Le choix du sujet
Le projet consiste à choisir un terme et à observer son comportement dans différentes langues, dans notre cas le français, l'anglais, le russe et l'albanais.
Lorsqu'il a fallu se mettre d'accord sur le choix d'un terme à étudier, nous avions choisi le terme "chef de cuisine", en raison de notre attrait pour le domaine culinaire. Cependant au fil du semestre après avoir commencé à extraire nos corpus, nous nous sommes rendu compte que le côté peu polémique du terme ne faisait pas particulièrement ressortir d'observations intéressantes en comparant les différentes langues. De plus, le contenu à ce sujet consiste principalement en des sites techniques qui concernent directement la vie du cuisinier au sens pratique. Ils étaient principalement des sites de recherche d'emploi, de recettes techniques et des sites de média qui s'entichent de la cuisine en vogue. Le contenu écrit était donc moins vivant et parlant que nous le pensions…
Le choix d'un sujet plus à même de l'actualité s'avérait être judicieux, car le contenu écrit trouvable sur le net, et ne datant pas trop est abondant, et ainsi, on pourrait constituer un corpus cohérent, plus regroupé autour d'un genre, et éviter de mélanger des contenus de tous abords.
Nous avons fini par prendre la difficile décision de changer de sujet en cours de route, et nous sommes mis d'accord sur le terme "Brexit" puisque la concrétisation du Brexit est un sujet d'actualité qui fait depuis plusieurs années déjà couler beaucoup d'encre, et d'autant plus maintenant que le Royaume-Uni ne fait officiellement plus parti de l'Union Européenne.
Il a été très facile de trouver bien du contenu à ce sujet, et nous nous sommes particulièrement concentrés sur les sites de presse. En parcourant ces sites de presse, nous nous sommes rendu compte que depuis quelques mois, les articles concernant le Brexit avaient changé de ton. En effet, ces dernières années, il s'agissait plus de craindre que le Brexit ne se fasse, et de jauger à vue de nez l'ampleur des dégâts que celui-ci pourrait causer. Mais récemment, la presse parle des conséquences concrètes du Brexit avec les mesures qui commencent à s'appliquer et à influer directement les relations entre le Royaume-Uni et ses voisins européens.
L'objectif est d'essayer par l'usage des techniques vues en cours et d'outils de textométrie de faire parler notre corpus, et d'observer des phénomènes linguistiques intéressants.
Objectifs du projet
Au début de l'année, nous avons d'abord commencé par nous initier au langage bash. Il a fallu apprendre les commandes les plus basiques qui permettent de se déplacer dans le terminal, et effectuer des opérations de bases, comme écrire du texte dans un fichier, manipuler des fichiers et créer un environnement de travail.
L'objectif premier du projet est de faire de l'analyse textuelle. Il convient ainsi de commencer par bien identifier les données sur lesquelles on travaille. On doit récupérer un corpus, qui est un ensemble de textes cohérents, regroupés autour d'une thématique ou d'une période donnée. Ce corpus sera traité par le biais d'un programme que nous avons réalisé dans le cadre du cours.
L'application de cet apprentissage se concrétise par la réalisation d'un script bash. Un script, c'est un peu comme une partition. C'est un texte qui constitue un ensemble défini de commandes qui s'exécutent les unes après les autres dans le but de réaliser des opérations sur des données. Nous lui donnons à traiter des données en entrées et le script doit nous produire des données en sortie, résultats de nos opérations.
Les données avec lesquelles on travaille sont du texte récupéré sur internet, notre corpus en somme. Il s'agit de consulter des pages en rapport avec notre sujet, ici le Brexit, de juger si leur contenu est cohérent et si il l'est, nous récupérons l'URL du site en question. Cet URL est l'adresse à laquelle le contenu est trouvable, donc nous constituons un fichier d'URL regroupant toutes les adresses des sites dont nous voulons récupérer le contenu textuel. Notre sujet étant un sujet politique, nous avons principalement récupéré du contenu venant de sites journalistiques. Il suffit de produire un fichier au format texte brut dans lequel nous séparons chaque URL de chaque page par le caractère retour à la ligne.
Nous avons construit le script autour d'un environnement de travail, une arborescence de dossiers précisément nommés, prévus pour accueillir d'une part nos données en entrée et d'autre part les résultats de nos traitements. Ainsi le fichier susnommé contenant les URLs des sites sont placés dans cette arborescence, et d'autres dossiers sont prévus pour accueillir les résultats. Le premier traitement consiste à récupérer notre corpus au format texte après avoir vérifié la validité de l'encodage, à savoir si l'encodage utilisé est bien de l'UTF-8. Il est essentiel de vérifier cela car les sous programmes que nous utilisons le requièrent afin de bien fonctionner.
Voici la représentation graphique de traitements inclus dans notre script :
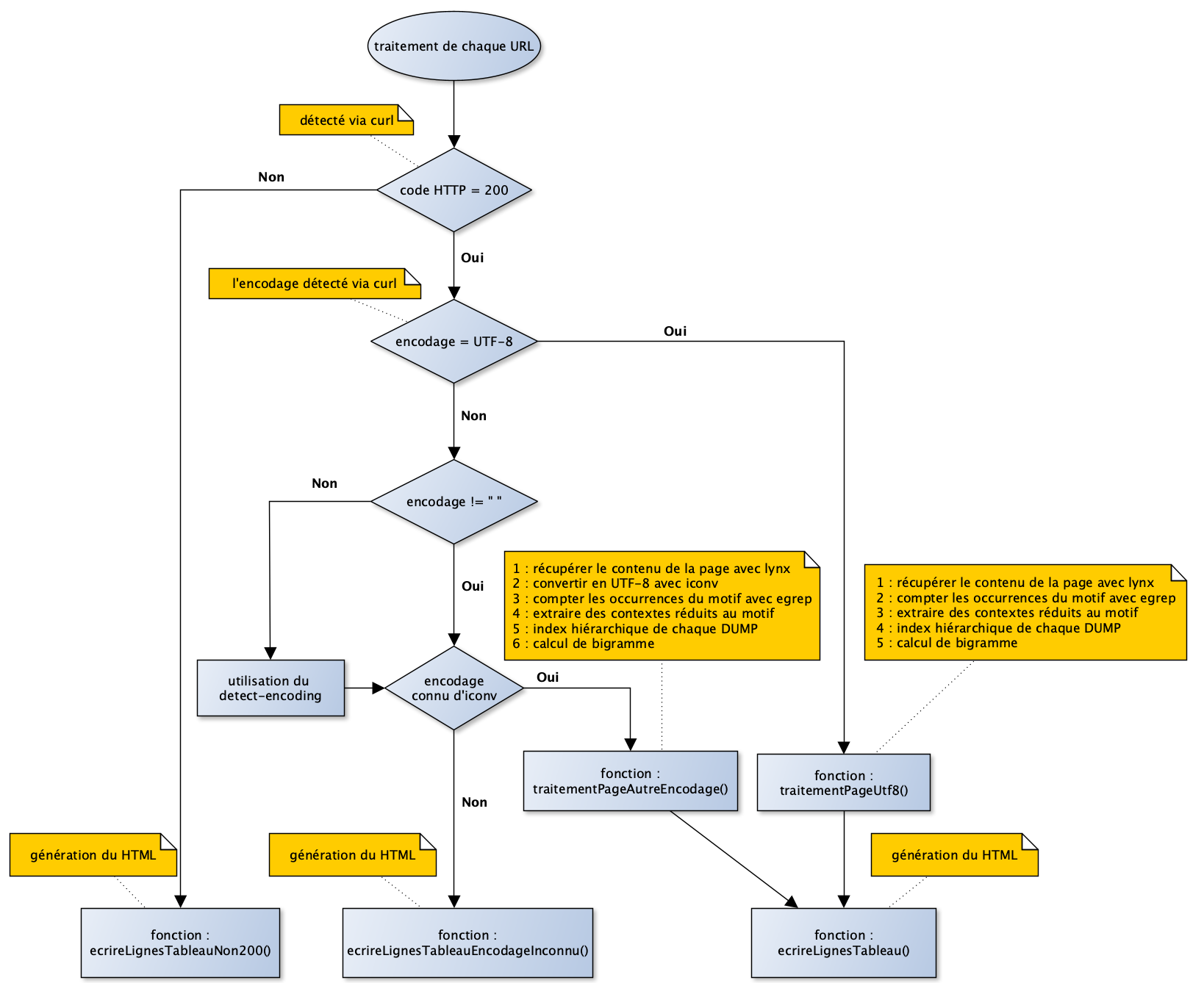
Ensuite, nous effectuons sur ce corpus des opérations textométriques de base, comme compter le nombre d'occurrences d'un motif dans un texte, constituer un fichier qui place le motif ciblé dans son contexte (le contexte textuel dans lequel le mot ciblé est trouvé et la ligne à laquelle il est trouvé), créer des index (une liste classant les tokens du plus occurrent au moins occurrent).
Arborescence de travail
Voici la représentation graphique de notre environement de travail :
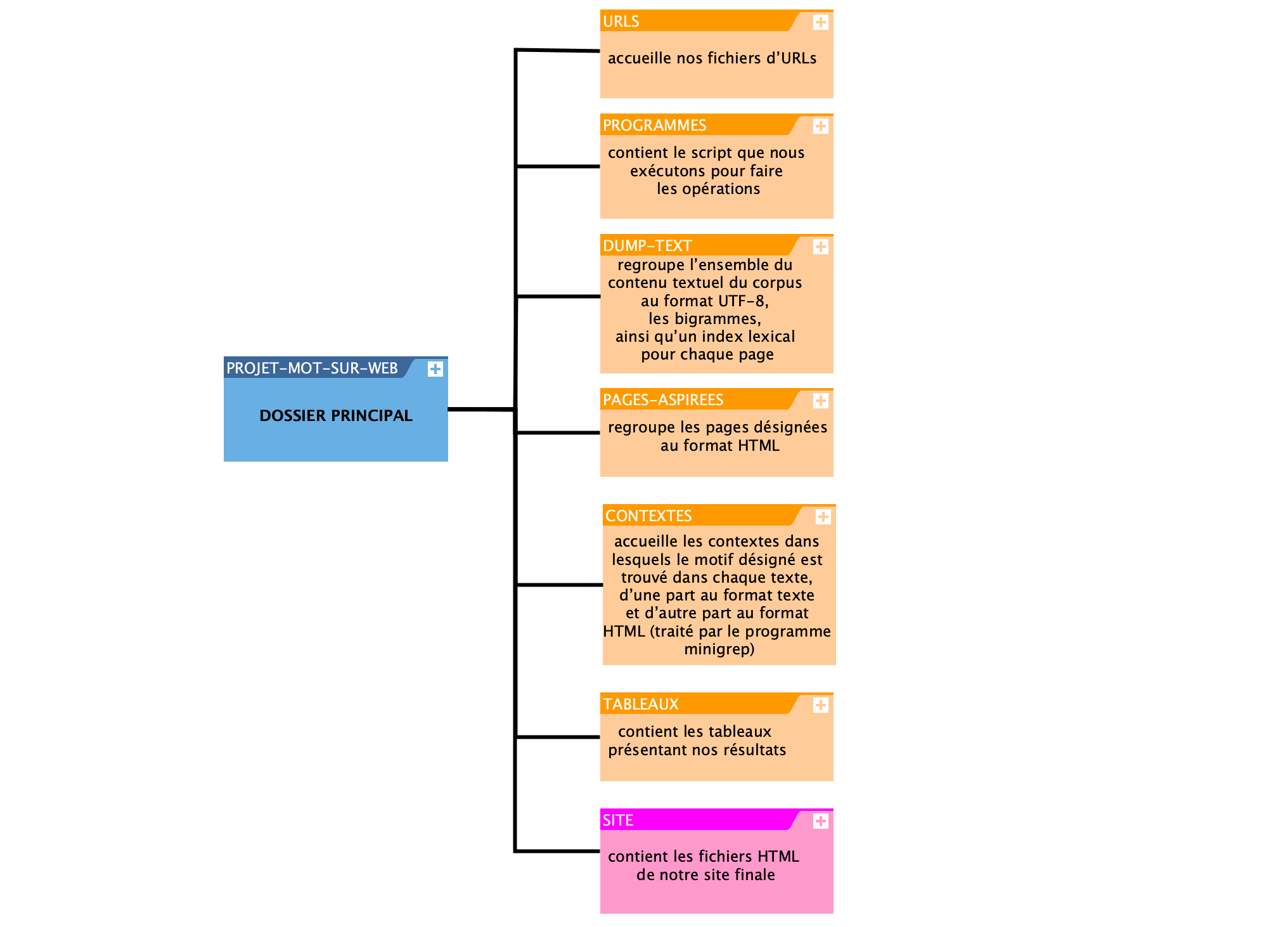
En entrée on a eu les dossiers URLS, et PROGRAMMES, DUMP-TEXT, PAGES-ASPIREES, CONTEXTES et TABLEAUX. Le dossier SITE était ajouté à la fin du projet afin d'accueillir tous les fichiers HTML et CSS de notre site final.
Vous trouverez plus loin les différentes versions de nos scripts ainsi que nos tableaux, pour chaque langue.