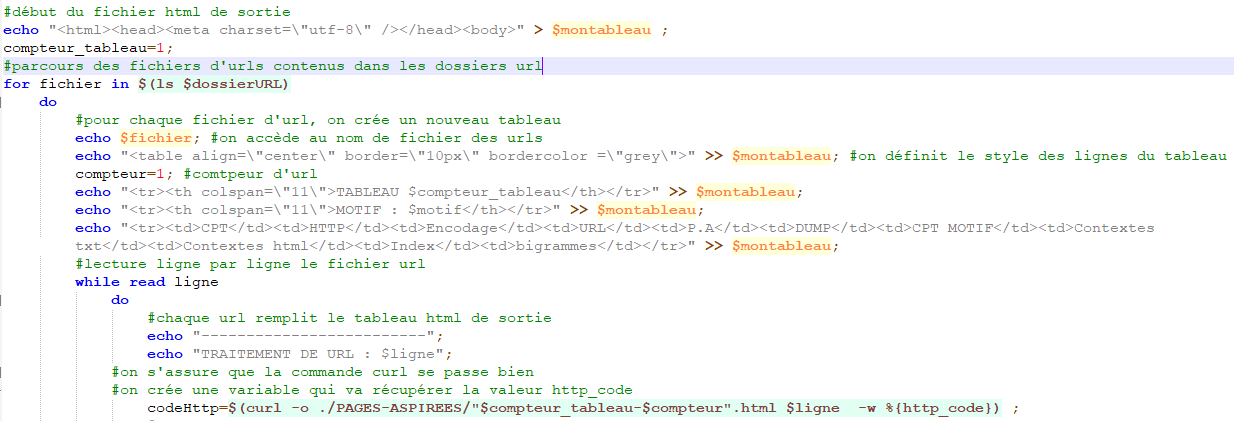
Le script que nous avons écrit nous a servi à créer les tableaux des 50 URLs que nous avons récupérées pour chaque langue. Dans un premier temps nous demandons dans le script de récupérer dans les fichiers URL, les URLs ligne par ligne et grâce à la commande curl nous récupérons le contenu de la page html. Cette commande indique également si la page fonctionne ou non. Si c’est le cas, elle indiquera le code 200, autrement elle indiquera 301. Il peut y avoir d’autre code comme 404, 302, 401 mais ces codes signifient que l’on ne peut accéder à la page soit parce que l’accès nous y interdit soit parce que celle-ci a été déplacée ou supprimée.
Le script que nous avons écrit nous a servi à créer les tableaux des 50 URLs que nous avons récupérées pour chaque langue. Dans un premier temps nous demandons dans le script de récupérer dans les fichiers URL, les URLs ligne par ligne et grâce à la commande curl nous récupérons le contenu de la page html. Cette commande indique également si la page fonctionne ou non. Si c’est le cas, elle indiquera le code 200, autrement elle indiquera 301. Il peut y avoir d’autre code comme 404, 302, 401 mais ces codes signifient que l’on ne peut accéder à la page soit parce que l’accès nous y interdit soit parce que celle-ci a été déplacée ou supprimée.
Nous créons ensuite la première boucle du script. Si le code http indique bien 200 nous cherchons à connaître la valeur de l’encodage pour commencer les traitements du motif.
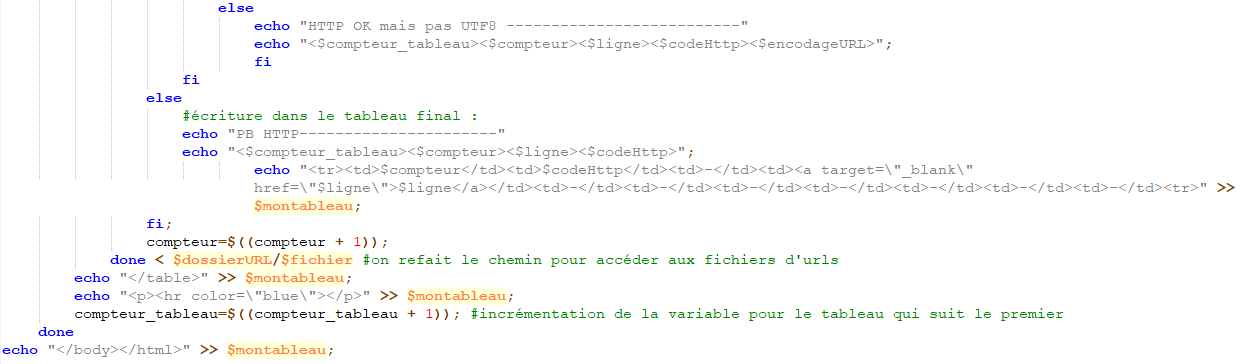
Nous introduisons une seconde boucle dans laquelle nous indiquons que si l’encodage est en UTF-8 alors nous l’affichons dans la colonne correspondant à l’encodage sinon des « -- » y seront insérés et des « ?? » se trouveront dans les colonnes des dumps et du motif.
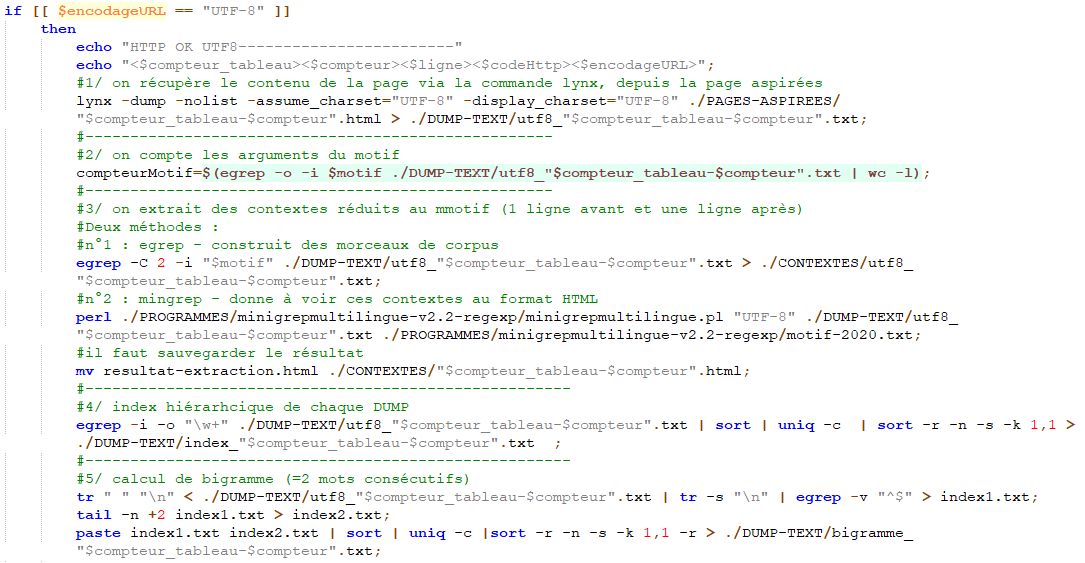
En outre, si nous avons un encodage UTF-8 nous pouvons continuer les traitements. Ces traitements vont nous servir à récupérer le mot que nous avons décider d’analyser. Nous allons donc prendre les contextes que nous retrouvons sous deux formes. Nous aurons les contextes au format txt et nous les auront au format html. Nous allons aussi récupérer les index et les bigrammes liés au motif.
Cependant, il nous reste des URL qui n’ont pas été traitées car la commande curl n’arrivait pas à récupérer l’encodage. Pour remédier à ce problème, nos URLs nous on permit, en raison des langues choisies notamment, de créer une nouvelle boucle servant à convertir l’encodage qui n’est pas en UTF-8 et de recommencer les traitements que nous avons vu précédemment.
A partir de ce moment-là, tout doit être opérationnel nous pouvons passer à l’écriture finale du tableau (et du script).