Automatiser un procédé d'extraction et regarder à travers un large corpus divers patrons lexicaux.
Ecrire plusieurs scripts Perl qui peuvent être généralisés et modifiés pour travailler dans divers contextes mais dans des buts similaires.
Montrer les résultats sous forme de graphes avec nos interprétations.
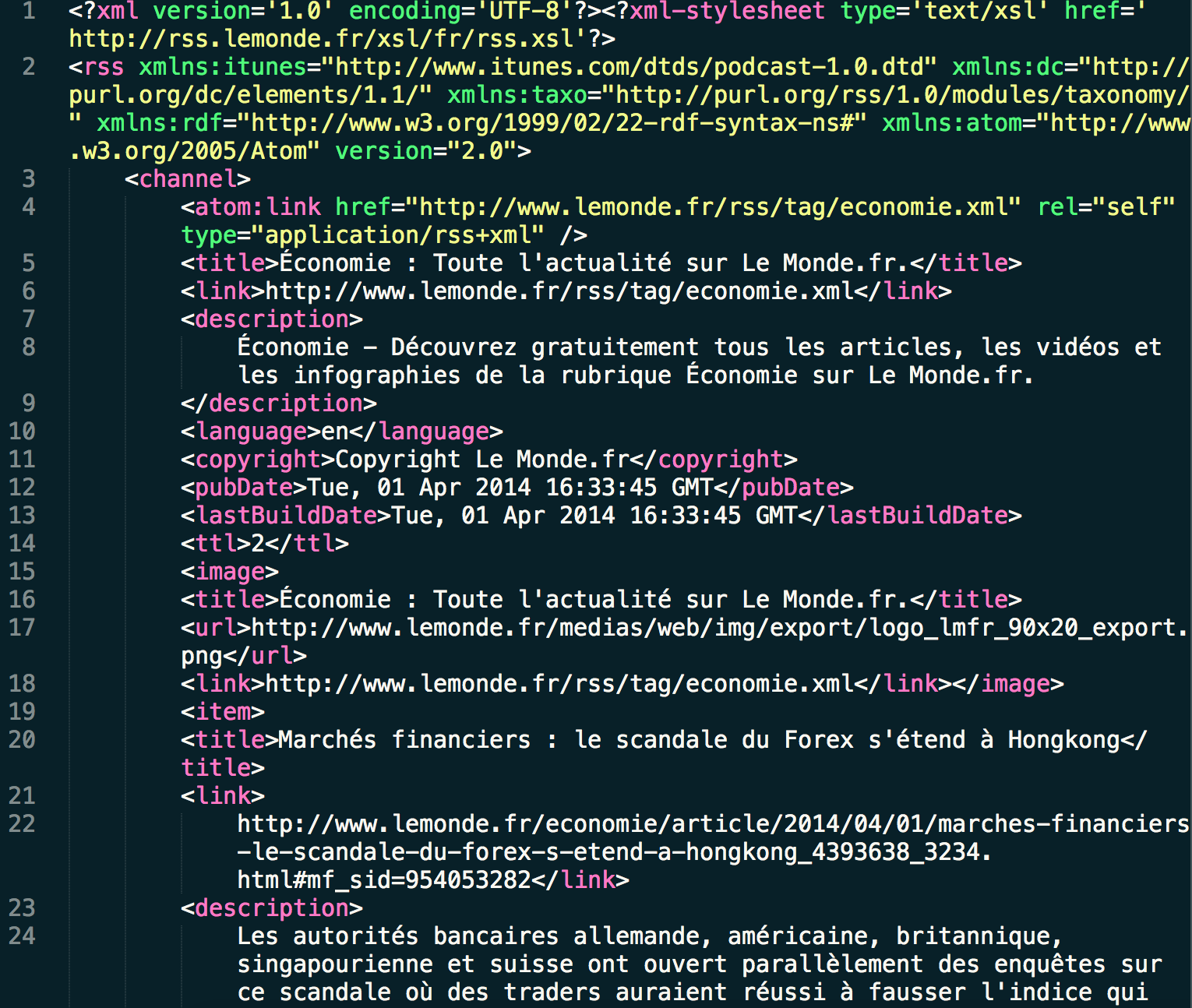
Nos données sont les fils RSS 2014 du journal Le Monde. Les fichiers sont au format XML et rangés dans des dossiers classés par mois.
Notre première Outil lit la structure des fichiers et extrait tout ce qui se trouve entre les balises <title> et <description>. Ces données sont ensuite nettoyées pour remplacer les caractères échappés, supprimer les images et toute autre donnée non traitable.
Cet outil prend la sortie de l'Outil 1 et utilise ensuite deux POS taggers différents : TreeTagger et Cordial.
L'Outil 3 est composée de deux scripts différents, un pour la sortie TreeTagger et l'autre pour Cordial. On cherche des patrons morphosyntaxiques spécifiques à travers ces deux sorties (ex : nom-préposition-nom).
Notre dernière Outil utilise les patrons trouvés pour créer une représentation visuelle de ces syntagmes dans le texte.
Que fait l'Outil 1 ?
Perl
Perl avec XPATH
Pure Perl
Perl Modules
Un exemple

Que fait l'Outil 2 ?
La methode du professeur
Outil 2 & Outil 3 & Outil 4
Pure Perl
Perl modules
Un exemple
Que fait l'Outil 3 ?
Perl
XPATH
Modification des scripts
Patrons utilisés
Phrases extraites
Comment créer ces graphes ?
NOM-ADJ
NOM-PREP-DET-NOM
PCTFORTE ":"
CONJONNCTION
Que pouvons-nous conclure ?
Nous sommes des étudiants en première année de Master en Traitement Automatique des Langues à l'Institut National des Langues et Civilisations Orientales (INALCO) à Paris, en France. Vous pouvez trouver toutes les informations sur notre cursus ici.
Que fait l'outil 1 ?

L'Outil 1 est un programme qui lit la structure d'un fichier du fil RSS du journal Le Monde. Les fichiers sont rangés dans un dossier nommé 2014 (l'année sur laquelle nous faisons nos recherches). Dans ce dossier se trouve d'autres dossiers, un pour chaque mois et dans chacun se trouve les fichiers XML et TXT contenant les articles et les balises, le tout organisé en rubriques (Politique, Culture, etc.). Pour notre projet, nous utiliserons uniquement les fichiers XML.
Voici un exemple d'un de nos fichiers XML :
L'Outil 1 extait tout ce qui se trouve entre les balises <title> et <description> de chaque fichier XML. Puisqu'on peut avoir des doublons avec les fils RSS, on s'assure que le code traite bien chaque fichier une seule fois sans répétition. Les données sont ensuite nettoyées pour remplacer les caractères d'échappement, supprimer les images et autres données non traitables.
Un exemple des balises <title> et <description> pour voir quel type de nettoyage effectuer :

On produit deux sorties : une au format TXT et l'autre au format XML.Le format TXT contient des descriptions avant chaque titre et chaque description (ex : Title: L'Unedic a versé 756 millions d'euros d'allocations chômage à tort en 2013 § Description:L'Unedic, qui gère les allocations chômage, estime que « le poids des indus rapportés aux dépenses d'indemnisation est resté stable, à 2,52 % ». §) et le format XML garde les balises <title> et <description>.
Sorties de l'Outil 1

Nous devons faire face à certains problèmes en écrivant notre code, le premier étant l'encodage. Les fichiers ne sont pas tous forcément encodés de la même manière, nous pouvons avoir de l'iso-8859-x ou de l'utf-8 par exemple, et nous voulons que toutes nos sorties soient en utf-8. Un autre problème est la formation des fichiers, car certains d'entre eux contiennent des balises sur des lignes différentes et d'autres sur la même. Nous ne voulons pas écrire deux scripts différents pour chacun des cas alors nous devions trouver un moyen de traiter les deux dans un même script.
Il est très important de faire cette étape correctement puisqu'on utilise ensuite ces données créées dans les Outils 1, 2, 3 et 4. Oublier des entités HTML dans les données peut avoir de graves conséquences sur les mots qu'on voudra tagguer plus tard.
Perl
Vous remarquerez que nous avons classé nos programmes de deux manières différentes : "Pure Perl" et "Perl Modules". Dans les deux cas, nous utilisons du Perl (v5.xx.x) mais dans les programmes que nous avons appelés "Pure Perl", nous avons mené une approche directe. Cela veut dire que toutes les étapes suivies dans le traitement des données sont visibles dans le programme et nous n'utilisons aucun programme externe en Perl (modules) qui pourrait introduire des variables non déclarées déstabiliser le code. Nous avons, dans ce cas, préféré utiliser des expressions régulières pour trouver les informations que nous voulions extraire.
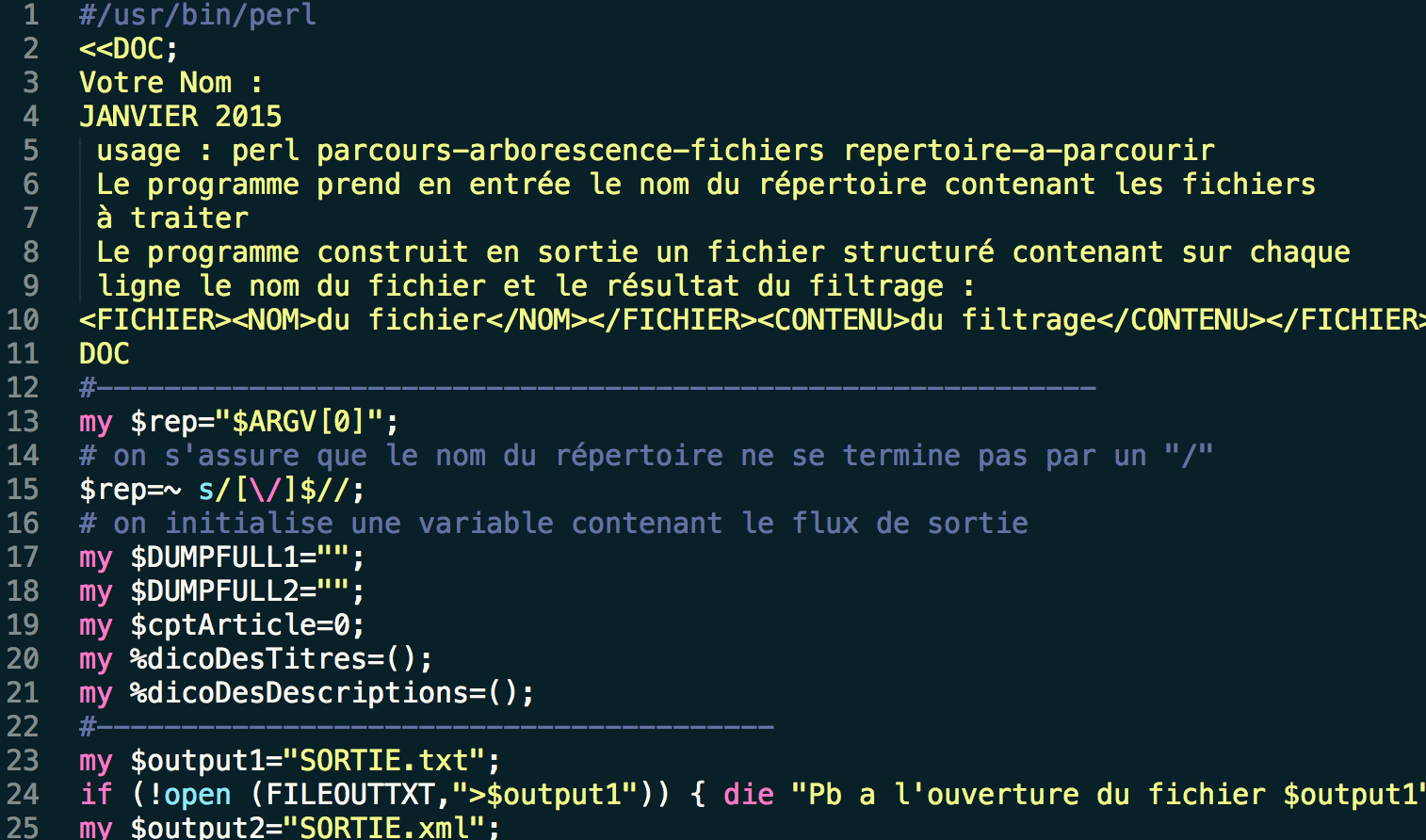
Ce script utilise l'approche "Pure Perl". Pour lancer ce script, il faut écrire en ligne de commandes "perl nom_du_programme.pl dossier_de_fichiers". Ce programme crée deux sorties (TXT et XML, lignes 23-26) et lit le chemin de fichier pour trouver les bons fichiers à l'aide d'une procédure récursive (ligne 28, fonction aux lignes 40-95).  Cette procédure appelle la procédure pour nettoyer le texte (lignes 65 et 78)
Cette procédure appelle la procédure pour nettoyer le texte (lignes 65 et 78)  et aussi vérifier que nous n'avons pas nettoyé le même texte plusieurs fois en utilisant un hash pour ne garder qu'une seule copie de chaque text. On ajoute également des balises XML dans le fichier de sortie. A la fin du programme, on imprime les résultats dans deux fichiers bien formés (lignes 33 et 36).
et aussi vérifier que nous n'avons pas nettoyé le même texte plusieurs fois en utilisant un hash pour ne garder qu'une seule copie de chaque text. On ajoute également des balises XML dans le fichier de sortie. A la fin du programme, on imprime les résultats dans deux fichiers bien formés (lignes 33 et 36).
- #/usr/bin/perl
- <<DOC;
- Votre Nom :
- JANVIER 2015
- usage : perl parcours-arborescence-fichiers repertoire-a-parcourir
- Le programme prend en entrée le nom du répertoire contenant les fichiers
- à traiter
- Le programme construit en sortie un fichier structuré contenant sur chaque
- ligne le nom du fichier et le résultat du filtrage :
- <FICHIER><NOM>du fichier</NOM></FICHIER><CONTENU>du filtrage</CONTENU></FICHIER>
- DOC
- #-----------------------------------------------------------
- my $rep="$ARGV[0]";
- # on s'assure que le nom du répertoire ne se termine pas par un "/"
- $rep=~ s/[\/]$//;
- # on initialise une variable contenant le flux de sortie
- my $DUMPFULL1="";
- my $DUMPFULL2="";
- my $cptArticle=0;
- my %dicoDesTitres=();
- my %dicoDesDescriptions=();
- #----------------------------------------
- my $output1="SORTIE.txt";
- if (!open (FILEOUTTXT,">$output1")) { die "Pb a l'ouverture du fichier $output1"};
- my $output2="SORTIE.xml";
- if (!open (FILEOUTXML,">$output2")) { die "Pb a l'ouverture du fichier $output2"};
- #----------------------------------------
- &parcoursarborescencefichiers($rep); #recurse!
- #----------------------------------------
- print FILEOUTXML "<?xml version=\"1.0\" encoding=\"iso-8859-1\" ?>\n";
- print FILEOUTXML "<PARCOURS>\n";
- print FILEOUTXML "<NOM>SF</NOM>\n";
- print FILEOUTXML "<FILTRAGE>".$DUMPFULL1."</FILTRAGE>\n";
- print FILEOUTXML "</PARCOURS>\n";
- close(FILEOUTXML);
- print FILEOUTTXT $DUMPFULL2;
- close(FILEOUTTXT);
- exit;
- #----------------------------------------------
- sub parcoursarborescencefichiers {
- my $path = shift(@_);
- opendir(DIR, $path) or die "can't open $path: $!\n";
- my @files = readdir(DIR);
- closedir(DIR);
- foreach my $file (@files) {
- next if $file =~ /^\.\.?$/;
- $file = $path."/".$file;
- if (-d $file) {
- &parcoursarborescencefichiers($file); #recurse!
- }
- if (-f $file) {
- if ($file=~/\.xml$/) {
- print $i++,"\n";
- open(FILEIN,$file);
- while (my $ligne=<FILEIN>) {
- if ($ligne=~/<\/item>/) {
- $DUMPFULL1.="</article>\n";
- }
- if ($ligne=~/<item>/) {
- $cptArticle++;
- $DUMPFULL1.="<article numero=\"$cptArticle\">\n";
- }
- if ($ligne=~/<description>(.+?)<\/description>/) {
- my $text=$1;
- $text=&nettoieText($text);
- if (!(exists($dicoDesDescriptions{$text}))) {
- $DUMPFULL1.="<description>$text</description>\n";
- $DUMPFULL2.=$text."\n";
- $dicoDesDescriptions{$text}++;
- }
- else {
- $dicoDesDescriptions{$text}++;
- $DUMPFULL1.="<description>-</description>\n";
- }
- }
- if ($ligne=~/<title>(.+?)<\/title>/) {
- my $text=$1;
- $text=&nettoieText($text);
- if (!(exists($dicoDesTitres{$text}))) {
- $DUMPFULL1.="<abstract>$text</abstract>\n";
- $DUMPFULL2.=$text."\n";
- $dicoDesTitres{$text}++;
- }
- else {
- $dicoDesTitres{$text}++;
- $DUMPFULL1.="<abstract>-</abstract>\n";
- }
- }
- }
- close(FILEIN);
- }
- }
- }
- }
- #----------------------------------------------
- sub nettoieText {
- my $texte=shift;
- $texte =~ s/</</g;
- $texte =~ s/>/>/g;
- $texte =~ s/<a href[^>]+>//g;
- $texte =~ s/<img[^>]+>//g;
- $texte =~ s/<\/a>//g;
- $texte =~ s/&#39;/'/g;
- $texte =~ s/&#34;/"/g;
- $texte =~ s/<[^>]+>//g;
- $texte =~ s/é/é/g;
- $texte =~ s/ê/ê/g;
- return $texte;
- }
#/usr/bin/perl
<<DOC;
Votre Nom :
JANVIER 2015
usage : perl parcours-arborescence-fichiers repertoire-a-parcourir
Le programme prend en entrée le nom du répertoire contenant les fichiers
à traiter
Le programme construit en sortie un fichier structuré contenant sur chaque
ligne le nom du fichier et le résultat du filtrage :
<FICHIER><NOM>du fichier</NOM></FICHIER><CONTENU>du filtrage</CONTENU></FICHIER>
DOC
#-----------------------------------------------------------
my $rep="$ARGV[0]";
# on s'assure que le nom du répertoire ne se termine pas par un "/"
$rep=~ s/[\/]$//;
# on initialise une variable contenant le flux de sortie
my $DUMPFULL1="";
my $DUMPFULL2="";
my $cptArticle=0;
my %dicoDesTitres=();
my %dicoDesDescriptions=();
#----------------------------------------
my $output1="SORTIE.txt";
if (!open (FILEOUTTXT,">$output1")) { die "Pb a l'ouverture du fichier $output1"};
my $output2="SORTIE.xml";
if (!open (FILEOUTXML,">$output2")) { die "Pb a l'ouverture du fichier $output2"};
#----------------------------------------
&parcoursarborescencefichiers($rep); #recurse!
#----------------------------------------
print FILEOUTXML "<?xml version=\"1.0\" encoding=\"iso-8859-1\" ?>\n";
print FILEOUTXML "<PARCOURS>\n";
print FILEOUTXML "<NOM>SF</NOM>\n";
print FILEOUTXML "<FILTRAGE>".$DUMPFULL1."</FILTRAGE>\n";
print FILEOUTXML "</PARCOURS>\n";
close(FILEOUTXML);
print FILEOUTTXT $DUMPFULL2;
close(FILEOUTTXT);
exit;
#----------------------------------------------
sub parcoursarborescencefichiers {
my $path = shift(@_);
opendir(DIR, $path) or die "can't open $path: $!\n";
my @files = readdir(DIR);
closedir(DIR);
foreach my $file (@files) {
next if $file =~ /^\.\.?$/;
$file = $path."/".$file;
if (-d $file) {
&parcoursarborescencefichiers($file); #recurse!
}
if (-f $file) {
if ($file=~/\.xml$/) {
print $i++,"\n";
open(FILEIN,$file);
while (my $ligne=<FILEIN>) {
if ($ligne=~/<\/item>/) {
$DUMPFULL1.="</article>\n";
}
if ($ligne=~/<item>/) {
$cptArticle++;
$DUMPFULL1.="<article numero=\"$cptArticle\">\n";
}
if ($ligne=~/<description>(.+?)<\/description>/) {
my $text=$1;
$text=&nettoieText($text);
if (!(exists($dicoDesDescriptions{$text}))) {
$DUMPFULL1.="<description>$text</description>\n";
$DUMPFULL2.=$text."\n";
$dicoDesDescriptions{$text}++;
}
else {
$dicoDesDescriptions{$text}++;
$DUMPFULL1.="<description>-</description>\n";
}
}
if ($ligne=~/<title>(.+?)<\/title>/) {
my $text=$1;
$text=&nettoieText($text);
if (!(exists($dicoDesTitres{$text}))) {
$DUMPFULL1.="<abstract>$text</abstract>\n";
$DUMPFULL2.=$text."\n";
$dicoDesTitres{$text}++;
}
else {
$dicoDesTitres{$text}++;
$DUMPFULL1.="<abstract>-</abstract>\n";
}
}
}
close(FILEIN);
}
}
}
}
#----------------------------------------------
sub nettoieText {
my $texte=shift;
$texte =~ s/</</g;
$texte =~ s/>/>/g;
$texte =~ s/<a href[^>]+>//g;
$texte =~ s/<img[^>]+>//g;
$texte =~ s/<\/a>//g;
$texte =~ s/&#39;/'/g;
$texte =~ s/&#34;/"/g;
$texte =~ s/<[^>]+>//g;
$texte =~ s/é/é/g;
$texte =~ s/ê/ê/g;
return $texte;
}
Nous avons ici la seconde version de l'Outil 1 qui utilise un des modules disponible en Perl. La raison pour laquelle on distingue ces deux catégories est que les modules sont des programmes additionnels déjà écrits en Perl mais qui doivent être téléchargés séparément. Ils sont faits de plusieurs manières différentes, en fonction du système d'exploitation sous lequel on tourne. Habituellement, il est plus facile d'utiliser un package manager (comme Homebrew pour MacOS, Chocolatey pour Windows, etc.) pour pouvoir télécharger et installer correctement ces modules en quelques clics.
Ce script utilise l'approche "Perl modules". Pour ce script, nous avons téléchargé les modules XML::RSS et Unicode::String (la casse est importante !) et nous pouvons donc les utiliser pour parser les fichiers XML et convertir le texte en utf-8.  Le script vérifie l'encodage (en majuscule avec uc) à la première ligne avec la string "UTF-8" et si cela ne correspond pas, on utilise le module Unicode::String pour convertir le fichier en utf-8. L'autre grande différence est que par rapport au premier programme où on utilise des expressions régulières pour extraire les titres et descriptions, on utilise XML::RSS pour le faire (lignes 25-26). Autrement dit, comme dans le premier programme, on s'assure également que l'on traite chaque texte seulement une fois et qu'on nettoie le texte en utilisant une procédure qui contient beaucoup de s///g pour substituer les caractères indésirables à leur équivalent.
Le script vérifie l'encodage (en majuscule avec uc) à la première ligne avec la string "UTF-8" et si cela ne correspond pas, on utilise le module Unicode::String pour convertir le fichier en utf-8. L'autre grande différence est que par rapport au premier programme où on utilise des expressions régulières pour extraire les titres et descriptions, on utilise XML::RSS pour le faire (lignes 25-26). Autrement dit, comme dans le premier programme, on s'assure également que l'on traite chaque texte seulement une fois et qu'on nettoie le texte en utilisant une procédure qui contient beaucoup de s///g pour substituer les caractères indésirables à leur équivalent.
- #!/usr/bin/perl
- use XML::RSS;
- use Unicode::String qw(utf8);
- #----------------------------------------------------------
- my $encodagesortie="utf-8";
- my $encodage=`file -i $ARGV[0] | cut -d= -f2`;
- open(OUT1,">:encoding($encodagesortie)","sortie-textebrut-avec-xmlrss.txt");
- open(OUT2,">:encoding($encodagesortie)","sortie-textexml-avec-xmlrss.xml");
- print OUT2 "<?xml version=\"1.0\" encoding=\"$encodagesortie\" ?>\n";
- print OUT2 "<file>\n";
- print OUT2 "<name>$ARGV[0]</name>\n";
- #-----------------------------------------------------------
- my $file="$ARGV[0]";
- my $rss=new XML::RSS;
- #-----------------------------------------------------------
- eval {$rss->parsefile($file); };
- if( $@ ) {
- $@ =~ s/at \/.*?$//s; # remove module line number
- print STDERR "\nERROR in '$file':\n$@\n";
- } else {
- my $date=$rss->{'channel'}->{'pubDate'};
- print OUT2 "<date>$date</date>\n";
- print OUT2 "<items>\n";
- foreach my $item (@{$rss->{'items'}}) {
- my $titre=$item->{'title'};
- my $resume=$item->{'description'};
- $titre=&nettoietexte($titre);
- $resume=&nettoietexte($resume);
- if (uc($encodage) ne "UTF-8") {utf8($titre);utf8($resume);}
- print OUT1 "Titre : $titre \n";
- print OUT1 "Resume : $resume \n";;
- print OUT2
- "<item><title>$titre</title><abstract>$resume</abstract></item>\n";
- }
- }
- #----------------------------------------------------------
- print OUT2 "</items>\n</file>\n";
- close(OUT1);
- close(OUT2);
- close(FILE);
- exit;
- #----------------------------------------------------------
- #----------------------------------------------------------
- sub nettoietexte {
- my $texte=shift;
- $texte=~s/'/'/g;
- $texte=~s/"/"/g;
- $texte =~ s/</</g;
- $texte =~ s/>/>/g;
- $texte =~ s/<a href[^>]+>//g;
- $texte =~ s/<img[^>]+>//g;
- $texte =~ s/<\/a>//g;
- $texte =~ s/&#39;/'/g;
- $texte =~ s/&#34;/"/g;
- $texte =~ s/<[^>]+>//g;
- return $texte;
- }
#!/usr/bin/perl
use XML::RSS;
use Unicode::String qw(utf8);
#----------------------------------------------------------
my $encodagesortie="utf-8";
my $encodage=`file -i $ARGV[0] | cut -d= -f2`;
open(OUT1,">:encoding($encodagesortie)","sortie-textebrut-avec-xmlrss.txt");
open(OUT2,">:encoding($encodagesortie)","sortie-textexml-avec-xmlrss.xml");
print OUT2 "<?xml version=\"1.0\" encoding=\"$encodagesortie\" ?>\n";
print OUT2 "<file>\n";
print OUT2 "<name>$ARGV[0]</name>\n";
#-----------------------------------------------------------
my $file="$ARGV[0]";
my $rss=new XML::RSS;
#-----------------------------------------------------------
eval {$rss->parsefile($file); };
if( $@ ) {
$@ =~ s/at \/.*?$//s; # remove module line number
print STDERR "\nERROR in '$file':\n$@\n";
} else {
my $date=$rss->{'channel'}->{'pubDate'};
print OUT2 "<date>$date</date>\n";
print OUT2 "<items>\n";
foreach my $item (@{$rss->{'items'}}) {
my $titre=$item->{'title'};
my $resume=$item->{'description'};
$titre=&nettoietexte($titre);
$resume=&nettoietexte($resume);
if (uc($encodage) ne "UTF-8") {utf8($titre);utf8($resume);}
print OUT1 "Titre : $titre \n";
print OUT1 "Resume : $resume \n";;
print OUT2
"<item><title>$titre</title><abstract>$resume</abstract></item>\n";
}
}
#----------------------------------------------------------
print OUT2 "</items>\n</file>\n";
close(OUT1);
close(OUT2);
close(FILE);
exit;
#----------------------------------------------------------
#----------------------------------------------------------
sub nettoietexte {
my $texte=shift;
$texte=~s/'/'/g;
$texte=~s/"/"/g;
$texte =~ s/</</g;
$texte =~ s/>/>/g;
$texte =~ s/<a href[^>]+>//g;
$texte =~ s/<img[^>]+>//g;
$texte =~ s/<\/a>//g;
$texte =~ s/&#39;/'/g;
$texte =~ s/&#34;/"/g;
$texte =~ s/<[^>]+>//g;
return $texte;
}Perl avec XPATH
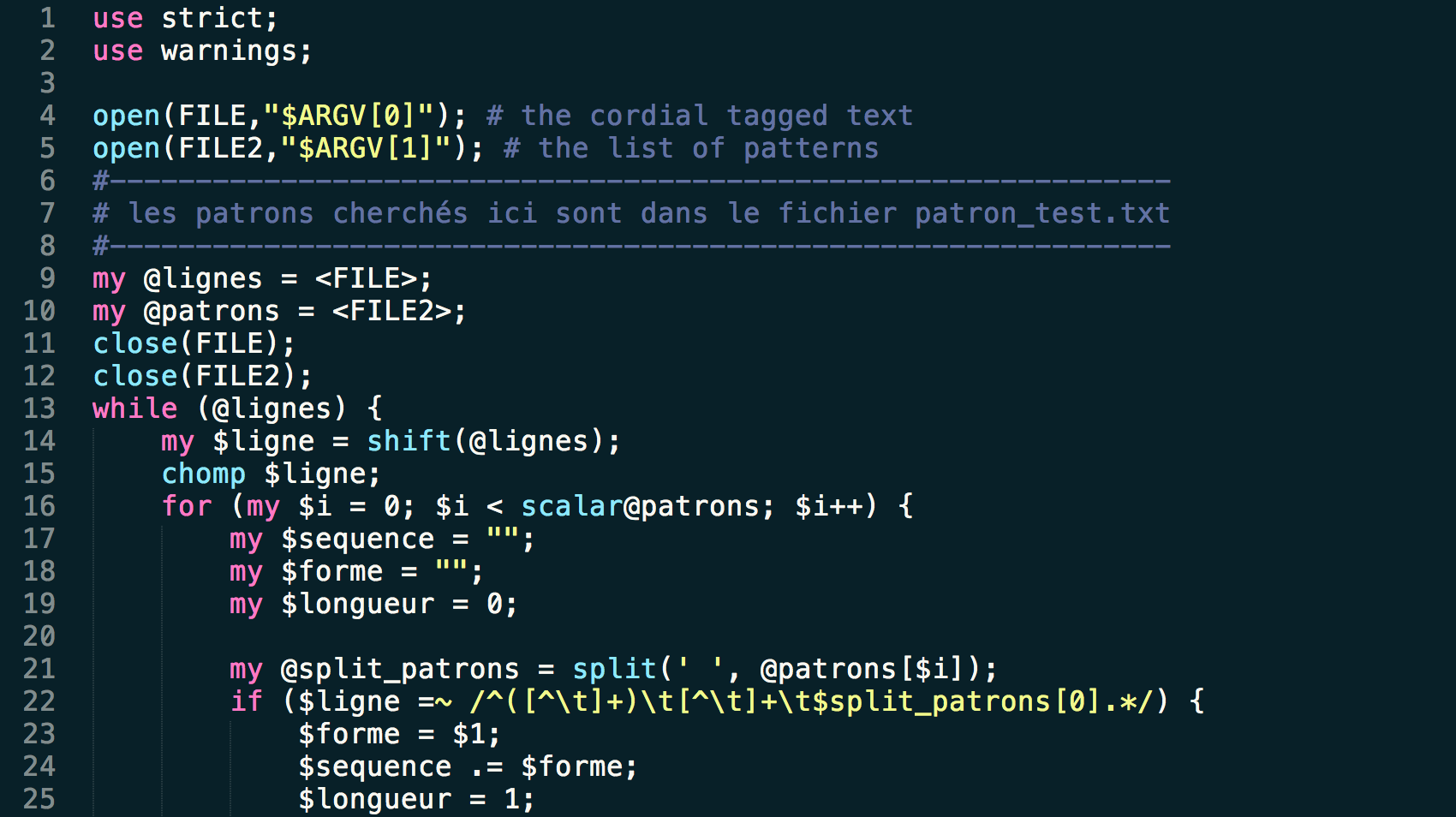
La troisième version du script utilise un module différent : XML::XPath. Avec l'utilisation de ce module, nous avons un script qui ressemble plus au script qui utilise XML::RSS. Le module utilise XPATH pour parser la structure XML et trouver les éléments contenus dans les balises cherchées. 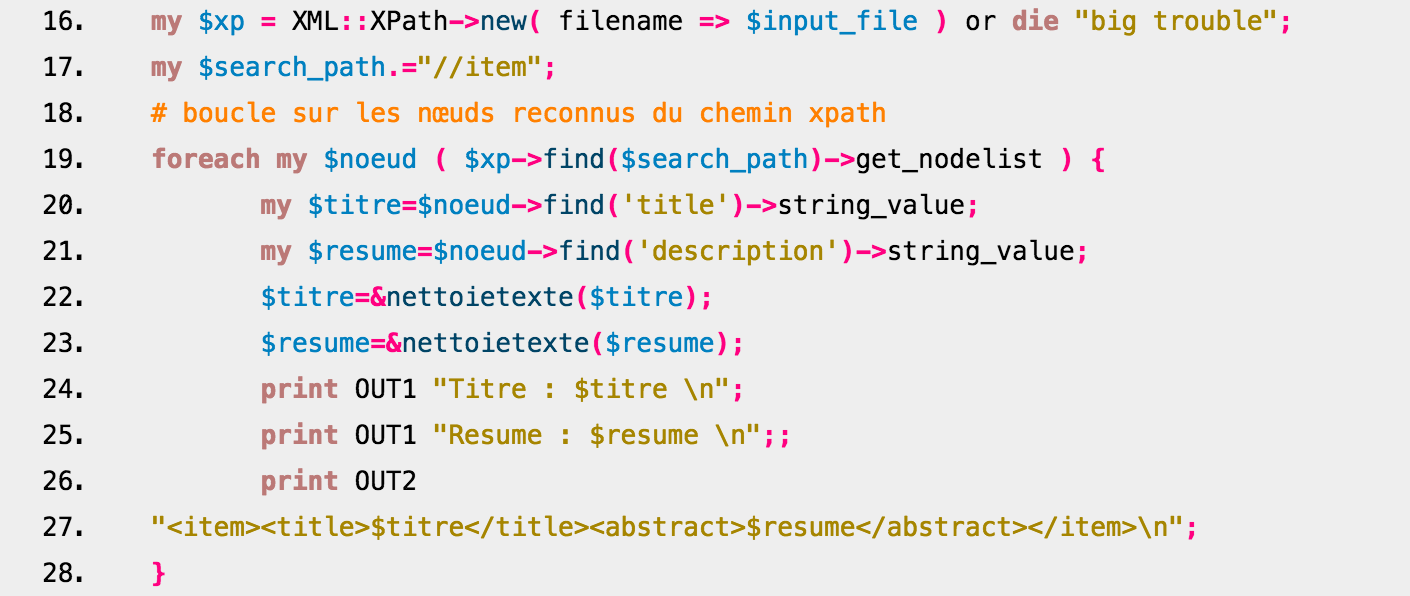 Ce script crée également deux sorties (XML et TXT) et nettoie les données à l'aide d'une procédure qui substitue les caractères indésirables par leur équivalent.
Ce script crée également deux sorties (XML et TXT) et nettoie les données à l'aide d'une procédure qui substitue les caractères indésirables par leur équivalent.
- #/usr/bin/perl
- use XML::XPath;
- # On vérifie le nombre d'arguments de l'appel au script ($0 : le nom du script)
- if($#ARGV!=0){
- print "usage : perl $0 fichier_tag fichier_motif";
- exit; }
- #----------------------------------------------------------------------------------
- -----------------------------------------------------------------
- my $encodagesortie="utf-8";
- open(OUT1,">:encoding($encodagesortie)","sortie-textebrut-avec-xmlxpath.txt");
- open(OUT2,">:encoding($encodagesortie)","sortie-textexml-avec-xmlxpath.xml");
- print OUT2 "<?xml version=\"1.0\" encoding=\"$encodagesortie\" ?>\n";
- print OUT2 "<file>\n";
- print OUT2 "<name>$ARGV[0]</name>\n";
- my $input_file= shift @ARGV;
- my $xp = XML::XPath->new( filename => $input_file ) or die "big trouble";
- my $search_path.="//item";
- # boucle sur les nœuds reconnus du chemin xpath
- foreach my $noeud ( $xp->find($search_path)->get_nodelist ) {
- my $titre=$noeud->find('title')->string_value;
- my $resume=$noeud->find('description')->string_value;
- $titre=&nettoietexte($titre);
- $resume=&nettoietexte($resume);
- print OUT1 "Titre : $titre \n";
- print OUT1 "Resume : $resume \n";;
- print OUT2
- "<item><title>$titre</title><abstract>$resume</abstract></item>\n";
- }
- #----------------------------------------------------------
- print OUT2 "</items>\n</file>\n";
- close(OUT1);
- close(OUT2);
- close(FILE);
- exit;
- sub nettoietexte {
- my $texte=shift;
- $texte=~s/'/'/g;
- $texte=~s/"/"/g;
- $texte =~ s/</</g;
- $texte =~ s/>/>/g;
- $texte =~ s/<a href[^>]+>//g;
- $texte =~ s/<img[^>]+>//g;
- $texte =~ s/<\/a>//g;
- $texte =~ s/&#39;/'/g;
- $texte =~ s/&#34;/"/g;
- $texte =~ s/<[^>]+>//g;
- return $texte;
- }
#/usr/bin/perl
use XML::XPath;
# On vérifie le nombre d'arguments de l'appel au script ($0 : le nom du script)
if($#ARGV!=0){
print "usage : perl $0 fichier_tag fichier_motif";
exit; }
#----------------------------------------------------------------------------------
-----------------------------------------------------------------
my $encodagesortie="utf-8";
open(OUT1,">:encoding($encodagesortie)","sortie-textebrut-avec-xmlxpath.txt");
open(OUT2,">:encoding($encodagesortie)","sortie-textexml-avec-xmlxpath.xml");
print OUT2 "<?xml version=\"1.0\" encoding=\"$encodagesortie\" ?>\n";
print OUT2 "<file>\n";
print OUT2 "<name>$ARGV[0]</name>\n";
my $input_file= shift @ARGV;
my $xp = XML::XPath->new( filename => $input_file ) or die "big trouble";
my $search_path.="//item";
# boucle sur les nœuds reconnus du chemin xpath
foreach my $noeud ( $xp->find($search_path)->get_nodelist ) {
my $titre=$noeud->find('title')->string_value;
my $resume=$noeud->find('description')->string_value;
$titre=&nettoietexte($titre);
$resume=&nettoietexte($resume);
print OUT1 "Titre : $titre \n";
print OUT1 "Resume : $resume \n";;
print OUT2
"<item><title>$titre</title><abstract>$resume</abstract></item>\n";
}
#----------------------------------------------------------
print OUT2 "</items>\n</file>\n";
close(OUT1);
close(OUT2);
close(FILE);
exit;
sub nettoietexte {
my $texte=shift;
$texte=~s/'/'/g;
$texte=~s/"/"/g;
$texte =~ s/</</g;
$texte =~ s/>/>/g;
$texte =~ s/<a href[^>]+>//g;
$texte =~ s/<img[^>]+>//g;
$texte =~ s/<\/a>//g;
$texte =~ s/&#39;/'/g;
$texte =~ s/&#34;/"/g;
$texte =~ s/<[^>]+>//g;
return $texte;
}Pure Perl
Notre version fait la même chose que celle faite en cours mais d'une manière légèrement différente. Vous verrez que notre version est bien plus longue. C'est essentiellement dû au fait que les commentaires que nous avons ajoutés mais aussi à la procédure de nettoyage qui est très longue (la procédure nettoietexte()**). Nous avons remarqué qu'il y a toujours quelques caractères dans la sortie qui ne sont pas affichés correctement alors nous avons ajouté d'autres expressions régulières pour régler ces exceptions. 
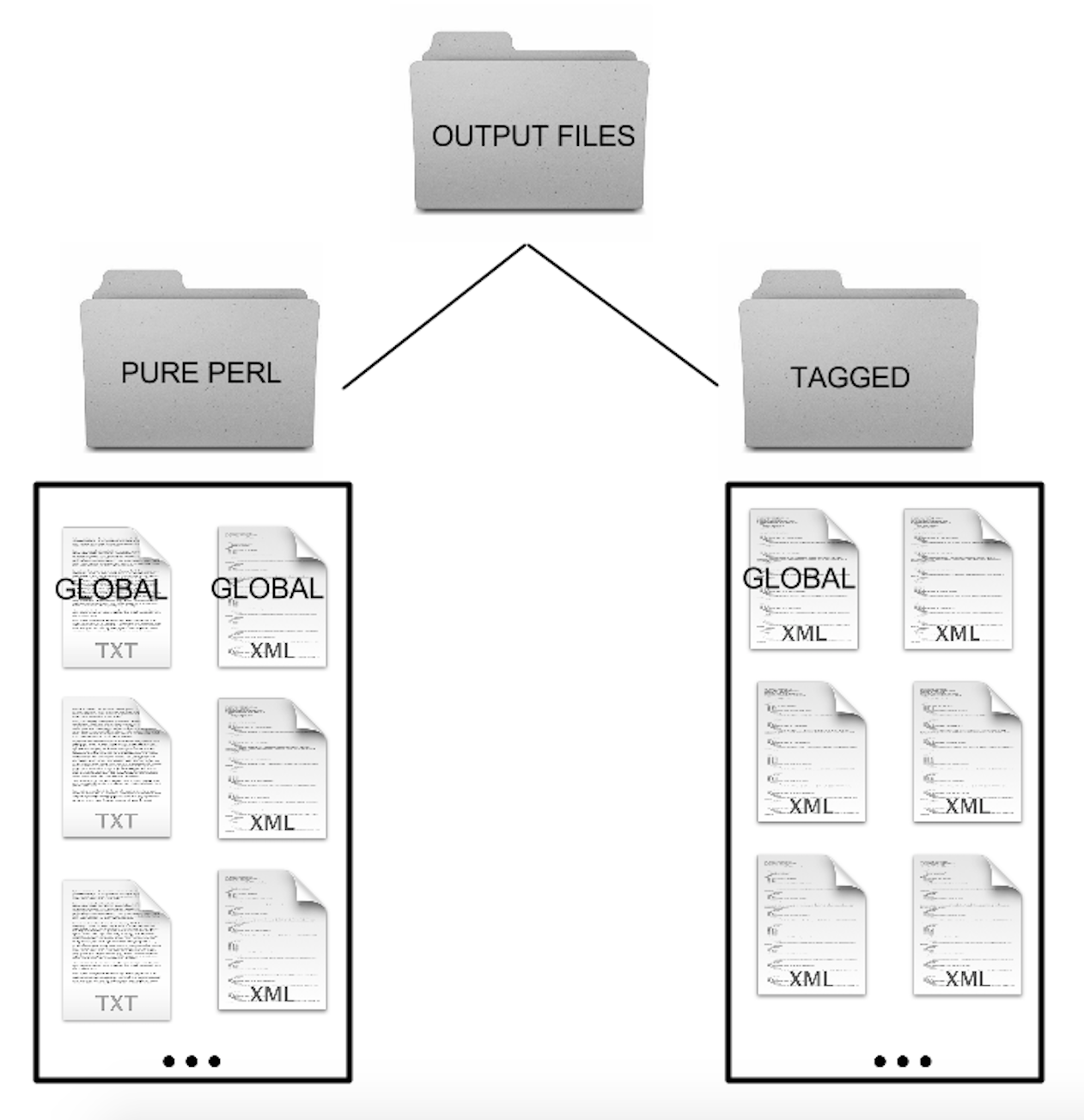
Nous avons aussi changé un des aspects les plus importants dans le code. Nous n'avons plus juste un fichier global de sorties qui contient tous les sujets différents ensemble. Nous avons séparé chaque sujet pour qu'il ait son propre fichier de sorties (un XML et un TXT).  Avoir ses données séparées de cette manière est important, particulièrement pour l'Outil 3. L'inclure dans le code à cette étape nous simplifiera la tâche pour plus tard.
Avoir ses données séparées de cette manière est important, particulièrement pour l'Outil 3. L'inclure dans le code à cette étape nous simplifiera la tâche pour plus tard.
**Vous remarquerez également que quelques noms de varibles diffèrent. Cependant, les idées sont les mêmes.
***Ce code n'est pas du 100% "Pure Perl", nous utilisons un module, Unicode::String, pour convertir en utf-8.
Le code :
- #/usr/bin/perl
- use Unicode::String qw(utf8);
- #lire l'entrée standard
- my $rep="$ARGV[0]";
- # éliminier les possibles "/" à la fin du nom du dossier
- $rep=~ s/[\/]$//;
- # liste pour stocker les items déjà traités
- my %dictionnairedesitems = ();
- # liste pour stocker les rubriques déjà traités
- my %dictionnairesdesrubriques = ();
- # appeler la fonction extraire_rubrique() pour lire les dossiers et extraire les rubriques des fichiers
- &extraire_rubrique($rep);
- my @liste_rubriques = keys(%dictionnairesdesrubriques);
- # pour chaque rubrique, créer un fichier de sortie .xml et un fichier .txt
- foreach my $rub (@liste_rubriques) {
- my $output1= "SORTIE-extract-txt-".$rub.".xml";
- my $output2= "SORTIE-extract-txt-".$rub.".txt";
- # créer fichier .xml de sortie
- open (FILEOUTXML, ">:encoding(utf-8)", $output1) or die "Could not open file @output1!"; # open file for writing
- # créer fichier .txt de sortie
- open (FILEOUTTXT, ">:encoding(utf-8)", $output2) or die "Could not open file $output2!"; # open file for writing)
- # écrier déclaration d'en-tête du fichier xml
- print FILEOUTXML "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
- print FILEOUTXML "<PARCOURS>\n";
- #fermer les deux fichiers
- close(FILEOUTXML);
- close(FILEOUTTXT);
- print $output1;
- }
- # appeler lire_et_ecrire_xml() pour lire tous les fichiers xml et créer les sorties
- &lire_et_ecrire_xml($rep);
- foreach my $rub (@liste_rubriques)
- {
- my $output1="SORTIE-extract-txt-".$rub.".xml";
- if (!open (FILEOUTXML,">>:encoding(utf-8)", $output1))
- {
- die "Pb a l'ouverture du fichier $output1";
- }
- print FILEOUTXML "</PARCOURS>\n";
- close(FILEOUTXML);
- }
- exit;
- #########################################################################################################
- # #
- # cette fonction reçoit un nom de dossier comme argument et lit tous les fichiers .xml du dossier #
- # Pour chaque fichier lu, la fonction extrait les texte des balise <title> et <description>, ainsi que #
- # les dates présente en <pubDate> et <rubrique> #
- # Ce contenu insère dans des fichiers .xml et .txt de sortie de la rubrique correspondante #
- # #
- #########################################################################################################
- sub lire_et_ecrire_xml {
- # lire nom de dossier passé comme argument
- my $path = shift(@_);
- # ouvrir dossier
- opendir(DIR, $path) or die "can't open $path: $!\n";
- # lire itens dans le dossier
- my @files = readdir(DIR);
- closedir(DIR);
- # fermer dossier
- foreach my $file (@files)
- {
- # ignorer les items cachés
- next if $file =~ /^\.\.?$/;
- # construire le chemin complet avec le nom du dossier + item traité
- $file = $path."/".$file;
- # vérifier si l'item traité est dossier
- if (-d $file)
- {
- # si l'item qu'on est en train de traiter est un dossier, on recommence la procédure
- &lire_et_ecrire_xml($file);
- }
- # vérifier si l'item traité un fichier IF1
- if (-f $file)
- {
- # vérifier s'il s'agit d'un fichier .xml qui ne contient pas fil dans le nom iF2
- if (($file=~/\.xml$/) && ($file!~/\/fil.+\.xml$/))
- {
- # ouvrir fichier
- open(FILE, $file);
- # variable pour stocker le contenu du fichier
- my $texte="";
- #lire le contenu du fichier ligne à line
- while (my $ligne=<FILE>)
- {
- chomp $ligne;
- $texte .= $ligne;
- }
- # fermer fichier
- close(FILE);
- # regex pour capturer l'encodage du fichier
- $texte=~/encoding ?= ?[\'\"]([^\'\"]+)[\'\"]/i;
- # stocker l'encogade du fichier
- my $encodage=$1;
- # vérifier si l'encodage n'est pas vide pour traiter le contenu IF3
- if ($encodage ne "")
- {
- # la variable temptexteXML stocke les contenus prêts à être écrits dans fichier .xml de sortie
- my $tmptexteXML="<file>\n";
- # créer balise avec le nom du fichier
- $tmptexteXML.="<name>$file</name>\n";
- # éliminier les balises avec des espaces en blanc
- $texte =~ s/> *</></g;
- # regex pour capturer date
- $texte=~/<pubDate>([^<]+)<\/pubDate>/;
- # stocker la valeur de date capturée par la regex
- $tmptexteXML.="<date>$1</date>\n";
- # insérer la balise <items>
- $tmptexteXML.="<items>\n";
- my $tmptexteBRUT="";
- open(FILE,"<:encoding($encodage)", $file);
- $texte="";
- # lire le fichier ligne à ligne
- while (my $ligne=<FILE>)
- {
- chomp $ligne;
- $texte .= $ligne;
- }
- close(FILE);
- $texte=~s/> *</></g;
- # on recherche la rubrique
- $texte=~/<channel><title>([^<]+)<\/title>/;
- # nettoyer le string rubrique
- my $rub=$1;
- $rub =~ s/Toute l'actualité sur Le Monde.fr.//gi;
- $rub=~s/é/e/gi;
- $rub=~s/è/e/gi;
- $rub=~s/ê/e/gi;
- $rub=~s/à/a/gi;
- $rub=~ s/Le ?Monde.fr ?://;
- $rub=~ s/ //g;
- $rub=uc($rub);
- my $output1="SORTIE-extract-txt-".$rub.".xml";
- my $output2="SORTIE-extract-txt-".$rub.".txt";
- if (!open (FILEOUTXML,">>:encoding(utf-8)", $output1)) { die "Pb a l'ouverture du fichier $output1"};
- if (!open (FILEOUTTXT,">>:encoding(utf-8)", $output2)) { die "Pb a l'ouverture du fichier $output2"};
- # lire texte pour extraire contenu des balises <title> et <description>
- while ($texte =~ /<item><title>(.+?)<\/title>.+?<description>(.+?)<\/description>/g)
- {
- # capturer contenu de la regex pour titre
- my $titre=$1;
- # capturer contenu de la regex pour description
- my $resume=$2;
- #
- $titre = &nettoyer_texte($1);
- $resume = &nettoyer_texte($2);
- # si le fichier n'est pas en UTF-8, convertir le string $titre et $resume en UTF-8
- if (uc($encodage) ne "UTF-8")
- {
- utf8($titre);
- utf8($resume);
- }
- # si le contenu de $resume n'a pas encore été traite, on doit le traiter
- if (!(exists($dictionnairedesitems{$resume})))
- {
- # créer contenu le fichier .txt
- $tmptexteBRUT.="§ $titre \n";
- $tmptexteBRUT.="$resume \n";
- # créer contenu pour fichier .xml
- $tmptexteXML.="<item><title>$titre</title><abstract>$resume</abstract></item>\n";
- # inclure contenu de $resume dans liste
- $dictionnairedesitems{$resume}++;
- } else {
- $tmptexteXML.="<item><title>-</title><abstract>-</abstract></item>\n";
- }
- } # fin while
- # rajouter la fin des balise <items> et <file>
- $tmptexteXML.="</items>\n</file>\n";
- # écrire contenu dans le fichier .xml
- print FILEOUTXML $tmptexteXML;
- # écrire contenu dans le fichier .txt
- print FILEOUTTXT $tmptexteBRUT;
- # fermer fichiers
- close FILEOUTXML;
- close FILEOUTTXT;
- } else {
- #si l'encaodre est vide afficher message
- print "$file ==> $encodage \n";
- } # fin IF3
- } # fin IF 2
- } # fin IF 1
- } # fin FOR
- } # fin lire_et_ecrire_xml()
- sub nettoyer_texte {
- my $texte=shift;
- $texte =~ s/</</g;
- $texte =~ s/>/>/g;
- $texte =~ s/<a href[^>]+>//g;
- $texte =~ s/<img[^>]+>//g;
- $texte =~ s/<\/a>//g;
- $texte =~ s/&#39;/'/g;
- $texte =~ s/&#34;/"/g;
- $texte =~ s/é/é/g;
- $texte =~ s/ê/ê/g;
- $texte =~ s/<[^>]+>//g;
- $texte =~ s/ / /g;
- $texte=~s/'/'/g;
- $texte=~s/"/"/g;
- $texte=~s/&#39;/'/g;
- $texte=~s/&#34;/"/g;
- return $texte;
- }
- ####################################################################################################
- # #
- # cette fonction reçoit un nom de dossier comme argument et lit tous les fichiers .xml du dossier #
- # Pour chaque fichier lu, la fonction extrait les rubriques et crée des fichiers de sortie #
- # possédant le nom de la rubrique #
- # #
- ####################################################################################################
- sub extraire_rubrique {
- #lire le nom dossier passé comme argument
- my $path = shift(@_);
- #ouvrir le dossier
- opendir(DIR, $path) or die "can't open $path: $!\n";
- #lire la liste de fichier du dossier
- my @files = readdir(DIR);
- closedir(DIR);
- # lire un à un les items du dossier
- foreach my $file (@files)
- {
- # ignorer les items cachés
- next if $file =~ /^\.\.?$/;
- # construire le chemin complet avec le nom du dossier + item traité
- $file = $path."/".$file;
- # vérifier si l'item est un dossier
- if (-d $file)
- {
- # si l'item qu'on est en train de traiter est un dossier, on recommence la procédure
- &extraire_rubrique($file);
- }
- # vérifier si l'item est un fichier - IF1
- if (-f $file)
- {
- # tester si fichier possède l'extension .xml et ne contient pas la substring fil dans le nom - IF2
- if (($file =~ /\.xml$/) && ($file!~/\/fil.+\.xml$/))
- {
- #ouvrir fichier .xml
- open(FILE,$file);
- #variable pour stocker le contenu du fichier .xml
- my $texte="";
- #lire toutes les lignes du fichier .xml
- while (my $ligne=<FILE>)
- {
- # effacer les retours à la ligne
- chomp $ligne;
- # stocker le contenu de ligne lue
- $texte .= $ligne;
- }
- # fermer le fichier .xml
- close(FILE);
- # regex pour capture l`encodage du fichier
- $texte =~ /encoding ?= ?[\'\"]([^\'\"]+)[\'\"]/i;
- # stocker le contenu trouvé par la regex
- my $encodage=$1;
- # vérifier la contenu de regex n'est pas vide IF3
- if ($encodage ne "")
- {
- # reouvrir le fichier avec l'encogade correcte
- open(FILE,"<:encoding($encodage)", $file);
- # variables pour stocker le contenu du fichier lu
- $texte="";
- # lire le fichier .xml
- while (my $ligne=<FILE>)
- {
- # effacer les retours à la ligne
- chomp $ligne;
- # stocker le contenu de ligne lue
- $texte .= $ligne;
- }
- # fermer le fichier .xml
- close(FILE);
- # effacer les espaces en blanc
- $texte =~ s/> *</></g;
- # capturer le contenu à l'intérieur des balises <title> - IF4
- if ($texte=~ /<channel><title>([^>]+)<\/title>/)
- {
- print $texte;
- # stocker la valeur de rubrique trouvée par la regex
- my $rub=$1;
- # nettoyer les noms des rubriques
- $rub =~ s/Toute l'actualité sur Le Monde.fr.//gi;
- $rub=~s/é/e/gi;
- $rub=~s/è/e/gi;
- $rub=~s/ê/e/gi;
- $rub=~s/à/a/gi;
- $rub=~ s/Le ?Monde.fr ?://i;
- $rub=~ s/ //g;
- $rub=uc($rub);
- # stocker la rubrique dans le dictionnaire des rubriques
- $dictionnairesdesrubriques{$rub}++;
- } # fin IF4
- } # fin IF3
- } # fin IF2
- } # fin IF1
- } # fin FOR
- } # fin extraire_rubrique()
#/usr/bin/perl
use Unicode::String qw(utf8);
#lire l'entrée standard
my $rep="$ARGV[0]";
# éliminier les possibles "/" à la fin du nom du dossier
$rep=~ s/[\/]$//;
# liste pour stocker les items déjà traités
my %dictionnairedesitems = ();
# liste pour stocker les rubriques déjà traités
my %dictionnairesdesrubriques = ();
# appeler la fonction extraire_rubrique() pour lire les dossiers et extraire les rubriques des fichiers
&extraire_rubrique($rep);
my @liste_rubriques = keys(%dictionnairesdesrubriques);
# pour chaque rubrique, créer un fichier de sortie .xml et un fichier .txt
foreach my $rub (@liste_rubriques) {
my $output1= "SORTIE-extract-txt-".$rub.".xml";
my $output2= "SORTIE-extract-txt-".$rub.".txt";
# créer fichier .xml de sortie
open (FILEOUTXML, ">:encoding(utf-8)", $output1) or die "Could not open file @output1!"; # open file for writing
# créer fichier .txt de sortie
open (FILEOUTTXT, ">:encoding(utf-8)", $output2) or die "Could not open file $output2!"; # open file for writing)
# écrier déclaration d'en-tête du fichier xml
print FILEOUTXML "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print FILEOUTXML "<PARCOURS>\n";
#fermer les deux fichiers
close(FILEOUTXML);
close(FILEOUTTXT);
print $output1;
}
# appeler lire_et_ecrire_xml() pour lire tous les fichiers xml et créer les sorties
&lire_et_ecrire_xml($rep);
foreach my $rub (@liste_rubriques)
{
my $output1="SORTIE-extract-txt-".$rub.".xml";
if (!open (FILEOUTXML,">>:encoding(utf-8)", $output1))
{
die "Pb a l'ouverture du fichier $output1";
}
print FILEOUTXML "</PARCOURS>\n";
close(FILEOUTXML);
}
exit;
#########################################################################################################
# #
# cette fonction reçoit un nom de dossier comme argument et lit tous les fichiers .xml du dossier #
# Pour chaque fichier lu, la fonction extrait les texte des balise <title> et <description>, ainsi que #
# les dates présente en <pubDate> et <rubrique> #
# Ce contenu insère dans des fichiers .xml et .txt de sortie de la rubrique correspondante #
# #
#########################################################################################################
sub lire_et_ecrire_xml {
# lire nom de dossier passé comme argument
my $path = shift(@_);
# ouvrir dossier
opendir(DIR, $path) or die "can't open $path: $!\n";
# lire itens dans le dossier
my @files = readdir(DIR);
closedir(DIR);
# fermer dossier
foreach my $file (@files)
{
# ignorer les items cachés
next if $file =~ /^\.\.?$/;
# construire le chemin complet avec le nom du dossier + item traité
$file = $path."/".$file;
# vérifier si l'item traité est dossier
if (-d $file)
{
# si l'item qu'on est en train de traiter est un dossier, on recommence la procédure
&lire_et_ecrire_xml($file);
}
# vérifier si l'item traité un fichier IF1
if (-f $file)
{
# vérifier s'il s'agit d'un fichier .xml qui ne contient pas fil dans le nom iF2
if (($file=~/\.xml$/) && ($file!~/\/fil.+\.xml$/))
{
# ouvrir fichier
open(FILE, $file);
# variable pour stocker le contenu du fichier
my $texte="";
#lire le contenu du fichier ligne à line
while (my $ligne=<FILE>)
{
chomp $ligne;
$texte .= $ligne;
}
# fermer fichier
close(FILE);
# regex pour capturer l'encodage du fichier
$texte=~/encoding ?= ?[\'\"]([^\'\"]+)[\'\"]/i;
# stocker l'encogade du fichier
my $encodage=$1;
# vérifier si l'encodage n'est pas vide pour traiter le contenu IF3
if ($encodage ne "")
{
# la variable temptexteXML stocke les contenus prêts à être écrits dans fichier .xml de sortie
my $tmptexteXML="<file>\n";
# créer balise avec le nom du fichier
$tmptexteXML.="<name>$file</name>\n";
# éliminier les balises avec des espaces en blanc
$texte =~ s/> *</></g;
# regex pour capturer date
$texte=~/<pubDate>([^<]+)<\/pubDate>/;
# stocker la valeur de date capturée par la regex
$tmptexteXML.="<date>$1</date>\n";
# insérer la balise <items>
$tmptexteXML.="<items>\n";
my $tmptexteBRUT="";
open(FILE,"<:encoding($encodage)", $file);
$texte="";
# lire le fichier ligne à ligne
while (my $ligne=<FILE>)
{
chomp $ligne;
$texte .= $ligne;
}
close(FILE);
$texte=~s/> *</></g;
# on recherche la rubrique
$texte=~/<channel><title>([^<]+)<\/title>/;
# nettoyer le string rubrique
my $rub=$1;
$rub =~ s/Toute l'actualité sur Le Monde.fr.//gi;
$rub=~s/é/e/gi;
$rub=~s/è/e/gi;
$rub=~s/ê/e/gi;
$rub=~s/à/a/gi;
$rub=~ s/Le ?Monde.fr ?://;
$rub=~ s/ //g;
$rub=uc($rub);
my $output1="SORTIE-extract-txt-".$rub.".xml";
my $output2="SORTIE-extract-txt-".$rub.".txt";
if (!open (FILEOUTXML,">>:encoding(utf-8)", $output1)) { die "Pb a l'ouverture du fichier $output1"};
if (!open (FILEOUTTXT,">>:encoding(utf-8)", $output2)) { die "Pb a l'ouverture du fichier $output2"};
# lire texte pour extraire contenu des balises <title> et <description>
while ($texte =~ /<item><title>(.+?)<\/title>.+?<description>(.+?)<\/description>/g)
{
# capturer contenu de la regex pour titre
my $titre=$1;
# capturer contenu de la regex pour description
my $resume=$2;
#
$titre = &nettoyer_texte($1);
$resume = &nettoyer_texte($2);
# si le fichier n'est pas en UTF-8, convertir le string $titre et $resume en UTF-8
if (uc($encodage) ne "UTF-8")
{
utf8($titre);
utf8($resume);
}
# si le contenu de $resume n'a pas encore été traite, on doit le traiter
if (!(exists($dictionnairedesitems{$resume})))
{
# créer contenu le fichier .txt
$tmptexteBRUT.="§ $titre \n";
$tmptexteBRUT.="$resume \n";
# créer contenu pour fichier .xml
$tmptexteXML.="<item><title>$titre</title><abstract>$resume</abstract></item>\n";
# inclure contenu de $resume dans liste
$dictionnairedesitems{$resume}++;
} else {
$tmptexteXML.="<item><title>-</title><abstract>-</abstract></item>\n";
}
} # fin while
# rajouter la fin des balise <items> et <file>
$tmptexteXML.="</items>\n</file>\n";
# écrire contenu dans le fichier .xml
print FILEOUTXML $tmptexteXML;
# écrire contenu dans le fichier .txt
print FILEOUTTXT $tmptexteBRUT;
# fermer fichiers
close FILEOUTXML;
close FILEOUTTXT;
} else {
#si l'encaodre est vide afficher message
print "$file ==> $encodage \n";
} # fin IF3
} # fin IF 2
} # fin IF 1
} # fin FOR
} # fin lire_et_ecrire_xml()
sub nettoyer_texte {
my $texte=shift;
$texte =~ s/</</g;
$texte =~ s/>/>/g;
$texte =~ s/<a href[^>]+>//g;
$texte =~ s/<img[^>]+>//g;
$texte =~ s/<\/a>//g;
$texte =~ s/&#39;/'/g;
$texte =~ s/&#34;/"/g;
$texte =~ s/é/é/g;
$texte =~ s/ê/ê/g;
$texte =~ s/<[^>]+>//g;
$texte =~ s/ / /g;
$texte=~s/'/'/g;
$texte=~s/"/"/g;
$texte=~s/&#39;/'/g;
$texte=~s/&#34;/"/g;
return $texte;
}
####################################################################################################
# #
# cette fonction reçoit un nom de dossier comme argument et lit tous les fichiers .xml du dossier #
# Pour chaque fichier lu, la fonction extrait les rubriques et crée des fichiers de sortie #
# possédant le nom de la rubrique #
# #
####################################################################################################
sub extraire_rubrique {
#lire le nom dossier passé comme argument
my $path = shift(@_);
#ouvrir le dossier
opendir(DIR, $path) or die "can't open $path: $!\n";
#lire la liste de fichier du dossier
my @files = readdir(DIR);
closedir(DIR);
# lire un à un les items du dossier
foreach my $file (@files)
{
# ignorer les items cachés
next if $file =~ /^\.\.?$/;
# construire le chemin complet avec le nom du dossier + item traité
$file = $path."/".$file;
# vérifier si l'item est un dossier
if (-d $file)
{
# si l'item qu'on est en train de traiter est un dossier, on recommence la procédure
&extraire_rubrique($file);
}
# vérifier si l'item est un fichier - IF1
if (-f $file)
{
# tester si fichier possède l'extension .xml et ne contient pas la substring fil dans le nom - IF2
if (($file =~ /\.xml$/) && ($file!~/\/fil.+\.xml$/))
{
#ouvrir fichier .xml
open(FILE,$file);
#variable pour stocker le contenu du fichier .xml
my $texte="";
#lire toutes les lignes du fichier .xml
while (my $ligne=<FILE>)
{
# effacer les retours à la ligne
chomp $ligne;
# stocker le contenu de ligne lue
$texte .= $ligne;
}
# fermer le fichier .xml
close(FILE);
# regex pour capture l`encodage du fichier
$texte =~ /encoding ?= ?[\'\"]([^\'\"]+)[\'\"]/i;
# stocker le contenu trouvé par la regex
my $encodage=$1;
# vérifier la contenu de regex n'est pas vide IF3
if ($encodage ne "")
{
# reouvrir le fichier avec l'encogade correcte
open(FILE,"<:encoding($encodage)", $file);
# variables pour stocker le contenu du fichier lu
$texte="";
# lire le fichier .xml
while (my $ligne=<FILE>)
{
# effacer les retours à la ligne
chomp $ligne;
# stocker le contenu de ligne lue
$texte .= $ligne;
}
# fermer le fichier .xml
close(FILE);
# effacer les espaces en blanc
$texte =~ s/> *</></g;
# capturer le contenu à l'intérieur des balises <title> - IF4
if ($texte=~ /<channel><title>([^>]+)<\/title>/)
{
print $texte;
# stocker la valeur de rubrique trouvée par la regex
my $rub=$1;
# nettoyer les noms des rubriques
$rub =~ s/Toute l'actualité sur Le Monde.fr.//gi;
$rub=~s/é/e/gi;
$rub=~s/è/e/gi;
$rub=~s/ê/e/gi;
$rub=~s/à/a/gi;
$rub=~ s/Le ?Monde.fr ?://i;
$rub=~ s/ //g;
$rub=uc($rub);
# stocker la rubrique dans le dictionnaire des rubriques
$dictionnairesdesrubriques{$rub}++;
} # fin IF4
} # fin IF3
} # fin IF2
} # fin IF1
} # fin FOR
} # fin extraire_rubrique()
Perl Modules
L’utilisation des modules XML::Entities et HTML::Entities servent à changer les entités XML et HTML, des caractères spéciaux qui permettent d’interpréter certains caractères d’une certaine manière en fonction du format du document (ici XML et HTML) en leur représentation graphique « réelle ». Par exemple, le caractère « < » est un caractère spécial en HTML et en XML qui indique l’ouverture d’une balise. Pour éviter qu’il soit confondu avec une ouverture de balise dans le fichier, on a l’entité pour éviter de l’interpréter d’une mauvaise manière et donc de potentiellement avoir un document mal structuré si on n’avait pas l’entité à la place du caractère. C’est pourquoi, comme plusieurs autres caractères, « < » sera indiqué par « ‹ » dans le fichier pour savoir qu’il ne fait pas partie de la structuration du document mais bien du contenu.
L’utilisation de ces modules dans les scripts Perl se font de la même manière, XML::Entities étant basé sur HTML::Entities. Donc, pour décoder les entités, il suffit de déclarer le module de cette façon :

Puis l’utilisation dans le programme se fait comme encadré en rouge sur l’image suivante :

Pour l'Outil 1, nous avons écrit des scripts Perl en utilisant les procédures pour nettoyer les fichiers des entités existantes mais aussi en utilisant les modules XML::Entities et HTML::Entities. Nous avons donc deux scripts différents pour l'Outil 1 et 2, autrement dit avec et sans modules Perl.
Nous nous sommes rendu compte que dans les fichiers XML, il y avait des balises images dans les balises que descriptions, mais le problème était que ces balises n’étaient pas sous forme de balises. Donc, au moment de prendre celles qui nous intéressaient dans le fichier, il nous prenait aussi ces balises bien que nous n’en voulions pas dans nos résultats. Nous avons donc procédé à un nettoyage du fichier de résultats après le décodage des entités dans les balises de descriptions.
- #/usr/bin/perl
- use Unicode::String qw(utf8);
- use XML::Entities;
- use HTML::Entities;
- use XML::RSS;
- #lire l'entrée standard
- my $rep="$ARGV[0]";
- # éliminier les possibles "/" à la fin du nom du dossier
- $rep=~ s/[\/]$//;
- # liste pour stocker les items déjà traités
- my %dictionnairedesitems = ();
- # liste pour stocker les rubriques déjà traités
- my %dictionnairesdesrubriques = ();
- # appeler la fonction extraire_rubrique() pour lire les dossiers et extraire les rubriques des fichiers
- &extraire_rubrique($rep);
- my @liste_rubriques = keys(%dictionnairesdesrubriques);
- # pour chaque rubrique, créer un fichier de sortie .xml et un fichier .txt
- foreach my $rub (@liste_rubriques) {
- my $output1= "SORTIE-extract-txt-".$rub.".xml";
- my $output2= "SORTIE-extract-txt-".$rub.".txt";
- # créer fichier .xml de sortie
- open (FILEOUTXML, ">:encoding(utf-8)", $output1) or die "Could not open file @output1!"; # open file for writing
- # créer fichier .txt de sortie
- open (FILEOUTTXT, ">:encoding(utf-8)", $output2) or die "Could not open file $output2!"; # open file for writing)
- # écrier déclaration d'en-tête du fichier xml
- print FILEOUTXML "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
- print FILEOUTXML "<PARCOURS>\n";
- #fermer les deux fichiers
- close(FILEOUTXML);
- close(FILEOUTTXT);
- print $output1;
- }
- # appeler lire_et_ecrire_xml() pour lire tous les fichiers xml et créer les sorties
- &lire_et_ecrire_xml($rep);
- foreach my $rub (@liste_rubriques)
- {
- my $output1="SORTIE-extract-txt-".$rub.".xml";
- if (!open (FILEOUTXML,">>:encoding(utf-8)", $output1))
- {
- die "Pb a l'ouverture du fichier $output1";
- }
- print FILEOUTXML "</PARCOURS>\n";
- close(FILEOUTXML);
- }
- exit;
- #########################################################################################################
- # #
- # cette fonction reçoit un nom de dossier comme argument et lit tous les fichiers .xml du dossier #
- # Pour chaque fichier lu, la fonction extrait le texte des balises <title> et <description>, ainsi que #
- # les dates présentes entre <pubDate> et <rubrique> #
- # Ce contenu insère dans des fichiers de sortie .xml et .txt la rubrique correspondante #
- # #
- #########################################################################################################
- sub lire_et_ecrire_xml {
- # lire nom de dossier passé comme argument
- my $path = shift(@_);
- # ouvrir dossier
- opendir(DIR, $path) or die "can't open $path: $!\n";
- # lire items dans le dossier
- my @files = readdir(DIR);
- closedir(DIR);
- # fermer dossier
- foreach my $file (@files)
- {
- # ignorer les items cachés
- next if $file =~ /^\.\.?$/;
- # construire le chemin complet avec le nom du dossier + item traité
- $file = $path."/".$file;
- # vérifier si l'item traité est un dossier
- if (-d $file)
- {
- # si l'item qu'on est en train de traiter est un dossier, on recommence la procédure
- &lire_et_ecrire_xml($file);
- }
- # vérifier si l'item traité un fichier IF1
- if (-f $file)
- {
- # vérifier s'il s'agit d'un fichier .xml qui ne contient pas fil dans le nom iF2
- if (($file=~/\.xml$/) && ($file!~/\/fil.+\.xml$/))
- {
- # ouvrir fichier
- open(FILE, $file);
- # variable pour stocker le contenu du fichier
- my $texte="";
- #lire le contenu du fichier ligne à line
- while (my $ligne=<FILE>)
- {
- chomp $ligne;
- $texte .= $ligne;
- }
- # fermer fichier
- close(FILE);
- # regex pour capturer l'encodage du fichier
- $texte=~/encoding ?= ?[\'\"]([^\'\"]+)[\'\"]/i;
- # stocker l'encodage du fichier
- my $encodage=$1;
- # vérifier si l'encodage n'est pas vide pour traiter le contenu IF3
- if ($encodage ne "")
- {
- # la variable tmptexteXML stocke les contenus prêts à être écrits dans fichier .xml de sortie
- my $tmptexteXML="<file>\n";
- # créer balise avec le nom du fichier
- $tmptexteXML.="<name>$file</name>\n";
- # éliminier les balises avec des espaces en blanc
- $texte =~ s/> *</></g;
- # regex pour capturer date
- $texte=~/<pubDate>([^<]+)<\/pubDate>/;
- # stocker la valeur de date capturée par la regex
- $tmptexteXML.="<date>$1</date>\n";
- # insérer la balise <items>
- $tmptexteXML.="<items>\n";
- my $tmptexteBRUT="";
- open(FILE,"<:encoding($encodage)", $file);
- $texte="";
- # lire le fichier ligne à ligne
- while (my $ligne=<FILE>)
- {
- chomp $ligne;
- $texte .= $ligne;
- }
- close(FILE);
- $texte=~s/> *</></g;
- # on recherche la rubrique
- $texte=~/<channel><title>([^<]+)<\/title>/;
- # on met le contenu trouvé par la regex dans $rub
- my $rub=$1;
- # nettoyer le string rubrique
- $rub =~ s/Toute l'actualité sur Le Monde.fr.//gi;
- $rub =~ s/é/e/gi;
- $rub =~ s/è/e/gi;
- $rub =~ s/ê/e/gi;
- $rub =~ s/à/a/gi;
- $rub =~ s/Le ?Monde.fr ?://;
- $rub =~ s/ //g;
- $rub=uc($rub);
- my $output1="SORTIE-extract-txt-".$rub.".xml";
- my $output2="SORTIE-extract-txt-".$rub.".txt";
- if (!open (FILEOUTXML,">>:encoding(utf-8)", $output1)) { die "Pb a l'ouverture du fichier $output1"};
- if (!open (FILEOUTTXT,">>:encoding(utf-8)", $output2)) { die "Pb a l'ouverture du fichier $output2"};
- # lire texte pour extraire contenu des balises <title> et <description>
- while ($texte =~ /<item><title>(.+?)<\/title>.+?<description>(.+?)<\/description>/g)
- {
- # capturer contenu de la regex pour titre
- my $titre=$1;
- # capturer contenu de la regex pour description
- my $resume=$2;
- # utilisation des modules pour remplacer dans les fichiers les entités XML et HTML
- if (!(exists ($dictionnairedesitems{$titre})) and !(exists ($dictionnairedesitems{$resume})))
- {
- $dictionnairedesitems{$titre}++;
- $dictionnairedesitems{$resume}++;
- $titre = XML::Entities::decode('all', $titre);
- $resume = XML::Entities::decode('all', $resume);
- $titre = HTML::Entities::decode($titre);
- $resume = HTML::Entities::decode($resume);
- $tmptexteBRUT.="$titre \n";
- $tmptexteBRUT.="$resume \n";
- $tmptexteXML.="<item><title>$titre</title><description>$resume</description></item>\n";
- # nettoyage des balises <description> pour supprimer les balises superflues
- $tmptexteXML =~ s/<img.*?\/><\/description>/<\/description>/g;
- $tmptexteBRUT =~ s/<img.*?\/> \n/\n/g;
- }
- # si le fichier n'est pas en UTF-8, convertir le string $titre et $resume en UTF-8
- if (uc($encodage) ne "UTF-8")
- {
- utf8($titre);
- utf8($resume);
- }
- } # fin while
- # rajouter la fin des balises <items> et <file>
- $tmptexteXML.="</items>\n</file>\n";
- # écrire contenu dans le fichier .xml
- print FILEOUTXML $tmptexteXML;
- # écrire contenu dans le fichier .txt
- print FILEOUTTXT $tmptexteBRUT;
- # fermer fichiers
- close FILEOUTXML;
- close FILEOUTTXT;
- } else {
- #si l'encodage est vide afficher message
- print "$file ==> $encodage \n";
- } # fin IF3
- } # fin IF 2
- } # fin IF 1
- } # fin FOR
- } # fin lire_et_ecrire_xml()
- ####################################################################################################
- # #
- # cette fonction reçoit un nom de dossier comme argument et lit tous les fichiers .xml du dossier #
- # Pour chaque fichier lu, la fonction extrait les rubriques et crée des fichiers de sortie #
- # possédant le nom de la rubrique #
- # #
- ####################################################################################################
- sub extraire_rubrique {
- #lire le nom dossier passé comme argument
- my $path = shift(@_);
- #ouvrir le dossier
- opendir(DIR, $path) or die "can't open $path: $!\n";
- #lire la liste de fichier du dossier
- my @files = readdir(DIR);
- closedir(DIR);
- # lire un à un les items du dossier
- foreach my $file (@files)
- {
- # ignorer les items cachés
- next if $file =~ /^\.\.?$/;
- # construire le chemin complet avec le nom du dossier + item traité
- $file = $path."/".$file;
- # vérifier si l'item est un dossier
- if (-d $file)
- {
- # si l'item qu'on est en train de traiter est un dossier, on recommence la procédure
- &extraire_rubrique($file);
- }
- # vérifier si l'item est un fichier - IF1
- if (-f $file)
- {
- # tester si fichier possède l'extension .xml et ne contient pas la substring fil dans le nom - IF2
- if (($file =~ /\.xml$/) && ($file!~/\/fil.+\.xml$/))
- {
- #ouvrir fichier .xml
- open(FILE,$file);
- #variable pour stocker le contenu du fichier .xml
- my $texte="";
- #lire toutes les lignes du fichier .xml
- while (my $ligne=<FILE>)
- {
- # effacer les retours à la ligne
- chomp $ligne;
- # stocker le contenu de ligne lue
- $texte .= $ligne;
- }
- # fermer le fichier .xml
- close(FILE);
- # regex pour capture l`encodage du fichier
- $texte =~ /encoding ?= ?[\'\"]([^\'\"]+)[\'\"]/i;
- # stocker le contenu trouvé par la regex
- my $encodage=$1;
- # vérifier la contenu de regex n'est pas vide IF3
- if ($encodage ne "")
- {
- # reouvrir le fichier avec l'encogade correcte
- open(FILE,"<:encoding($encodage)", $file);
- # variables pour stocker le contenu du fichier lu
- $texte="";
- # lire le fichier .xml
- while (my $ligne=<FILE>)
- {
- # effacer les retours à la ligne
- chomp $ligne;
- # stocker le contenu de ligne lue
- $texte .= $ligne;
- }
- # fermer le fichier .xml
- close(FILE);
- # effacer les espaces en blanc
- $texte =~ s/> *</></g;
- # capturer le contenu à l'intérieur des balises <title> - IF4
- if ($texte=~ /<channel><title>([^>]+)<\/title>/)
- {
- print $texte;
- # stocker la valeur de rubrique trouvée par la regex
- my $rub=$1;
- # nettoyer les noms des rubriques
- $rub =~ s/Toute l'actualité sur Le Monde.fr.//gi;
- $rub =~ s/é/e/gi;
- $rub =~ s/è/e/gi;
- $rub =~ s/ê/e/gi;
- $rub =~ s/à/a/gi;
- $rub =~ s/Le ?Monde.fr ?://;
- $rub =~ s/ //g;
- $rub=uc($rub);
- # stocker la rubrique dans le dictionnaire des rubriques
- $dictionnairesdesrubriques{$rub}++;
- } # fin IF4
- } # fin IF3
- } # fin IF2
- } # fin IF1
- } # fin FOR
- } # fin extraire_rubrique()
#/usr/bin/perl
use Unicode::String qw(utf8);
use XML::Entities;
use HTML::Entities;
use XML::RSS;
#lire l'entrée standard
my $rep="$ARGV[0]";
# éliminier les possibles "/" à la fin du nom du dossier
$rep=~ s/[\/]$//;
# liste pour stocker les items déjà traités
my %dictionnairedesitems = ();
# liste pour stocker les rubriques déjà traités
my %dictionnairesdesrubriques = ();
# appeler la fonction extraire_rubrique() pour lire les dossiers et extraire les rubriques des fichiers
&extraire_rubrique($rep);
my @liste_rubriques = keys(%dictionnairesdesrubriques);
# pour chaque rubrique, créer un fichier de sortie .xml et un fichier .txt
foreach my $rub (@liste_rubriques) {
my $output1= "SORTIE-extract-txt-".$rub.".xml";
my $output2= "SORTIE-extract-txt-".$rub.".txt";
# créer fichier .xml de sortie
open (FILEOUTXML, ">:encoding(utf-8)", $output1) or die "Could not open file @output1!"; # open file for writing
# créer fichier .txt de sortie
open (FILEOUTTXT, ">:encoding(utf-8)", $output2) or die "Could not open file $output2!"; # open file for writing)
# écrier déclaration d'en-tête du fichier xml
print FILEOUTXML "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print FILEOUTXML "<PARCOURS>\n";
#fermer les deux fichiers
close(FILEOUTXML);
close(FILEOUTTXT);
print $output1;
}
# appeler lire_et_ecrire_xml() pour lire tous les fichiers xml et créer les sorties
&lire_et_ecrire_xml($rep);
foreach my $rub (@liste_rubriques)
{
my $output1="SORTIE-extract-txt-".$rub.".xml";
if (!open (FILEOUTXML,">>:encoding(utf-8)", $output1))
{
die "Pb a l'ouverture du fichier $output1";
}
print FILEOUTXML "</PARCOURS>\n";
close(FILEOUTXML);
}
exit;
#########################################################################################################
# #
# cette fonction reçoit un nom de dossier comme argument et lit tous les fichiers .xml du dossier #
# Pour chaque fichier lu, la fonction extrait le texte des balises <title> et <description>, ainsi que #
# les dates présentes entre <pubDate> et <rubrique> #
# Ce contenu insère dans des fichiers de sortie .xml et .txt la rubrique correspondante #
# #
#########################################################################################################
sub lire_et_ecrire_xml {
# lire nom de dossier passé comme argument
my $path = shift(@_);
# ouvrir dossier
opendir(DIR, $path) or die "can't open $path: $!\n";
# lire items dans le dossier
my @files = readdir(DIR);
closedir(DIR);
# fermer dossier
foreach my $file (@files)
{
# ignorer les items cachés
next if $file =~ /^\.\.?$/;
# construire le chemin complet avec le nom du dossier + item traité
$file = $path."/".$file;
# vérifier si l'item traité est un dossier
if (-d $file)
{
# si l'item qu'on est en train de traiter est un dossier, on recommence la procédure
&lire_et_ecrire_xml($file);
}
# vérifier si l'item traité un fichier IF1
if (-f $file)
{
# vérifier s'il s'agit d'un fichier .xml qui ne contient pas fil dans le nom iF2
if (($file=~/\.xml$/) && ($file!~/\/fil.+\.xml$/))
{
# ouvrir fichier
open(FILE, $file);
# variable pour stocker le contenu du fichier
my $texte="";
#lire le contenu du fichier ligne à line
while (my $ligne=<FILE>)
{
chomp $ligne;
$texte .= $ligne;
}
# fermer fichier
close(FILE);
# regex pour capturer l'encodage du fichier
$texte=~/encoding ?= ?[\'\"]([^\'\"]+)[\'\"]/i;
# stocker l'encodage du fichier
my $encodage=$1;
# vérifier si l'encodage n'est pas vide pour traiter le contenu IF3
if ($encodage ne "")
{
# la variable tmptexteXML stocke les contenus prêts à être écrits dans fichier .xml de sortie
my $tmptexteXML="<file>\n";
# créer balise avec le nom du fichier
$tmptexteXML.="<name>$file</name>\n";
# éliminier les balises avec des espaces en blanc
$texte =~ s/> *</></g;
# regex pour capturer date
$texte=~/<pubDate>([^<]+)<\/pubDate>/;
# stocker la valeur de date capturée par la regex
$tmptexteXML.="<date>$1</date>\n";
# insérer la balise <items>
$tmptexteXML.="<items>\n";
my $tmptexteBRUT="";
open(FILE,"<:encoding($encodage)", $file);
$texte="";
# lire le fichier ligne à ligne
while (my $ligne=<FILE>)
{
chomp $ligne;
$texte .= $ligne;
}
close(FILE);
$texte=~s/> *</></g;
# on recherche la rubrique
$texte=~/<channel><title>([^<]+)<\/title>/;
# on met le contenu trouvé par la regex dans $rub
my $rub=$1;
# nettoyer le string rubrique
$rub =~ s/Toute l'actualité sur Le Monde.fr.//gi;
$rub =~ s/é/e/gi;
$rub =~ s/è/e/gi;
$rub =~ s/ê/e/gi;
$rub =~ s/à/a/gi;
$rub =~ s/Le ?Monde.fr ?://;
$rub =~ s/ //g;
$rub=uc($rub);
my $output1="SORTIE-extract-txt-".$rub.".xml";
my $output2="SORTIE-extract-txt-".$rub.".txt";
if (!open (FILEOUTXML,">>:encoding(utf-8)", $output1)) { die "Pb a l'ouverture du fichier $output1"};
if (!open (FILEOUTTXT,">>:encoding(utf-8)", $output2)) { die "Pb a l'ouverture du fichier $output2"};
# lire texte pour extraire contenu des balises <title> et <description>
while ($texte =~ /<item><title>(.+?)<\/title>.+?<description>(.+?)<\/description>/g)
{
# capturer contenu de la regex pour titre
my $titre=$1;
# capturer contenu de la regex pour description
my $resume=$2;
# utilisation des modules pour remplacer dans les fichiers les entités XML et HTML
if (!(exists ($dictionnairedesitems{$titre})) and !(exists ($dictionnairedesitems{$resume})))
{
$dictionnairedesitems{$titre}++;
$dictionnairedesitems{$resume}++;
$titre = XML::Entities::decode('all', $titre);
$resume = XML::Entities::decode('all', $resume);
$titre = HTML::Entities::decode($titre);
$resume = HTML::Entities::decode($resume);
$tmptexteBRUT.="$titre \n";
$tmptexteBRUT.="$resume \n";
$tmptexteXML.="<item><title>$titre</title><description>$resume</description></item>\n";
# nettoyage des balises <description> pour supprimer les balises superflues
$tmptexteXML =~ s/<img.*?\/><\/description>/<\/description>/g;
$tmptexteBRUT =~ s/<img.*?\/> \n/\n/g;
}
# si le fichier n'est pas en UTF-8, convertir le string $titre et $resume en UTF-8
if (uc($encodage) ne "UTF-8")
{
utf8($titre);
utf8($resume);
}
} # fin while
# rajouter la fin des balises <items> et <file>
$tmptexteXML.="</items>\n</file>\n";
# écrire contenu dans le fichier .xml
print FILEOUTXML $tmptexteXML;
# écrire contenu dans le fichier .txt
print FILEOUTTXT $tmptexteBRUT;
# fermer fichiers
close FILEOUTXML;
close FILEOUTTXT;
} else {
#si l'encodage est vide afficher message
print "$file ==> $encodage \n";
} # fin IF3
} # fin IF 2
} # fin IF 1
} # fin FOR
} # fin lire_et_ecrire_xml()
####################################################################################################
# #
# cette fonction reçoit un nom de dossier comme argument et lit tous les fichiers .xml du dossier #
# Pour chaque fichier lu, la fonction extrait les rubriques et crée des fichiers de sortie #
# possédant le nom de la rubrique #
# #
####################################################################################################
sub extraire_rubrique {
#lire le nom dossier passé comme argument
my $path = shift(@_);
#ouvrir le dossier
opendir(DIR, $path) or die "can't open $path: $!\n";
#lire la liste de fichier du dossier
my @files = readdir(DIR);
closedir(DIR);
# lire un à un les items du dossier
foreach my $file (@files)
{
# ignorer les items cachés
next if $file =~ /^\.\.?$/;
# construire le chemin complet avec le nom du dossier + item traité
$file = $path."/".$file;
# vérifier si l'item est un dossier
if (-d $file)
{
# si l'item qu'on est en train de traiter est un dossier, on recommence la procédure
&extraire_rubrique($file);
}
# vérifier si l'item est un fichier - IF1
if (-f $file)
{
# tester si fichier possède l'extension .xml et ne contient pas la substring fil dans le nom - IF2
if (($file =~ /\.xml$/) && ($file!~/\/fil.+\.xml$/))
{
#ouvrir fichier .xml
open(FILE,$file);
#variable pour stocker le contenu du fichier .xml
my $texte="";
#lire toutes les lignes du fichier .xml
while (my $ligne=<FILE>)
{
# effacer les retours à la ligne
chomp $ligne;
# stocker le contenu de ligne lue
$texte .= $ligne;
}
# fermer le fichier .xml
close(FILE);
# regex pour capture l`encodage du fichier
$texte =~ /encoding ?= ?[\'\"]([^\'\"]+)[\'\"]/i;
# stocker le contenu trouvé par la regex
my $encodage=$1;
# vérifier la contenu de regex n'est pas vide IF3
if ($encodage ne "")
{
# reouvrir le fichier avec l'encogade correcte
open(FILE,"<:encoding($encodage)", $file);
# variables pour stocker le contenu du fichier lu
$texte="";
# lire le fichier .xml
while (my $ligne=<FILE>)
{
# effacer les retours à la ligne
chomp $ligne;
# stocker le contenu de ligne lue
$texte .= $ligne;
}
# fermer le fichier .xml
close(FILE);
# effacer les espaces en blanc
$texte =~ s/> *</></g;
# capturer le contenu à l'intérieur des balises <title> - IF4
if ($texte=~ /<channel><title>([^>]+)<\/title>/)
{
print $texte;
# stocker la valeur de rubrique trouvée par la regex
my $rub=$1;
# nettoyer les noms des rubriques
$rub =~ s/Toute l'actualité sur Le Monde.fr.//gi;
$rub =~ s/é/e/gi;
$rub =~ s/è/e/gi;
$rub =~ s/ê/e/gi;
$rub =~ s/à/a/gi;
$rub =~ s/Le ?Monde.fr ?://;
$rub =~ s/ //g;
$rub=uc($rub);
# stocker la rubrique dans le dictionnaire des rubriques
$dictionnairesdesrubriques{$rub}++;
} # fin IF4
} # fin IF3
} # fin IF2
} # fin IF1
} # fin FOR
} # fin extraire_rubrique()
Un aperçu de nos résultats de l'Outil 1
Voilà ce à quoi ressemble nos données une fois que nous avons remplacé les caractères spéciaux. Remarquez les caractères accentués et aussi les balises images non présentes ici !
Un aperçu de notre sortie XML.

Pour que nos résultats soient plus faciles à visionner, nous avons joint le fichier XML à une feuille de styles XSL que vous trouverez ici.
Voici à quoi ressemble notre sortie XML quand nous la joignons à une feuille de styles XSL.

La sortie texte brut contient juste du texte brut. Avoir une sortie qui ne contient que cela est utile pour la prochaine étape où nous utilisons les programmes d'étiquetage Cordial et TreeTagger pour ajouter de l'information.
Un aperçu de notre sortie TXT.
Que fait l'Outil 2 ?
L'Outil 2 est un programme qui ajoute à l'Outil 1 le texte contenu dans les balises <title> et <description> à travers deux annotateurs, TreeTagger et Cordial.
Le programme donne plusieurs sorties différentes qui peuvent être divisées en deux groupes principaux : le premier est la même sortie que l'Outil 1, des fichiers en texte brut pour chaque catégorie et la sortie XML. L'autre groupe est la sortie TreeTagger au format XML. Cette sortie est organisée par ligne et mot. Chaque mot de la ligne est associé à son étiquette part-of-speech et à son lemme.
Nous avons également décidé de créer des fichiers globaux qui contiennent tous les fichiers séparés par catégorie en les concaténant (autrement dit, tous les fichiers).
L'étape suivante de l'Outil 2 est faite manuellement. Chaque fichier texte brut est converti en ISO-8859-15 (Latin 9) pour être compatible avec Cordial. Le "œ" a aussi besoin d'être remplacé par "oe" comme le caractère n'est pas supporté dans la version de Cordial que nous utilisons.
La sortie Cordial est un fichier qui, quand on l'ouvre dans un éditeur de texte, révèle trois colonnes de mots, de part-of-speech et de lemmes. Pour voir un exemple, veuillez consulter notre page page "Résultats".
TreeTagger est un logiciel gratuit développé par Helmut Schmid et qui peut être téléchargé ici. Normalement, il peut être utilisé pour tagger des textes en allemand, anglais, français, italien, espagnol, bulgare, russe, portugais, galicien, chinois, swahili, slovaque, latin, estonien, polonais et vieux français.
Cordial est un logiciel payant qui contient énormément d'outils linguistiques comme un dictionnaire ou un traducteur. Cordial a beaucoup plus de fonctionnalités mais est limité en terme de langages disponibles pour le POS tagging. En général, on trouve que les résultats sont plus précis que ceux de TreeTagger. On peut le constater ici.
La méthode du professeur
Cette version ne correspond pas vraiment à du "Pure Perl" car on y utilise un module ("Unicode::String") pour convertir les fichiers en utf-8. Voici la version vue en cours que nous avons essayé d'améliorer à travers nos pages de résultats.
- #/usr/bin/perl
- use Unicode::String qw(utf8);
- #-----------------------------------------------------------
- my $rep="$ARGV[0]";
- # on s'assure que le nom du répertoire ne se termine pas par un "/"
- $rep=~ s/[\/]$//;
- # on initialise une variable contenant le flux de sortie
- my %dictionnairedesitems=();
- my %dictionnairesdesrubriques=();
- #----------------------------------------
- &parcoursarborescencefichierspourrepererlesrubriques($rep); # on recupere les rubriques...
- #----------------------------------------
- my @liste_rubriques = keys(%dictionnairesdesrubriques);
- foreach my $rub (@liste_rubriques) {
- print $rub,"\n";
- #----------------------------------------
- my $output1="SORTIE/SORTIE-extract-txt-".$rub.".xml";
- my $output2="SORTIE/SORTIE-extract-txt-".$rub.".txt";
- my $output3="SORTIE/SORTIE-extract-txt-".$rub."-treetagger.xml";
- if (!open (FILEOUT1,">:encoding(utf-8)", $output1)) { die "Pb a l'ouverture du fichier $output1"};
- if (!open (FILEOUT2,">:encoding(utf-8)",$output2)) { die "Pb a l'ouverture du fichier $output2"};
- if (!open (FILEOUT3,">:encoding(utf-8)",$output3)) { die "Pb a l'ouverture du fichier $output3"};
- print FILEOUT1 "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
- print FILEOUT1 "<PARCOURS>\n";
- print FILEOUT3 "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
- print FILEOUT3 "<PARCOURS>\n";
- close(FILEOUT1);
- close(FILEOUT2);
- close(FILEOUT3);
- }
- #----------------------------------------
- &parcoursarborescencefichiers($rep); # on traite tous les fichiers
- #----------------------------------------
- foreach my $rub (@liste_rubriques) {
- my $output1="SORTIE/SORTIE-extract-txt-".$rub.".xml";
- my $output3="SORTIE/SORTIE-extract-txt-".$rub."-treetagger.xml";
- if (!open (FILEOUT1,">>:encoding(utf-8)", $output1)) { die "Pb a l'ouverture du fichier $output1"};
- if (!open (FILEOUT3,">>:encoding(utf-8)",$output3)) { die "Pb a l'ouverture du fichier $output3"};
- print FILEOUT1 "</PARCOURS>\n";
- print FILEOUT3 "</PARCOURS>\n";
- close(FILEOUT1);
- close(FILEOUT3);
- }
- exit;
- #----------------------------------------------
- #----------------------------------------------
- sub parcoursarborescencefichiers {
- my $path = shift(@_);
- opendir(DIR, $path) or die "can't open $path: $!\n";
- my @files = readdir(DIR);
- closedir(DIR);
- foreach my $file (@files) {
- next if $file =~ /^\.\.?$/;
- $file = $path."/".$file;
- if (-d $file) {
- &parcoursarborescencefichiers($file); #recurse!
- }
- if (-f $file) {
- if (($file=~/\.xml$/) && ($file!~/\/fil.+\.xml$/)) {
- open(FILE, $file);
- #print "Traitement de :\n$file\n";
- my $texte="";
- while (my $ligne=<FILE>) {
- $ligne =~ s/\n//g;
- $texte .= $ligne;
- }
- close(FILE);
- $texte=~/encoding ?= ?[\'\"]([^\'\"]+)[\'\"]/i;
- my $encodage=$1;
- #print "ENCODAGE : $encodage \n";
- if ($encodage ne "") {
- print "Extraction dans : $file \n";
- my $tmptexteXML="<file>\n";
- $tmptexteXML.="<name>$file</name>\n";
- my $tmptexteXMLtagger="<file>\n";
- $tmptexteXMLtagger.="<name>$file</name>\n";
- $texte =~ s/> *</></g;
- $texte=~/<pubDate>([^<]+)<\/pubDate>/;
- $tmptexteXML.="<date>$1</date>\n";
- $tmptexteXML.="<items>\n";
- $tmptexteXMLtagger.="<date>$1</date>\n";
- $tmptexteXMLtagger.="<items>\n";
- my $tmptexteBRUT="";
- open(FILE,"<:encoding($encodage)", $file);
- #print "Traitement de :\n$file\n";
- $texte="";
- while (my $ligne=<FILE>) {
- $ligne =~ s/\n//g;
- $texte .= $ligne;
- }
- close(FILE);
- $texte=~s/> *</></g;
- # on recherche la rubrique
- $texte=~/<channel><title>([^<]+)<\/title>/;
- my $rub=$1;
- $rub=~s/é/e/gi;
- $rub=~s/è/e/gi;
- $rub=~s/ê/e/gi;
- $rub=~s/à/a/gi;
- $rub=~ s/Le *Monde *\. *fr *://gi;
- $rub=~ s/ //g;
- $rub=~ s/s$//;
- $rub=uc($rub);
- #print $rub,"\n";
- #----------------------------------------
- my $output1="SORTIE/SORTIE-extract-txt-".$rub.".xml";
- my $output2="SORTIE/SORTIE-extract-txt-".$rub.".txt";
- my $output3="SORTIE/SORTIE-extract-txt-".$rub."-treetagger.xml";
- if (!open (FILEOUT1,">>:encoding(utf-8)", $output1)) { die "Pb a l'ouverture du fichier $output1"};
- if (!open (FILEOUT2,">>:encoding(utf-8)", $output2)) { die "Pb a l'ouverture du fichier $output2"};
- if (!open (FILEOUT3,">>:encoding(utf-8)", $output3)) { die "Pb a l'ouverture du fichier $output3"};
- #----------------------------------------
- my $compteurItem=0;
- my $compteurEtiquetage=0;
- while ($texte =~ /<item><title>(.+?)<\/title>.+?<description>(.+?)<\/description>/g) {
- my $titre=$1;
- my $resume=$2;
- #print "T : $titre \n R : $resume \n";
- if (uc($encodage) ne "UTF-8") {utf8($titre);utf8($resume);}
- $titre = &nettoietexte($1);
- $resume = &nettoietexte($2);
- $compteurItem++;
- if (!(exists($dictionnairedesitems{$resume}))) {
- $compteurEtiquetage++;
- print "Etiquetage (num : $compteurEtiquetage) sur item (num : $compteurItem) \n";
- my ($titreetiquete,$texteetiquete)=&etiquetageavectreetagger($titre,$resume);
- $tmptexteBRUT.="§ $titre \n";
- $tmptexteBRUT.="$resume \n";
- $tmptexteXML.="<item><title>$titre</title><abstract>$resume</abstract></item>\n";
- $tmptexteXMLtagger.="<item>\n<title>\n$titreetiquete</title>\n<abstract>\n$texteetiquete</abstract>\n</item>\n";
- $dictionnairedesitems{$resume}++;
- }
- else {
- $tmptexteXML.="<item><title>-</title><abstract>-</abstract></item>\n";
- }
- }
- $tmptexteXML.="</items>\n</file>\n";
- $tmptexteXMLtagger.="</items>\n</file>\n";
- print FILEOUT1 $tmptexteXML;
- print FILEOUT2 $tmptexteBRUT;
- print FILEOUT3 $tmptexteXMLtagger;
- close FILEOUT1;
- close FILEOUT2;
- close FILEOUT3;
- }
- else {
- print "$file ==> $encodage \n";
- }
- }
- }
- }
- }
- #----------------------------------------------------
- sub nettoietexte {
- my $texte=shift;
- $texte =~ s/</</g;
- $texte =~ s/>/>/g;
- $texte =~ s/<a href[^>]+>//g;
- $texte =~ s/<img[^>]+>//g;
- $texte =~ s/<\/a>//g;
- $texte =~ s/&#39;/'/g;
- $texte =~ s/&#34;/"/g;
- $texte =~ s/é/é/g;
- $texte =~ s/ê/ê/g;
- $texte =~ s/<[^>]+>//g;
- $texte =~ s/ / /g;
- $texte=~s/'/'/g;
- $texte=~s/"/"/g;
- $texte=~s/&#39;/'/g;
- $texte=~s/&#34;/"/g;
- return $texte;
- }
- #-----------------------------------------------------------------------------------
- sub parcoursarborescencefichierspourrepererlesrubriques {
- my $path = shift(@_);
- opendir(DIR, $path) or die "can't open $path: $!\n";
- my @files = readdir(DIR);
- closedir(DIR);
- foreach my $file (@files) {
- next if $file =~ /^\.\.?$/;
- $file = $path."/".$file;
- if (-d $file) {
- &parcoursarborescencefichierspourrepererlesrubriques($file); #recurse!
- }
- if (-f $file) {
- if (($file=~/\.xml$/) && ($file!~/\/fil.+\.xml$/)) {
- open(FILE,$file);
- #print "Traitement de :\n$file\n";
- my $texte="";
- while (my $ligne=<FILE>) {
- $ligne =~ s/\n//g;
- $texte .= $ligne;
- }
- close(FILE);
- $texte=~/encoding ?= ?[\'\"]([^\'\"]+)[\'\"]/i;
- my $encodage=$1;
- if ($encodage ne "") {
- open(FILE,"<:encoding($encodage)", $file);
- #print "Traitement de :\n$file\n";
- $texte="";
- while (my $ligne=<FILE>) {
- $ligne =~ s/\n//g;
- $texte .= $ligne;
- }
- close(FILE);
- $texte =~ s/> *</></g;
- if ($texte=~ /<channel><title>([^>]+)<\/title>/) {
- my $rub=$1;
- $rub=~s/é/e/gi;
- $rub=~s/è/e/gi;
- $rub=~s/ê/e/gi;
- $rub=~s/à/a/gi;
- $rub=~ s/Le *Monde *\. *fr *://gi;
- $rub=~ s/ //g;
- $rub=~ s/s$//;
- $rub=uc($rub);
- $dictionnairesdesrubriques{$rub}++;
- }
- }
- else {
- #print "$file ==> $encodage \n";
- }
- }
- }
- }
- }
- sub etiquetageavectreetagger {
- my ($titre,$texte)=@_;
- #----- le titre
- my $codage="utf-8";
- my $tmptag="texteaetiqueter.txt";
- open (TMPFILE,">:encoding(utf-8)", $tmptag);
- print TMPFILE $titre,"\n";
- close(TMPFILE);
- system("perl ./treetagger-win32/cmd/tokenise-fr.pl $tmptag | tree-tagger.exe ./treetagger-win32/lib/french-utf8.par -lemma -token -no-unknown -sgml > treetagger.txt");
- system("perl ./treetagger-win32/cmd/treetagger2xml-utf8.pl treetagger.txt $codage ");
- # lecture du resultat tagge en xml :
- open(OUT,"<:encoding(utf-8)","treetagger.txt.xml");
- my $fistline=<OUT>;
- my $titreetiquete="";
- while (my $l=<OUT>) {
- $titreetiquete.=$l;
- }
- close(OUT);
- #----- le resume
- open (TMPFILE,">:encoding(utf-8)", $tmptag);
- print TMPFILE $texte,"\n";
- close(TMPFILE);
- system("perl ./treetagger-win32/cmd/tokenise-fr.pl $tmptag | tree-tagger.exe ./treetagger-win32/lib/french-utf8.par -lemma -token -no-unknown -sgml > treetagger.txt");
- system("perl ./treetagger-win32/cmd/treetagger2xml-utf8.pl treetagger.txt $codage");
- # lecture du resultat tagge en xml :
- open(OUT,"<:encoding(utf-8)","treetagger.txt.xml");
- my $fistline=<OUT>;
- my $texteetiquete="";
- while (my $l=<OUT>) {
- $texteetiquete.=$l;
- }
- close(OUT);
- # on renvoie les resultats :
- return ($titreetiquete,$texteetiquete);
- }
#/usr/bin/perl
use Unicode::String qw(utf8);
#-----------------------------------------------------------
my $rep="$ARGV[0]";
# on s'assure que le nom du répertoire ne se termine pas par un "/"
$rep=~ s/[\/]$//;
# on initialise une variable contenant le flux de sortie
my %dictionnairedesitems=();
my %dictionnairesdesrubriques=();
#----------------------------------------
&parcoursarborescencefichierspourrepererlesrubriques($rep); # on recupere les rubriques...
#----------------------------------------
my @liste_rubriques = keys(%dictionnairesdesrubriques);
foreach my $rub (@liste_rubriques) {
print $rub,"\n";
#----------------------------------------
my $output1="SORTIE/SORTIE-extract-txt-".$rub.".xml";
my $output2="SORTIE/SORTIE-extract-txt-".$rub.".txt";
my $output3="SORTIE/SORTIE-extract-txt-".$rub."-treetagger.xml";
if (!open (FILEOUT1,">:encoding(utf-8)", $output1)) { die "Pb a l'ouverture du fichier $output1"};
if (!open (FILEOUT2,">:encoding(utf-8)",$output2)) { die "Pb a l'ouverture du fichier $output2"};
if (!open (FILEOUT3,">:encoding(utf-8)",$output3)) { die "Pb a l'ouverture du fichier $output3"};
print FILEOUT1 "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print FILEOUT1 "<PARCOURS>\n";
print FILEOUT3 "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print FILEOUT3 "<PARCOURS>\n";
close(FILEOUT1);
close(FILEOUT2);
close(FILEOUT3);
}
#----------------------------------------
&parcoursarborescencefichiers($rep); # on traite tous les fichiers
#----------------------------------------
foreach my $rub (@liste_rubriques) {
my $output1="SORTIE/SORTIE-extract-txt-".$rub.".xml";
my $output3="SORTIE/SORTIE-extract-txt-".$rub."-treetagger.xml";
if (!open (FILEOUT1,">>:encoding(utf-8)", $output1)) { die "Pb a l'ouverture du fichier $output1"};
if (!open (FILEOUT3,">>:encoding(utf-8)",$output3)) { die "Pb a l'ouverture du fichier $output3"};
print FILEOUT1 "</PARCOURS>\n";
print FILEOUT3 "</PARCOURS>\n";
close(FILEOUT1);
close(FILEOUT3);
}
exit;
#----------------------------------------------
#----------------------------------------------
sub parcoursarborescencefichiers {
my $path = shift(@_);
opendir(DIR, $path) or die "can't open $path: $!\n";
my @files = readdir(DIR);
closedir(DIR);
foreach my $file (@files) {
next if $file =~ /^\.\.?$/;
$file = $path."/".$file;
if (-d $file) {
&parcoursarborescencefichiers($file); #recurse!
}
if (-f $file) {
if (($file=~/\.xml$/) && ($file!~/\/fil.+\.xml$/)) {
open(FILE, $file);
#print "Traitement de :\n$file\n";
my $texte="";
while (my $ligne=<FILE>) {
$ligne =~ s/\n//g;
$texte .= $ligne;
}
close(FILE);
$texte=~/encoding ?= ?[\'\"]([^\'\"]+)[\'\"]/i;
my $encodage=$1;
#print "ENCODAGE : $encodage \n";
if ($encodage ne "") {
print "Extraction dans : $file \n";
my $tmptexteXML="<file>\n";
$tmptexteXML.="<name>$file</name>\n";
my $tmptexteXMLtagger="<file>\n";
$tmptexteXMLtagger.="<name>$file</name>\n";
$texte =~ s/> *</></g;
$texte=~/<pubDate>([^<]+)<\/pubDate>/;
$tmptexteXML.="<date>$1</date>\n";
$tmptexteXML.="<items>\n";
$tmptexteXMLtagger.="<date>$1</date>\n";
$tmptexteXMLtagger.="<items>\n";
my $tmptexteBRUT="";
open(FILE,"<:encoding($encodage)", $file);
#print "Traitement de :\n$file\n";
$texte="";
while (my $ligne=<FILE>) {
$ligne =~ s/\n//g;
$texte .= $ligne;
}
close(FILE);
$texte=~s/> *</></g;
# on recherche la rubrique
$texte=~/<channel><title>([^<]+)<\/title>/;
my $rub=$1;
$rub=~s/é/e/gi;
$rub=~s/è/e/gi;
$rub=~s/ê/e/gi;
$rub=~s/à/a/gi;
$rub=~ s/Le *Monde *\. *fr *://gi;
$rub=~ s/ //g;
$rub=~ s/s$//;
$rub=uc($rub);
#print $rub,"\n";
#----------------------------------------
my $output1="SORTIE/SORTIE-extract-txt-".$rub.".xml";
my $output2="SORTIE/SORTIE-extract-txt-".$rub.".txt";
my $output3="SORTIE/SORTIE-extract-txt-".$rub."-treetagger.xml";
if (!open (FILEOUT1,">>:encoding(utf-8)", $output1)) { die "Pb a l'ouverture du fichier $output1"};
if (!open (FILEOUT2,">>:encoding(utf-8)", $output2)) { die "Pb a l'ouverture du fichier $output2"};
if (!open (FILEOUT3,">>:encoding(utf-8)", $output3)) { die "Pb a l'ouverture du fichier $output3"};
#----------------------------------------
my $compteurItem=0;
my $compteurEtiquetage=0;
while ($texte =~ /<item><title>(.+?)<\/title>.+?<description>(.+?)<\/description>/g) {
my $titre=$1;
my $resume=$2;
#print "T : $titre \n R : $resume \n";
if (uc($encodage) ne "UTF-8") {utf8($titre);utf8($resume);}
$titre = &nettoietexte($1);
$resume = &nettoietexte($2);
$compteurItem++;
if (!(exists($dictionnairedesitems{$resume}))) {
$compteurEtiquetage++;
print "Etiquetage (num : $compteurEtiquetage) sur item (num : $compteurItem) \n";
my ($titreetiquete,$texteetiquete)=&etiquetageavectreetagger($titre,$resume);
$tmptexteBRUT.="§ $titre \n";
$tmptexteBRUT.="$resume \n";
$tmptexteXML.="<item><title>$titre</title><abstract>$resume</abstract></item>\n";
$tmptexteXMLtagger.="<item>\n<title>\n$titreetiquete</title>\n<abstract>\n$texteetiquete</abstract>\n</item>\n";
$dictionnairedesitems{$resume}++;
}
else {
$tmptexteXML.="<item><title>-</title><abstract>-</abstract></item>\n";
}
}
$tmptexteXML.="</items>\n</file>\n";
$tmptexteXMLtagger.="</items>\n</file>\n";
print FILEOUT1 $tmptexteXML;
print FILEOUT2 $tmptexteBRUT;
print FILEOUT3 $tmptexteXMLtagger;
close FILEOUT1;
close FILEOUT2;
close FILEOUT3;
}
else {
print "$file ==> $encodage \n";
}
}
}
}
}
#----------------------------------------------------
sub nettoietexte {
my $texte=shift;
$texte =~ s/</</g;
$texte =~ s/>/>/g;
$texte =~ s/<a href[^>]+>//g;
$texte =~ s/<img[^>]+>//g;
$texte =~ s/<\/a>//g;
$texte =~ s/&#39;/'/g;
$texte =~ s/&#34;/"/g;
$texte =~ s/é/é/g;
$texte =~ s/ê/ê/g;
$texte =~ s/<[^>]+>//g;
$texte =~ s/ / /g;
$texte=~s/'/'/g;
$texte=~s/"/"/g;
$texte=~s/&#39;/'/g;
$texte=~s/&#34;/"/g;
return $texte;
}
#-----------------------------------------------------------------------------------
sub parcoursarborescencefichierspourrepererlesrubriques {
my $path = shift(@_);
opendir(DIR, $path) or die "can't open $path: $!\n";
my @files = readdir(DIR);
closedir(DIR);
foreach my $file (@files) {
next if $file =~ /^\.\.?$/;
$file = $path."/".$file;
if (-d $file) {
&parcoursarborescencefichierspourrepererlesrubriques($file); #recurse!
}
if (-f $file) {
if (($file=~/\.xml$/) && ($file!~/\/fil.+\.xml$/)) {
open(FILE,$file);
#print "Traitement de :\n$file\n";
my $texte="";
while (my $ligne=<FILE>) {
$ligne =~ s/\n//g;
$texte .= $ligne;
}
close(FILE);
$texte=~/encoding ?= ?[\'\"]([^\'\"]+)[\'\"]/i;
my $encodage=$1;
if ($encodage ne "") {
open(FILE,"<:encoding($encodage)", $file);
#print "Traitement de :\n$file\n";
$texte="";
while (my $ligne=<FILE>) {
$ligne =~ s/\n//g;
$texte .= $ligne;
}
close(FILE);
$texte =~ s/> *</></g;
if ($texte=~ /<channel><title>([^>]+)<\/title>/) {
my $rub=$1;
$rub=~s/é/e/gi;
$rub=~s/è/e/gi;
$rub=~s/ê/e/gi;
$rub=~s/à/a/gi;
$rub=~ s/Le *Monde *\. *fr *://gi;
$rub=~ s/ //g;
$rub=~ s/s$//;
$rub=uc($rub);
$dictionnairesdesrubriques{$rub}++;
}
}
else {
#print "$file ==> $encodage \n";
}
}
}
}
}
sub etiquetageavectreetagger {
my ($titre,$texte)=@_;
#----- le titre
my $codage="utf-8";
my $tmptag="texteaetiqueter.txt";
open (TMPFILE,">:encoding(utf-8)", $tmptag);
print TMPFILE $titre,"\n";
close(TMPFILE);
system("perl ./treetagger-win32/cmd/tokenise-fr.pl $tmptag | tree-tagger.exe ./treetagger-win32/lib/french-utf8.par -lemma -token -no-unknown -sgml > treetagger.txt");
system("perl ./treetagger-win32/cmd/treetagger2xml-utf8.pl treetagger.txt $codage ");
# lecture du resultat tagge en xml :
open(OUT,"<:encoding(utf-8)","treetagger.txt.xml");
my $fistline=<OUT>;
my $titreetiquete="";
while (my $l=<OUT>) {
$titreetiquete.=$l;
}
close(OUT);
#----- le resume
open (TMPFILE,">:encoding(utf-8)", $tmptag);
print TMPFILE $texte,"\n";
close(TMPFILE);
system("perl ./treetagger-win32/cmd/tokenise-fr.pl $tmptag | tree-tagger.exe ./treetagger-win32/lib/french-utf8.par -lemma -token -no-unknown -sgml > treetagger.txt");
system("perl ./treetagger-win32/cmd/treetagger2xml-utf8.pl treetagger.txt $codage");
# lecture du resultat tagge en xml :
open(OUT,"<:encoding(utf-8)","treetagger.txt.xml");
my $fistline=<OUT>;
my $texteetiquete="";
while (my $l=<OUT>) {
$texteetiquete.=$l;
}
close(OUT);
# on renvoie les resultats :
return ($titreetiquete,$texteetiquete);
}
Outil 2 & Outil 3 & Outil 4
Un bonus dans cette section était d'utiliser un outil d'analyse textométrique appelé Le Trameur pour étiqueter le texte en utilisant TreeTagger qui est déjà intégré, d'extraire les séquences morphosyntaxiques et ensuite visualiser les résultats à travers une série de graphes.Cet outil permet donc de remplacer l'Outil 2, 3 et 4.
Ne travaillant pas sous Windows, nous avons trouvé un moyen d'utiliser quand même Le Trameur, (Wine), mais certaines fonctionnalités ne marchents pas aussi bien que si nous étions sous Windows. TreeTagger est une de ces fonctions alors cette étape bonue n'a pas pu être complétée.

Vous trouverez une description complète des différentes fonctionnalités du Trameur surcette page.
Pure Perl
Comme nous l'avons déjà indiqué précédemment, notre version "Pure Perl" consiste à ne pas utiliser de modules Perl dans notre programme. Nous avons donc effectué nous-mêmes toutes les procédures nécessaires au bon fonctionnement du script.
Pour les entités, nous avons créé une procédure de nettoyage qui change toutes les entités par leur équivalent. Nous avons dû les énumérer une à une afin d'avoir la liste la plus complète possible. Nous avons appelé cette procédure "nettoyerTexte". Nous avons également procédé à un autre nettoyage pour les rubriques, mais cette fois-ci, ce ne sont pas des entités mais des caractères accentués qu'on change pour des non-accentués afin d'avoir des noms de fichiers sans accent et pas de ponctuation non plus ou d'URL.
Pour la création de nos sorties, nous n'utilisons pas non plus le module XML::RSS, nous avons créé nous-mêmes nos propres sorties TXT et XML.
Contrairement à la version faite en cours, nous avons crée un répertoire de sortie qui lui-même est séparé en deux répertoires dont l'un rassemble les fichiers étiquetés par TreeTagger en un fichier global XML et l'autre qui rassemble tous les titres et descriptions en un fichier TXT. On utilise la récursivité de la procédure "parcoursarborescencefichiers" pour récupérer les données souhaitées.
- #!/usr/bin/perl
- <<DOC;
- Votre Nom : Bienvenue, Poadey, Cavalcante
- MARS 2015
- usage : perl parcours-arborescence-fichiers repertoire-a-parcourir
- Le programme prend en entrée le nom du répertoire contenant les fichiers
- à traiter
- Le programme construit en sortie des fichiers structurés : en format XML
- et en format TXT
- DOC
- use Unicode::String qw(utf8);
- use utf8;
- # pour pouvoir afficher la date
- use Time::localtime;
- #------------------------------------------------------------------------------
- # des compteurs pour le nombre des items
- my $nb_filesIN = 0;
- my $nb_itemsIN = 0;
- my $nb_itemsOUT = 0;
- #------------------------------------------------------------------------------
- # le répertoire d'entrée
- my $rep = "$ARGV[0]";
- # enlever le slash à la fin du répertoire
- $rep =~ s/[\/]$//;
- #------------------------------------------------------------------------------
- # des hash tables pour vérifier qu'on n'a pas deux fois les même infos
- my %dico_titre = ();
- my %dico_description = ();
- # cet hash nous permet de juste traiter une fois chaque texte
- my %dico_files = ();
- # creer l`objet date pour ecrire les dates dans le log
- my $date_time = ctime();
- #------------------------------------------------------------------------------
- # creation des dossiers de sortie
- my $res = "./Sorties/";
- if (! -e $res) {
- mkdir($res) or die ("Problème avec la création du répertoire de $rep : $!");
- }
- $res = "./Sorties/Sorties_PurePerl/";
- if (! -e $res) {
- mkdir($res) or die ("Problème avec la création du répertoire de $rep : $!\n");
- }
- #------------------------------------------------------------------------------
- # sorties etiquetées
- my $resBAO2 = "./Sorties/Sorties_Tagged/";
- if (! -e $resBAO2) {
- mkdir($resBAO2) or die ("Problème avec la création du répertoire de $rep : $!\n");
- }
- #------------------------------------------------------------------------------
- # sortie globale txt
- open(FILEGLOBALTXT,">:encoding(UTF-8)", $res."SortieGlobale1.txt");
- #------------------------------------------------------------------------------
- &parcoursarborescencefichiers($rep); #recurse!
- #------------------------------------------------------------------------------
- close FILEGLOBALTXT;
- #------------------------------------------------------------------------------
- # création de la sortie globale xml
- open(FILEGLOBALXML, ">:encoding(UTF-8)", $res."SortieGlobale1.xml");
- print FILEGLOBALXML "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
- print FILEGLOBALXML "<PARCOURS>\n";
- print FILEGLOBALXML "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
- print FILEGLOBALXML "<FILTRAGE>";
- #------------------------------------------------------------------------------
- # écrire contenu de la sortie globale xml
- opendir(DIR, $res) or die "Erreur d'ouverture du repertoire: $!\n";
- my @sorties = readdir(DIR);
- closedir(DIR);
- foreach my $sortie (@sorties) {
- if ($sortie=~/(.+?)\.xml$/ && $1 != "SortieGlobale1") {
- my $rub=$1;
- open(FILE,">>:encoding(UTF-8)", $res.$sortie);
- print FILE "</".$rub.">\n";;
- print FILE "</PARCOURS>\n";
- close(FILE);
- print FILEGLOBALXML "<$rub>\n";
- print FILEGLOBALXML ${"DumpXML".$rub};
- print FILEGLOBALXML "</$rub>";
- }
- }
- print FILEGLOBALXML "</FILTRAGE>\n";
- print FILEGLOBALXML "</PARCOURS>\n";
- close(FILEGLOBALXML);
- #------------------------------------------------------------------------------
- open(FILEGLOBALXML, ">:encoding(UTF-8)", $resBAO2."SortieGlobale2.xml");
- print FILEGLOBALXML "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
- print FILEGLOBALXML "<PARCOURS>\n";
- print FILEGLOBALXML "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
- print FILEGLOBALXML "<FILTRAGE>";
- #------------------------------------------------------------------------------
- opendir(DIR, $resBAO2) or die "Erreur d'ouverture de repertoire: $!\n";
- @sorties = readdir(DIR);
- closedir(DIR);
- foreach my $sortie (@sorties) {
- # se fait sur chaque sortie xml dans chaque rubrique
- if ($sortie=~/(.+?)\.xml$/ && $1 != "SortieGlobale2") {
- my $rub = $1;
- open(FILE,">>:encoding(UTF-8)", $resBAO2.$sortie);
- print FILE "</".$rub.">\n";;
- print FILE "</PARCOURS>\n";
- close FILE;
- print FILEGLOBALXML "<$rub>\n";
- print FILEGLOBALXML ${"DumpXML2_Tagged".$rub};
- print FILEGLOBALXML "</$rub>";
- }
- }
- #------------------------------------------------------------------------------
- print FILEGLOBALXML "</FILTRAGE>\n";
- print FILEGLOBALXML "</PARCOURS>\n";
- close(FILEGLOBALXML);
- #------------------------------------------------------------------------------
- # imprime le nombre des infos à la fin du programme
- print "\n" . "files IN = $nb_filesIN\n";
- print "items IN = $nb_itemsIN\n";
- print "items OUT = $nb_itemsOUT\n";
- print "fin.\n";
- exit;
- # fin du main programme
- #------------------------------------------------------------------------------
- #------------------------------------------------------------------------------
- # commencement des subroutines
- #------------------------------------------------------------------------------
- # subroutine pour parcourir l'aborescence
- sub parcoursarborescencefichiers {
- my $path = shift(@_); # chemin vers le dossier en entrée
- opendir(DIR, $path) or die "Probleme d'ouverture du dossier: $!\n";
- my @files = readdir(DIR);
- closedir(DIR);
- #--------------------------------------------
- foreach my $file (@files) {
- next if $file =~ /^\.\.?$/; #si . ou ..
- $file = $path."/".$file;
- #si $file est un dossier
- if (-d $file) {
- &parcoursarborescencefichiers($file); #recurse!
- }
- # faire le traitement si $file est un fichier
- if (-f $file) {
- # traiter les fichiers xml seulement
- if ($file=~/^[^(fil)]+?\.xml$/) {
- $nb_filesIN++;
- print $file,"\n";
- #lire le fichier xml
- open(FILE,$file);
- my $firstLine = <FILE>;
- my $encodage = "";
- #vérifier encodage du fichier xml
- if($firstLine =~ /encoding= ?['"]([^\'"]+)['"]/) {
- $encodage = $1; #extraire l'encodage
- }
- close(FILE);
- # si on trouve l'encodage, le fichier est reouvert avec l'encodage correcte
- if (!($encodage eq "")) {
- open(FILE,"<:encoding($encodage)",$file);
- my $texte = "";
- #éliminer les retours à ligne dans le fichier [ \n et \r ]
- while (my $ligne = <FILE>) {
- $ligne =~ s/\n//g;
- $ligne =~ s/\r//g;
- $texte .= $ligne;
- }
- close FILE;
- $texte =~ s/> *?</></g; # coller les balises
- #-----------------------------------------
- # extraire rubrique, date et nom
- $texte =~ /<channel>.*?<title>(.*?)<\/title>.*?<pubDate>(.+?)<\/pubDate>.*?<\/channel>/;
- # nettoyer les rubriques
- my $rubrique = &nettoyerRubriques($1);
- print "RUBRIQUE : $rubrique\n";
- # extraire la date
- my $date = &nettoyerRubriques($2);
- # nom du fichier
- my $name = $file;
- # uniquement les fichiers XML contenant les mises à jour
- $name =~ s/.*?(20.*)/$1/;
- #------------------------------------------
- # ouvre des balises et écrire dans des fichiers de sortie
- my $cheminXML=$res.$rubrique.".xml";
- # si on n'a pas encore vu le rubrique on doit le créer
- if (! -e $cheminXML) {
- # créer un fichier
- if (!open (FILEOUT,">:encoding(UTF-8)",$cheminXML)) {
- die "Probleme a la creation du fichier $cheminXML : $!";
- }
- # ouverture des balises XML du début du fichier
- print FILEOUT "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
- print FILEOUT "<PARCOURS>\n";
- print FILEOUT "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
- print FILEOUT "<$rubrique>\n";
- print FILEOUT "<file>";
- print FILEOUT "<name>$name</name>";
- print FILEOUT "<date>$date</date>";
- print FILEOUT "<items>";
- close(FILEOUT);
- ${"DumpXML"."$rubrique"}="";
- }
- # si le fichier existe déjà
- else {
- if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML)) {
- die "Problème a l'ouverture du fichier $cheminXML : $!\n";
- }
- print FILEOUT "<file>";
- print FILEOUT "<name>$name</name>";
- print FILEOUT "<date>$date</date>";
- print FILEOUT "<items>";
- close(FILEOUT);
- }
- #-------------------------------------------
- my $cheminXML_BAO2=$resBAO2.$rubrique.".xml";
- # si on n'a pas encore vu le rubrique
- if (! -e $cheminXML_BAO2) {
- # créer un fichier
- if (!open (FILEOUT,">:encoding(UTF-8)",$cheminXML_BAO2)) {
- die "Probleme a la creation du fichier $cheminXML_BAO2 : $!\n";
- }
- # ouverture des balises XML du début du fichier
- print FILEOUT "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
- print FILEOUT "<PARCOURS>\n";
- print FILEOUT "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
- print FILEOUT "<$rubrique>\n";
- print FILEOUT "<file>";
- print FILEOUT "<name>$name</name>";
- print FILEOUT "<date>$date</date>";
- print FILEOUT "<items>";
- close(FILEOUT);
- ${"DumpXML_tagged"."$rubrique"}="";
- }
- # si le fichier existe déjà
- else {
- if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML_BAO2)) {
- die "Problème a l'ouverture du fichier $cheminXML_BAO2 : $!\n";
- }
- print FILEOUT "<file>";
- print FILEOUT "<name>$file</name>";
- print FILEOUT "<date>$date</date>";
- print FILEOUT "<items>";
- close(FILEOUT);
- }
- #---------------------------------------------
- # extractions des titres et descriptions
- while ($texte =~ /<item>.*?<title>(.*?)<\/title>.*?<description>(.*?)<\/description>/g)
- {
- my $titre = $1;
- my $description = $2;
- $nb_itemsIN++;
- #-----------------------------------------
- # nettoyer le texte
- $titre = &nettoyerTexte($titre);
- $description = &nettoyerTexte($description);
- if (!(($titre eq "") or ($description eq ""))) {
- #-----------------------------------------
- # convertir si besoin en utf-8
- if (uc($encodage) ne "UTF-8") {
- utf8($titre);
- utf8($description);
- }
- #----------------------------------------------
- # regarde si on a déjà vu le texte
- if (!((exists $dico_titre{$rubrique . $titre}) && (exists $dico_description{$rubrique . $description})))
- {
- $dico_titre{$rubrique . $titre} = "1";
- $dico_description{$rubrique . $description} = "1";
- $nb_itemsOUT++;
- #------------------------------------------
- # faire l'etiquetage
- my $titre_tagged = &treetagger($titre);
- my $description_tagged = &treetagger($description);
- open(LOG, ">>", "log_bao2.txt");
- if(exists $dico_files{$file}){
- $count_file = int($dico_files{$file});
- $count_file++;
- %dico_files = ($file => $count_file);
- } else {
- %dico_files = ($file => 1);
- }
- #creer l`objet date pour ecrire les dates dans le log
- my $date_time = ctime();
- #ecrire le fichier de log avec le nom du fichier et l`heure de lecture
- print LOG $file." ".$dico_files{$file}."\t\t read on ".$date_time."\n";
- # mettre dans les sorties xml
- if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML)) {
- die "Problème a l'ouverture du fichier $cheminXML : $!\n";
- }
- print FILEOUT "<item>\n";
- print FILEOUT "<titre>" . $titre . "</titre>\n<description>" . $description . "</description>\n";
- print FILEOUT "</item>\n";
- close(FILEOUT);
- #----------------------------------------------
- # créer un dump pour chaque rubrique
- ${"DumpXML" . $rubrique} .= "<item>\n<titre>" . $titre . "</titre>\n<description>" . $description . "</description>\n</item>\n";
- #----------------------------------------------
- # partie de sorties txt
- my $cheminTXT = $res . $rubrique . ".txt";
- # si on n'a pas encore vu la rubrique
- if (! -e $cheminTXT) {
- if (!open (FILEGLOBALTXT,">>:encoding(iso-8859-15)",$cheminTXT)) {
- die "Problème a l'ouverture du fichier $cheminTXT : $!\n";
- }
- # écrire dans le sortie txt
- print FILEGLOBALTXT "$titre." . " $description.\n";
- close(FILEGLOBALTXT);
- }
- # si on a déjà vu la rubrique
- else {
- if (!open (FILEGLOBALTXT,">>:encoding(iso-8859-15)",$cheminTXT)) {
- die "Problème a l'ouverture du fichier $cheminTXT : $!\n";
- }
- # écrire dans le sortie txt
- print FILEGLOBALTXT "$titre." . " $description.";
- close(FILEGLOBALTXT);
- }
- if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML_BAO2)) {
- die "Problème a l'ouverture du fichier $cheminXML_BAO2 : $!\n";
- }
- print FILEOUT "<item>\n";
- print FILEOUT "<titre>".$titre_tagged."</titre>\n<description>".$description_tagged."</description>\n";
- print FILEOUT "</item>\n";
- close(FILEOUT);
- # créer un dump pour chaque rubrique
- ${"DumpXML2_Tagged".$rubrique}.="<item>\n<titre>".$titre_tagged."</titre>\n<description>".$description_tagged."</description>\n</item>\n";
- }
- }
- }
- # fermer la balise file pour chaque fichier xml
- if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML))
- {
- die "Problème a l'ouverture du fichier .$cheminXML : $!\n";
- }
- print FILEOUT "</items>";
- print FILEOUT "</file>";
- close(FILEOUT);
- # fermer la balise les fichier xml etiqutée
- if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML_BAO2)) {
- die "Problème a l'ouverture du fichier .$cheminXML_BAO2 : $!\n";
- }
- print FILEOUT "</items>";
- print FILEOUT "</file>";
- close(FILEOUT);
- }
- }
- }
- }
- }
- #------------------------------------------------------------------------------
- # subroutine pour nettoyer le texte
- #------------------------------------------------------------------------------
- sub nettoyerTexte {
- my $tx = $_[0];
- $tx =~ s/&/&/g;
- $tx =~ s/&/&/g;
- $tx =~ s/"/"/g;
- $tx =~ s/"/"/g;
- $tx =~ s/'/'/g;
- $tx =~ s/'/'/g;
- $tx =~ s/</</g;
- $tx =~ s/</</g;
- $tx =~ s/>/>/g;
- $tx =~ s/>/>/g;
- $tx =~ s/ //g;
- $tx =~ s/ //g;
- $tx =~ s/£/£/g;
- $tx =~ s/£/£/g;
- $tx =~ s/©/©/g;
- $tx =~ s/«/«/g;
- $tx =~ s/«/«/g;
- $tx =~ s/»/»/g;
- $tx =~ s/»//g;
- $tx =~ s/É/É/g;
- $tx =~ s/É/É/g;
- $tx =~ s/í/î/g;
- $tx =~ s/î/î/g;
- $tx =~ s/ï/ï/g;
- $tx =~ s/ï/ï/g;
- $tx =~ s/à/à/g;
- $tx =~ s/à/à/g;
- $tx =~ s/â/â/g;
- $tx =~ s/â/â/g;
- $tx =~ s/ç/ç/g;
- $tx =~ s/ç/ç/g;
- $tx =~ s/è/è/g;
- $tx =~ s/è/è/g;
- $tx =~ s/é/é/g;
- $tx =~ s/é/é/g;
- $tx =~ s/ê/ê/g;
- $tx =~ s/ê/ê/g;
- $tx =~ s/ô/ô/g;
- $tx =~ s/ô/ô/g;
- $tx =~ s/û/û/g;
- $tx =~ s/û/û/g;
- $tx =~ s/ü/ü/g;
- $tx =~ s/ü/ü/g;
- $tx =~ s/\x9c/œ/g;
- $tx =~ s/<br\/\>//g;
- $tx =~ s/<img.*?\/>//g;
- $tx =~ s/<.+?>//sg;
- $tx =~ s/<a.*?>.*?<\/a>//g;
- $tx =~ s/<![CDATA[(.*?)]]>/$1/g;
- $tx =~ s/<[^>]>//g;
- $tx =~ s/\.$//;
- $tx =~ s/&/et/g;
- return $tx;
- }
- #------------------------------------------------------------------------------
- # subroutine pour nettoyer des rubriques
- #------------------------------------------------------------------------------
- sub nettoyerRubriques {
- my $rubrique = shift;
- $rubrique =~ s/Le Monde.fr//g;
- $rubrique =~ s/LeMonde.fr//g;
- $rubrique =~ s/: Toute l'actualité sur//g;
- $rubrique =~ s/É/e/g;
- $rubrique =~ s/é/e/g;
- $rubrique =~ s/è/e/g;
- $rubrique =~ s/ê/a/g;
- $rubrique =~ s/ë/e/g;
- $rubrique =~ s/ï/i/g;
- $rubrique =~ s/î/i/g;
- $rubrique =~ s/à/a/g;
- $rubrique =~ s/ô/o/g;
- $rubrique =~ s/,/_/g;
- $rubrique = uc($rubrique);
- $rubrique =~ s/ //g;
- $rubrique =~ s/[\.\:;\'\"\-]+//g;
- return $rubrique;
- }
- #------------------------------------------------------------------------------
- # subroutine pour le tokenisation et etiquetage
- #------------------------------------------------------------------------------
- sub treetagger {
- my $texte = shift;
- my $temptag;
- # créer un fichier temporaire pour tagger des morceaux de texte
- open($temptag, ">:encoding(UTF-8)", "./temptag.txt");
- print $temptag $texte;
- close($temptag);
- system("perl tokenise-utf8.pl ./temptag.txt | /home/alexandre/tree-tagger/bin/tree-tagger -lemma -token -no-unknown -sgml /home/alexandre/tree-tagger/models/french.par > treetagger.txt");
- system("perl ./treetagger2xml-utf8.pl treetagger.txt utf-8");
- open(TaggedOUT,"<:encoding(utf-8)","treetagger.txt.xml");
- my $tagged_text = "";
- #lire la ligne d'en tête du fichier xml étiqueté, pour éviter que cette
- # ligne soit inclue dans le nouveau fichier xml
- my $line_den_tete = <TaggedOUT>;
- while (my $l = <TaggedOUT>) {
- $tagged_text .= $l;
- }
- close(TaggedOUT);
- return $tagged_text;
- }
- # fin des subroutines
- #------------------------------------------------------------------------------
- #------------------------------------------------------------------------------
#!/usr/bin/perl
<<DOC;
Votre Nom : Bienvenue, Poadey, Cavalcante
MARS 2015
usage : perl parcours-arborescence-fichiers repertoire-a-parcourir
Le programme prend en entrée le nom du répertoire contenant les fichiers
à traiter
Le programme construit en sortie des fichiers structurés : en format XML
et en format TXT
DOC
use Unicode::String qw(utf8);
use utf8;
# pour pouvoir afficher la date
use Time::localtime;
#------------------------------------------------------------------------------
# des compteurs pour le nombre des items
my $nb_filesIN = 0;
my $nb_itemsIN = 0;
my $nb_itemsOUT = 0;
#------------------------------------------------------------------------------
# le répertoire d'entrée
my $rep = "$ARGV[0]";
# enlever le slash à la fin du répertoire
$rep =~ s/[\/]$//;
#------------------------------------------------------------------------------
# des hash tables pour vérifier qu'on n'a pas deux fois les même infos
my %dico_titre = ();
my %dico_description = ();
# cet hash nous permet de juste traiter une fois chaque texte
my %dico_files = ();
# creer l`objet date pour ecrire les dates dans le log
my $date_time = ctime();
#------------------------------------------------------------------------------
# creation des dossiers de sortie
my $res = "./Sorties/";
if (! -e $res) {
mkdir($res) or die ("Problème avec la création du répertoire de $rep : $!");
}
$res = "./Sorties/Sorties_PurePerl/";
if (! -e $res) {
mkdir($res) or die ("Problème avec la création du répertoire de $rep : $!\n");
}
#------------------------------------------------------------------------------
# sorties etiquetées
my $resBAO2 = "./Sorties/Sorties_Tagged/";
if (! -e $resBAO2) {
mkdir($resBAO2) or die ("Problème avec la création du répertoire de $rep : $!\n");
}
#------------------------------------------------------------------------------
# sortie globale txt
open(FILEGLOBALTXT,">:encoding(UTF-8)", $res."SortieGlobale1.txt");
#------------------------------------------------------------------------------
&parcoursarborescencefichiers($rep); #recurse!
#------------------------------------------------------------------------------
close FILEGLOBALTXT;
#------------------------------------------------------------------------------
# création de la sortie globale xml
open(FILEGLOBALXML, ">:encoding(UTF-8)", $res."SortieGlobale1.xml");
print FILEGLOBALXML "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print FILEGLOBALXML "<PARCOURS>\n";
print FILEGLOBALXML "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
print FILEGLOBALXML "<FILTRAGE>";
#------------------------------------------------------------------------------
# écrire contenu de la sortie globale xml
opendir(DIR, $res) or die "Erreur d'ouverture du repertoire: $!\n";
my @sorties = readdir(DIR);
closedir(DIR);
foreach my $sortie (@sorties) {
if ($sortie=~/(.+?)\.xml$/ && $1 != "SortieGlobale1") {
my $rub=$1;
open(FILE,">>:encoding(UTF-8)", $res.$sortie);
print FILE "</".$rub.">\n";;
print FILE "</PARCOURS>\n";
close(FILE);
print FILEGLOBALXML "<$rub>\n";
print FILEGLOBALXML ${"DumpXML".$rub};
print FILEGLOBALXML "</$rub>";
}
}
print FILEGLOBALXML "</FILTRAGE>\n";
print FILEGLOBALXML "</PARCOURS>\n";
close(FILEGLOBALXML);
#------------------------------------------------------------------------------
open(FILEGLOBALXML, ">:encoding(UTF-8)", $resBAO2."SortieGlobale2.xml");
print FILEGLOBALXML "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print FILEGLOBALXML "<PARCOURS>\n";
print FILEGLOBALXML "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
print FILEGLOBALXML "<FILTRAGE>";
#------------------------------------------------------------------------------
opendir(DIR, $resBAO2) or die "Erreur d'ouverture de repertoire: $!\n";
@sorties = readdir(DIR);
closedir(DIR);
foreach my $sortie (@sorties) {
# se fait sur chaque sortie xml dans chaque rubrique
if ($sortie=~/(.+?)\.xml$/ && $1 != "SortieGlobale2") {
my $rub = $1;
open(FILE,">>:encoding(UTF-8)", $resBAO2.$sortie);
print FILE "</".$rub.">\n";;
print FILE "</PARCOURS>\n";
close FILE;
print FILEGLOBALXML "<$rub>\n";
print FILEGLOBALXML ${"DumpXML2_Tagged".$rub};
print FILEGLOBALXML "</$rub>";
}
}
#------------------------------------------------------------------------------
print FILEGLOBALXML "</FILTRAGE>\n";
print FILEGLOBALXML "</PARCOURS>\n";
close(FILEGLOBALXML);
#------------------------------------------------------------------------------
# imprime le nombre des infos à la fin du programme
print "\n" . "files IN = $nb_filesIN\n";
print "items IN = $nb_itemsIN\n";
print "items OUT = $nb_itemsOUT\n";
print "fin.\n";
exit;
# fin du main programme
#------------------------------------------------------------------------------
#------------------------------------------------------------------------------
# commencement des subroutines
#------------------------------------------------------------------------------
# subroutine pour parcourir l'aborescence
sub parcoursarborescencefichiers {
my $path = shift(@_); # chemin vers le dossier en entrée
opendir(DIR, $path) or die "Probleme d'ouverture du dossier: $!\n";
my @files = readdir(DIR);
closedir(DIR);
#--------------------------------------------
foreach my $file (@files) {
next if $file =~ /^\.\.?$/; #si . ou ..
$file = $path."/".$file;
#si $file est un dossier
if (-d $file) {
&parcoursarborescencefichiers($file); #recurse!
}
# faire le traitement si $file est un fichier
if (-f $file) {
# traiter les fichiers xml seulement
if ($file=~/^[^(fil)]+?\.xml$/) {
$nb_filesIN++;
print $file,"\n";
#lire le fichier xml
open(FILE,$file);
my $firstLine = <FILE>;
my $encodage = "";
#vérifier encodage du fichier xml
if($firstLine =~ /encoding= ?['"]([^\'"]+)['"]/) {
$encodage = $1; #extraire l'encodage
}
close(FILE);
# si on trouve l'encodage, le fichier est reouvert avec l'encodage correcte
if (!($encodage eq "")) {
open(FILE,"<:encoding($encodage)",$file);
my $texte = "";
#éliminer les retours à ligne dans le fichier [ \n et \r ]
while (my $ligne = <FILE>) {
$ligne =~ s/\n//g;
$ligne =~ s/\r//g;
$texte .= $ligne;
}
close FILE;
$texte =~ s/> *?</></g; # coller les balises
#-----------------------------------------
# extraire rubrique, date et nom
$texte =~ /<channel>.*?<title>(.*?)<\/title>.*?<pubDate>(.+?)<\/pubDate>.*?<\/channel>/;
# nettoyer les rubriques
my $rubrique = &nettoyerRubriques($1);
print "RUBRIQUE : $rubrique\n";
# extraire la date
my $date = &nettoyerRubriques($2);
# nom du fichier
my $name = $file;
# uniquement les fichiers XML contenant les mises à jour
$name =~ s/.*?(20.*)/$1/;
#------------------------------------------
# ouvre des balises et écrire dans des fichiers de sortie
my $cheminXML=$res.$rubrique.".xml";
# si on n'a pas encore vu le rubrique on doit le créer
if (! -e $cheminXML) {
# créer un fichier
if (!open (FILEOUT,">:encoding(UTF-8)",$cheminXML)) {
die "Probleme a la creation du fichier $cheminXML : $!";
}
# ouverture des balises XML du début du fichier
print FILEOUT "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print FILEOUT "<PARCOURS>\n";
print FILEOUT "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
print FILEOUT "<$rubrique>\n";
print FILEOUT "<file>";
print FILEOUT "<name>$name</name>";
print FILEOUT "<date>$date</date>";
print FILEOUT "<items>";
close(FILEOUT);
${"DumpXML"."$rubrique"}="";
}
# si le fichier existe déjà
else {
if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML)) {
die "Problème a l'ouverture du fichier $cheminXML : $!\n";
}
print FILEOUT "<file>";
print FILEOUT "<name>$name</name>";
print FILEOUT "<date>$date</date>";
print FILEOUT "<items>";
close(FILEOUT);
}
#-------------------------------------------
my $cheminXML_BAO2=$resBAO2.$rubrique.".xml";
# si on n'a pas encore vu le rubrique
if (! -e $cheminXML_BAO2) {
# créer un fichier
if (!open (FILEOUT,">:encoding(UTF-8)",$cheminXML_BAO2)) {
die "Probleme a la creation du fichier $cheminXML_BAO2 : $!\n";
}
# ouverture des balises XML du début du fichier
print FILEOUT "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print FILEOUT "<PARCOURS>\n";
print FILEOUT "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
print FILEOUT "<$rubrique>\n";
print FILEOUT "<file>";
print FILEOUT "<name>$name</name>";
print FILEOUT "<date>$date</date>";
print FILEOUT "<items>";
close(FILEOUT);
${"DumpXML_tagged"."$rubrique"}="";
}
# si le fichier existe déjà
else {
if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML_BAO2)) {
die "Problème a l'ouverture du fichier $cheminXML_BAO2 : $!\n";
}
print FILEOUT "<file>";
print FILEOUT "<name>$file</name>";
print FILEOUT "<date>$date</date>";
print FILEOUT "<items>";
close(FILEOUT);
}
#---------------------------------------------
# extractions des titres et descriptions
while ($texte =~ /<item>.*?<title>(.*?)<\/title>.*?<description>(.*?)<\/description>/g)
{
my $titre = $1;
my $description = $2;
$nb_itemsIN++;
#-----------------------------------------
# nettoyer le texte
$titre = &nettoyerTexte($titre);
$description = &nettoyerTexte($description);
if (!(($titre eq "") or ($description eq ""))) {
#-----------------------------------------
# convertir si besoin en utf-8
if (uc($encodage) ne "UTF-8") {
utf8($titre);
utf8($description);
}
#----------------------------------------------
# regarde si on a déjà vu le texte
if (!((exists $dico_titre{$rubrique . $titre}) && (exists $dico_description{$rubrique . $description})))
{
$dico_titre{$rubrique . $titre} = "1";
$dico_description{$rubrique . $description} = "1";
$nb_itemsOUT++;
#------------------------------------------
# faire l'etiquetage
my $titre_tagged = &treetagger($titre);
my $description_tagged = &treetagger($description);
open(LOG, ">>", "log_bao2.txt");
if(exists $dico_files{$file}){
$count_file = int($dico_files{$file});
$count_file++;
%dico_files = ($file => $count_file);
} else {
%dico_files = ($file => 1);
}
#creer l`objet date pour ecrire les dates dans le log
my $date_time = ctime();
#ecrire le fichier de log avec le nom du fichier et l`heure de lecture
print LOG $file." ".$dico_files{$file}."\t\t read on ".$date_time."\n";
# mettre dans les sorties xml
if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML)) {
die "Problème a l'ouverture du fichier $cheminXML : $!\n";
}
print FILEOUT "<item>\n";
print FILEOUT "<titre>" . $titre . "</titre>\n<description>" . $description . "</description>\n";
print FILEOUT "</item>\n";
close(FILEOUT);
#----------------------------------------------
# créer un dump pour chaque rubrique
${"DumpXML" . $rubrique} .= "<item>\n<titre>" . $titre . "</titre>\n<description>" . $description . "</description>\n</item>\n";
#----------------------------------------------
# partie de sorties txt
my $cheminTXT = $res . $rubrique . ".txt";
# si on n'a pas encore vu la rubrique
if (! -e $cheminTXT) {
if (!open (FILEGLOBALTXT,">>:encoding(iso-8859-15)",$cheminTXT)) {
die "Problème a l'ouverture du fichier $cheminTXT : $!\n";
}
# écrire dans le sortie txt
print FILEGLOBALTXT "$titre." . " $description.\n";
close(FILEGLOBALTXT);
}
# si on a déjà vu la rubrique
else {
if (!open (FILEGLOBALTXT,">>:encoding(iso-8859-15)",$cheminTXT)) {
die "Problème a l'ouverture du fichier $cheminTXT : $!\n";
}
# écrire dans le sortie txt
print FILEGLOBALTXT "$titre." . " $description.";
close(FILEGLOBALTXT);
}
if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML_BAO2)) {
die "Problème a l'ouverture du fichier $cheminXML_BAO2 : $!\n";
}
print FILEOUT "<item>\n";
print FILEOUT "<titre>".$titre_tagged."</titre>\n<description>".$description_tagged."</description>\n";
print FILEOUT "</item>\n";
close(FILEOUT);
# créer un dump pour chaque rubrique
${"DumpXML2_Tagged".$rubrique}.="<item>\n<titre>".$titre_tagged."</titre>\n<description>".$description_tagged."</description>\n</item>\n";
}
}
}
# fermer la balise file pour chaque fichier xml
if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML))
{
die "Problème a l'ouverture du fichier .$cheminXML : $!\n";
}
print FILEOUT "</items>";
print FILEOUT "</file>";
close(FILEOUT);
# fermer la balise les fichier xml etiqutée
if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML_BAO2)) {
die "Problème a l'ouverture du fichier .$cheminXML_BAO2 : $!\n";
}
print FILEOUT "</items>";
print FILEOUT "</file>";
close(FILEOUT);
}
}
}
}
}
#------------------------------------------------------------------------------
# subroutine pour nettoyer le texte
#------------------------------------------------------------------------------
sub nettoyerTexte {
my $tx = $_[0];
$tx =~ s/&/&/g;
$tx =~ s/&/&/g;
$tx =~ s/"/"/g;
$tx =~ s/"/"/g;
$tx =~ s/'/'/g;
$tx =~ s/'/'/g;
$tx =~ s/</</g;
$tx =~ s/</</g;
$tx =~ s/>/>/g;
$tx =~ s/>/>/g;
$tx =~ s/ //g;
$tx =~ s/ //g;
$tx =~ s/£/£/g;
$tx =~ s/£/£/g;
$tx =~ s/©/©/g;
$tx =~ s/«/«/g;
$tx =~ s/«/«/g;
$tx =~ s/»/»/g;
$tx =~ s/»//g;
$tx =~ s/É/É/g;
$tx =~ s/É/É/g;
$tx =~ s/í/î/g;
$tx =~ s/î/î/g;
$tx =~ s/ï/ï/g;
$tx =~ s/ï/ï/g;
$tx =~ s/à/à/g;
$tx =~ s/à/à/g;
$tx =~ s/â/â/g;
$tx =~ s/â/â/g;
$tx =~ s/ç/ç/g;
$tx =~ s/ç/ç/g;
$tx =~ s/è/è/g;
$tx =~ s/è/è/g;
$tx =~ s/é/é/g;
$tx =~ s/é/é/g;
$tx =~ s/ê/ê/g;
$tx =~ s/ê/ê/g;
$tx =~ s/ô/ô/g;
$tx =~ s/ô/ô/g;
$tx =~ s/û/û/g;
$tx =~ s/û/û/g;
$tx =~ s/ü/ü/g;
$tx =~ s/ü/ü/g;
$tx =~ s/\x9c/œ/g;
$tx =~ s/<br\/\>//g;
$tx =~ s/<img.*?\/>//g;
$tx =~ s/<.+?>//sg;
$tx =~ s/<a.*?>.*?<\/a>//g;
$tx =~ s/<![CDATA[(.*?)]]>/$1/g;
$tx =~ s/<[^>]>//g;
$tx =~ s/\.$//;
$tx =~ s/&/et/g;
return $tx;
}
#------------------------------------------------------------------------------
# subroutine pour nettoyer des rubriques
#------------------------------------------------------------------------------
sub nettoyerRubriques {
my $rubrique = shift;
$rubrique =~ s/Le Monde.fr//g;
$rubrique =~ s/LeMonde.fr//g;
$rubrique =~ s/: Toute l'actualité sur//g;
$rubrique =~ s/É/e/g;
$rubrique =~ s/é/e/g;
$rubrique =~ s/è/e/g;
$rubrique =~ s/ê/a/g;
$rubrique =~ s/ë/e/g;
$rubrique =~ s/ï/i/g;
$rubrique =~ s/î/i/g;
$rubrique =~ s/à/a/g;
$rubrique =~ s/ô/o/g;
$rubrique =~ s/,/_/g;
$rubrique = uc($rubrique);
$rubrique =~ s/ //g;
$rubrique =~ s/[\.\:;\'\"\-]+//g;
return $rubrique;
}
#------------------------------------------------------------------------------
# subroutine pour le tokenisation et etiquetage
#------------------------------------------------------------------------------
sub treetagger {
my $texte = shift;
my $temptag;
# créer un fichier temporaire pour tagger des morceaux de texte
open($temptag, ">:encoding(UTF-8)", "./temptag.txt");
print $temptag $texte;
close($temptag);
system("perl tokenise-utf8.pl ./temptag.txt | /home/alexandre/tree-tagger/bin/tree-tagger -lemma -token -no-unknown -sgml /home/alexandre/tree-tagger/models/french.par > treetagger.txt");
system("perl ./treetagger2xml-utf8.pl treetagger.txt utf-8");
open(TaggedOUT,"<:encoding(utf-8)","treetagger.txt.xml");
my $tagged_text = "";
#lire la ligne d'en tête du fichier xml étiqueté, pour éviter que cette
# ligne soit inclue dans le nouveau fichier xml
my $line_den_tete = <TaggedOUT>;
while (my $l = <TaggedOUT>) {
$tagged_text .= $l;
}
close(TaggedOUT);
return $tagged_text;
}
# fin des subroutines
#------------------------------------------------------------------------------
#------------------------------------------------------------------------------Perl modules
Nous avons écrit des scripts Perl pour les Outils en utilisant les procédures pour nettoyer les fichiers des entités existantes mais aussi en utilisant les modules XML::Entities et HTML::Entities. Nous avons donc deux scripts différents pour l'Outil 1 et 2, autrement dit avec et sans modules Perl.
Pour l'Outil 2, nous avons procédé au même système que pour l'Outil 1 en nettoyant le fichier XML après décodage des entités.
La déclaration des modules :
L'utilisation des modules :
- #!/usr/bin/perl -w
- <<DOC;
- Votre Nom : Bienvenue, Poadey, Cavalcante
- MARS 2015
- usage : perl parcours-arborescence-fichiers repertoire-a-parcourir
- Le programme prend en entrée le nom du répertoire contenant les fichiers
- à traiter
- Le programme construit en sortie un fichier structuré contenant sur chaque
- ligne le nom du fichier et le résultat du filtrage :
- <FICHIER><NOM>du fichier</NOM></FICHIER><CONTENU>du filtrage</CONTENU></FICHIER>
- DOC
- use Unicode::String qw(utf8);
- use utf8;
- use Time::localtime;
- use XML::Entities;
- use HTML::Entities;
- #------------------------------------------------------------------------------
- # des compteurs pour le nombre des items
- my $nb_filesIN = 0;
- my $nb_itemsIN = 0;
- my $nb_itemsOUT = 0;
- #------------------------------------------------------------------------------
- # le répertoire d'entrée contenant les fichiers xml
- my $rep = "$ARGV[0]";
- # regex enlever le slash à la fin du nom du répertoire
- $rep =~ s/[\/]$//;
- #------------------------------------------------------------------------------
- # des hash tables pour vérifier qu'on n'a pas deux fois les même infos
- my %dicoTitre = ();
- my %dicoDescription = ();
- # cet hash controle le nombre de fois que le fichier a ete lu pour ecrire le fichier de log
- my %dico_files = ();
- #creer l`objet date pour ecire la date et l'heure de lecture des fichiers xml dans le fichier de log
- my $date_time = ctime();
- #------------------------------------------------------------------------------
- # creation des dossiers de sortie
- my $res = "../Sorties/";
- if (! -e $res) {
- mkdir($res) or die ("Problème avec la création du répertoire de $rep : $!");
- }
- $res = "../Sorties/1_Sorties_PurePerl/";
- if (! -e $res) {
- mkdir($res) or die ("Problème avec la création du répertoire de $rep : $!\n");
- }
- #------------------------------------------------------------------------------
- # sorties etiquetées
- my $resBAO2 = "../Sorties/2_Sorties_Etiquetees/";
- if (! -e $resBAO2) {
- mkdir($resBAO2) or die ("Problème avec la création du répertoire de $rep : $!\n");
- }
- #------------------------------------------------------------------------------
- # sortie globale txt
- open(FILEGLOBALTXT,">:encoding(UTF-8)", $res."1_SortieGlobale.txt");
- #------------------------------------------------------------------------------
- &parcoursarborescencefichiers($rep); #recurse!
- #------------------------------------------------------------------------------
- close FILEGLOBALTXT;
- #------------------------------------------------------------------------------
- # création de la sortie globale xml
- open(FILEGLOBALXML, ">:encoding(UTF-8)", $res."1_SortieGlobale.xml");
- print FILEGLOBALXML "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
- print FILEGLOBALXML "<PARCOURS>\n";
- print FILEGLOBALXML "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
- print FILEGLOBALXML "<FILTRAGE>";
- #------------------------------------------------------------------------------
- # écrire contenu de la sortie globale xml
- opendir(DIR, $res) or die "Erreur d'ouverture du repertoire: $!\n";
- my @sorties = readdir(DIR);
- closedir(DIR);
- foreach my $sortie (@sorties) {
- if ($sortie=~/(.+?)\.xml$/ && $1 != "1_SortieGlobale") {
- my $rub=$1;
- open(FILE,">>:encoding(UTF-8)", $res.$sortie);
- print FILE "</".$rub.">\n";;
- print FILE "</PARCOURS>\n";
- close(FILE);
- print FILEGLOBALXML "<$rub>\n";
- print FILEGLOBALXML ${"DumpXML".$rub};
- print FILEGLOBALXML "</$rub>";
- }
- }
- print FILEGLOBALXML "</FILTRAGE>\n";
- print FILEGLOBALXML "</PARCOURS>\n";
- close(FILEGLOBALXML);
- #------------------------------------------------------------------------------
- open(FILEGLOBALXML, ">:encoding(UTF-8)", $resBAO2."2_SortieGlobale.xml");
- print FILEGLOBALXML "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
- print FILEGLOBALXML "<PARCOURS>\n";
- print FILEGLOBALXML "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
- print FILEGLOBALXML "<FILTRAGE>";
- #------------------------------------------------------------------------------
- opendir(DIR, $resBAO2) or die "Erreur d'ouverture de repertoire: $!\n";
- @sorties = readdir(DIR);
- closedir(DIR);
- foreach my $sortie (@sorties) {
- # se fait sur chaque sortie xml dans chaque rubrique
- if ($sortie=~/(.+?)\.xml$/ && $1 != "2_SortieGlobale") {
- my $rub = $1;
- open(FILE,">>:encoding(UTF-8)", $resBAO2.$sortie);
- print FILE "</".$rub.">\n";;
- print FILE "</PARCOURS>\n";
- close FILE;
- print FILEGLOBALXML "<$rub>\n";
- print FILEGLOBALXML ${"DumpXML2_Tagged".$rub};
- print FILEGLOBALXML "</$rub>";
- }
- }
- #------------------------------------------------------------------------------
- print FILEGLOBALXML "</FILTRAGE>\n";
- print FILEGLOBALXML "</PARCOURS>\n";
- close(FILEGLOBALXML);
- #------------------------------------------------------------------------------
- # imprime le nombre des infos à la fin du programme
- print "\n" . "nbr files IN = $nb_filesIN\n";
- print "nbr items IN = $nb_itemsIN\n";
- print "nbr items OUT = $nb_itemsOUT\n";
- print "fin du programme.\n";
- exit;
- # fin du main programme
- #------------------------------------------------------------------------------
- #------------------------------------------------------------------------------
- # commencement des subroutines
- #------------------------------------------------------------------------------
- # subroutine pour parcourir l'aborescence
- sub parcoursarborescencefichiers {
- my $path = shift(@_); # chemin vers le dossier en entrée
- opendir(DIR, $path) or die "Probleme d'ouverture du dossier: $!\n";
- my @files = readdir(DIR);
- closedir(DIR);
- #------------------------------------------------------------------------------
- foreach my $file (@files) {
- next if $file =~ /^\.\.?$/; #si . ou ..
- $file = $path."/".$file;
- #si $file est un dossier
- if (-d $file) {
- &parcoursarborescencefichiers($file); #recurse!
- }
- # faire le traitement si $file est un fichier
- if (-f $file) {
- # traiter les fichiers xml seulement
- if ($file=~/^[^(fil)]+?\.xml$/) {
- $nb_filesIN++;
- print $file,"\n";
- #lire le fichier xml
- open(FILE,$file);
- my $firstLine = <FILE>;
- my $encodage = "";
- #vérifier encodage du fichier xml
- if($firstLine =~ /encoding= ?['"]([^\'"]+)['"]/) {
- $encodage = $1; #extraire l'encodage
- }
- close(FILE);
- # si on trouve l'encodage, le fichier est reouvert avec l'encodage correcte
- if (!($encodage eq "")) {
- open(FILE,"<:encoding($encodage)",$file);
- my $texte = "";
- #éliminer les retours à ligne dans le fichier [ \n et \r ]
- while (my $ligne = <FILE>) {
- $ligne =~ s/\n//g;
- $ligne =~ s/\r//g;
- $texte .= $ligne;
- }
- close FILE;
- $texte =~ s/> *?</></g; # coller les balises
- #------------------------------------------------------------------------------
- # extraire rubrique, date et nom
- $texte =~ /<channel>.*?<title>(.*?)<\/title>.*?<pubDate>(.+?)<\/pubDate>.*?<\/channel>/;
- # nettoyer les rubriques
- my $rubrique = &nettoyerRubriques($1);
- print "RUBRIQUE : $rubrique\n";
- # extraire la date
- my $date = &nettoyerRubriques($2);
- # nom du fichier
- my $name = $file;
- # uniquement les fichiers XML contenant les mises à jour
- $name =~ s/.*?(20.*)/$1/;
- #------------------------------------------------------------------------------
- # ouvre des balises et écrire dans des fichiers de sortie
- my $cheminXML=$res.$rubrique.".xml";
- # si on n'a pas encore vu le rubrique on doit le créer
- if (! -e $cheminXML) {
- # créer un fichier
- if (!open (FILEOUT,">:encoding(UTF-8)",$cheminXML)) {
- die "Probleme a la creation du fichier $cheminXML : $!";
- }
- # ouverture des balises XML du début du fichier
- print FILEOUT "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
- print FILEOUT "<PARCOURS>\n";
- print FILEOUT "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
- print FILEOUT "<$rubrique>\n";
- print FILEOUT "<file>";
- print FILEOUT "<name>$name</name>";
- print FILEOUT "<date>$date</date>";
- print FILEOUT "<items>";
- close(FILEOUT);
- ${"DumpXML"."$rubrique"}="";
- }
- # si le fichier existe déjà
- else {
- if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML)) {
- die "Problème a l'ouverture du fichier $cheminXML : $!\n";
- }
- print FILEOUT "<file>";
- print FILEOUT "<name>$name</name>";
- print FILEOUT "<date>$date</date>";
- print FILEOUT "<items>";
- close(FILEOUT);
- }
- #------------------------------------------------------------------------------
- my $cheminXML_BAO2=$resBAO2.$rubrique.".xml";
- # si on n'a pas encore vu le rubrique
- if (! -e $cheminXML_BAO2) {
- # créer un fichier
- if (!open (FILEOUT,">:encoding(UTF-8)",$cheminXML_BAO2)) {
- die "Probleme a la creation du fichier $cheminXML_BAO2 : $!\n";
- }
- # ouverture des balises XML du début du fichier
- print FILEOUT "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
- print FILEOUT "<PARCOURS>\n";
- print FILEOUT "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
- print FILEOUT "<$rubrique>\n";
- print FILEOUT "<file>";
- print FILEOUT "<name>$name</name>";
- print FILEOUT "<date>$date</date>";
- print FILEOUT "<items>";
- close(FILEOUT);
- ${"DumpXML_tagged"."$rubrique"}="";
- }
- # si le fichier existe déjà
- else {
- if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML_BAO2)) {
- die "Problème a l'ouverture du fichier $cheminXML_BAO2 : $!\n";
- }
- print FILEOUT "<file>";
- print FILEOUT "<name>$file</name>";
- print FILEOUT "<date>$date</date>";
- print FILEOUT "<items>";
- close(FILEOUT);
- }
- #------------------------------------------------------------------------------
- # extractions des titres et descriptions
- while ($texte =~ /<item>.*?<title>(.*?)<\/title>.*?<description>(.*?)<\/description>/g)
- {
- my $titre = $1;
- my $description = $2;
- $nb_itemsIN++;
- #------------------------------------------------------------------------------
- # nettoyer le texte
- if (!(exists ($dicoTitre{$titre})) and !(exists ($dicoDescription{$description})))
- {
- $dicoTitre{$titre}++;
- $dicoDescription{$description}++;
- $titre = XML::Entities::decode('all', $titre);
- $descritpion = XML::Entities::decode('all', $description);
- $titre = HTML::Entities::decode($titre);
- $description = HTML::Entities::decode($description);
- $tmptexteBRUT.="$titre \n";
- $tmptexteBRUT.="$description \n";
- $tmptexteXML.="<item><title>$titre</title><description>$description</description></item>\n";
- #--------------------------------------------------------------------------------------
- # nettoyage des balises <description> pour supprimer les balises superflues
- $tmptexteXML =~ s/<img.*?\/><\/description>/<\/description>/g;
- $tmptexteBRUT =~ s/<img.*?\/> \n/\n/g;
- }
- if (!(($titre eq "") or ($description eq ""))) {
- #------------------------------------------------------------------------------
- # convertir si besoin en utf-8
- if (uc($encodage) ne "UTF-8") {
- utf8($titre);
- utf8($description);
- }
- #------------------------------------------------------------------------------
- # regarde si on a déjà vu le texte
- if (!((exists $dicoTitre{$rubrique . $titre}) && (exists $dicoDescription{$rubrique . $description})))
- {
- $dicoTitre{$rubrique . $titre} = "1";
- $dicoDescription{$rubrique . $description} = "1";
- $nb_itemsOUT++;
- #------------------------------------------------------------------------------
- # faire l'etiquetage
- my $titre_tagged = &treetagger($titre);
- my $description_tagged = &treetagger($description);
- open(LOG, ">>", "log_bao2.txt");
- if(exists $dico_files{$file}){
- $count_file = int($dico_files{$file});
- $count_file++;
- %dico_files = ($file => $count_file);
- } else {
- %dico_files = ($file => 1);
- }
- #creer l`objet date pour ecire les date dans le fichier de log
- my $date_time = ctime();
- #ecrire le fichier de log avec le nom du fichier et l`heure de lecture
- print LOG $file." ".$dico_files{$file}."\t\t read on ".$date_time."\n";
- # mettre dans les sorties xml
- if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML)) {
- die "Problème a l'ouverture du fichier $cheminXML : $!\n";
- }
- print FILEOUT "<item>\n";
- print FILEOUT $tmptexteXML;
- print FILEOUT "</item>\n";
- close(FILEOUT);
- #------------------------------------------------------------------------------
- # créer un dump pour chaque rubrique
- ${"DumpXML" . $rubrique} .= $tmptexteXML."\n";
- #------------------------------------------------------------------------------
- # partie de sorties txt
- my $cheminTXT = $res . $rubrique . ".txt";
- # si on n'a pas encore vu la rubrique
- if (! -e $cheminTXT) {
- if (!open (FILEGLOBALTXT,">:encoding(iso-8859-15)",$cheminTXT)) {
- die "Problème a l'ouverture du fichier $cheminTXT : $!\n";
- }
- # écrire dans le sortie txt
- print FILEGLOBALTXT $tmptexteBRUT;
- close(FILEGLOBALTXT);
- }
- # si on a déjà vu la rubrique
- else {
- if (!open (FILEGLOBALTXT,">>:encoding(iso-8859-15)",$cheminTXT)) {
- die "Problème a l'ouverture du fichier $cheminTXT : $!\n";
- }
- # écrire dans la sortie txt
- print FILEGLOBALTXT $tmptexteBRUT;
- close(FILEGLOBALTXT);
- }
- if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML_BAO2)) {
- die "Problème a l'ouverture du fichier $cheminXML_BAO2 : $!\n";
- }
- print FILEOUT "<item>\n";
- print FILEOUT $tmptexteXML;
- print FILEOUT "</item>\n";
- close(FILEOUT);
- # créer un dump pour chaque rubrique
- ${"DumpXML2_Tagged".$rubrique}.= $tmptexteXML."\n";
- }
- }
- }
- # fermer la balise file pour chaque fichier xml
- if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML))
- {
- die "Problème a l'ouverture du fichier .$cheminXML : $!\n";
- }
- print FILEOUT "</items>";
- print FILEOUT "</file>";
- close(FILEOUT);
- # fermer la balise les fichier xml etiqutée
- if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML_BAO2)) {
- die "Problème a l'ouverture du fichier .$cheminXML_BAO2 : $!\n";
- }
- print FILEOUT "</items>";
- print FILEOUT "</file>";
- close(FILEOUT);
- }
- }
- }
- }
- }
- #------------------------------------------------------------------------------
- # subroutine pour nettoyer des rubriques
- #------------------------------------------------------------------------------
- sub nettoyerRubriques {
- my $rubrique = shift;
- $rubrique =~ s/Le Monde.fr//g;
- $rubrique =~ s/LeMonde.fr//g;
- $rubrique =~ s/: Toute l'actualité sur//g;
- $rubrique =~ s/É/e/g;
- $rubrique =~ s/é/e/g;
- $rubrique =~ s/è/e/g;
- $rubrique =~ s/ê/a/g;
- $rubrique =~ s/ë/e/g;
- $rubrique =~ s/ï/i/g;
- $rubrique =~ s/î/i/g;
- $rubrique =~ s/à/a/g;
- $rubrique =~ s/ô/o/g;
- $rubrique =~ s/,/_/g;
- $rubrique = uc($rubrique);
- $rubrique =~ s/ //g;
- $rubrique =~ s/[\.\:;\'\"\-]+//g;
- return $rubrique;
- }
- #------------------------------------------------------------------------------
- # subroutine pour tokenisation et etiquetage
- #------------------------------------------------------------------------------
- sub treetagger {
- my $texte = shift;
- my $temptag;
- # créer un fichier temporaire pour tagger des morceaux de texte
- open($temptag, ">:encoding(UTF-8)", "./temptag.txt");
- print $temptag $texte;
- close($temptag);
- system("perl tokenise-utf8.pl ./temptag.txt | tree-tagger.exe -lemma -token -no-unknown -sgml ./french.par > treetagger.txt");
- system("perl treetagger2xml-utf8.pl treetagger.txt utf-8");
- open(TaggedOUT,"<:encoding(utf-8)","treetagger.txt.xml");
- my $tagged_text = "";
- #lire la ligne d'en tête du fichier xml étiqueté, pour éviter que cette ligne soit incluse dans le nouveau fichier xml
- my $line_den_tete = <TaggedOUT>;
- while (my $l = <TaggedOUT>) {
- $tagged_text .= $l;
- }
- close(TaggedOUT);
- return $tagged_text;
- }
- # fin des subroutines
- #------------------------------------------------------------------------------
- #------------------------------------------------------------------------------
#!/usr/bin/perl -w
<<DOC;
Votre Nom : Bienvenue, Poadey, Cavalcante
MARS 2015
usage : perl parcours-arborescence-fichiers repertoire-a-parcourir
Le programme prend en entrée le nom du répertoire contenant les fichiers
à traiter
Le programme construit en sortie un fichier structuré contenant sur chaque
ligne le nom du fichier et le résultat du filtrage :
<FICHIER><NOM>du fichier</NOM></FICHIER><CONTENU>du filtrage</CONTENU></FICHIER>
DOC
use Unicode::String qw(utf8);
use utf8;
use Time::localtime;
use XML::Entities;
use HTML::Entities;
#------------------------------------------------------------------------------
# des compteurs pour le nombre des items
my $nb_filesIN = 0;
my $nb_itemsIN = 0;
my $nb_itemsOUT = 0;
#------------------------------------------------------------------------------
# le répertoire d'entrée contenant les fichiers xml
my $rep = "$ARGV[0]";
# regex enlever le slash à la fin du nom du répertoire
$rep =~ s/[\/]$//;
#------------------------------------------------------------------------------
# des hash tables pour vérifier qu'on n'a pas deux fois les même infos
my %dicoTitre = ();
my %dicoDescription = ();
# cet hash controle le nombre de fois que le fichier a ete lu pour ecrire le fichier de log
my %dico_files = ();
#creer l`objet date pour ecire la date et l'heure de lecture des fichiers xml dans le fichier de log
my $date_time = ctime();
#------------------------------------------------------------------------------
# creation des dossiers de sortie
my $res = "../Sorties/";
if (! -e $res) {
mkdir($res) or die ("Problème avec la création du répertoire de $rep : $!");
}
$res = "../Sorties/1_Sorties_PurePerl/";
if (! -e $res) {
mkdir($res) or die ("Problème avec la création du répertoire de $rep : $!\n");
}
#------------------------------------------------------------------------------
# sorties etiquetées
my $resBAO2 = "../Sorties/2_Sorties_Etiquetees/";
if (! -e $resBAO2) {
mkdir($resBAO2) or die ("Problème avec la création du répertoire de $rep : $!\n");
}
#------------------------------------------------------------------------------
# sortie globale txt
open(FILEGLOBALTXT,">:encoding(UTF-8)", $res."1_SortieGlobale.txt");
#------------------------------------------------------------------------------
&parcoursarborescencefichiers($rep); #recurse!
#------------------------------------------------------------------------------
close FILEGLOBALTXT;
#------------------------------------------------------------------------------
# création de la sortie globale xml
open(FILEGLOBALXML, ">:encoding(UTF-8)", $res."1_SortieGlobale.xml");
print FILEGLOBALXML "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print FILEGLOBALXML "<PARCOURS>\n";
print FILEGLOBALXML "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
print FILEGLOBALXML "<FILTRAGE>";
#------------------------------------------------------------------------------
# écrire contenu de la sortie globale xml
opendir(DIR, $res) or die "Erreur d'ouverture du repertoire: $!\n";
my @sorties = readdir(DIR);
closedir(DIR);
foreach my $sortie (@sorties) {
if ($sortie=~/(.+?)\.xml$/ && $1 != "1_SortieGlobale") {
my $rub=$1;
open(FILE,">>:encoding(UTF-8)", $res.$sortie);
print FILE "</".$rub.">\n";;
print FILE "</PARCOURS>\n";
close(FILE);
print FILEGLOBALXML "<$rub>\n";
print FILEGLOBALXML ${"DumpXML".$rub};
print FILEGLOBALXML "</$rub>";
}
}
print FILEGLOBALXML "</FILTRAGE>\n";
print FILEGLOBALXML "</PARCOURS>\n";
close(FILEGLOBALXML);
#------------------------------------------------------------------------------
open(FILEGLOBALXML, ">:encoding(UTF-8)", $resBAO2."2_SortieGlobale.xml");
print FILEGLOBALXML "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print FILEGLOBALXML "<PARCOURS>\n";
print FILEGLOBALXML "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
print FILEGLOBALXML "<FILTRAGE>";
#------------------------------------------------------------------------------
opendir(DIR, $resBAO2) or die "Erreur d'ouverture de repertoire: $!\n";
@sorties = readdir(DIR);
closedir(DIR);
foreach my $sortie (@sorties) {
# se fait sur chaque sortie xml dans chaque rubrique
if ($sortie=~/(.+?)\.xml$/ && $1 != "2_SortieGlobale") {
my $rub = $1;
open(FILE,">>:encoding(UTF-8)", $resBAO2.$sortie);
print FILE "</".$rub.">\n";;
print FILE "</PARCOURS>\n";
close FILE;
print FILEGLOBALXML "<$rub>\n";
print FILEGLOBALXML ${"DumpXML2_Tagged".$rub};
print FILEGLOBALXML "</$rub>";
}
}
#------------------------------------------------------------------------------
print FILEGLOBALXML "</FILTRAGE>\n";
print FILEGLOBALXML "</PARCOURS>\n";
close(FILEGLOBALXML);
#------------------------------------------------------------------------------
# imprime le nombre des infos à la fin du programme
print "\n" . "nbr files IN = $nb_filesIN\n";
print "nbr items IN = $nb_itemsIN\n";
print "nbr items OUT = $nb_itemsOUT\n";
print "fin du programme.\n";
exit;
# fin du main programme
#------------------------------------------------------------------------------
#------------------------------------------------------------------------------
# commencement des subroutines
#------------------------------------------------------------------------------
# subroutine pour parcourir l'aborescence
sub parcoursarborescencefichiers {
my $path = shift(@_); # chemin vers le dossier en entrée
opendir(DIR, $path) or die "Probleme d'ouverture du dossier: $!\n";
my @files = readdir(DIR);
closedir(DIR);
#------------------------------------------------------------------------------
foreach my $file (@files) {
next if $file =~ /^\.\.?$/; #si . ou ..
$file = $path."/".$file;
#si $file est un dossier
if (-d $file) {
&parcoursarborescencefichiers($file); #recurse!
}
# faire le traitement si $file est un fichier
if (-f $file) {
# traiter les fichiers xml seulement
if ($file=~/^[^(fil)]+?\.xml$/) {
$nb_filesIN++;
print $file,"\n";
#lire le fichier xml
open(FILE,$file);
my $firstLine = <FILE>;
my $encodage = "";
#vérifier encodage du fichier xml
if($firstLine =~ /encoding= ?['"]([^\'"]+)['"]/) {
$encodage = $1; #extraire l'encodage
}
close(FILE);
# si on trouve l'encodage, le fichier est reouvert avec l'encodage correcte
if (!($encodage eq "")) {
open(FILE,"<:encoding($encodage)",$file);
my $texte = "";
#éliminer les retours à ligne dans le fichier [ \n et \r ]
while (my $ligne = <FILE>) {
$ligne =~ s/\n//g;
$ligne =~ s/\r//g;
$texte .= $ligne;
}
close FILE;
$texte =~ s/> *?</></g; # coller les balises
#------------------------------------------------------------------------------
# extraire rubrique, date et nom
$texte =~ /<channel>.*?<title>(.*?)<\/title>.*?<pubDate>(.+?)<\/pubDate>.*?<\/channel>/;
# nettoyer les rubriques
my $rubrique = &nettoyerRubriques($1);
print "RUBRIQUE : $rubrique\n";
# extraire la date
my $date = &nettoyerRubriques($2);
# nom du fichier
my $name = $file;
# uniquement les fichiers XML contenant les mises à jour
$name =~ s/.*?(20.*)/$1/;
#------------------------------------------------------------------------------
# ouvre des balises et écrire dans des fichiers de sortie
my $cheminXML=$res.$rubrique.".xml";
# si on n'a pas encore vu le rubrique on doit le créer
if (! -e $cheminXML) {
# créer un fichier
if (!open (FILEOUT,">:encoding(UTF-8)",$cheminXML)) {
die "Probleme a la creation du fichier $cheminXML : $!";
}
# ouverture des balises XML du début du fichier
print FILEOUT "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print FILEOUT "<PARCOURS>\n";
print FILEOUT "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
print FILEOUT "<$rubrique>\n";
print FILEOUT "<file>";
print FILEOUT "<name>$name</name>";
print FILEOUT "<date>$date</date>";
print FILEOUT "<items>";
close(FILEOUT);
${"DumpXML"."$rubrique"}="";
}
# si le fichier existe déjà
else {
if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML)) {
die "Problème a l'ouverture du fichier $cheminXML : $!\n";
}
print FILEOUT "<file>";
print FILEOUT "<name>$name</name>";
print FILEOUT "<date>$date</date>";
print FILEOUT "<items>";
close(FILEOUT);
}
#------------------------------------------------------------------------------
my $cheminXML_BAO2=$resBAO2.$rubrique.".xml";
# si on n'a pas encore vu le rubrique
if (! -e $cheminXML_BAO2) {
# créer un fichier
if (!open (FILEOUT,">:encoding(UTF-8)",$cheminXML_BAO2)) {
die "Probleme a la creation du fichier $cheminXML_BAO2 : $!\n";
}
# ouverture des balises XML du début du fichier
print FILEOUT "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
print FILEOUT "<PARCOURS>\n";
print FILEOUT "<NOM>Bienvenue, Poadey, Cavalcante</NOM>\n";
print FILEOUT "<$rubrique>\n";
print FILEOUT "<file>";
print FILEOUT "<name>$name</name>";
print FILEOUT "<date>$date</date>";
print FILEOUT "<items>";
close(FILEOUT);
${"DumpXML_tagged"."$rubrique"}="";
}
# si le fichier existe déjà
else {
if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML_BAO2)) {
die "Problème a l'ouverture du fichier $cheminXML_BAO2 : $!\n";
}
print FILEOUT "<file>";
print FILEOUT "<name>$file</name>";
print FILEOUT "<date>$date</date>";
print FILEOUT "<items>";
close(FILEOUT);
}
#------------------------------------------------------------------------------
# extractions des titres et descriptions
while ($texte =~ /<item>.*?<title>(.*?)<\/title>.*?<description>(.*?)<\/description>/g)
{
my $titre = $1;
my $description = $2;
$nb_itemsIN++;
#------------------------------------------------------------------------------
# nettoyer le texte
if (!(exists ($dicoTitre{$titre})) and !(exists ($dicoDescription{$description})))
{
$dicoTitre{$titre}++;
$dicoDescription{$description}++;
$titre = XML::Entities::decode('all', $titre);
$descritpion = XML::Entities::decode('all', $description);
$titre = HTML::Entities::decode($titre);
$description = HTML::Entities::decode($description);
$tmptexteBRUT.="$titre \n";
$tmptexteBRUT.="$description \n";
$tmptexteXML.="<item><title>$titre</title><description>$description</description></item>\n";
#--------------------------------------------------------------------------------------
# nettoyage des balises <description> pour supprimer les balises superflues
$tmptexteXML =~ s/<img.*?\/><\/description>/<\/description>/g;
$tmptexteBRUT =~ s/<img.*?\/> \n/\n/g;
}
if (!(($titre eq "") or ($description eq ""))) {
#------------------------------------------------------------------------------
# convertir si besoin en utf-8
if (uc($encodage) ne "UTF-8") {
utf8($titre);
utf8($description);
}
#------------------------------------------------------------------------------
# regarde si on a déjà vu le texte
if (!((exists $dicoTitre{$rubrique . $titre}) && (exists $dicoDescription{$rubrique . $description})))
{
$dicoTitre{$rubrique . $titre} = "1";
$dicoDescription{$rubrique . $description} = "1";
$nb_itemsOUT++;
#------------------------------------------------------------------------------
# faire l'etiquetage
my $titre_tagged = &treetagger($titre);
my $description_tagged = &treetagger($description);
open(LOG, ">>", "log_bao2.txt");
if(exists $dico_files{$file}){
$count_file = int($dico_files{$file});
$count_file++;
%dico_files = ($file => $count_file);
} else {
%dico_files = ($file => 1);
}
#creer l`objet date pour ecire les date dans le fichier de log
my $date_time = ctime();
#ecrire le fichier de log avec le nom du fichier et l`heure de lecture
print LOG $file." ".$dico_files{$file}."\t\t read on ".$date_time."\n";
# mettre dans les sorties xml
if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML)) {
die "Problème a l'ouverture du fichier $cheminXML : $!\n";
}
print FILEOUT "<item>\n";
print FILEOUT $tmptexteXML;
print FILEOUT "</item>\n";
close(FILEOUT);
#------------------------------------------------------------------------------
# créer un dump pour chaque rubrique
${"DumpXML" . $rubrique} .= $tmptexteXML."\n";
#------------------------------------------------------------------------------
# partie de sorties txt
my $cheminTXT = $res . $rubrique . ".txt";
# si on n'a pas encore vu la rubrique
if (! -e $cheminTXT) {
if (!open (FILEGLOBALTXT,">:encoding(iso-8859-15)",$cheminTXT)) {
die "Problème a l'ouverture du fichier $cheminTXT : $!\n";
}
# écrire dans le sortie txt
print FILEGLOBALTXT $tmptexteBRUT;
close(FILEGLOBALTXT);
}
# si on a déjà vu la rubrique
else {
if (!open (FILEGLOBALTXT,">>:encoding(iso-8859-15)",$cheminTXT)) {
die "Problème a l'ouverture du fichier $cheminTXT : $!\n";
}
# écrire dans la sortie txt
print FILEGLOBALTXT $tmptexteBRUT;
close(FILEGLOBALTXT);
}
if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML_BAO2)) {
die "Problème a l'ouverture du fichier $cheminXML_BAO2 : $!\n";
}
print FILEOUT "<item>\n";
print FILEOUT $tmptexteXML;
print FILEOUT "</item>\n";
close(FILEOUT);
# créer un dump pour chaque rubrique
${"DumpXML2_Tagged".$rubrique}.= $tmptexteXML."\n";
}
}
}
# fermer la balise file pour chaque fichier xml
if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML))
{
die "Problème a l'ouverture du fichier .$cheminXML : $!\n";
}
print FILEOUT "</items>";
print FILEOUT "</file>";
close(FILEOUT);
# fermer la balise les fichier xml etiqutée
if (!open (FILEOUT,">>:encoding(UTF-8)",$cheminXML_BAO2)) {
die "Problème a l'ouverture du fichier .$cheminXML_BAO2 : $!\n";
}
print FILEOUT "</items>";
print FILEOUT "</file>";
close(FILEOUT);
}
}
}
}
}
#------------------------------------------------------------------------------
# subroutine pour nettoyer des rubriques
#------------------------------------------------------------------------------
sub nettoyerRubriques {
my $rubrique = shift;
$rubrique =~ s/Le Monde.fr//g;
$rubrique =~ s/LeMonde.fr//g;
$rubrique =~ s/: Toute l'actualité sur//g;
$rubrique =~ s/É/e/g;
$rubrique =~ s/é/e/g;
$rubrique =~ s/è/e/g;
$rubrique =~ s/ê/a/g;
$rubrique =~ s/ë/e/g;
$rubrique =~ s/ï/i/g;
$rubrique =~ s/î/i/g;
$rubrique =~ s/à/a/g;
$rubrique =~ s/ô/o/g;
$rubrique =~ s/,/_/g;
$rubrique = uc($rubrique);
$rubrique =~ s/ //g;
$rubrique =~ s/[\.\:;\'\"\-]+//g;
return $rubrique;
}
#------------------------------------------------------------------------------
# subroutine pour tokenisation et etiquetage
#------------------------------------------------------------------------------
sub treetagger {
my $texte = shift;
my $temptag;
# créer un fichier temporaire pour tagger des morceaux de texte
open($temptag, ">:encoding(UTF-8)", "./temptag.txt");
print $temptag $texte;
close($temptag);
system("perl tokenise-utf8.pl ./temptag.txt | tree-tagger.exe -lemma -token -no-unknown -sgml ./french.par > treetagger.txt");
system("perl treetagger2xml-utf8.pl treetagger.txt utf-8");
open(TaggedOUT,"<:encoding(utf-8)","treetagger.txt.xml");
my $tagged_text = "";
#lire la ligne d'en tête du fichier xml étiqueté, pour éviter que cette ligne soit incluse dans le nouveau fichier xml
my $line_den_tete = <TaggedOUT>;
while (my $l = <TaggedOUT>) {
$tagged_text .= $l;
}
close(TaggedOUT);
return $tagged_text;
}
# fin des subroutines
#------------------------------------------------------------------------------
#------------------------------------------------------------------------------
Un aperçu des résultats de l'Outil 2
Les résultats de l'Outil 2 prennent plusieurs formes : .xml, .txt et .cnr (la sortie Cordial)
Un exemple d'une sortie TreeTagger au format XML.
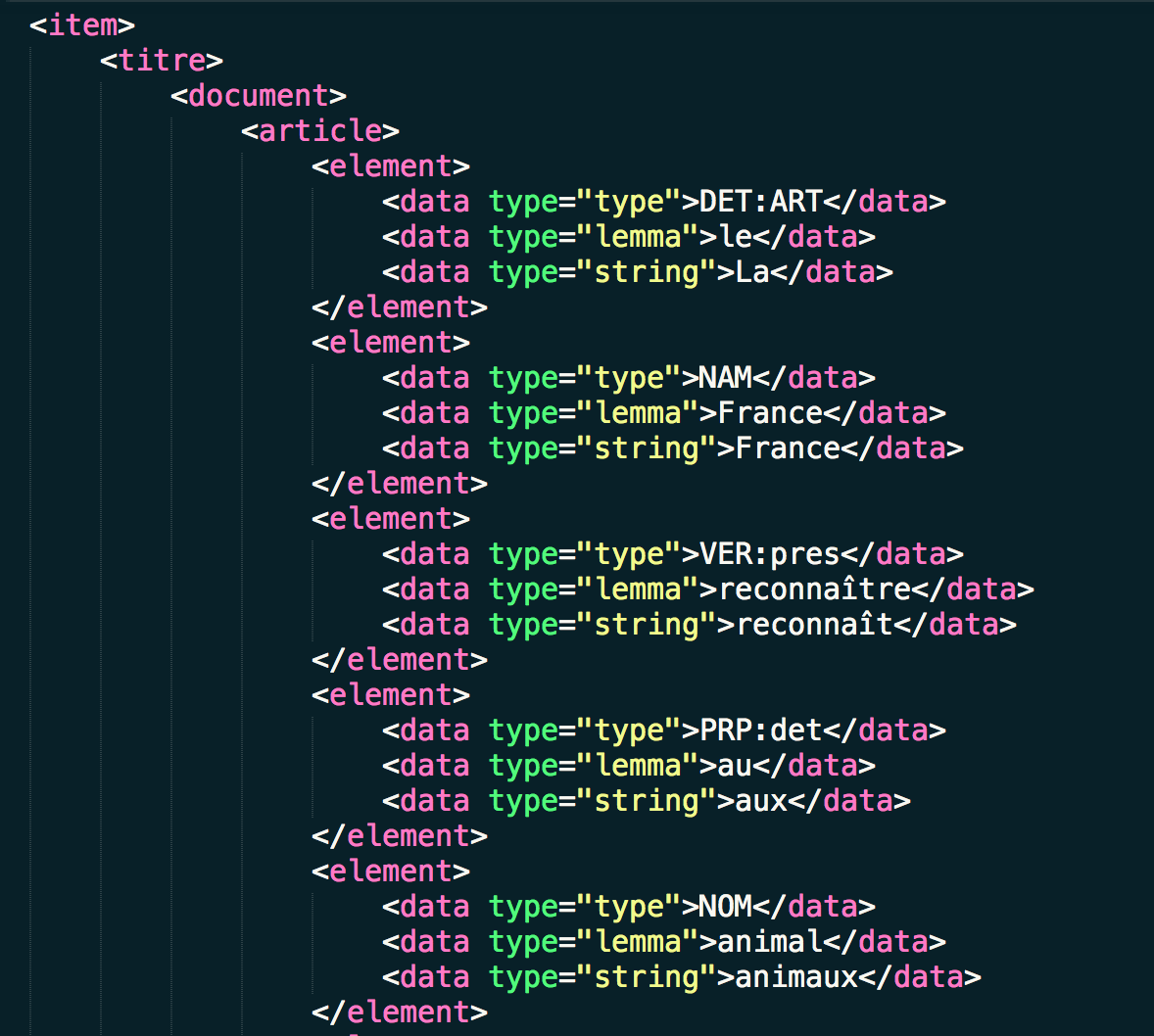
Un exemple de la sortie TXT(la même que celle de l'Outil 1)
Un exemple de la sortie Cordial au format CNR.

Que fait l'Outil 3 ?
L'Outil 3 est composée de deux* scripts différents, un pour chaque sortie (TreeTagger et Cordial). Les programmes cherchent à travers ces sorties des patrons morphosyntaxiques spécifiques (ex : nom-préposition-nom).
Un rappel des résultats dont l'Outil 3 a besoin :
Un exemple de sortie de TreeTagger
Un exemple de sortie de Cordial
Pour ce programme, on a eu deux approches différentes. Certains programmes ont besoin d'un fichier externe TXT qui contient les patrons morphosyntaxiques recherchés et d'autres sont inclus directement dans le script. Dans nos versions finales, on peut voir que nous avons utilisé la première option. Nous avons pensé qu'avoir les patrons dans un fichier externe était bien plus facile à modifier que réécrire les lignes de code correspondantes.
Cette partie contient également deux fichiers XSL qui ne contiennent pas de Perl mais qui arrivent à des résultats très similaires aux autres scripts Perl. XSL signifie Extensible Stylesheet Language. Les deux fichiers que nous avons sont des feuilles de style pour nos fichiers XML qui nous permet de montrer les éléments contenus dans les balises voulues.
L'algorithme de notre script consiste à trouver chaque item de la troisième colonne (l'étiquetage) et vérifie si oui ou non correspond au premier item de notre patron de recherche. Si c'est le cas, on continue pour l'item suivant et ainsi de suite jusqu'à ce que nous ayons trouvé tous les items de notre patron. Si tout correspond jusqu'à la fin de l'exploration du patron, la première colonne du fichier (associée à la troisième colonne correspondante) est extraite. Le diagramme ci-dessous, à lire de gauche à droite et de haut en bas, illustre cette procédure.
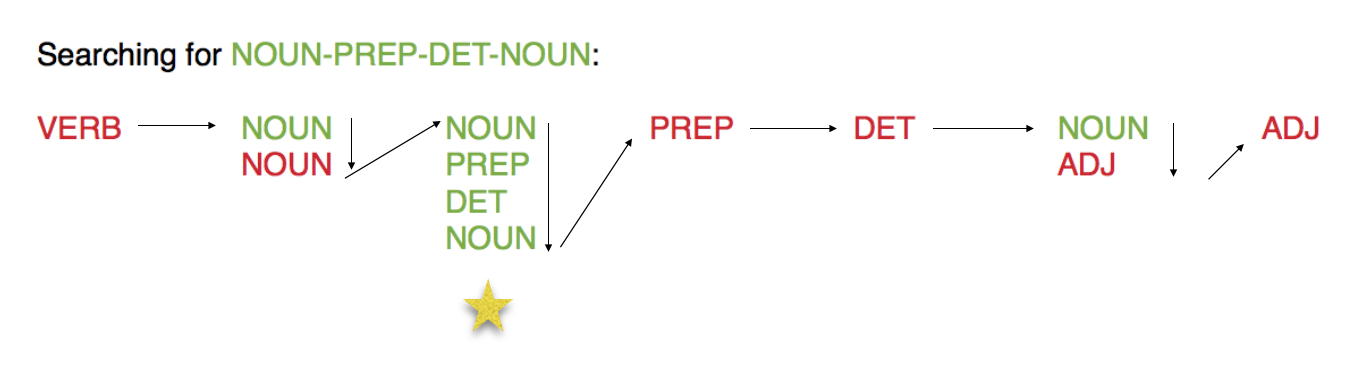
*Nous pouvons certainement écrire un seul script qui pourrait traiter les deux cas mais dans ce cas, il est mieux d'en avoir deux pour garder des données séparées et propres. Cependant, les deux scripts n'en sont pas moins très similaires.
Les méthodes de trois professeurs différents pour extraire les séquences morphosyntaxiques depuis les données obtenues via Cordial et TreeTagger.
Extraction des séquences morphosyntaxiques depuis les données Cordial
- #!/usr/bin/perl
- <<DOC;
- prend en entrée un fichier issu de treetagger
- et un fichier de patrons morphosyntaxiques et
- extrait suites de tokens correspondant aux patrons morpho-syntaxiques
- DOC
- open(FIC, $ARGV[0]) or die "impossible ouvrir $ARGV[0] : $!";
- print "choisis nom de fichier pour contenir termes extraits\n";
- my $fic=<STDIN>;
- open(FIC1, ">$fic");
- my $i=0;
- my $j=0;
- my $k=0;
- my @token=();
- while (<FIC>)
- {
- my $ligne=$_;
- chomp $ligne;
- my @liste=split(/\t/,$ligne);
- push(@token, $liste[$i++]." ");
- push(@lemme, "$liste[$i++]" ." ");
- push(@patron, "$liste[$i++]" ." ");
- $i=0;
- }
- #on a 3 listes @token, @lemme, @patron
- @sous_patron=();
- while (defined($element_patron=shift(@patron)))
- {
- $element_patron=~s/\n//;
- if ($element_patron !~ "PCTFORTE")
- {
- push(@sous_patron, $element_patron);
- $j++;
- next;
- }
- my @sous_token=@token[$k..$j-1];
- &cherche_patron(@sous_patron);
- @sous_patron=();
- $k=$j+1;
- #print "tape return pour continuer";
- #my $reponse=<STDIN>;
- $j++;
- }
- #=============================================
- sub cherche_patron
- {
- my @liste=@_;
- my $suite_de_patrons=join("",@liste);
- $z=0;
- $nb=0;
- open(FIC, "$ARGV[1]");
- while(<FIC>)
- {
- $nb=0;
- $ligne=$_;
- chomp $ligne;
- #print "voici le patron traité : $ligne\n";
- while ($ligne=~m/ /g) {$nb++};
- $nb++;
- while ($suite_de_patrons=~m/$ligne/g)
- {
- my $avant=substr ($suite_de_patrons, 0, pos($suite_de_patrons)-length($&));
- while ($avant=~m/ /g) {$z++};
- print FIC1 "@token[$k+$z..$k+$z+$nb-1]\n";
- #print "tape sur return pour continuer\n";
- #my $reponse=<STDIN>;
- $z=0;
- }
- }
- }
#!/usr/bin/perl
<<DOC;
prend en entrée un fichier issu de treetagger
et un fichier de patrons morphosyntaxiques et
extrait suites de tokens correspondant aux patrons morpho-syntaxiques
DOC
open(FIC, $ARGV[0]) or die "impossible ouvrir $ARGV[0] : $!";
print "choisis nom de fichier pour contenir termes extraits\n";
my $fic=<STDIN>;
open(FIC1, ">$fic");
my $i=0;
my $j=0;
my $k=0;
my @token=();
while (<FIC>)
{
my $ligne=$_;
chomp $ligne;
my @liste=split(/\t/,$ligne);
push(@token, $liste[$i++]." ");
push(@lemme, "$liste[$i++]" ." ");
push(@patron, "$liste[$i++]" ." ");
$i=0;
}
#on a 3 listes @token, @lemme, @patron
@sous_patron=();
while (defined($element_patron=shift(@patron)))
{
$element_patron=~s/\n//;
if ($element_patron !~ "PCTFORTE")
{
push(@sous_patron, $element_patron);
$j++;
next;
}
my @sous_token=@token[$k..$j-1];
&cherche_patron(@sous_patron);
@sous_patron=();
$k=$j+1;
#print "tape return pour continuer";
#my $reponse=<STDIN>;
$j++;
}
#=============================================
sub cherche_patron
{
my @liste=@_;
my $suite_de_patrons=join("",@liste);
$z=0;
$nb=0;
open(FIC, "$ARGV[1]");
while(<FIC>)
{
$nb=0;
$ligne=$_;
chomp $ligne;
#print "voici le patron traité : $ligne\n";
while ($ligne=~m/ /g) {$nb++};
$nb++;
while ($suite_de_patrons=~m/$ligne/g)
{
my $avant=substr ($suite_de_patrons, 0, pos($suite_de_patrons)-length($&));
while ($avant=~m/ /g) {$z++};
print FIC1 "@token[$k+$z..$k+$z+$nb-1]\n";
#print "tape sur return pour continuer\n";
#my $reponse=<STDIN>;
$z=0;
}
}
}
Deux scripts qui extraient des séquences morphosyntaxiques depuis les données TreeTagger et Cordial.
Le premier script extrait tout les "nom-adjectif" des données TreeTagger.
- open(FILE,"$ARGV[0]");
- #--------------------------------------------
- # le patron cherché ici est du type NOM ADJ"
- #--------------------------------------------
- my @lignes = <FILE>;
- close(FILE);
- while (@lignes) {
- my $ligne = shift(@lignes);
- chomp $ligne;
- my $sequence = "";
- my $longueur = 0;
- if ( $ligne =~ /<element><data type=\"type\">NOM<\/data><data type=\"lemma\">[^<]+<\/data><data type=\"string\">([^<]+)<\/data><\/element>/) {
- my $forme = $1;
- $sequence .= $forme;
- $longueur = 1;
- my $nextligne = $lignes[0];
- if ( $nextligne =~ /<element><data type=\"type\">ADJ<\/data><data type=\"lemma\">[^<]+<\/data><data type=\"string\">([^<]+)<\/data><\/element>/) {
- my $forme = $1;
- $sequence .= " " . $forme;
- $longueur = 2;
- }
- }
- if ($longueur == 2) {
- print $sequence . "\n";
- }
- }
open(FILE,"$ARGV[0]");
#--------------------------------------------
# le patron cherché ici est du type NOM ADJ"
#--------------------------------------------
my @lignes = <FILE>;
close(FILE);
while (@lignes) {
my $ligne = shift(@lignes);
chomp $ligne;
my $sequence = "";
my $longueur = 0;
if ( $ligne =~ /<element><data type=\"type\">NOM<\/data><data type=\"lemma\">[^<]+<\/data><data type=\"string\">([^<]+)<\/data><\/element>/) {
my $forme = $1;
$sequence .= $forme;
$longueur = 1;
my $nextligne = $lignes[0];
if ( $nextligne =~ /<element><data type=\"type\">ADJ<\/data><data type=\"lemma\">[^<]+<\/data><data type=\"string\">([^<]+)<\/data><\/element>/) {
my $forme = $1;
$sequence .= " " . $forme;
$longueur = 2;
}
}
if ($longueur == 2) {
print $sequence . "\n";
}
}
Le second script extrait tous les "nom-préposition-nom" des données Cordial.
- open(FILE,"$ARGV[0]");
- #--------------------------------------------
- # le patron cherché ici est du type NOM PREP NOM
- #--------------------------------------------
- my @lignes = <FILE>;
- close(FILE);
- while (@lignes) {
- my $ligne = shift(@lignes);
- chomp $ligne;
- my $sequence = "";
- my $longueur = 0;
- if ( $ligne =~ /^([^\t]+)\t[^\t]+\tNC.*/) {
- my $forme = $1;
- $sequence .= $forme;
- $longueur = 1;
- my $nextligne = $lignes[0];
- if ( $nextligne =~ /^([^\t]+)\t[^\t]+\tPREP.*/) {
- my $forme = $1;
- $sequence .= " " . $forme;
- $longueur = 2;
- my $next_nextligne = $lignes[1];
- if ( $next_nextligne =~ /^([^\t]+)\t[^\t]+\tNC.*/) {
- my $forme = $1;
- $sequence .= " " . $forme;
- $longueur = 3;
- }
- }
- }
- if ($longueur == 3) {
- print $sequence . "\n";
- }
- }
open(FILE,"$ARGV[0]");
#--------------------------------------------
# le patron cherché ici est du type NOM PREP NOM
#--------------------------------------------
my @lignes = <FILE>;
close(FILE);
while (@lignes) {
my $ligne = shift(@lignes);
chomp $ligne;
my $sequence = "";
my $longueur = 0;
if ( $ligne =~ /^([^\t]+)\t[^\t]+\tNC.*/) {
my $forme = $1;
$sequence .= $forme;
$longueur = 1;
my $nextligne = $lignes[0];
if ( $nextligne =~ /^([^\t]+)\t[^\t]+\tPREP.*/) {
my $forme = $1;
$sequence .= " " . $forme;
$longueur = 2;
my $next_nextligne = $lignes[1];
if ( $next_nextligne =~ /^([^\t]+)\t[^\t]+\tNC.*/) {
my $forme = $1;
$sequence .= " " . $forme;
$longueur = 3;
}
}
}
if ($longueur == 3) {
print $sequence . "\n";
}
}
Extraction des séquences morphosyntaxiques depuis les données TreeTagger.
- #/usr/bin/perl
- <<DOC;
- Nom : Rachid Belmouhoub
- Avril 2012
- usage : perl bao3_rb_new.pl fichier_tag fichier_motif
- DOC
- use strict;
- use utf8;
- use XML::LibXML;
- # Définition globale des encodage d'entrée et sortie du script à utf8
- binmode STDIN, ':encoding(utf8)';
- binmode STDOUT, ':encoding(utf8)';
- # On vérifie le nombre d'arguments de l'appel au script ($0 : le nom du script)
- if($#ARGV!=1){print "usage : perl $0 fichier_tag fichier_motif";exit;}
- # Enregistrement des arguments de la ligne de commande dans les variables idoines
- my $tag_file= shift @ARGV;
- my $patterns_file = shift @ARGV;
- # création de l'objet XML::XPath pour explorer le fichier de sortie tree-tagger XML
- my $xp = XML::LibXML->new(XML_LIBXML_RECOVER => 2);
- $xp->recover_silently(1);
- my $dom = $xp->load_xml( location => $tag_file );
- my $root = $dom->getDocumentElement();
- my $xpc = XML::LibXML::XPathContext->new($root);
- # Ouverture du fichiers de motifs
- open(PATTERNSFILE, $patterns_file) or die "can't open $patterns_file: $!\n";
- # lecture du fichier contenant les motifs, un motif par ligne (par exemple : NOM ADJ)
- while (my $ligne = <PATTERNSFILE>) {
- # Appel à la procédure d'extraction des motifs
- &extract_pattern($ligne);
- }
- # Fermeture du fichiers de motifs
- close(PATTERNSFILE);
- # routine de construction des chemins XPath
- sub construit_XPath{
- # On récupère la ligne du motif recherché
- my $local_ligne=shift @_;
- # initialisation du chemin XPath
- my $search_path="";
- # on supprime avec la fonction chomp un éventuel retour à la ligne
- chomp($local_ligne);
- # on élimine un éveltuel retour chariot hérité de windows
- $local_ligne=~ s/\r$//;
- # Construction au moyen de la fonction split d'un tableau dont chaque élément a pour valeur un élément du motif recherché
- my @tokens=split(/ /,$local_ligne);
- # On commence ici la construction du chemin XPath
- # Ce chemin correspond au premier noeud "element" de l'arbre XML qui répond au motif cherché
- $search_path="//element[contains(data[\@type=\"type\"],\"$tokens[0]\")]";
- # Initialisation du compteur pour la boucle de construction du chemin XPath
- my $i=1;
- while ($i < $#tokens) {
- $search_path.="[following-sibling::element[1][contains(data[\@type=\"type\"],\"$tokens[$i]\")]";
- $i++;
- }
- my $search_path_suffix="]";
- # on utilise l'opérateur x qui permet de répéter la chaine de caractère à sa gauche autant de fois que l'entier à sa droite,
- # soit $i fois $search_path_suffix
- $search_path_suffix=$search_path_suffix x $i;
- # le chemin XPath final
- $search_path.="[following-sibling::element[1][contains(data[\@type=\"type\"],\"".$tokens[$#tokens]."\")]"
- .$search_path_suffix;
- # print "$search_path\n";
- # on renvoie à la procédure appelante le chein XPath et le tableau des éléments du motif
- return ($search_path,@tokens);
- }
- # routine d'extraction du motif
- sub extract_pattern{
- # On récupère la ligne du motif recherché
- my $ext_pat_ligne= shift @_;
- # Appel de la fonction construit_XPath pour le motif lu à la ligne courrante du fichier de motif
- my ($search_path,@tokens) = &construit_XPath($ext_pat_ligne);
- # définition du nom du fichier de résultats pour le motif en utilisant la fonction join
- my $match_file = "res_extract-".join('_', @tokens).".txt";
- # Ouverture du fichiers de résultats encodé en UTF-8
- open(MATCHFILE,">:encoding(UTF-8)", "$match_file") or die "can't open $match_file: $!\n";
- # création de l'objet XML::XPath pour explorer le fichier de sortie tree-tagger XML
- # Parcours des noeuds du ficher XML correspondant au motif, au moyen de la méthode findnodes
- # qui prend pour argument le chemin XPath construit précédement
- # avec la fonction "construit_XPath"
- my @nodes=$root->findnodes($search_path);
- foreach my $noeud ( @nodes) {
- # Initialisation du chemin XPath relatif du noeud "data" contenant
- # la forme correspondant au premier élément du motif
- # Ce chemin est relatif au premier noeud "element" du bloc retourné
- # et pointe sur le troisième noeud "data" fils du noeud "element"
- # en l'identifiant par la valeur "string" de son attribut "type"
- my $form_xpath="";
- $form_xpath="./data[\@type=\"string\"]";
- # Initialisation du compteur pour la boucle d'éxtraction des formes correspondants
- # aux éléments suivants du motif
- my $following=0;
- # Recherche du noeud data contenant la forme correspondant au premier élément du motif
- # au moyen de la fonction "find" qui prend pour arguments:
- # 1. le chemin XPath relatif du noeud "data"
- # 2. le noeud en cours de traitement dans cette boucle foreach
- # la fonction "find" retourne par défaut une liste de noeuds, dans notre cas cette liste
- # ne contient qu'un seul élément que nous récupérons avec la fonction "get_node"
- # enfin nous en imprimons le contenu textuel au moyen de la méthode string_value
- print MATCHFILE $xpc->findvalue($form_xpath,$noeud);
- # Boucle d'éxtraction des formes correspondants aux éléments suivants du motif
- # On descend dans chaque noeud element du bloc
- while ( $following < $#tokens) {
- # Incrémentation du compteur $following de cette boucle d'éxtraction des formes
- $following++;
- # Construction du chemin XPath relatif du noeud "data" contenant
- # la forme correspondant à l'élément suivant du motif
- # Notez bien l'utilisation du compteur $folowing tant dans la condition de la boucle ci-dessus
- # que dans la construction du chemin relatif XPath
- my $following_elmt="following-sibling::element[".$following."]";
- $form_xpath=$following_elmt."/data[\@type=\"string\"]";
- # Impression du contenu textuel du noeud data contenant la forme correspondant à l'élément suivant du motif
- print MATCHFILE " ",$xpc->findvalue($form_xpath,$noeud);
- # Incrémentation du compteur $following de cette boucle d'éxtraction des formes
- # $following++;
- }
- print MATCHFILE "\n";
- }
- # Fermeture du fichiers de motifs
- close(MATCHFILE);
- }
#/usr/bin/perl
<<DOC;
Nom : Rachid Belmouhoub
Avril 2012
usage : perl bao3_rb_new.pl fichier_tag fichier_motif
DOC
use strict;
use utf8;
use XML::LibXML;
# Définition globale des encodage d'entrée et sortie du script à utf8
binmode STDIN, ':encoding(utf8)';
binmode STDOUT, ':encoding(utf8)';
# On vérifie le nombre d'arguments de l'appel au script ($0 : le nom du script)
if($#ARGV!=1){print "usage : perl $0 fichier_tag fichier_motif";exit;}
# Enregistrement des arguments de la ligne de commande dans les variables idoines
my $tag_file= shift @ARGV;
my $patterns_file = shift @ARGV;
# création de l'objet XML::XPath pour explorer le fichier de sortie tree-tagger XML
my $xp = XML::LibXML->new(XML_LIBXML_RECOVER => 2);
$xp->recover_silently(1);
my $dom = $xp->load_xml( location => $tag_file );
my $root = $dom->getDocumentElement();
my $xpc = XML::LibXML::XPathContext->new($root);
# Ouverture du fichiers de motifs
open(PATTERNSFILE, $patterns_file) or die "can't open $patterns_file: $!\n";
# lecture du fichier contenant les motifs, un motif par ligne (par exemple : NOM ADJ)
while (my $ligne = <PATTERNSFILE>) {
# Appel à la procédure d'extraction des motifs
&extract_pattern($ligne);
}
# Fermeture du fichiers de motifs
close(PATTERNSFILE);
# routine de construction des chemins XPath
sub construit_XPath{
# On récupère la ligne du motif recherché
my $local_ligne=shift @_;
# initialisation du chemin XPath
my $search_path="";
# on supprime avec la fonction chomp un éventuel retour à la ligne
chomp($local_ligne);
# on élimine un éveltuel retour chariot hérité de windows
$local_ligne=~ s/\r$//;
# Construction au moyen de la fonction split d'un tableau dont chaque élément a pour valeur un élément du motif recherché
my @tokens=split(/ /,$local_ligne);
# On commence ici la construction du chemin XPath
# Ce chemin correspond au premier noeud "element" de l'arbre XML qui répond au motif cherché
$search_path="//element[contains(data[\@type=\"type\"],\"$tokens[0]\")]";
# Initialisation du compteur pour la boucle de construction du chemin XPath
my $i=1;
while ($i < $#tokens) {
$search_path.="[following-sibling::element[1][contains(data[\@type=\"type\"],\"$tokens[$i]\")]";
$i++;
}
my $search_path_suffix="]";
# on utilise l'opérateur x qui permet de répéter la chaine de caractère à sa gauche autant de fois que l'entier à sa droite,
# soit $i fois $search_path_suffix
$search_path_suffix=$search_path_suffix x $i;
# le chemin XPath final
$search_path.="[following-sibling::element[1][contains(data[\@type=\"type\"],\"".$tokens[$#tokens]."\")]"
.$search_path_suffix;
# print "$search_path\n";
# on renvoie à la procédure appelante le chein XPath et le tableau des éléments du motif
return ($search_path,@tokens);
}
# routine d'extraction du motif
sub extract_pattern{
# On récupère la ligne du motif recherché
my $ext_pat_ligne= shift @_;
# Appel de la fonction construit_XPath pour le motif lu à la ligne courrante du fichier de motif
my ($search_path,@tokens) = &construit_XPath($ext_pat_ligne);
# définition du nom du fichier de résultats pour le motif en utilisant la fonction join
my $match_file = "res_extract-".join('_', @tokens).".txt";
# Ouverture du fichiers de résultats encodé en UTF-8
open(MATCHFILE,">:encoding(UTF-8)", "$match_file") or die "can't open $match_file: $!\n";
# création de l'objet XML::XPath pour explorer le fichier de sortie tree-tagger XML
# Parcours des noeuds du ficher XML correspondant au motif, au moyen de la méthode findnodes
# qui prend pour argument le chemin XPath construit précédement
# avec la fonction "construit_XPath"
my @nodes=$root->findnodes($search_path);
foreach my $noeud ( @nodes) {
# Initialisation du chemin XPath relatif du noeud "data" contenant
# la forme correspondant au premier élément du motif
# Ce chemin est relatif au premier noeud "element" du bloc retourné
# et pointe sur le troisième noeud "data" fils du noeud "element"
# en l'identifiant par la valeur "string" de son attribut "type"
my $form_xpath="";
$form_xpath="./data[\@type=\"string\"]";
# Initialisation du compteur pour la boucle d'éxtraction des formes correspondants
# aux éléments suivants du motif
my $following=0;
# Recherche du noeud data contenant la forme correspondant au premier élément du motif
# au moyen de la fonction "find" qui prend pour arguments:
# 1. le chemin XPath relatif du noeud "data"
# 2. le noeud en cours de traitement dans cette boucle foreach
# la fonction "find" retourne par défaut une liste de noeuds, dans notre cas cette liste
# ne contient qu'un seul élément que nous récupérons avec la fonction "get_node"
# enfin nous en imprimons le contenu textuel au moyen de la méthode string_value
print MATCHFILE $xpc->findvalue($form_xpath,$noeud);
# Boucle d'éxtraction des formes correspondants aux éléments suivants du motif
# On descend dans chaque noeud element du bloc
while ( $following < $#tokens) {
# Incrémentation du compteur $following de cette boucle d'éxtraction des formes
$following++;
# Construction du chemin XPath relatif du noeud "data" contenant
# la forme correspondant à l'élément suivant du motif
# Notez bien l'utilisation du compteur $folowing tant dans la condition de la boucle ci-dessus
# que dans la construction du chemin relatif XPath
my $following_elmt="following-sibling::element[".$following."]";
$form_xpath=$following_elmt."/data[\@type=\"string\"]";
# Impression du contenu textuel du noeud data contenant la forme correspondant à l'élément suivant du motif
print MATCHFILE " ",$xpc->findvalue($form_xpath,$noeud);
# Incrémentation du compteur $following de cette boucle d'éxtraction des formes
# $following++;
}
print MATCHFILE "\n";
}
# Fermeture du fichiers de motifs
close(MATCHFILE);
}
Au lieu d'utiliser Perl, on peut aussi utiliser XPATH pour extraire nos séquences.
Pour créer une page HTML qui montre les séquences, on peut utiliser xsltproc via la commande suivante :
xsltproc stylesheet.xsl xml_file.xml > sequence.html
Cette feuille de style permet d'extraire tous les "nom-prépostion-nom" en utilisant XPATH.
- <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
- <xsl:output method="html"/>
- <xsl:template match="/">
- <html>
- <body bgcolor="#81808E">
- <table align="center" bgcolor="white" border="1" bordercolor="#3300FF" width="50%">
- <tr bgcolor="black">
- <td valign="top" width="90%">
- <font color="white">
- <h1>Extraction de patron
- <font color="red">
- <b>NOM</b></font>
- <xsl:text/>
- <font color="blue">
- <b>PRP</b>
- </font>
- <xsl:text/>
- <font color="red">
- <b>NOM</b>
- </font>
- </h1>
- </font>
- </td>
- </tr>
- <tr>
- <td>
- <blockquote>
- <xsl:apply-templates select="PARCOURS/ETIQUETAGE/file"/>
- </blockquote>
- </td>
- </tr>
- </table>
- </body>
- </html>
- </xsl:template>
- <xsl:template match="file">
- <xsl:for-each select="element">
- <xsl:if test="(./data[contains(text(),'NOM')])">
- <xsl:variable name="p1" select="./data[3]/text()"/>
- <xsl:if test="following-sibling::element[1][./data[contains(text(),'PRP')]]">
- <xsl:variable name="p2" select="following-sibling::element[1]/data[3]/text()"/>
- <xsl:if test="following-sibling::element[2][./data[contains(text(),'NOM')]]">
- <xsl:variable name="p3" select="following-sibling::element[2]/data[3]/text()"/>
- <font color="red">
- <xsl:value-of select="$p1"/>
- </font>
- <xsl:text/>
- <font color="blue">
- <xsl:value-of select="$p2"/>
- </font>
- <xsl:text/>
- <font color="red">
- <xsl:value-of select="$p3"/>
- </font>
- <br/>
- <xsl:text/>
- </xsl:if>
- </xsl:if>
- </xsl:if>
- </xsl:for-each>
- </xsl:template>
- </xsl:stylesheet>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="html"/>
<xsl:template match="/">
<html>
<body bgcolor="#81808E">
<table align="center" bgcolor="white" border="1" bordercolor="#3300FF" width="50%">
<tr bgcolor="black">
<td valign="top" width="90%">
<font color="white">
<h1>Extraction de patron
<font color="red">
<b>NOM</b></font>
<xsl:text/>
<font color="blue">
<b>PRP</b>
</font>
<xsl:text/>
<font color="red">
<b>NOM</b>
</font>
</h1>
</font>
</td>
</tr>
<tr>
<td>
<blockquote>
<xsl:apply-templates select="PARCOURS/ETIQUETAGE/file"/>
</blockquote>
</td>
</tr>
</table>
</body>
</html>
</xsl:template>
<xsl:template match="file">
<xsl:for-each select="element">
<xsl:if test="(./data[contains(text(),'NOM')])">
<xsl:variable name="p1" select="./data[3]/text()"/>
<xsl:if test="following-sibling::element[1][./data[contains(text(),'PRP')]]">
<xsl:variable name="p2" select="following-sibling::element[1]/data[3]/text()"/>
<xsl:if test="following-sibling::element[2][./data[contains(text(),'NOM')]]">
<xsl:variable name="p3" select="following-sibling::element[2]/data[3]/text()"/>
<font color="red">
<xsl:value-of select="$p1"/>
</font>
<xsl:text/>
<font color="blue">
<xsl:value-of select="$p2"/>
</font>
<xsl:text/>
<font color="red">
<xsl:value-of select="$p3"/>
</font>
<br/>
<xsl:text/>
</xsl:if>
</xsl:if>
</xsl:if>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>Cette feuille de style permet d'extraire tous les "nom-adjectif" en utilisant XPATH.
- <xsl:stylesheet version="2.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
- <xsl:output method="html"/>
- <xsl:template match="/">
- <html>
- <body bgcolor="#81808E">
- <table align="center" bgcolor="white" border="1" bordercolor="#3300FF" width="50%">
- <tr bgcolor="black">
- <td valign="top" width="90%">
- <font color="white">
- <h1>Extraction de patron
- <font color="red">
- <b>NOM</b></font>
- <font color="blue">
- <b>ADJ</b>
- </font>
- </h1>
- </font>
- </td>
- </tr>
- <tr>
- <td>
- <blockquote>
- <xsl:apply-templates select="./PARCOURS/ETIQUETAGE/file/element"/>
- </blockquote>
- </td>
- </tr>
- </table>
- </body>
- </html>
- </xsl:template>
- <xsl:template match="element">
- <xsl:choose>
- <xsl:when test="(./data[contains(text(),'NOM')]) and (following-sibling::element[1][./data[contains(text(),'ADJ')]])">
- <font color="red">
- <xsl:value-of select="./data[3]"/>
- </font>
- <xsl:text/>
- </xsl:when>
- <xsl:when test="(./data[contains(text(),'ADJ')]) and (preceding-sibling::element[1][./data[contains(text(),'NOM')]])">
- <font color="blue">
- <xsl:value-of select="./data[3]"/>
- </font>
- <br/>
- </xsl:when>
- </xsl:choose>
- </xsl:template>
- </xsl:stylesheet>
<xsl:stylesheet version="2.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="html"/>
<xsl:template match="/">
<html>
<body bgcolor="#81808E">
<table align="center" bgcolor="white" border="1" bordercolor="#3300FF" width="50%">
<tr bgcolor="black">
<td valign="top" width="90%">
<font color="white">
<h1>Extraction de patron
<font color="red">
<b>NOM</b></font>
<font color="blue">
<b>ADJ</b>
</font>
</h1>
</font>
</td>
</tr>
<tr>
<td>
<blockquote>
<xsl:apply-templates select="./PARCOURS/ETIQUETAGE/file/element"/>
</blockquote>
</td>
</tr>
</table>
</body>
</html>
</xsl:template>
<xsl:template match="element">
<xsl:choose>
<xsl:when test="(./data[contains(text(),'NOM')]) and (following-sibling::element[1][./data[contains(text(),'ADJ')]])">
<font color="red">
<xsl:value-of select="./data[3]"/>
</font>
<xsl:text/>
</xsl:when>
<xsl:when test="(./data[contains(text(),'ADJ')]) and (preceding-sibling::element[1][./data[contains(text(),'NOM')]])">
<font color="blue">
<xsl:value-of select="./data[3]"/>
</font>
<br/>
</xsl:when>
</xsl:choose>
</xsl:template>
</xsl:stylesheet>Scripts basés sur ceux des professeurs pour améliorer l'extraction des patrons morphosyntaxiques des résultats TreeTagger et Cordial.
En cours, nous avons vu trois manières d'utiliser Perl en extrayant les syntagmes recherchés. Ces trois scripts fonctionnent de manière similaire en écrivant le patron directement dans les scripts et en cherchant un seul patron uniquement.
Ici, nous proposons deux scripts très similaires que nous avons créés. Ces scripts sont différents des versions des professeurs car nous pouvons chercher plusieurs patrons et ceux-ci peuvent être de longueur non déterminée au préalable.
- use strict;
- use warnings;
- #--------------------------------------------------------------
- # This script allows the user to search for as many morphosyntactic patterns
- # (of any/varying length) as desired from the Cordial results of tool 2
- # usage: perl ourversion1.pl patron_test.txt
- #--------------------------------------------------------------
- open(FILE,"$ARGV[0]"); # the cordial tagged text
- open(FILE2,"$ARGV[1]"); # the list of patterns
- #--------------------------------------------------------------
- # the patterns searched for are in the file patron_test.txt
- #--------------------------------------------------------------
- my @lignes = <FILE>;
- my @patrons = <FILE2>;
- close(FILE);
- close(FILE2);
- while (@lignes) {
- my $ligne = shift(@lignes);
- chomp $ligne;
- for (my $i = 0; $i < scalar@patrons; $i++) {
- my $sequence = "";
- my $forme = "";
- my $longueur = 0;
- my @split_patrons = split(' ', @patrons[$i]);
- if ($ligne =~ /^([^\t]+)\t[^\t]+\t$split_patrons[0].*/) {
- $forme = $1;
- $sequence .= $forme;
- $longueur = 1;
- for (my $j = 1; $j < scalar@split_patrons; $j++) {
- if ($lignes[$j-1] =~ /^([^\t]+)\t[^\t]+\t$split_patrons[$j].*/) {
- $forme = $1;
- $sequence .= " " . $forme;
- $longueur++;
- }
- }
- }
- if ($longueur == scalar@split_patrons) {
- print "\n[" . $sequence . "]\n";
- }
- }
- }
- close FILE;
- close FILE2;
use strict;
use warnings;
#--------------------------------------------------------------
# This script allows the user to search for as many morphosyntactic patterns
# (of any/varying length) as desired from the Cordial results of tool 2
# usage: perl ourversion1.pl patron_test.txt
#--------------------------------------------------------------
open(FILE,"$ARGV[0]"); # the cordial tagged text
open(FILE2,"$ARGV[1]"); # the list of patterns
#--------------------------------------------------------------
# the patterns searched for are in the file patron_test.txt
#--------------------------------------------------------------
my @lignes = <FILE>;
my @patrons = <FILE2>;
close(FILE);
close(FILE2);
while (@lignes) {
my $ligne = shift(@lignes);
chomp $ligne;
for (my $i = 0; $i < scalar@patrons; $i++) {
my $sequence = "";
my $forme = "";
my $longueur = 0;
my @split_patrons = split(' ', @patrons[$i]);
if ($ligne =~ /^([^\t]+)\t[^\t]+\t$split_patrons[0].*/) {
$forme = $1;
$sequence .= $forme;
$longueur = 1;
for (my $j = 1; $j < scalar@split_patrons; $j++) {
if ($lignes[$j-1] =~ /^([^\t]+)\t[^\t]+\t$split_patrons[$j].*/) {
$forme = $1;
$sequence .= " " . $forme;
$longueur++;
}
}
}
if ($longueur == scalar@split_patrons) {
print "\n[" . $sequence . "]\n";
}
}
}
close FILE;
close FILE2;
Une deuxième option :
- #! /usr/bin/perl
- use strict;
- open(PATRONS, "$ARGV[0]");
- open(CORDIAL, "$ARGV[1]");
- open(CORDIAL_BKP, "$ARGV[1]");
- # créer fichier de résultats
- open my $final_result, '>>', "results.txt";
- my $terme;
- my @tags;
- # lire lignes du fichier de patrons
- while(chomp($terme=<PATRONS>)){
- # séparer les patrons de la ligne lue
- @tags = split(" ", $terme);
- my @LISTE;
- # lire le fichier étiquetté
- while(@LISTE = split(/\t/, <CORDIAL>)){
- # comparer les patrons du texte avec la patrons recherché
- if($LISTE[2] =~ m/$tags[0]/){
- # repérer position où le premier patron a été trouvé
- my $position = tell(CORDIAL);
- # continuer lecture à partir de $position
- seek(CORDIAL_BKP, $position, 0);
- my $compteur = 0;
- my $result="";
- # lire la séquence de patrons
- foreach my $tag (@tags){
- if($LISTE[2]=~ m/$tag/){
- # stocker résultat
- $result .= $LISTE[0]." ";
- # lire ligne suivant
- @LISTE = split(/\t/, <CORDIAL_BKP>);
- $compteur++;
- # si vrai, l`analyse est finie
- if($compteur == @tags){
- # écrire résultat
- print $final_result $result."\n";
- }
- }
- }
- }
- }
- seek(CORDIAL, 0, 0);
- }
- close(CORDIAL);
- close(PATRONS);
#! /usr/bin/perl
use strict;
open(PATRONS, "$ARGV[0]");
open(CORDIAL, "$ARGV[1]");
open(CORDIAL_BKP, "$ARGV[1]");
# créer fichier de résultats
open my $final_result, '>>', "results.txt";
my $terme;
my @tags;
# lire lignes du fichier de patrons
while(chomp($terme=<PATRONS>)){
# séparer les patrons de la ligne lue
@tags = split(" ", $terme);
my @LISTE;
# lire le fichier étiquetté
while(@LISTE = split(/\t/, <CORDIAL>)){
# comparer les patrons du texte avec la patrons recherché
if($LISTE[2] =~ m/$tags[0]/){
# repérer position où le premier patron a été trouvé
my $position = tell(CORDIAL);
# continuer lecture à partir de $position
seek(CORDIAL_BKP, $position, 0);
my $compteur = 0;
my $result="";
# lire la séquence de patrons
foreach my $tag (@tags){
if($LISTE[2]=~ m/$tag/){
# stocker résultat
$result .= $LISTE[0]." ";
# lire ligne suivant
@LISTE = split(/\t/, <CORDIAL_BKP>);
$compteur++;
# si vrai, l`analyse est finie
if($compteur == @tags){
# écrire résultat
print $final_result $result."\n";
}
}
}
}
}
seek(CORDIAL, 0, 0);
}
close(CORDIAL);
close(PATRONS);Les patrons utilisés pour l'extraction des syntagmes
Nous avons utilisés plusieurs patrons différents avec ":" . En voici quelques-uns :
NPMS PCTFORTE NCMS PREP ADJIND NCMIN
VINF DETDMS NCMS PCTFORTE DETDPIG NCFP DETDMS ADJNUM NCMIN
NPI PCTFORTE DETDMS NCMS ADV VINDP3S ADV COO VINDP3S
Voici la liste complète ici.
Patron utilisé : N[A-Z]+ ADJ[A-Z]+
Patron utilisé : N[A-Z]+ PREP DET[A-Z]+ N[A-Z]+
Patron utilisé : .*?que.*
Syntagmes extraits
Nous avons utilisés plusieurs patrons différents avec ":" . En voici quelques-uns :
NPMS PCTFORTE NCMS PREP ADJIND NCMIN
VINF DETDMS NCMS PCTFORTE DETDPIG NCFP DETDMS ADJNUM NCMIN
NPI PCTFORTE DETDMS NCMS ADV VINDP3S ADV COO VINDP3S
Voici la liste complète ici.
La liste des résultats avec ":" .
Patron utilisé : N[A-Z]+ ADJ[A-Z]+
La liste des résultats NOM-AD.
Patron utilisé: N[A-Z]+ PREP DET[A-Z]+ N[A-Z]+
La liste des résultats NOM-PREP-DET-NOM.
Patron utlisé : .*?que.*
La liste des résultats VERBE-CONJUNCTION .
Comment créer ces graphes ?
Le projet Boîte à Outils arrive à sa fin et pour clore cette série de traitements textuels, nous allons construire des graphes.
L'Outil 4 utilise un programme externe pour Windows qui permet de créer des graphes en utilisant les résultats de l'Outil 3. Ces graphes nous aident à avoir une représentation visuelle de nos patrons trouvés dans le texte.
La construction de ces graphes a pour objectif d'illustrer le comportement d'un token et/ou d'un type morpho-syntaxique spécifique pour lesquels nous avons fait des suppositions linguistiques.
Ce type de représentation visuelle nous permet d'avoir une notion plus claire de comment les patrons s'articulent entre eux. Nous pouvons, par exemple, utiliser la représentation graphique qui met en évidence les relations entretenues par une forme donnée aux niveaux syntagmatique et paradigmatique.
Prenons par exemple le graphe ci-dessous confectionné avec des données extraites de la rubrique POLITIQUE. Nous avons choisi des énoncés où le nom du président François Hollande apparaît. Afin de faciliter la visualisation et la compréhension du graphique, nous avons utilisé un nombre réduit de phrases.
Les flèches rouges indiquent des exemples d'énoncés négatifs, alors que les flèches vertes indiquent des énoncés positifs. La flèche mauve, à droite, indique une transition possible dans l'axe paradigmatique.
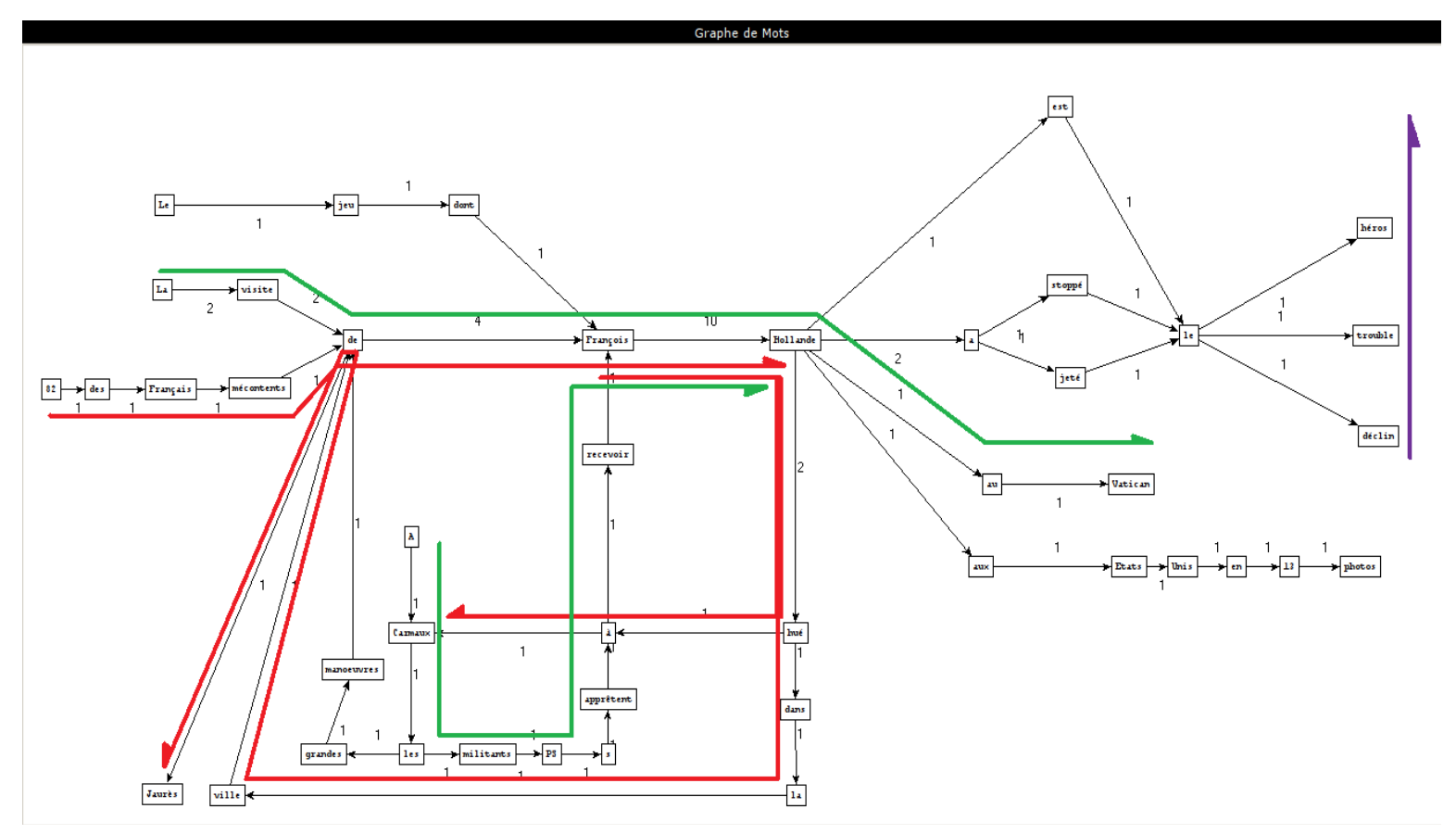
Une brève analyse du graphe peut nous suffire à identifier plusieurs constructions syntaxiquement intéressantes.
Par exemple, nous pouvons remarquer que les changements dans l'axe paradigmatique peuvent créer des énoncés "étranges" mais pas agrammaticaux.
Nous pouvons par exemple nous amuser en créant de nouveaux énoncés en suivant les différents parcours proposés par les flèches. Il suffit de changer la direction lorsque l'on trouve une bifurcation.
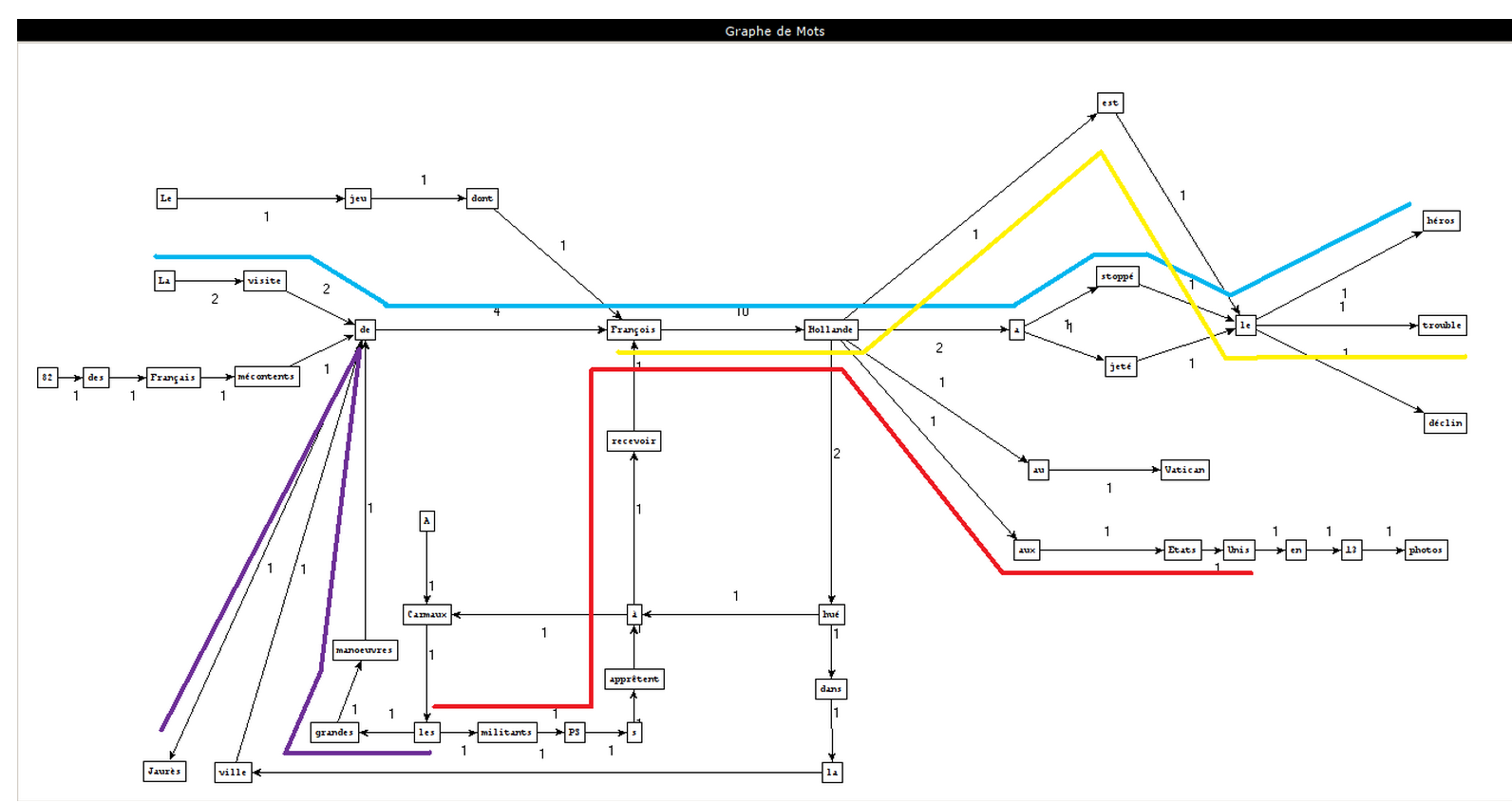
Obs.: les énoncés ci-dessus ont été produits à titre seulement illustratif et n'expriment aucune position politique.
Cette expérience ne présente pas les mêmes effets sur l'axe syntagmatique. L'inversement de formes voisines sur cet axe engendre dans la plupart des cas soit des énoncés agrammaticaux, soit des syntagmes avec une valeur différente sémantiquement.
Cela s'explique par le fait que les constructions parallèles sur l'axe paradigmatique appartiennent très souvent à la même classe grammaticale.
Sur la représentation en graphe, ces types de structure se trouvent alignés avec des flèches qui partent dans la même direction, comme nous pouvons le voir dans les exemples ci-dessous :
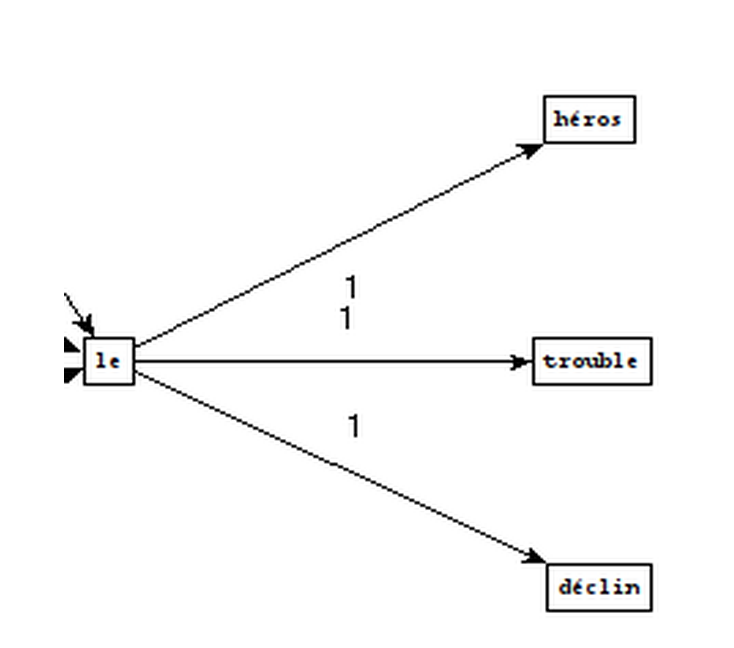

Il faut remarquer que même un alignement paradigmatique peut aussi contenir des éléments des types distincts, et dans ce cas aucun changement n'est possible.
Par exemple :
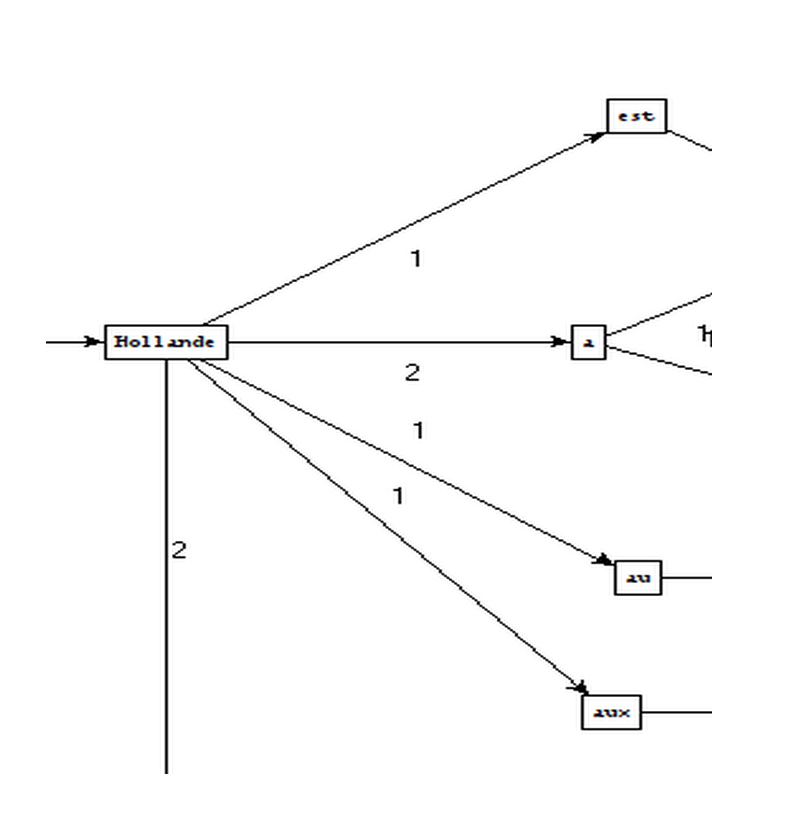
*Comme nous n'utilisons pas tous Windows, nous avons lancé ce programme via Wine.
noun-adj
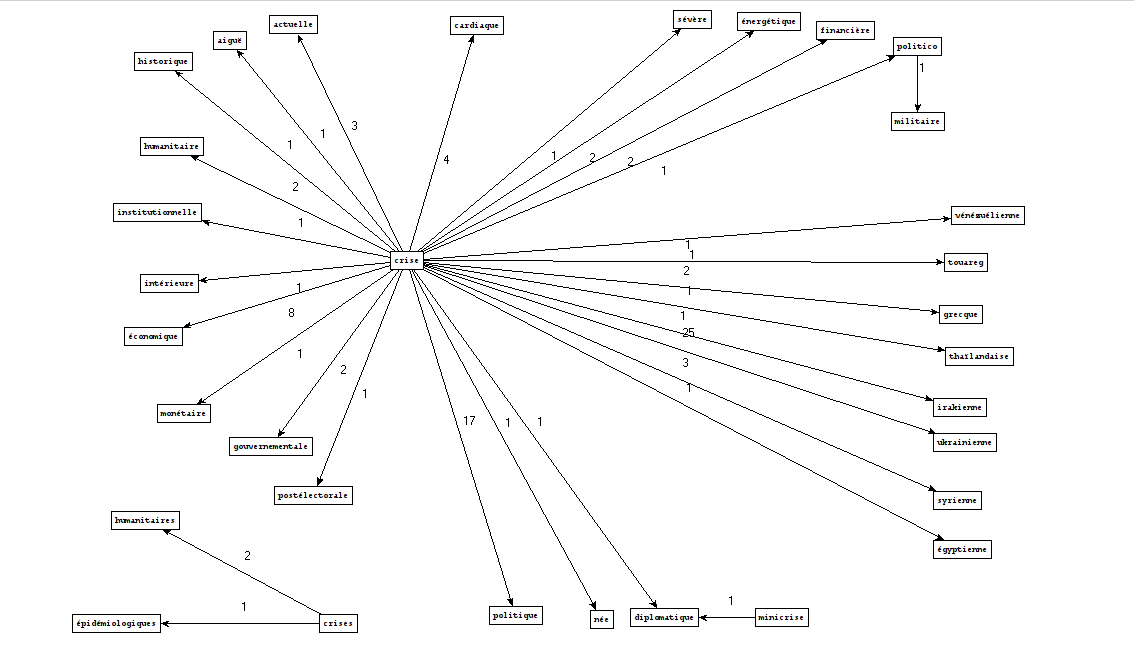
Nous avons choisi de faire tourner notre Outil 3 dans notre rubrique INTERNATIONAL avec le patron NOM-ADJ pour récupérer toutes les séquences morphosyntaxiques contenant un nom suivi d’un adjectif.
Puis dans l'Outil 4, nous avons choisi comme motif le nom « crise » suivi de tous les adjectifs qui le suit pour établir le graphe. Nous sommes partis de l’hypothèse que, dans le contexte économique actuel auquel nous faisons face dans le monde entier, nous trouverions beaucoup d’occurrences du type « crise économique ». Comme nous pouvons le constater sur le graphe, nous avons 8 occurrences de ce syntagme dans la rubrique. Cela reste finalement un très infime résultat comparé à « crise ukrainienne ». En effet, en 2014, les événements qui se sont passés en Ukraine ont beaucoup bouleversé le monde.
Mais, même sans regarder le contexte dans lequel le monde était politiquement ou économiquement, on se rend compte avec ce graphe qu’on va plus souvent avoir « crise + nationalité » que « crise économique » comme on s’y attendait. Finalement, on va plutôt désigner directement où la crise se passe et le contexte global du texte dira de quel type de crise il s’agit. Mais d’après les résultats trouvés, quasiment tous les syntagmes trouvés font référence à un contexte politique ou économique.
Cependant, la surprise a été de retrouver 4 occurrences de « crise cardiaque » dans notre graphe. On ne s’attendait absolument pas à trouver un contexte médical dans nos résultats. Sans vérifier dans le corpus et en ne se fiant qu’au graphe et à la rubrique dans laquelle nous avons fait nos recherches, on peut supposer que des personnes importantes au niveau international ont fait une crise cardiaque.
On a également 3 occurrences du motif au pluriel (« crises ») mais qui, a priori, ne relèvent pas non plus du domaine économique ou politique. Le domaine médical (« épidémiologiques ») et peut-être aussi social (« humanitaires ») semblent être les contextes qui ressortent à travers ces syntagmes. Mais les occurrences au pluriel ne sont vraiment pas significatives pour toute une année entière, nous pensons donc que cela ne nécessite pas vraiment une analyse plus poussée.
NOM-PREP-DET-NOM
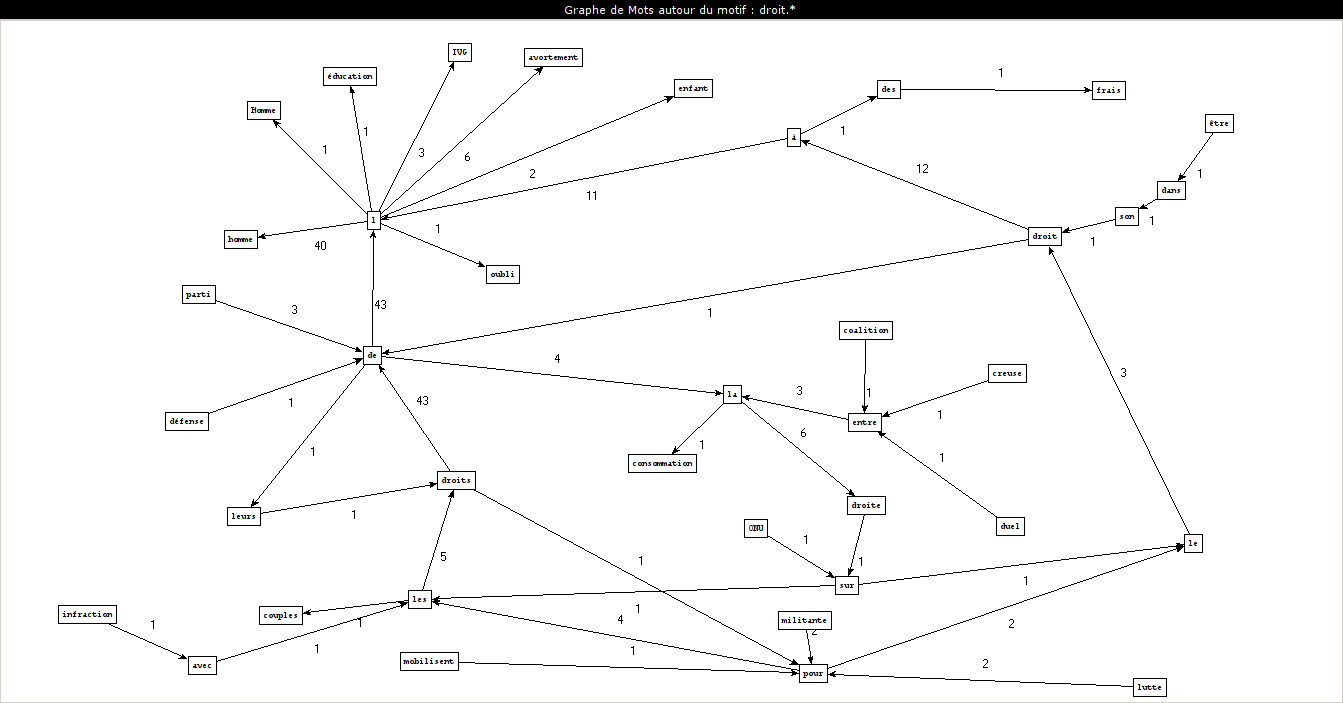
Avec le motif droit.*, nous voulions accéder au contexte politique/législatif du corpus de la rubrique INTERNATIONAL. Nous constatons en effet que le syntagme « droits de l’homme » apparaît 41 fois (si on ne différencie pas Homme et homme). La plupart des syntagmes trouvés autour de ce motif ont le mot « droit(s) » en premier comme « droit à » ou « droit de » suivi de quelque chose d’autre. Néanmoins, on en trouve quelques-uns où il se trouve à la fin comme « être dans son droit » ou « lutte pour le droit ».
On se rend compte que dans le premier cas, on va plutôt faire référence à tout ce qui est législatif, en indiquant des lois qui ont déjà été votées ou en discussion alors que dans le second cas, on est plutôt dans le contexte politique avec des situations où il y a lutte ou mobilisation pour avoir des droits.
En minorité mais présents sur le graphe, on trouve quelques syntagmes où le motif est « droite » et va plutôt parler de politique. On a notamment « coalition entre la droite » ou « duel entre la droite ». Cela permet de constater que le sujet est ciblé et parle de parti politique, sans forcément parler spécifiquement de « droit » dans le sens législatif du terme ou de mobilisation politique pour faire valoir des droits.
PCTFORTE ":"
Nous avons reperé sur le site du Monde un patron qui permettrait d'identifier de potentiels des mots-clés. Il s'agit de phrases contenant la ponctuation forte ':'


Comme nous pouvons l'observer, ce type de construction est très présent sur Le Monde. En fait, cette structure de phrase [syntagme nominal] ':' [syntagme nominal][syntagame verbal]* est une marque caractéristique du registre journalistique pour créer des titres.
Voici quelques exemples de la même structure sur d'autre périodiques français parus le même jour.


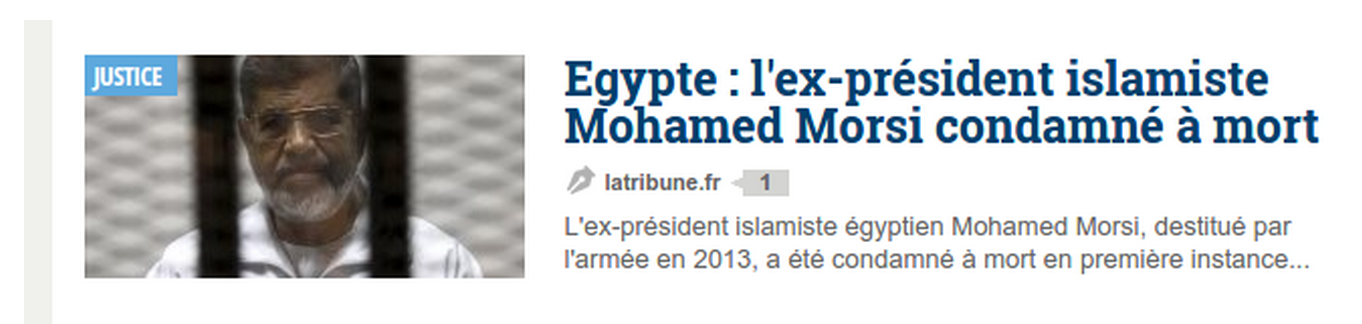

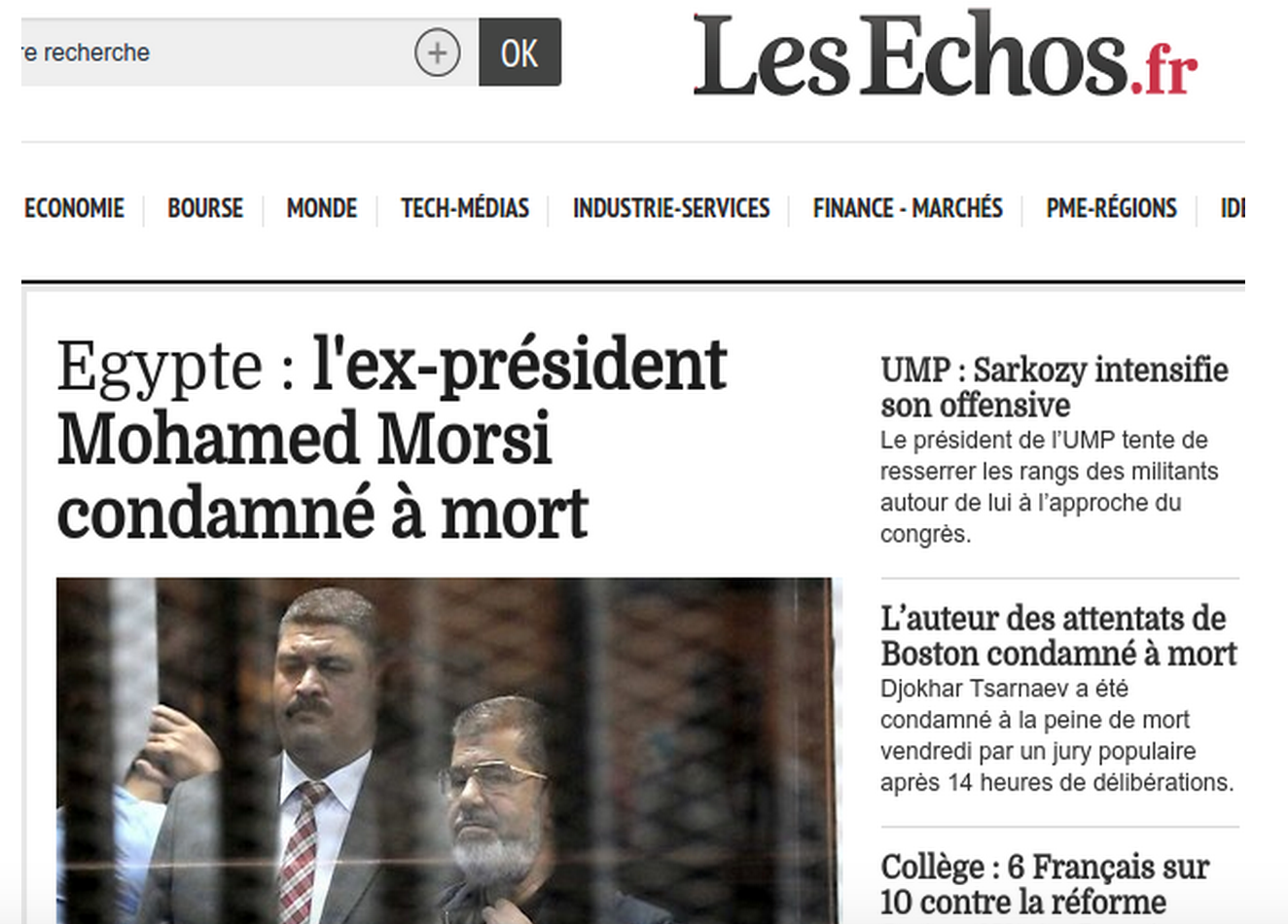
Nous pouvons remarquer que certains journaux réutilisent presque le même titre, avec la même structure.
Libération
"Egypte : l'ex-président islamiste Mohamed Morsi condamné à mort"
La Tribune
"Egypte : l'ex-président islamiste Mohamed Morsi condamné à mort"
Le Figaro
"Egypte : l'ex-président Mohamed Morsi condamné à mort"
Métro News
"Egypte : Mohamed Morsi condamné à mort"
Il ne s'agit pas d'un manque de créativité des journalistes, mais d'une technique raffinée pour susciter chez le lecteur l'envie de lire le texte en question, d'en savoir plus sur les faits cités dans le titre. En fait, le titre nous donne les idées principales du sujet traité, tout en laissant un trou d'informations qui ne peut être comblé que lorsque nous lisons l'article. Par exemple, à partir des titres ci-dessus, nous pouvons savoir où se passent les événements et la personne qui les subit.
En Egypte, Mohamed Morsi a été condamné à la peine capitale. Face à cette information le lecteur peut se demander : "Pour quelle raison a-t-il été condamné?" "Quand aura lieu la condamnation ?" Ou encore : "Qui est Mohamed Morsi?"
Ce type de phrase fournit l'essentiel sans dire les "pourquoi", "quand", "qui", "où", etc. Pour nous, cette information essentielle est très importante, puisqu'elle peut être utilisée, par exemple, par des systèmes de référencement (SEO).
Dans Cordial le symbole ':' est marqué comme ponctuation forte, ainsi que ';' , '!' , '?' et '.' . Alors, nous avons remarqué qu'une recherche simple par un patron comme : N[A-Z]+ PCTFORTE N[A-Z]+ V[A-Z]+ PREP N[A-Z]+ nous aurait donné plusieurs énoncés comme :
Pour éviter ce problème et essayer de découvrir s'il existe des structures récurrentes pour ce type de phrase, nous avons créé un script en Python pour nous aider. L'objectif de ce programme est de lire un ensemble de fichiers étitquetés tout en cherchant des 'tags' ou des 'tokens' spécifiques fournis par l'utilisateur. Comme résultat, il produit un fichier avec les patrons de phrases qui contiennent la tag, le token ou le patron choisi.
Dans notre cas, nous avons cherché des énoncés qui contiennent le token ':' pour tous les fichiers de toutes les rubriques étiquetées par Cordial, à l'exception du fichier CINEMA.cnr , car ce fichier était utilisé pour essayer la pertinence des patrons fournis par notre script. Si le fichier CINEMA.cnr avait aussi été lu par le script Trouver_Patrons.py, le résultat de notre recherche serait dénaturé, car les patrons dans le fichier de sortie incluraient ceux de CINEMA.cnr. Donc, l'exclusion du fichier étiquété qui nous intéresse dans le groupe des fichiers qui est analysé avec Trouver_Patrons.py permet de créer une sorte de corpus d'essai.
Voici les résultats (trouvés avec Trouver_Patrons.py) :
Rubrique Cinema : total du nombre de phrases - 1927 phrases
| Vrais Positifs | 91 |
| Faux Positifs | 19 |
| Vrais Négatifs | 1836 |
| Faux Négatifs | 5 |
| Rappel | 0,947 | 94% |
| Précision | 0,827 | 82% |
| F-Mesure | 0,87 | 87% |
Avec ces résultats, nous pensons que malgré la variété des formes, il est possible d'identifier certains types d'énoncés.
Voici les graphes créés après l'utilisation du script pour la rubrique CINEMA. Afin de faciliter la compréhension du graphe, le nombre d'énoncés a été réduit:
Obs.: le symbole ':' est représente par le token 'pct'
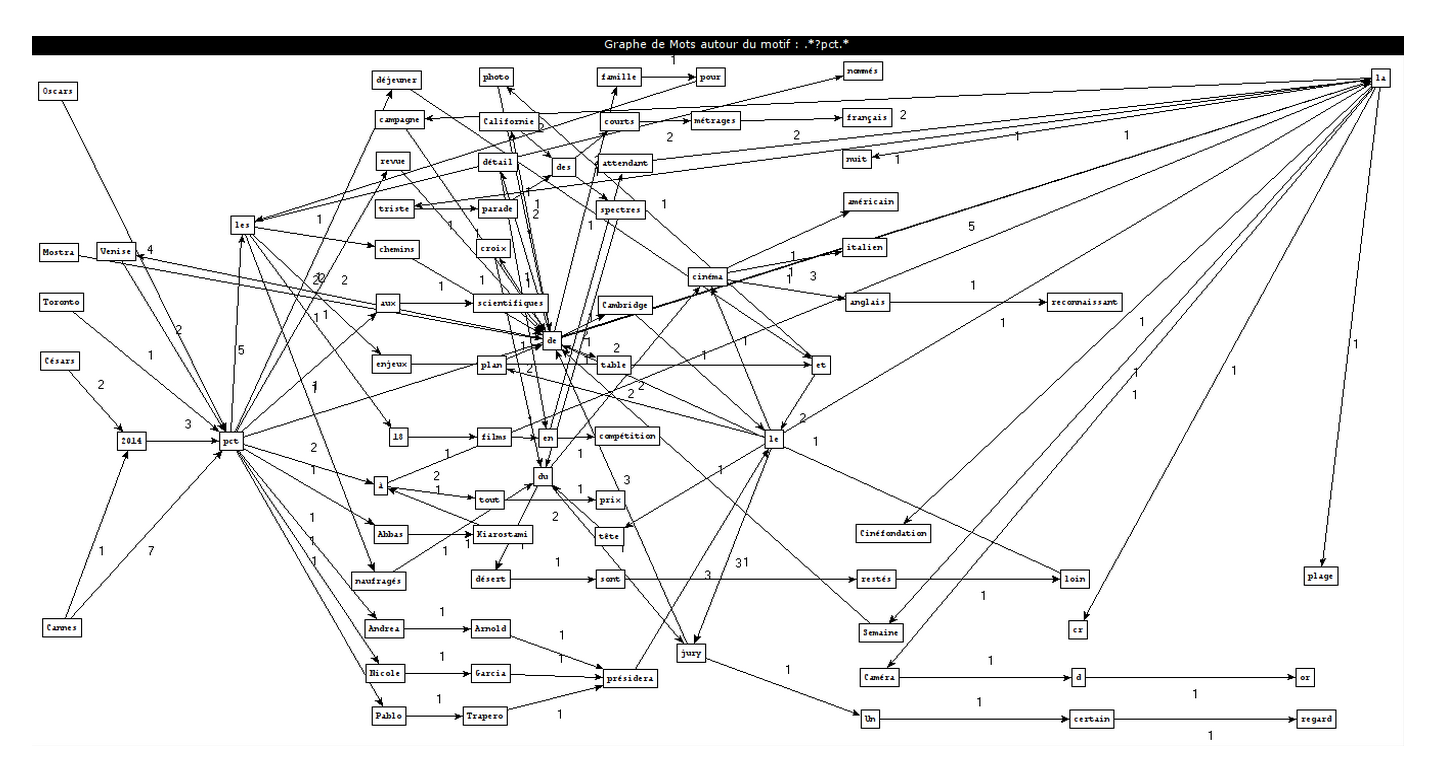
Exemples de quelques énoncés extraits avec le script de l'Outil 3 utilisant des patrons produits par Trouver_Patrons.py:
Les mots clés :

Les mots dits sémantiquement vides possédent beaucoup d'occurrences. Sur un graphe cela représente une agglomération de noeuds tout comme le patron recherché.
Voici le même graphe filtré par une stop-list.

Dans ce graphe, nous pouvons observer que les mots 'cinéma' et 'jury' possèdent beaucoup de connections. Ce résultat est révélateur du sujet traité par la rubrique analysée - le cinéma.
Pour conclure, il faut souligner que plusieurs autres analyses peuvent être réalisées avec les mêmes types de données et d'outils de représentation. Les théories présentées dans ce travail ne prennent en compte que le corpus utilisé par le projet, une vérification plus complète exigerait la même application dans un corpus de plus grande envergure.
CONJONCTION
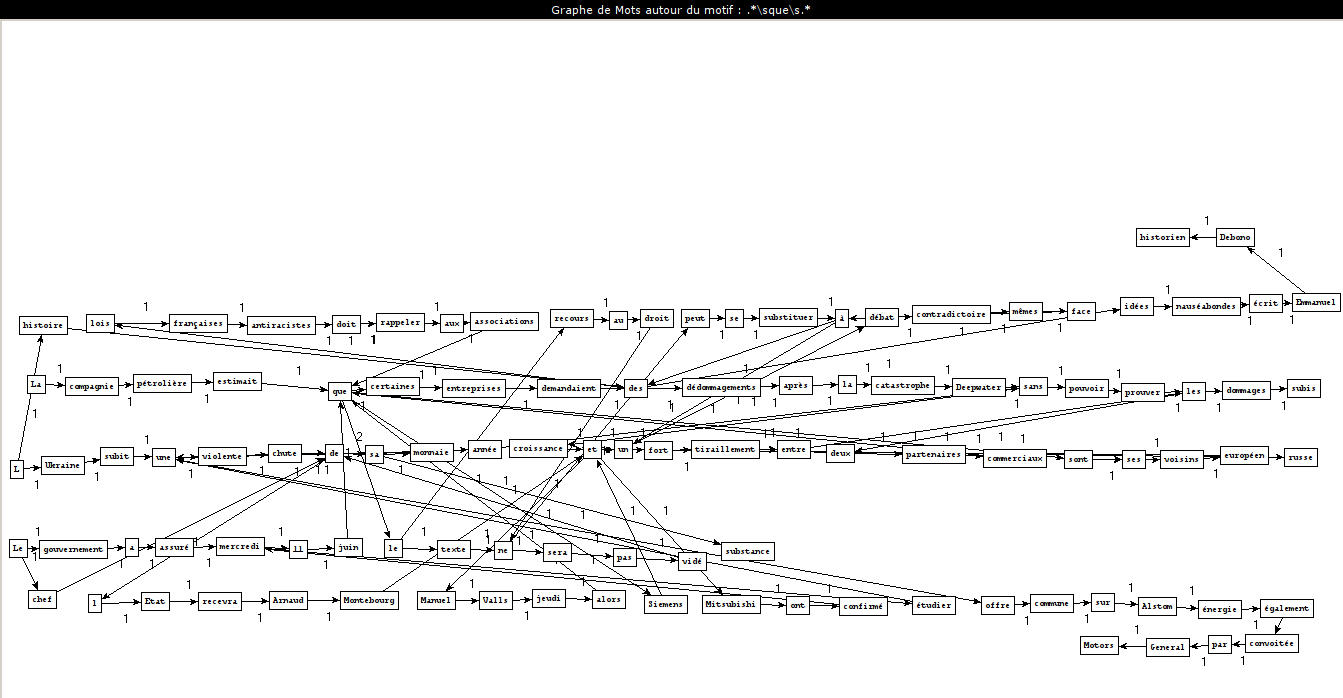
Nous avons essayé de créer un graphe avec des conjonctions mais le problème est que les résultats obtenus sont très denses car tout ce qui se rapporte à la conjonction amène des syntagmes très longs. Comme on peut le voir, on ne distingue pas clairement le résultat à travers le graphe. Grâce à notre fichier de résultats qui contient toutes les phrases ayant le patron recherché, nous avons récupéré uniquement les phrases qui contiennent "que". Nous avons finalement les 5 phrases suivantes :
Nous n'avons que des résultats qui proviennent des descriptions, dû au motif très long mis en entrée pour l'établissement du graphe. Les titres étant des phrases plutôt courtes, cela explique pourquoi nous n'avons récolté que des descriptions et pourquoi la longueur est surprenante. Mais avec des phrases aussi longues, on ne s'étonne pas du tout de ne pas obtenir plusieurs fois les mêmes segments, sinon, cela signifierait qu'on aurait deux fois la même phrase dans le graphe, autrement dit un doublon.
Que pouvons-nous conclure ?
En conclusion, nous avons pu constater que nous avions une variété de syntagmes très intéressants à analyser dans les articles du Monde. Nous avons choisi 4 patrons avec lesquels nous pensions trouver le plus de résultats possibles dans nos graphes.
Ce type d'analyse nous donne la possibilité d'explorer largement de quoi parle notre corpus, sans vraiment avoir besoin de le lire. Une fois que nous connaissions le type d'événement à chercher, il était bien plus facile d'analyser et de trouver des événements semblables. Cela peut être généralisé à d'autres sortes de publications. Si nous cherchions des informations dans des articles du Figaro ou L'Humanité, même si ce sont des journaux différents, nous serions capables de les analyser de en suivant la même méthode.



