BàO 1 : Extraction des contenus textuels
Objectif
Appliquer le traitement d'extraction des données textuelles à toute l'arborescence de fils RSS
Qu'est-ce-qu'un flux RSS ?
RSS est l'acronyme de « Really Simple Syndication ». Il s'agit d'un format standard d'échange de données reposant sur la technologie XML qui permet de structurer un contenu au moyen d'un balisage de l'information. Ainsi, cela permet de donner du sens au contenu syndiqué grâce aux balises XML adéquates mais également de pouvoir le stocker en brut et sans mise en forme particulière. L'avantage de ça est bien entendu de pouvoir le porter sur un support complètement différent que son support original.
Données à extraire
Les titres et les decriptions de chaque article dans les fils RSS
Sortie de Bào 1
Pour chaque rubrique, 2 fichiers de sortie : TXT et XML
Ici dans notre travail, les rubriques à traiter sont : à la une et international. La rubrique "à la une" possède un code d'identifiant "3208", ex. 0,2-3208,1-0,0.xml, et la rubrique "international" possède le code d'identifiant 3210, ex. 0,2-3210,1-0,0.xml
C'est parti !
Il y a deux méthodes pour réaliser la BàO 1 : une via des expressions régulières, l'autre via XML:RSS. La première considère le texte comme un "sacs de caractères" dans lequel on va essayer de repérer certaines régularités (via les regexep). La seconde prend en considération la structuration logique du texte (un arbre) et sa modélisation dans un programme pour au final n'avoir qu'à "cueillir" les feuilles textuelles visées.
Extraction grâce à des expressions régulières
Il s'agit d'un processus récursif de trouver les fichiers, c'est-à-dire un processus d'ouvrir un répertoire et de le vérifier et jusqu'à qu'on trouve ce qu'on veut. C'est les expressions régulières qui nous permettent de réaliser les étapes de vérification.
Avec le script de perl, premièrement on trouve tous les répertoires d'une façon récursive, lorsqu'on arrive à l'intérieur de tous les répertoires, on récupère tous les fichiers xml à l'aide d'une expression régulière if ($file =~ /$rubrique.+\.xml$/) qui permet de sélectionner tous les fichiers dont le nom contient le code de rubrique qu'on choisit. Ensuite, pour extraire les titres et les descriptions se situant dans le fichier xml, on se servit encore d'une expression régulière :

Notre groupe a choisi les rubriques "à la une" et "international" pour travailler, donc on a lancé les commandes dans le cygwin comme le suivant:
$ perl BAO1_regexp.pl 2018 3208
$ perl BAO1_regexp.pl 2018 3210
Télécharger le script et les résultats :
BAO1_regexp.pl sortie-3208-regexp.txt sortie-3208-regexp.xml sortie-3210-regexp.txt sortie-3210-regexp.xmlExtraction grâce à XML:RSS
XML::RSS est un module de perl pour créer et mettre à jour les fichiers RSS. Pour utiliser ce module, il faut d'abord l'installer dans la machine.
Dans le terminal de perl, on tape ces commandes :
perl -MCPAN -e shell
cpan>install XML::RSS
cpan>quit
Comme on a des problèmes à utiliser le module XML::RSS dans le cygwin, on a déplacé dans le cmd pour faire fonctionner le script :
perl BAO1_xml_rss.pl 2018 3208
Le module XML:RSS nous permet de fouiller dans l'arborescence du fichier xml, il nous emmène dans tous les noeuds "item" et recueillir les contenus inclus dans ses noeuds descendants "titre" et "description".
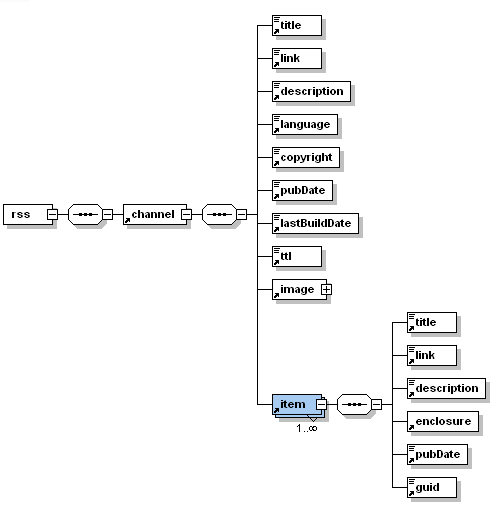
Télécharger le script et les résultats :
BAO1_xml_rss.pl sortie-3208-xmlrss.txt sortie-3208-xmlrss.xml sortie-3210-xmlrss.txt sortie-3210-xmlrss.xmlRemarques
En fait, les deux méthodes produisent les mêmes résultats, mais la vitesse d'exécutation oppose les deux. Le script avec les expressions régulières fonctionne beaucoup plus vite que celui avec la biblithèque XML::RSS. Donc dans la BàO 2, pour ne pas augmenter trop le temps total de l'exécutation de script, on adopte la méthode avec les expressions régulières pour extraire les donneés et ensuite les étiquetter avec deux outils différents.