Projet
Ce projet vise à mettre "en oeuvre une chaîne de traitement textuel semi-automatique, depuis la récupération des données jusqu'à leur présentation". Ces données proviennent du journal Le Monde et correspondent à tous les fils rss qui ont été générés en 2020, tous les soirs, à 19h. Il s'agit d'extraire des données textuelles de chaque rubrique du journal pour constituer un recueil de terminologies. Les rubriques comportent chacune un identifiant (l'identifiant de la rubrique à la une est 3208, par exemple), ce qui facilite leur repérage au sein du corpus.
Les thèmes des rubriques sont répertoriés dans le tableau suivant:
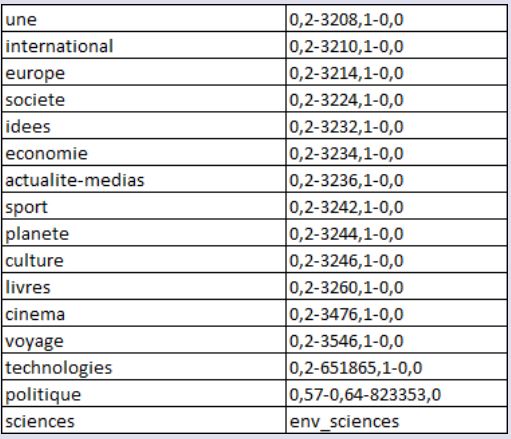
Notre travail porte sur les rubriques "A la une", "International", "Europe" et "Sport". Il s'effectue en plusieurs étapes:
Cette étape a pour objectif d'extraire les données textuelles contenues dans le titre et la description des fils rss des rubriques, en parcourant une arborescence de fichiers, avec des scripts Perl, à l'aide de deux méthodes (méthode regex, méthode xml::rss).
On effectue ensuite un étiquetage morphosyntaxique et en dépendance des données avec les outils Treetagger et Udpipe.
On extrait, à partir de cet étiquetage, 6 patrons morphosyntaxiques et des relations en dépendance de type "obj" (c'est-à-dire les mots connectés dans une relation "objet"), en utilisant trois méthodes: un script perl, des requêtes xquery et des feuilles de style xslt.