hash tables pour vérifier qu'on n'a pas deux fois les même infos
my %dicoTitre = ();
my %dicoDescription = ();
# cet hash controle le nombre de fois que le fichier a ete lu pour ecrire le fichier de log
my %dico_files = ();
#creer l`objet date pour ecire la date et l'heure de lecture des fichiers xml dans le fichier de log
my $date_time = ctime();
#------------------------------------------------------------------------------
# creation des dossiers de sortie
my $res = "../Sorties/";
if (! -e $res) {
mkdir($res) or die ("Problème avec la création du répertoire de $rep : $!");
}
$res = "../Sorties/1_Sorties_PurePerl/";
if (! -e $res) {
mkdir($res) or die ("Problème avec la création du répertoire de $rep : $!\n");
}
#------------------------------------------------------------------------------
# sorties etiquetées
my $resBAO2 = "../Sorties/2_Sorties_Etiquetees/";
if (! -e $resBAO2) {
mkdir($resBAO2) or die ("Problème avec la création du répertoire de $rep : $!\n");
}
#------------------------------------------------------------------------------
# sortie globale txt
open(FILEGLOBALTXT,">:encoding(UTF-8)", $res."1_SortieGlobale.txt");
#------------------------------------------------------------------------------
&parcoursarborescencefichiers($rep); #recurse!
#------------------------------------------------------------------------------
close FILEGLOBALTXT;
#------------------------------------------------------------------------------
# création de la sortie globale xml
open(FILEGLOBALXML, ">:encoding(UTF-8)", $res."1_SortieGlobale.xml");
print FILEGLOBALXML "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print FILEGLOBALXML "<PARCOURS>\n";
print FILEGLOBALXML "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
print FILEGLOBALXML "<FILTRAGE>";
#------------------------------------------------------------------------------
# écrire contenu de la sortie globale xml
opendir(DIR, $res) or die "Erreur d'ouverture du repertoire: $!\n";
my @sorties = readdir(DIR);
closedir(DIR);
foreach my $sortie (@sorties) {
if ($sortie=~/(.+?)\.xml$/ && $1 != "1_SortieGlobale") {
my $rub=$1;
open(FILE,">>:encoding(UTF-8)", $res.$sortie);
print FILE "</".$rub.">\n";;
print FILE "</PARCOURS>\n";
close(FILE);
print FILEGLOBALXML "<$rub>\n";
print FILEGLOBALXML ${"DumpXML".$rub};
print FILEGLOBALXML "</$rub>";
}
}
print FILEGLOBALXML "</FILTRAGE>\n";
print FILEGLOBALXML "</PARCOURS>\n";
close(FILEGLOBALXML);
#------------------------------------------------------------------------------
open(FILEGLOBALXML, ">:encoding(UTF-8)", $resBAO2."2_SortieGlobale.xml");
print FILEGLOBALXML "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print FILEGLOBALXML "<PARCOURS>\n";
print FILEGLOBALXML "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
print FILEGLOBALXML "<FILTRAGE>";
#------------------------------------------------------------------------------
opendir(DIR, $resBAO2) or die "Erreur d'ouverture de repertoire: $!\n";
@sorties = readdir(DIR);
closedir(DIR);
foreach my $sortie (@sorties) {
# se fait sur chaque sortie xml dans chaque rubrique
if ($sortie=~/(.+?)\.xml$/ && $1 != "2_SortieGlobale") {
my $rub = $1;
open(FILE,">>:encoding(UTF-8)", $resBAO2.$sortie);
print FILE "</".$rub.">\n";;
print FILE "</PARCOURS>\n";
close FILE;
print FILEGLOBALXML "<$rub>\n";
print FILEGLOBALXML ${"DumpXML2_Tagged".$rub};
print FILEGLOBALXML "</$rub>";
}
}
#------------------------------------------------------------------------------
print FILEGLOBALXML "</FILTRAGE>\n";
print FILEGLOBALXML "</PARCOURS>\n";
close(FILEGLOBALXML);
#------------------------------------------------------------------------------
# imprime le nombre des infos à la fin du programme
print "\n" . "nbr files IN = $nb_filesIN\n";
print "nbr items IN = $nb_itemsIN\n";
print "nbr items OUT = $nb_itemsOUT\n";
print "fin du programme.\n";
exit;
# fin du main programme
#------------------------------------------------------------------------------
#------------------------------------------------------------------------------
# commencement des subroutines
#------------------------------------------------------------------------------
# subroutine pour parcourir l'aborescence
sub parcoursarborescencefichiers {
my $path = shift(@_); # chemin vers le dossier en entrée
opendir(DIR, $path) or die "Probleme d'ouverture du dossier: $!\n";
my @files = readdir(DIR);
closedir(DIR);
#------------------------------------------------------------------------------
foreach my $file (@files) {
next if $file =~ /^\.\.?$/; #si . ou ..
$file = $path."/".$file;
#si $file est un dossier
if (-d $file) {
&parcoursarborescencefichiers($file); #recurse!
}
# faire le traitement si $file est un fichier
if (-f $file) {
# traiter les fichiers xml seulement
if ($file=~/^[^(fil)]+?\.xml$/) {
$nb_filesIN++;
print $file,"\n";
#lire le fichier xml
open(FILE,$file);
my $firstLine = <FILE>;
my $encodage = "";
#vérifier encodage du fichier xml
if($firstLine =~ /encoding= ?['"]([^\'"]+)['"]/) {
$encodage = $1; #extraire l'encodage
}
close(FILE);
# si on trouve l'encodage, le fichier est reouvert avec l'encodage correcte
if (!($encodage eq "")) {
open(FILE,"<:encoding($encodage)",$file);
my $texte = "";
#éliminer les retours à ligne dans le fichier [ \n et \r ]
while (my $ligne = <FILE>) {
$ligne =~ s/\n//g;
$ligne =~ s/\r//g;
$texte .= $ligne;
}
close FILE;
$texte =~ s/> *?</></g; # coller les balises
#------------------------------------------------------------------------------
# extraire rubrique, date et nom
$texte =~ /<channel>.*?<title>(.*?)<\/title>.*?<pubDate>(.+?)<\/pubDate>.*?<\/channel>/;
# nettoyer les rubriques
my $rubrique = &nettoyerRubriques($1);
print "RUBRIQUE : $rubrique\n";
# extraire la date
my $date = &nettoyerRubriques($2);
# nom du fichier
my $name = $file;
# uniquement les fichiers XML contenant les mises à jour
$name =~ s/.*?(20.*)/$1/;
#------------------------------------------------------------------------------
# ouvre des balises et écrire dans des fichiers de sortie
my $cheminXML=$res.$rubrique.".xml";
# si on n'a pas encore vu le rubrique on doit le créer
if (! -e $cheminXML) {
# créer un fichier
if (!open (FILEOUT,">:encoding(UTF-8)",$cheminXML)) {
die "Probleme a la creation du fichier $cheminXML : $!";
}
# ouverture des balises XML du début du fichier
print FILEOUT "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print FILEOUT "<PARCOURS>\n";
print FILEOUT "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
print FILEOUT "<$rubrique>\n";
print FILEOUT "<file>";
print FILEOUT "<name>$name</name>";
print FILEOUT "<date>$date</date>";
print FILEOUT "<items>";
close(FILEOUT);
${"DumpXML"."$rubrique"}="";
}
# si le fichier existe déjà
else {
if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML)) {
die "Problème a l'ouverture du fichier $cheminXML : $!\n";
}
print FILEOUT "<file>";
print FILEOUT "<name>$name</name>";
print FILEOUT "<date>$date</date>";
print FILEOUT "<items>";
close(FILEOUT);
}
#------------------------------------------------------------------------------
my $cheminXML_BAO2=$resBAO2.$rubrique.".xml";
# si on n'a pas encore vu le rubrique
if (! -e $cheminXML_BAO2) {
# créer un fichier
if (!open (FILEOUT,">:encoding(UTF-8)",$cheminXML_BAO2)) {
die "Probleme a la creation du fichier $cheminXML_BAO2 : $!\n";
}
# ouverture des balises XML du début du fichier
print FILEOUT "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print FILEOUT "<PARCOURS>\n";
print FILEOUT "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
print FILEOUT "<$rubrique>\n";
print FILEOUT "<file>";
print FILEOUT "<name>$name</name>";
print FILEOUT "<date>$date</date>";
print FILEOUT "<items>";
close(FILEOUT);
${"DumpXML_tagged"."$rubrique"}="";
}
# si le fichier existe déjà
else {
if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML_BAO2)) {
die "Problème a l'ouverture du fichier $cheminXML_BAO2 : $!\n";
}
print FILEOUT "<file>";
print FILEOUT "<name>$file</name>";
print FILEOUT "<date>$date</date>";
print FILEOUT "<items>";
close(FILEOUT);
}
#------------------------------------------------------------------------------
# extractions des titres et descriptions
while ($texte =~ /<item>.*?<title>(.*?)<\/title>.*?<description>(.*?)<\/description>/g)
{
my $titre = $1;
my $description = $2;
$nb_itemsIN++;
#------------------------------------------------------------------------------
# nettoyer le texte
if (!(exists ($dicoTitre{$titre})) and !(exists ($dicoDescription{$description})))
{
$dicoTitre{$titre}++;
$dicoDescription{$description}++;
$titre = XML::Entities::decode('all', $titre);
$descritpion = XML::Entities::decode('all', $description);
$titre = HTML::Entities::decode($titre);
$description = HTML::Entities::decode($description);
$tmptexteBRUT.="$titre \n";
$tmptexteBRUT.="$description \n";
$tmptexteXML.="<item><title>$titre</title><description>$description</description></item>\n";
#--------------------------------------------------------------------------------------
# nettoyage des balises <description> pour supprimer les balises superflues
$tmptexteXML =~ s/<img.*?\/><\/description>/<\/description>/g;
$tmptexteBRUT =~ s/<img.*?\/> \n/\n/g;
}
if (!(($titre eq "") or ($description eq ""))) {
#------------------------------------------------------------------------------
# convertir si besoin en utf-8
if (uc($encodage) ne "UTF-8") {
utf8($titre);
utf8($description);
}
#------------------------------------------------------------------------------
# regarde si on a déjà vu le texte
if (!((exists $dicoTitre{$rubrique . $titre}) && (exists $dicoDescription{$rubrique . $description})))
{
$dicoTitre{$rubrique . $titre} = "1";
$dicoDescription{$rubrique . $description} = "1";
$nb_itemsOUT++;
#------------------------------------------------------------------------------
# faire l'etiquetage
my $titre_tagged = &treetagger($titre);
my $description_tagged = &treetagger($description);
open(LOG, ">>", "log_bao2.txt");
if(exists $dico_files{$file}){
$count_file = int($dico_files{$file});
$count_file++;
%dico_files = ($file => $count_file);
} else {
%dico_files = ($file => 1);
}
#creer l`objet date pour ecire les date dans le fichier de log
my $date_time = ctime();
#ecrire le fichier de log avec le nom du fichier et l`heure de lecture
print LOG $file." ".$dico_files{$file}."\t\t read on ".$date_time."\n";
# mettre dans les sorties xml
if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML)) {
die "Problème a l'ouverture du fichier $cheminXML : $!\n";
}
print FILEOUT "<item>\n";
print FILEOUT $tmptexteXML;
print FILEOUT "</item>\n";
close(FILEOUT);
#------------------------------------------------------------------------------
# créer un dump pour chaque rubrique
${"DumpXML" . $rubrique} .= $tmptexteXML."\n";
#------------------------------------------------------------------------------
# partie de sorties txt
my $cheminTXT = $res . $rubrique . ".txt";
# si on n'a pas encore vu la rubrique
if (! -e $cheminTXT) {
if (!open (FILEGLOBALTXT,">:encoding(iso-8859-15)",$cheminTXT)) {
die "Problème a l'ouverture du fichier $cheminTXT : $!\n";
}
# écrire dans le sortie txt
print FILEGLOBALTXT $tmptexteBRUT;
close(FILEGLOBALTXT);
}
# si on a déjà vu la rubrique
else {
if (!open (FILEGLOBALTXT,">>:encoding(iso-8859-15)",$cheminTXT)) {
die "Problème a l'ouverture du fichier $cheminTXT : $!\n";
}
# écrire dans la sortie txt
print FILEGLOBALTXT $tmptexteBRUT;
close(FILEGLOBALTXT);
}
if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML_BAO2)) {
die "Problème a l'ouverture du fichier $cheminXML_BAO2 : $!\n";
}
print FILEOUT "<item>\n";
print FILEOUT $tmptexteXML;
print FILEOUT "</item>\n";
close(FILEOUT);
# créer un dump pour chaque rubrique
${"DumpXML2_Tagged".$rubrique}.= $tmptexteXML."\n";
}
}
}
# fermer la balise file pour chaque fichier xml
if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML))
{
die "Problème a l'ouverture du fichier .$cheminXML : $!\n";
}
print FILEOUT "</items>";
print FILEOUT "</file>";
close(FILEOUT);
# fermer la balise les fichier xml etiqutée
if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML_BAO2)) {
die "Problème a l'ouverture du fichier .$cheminXML_BAO2 : $!\n";
}
print FILEOUT "</items>";
print FILEOUT "</file>";
close(FILEOUT);
}
}
}
}
}
#------------------------------------------------------------------------------
# subroutine pour nettoyer des rubriques
#------------------------------------------------------------------------------
sub nettoyerRubriques {
my $rubrique = shift;
$rubrique =~ s/Le Monde.fr//g;
$rubrique =~ s/LeMonde.fr//g;
$rubrique =~ s/: Toute l'actualité sur//g;
$rubrique =~ s/É/e/g;
$rubrique =~ s/é/e/g;
$rubrique =~ s/è/e/g;
$rubrique =~ s/ê/a/g;
$rubrique =~ s/ë/e/g;
$rubrique =~ s/ï/i/g;
$rubrique =~ s/î/i/g;
$rubrique =~ s/à/a/g;
$rubrique =~ s/ô/o/g;
$rubrique =~ s/,/_/g;
$rubrique = uc($rubrique);
$rubrique =~ s/ //g;
$rubrique =~ s/[\.\:;\'\"\-]+//g;
return $rubrique;
}
#------------------------------------------------------------------------------
# subroutine pour tokenisation et etiquetage
#------------------------------------------------------------------------------
sub treetagger {
my $texte = shift;
my $temptag;
# créer un fichier temporaire pour tagger des morceaux de texte
open($temptag, ">:encoding(UTF-8)", "./temptag.txt");
print $temptag $texte;
close($temptag);
system("perl tokenise-utf8.pl ./temptag.txt | tree-tagger.exe -lemma -token -no-unknown -sgml ./french.par > treetagger.txt");
system("perl treetagger2xml-utf8.pl treetagger.txt utf-8");
open(TaggedOUT,"<:encoding(utf-8)","treetagger.txt.xml");
my $tagged_text = "";
#lire la ligne d'en tête du fichier xml étiqueté, pour éviter que cette ligne soit incluse dans le nouveau fichier xml
my $line_den_tete = <TaggedOUT>;
while (my $l = <TaggedOUT>) {
$tagged_text .= $l;
}
close(TaggedOUT);
return $tagged_text;
}
# fin des subroutines
#------------------------------------------------------------------------------
#------------------------------------------------------------------------------
Exemplo de resultados da Ferramenta 2
Os resultados da Ferramenta 2 estão em formatos diferentes: .xml, .txt e .cnr (extensão do Cordial).
Um exemplo de saída TreeTagger em formato XML.
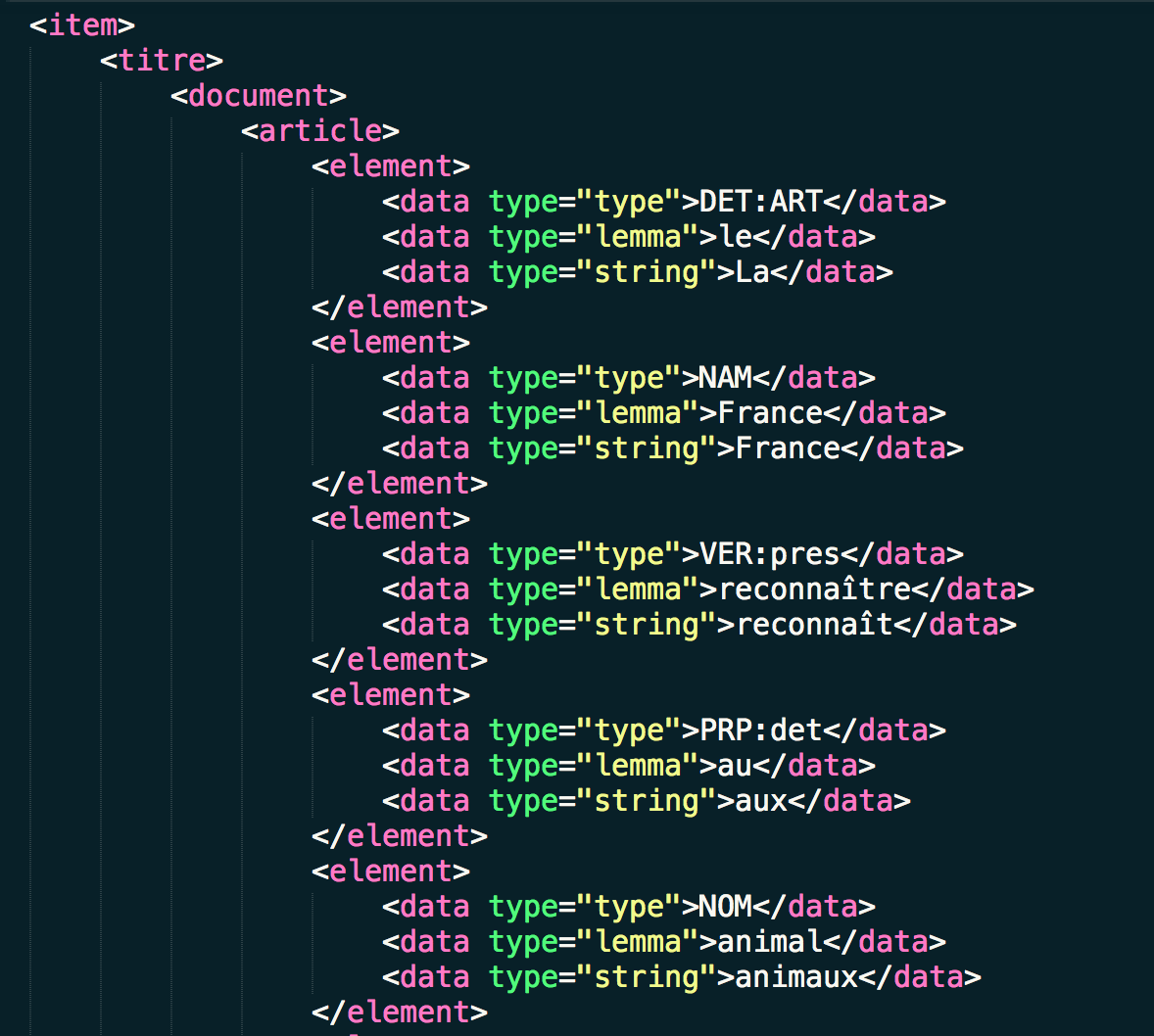
Um exemplo de saída TXT (os mesmo que na Ferramenta 1)
Exemplo da saída do Cordial em formato CNR.

O que a Ferramenta 3 faz?
A Ferramenta 3 é composta de dois* scripts diferentes, um para cada saída(TreeTagger e Cordial). Os programas buscam nas saídas padrões morfosintáticos específicos (ex. substantivo-preposição-substantivo).
Recapitulação dos restultados tratados pela Ferramenta 3:
Exemplo de saída do TreeTagger
Exemplo de saída do Cordial
Para este programa, nós realizamos duas abordagens diferenes. Alguns programas necessitam de um arquivos externo TXT que contém os padrões morfosintáticos que estamos procurando e outros são inclusos diretamente nos script. Nas versões finais, nós podemos verificar que nós utilizamos a primeira opção. A utilização de um arquivo externo contendo os padrões facilita a modificição da pesquisa. O mesmo não pode ser dito sobre a mudança de padrões quando eles estão inclusos na estrutura do script.
Esta parte possue também dois arquivos XSL qui não contém código Perl, mas que produzem resultados muito similares àqueles produzidos pelos scripts. XSL é o acrônimo de Extensible Stylesheet Language. Os dois arquivos que nós possuímos são folhas de estilo para os nossos arquivos XMl que nos permetem exiber os elementos contidos nas tags que estamos buscando.
Nosso algoritmo lê cada ítem na terceira coluna do arquivo (a etiqueta de parte do discurso) e verifica se ela coincide com o primeiro ítem do padrão desejado. Caso nao, o script segue para os próximo ítem no arquivo. Caso sim, o script segue a verificação para se certificar que o próximo ítem combina com o próximo ítem na lista de padrões estabelecidade pelo usuário. Se a sequência combina até, ela é extraída e considerada como "compatível". Abaixo nós temos um diagrama básico que deve ser lido da esquerda para direita, de cima para baixo que ilustra o funcionamento do script.
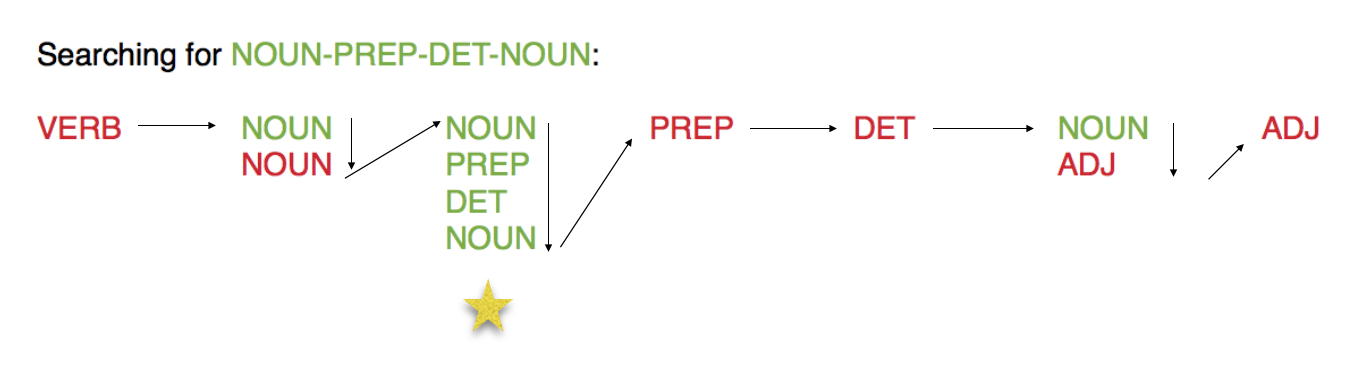
*Claro nós poderíamos escrever um único script que trataria ambos os casos. Porém, é melhor ter dois script para estocar os dados separadamente e limpos.
Os métodos de três professores diferentes para extrair as sequências morfosintáticas a partir dos dados obtidos via Cordial e TreeTagger.
Extração das sequências morfosintáticas a partir de dados Cordial
- #!/usr/bin/perl
- <<DOC;
- prend en entrée un fichier issu de treetagger
- et un fichier de patrons morphosyntaxiques et
- extrait suites de tokens correspondant aux patrons morpho-syntaxiques
- DOC
- open(FIC, $ARGV[0]) or die "impossible ouvrir $ARGV[0] : $!";
- print "choisis nom de fichier pour contenir termes extraits\n";
- my $fic=<STDIN>;
- open(FIC1, ">$fic");
- my $i=0;
- my $j=0;
- my $k=0;
- my @token=();
- while (<FIC>)
- {
- my $ligne=$_;
- chomp $ligne;
- my @liste=split(/\t/,$ligne);
- push(@token, $liste[$i++]." ");
- push(@lemme, "$liste[$i++]" ." ");
- push(@patron, "$liste[$i++]" ." ");
- $i=0;
- }
- #on a 3 listes @token, @lemme, @patron
- @sous_patron=();
- while (defined($element_patron=shift(@patron)))
- {
- $element_patron=~s/\n//;
- if ($element_patron !~ "PCTFORTE")
- {
- push(@sous_patron, $element_patron);
- $j++;
- next;
- }
- my @sous_token=@token[$k..$j-1];
- &cherche_patron(@sous_patron);
- @sous_patron=();
- $k=$j+1;
- #print "tape return pour continuer";
- #my $reponse=<STDIN>;
- $j++;
- }
- #=============================================
- sub cherche_patron
- {
- my @liste=@_;
- my $suite_de_patrons=join("",@liste);
- $z=0;
- $nb=0;
- open(FIC, "$ARGV[1]");
- while(<FIC>)
- {
- $nb=0;
- $ligne=$_;
- chomp $ligne;
- #print "voici le patron traité : $ligne\n";
- while ($ligne=~m/ /g) {$nb++};
- $nb++;
- while ($suite_de_patrons=~m/$ligne/g)
- {
- my $avant=substr ($suite_de_patrons, 0, pos($suite_de_patrons)-length($&));
- while ($avant=~m/ /g) {$z++};
- print FIC1 "@token[$k+$z..$k+$z+$nb-1]\n";
- #print "tape sur return pour continuer\n";
- #my $reponse=<STDIN>;
- $z=0;
- }
- }
- }
#!/usr/bin/perl
<<DOC;
prend en entrée un fichier issu de treetagger
et un fichier de patrons morphosyntaxiques et
extrait suites de tokens correspondant aux patrons morpho-syntaxiques
DOC
open(FIC, $ARGV[0]) or die "impossible ouvrir $ARGV[0] : $!";
print "choisis nom de fichier pour contenir termes extraits\n";
my $fic=<STDIN>;
open(FIC1, ">$fic");
my $i=0;
my $j=0;
my $k=0;
my @token=();
while (<FIC>)
{
my $ligne=$_;
chomp $ligne;
my @liste=split(/\t/,$ligne);
push(@token, $liste[$i++]." ");
push(@lemme, "$liste[$i++]" ." ");
push(@patron, "$liste[$i++]" ." ");
$i=0;
}
#on a 3 listes @token, @lemme, @patron
@sous_patron=();
while (defined($element_patron=shift(@patron)))
{
$element_patron=~s/\n//;
if ($element_patron !~ "PCTFORTE")
{
push(@sous_patron, $element_patron);
$j++;
next;
}
my @sous_token=@token[$k..$j-1];
&cherche_patron(@sous_patron);
@sous_patron=();
$k=$j+1;
#print "tape return pour continuer";
#my $reponse=<STDIN>;
$j++;
}
#=============================================
sub cherche_patron
{
my @liste=@_;
my $suite_de_patrons=join("",@liste);
$z=0;
$nb=0;
open(FIC, "$ARGV[1]");
while(<FIC>)
{
$nb=0;
$ligne=$_;
chomp $ligne;
#print "voici le patron traité : $ligne\n";
while ($ligne=~m/ /g) {$nb++};
$nb++;
while ($suite_de_patrons=~m/$ligne/g)
{
my $avant=substr ($suite_de_patrons, 0, pos($suite_de_patrons)-length($&));
while ($avant=~m/ /g) {$z++};
print FIC1 "@token[$k+$z..$k+$z+$nb-1]\n";
#print "tape sur return pour continuer\n";
#my $reponse=<STDIN>;
$z=0;
}
}
}
Dois scripts que extraem sequências morfosintáticas a partir de dados TreeTagger e Cordial.
O primeiro script extrai todos os "substantivos-adjetivos" dos dados TreeTagger.
- open(FILE,"$ARGV[0]");
- #--------------------------------------------
- # le patron cherché ici est du type NOM ADJ"
- #--------------------------------------------
- my @lignes = <FILE>;
- close(FILE);
- while (@lignes) {
- my $ligne = shift(@lignes);
- chomp $ligne;
- my $sequence = "";
- my $longueur = 0;
- if ( $ligne =~ /<element><data type=\"type\">NOM<\/data><data type=\"lemma\">[^<]+<\/data><data type=\"string\">([^<]+)<\/data><\/element>/) {
- my $forme = $1;
- $sequence .= $forme;
- $longueur = 1;
- my $nextligne = $lignes[0];
- if ( $nextligne =~ /<element><data type=\"type\">ADJ<\/data><data type=\"lemma\">[^<]+<\/data><data type=\"string\">([^<]+)<\/data><\/element>/) {
- my $forme = $1;
- $sequence .= " " . $forme;
- $longueur = 2;
- }
- }
- if ($longueur == 2) {
- print $sequence . "\n";
- }
- }
open(FILE,"$ARGV[0]");
#--------------------------------------------
# le patron cherché ici est du type NOM ADJ"
#--------------------------------------------
my @lignes = <FILE>;
close(FILE);
while (@lignes) {
my $ligne = shift(@lignes);
chomp $ligne;
my $sequence = "";
my $longueur = 0;
if ( $ligne =~ /<element><data type=\"type\">NOM<\/data><data type=\"lemma\">[^<]+<\/data><data type=\"string\">([^<]+)<\/data><\/element>/) {
my $forme = $1;
$sequence .= $forme;
$longueur = 1;
my $nextligne = $lignes[0];
if ( $nextligne =~ /<element><data type=\"type\">ADJ<\/data><data type=\"lemma\">[^<]+<\/data><data type=\"string\">([^<]+)<\/data><\/element>/) {
my $forme = $1;
$sequence .= " " . $forme;
$longueur = 2;
}
}
if ($longueur == 2) {
print $sequence . "\n";
}
}
O segundo script extrai todas as sequências "substantivo-preposição" dos dados Cordial.
- open(FILE,"$ARGV[0]");
- #--------------------------------------------
- # le patron cherché ici est du type NOM PREP NOM
- #--------------------------------------------
- my @lignes = <FILE>;
- close(FILE);
- while (@lignes) {
- my $ligne = shift(@lignes);
- chomp $ligne;
- my $sequence = "";
- my $longueur = 0;
- if ( $ligne =~ /^([^\t]+)\t[^\t]+\tNC.*/) {
- my $forme = $1;
- $sequence .= $forme;
- $longueur = 1;
- my $nextligne = $lignes[0];
- if ( $nextligne =~ /^([^\t]+)\t[^\t]+\tPREP.*/) {
- my $forme = $1;
- $sequence .= " " . $forme;
- $longueur = 2;
- my $next_nextligne = $lignes[1];
- if ( $next_nextligne =~ /^([^\t]+)\t[^\t]+\tNC.*/) {
- my $forme = $1;
- $sequence .= " " . $forme;
- $longueur = 3;
- }
- }
- }
- if ($longueur == 3) {
- print $sequence . "\n";
- }
- }
open(FILE,"$ARGV[0]");
#--------------------------------------------
# le patron cherché ici est du type NOM PREP NOM
#--------------------------------------------
my @lignes = <FILE>;
close(FILE);
while (@lignes) {
my $ligne = shift(@lignes);
chomp $ligne;
my $sequence = "";
my $longueur = 0;
if ( $ligne =~ /^([^\t]+)\t[^\t]+\tNC.*/) {
my $forme = $1;
$sequence .= $forme;
$longueur = 1;
my $nextligne = $lignes[0];
if ( $nextligne =~ /^([^\t]+)\t[^\t]+\tPREP.*/) {
my $forme = $1;
$sequence .= " " . $forme;
$longueur = 2;
my $next_nextligne = $lignes[1];
if ( $next_nextligne =~ /^([^\t]+)\t[^\t]+\tNC.*/) {
my $forme = $1;
$sequence .= " " . $forme;
$longueur = 3;
}
}
}
if ($longueur == 3) {
print $sequence . "\n";
}
}
Extração de sequências morfosintáticas a partir de dados TreeTagger.
- #/usr/bin/perl
- <<DOC;
- Nom : Rachid Belmouhoub
- Avril 2012
- usage : perl bao3_rb_new.pl fichier_tag fichier_motif
- DOC
- use strict;
- use utf8;
- use XML::LibXML;
- # Définition globale des encodage d'entrée et sortie du script à utf8
- binmode STDIN, ':encoding(utf8)';
- binmode STDOUT, ':encoding(utf8)';
- # On vérifie le nombre d'arguments de l'appel au script ($0 : le nom du script)
- if($#ARGV!=1){print "usage : perl $0 fichier_tag fichier_motif";exit;}
- # Enregistrement des arguments de la ligne de commande dans les variables idoines
- my $tag_file= shift @ARGV;
- my $patterns_file = shift @ARGV;
- # création de l'objet XML::XPath pour explorer le fichier de sortie tree-tagger XML
- my $xp = XML::LibXML->new(XML_LIBXML_RECOVER => 2);
- $xp->recover_silently(1);
- my $dom = $xp->load_xml( location => $tag_file );
- my $root = $dom->getDocumentElement();
- my $xpc = XML::LibXML::XPathContext->new($root);
- # Ouverture du fichiers de motifs
- open(PATTERNSFILE, $patterns_file) or die "can't open $patterns_file: $!\n";
- # lecture du fichier contenant les motifs, un motif par ligne (par exemple : NOM ADJ)
- while (my $ligne = <PATTERNSFILE>) {
- # Appel à la procédure d'extraction des motifs
- &extract_pattern($ligne);
- }
- # Fermeture du fichiers de motifs
- close(PATTERNSFILE);
- # routine de construction des chemins XPath
- sub construit_XPath{
- # On récupère la ligne du motif recherché
- my $local_ligne=shift @_;
- # initialisation du chemin XPath
- my $search_path="";
- # on supprime avec la fonction chomp un éventuel retour à la ligne
- chomp($local_ligne);
- # on élimine un éveltuel retour chariot hérité de windows
- $local_ligne=~ s/\r$//;
- # Construction au moyen de la fonction split d'un tableau dont chaque élément a pour valeur un élément du motif recherché
- my @tokens=split(/ /,$local_ligne);
- # On commence ici la construction du chemin XPath
- # Ce chemin correspond au premier noeud "element" de l'arbre XML qui répond au motif cherché
- $search_path="//element[contains(data[\@type=\"type\"],\"$tokens[0]\")]";
- # Initialisation du compteur pour la boucle de construction du chemin XPath
- my $i=1;
- while ($i < $#tokens) {
- $search_path.="[following-sibling::element[1][contains(data[\@type=\"type\"],\"$tokens[$i]\")]";
- $i++;
- }
- my $search_path_suffix="]";
- # on utilise l'opérateur x qui permet de répéter la chaine de caractère à sa gauche autant de fois que l'entier à sa droite,
- # soit $i fois $search_path_suffix
- $search_path_suffix=$search_path_suffix x $i;
- # le chemin XPath final
- $search_path.="[following-sibling::element[1][contains(data[\@type=\"type\"],\"".$tokens[$#tokens]."\")]"
- .$search_path_suffix;
- # print "$search_path\n";
- # on renvoie à la procédure appelante le chein XPath et le tableau des éléments du motif
- return ($search_path,@tokens);
- }
- # routine d'extraction du motif
- sub extract_pattern{
- # On récupère la ligne du motif recherché
- my $ext_pat_ligne= shift @_;
- # Appel de la fonction construit_XPath pour le motif lu à la ligne courrante du fichier de motif
- my ($search_path,@tokens) = &construit_XPath($ext_pat_ligne);
- # définition du nom du fichier de résultats pour le motif en utilisant la fonction join
- my $match_file = "res_extract-".join('_', @tokens).".txt";
- # Ouverture du fichiers de résultats encodé en UTF-8
- open(MATCHFILE,">:encoding(UTF-8)", "$match_file") or die "can't open $match_file: $!\n";
- # création de l'objet XML::XPath pour explorer le fichier de sortie tree-tagger XML
- # Parcours des noeuds du ficher XML correspondant au motif, au moyen de la méthode findnodes
- # qui prend pour argument le chemin XPath construit précédement
- # avec la fonction "construit_XPath"
- my @nodes=$root->findnodes($search_path);
- foreach my $noeud ( @nodes) {
- # Initialisation du chemin XPath relatif du noeud "data" contenant
- # la forme correspondant au premier élément du motif
- # Ce chemin est relatif au premier noeud "element" du bloc retourné
- # et pointe sur le troisième noeud "data" fils du noeud "element"
- # en l'identifiant par la valeur "string" de son attribut "type"
- my $form_xpath="";
- $form_xpath="./data[\@type=\"string\"]";
- # Initialisation du compteur pour la boucle d'éxtraction des formes correspondants
- # aux éléments suivants du motif
- my $following=0;
- # Recherche du noeud data contenant la forme correspondant au premier élément du motif
- # au moyen de la fonction "find" qui prend pour arguments:
- # 1. le chemin XPath relatif du noeud "data"
- # 2. le noeud en cours de traitement dans cette boucle foreach
- # la fonction "find" retourne par défaut une liste de noeuds, dans notre cas cette liste
- # ne contient qu'un seul élément que nous récupérons avec la fonction "get_node"
- # enfin nous en imprimons le contenu textuel au moyen de la méthode string_value
- print MATCHFILE $xpc->findvalue($form_xpath,$noeud);
- # Boucle d'éxtraction des formes correspondants aux éléments suivants du motif
- # On descend dans chaque noeud element du bloc
- while ( $following < $#tokens) {
- # Incrémentation du compteur $following de cette boucle d'éxtraction des formes
- $following++;
- # Construction du chemin XPath relatif du noeud "data" contenant
- # la forme correspondant à l'élément suivant du motif
- # Notez bien l'utilisation du compteur $folowing tant dans la condition de la boucle ci-dessus
- # que dans la construction du chemin relatif XPath
- my $following_elmt="following-sibling::element[".$following."]";
- $form_xpath=$following_elmt."/data[\@type=\"string\"]";
- # Impression du contenu textuel du noeud data contenant la forme correspondant à l'élément suivant du motif
- print MATCHFILE " ",$xpc->findvalue($form_xpath,$noeud);
- # Incrémentation du compteur $following de cette boucle d'éxtraction des formes
- # $following++;
- }
- print MATCHFILE "\n";
- }
- # Fermeture du fichiers de motifs
- close(MATCHFILE);
- }
#/usr/bin/perl
<<DOC;
Nom : Rachid Belmouhoub
Avril 2012
usage : perl bao3_rb_new.pl fichier_tag fichier_motif
DOC
use strict;
use utf8;
use XML::LibXML;
# Définition globale des encodage d'entrée et sortie du script à utf8
binmode STDIN, ':encoding(utf8)';
binmode STDOUT, ':encoding(utf8)';
# On vérifie le nombre d'arguments de l'appel au script ($0 : le nom du script)
if($#ARGV!=1){print "usage : perl $0 fichier_tag fichier_motif";exit;}
# Enregistrement des arguments de la ligne de commande dans les variables idoines
my $tag_file= shift @ARGV;
my $patterns_file = shift @ARGV;
# création de l'objet XML::XPath pour explorer le fichier de sortie tree-tagger XML
my $xp = XML::LibXML->new(XML_LIBXML_RECOVER => 2);
$xp->recover_silently(1);
my $dom = $xp->load_xml( location => $tag_file );
my $root = $dom->getDocumentElement();
my $xpc = XML::LibXML::XPathContext->new($root);
# Ouverture du fichiers de motifs
open(PATTERNSFILE, $patterns_file) or die "can't open $patterns_file: $!\n";
# lecture du fichier contenant les motifs, un motif par ligne (par exemple : NOM ADJ)
while (my $ligne = <PATTERNSFILE>) {
# Appel à la procédure d'extraction des motifs
&extract_pattern($ligne);
}
# Fermeture du fichiers de motifs
close(PATTERNSFILE);
# routine de construction des chemins XPath
sub construit_XPath{
# On récupère la ligne du motif recherché
my $local_ligne=shift @_;
# initialisation du chemin XPath
my $search_path="";
# on supprime avec la fonction chomp un éventuel retour à la ligne
chomp($local_ligne);
# on élimine un éveltuel retour chariot hérité de windows
$local_ligne=~ s/\r$//;
# Construction au moyen de la fonction split d'un tableau dont chaque élément a pour valeur un élément du motif recherché
my @tokens=split(/ /,$local_ligne);
# On commence ici la construction du chemin XPath
# Ce chemin correspond au premier noeud "element" de l'arbre XML qui répond au motif cherché
$search_path="//element[contains(data[\@type=\"type\"],\"$tokens[0]\")]";
# Initialisation du compteur pour la boucle de construction du chemin XPath
my $i=1;
while ($i < $#tokens) {
$search_path.="[following-sibling::element[1][contains(data[\@type=\"type\"],\"$tokens[$i]\")]";
$i++;
}
my $search_path_suffix="]";
# on utilise l'opérateur x qui permet de répéter la chaine de caractère à sa gauche autant de fois que l'entier à sa droite,
# soit $i fois $search_path_suffix
$search_path_suffix=$search_path_suffix x $i;
# le chemin XPath final
$search_path.="[following-sibling::element[1][contains(data[\@type=\"type\"],\"".$tokens[$#tokens]."\")]"
.$search_path_suffix;
# print "$search_path\n";
# on renvoie à la procédure appelante le chein XPath et le tableau des éléments du motif
return ($search_path,@tokens);
}
# routine d'extraction du motif
sub extract_pattern{
# On récupère la ligne du motif recherché
my $ext_pat_ligne= shift @_;
# Appel de la fonction construit_XPath pour le motif lu à la ligne courrante du fichier de motif
my ($search_path,@tokens) = &construit_XPath($ext_pat_ligne);
# définition du nom du fichier de résultats pour le motif en utilisant la fonction join
my $match_file = "res_extract-".join('_', @tokens).".txt";
# Ouverture du fichiers de résultats encodé en UTF-8
open(MATCHFILE,">:encoding(UTF-8)", "$match_file") or die "can't open $match_file: $!\n";
# création de l'objet XML::XPath pour explorer le fichier de sortie tree-tagger XML
# Parcours des noeuds du ficher XML correspondant au motif, au moyen de la méthode findnodes
# qui prend pour argument le chemin XPath construit précédement
# avec la fonction "construit_XPath"
my @nodes=$root->findnodes($search_path);
foreach my $noeud ( @nodes) {
# Initialisation du chemin XPath relatif du noeud "data" contenant
# la forme correspondant au premier élément du motif
# Ce chemin est relatif au premier noeud "element" du bloc retourné
# et pointe sur le troisième noeud "data" fils du noeud "element"
# en l'identifiant par la valeur "string" de son attribut "type"
my $form_xpath="";
$form_xpath="./data[\@type=\"string\"]";
# Initialisation du compteur pour la boucle d'éxtraction des formes correspondants
# aux éléments suivants du motif
my $following=0;
# Recherche du noeud data contenant la forme correspondant au premier élément du motif
# au moyen de la fonction "find" qui prend pour arguments:
# 1. le chemin XPath relatif du noeud "data"
# 2. le noeud en cours de traitement dans cette boucle foreach
# la fonction "find" retourne par défaut une liste de noeuds, dans notre cas cette liste
# ne contient qu'un seul élément que nous récupérons avec la fonction "get_node"
# enfin nous en imprimons le contenu textuel au moyen de la méthode string_value
print MATCHFILE $xpc->findvalue($form_xpath,$noeud);
# Boucle d'éxtraction des formes correspondants aux éléments suivants du motif
# On descend dans chaque noeud element du bloc
while ( $following < $#tokens) {
# Incrémentation du compteur $following de cette boucle d'éxtraction des formes
$following++;
# Construction du chemin XPath relatif du noeud "data" contenant
# la forme correspondant à l'élément suivant du motif
# Notez bien l'utilisation du compteur $folowing tant dans la condition de la boucle ci-dessus
# que dans la construction du chemin relatif XPath
my $following_elmt="following-sibling::element[".$following."]";
$form_xpath=$following_elmt."/data[\@type=\"string\"]";
# Impression du contenu textuel du noeud data contenant la forme correspondant à l'élément suivant du motif
print MATCHFILE " ",$xpc->findvalue($form_xpath,$noeud);
# Incrémentation du compteur $following de cette boucle d'éxtraction des formes
# $following++;
}
print MATCHFILE "\n";
}
# Fermeture du fichiers de motifs
close(MATCHFILE);
}
Ao invés de utilizar um script em Perl, nós podemos também utilizar XPATH para extrair as sequências buscadas.
Para criar uma página HTML que exiba as sequências, nós podemos utilizar xsltproc como no seguinte comando:
xsltproc stylesheet.xsl xml_file.xml > sequence.html
Esta folha de estilo permite a extração de todos as sequências "substantivo-preposição", utilizando XPATH.
- <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
- <xsl:output method="html"/>
- <xsl:template match="/">
- <html>
- <body bgcolor="#81808E">
- <table align="center" bgcolor="white" border="1" bordercolor="#3300FF" width="50%">
- <tr bgcolor="black">
- <td valign="top" width="90%">
- <font color="white">
- <h1>Extraction de patron
- <font color="red">
- <b>NOM</b></font>
- <xsl:text/>
- <font color="blue">
- <b>PRP</b>
- </font>
- <xsl:text/>
- <font color="red">
- <b>NOM</b>
- </font>
- </h1>
- </font>
- </td>
- </tr>
- <tr>
- <td>
- <blockquote>
- <xsl:apply-templates select="PARCOURS/ETIQUETAGE/file"/>
- </blockquote>
- </td>
- </tr>
- </table>
- </body>
- </html>
- </xsl:template>
- <xsl:template match="file">
- <xsl:for-each select="element">
- <xsl:if test="(./data[contains(text(),'NOM')])">
- <xsl:variable name="p1" select="./data[3]/text()"/>
- <xsl:if test="following-sibling::element[1][./data[contains(text(),'PRP')]]">
- <xsl:variable name="p2" select="following-sibling::element[1]/data[3]/text()"/>
- <xsl:if test="following-sibling::element[2][./data[contains(text(),'NOM')]]">
- <xsl:variable name="p3" select="following-sibling::element[2]/data[3]/text()"/>
- <font color="red">
- <xsl:value-of select="$p1"/>
- </font>
- <xsl:text/>
- <font color="blue">
- <xsl:value-of select="$p2"/>
- </font>
- <xsl:text/>
- <font color="red">
- <xsl:value-of select="$p3"/>
- </font>
- <br/>
- <xsl:text/>
- </xsl:if>
- </xsl:if>
- </xsl:if>
- </xsl:for-each>
- </xsl:template>
- </xsl:stylesheet>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="html"/>
<xsl:template match="/">
<html>
<body bgcolor="#81808E">
<table align="center" bgcolor="white" border="1" bordercolor="#3300FF" width="50%">
<tr bgcolor="black">
<td valign="top" width="90%">
<font color="white">
<h1>Extraction de patron
<font color="red">
<b>NOM</b></font>
<xsl:text/>
<font color="blue">
<b>PRP</b>
</font>
<xsl:text/>
<font color="red">
<b>NOM</b>
</font>
</h1>
</font>
</td>
</tr>
<tr>
<td>
<blockquote>
<xsl:apply-templates select="PARCOURS/ETIQUETAGE/file"/>
</blockquote>
</td>
</tr>
</table>
</body>
</html>
</xsl:template>
<xsl:template match="file">
<xsl:for-each select="element">
<xsl:if test="(./data[contains(text(),'NOM')])">
<xsl:variable name="p1" select="./data[3]/text()"/>
<xsl:if test="following-sibling::element[1][./data[contains(text(),'PRP')]]">
<xsl:variable name="p2" select="following-sibling::element[1]/data[3]/text()"/>
<xsl:if test="following-sibling::element[2][./data[contains(text(),'NOM')]]">
<xsl:variable name="p3" select="following-sibling::element[2]/data[3]/text()"/>
<font color="red">
<xsl:value-of select="$p1"/>
</font>
<xsl:text/>
<font color="blue">
<xsl:value-of select="$p2"/>
</font>
<xsl:text/>
<font color="red">
<xsl:value-of select="$p3"/>
</font>
<br/>
<xsl:text/>
</xsl:if>
</xsl:if>
</xsl:if>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>Esta folah de estilos permite a extração de todas as sequências "substantivos-adjetivo", utilizando XPATH.
- <xsl:stylesheet version="2.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
- <xsl:output method="html"/>
- <xsl:template match="/">
- <html>
- <body bgcolor="#81808E">
- <table align="center" bgcolor="white" border="1" bordercolor="#3300FF" width="50%">
- <tr bgcolor="black">
- <td valign="top" width="90%">
- <font color="white">
- <h1>Extraction de patron
- <font color="red">
- <b>NOM</b></font>
- <font color="blue">
- <b>ADJ</b>
- </font>
- </h1>
- </font>
- </td>
- </tr>
- <tr>
- <td>
- <blockquote>
- <xsl:apply-templates select="./PARCOURS/ETIQUETAGE/file/element"/>
- </blockquote>
- </td>
- </tr>
- </table>
- </body>
- </html>
- </xsl:template>
- <xsl:template match="element">
- <xsl:choose>
- <xsl:when test="(./data[contains(text(),'NOM')]) and (following-sibling::element[1][./data[contains(text(),'ADJ')]])">
- <font color="red">
- <xsl:value-of select="./data[3]"/>
- </font>
- <xsl:text/>
- </xsl:when>
- <xsl:when test="(./data[contains(text(),'ADJ')]) and (preceding-sibling::element[1][./data[contains(text(),'NOM')]])">
- <font color="blue">
- <xsl:value-of select="./data[3]"/>
- </font>
- <br/>
- </xsl:when>
- </xsl:choose>
- </xsl:template>
- </xsl:stylesheet>
<xsl:stylesheet version="2.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="html"/>
<xsl:template match="/">
<html>
<body bgcolor="#81808E">
<table align="center" bgcolor="white" border="1" bordercolor="#3300FF" width="50%">
<tr bgcolor="black">
<td valign="top" width="90%">
<font color="white">
<h1>Extraction de patron
<font color="red">
<b>NOM</b></font>
<font color="blue">
<b>ADJ</b>
</font>
</h1>
</font>
</td>
</tr>
<tr>
<td>
<blockquote>
<xsl:apply-templates select="./PARCOURS/ETIQUETAGE/file/element"/>
</blockquote>
</td>
</tr>
</table>
</body>
</html>
</xsl:template>
<xsl:template match="element">
<xsl:choose>
<xsl:when test="(./data[contains(text(),'NOM')]) and (following-sibling::element[1][./data[contains(text(),'ADJ')]])">
<font color="red">
<xsl:value-of select="./data[3]"/>
</font>
<xsl:text/>
</xsl:when>
<xsl:when test="(./data[contains(text(),'ADJ')]) and (preceding-sibling::element[1][./data[contains(text(),'NOM')]])">
<font color="blue">
<xsl:value-of select="./data[3]"/>
</font>
<br/>
</xsl:when>
</xsl:choose>
</xsl:template>
</xsl:stylesheet>Scripts baseados a partir dos scripts dos professores para melhorar a extração dos padrões morfosintáticos dos resultados do TreeTagger e Cordial.
Em aula nós vimos três maneiras de extrair padrões as frases desejadas utilizando Perl. Esses três scripts funcionam de maneira similar incorporando os padrões desejadas nos scripts e buscando um único padrão.
Nós propomos aqui dois scripts muito similares que nós mesmos produzimos. Eles são diferentes daquele produzidos pelos professores pelo fato de nos permitir a busca por um número ilimitado de padrões independentemente do tamanho do padrão.
- use strict;
- use warnings;
- #--------------------------------------------------------------
- # This script allows the user to search for as many morphosyntactic patterns
- # (of any/varying length) as desired from the Cordial results of tool 2
- # usage: perl ourversion1.pl patron_test.txt
- #--------------------------------------------------------------
- open(FILE,"$ARGV[0]"); # the cordial tagged text
- open(FILE2,"$ARGV[1]"); # the list of patterns
- #--------------------------------------------------------------
- # the patterns searched for are in the file patron_test.txt
- #--------------------------------------------------------------
- my @lignes = <FILE>;
- my @patrons = <FILE2>;
- close(FILE);
- close(FILE2);
- while (@lignes) {
- my $ligne = shift(@lignes);
- chomp $ligne;
- for (my $i = 0; $i < scalar@patrons; $i++) {
- my $sequence = "";
- my $forme = "";
- my $longueur = 0;
- my @split_patrons = split(' ', @patrons[$i]);
- if ($ligne =~ /^([^\t]+)\t[^\t]+\t$split_patrons[0].*/) {
- $forme = $1;
- $sequence .= $forme;
- $longueur = 1;
- for (my $j = 1; $j < scalar@split_patrons; $j++) {
- if ($lignes[$j-1] =~ /^([^\t]+)\t[^\t]+\t$split_patrons[$j].*/) {
- $forme = $1;
- $sequence .= " " . $forme;
- $longueur++;
- }
- }
- }
- if ($longueur == scalar@split_patrons) {
- print "\n[" . $sequence . "]\n";
- }
- }
- }
- close FILE;
- close FILE2;
use strict;
use warnings;
#--------------------------------------------------------------
# This script allows the user to search for as many morphosyntactic patterns
# (of any/varying length) as desired from the Cordial results of tool 2
# usage: perl ourversion1.pl patron_test.txt
#--------------------------------------------------------------
open(FILE,"$ARGV[0]"); # the cordial tagged text
open(FILE2,"$ARGV[1]"); # the list of patterns
#--------------------------------------------------------------
# the patterns searched for are in the file patron_test.txt
#--------------------------------------------------------------
my @lignes = <FILE>;
my @patrons = <FILE2>;
close(FILE);
close(FILE2);
while (@lignes) {
my $ligne = shift(@lignes);
chomp $ligne;
for (my $i = 0; $i < scalar@patrons; $i++) {
my $sequence = "";
my $forme = "";
my $longueur = 0;
my @split_patrons = split(' ', @patrons[$i]);
if ($ligne =~ /^([^\t]+)\t[^\t]+\t$split_patrons[0].*/) {
$forme = $1;
$sequence .= $forme;
$longueur = 1;
for (my $j = 1; $j < scalar@split_patrons; $j++) {
if ($lignes[$j-1] =~ /^([^\t]+)\t[^\t]+\t$split_patrons[$j].*/) {
$forme = $1;
$sequence .= " " . $forme;
$longueur++;
}
}
}
if ($longueur == scalar@split_patrons) {
print "\n[" . $sequence . "]\n";
}
}
}
close FILE;
close FILE2;
Uma segunda opção:
- #! /usr/bin/perl
- use strict;
- open(PATRONS, "$ARGV[0]");
- open(CORDIAL, "$ARGV[1]");
- open(CORDIAL_BKP, "$ARGV[1]");
- # créer fichier de résultats
- open my $final_result, '>>', "results.txt";
- my $terme;
- my @tags;
- # lire lignes du fichier de patrons
- while(chomp($terme=<PATRONS>)){
- # séparer les patrons de la ligne lue
- @tags = split(" ", $terme);
- my @LISTE;
- # lire le fichier étiquetté
- while(@LISTE = split(/\t/, <CORDIAL>)){
- # comparer les patrons du texte avec la patrons recherché
- if($LISTE[2] =~ m/$tags[0]/){
- # repérer position où le premier patron a été trouvé
- my $position = tell(CORDIAL);
- # continuer lecture à partir de $position
- seek(CORDIAL_BKP, $position, 0);
- my $compteur = 0;
- my $result="";
- # lire la séquence de patrons
- foreach my $tag (@tags){
- if($LISTE[2]=~ m/$tag/){
- # stocker résultat
- $result .= $LISTE[0]." ";
- # lire ligne suivant
- @LISTE = split(/\t/, <CORDIAL_BKP>);
- $compteur++;
- # si vrai, l`analyse est finie
- if($compteur == @tags){
- # écrire résultat
- print $final_result $result."\n";
- }
- }
- }
- }
- }
- seek(CORDIAL, 0, 0);
- }
- close(CORDIAL);
- close(PATRONS);
#! /usr/bin/perl
use strict;
open(PATRONS, "$ARGV[0]");
open(CORDIAL, "$ARGV[1]");
open(CORDIAL_BKP, "$ARGV[1]");
# créer fichier de résultats
open my $final_result, '>>', "results.txt";
my $terme;
my @tags;
# lire lignes du fichier de patrons
while(chomp($terme=<PATRONS>)){
# séparer les patrons de la ligne lue
@tags = split(" ", $terme);
my @LISTE;
# lire le fichier étiquetté
while(@LISTE = split(/\t/, <CORDIAL>)){
# comparer les patrons du texte avec la patrons recherché
if($LISTE[2] =~ m/$tags[0]/){
# repérer position où le premier patron a été trouvé
my $position = tell(CORDIAL);
# continuer lecture à partir de $position
seek(CORDIAL_BKP, $position, 0);
my $compteur = 0;
my $result="";
# lire la séquence de patrons
foreach my $tag (@tags){
if($LISTE[2]=~ m/$tag/){
# stocker résultat
$result .= $LISTE[0]." ";
# lire ligne suivant
@LISTE = split(/\t/, <CORDIAL_BKP>);
$compteur++;
# si vrai, l`analyse est finie
if($compteur == @tags){
# écrire résultat
print $final_result $result."\n";
}
}
}
}
}
seek(CORDIAL, 0, 0);
}
close(CORDIAL);
close(PATRONS);Padrões utilizadas para a extração
Nós utilizamos diferentes padrões contendo ":" . Exemplo de alguns:
NPMS PCTFORTE NCMS PREP ADJIND NCMIN
VINF DETDMS NCMS PCTFORTE DETDPIG NCFP DETDMS ADJNUM NCMIN
NPI PCTFORTE DETDMS NCMS ADV VINDP3S ADV COO VINDP3S
A lista completa pode ser vista aqui.
Padrão usado: N[A-Z]+ ADJ[A-Z]+
Padrão usado: N[A-Z]+ PREP DET[A-Z]+ N[A-Z]+
Padrão usado: .*?que.*
Frases Extraídas
Diferentes padrões contendo ":" foram utilizados. Alguns exemplos:
NPMS PCTFORTE NCMS PREP ADJIND NCMIN
VINF DETDMS NCMS PCTFORTE DETDPIG NCFP DETDMS ADJNUM NCMIN
NPI PCTFORTE DETDMS NCMS ADV VINDP3S ADV COO VINDP3S
A lista completa pode ser vista aqui.
Lista de resultados com ":" .
Padrão utilizado: N[A-Z]+ ADJ[A-Z]+
Lista de resultados SUBSTANTIVO-ADJETIVO.
Padrão utilizado: N[A-Z]+ PREP DET[A-Z]+ N[A-Z]+
Lista de resultados SUBSTANTIVO-PREPOSIÇÃO-ARITGO-SUBSTANTIVO.
Padrão usado: .*?que.*
Lista de resultados VERBO-CONJUNÇÃO.
Como criar gráficos
O projeto Caixa de Ferramentas chega ao fim e, para fechar essa série de tratamentos, nós vamos construir alguns gráficos.
A Ferramenta 4 utiliza um programa externo desenvolvido para Windows que permite criar gráficos, utilizando os resultado da Ferramenta 3. Esse gráficos nos auxiliam a ter uma representação visual dos padrões encontrados nos texto.
A construção desses gráfigo tem o objetivo de ilustrar o comportamento de um token e, ou, de um tipo morfosintático específico para os quais nós fizemos suposição linguísticas.
Este tipo de representação visual nos permit ter uma noção mais clara sobre como os padrões se articulam entre eles. Nós podemos, por exemplo, utilizar a representação gráfica para destacar as relações mantidas por uma dada forma em níveis sintagmáticos e pragmáticos.
Tomamos como exemplo os gráficos abaixo confeccionados a partir de dados extraídos do tema política. Nós escolhemos enunciados onde o nome do presidente François Hollande aparece. Para facilitar a visualização e a compreenção do gráfico, nos utilizamos um número reduzido de frases.
As setas em vermelho indicam exemplos de enunciados negativos, enquanto que as setas verdes indicam enunciados positvos. A seta roxa indica uma possível transição no eixo pragmático.
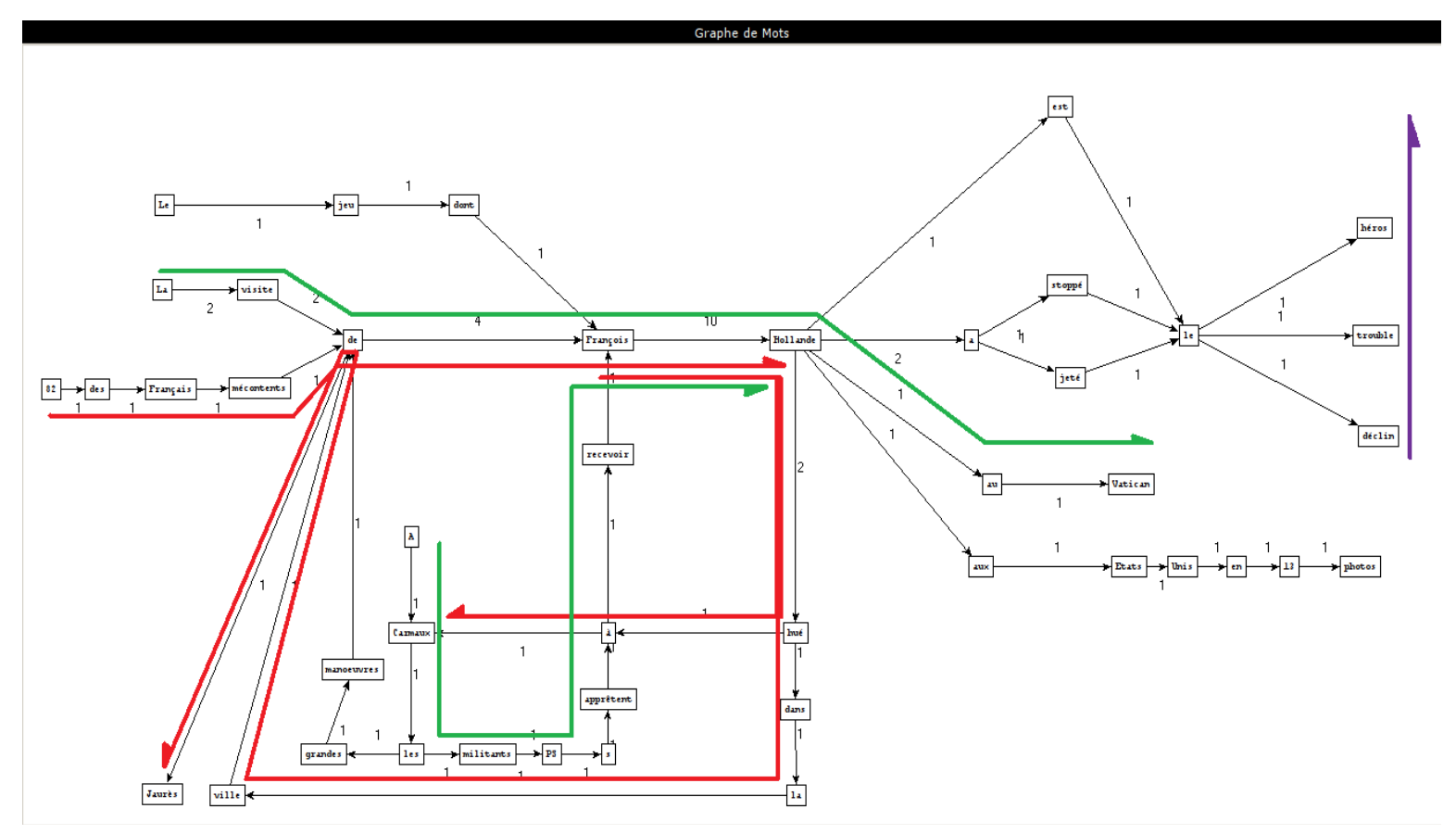
Uma breve análise do gráfico é suficiente para nos indicar construções sintaximente interessantes.
Por exemplo, nós podemos observar que as mudanças no eixo paradigmático podem criar enunciados estranhos, mas não agramaticais.
Nós podemos nos divertir, criando novos enunciados seguindo o percurso proposto pelas setas. Basta mudar as direções quando encontramos um bifurcação.
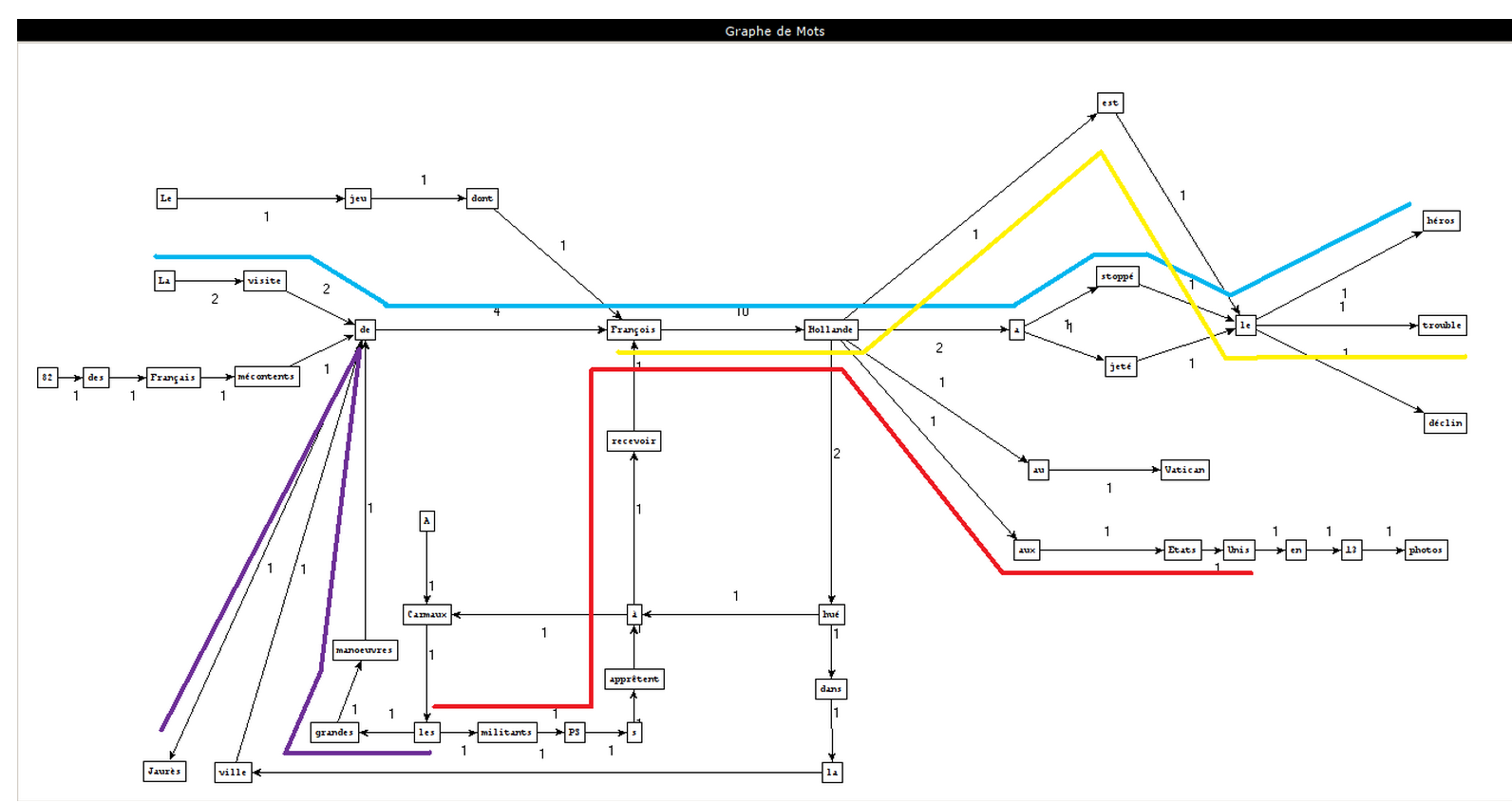
Obs.: Os enunciados acima foram produzido a título meramente ilustrativo e não exprimem nenhum posição política.
Esta experiência não tem o mesmo efeito no eixo sintagmático. A inversão das formas vizinhas nesse eixo ou cria enunciados agramaticais ou enunciados semanticamente diferente.
Isso se explica pelo fato de que construções paralelas no eixo paradigmático frequentemente pertence a uma mesma classe gramatical.
Na representação gráfica, esse tipo de estrutura se encontra alinhada com setas que partem na mesma direção. Como nós podemos ver nos exemplos abaixo.
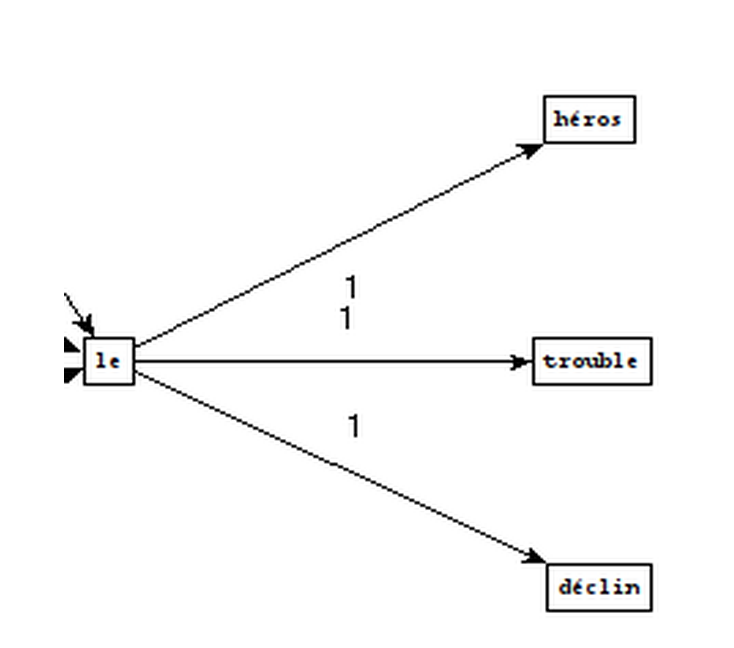

É preciso notar que um mesmo alinhamento paradigmático pode também conter elementos de tipos distintos e, neste caso, nenhuma mudança é possível.
Por exemplo:
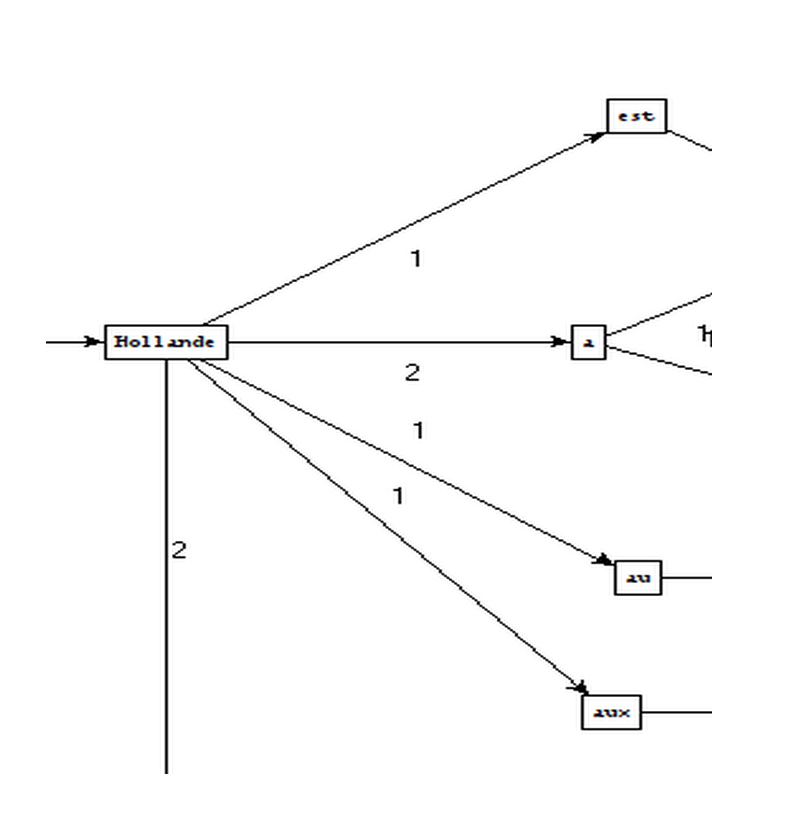
*Como nem todos os integrantes usam Windows, nós utilizamos o programa comWine.
SUBSTANTIVO ADJETIVO
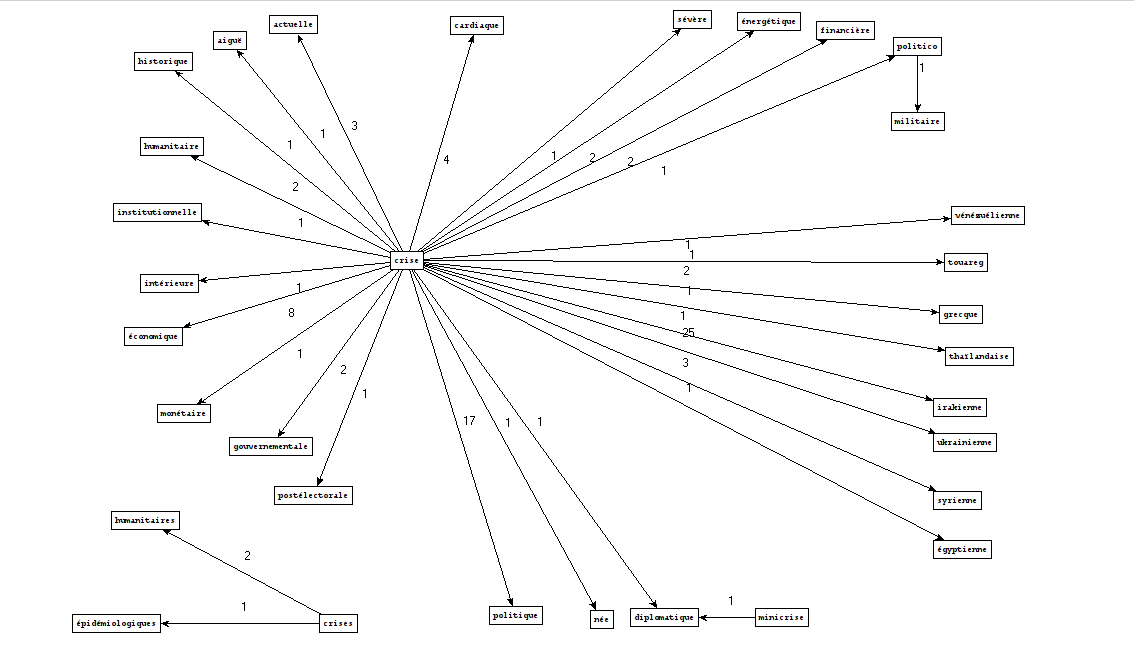
Nós decidimos executar a CdF3 para os textos do tema INTERNACIONAL com o padrão SUBSTANTIVO-ADJETIVO para recuperar todas as sequências morfosintáticas contendo um substantivo seguido de um adjetivo.
Em seguida dans CdF4, nós escolhemos como motivo o substantivo "crise" seguido de todos os adjetivos para criar o gráfico. Nós partimos da hipótese que, no contexo econômico atual no qual nós encontramos no mundo inteiro, nós encontraríamos muitas ocorrências do tipo "crise econônima". Como nós podemos constatar no gráfico, nós temos 8 ocorrências deste sintagma no tema INTERNACIONAL. O que permanece muito baixo em relação ao resultado de "crise ukranienne". Isso indica a importância dos eventos ocorridos em 2014 na Ucrânia.
No entanto, mesmo sem observar o contexto no qualo mundo estava politica e economicamente, nós nos damos conta que frequentemente nós encontramos "crise" + nacionalidade do que "crise économique", como nós esperávamos. Finalmente, a crise é mais frequentemente designada ao local onde ela ocorre e o contexto textual determina de qual tipo de crise se trata. Porém, de acordo com os resultados encontrados, praticamente todos os sintagmas encontrados fazem referência a uma crise política ou econômica.
Entretanto, a supresa foi encontrar 4 ocorrências de "crise cardiaque" no nosso gráfico. Nós esperávamos encontrar algo ligado ao contexto médico nos resultados. Sem verificar o corpus e se baseando somente nos dados fornecidos pelo gráficos, nós podemos supor que algum personagem político importante de nível internacional tenha tido um ataque cardíaco.
Nós temos igualmente três ocorrências do motivo no plural ("crises"), mas que à priori, não fazem parte do contexto econômico. O contexto médico ("epidemiológico") e talvez social ("humanitário") parecem ser os contexto que aparecem através do sintagmas. Porém, como as ocorrência no plural não são significativas para um ano inteiro, nós pensamos que isto não necessita uma análise mais profunda.
SUBSTANTIVO-PREPOSIÇÃO-ARTIGO-SUBSTANTIVO
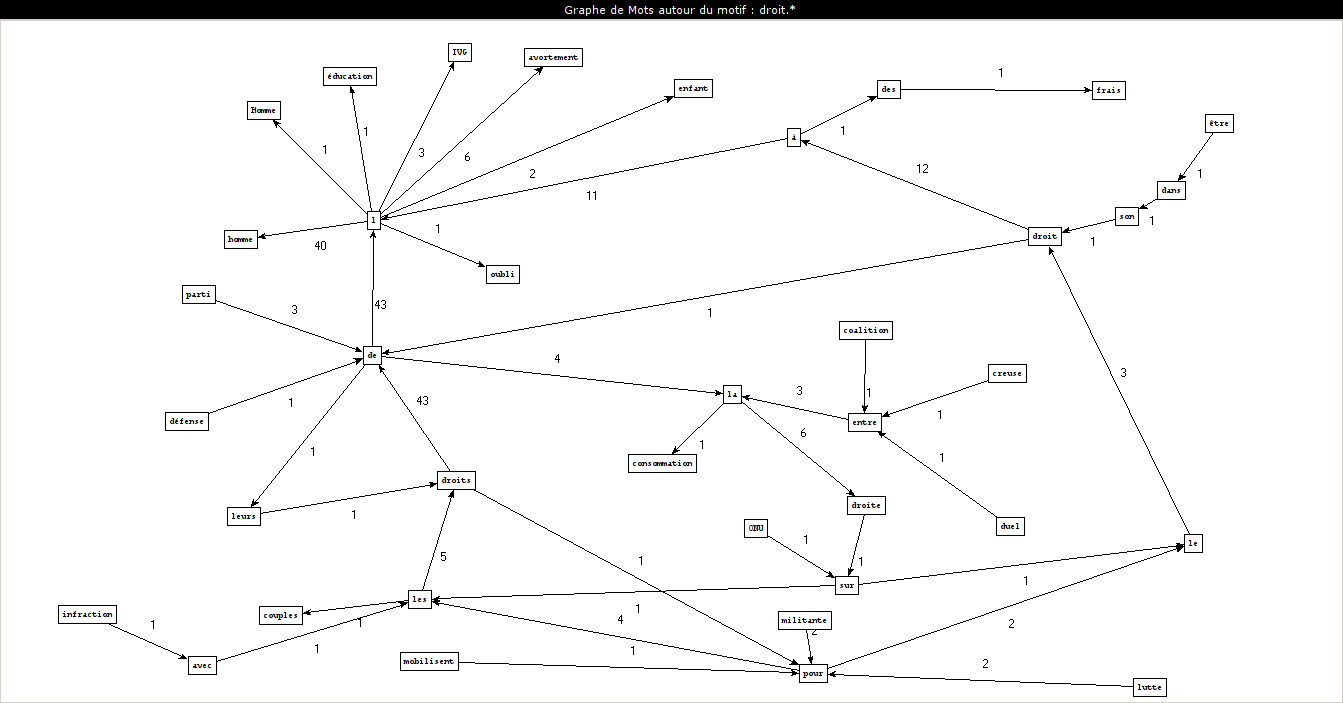
Com o motivo direito.*, nós queríamos chegar ao contexto político/legislativo do corpus para o tema INTERNACIONAL. Nós constatamos com isso que o sintagma que o sintagma "droit de l'homme" aparece 41 vezes (se não não fizermos a distinção entre Homme e homme). A maioria dos sintagmas encontrados em torno desse motivo possuem a palavras "droit(s)" em primeiro como "droit à" ou "droit de" seguido de outros tipos. Entretanto, encontramoss algumas ocorrências que ela se encontra no fim do sintagma como "être dans son drois".
Nós percebemos que no primeiro caso, os sintagmas fazem referência a algo legislativo, indicando leis que já foram votadas ou estão em discussão. Enquanto que no segundo caso, as referências são feitas a um contexto político com situação onde há uma luta ou mobilizção para se alcançar aos direitos.
PONTUAÇÃO FORTE ":"
Nós percebemos o site do Le Monde um padrão que indicaria fortes candidatos a serem palavras-chave. Trata-se de frases contendo a pontução forte ":".


Como nós podemos observar, esse tipo de construção é muito frequente no Le Monde. Na verdade, esta estrutura de frase [sintagma nominal] ':' [sintagma nominal][sintagama]* é uma marca característica do registro jornalístico para criar títulos.
Veja alguns exemplos da mesma estrutura encontra outros periódicos franceses extraídos no mesmo dia.



Nós podemos observar que algumas reportagens reutilizam quase o mesmo título, com a mesma estrutura.
Libération
"Egypt: l'ex-président islamiste Mohamed Morsi condamné à mort"
La Tribune
"Egypt: l'ex-président islamiste Mohamed Morsi condamné à mort"
Le Figaro
"Egypt: l'ex-président Mohamed Morsi condamné à mort"
Métro News
"Egypt: Mohamed Morsi condamné à mort"
Não trata de uma falta de criativade jornalística, mas sim de uma técnica refinada para suscitar no leito o desejo de ler o texto em questão. de saber mais sobre os fatos aludidos pelo título. Na verdade, o título nos fornece os tópicos principais do assunto tratado, deixando uma lacuna de informação que só pode ser preenchida quando nós lemos a reportagem. Por exemplo, a partir dos títulos dos exemplos acima, nós podemos saver o local onde se passam os fatos e que a pessoas que lhes é submetida.
No Egito, Mohamed Morsi foi condenado a pena de morte. Mediante a essa informação o leitor pode se perguntar: "Por que razão?" "Quando será a condenação" Ou ainda: "Quem é Mohamed Morsi?"
Ce type de phrase fournit l'essenciel sans dire les "pourquoi", "quand", "qui", "où", etc. Pour nous cet essenciel est très important, puisqu'il peut être utiliser, par exemple, par des système de réfférencement (SEO). Este tipo de frase fornece o essencial sem dizer os "porquês", "quando", "quem", "onde", etc. Para nós esse tipo de informação essencial é muito importante, pois ele pode ser utilizado, por exemplo, por sistemas de otimização de motores de busca (SEO)
No Cordial o símbolo ":" é marcado com uma pontução forte, assim como ";", "!", "?" e ".". Nesse sentido, nós percebemos que uma busca simples por N[A-Z]+ PCTFORTE N[A-Z]+ V[A-Z]+ PREP N[A-Z]+
Poderia fornecido vários enunciados como:
Para contornar este problema e tentar descobrir se existem estruturas recorrentes para este tipo de frase, nós criamos um script em Python para nos ajudar com essa tarefa. O objetivo do programa é ler um conjunto de arquivo etiquetados, buscando seja "tags" ou "tokens" específicos fornecidos pelo utilizador. Como resultado, o programa produz um arquivo contendo padrões de frases que contenham o token ou o patrão escolhido.
Dans notre cas, nous avons cherché des énoncés qui contiennent le token ':' pour tous les fichiers de toutes les rubrique étiquettés par Cordial, à l'execption du fichier CINEMA.cnr. Car, nous ce fichier serait utilisé pour essayer la pertinence des patrons fournis par notre script. Si le fichier CINEMA.cnr avait aussi été lu par Trouver_Patrons.py, le résultat de notre recherche serait dénaturé car, les patrons dans le fichier de sortie inclueraient ceux de CINEMA.cnr. Donc, l'exclusion de fichier étiquété qui nous intéresse du groupe de fichiers à être analysés avec Trouver_Patrons.py est une manière de créer une sorte de training corpus. No nosso caso, nós buscamos frases que contivessem o token ":" em todos os arquivos dos temas etiquetados pelo Cordial, com exceção do arquivo CINEMA.cnr. Pois, esse arquivo seria utilizado para testar a pertinência dos padrões fornecidos pelos script. Caso o arquivo CINEMA.cnr tivesse também sido lido pelo script Trouver_Patrons.py, o resultado da nossa pesquisa seria desvirtuado, pois os padrões do resultado já incluiriam todos os padrẽos presentes em CINEMA.cnr. Portanto, a exclusão do arquivo etiquetado que nos interessa do grupo de arquivos a serem analizados por Trouver_Patrons.py é uma maneira de criar algo como o um corpus de treinamento (training corpus).
Seguem abaixo os resultado (encontrados com Trouver_Patrons.py):
Tema Cinema: total de número de frases - 1927 frases
| Verdeiro Positivo | 91 |
| Falso Positivo | 19 |
| Verdadeiro Negativo | 1836 |
| Falso Negativo | 5 |
| Abrangência | 0,947 | 94% |
| Precisão | 0,827 | 82% |
| Medida-F | 0,87 | 87% |
Tema Política : total do número de frase - 6781 frases
| Verdadeiro Positivo | 245 |
| Falso Positivo | 10 |
| Verdadeiro Negativo | 11721 |
| Falso Negativo | 1004 |
| Abrangência | 0,96 | 96% |
| Precisão | 0,19 | 19% |
A partir desse resultados, nós acreditamos que, apesar da variedade de formas, é possível identificar certos tipos frase. Tendo em vista que nas frases possedendo esse tipo de estrutura contêm palavras-chave sua identificação pode ser de grande utilidade.
Segue abaixo os gráficos criados após a utilização do script para o tema CINEMA. Afim de facilitar a leitura a compreenção do gráfico, o número de frases foi reduzido:
Obs.: o símbolo ":" é representado pelo token 'pct'
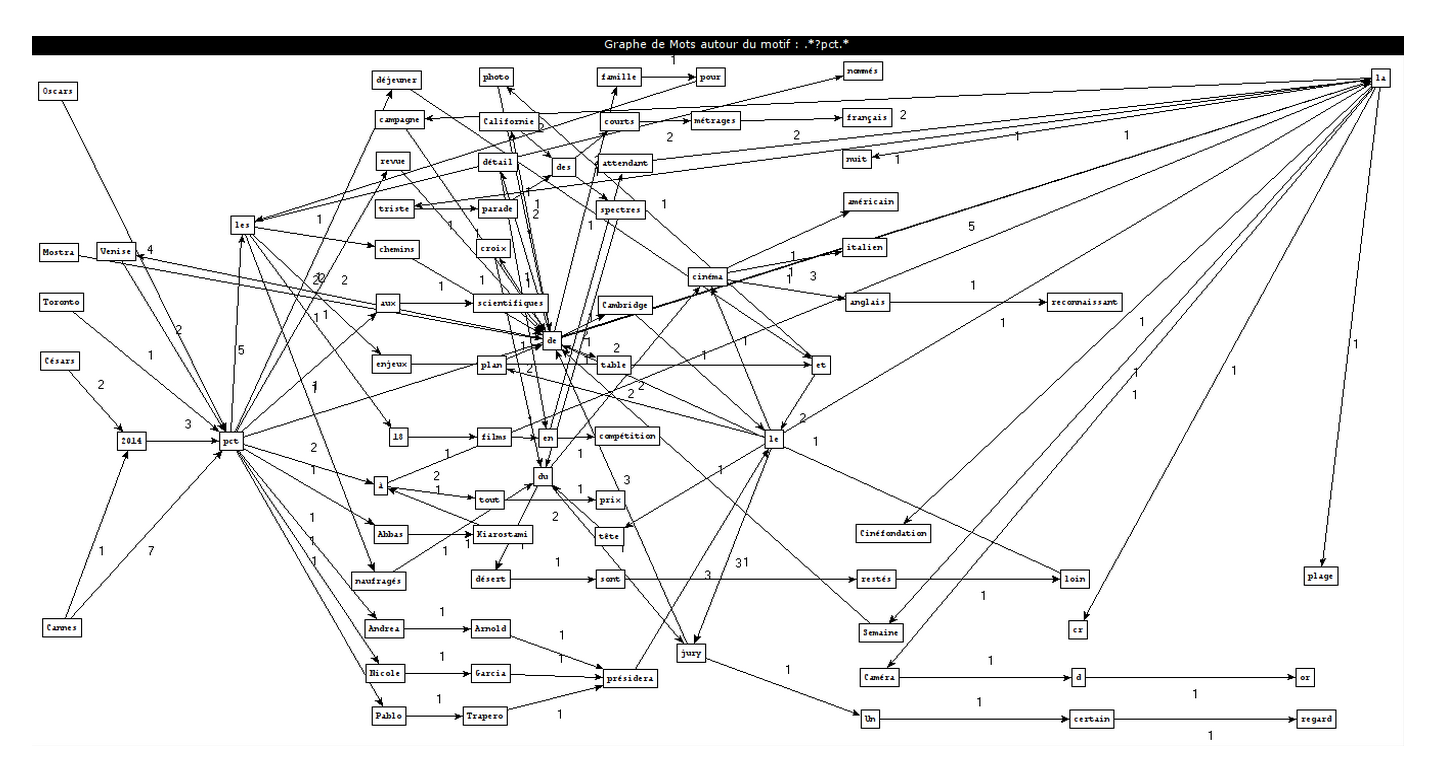
Exemplo de algumas enunciados extraídos com o o script de CdF3, utilizando padrões produzido pelo script Trouver_Patrons.py:
As palavras-chave:

A palavras ditas semanticamente vazias possuem muitas ocorrências. No gráficos isso representa muitos nós, assim como para o padrão procurado.
Segue o mesmo gráfico filtrado por uma stop-list:

Neste gráfico nós podemos observar que as palavras "cinéma" e "jury" possuem muitas conexões. Esse resultado é revelador sobre o assunto tratado pelo tema em questão - o cinema.
Para concluir, é preciso dizer que várias outras análises podem ser realizadas com os mesmo tipos de dados e de ferramentos de representação. As teorias apresentadas neste trabalho, levam em conta somente o corpus utilizado para o projet. Uma averigação mais completad exige um a mesma aplicação em corpus de mais envergadura.
CONJUNÇÃO
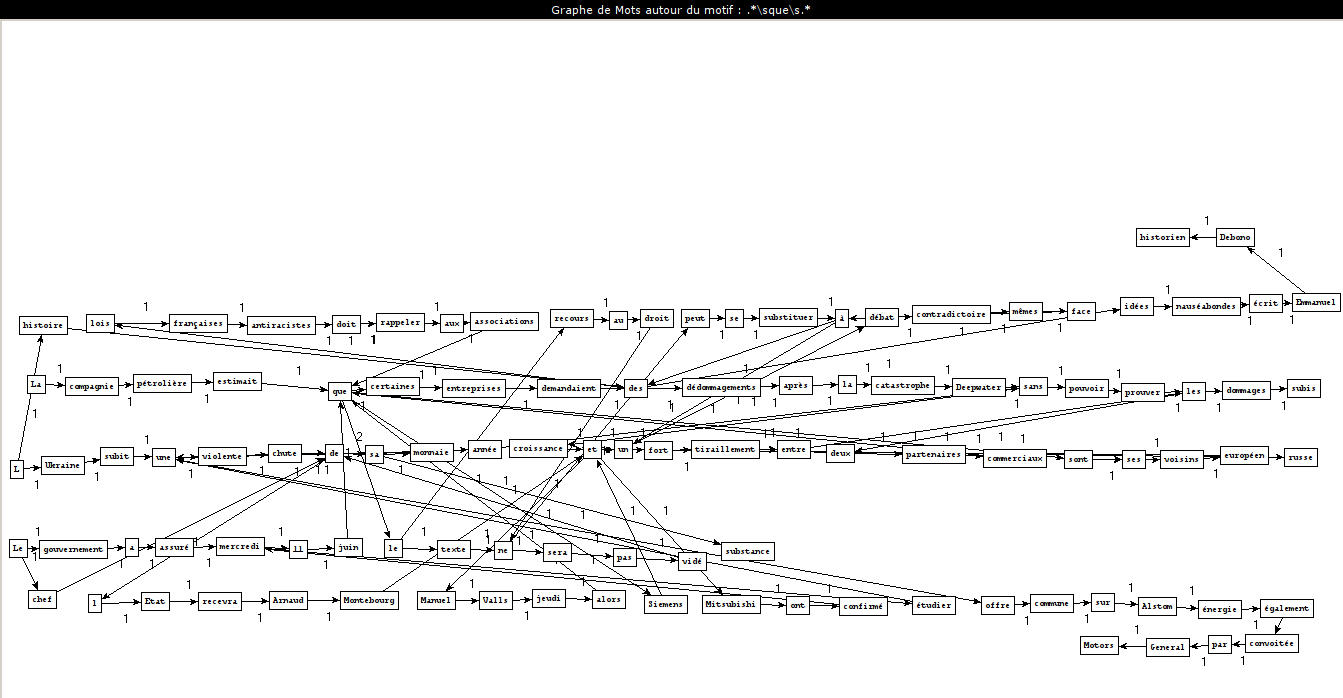
Nós tentamos criar um gráfico com conjunções, porém o problema é que os resultados obtidos são muito densos, pois todos as frases contendo conjunção se mostram muito engedreram sintagamas muito longos. Como nós podemos observar, nós não distinguimos claramente o resultado obtido através do gráfico. Com auxílio do nosso arquivo de resultado que contém todas as frases tendo o padrão procurados, nós recuperamos somente as frases que contêm "que". Nós temos finalmente as 5 frases a seguir:
Nós possuímos somente resultados que provêm das descrição, devido ao fato do motivo fornecido para busca e criação do gráfico. O títulos sendo frases, na maior parte do tempo, curtas, isso explica o porquê nós obtemos somente frases extraídas das descrição e o comprimento surpreendente. Porém, com frases não longas, não nos supreende o fato de não termos obtido várias vezes os mesmos segmentos. Isso significaria que nós teríamos duas vezes a mesma frase no gráfico, ou seja um repetição.
O que nós podemos concluir?
Para concluir, nós podemos dizer que há uma grande variedade de sintagmes para serem analizados nos texto do Le Monde. Nós escolhemos quatros que nós acreditamos nos daria uma grande possibilidade de resultado nos gráficos realizados.
Este tipo de análise nos dá uma grande visão sobre o assunto tratado pelo corpus, sem termos necessariamente que ler o texto. Uma vez que nós saibamos que tipo de fenômeno observar, torna-se muito mais fácil analizar e encontrar eventos similares. Isso pode ser generalizados para outros tipos de publicação. Se nós tivemos, por exemplo, observamos os textos produzidos pelo Le Figaro ou L'Humanité, emborar eles sejam jornais tão diferentes, nós seríamos capazes de analizá-los da mesma maneira.



