
Secteur TAL Informatique
ILPGA Université Paris 3
Parcours TAL : step 5
Les documents présentés ici (in-progress) sous ce thème ont été écrits à partir de : (1) le document écrit (ici : l'original) sur le site de Polytechnique...; (2) les cours réalisés par Benoît Habert à L'ENS de Fontenay St Cloud
Segmentation. Analyse. Corpus catégorisé
Segmentation, étiquetage et analyse syntaxique
Préambule
Les correcteurs orthographiques et grammaticaux sont apparus ces dernières
années dans de nombreux logiciels de traitement de texte. Pour être efficaces, ceux-ci doivent identifier de manière automatique la nature et la fonction grammaticale des différents
mots de la phrase. Il s'agit en fait d'un problème complexe actuellement non complètement
résolu. La principale raison de cette complexité est que
les mots utilisés sont naturellement très ambigus. Par exemple,
le mot ne nous posera jamais aucun problème d'interprétation
: ainsi nous lirons "Il est (verbe être) grand'', et "Cet homme vient
de l'est ( ![]() ouest)". Nous allons voir ici, comment pendant une première phase d'analyse syntaxique un grand nombre d'ambiguïtés de ce genre peuvent être éliminées.
ouest)". Nous allons voir ici, comment pendant une première phase d'analyse syntaxique un grand nombre d'ambiguïtés de ce genre peuvent être éliminées.
En allant vers l'analyse ...
Phase 1 : segmentation
La première phase de l'analyse syntaxique d'une phrase est d'en distinguer les différents constituants :
- séparation des mots
- des symboles de ponctuation
- des séparateurs
Par exemple, la phrase :
La petite brise la glace.
comporte les mots : la, petite, brise, glace ; et le symbole de fin de phrase ".".
Pour aller plus loin sur la segmentation
Phase 2 : étiquetage
Puis à l'aide d'un dictionnaire on peut étiqueter tous les mots du texte. La lecture du dictionnaire donne les différents sens (grammaticaux) du mot la :
- Pronom féminin singulier PRO:fs
- Déterminant défini féminin singulier DET:fs
- (musical) Nom masculin singulier N:ms
|
Figure 1: Phrase étiquettée. |
|
Figure 2: Phrase totalement désambiguïsée (au niveau syntaxique.) |
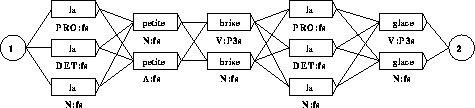
La phrase est ensuite représentée sous la forme d'un graphe
représentant les différentes combinaisons possibles (Figure
1). Ainsi étiquettée cette phrase comporte ![]() interprétations, puisque tout ``chemin'' allant du cercle 1 au cercle
2, représente une interprétation grammaticale potentielle
de la phrase. On dit que cette phrase est 72 fois ambigüe.
interprétations, puisque tout ``chemin'' allant du cercle 1 au cercle
2, représente une interprétation grammaticale potentielle
de la phrase. On dit que cette phrase est 72 fois ambigüe.
Pour aller plus loin sur l'étiquetage
Phase 3 : désambiguïsation
La troisième phase de l'analyse syntaxique consiste à éliminer le maximum d'ambiguïtés à l'aide de règles appellées grammaires locales.
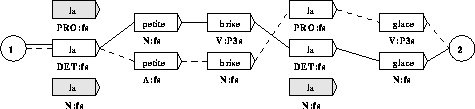
Par exemple la règle : un déterminant ne peut pas précéder un verbe, supprime le chemin entre le mot la=DET:fs et le mot glace=V:P3s.
Après la levée complète des ambiguïtés syntaxiques, la phrase reste ici doublement ambiguë (Figure 2) et un seul mot sur les cinq est totalement désambiguïsé (le mot la).
La manière de représenter les règles de désambiguïsation, sera de définir des combinaisons de mots interdites. On dira qu'il s'agit de règles négatives (qui supprime des chemins). Par exemple :
- un déterminant ne peut pas précéder un verbe : signifie que la combinaison (<DET> <V>) est interdite.
- une phrase comporte au moins un verbe : signifie que la combinaison:
![]()
où M1, M2, ..., Mk sont tous des mots non <V> est interdite.
Une règle est représentée par un automate, c'est à
dire un graphe orienté ayant un état initial et un état
final, dont chaque état "![]() " représente :
" représente :
- un mot : par exemple
 ,
, 
- un séparateur
 ,
,  ,
,  ,
,
,
,  et le séparateur
et le séparateur  qui marque le début de la phrase.
qui marque le début de la phrase. - une catégorie : Pour un mot il peut s'agir de
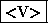 (verbe),
(verbe),  (adjectif),
(adjectif), 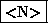 (nom),
(nom),  (déterminant),
(déterminant),  (préposition),
(préposition),  (non classé : par exemple le mot ne).
(non classé : par exemple le mot ne). - Pour un séparateur,
il n'y a que deux catégories :
 qui ``marque'' tous les séparateurs de fin de phrase et de début
de phrase et
qui marque les autres.
qui ``marque'' tous les séparateurs de fin de phrase et de début
de phrase et
qui marque les autres. - un mot avec sa catégorie :

- une expression plus complexe utilisant le symbole de négation (point
d'exclamation) : par exemple
 représente tous les mots sauf le mot est,
représente tous les mots sauf le mot est,  représente le mot est sans la catégorie <V>,
et
représente le mot est sans la catégorie <V>,
et 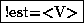 est ou qui n'a pas la catégorie
<V>.
est ou qui n'a pas la catégorie
<V>.
Une combinaison dans le graphe de la phrase (c'est à dire une interprétation
possible) est supprimée par une règle donnée, si il
existe un chemin dans l'automate de la règle coïncidant avec
un morceau de cette combinaison. Les figures 3, 4 et 5 représentent
trois automates de désambiguïsation.
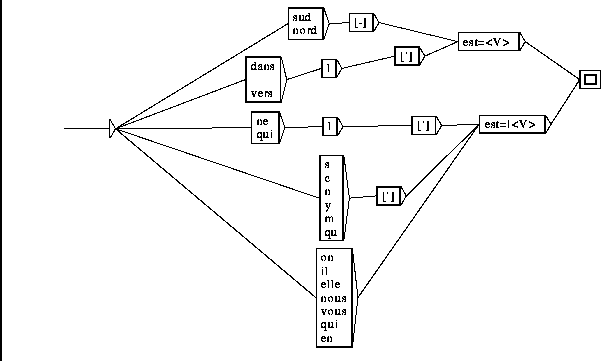
Par exemple, l'unique chemin de l'automate de la figure 4 coïncide
avec n'importe quel chemin de la phrase d'exemple contenant <DET>
suivi de <V>, ce qui supprime tous ces chemins.
De même le chemin suivant de l'automate de la figure 3
![]()
coïncide avec la combinaison
![]()
donc cette combinaison sera supprimée.
|
Figure 3: Une phrase a toujours au moins un verbe |
|
|
|
Figure 4: Un déterminant ne peut pas précéder un verbe |
|
|
|
Figure 5: Désambiguïsation du mot est en fonction du contexte |
Pour aller plus loin sur la désambiguïsation
Aller plus loin et expérimentations
1. Segmentation : segmentation
2. Etiquetage : étiquetage
3. Désambiguïsation : désambiguïsation
4. TP5