Boîte à outil 1
Extraction des contenus textuels
L'objectif de cette partie du travail consiste à extraire des données dans un corpus de fils rss du journal Le Monde.
Qu'est-ce qu'un fil rss?
A quoi ressemble un fil rss?
Quelles données cherchons-nous à extraire?
Quel outil pour réaliser cette tâche?
Les méthodes d'extraction des données
Le fonctionnement du script
Le script avec les expressions régulières
Le script avec la bibliothèque xml::rss
Les résultats
Il s'agit d'un fichier mis en oeuvre automatiquement par les sites internet pour signaler les mises à jour aux internautes.
Ce fichier est structuré au format xml et obéit à une organisation particulière propre à l'application rss. Il contient le titre et une sorte de résumé de l'article.
Exemple d'un fichier rss:
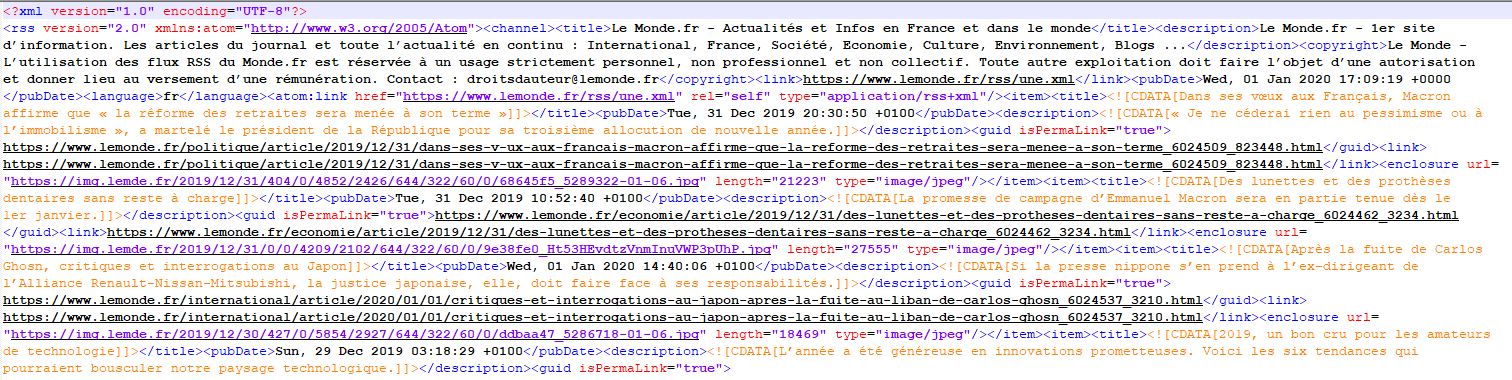
Structure principale des fichiers rss du journal Le Monde en 2020:

-Une entête xml
-Un élément racine qui spécifie la version et l'application utilisée (ici atom)
-Une balise
-Une balise item qui correspond à la description de l'article et qui contient une balise title, une balise pubdate, qui indique la date de publication et une balise description, qui contient le résumé de l'article
Nous voulons extraire le contenu des balises "title" et "description" qui se trouvent dans la balise "item", des rubriques du journal Le Monde (nous récupérons les données de 4 rubriques). Nous allons nous servir de la structuration des fichiers pour récupérer ces données.
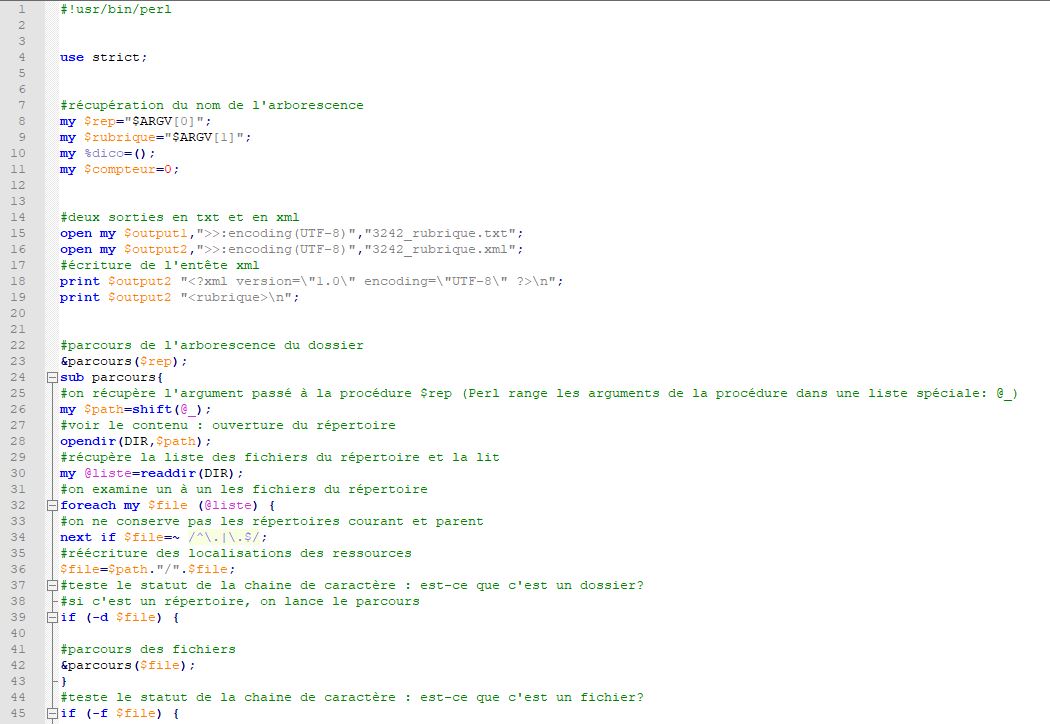
Nous utilisons un script écrit en Perl pour produire un résultat équivalent à la commande Unix egrep. Perl est un langage de programmation utilisé pour traiter des données textuelles. Il utilise trois types de données:
-Les scalaires, qui permettent de stocker des chaînes de caractères ou des valeurs numériques
-Les listes
-Les tableaux associatifs, qui sont comparables à des dictionnaires
-Les expressions régulières permettent de repérer des régularités dans les données textuelles, pour localiser les informations recherchées. Elles permettent de récupérer facilement le contenu textuel souhaité.
exemple: récupération du contenu des balises "title" et "description"

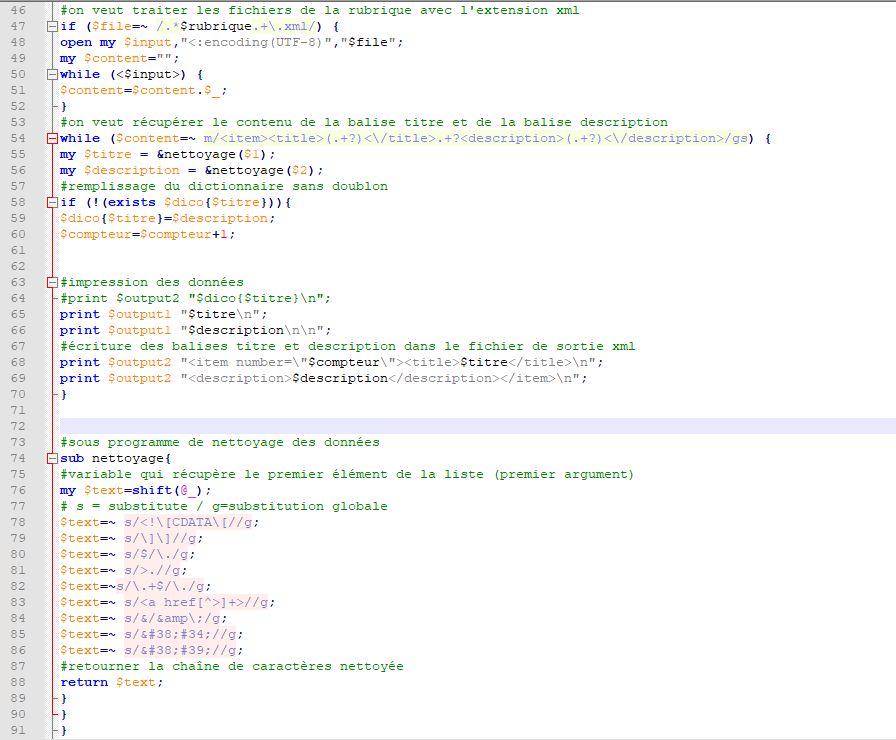
On les utilise également pour nettoyer les données, en effectuant des substitutions de caractères par d'autres caractères ou par un caractère vide.
exemple: substitution des fins de ligne par des points"
$text=~s/$/\./g;
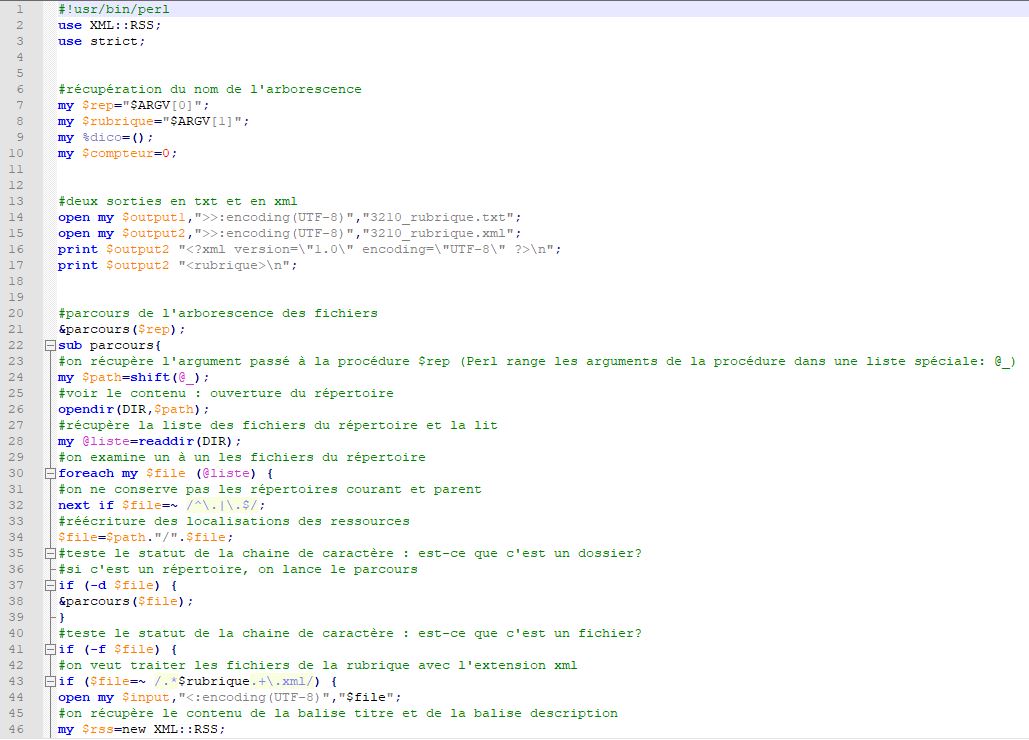
-La bibliothèque XML::RSS qui s'appuie sur la structure logique du fichier au formal xml. Elle donne la possibilité de modéliser l'arbre xml grâce au remplissage de listes et des tableaux associatifs.
Les données se trouvent dans une arborescence de fichiers. Elle est constituée d'un répertoire, qui comporte 12 dossiers (pour les 12 mois de l'année). Chaque dossier "mois" comporte 30 ou 31 sous dossiers (pour les 30 ou 31 jours par mois). Chaque dossier "jour" contient un fichier texte et un fichier xml par rubrique, qui correspondent au fil rss.
Le programme parcourt cette arborescence et effectue les traitements (extraction et nettoyage) lorsqu'il parvient aux fichiers qui possèdent une extension xml. Cette procédure récursive ouvre le répertoire, examine les dossiers et les fichiers un à un. Quand un fichier xml est traité elle remonte dans l'arborescence et répète cette opération jusqu'au traitement complet de tous les fichiers. Le script prend en compte une seule rubrique à la fois, pour le lancer il faut indiquer le nom du script, puis le nom du répertoire et renseigner comme troisième argument le nom de la rubrique que l'on souhaite traiter.
On crée deux fichiers de sortie: un fichier au format txt et un fichier au format xml.
Le script est disponible ici.

Le script est disponible ici.
L'application des scripts produit un fichier texte et un fichier xml, comme le montre cet exemple (rubrique 3208):

Les scripts produisent des résultats identiques.
Voici les résultats obtenus sur 4 rubriques après l'exécution du premier script: