Boîte à outil 3
Extraction de patrons morphosyntaxiques et de relations en dépendance syntaxique
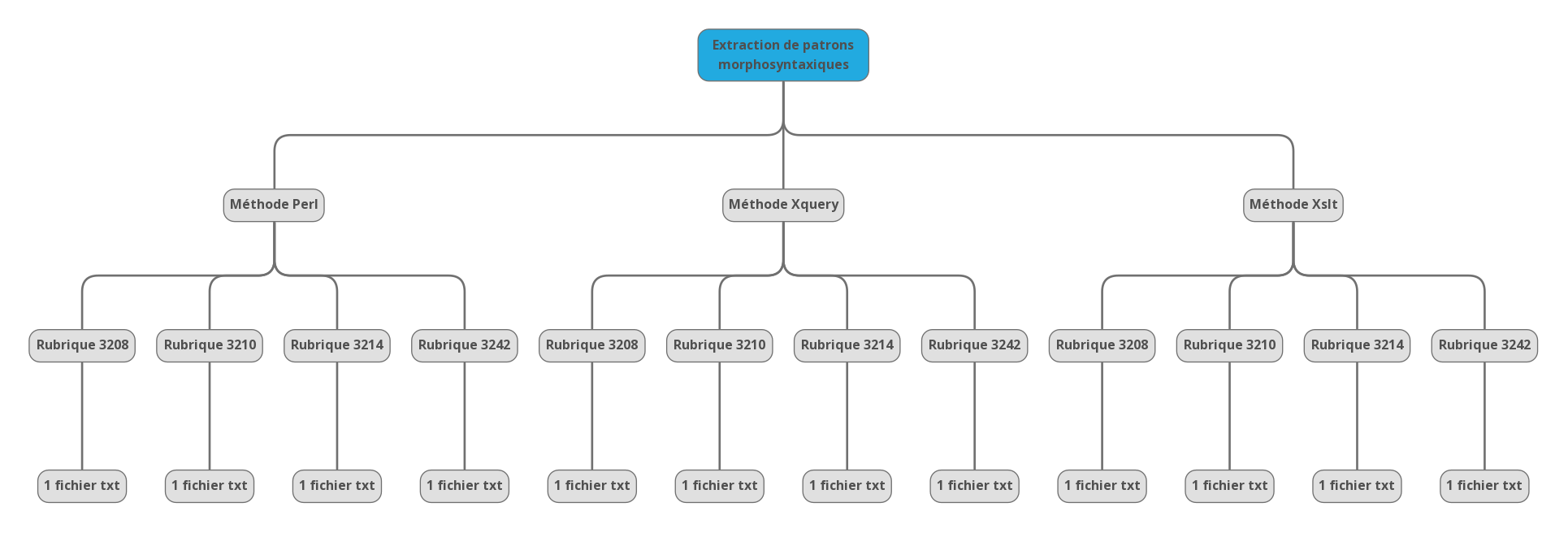
On réalise deux types d'activité dans cette dernière partie du travail. Dans un premier temps, on extrait des patrons morphosyntaxiques, puis dans un second temps des relations en dépendance syntaxique de type "objet". Chacune de ces étapes est effectuée avec trois méthodes différentes: un script perl, des requêtes xquery et des feuilles de style xslt. L'extraction des patrons morphosyntaxiques avec le programme perl est réalisée à partir des étiquetages produits avec Udpipe (sorties xml). L'extraction des patrons avec Xquery et les feuilles de style xslt est réalisée à partir des étiquetages produits avec Treetagger (sorties xml). L'extraction en dépendance avec ces trois méthodes est appliquée sur les sorties Udpipe au format xml. Ces méthodes sont résumées dans le graphique suivant:
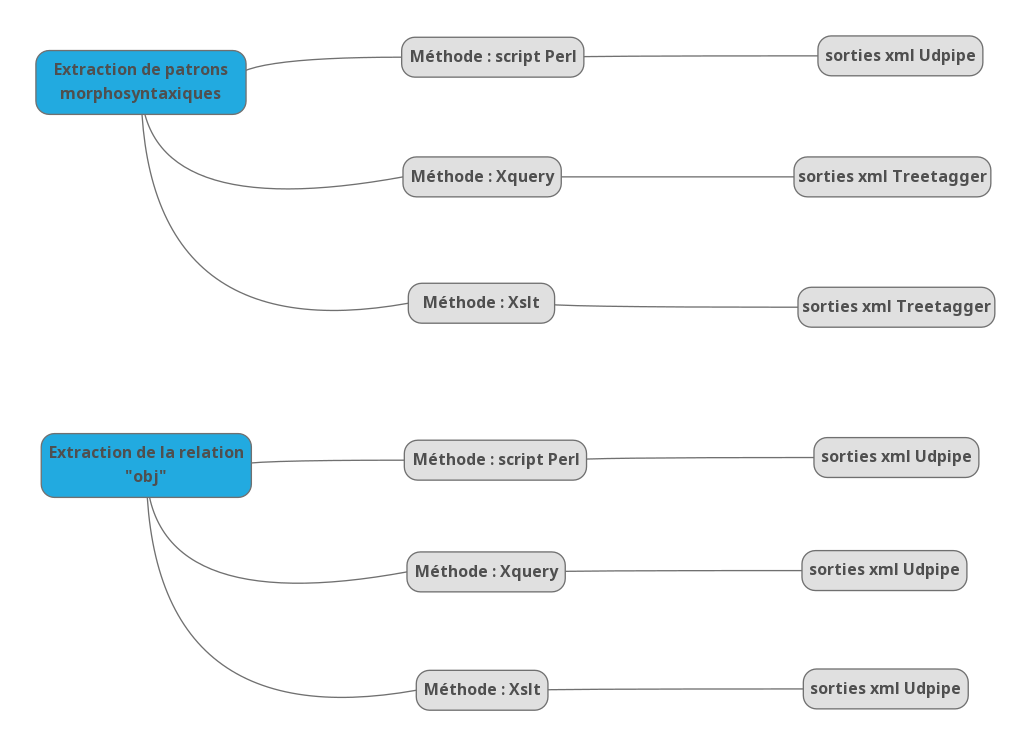
L'extraction des patrons morphosyntaxiques
Extraction de la relation objet
Les patrons morphosyntaxiques correspondent à des suites de POS (part of speech). Autrement dit nous cherchons à récupérer des séquences de mots particulières en fonction de leur catégorie grammaticale. Nous choisissons d'extraire les patrons suivants:
- patron 1: NOM PREP NOM PREP
- patron 2: VERBE DET NOM
- patron 3: NOM ADJ
- patron 4: ADJ NOM
- patron 5: VERBE PREP NOM
- patron 6: DET NOM VERBE
Chaque méthode va donc produire 6 fichiers par rubrique.
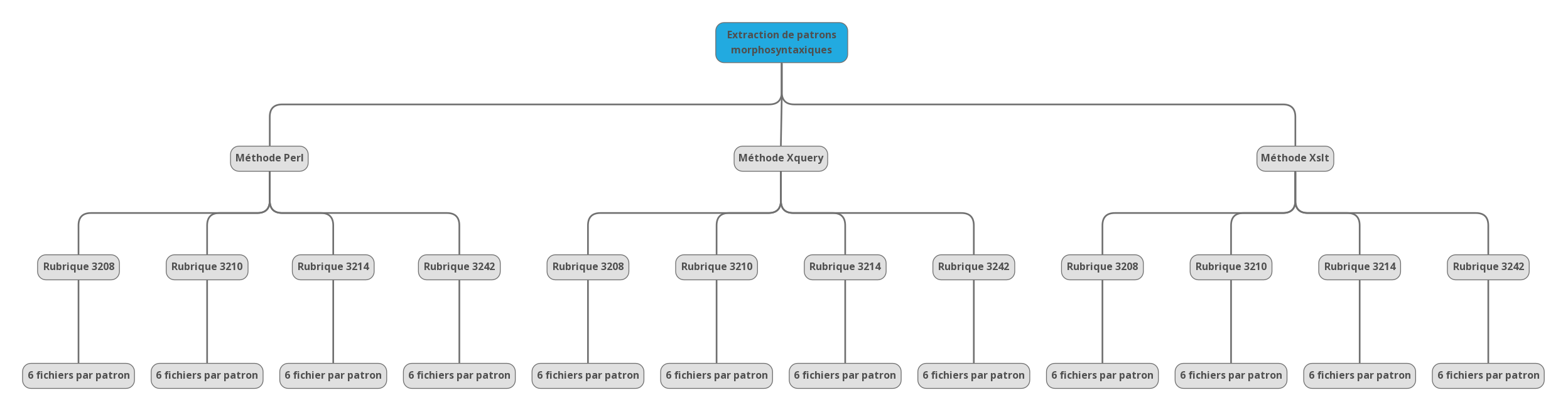
->LA MÉTHODE PERL
La méthode Perl tient compte de la syntaxe des fichiers de sortie xml Udpipe et implique de fournir au programme un fichier comportant le patron morphosyntaxique recherché. Dans les sorties xml Udpipe, les phrases apparaissent sous la forme de paragraphes, différenciés par des lignes vides. Elles sont organisées de manière tabulaire, chaque information étiquetée se trouve dans une colonne.
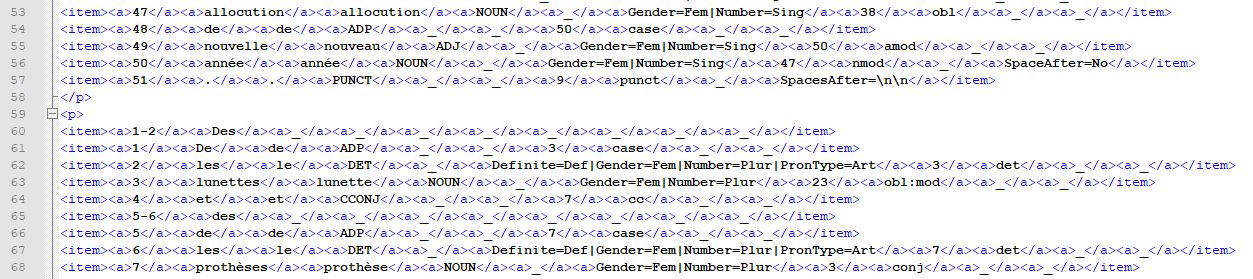
Le fonctionnement du script s'appuie sur le format des fichiers pour récupérer les données. Il s'arrête lorsqu'il trouve une ligne vide et traite ce qu'il vient de lire. On crée deux listes, l'une comportant les étiquettes des POS et l'autre les tokens. On met en correspondance ces deux listes en tenant compte de la localisation des informations dans les colonnes du fichier. Pour lancer le programme, l'utilisateur doit fournir le fichier d'entrée et le fichier comportant le patron qu'il souhaite extraire.
Le script est disponible ici.
Voici un exemple de fichier de sortie (patron 1):
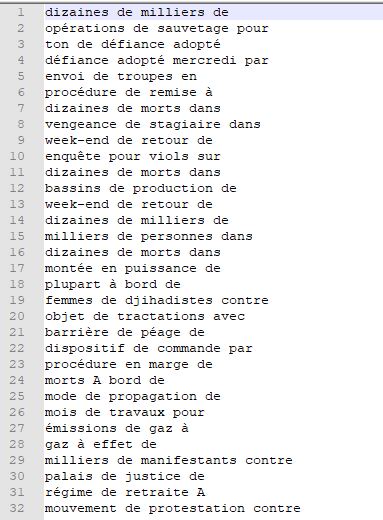
Les résultats du script:
RUBRIQUE 3208
RUBRIQUE 3210
RUBRIQUE 3214
RUBRIQUE 3242
->LA MÉTHODE XQUERY
Xquery est un langage conçu pour interroger des données xml. Il permet d'effectuer des requêtes sur une base de données de fichiers, en se basant sur la syntaxe xml. On utilise le logiciel BaseX pour le requêtage.
Vous trouverez ci-dessous les requêtes effectuées pour chaque rubrique et pour chaque patron:
RUBRIQUE 3208
RUBRIQUE 3210
RUBRIQUE 3214
RUBRIQUE 3242
Les résultats du script:
RUBRIQUE 3208
RUBRIQUE 3210
RUBRIQUE 3214
RUBRIQUE 3242
->LA MÉTHODE XSLT
Les feuilles de style xslt permettent de transformer les fichiers d'entrée xml, produits par Treetagger, pour pouvoir extraire les patrons morphosyntaxiques. On avance dans l'arborescence des fichiers, en commençant par se placer sur les balises "articles". On réalise ensuite une itération sur les éléments. Si on trouve l'élément recherché, on examine ses "frères", puis les éléments "fils". Lorsque l'on parvient à obtenir le patron souhaité, on affiche les données.
Vous trouverez ci-dessous les feuilles de style élaborées pour chaque rubrique et pour chaque patron:
RUBRIQUE 3208
RUBRIQUE 3210
RUBRIQUE 3214
RUBRIQUE 3242
Les résultats du script:
RUBRIQUE 3208
RUBRIQUE 3210
RUBRIQUE 3214
RUBRIQUE 3242
Les relations de dépendance syntaxique impliquent la présence d'un gouverneur et d'un dépendant. Dans ce travail on s'intéresse à la relation objet, ce qui signifie que l'on veut extraire les gouverneurs et les dépendants qui entretiennent une relation de type "objet". On extrait ces informations, en utilisant les méthodes Perl, Xquery et Xslt, à partir des sorties Udpipe reformatées en xml. Chaque méthode va produire, cette fois, un fichier par rubrique.
->LA MÉTHODE PERL
Comme précédemment, le script traite les phrases comme des listes de lignes. On parcourt la liste en itérant sur les indices des items. Si la ligne contient la relation "objet", on récupère la position du gouverneur et du dépendant, puis on imprime la liste des couples gouverneurs et dépendants. Pour lancer le script, il suffit de renseigner le nom du fichier xml en premier argument, puis d'indiquer le motif correspondant à la relation syntaxique recherchée.
Le script est disponible ici.
Les résultats du script:
->LA MÉTHODE XQUERY
On utilise également la position des éléments pour récupérer les informations qui nous intéressent. On récupère la forme des items qui occupent les fonctions de dépendants et de gouverneurs, grâce à leurs positions dans les fichiers xml. On teste la position du gouverneur par rapport au dépendant (il peut se trouver avant ou après), puis on regroupe les séquences (avec la fonction "concat").
Voici les requêtes effectuées pour la relation "obj" pour chaque rubrique:
Voici un exemple de fichier de sortie:
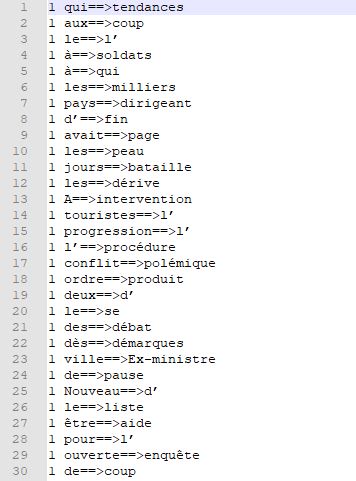
Les résultats des requêtes:
->LA MÉTHODE XSLT
La méthode xslt repose sur le même principe que la méthode précédente.
Voici les feuilles de style construites pour extraire la relation "obj" de chaque rubrique:
Feuille de style Rubrique 3208
Feuille de style Rubrique 3210
Feuille de style Rubrique 3214
Feuille de style Rubrique 3242
Les résultats des requêtes: