Introduction
Nous avons tout d'abord pris le temps de s'acclimater à l'usage du logiciel. Thomas a par exemple commencé par faire dans le cadre d'un autre cours une petite analyse succincte du roman Germinal d'Emile Zola pour s'habituer à l'utilisation de l'outil.
La première difficulté rencontrée a été de paramétrer l'étiqueteur treetagger sur TXM, et nous avons à ce sujet posté sur le blog un tutoriel illustré, pas à pas de cette installation. Vous y trouverez également une petite présentation du logiciel : Introduction et Tutoriel d’installation de Treetagger sur TXM.
Mais pourquoi utilisons nous TXM ? Il est vrai que l'outil n'est pas à première vue des plus facile à utiliser, cependant, il propose des fonctionnalités très intéressantes qui permettent vraiment une analyse fine de nos corpus.
- Il est possible de lui installer une multitude de taggers et le logiciel se charge de faire la tokenisation et l'étiquetage morpho-syntaxique automatiquement.
- Grâce à son moteur de lemmatisation, il permet une manipulation aisée des données, en se souciant peu des problèmes de mise en forme du texte concernant le format, comme la casse par exemple. Ainsi, nous pouvons facilement grouper les occurrences de "Brexit", de "BREXIT" et de "brexit" en une seule et même entité.
- Il est capable également de produire des index, des calculs de fréquence et de cooccurrences, et toutes les opérations basiques de textométrie.
- Enfin, et c'est ce qui nous a le plus intéressé, il embarque un système de recherche précis sur des patterns que nous pouvons isoler, en faisant des requêtes dans un format appelé le CQL.
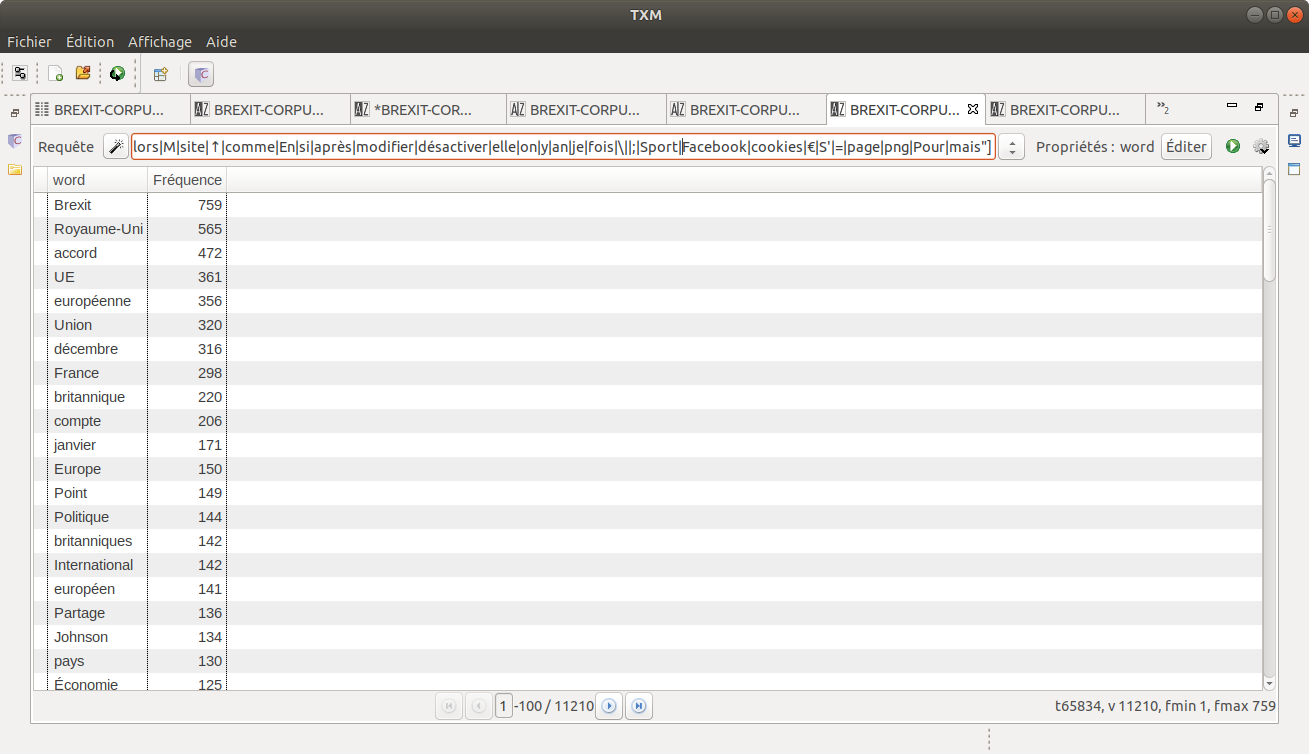
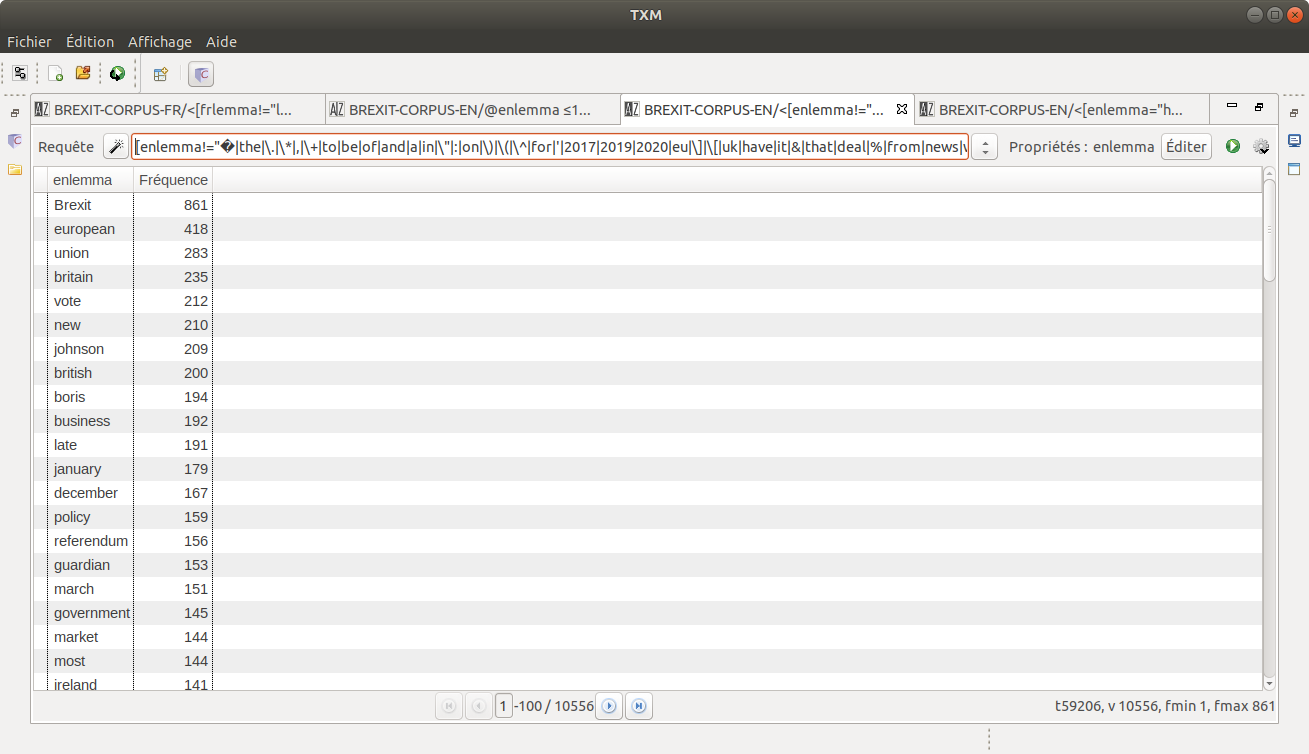
1. Index des occurrences nettoyés
Nous avons produit un index des lemmes dans notre corpus. Comme toujours, les stop-words trônent fièrement dans le haut du classement des occurrences. Nous avons pris la liberté de les éliminer "à la main". Nous ne sommes pas parvenus à éliminer par des biais automatiques les stop-words et la pollution (ponctuation, paratexte…) alors nous avons décidé de procéder à une requête CQL pour les éliminer manuellement. Celle-ci se présente sous la structure suivante :
Requête : [frlemma!= "stop_word_1|stop_word_2|stop_word_3| …… "%cd]
Vous trouverez ci-dessous le résultat de nos index nettoyés :
2. Observations de patterns linguistiques grâce aux requêtes CQL
Le CQL (Corpus Query Language) est un langage de requête sur des corpus. Il nous permet de jouer avec les différents étiquetages faits par TXM, et ainsi combiner dans des patterns des objets de différentes nature.
Les unités scindées dans TXM peuvent avoir plusieurs nature. Le premier type d'objet dénoté "words" désigne les tokens tels quels. Par exemple :
[word="appartenir"]→ désigne strictement la chaîne de caractères
On peut faire, par exemple, une requête qui isole une juxtaposition d'un lemme avec un token appartenant à une partie du discours désignée.
Nous vous présentons ci-dessous l'extraction de quelques patterns qui que l'on est parvenu à isoler.
a) Les mots dérivés de Brexit en anglais et en français.
On le sait tous, le terme "Brexit" n'est vieux que de quelques années. Cependant, il peut se vanter d'avoir créé un certain nombre de mots composés autour de lui. On cherche à faire une requête CQL qui nous sorte tous les mots qui contiennent la chaîne "Brexit" sauf la chaîne stricte "Brexit" elle-même :
[word = ".*Brexit.*"%cd & word != "Brexit"%cd]
Nous décortiquons la requête pour l'expliciter :
word = ".*Brexit.* "→ une chaîne de caractère contenant la chaîne "Brexit" avec ses affixes et suffixes éventuels%cd→ insensible à la casse et au diacritiques&→ connecteur logique ETword!="Brexit"%cd→ sauf le token "Brexit" (insensible à la casse et au diacritiques) lui-même
La requête sous cette forme marche aussi bien en anglais qu'en français. Voilà quelques résultats renvoyés par les requêtes :
Les mots composés autour de Brexit en français :
- "anti-brexit" = 4 occurrences
- "brexiters" = 19 occurrences
- "post-brexit" = 46 occurrences
- "pro-brexit" = 10 occurrences
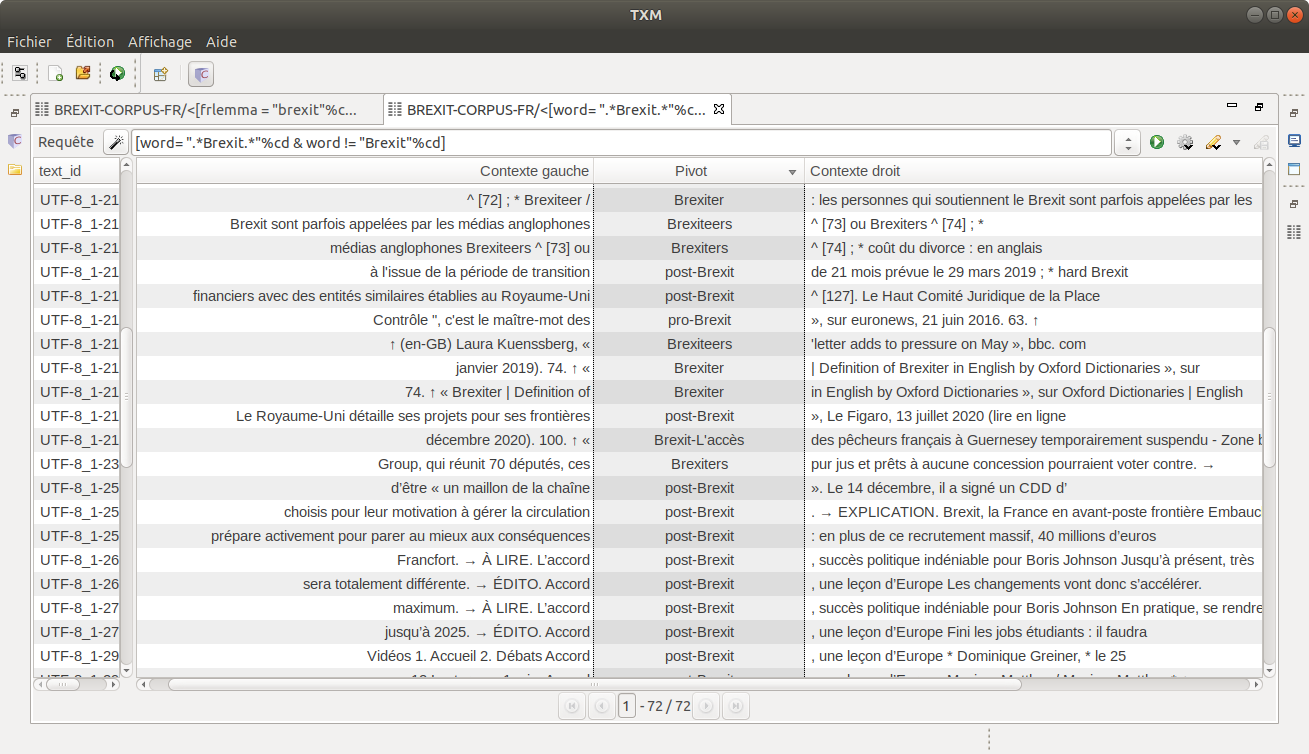
Plus curieux nous avons aussi remarqué quelques occurrences de la francisation de "brexiters" qui est "brexiteurs" qui apparaît seulement 3 fois.
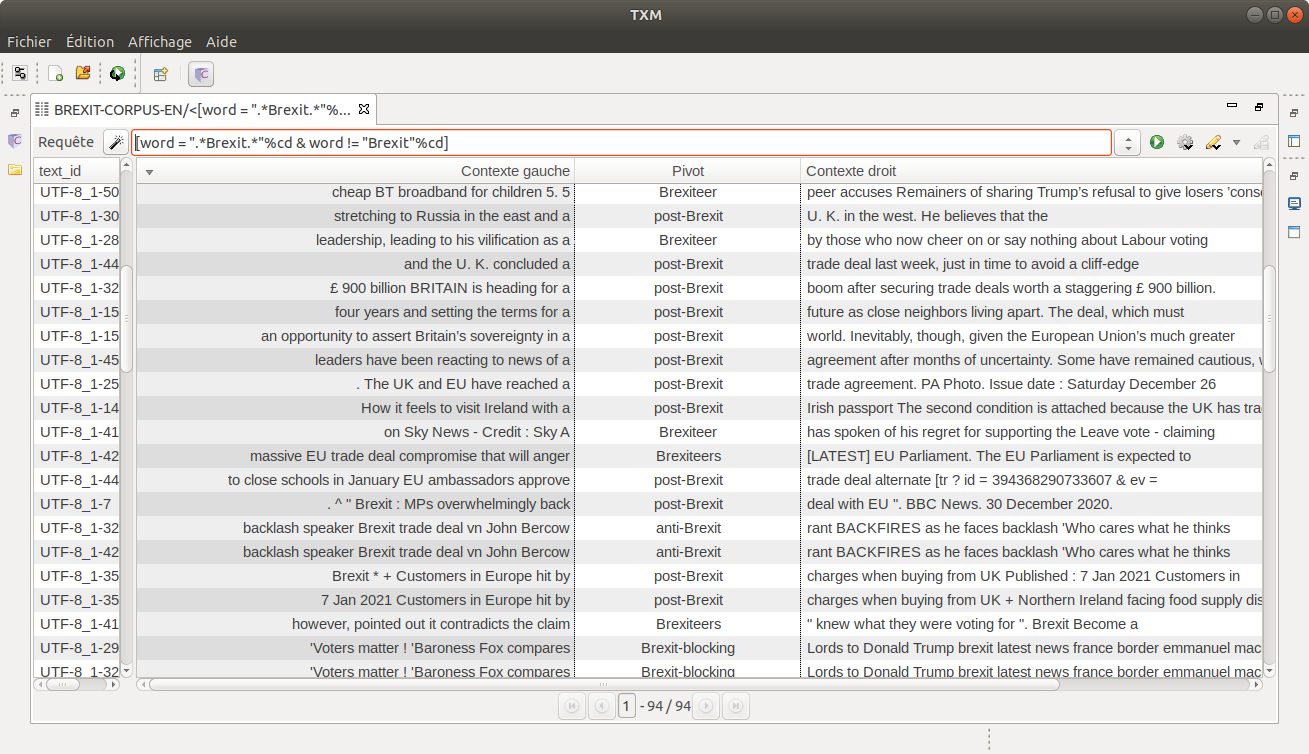
Voici les mots composés autour de Brexit en anglais :
- "post-brexit" = 34 occurrences
- "brexiteers" = 19 occurrences
- "anti-brexit" = 6 occurrences
b) Le terme "Brexit" associé à un adjectif qualificatif
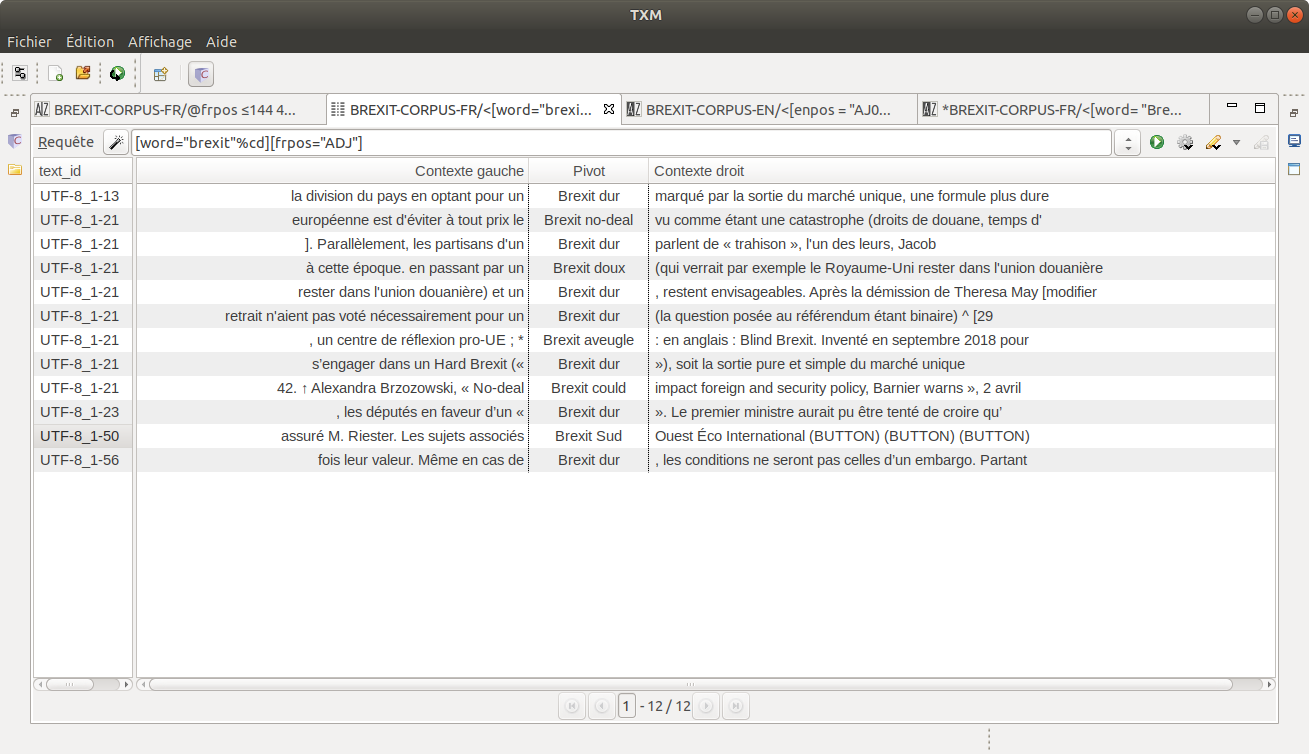
Nous avons remarqué assez curieusement que le terme "Brexit" en français n'est presque qualifié que par deux adjectifs, le "Brexit doux" et le "Brexit dur". C'est en effet une distinction qui a été faite pour désigner les termes dans les termes dans lesquels le Brexit serait négocié avec l'Union Européenne à savoir dur si les accords avec l'Union venaient à être complètement rompu sur le plan commercial, ou doux si certains d'entre eux étaient maintenus pour faciliter la sortie du Royaume-Uni de l'Union Européenne. L'expression française "Brexit dur" une francisation de l'expression "No deal Brexit". Nous avons trouvé ça assez curieux que la transposition faite de l'anglais au français dans ce cas consiste à transformer ce mot composé anglais "no-deal" en adjectifs qualificatif comme "dur" et "doux" :
[word="brexit"%cd][frpos="ADJ"]
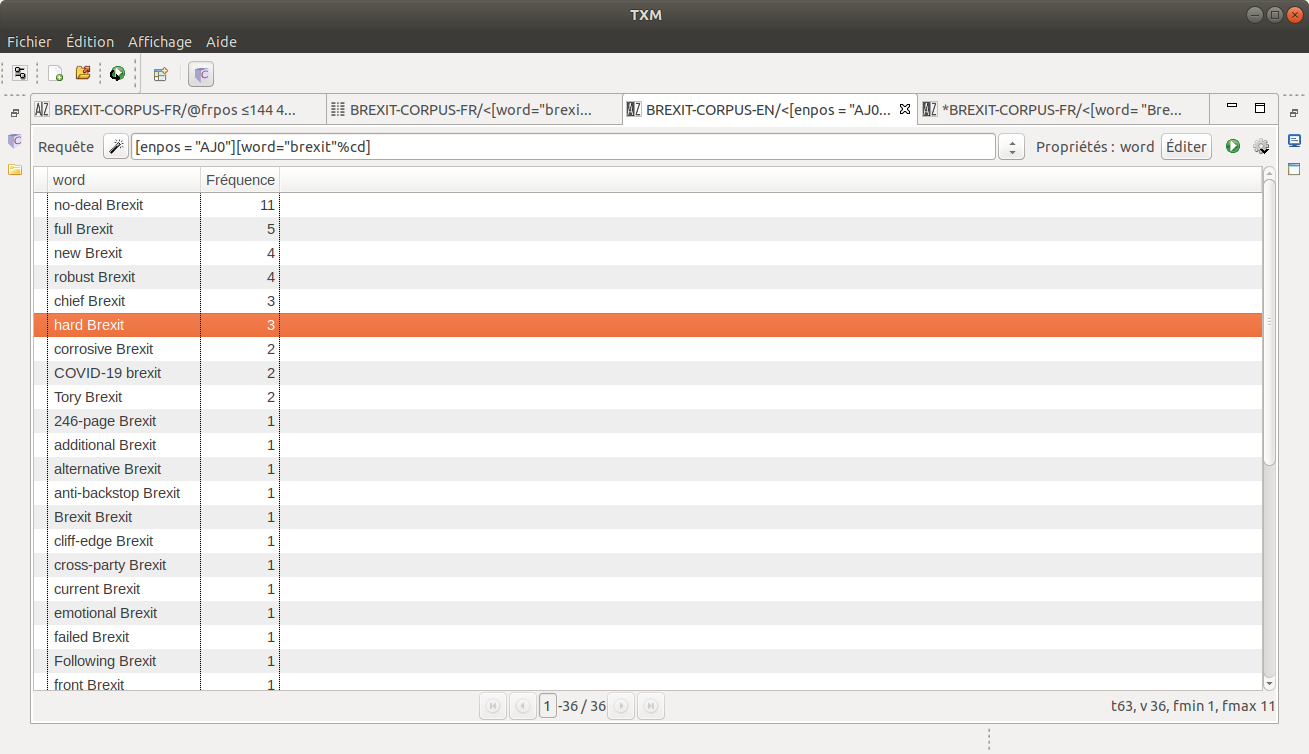
La presse anglophone se montre un peu plus inventive quant aux adjectifs qualificatifs qu'elle associe avec le terme "Brexit". La connotation de ces termes est d'ailleurs en général aussi assez péjorative :
[enpos="AJ0"][word="brexit"%cd]
- long-running Brexit
- failed Brexit
- emotional Brexit
- cliff-edge Brexit
- etc.
c) Distribution des temps et modes verbaux
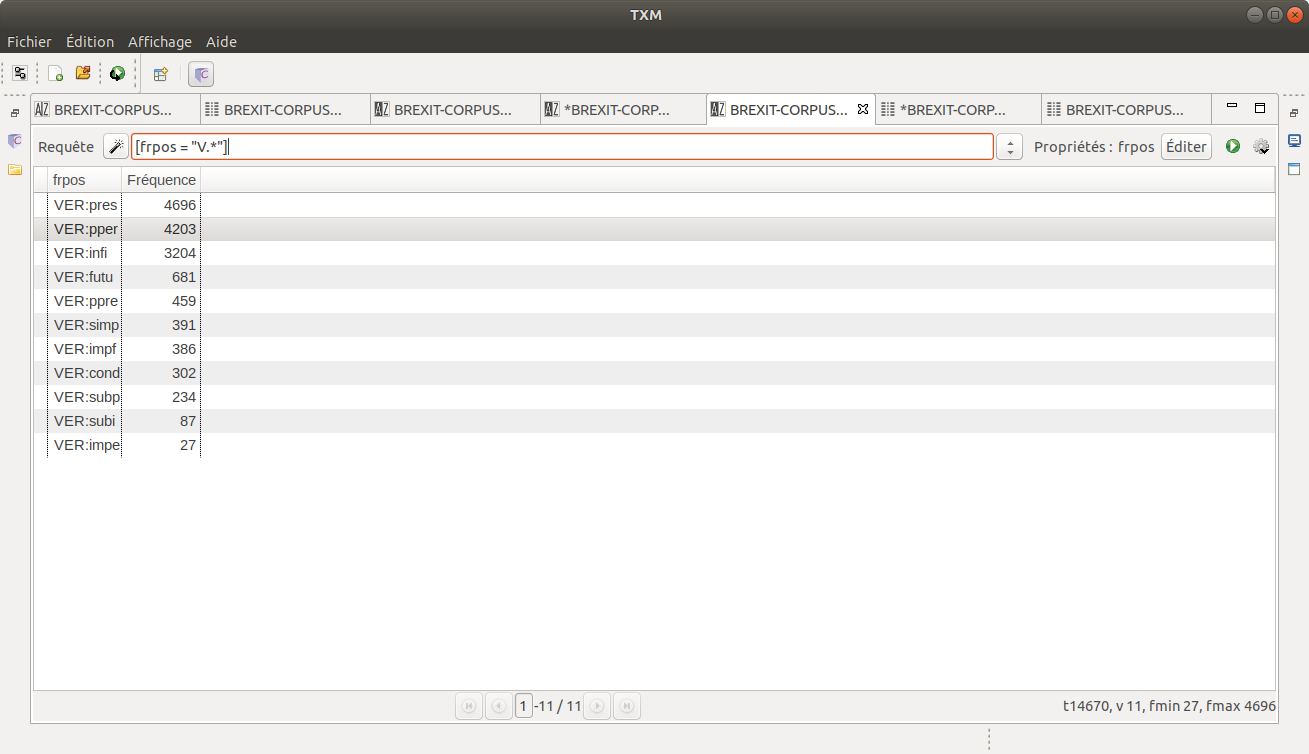
Enfin, nous avons aussi fait une petite recherche sur les lemmes pour identifier la distribution des temps et modes verbaux dans nos corpus. Nous pensons que c'est une statistique intéressante pour savoir quels sont les temps les plus utilisés dans le style journalistique.
En français, sans grande surprise, le présent de l'indicatif arrive grand champion suivi du passé composé, car les journaux décrivent bien souvent des évènements dans un passé très proche.
Nous pensons que ces statistiques correspondent bien à ce que l'on attendait d'un corpus journalistique :
[frpos="V.*"]
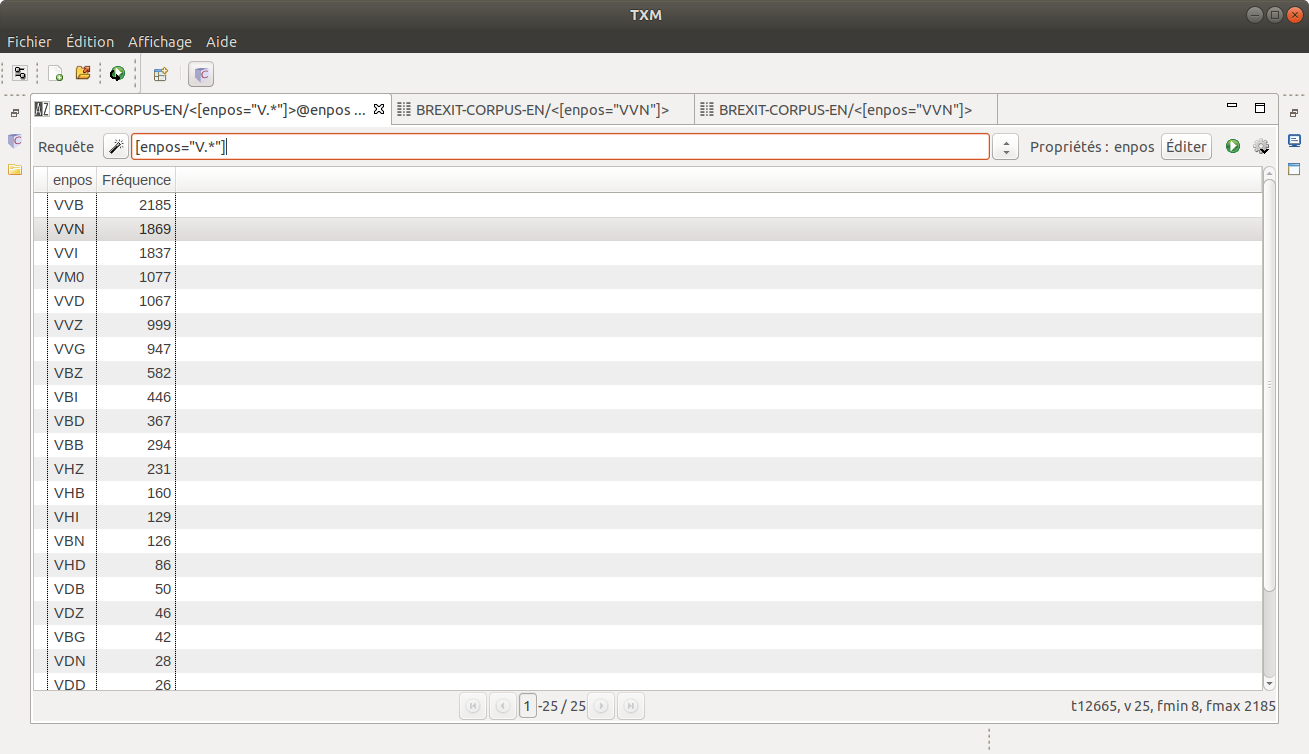
En anglais, nous avons des résultats assez similaires, avec la forme infinitive qui apparaît en première position suivie de la forme prétérit (-ed).
[enpos="V.*"]
Conclusion
Nous sommes parvenus grâce à l'utilisation du langage CQL à faire des requêtes qui nous ont permis de faire un peu "parler" nos corpus. Nous trouvons que la souplesse de ce système de requête permet vraiment d'isoler des cas très précis de phénomènes linguistiques. On a particulièrement aimé travailler avec TXM, qui sait se montrer clément dès lors qu'on fait preuve d'un peu de patience pour utiliser ses différentes fonctions.