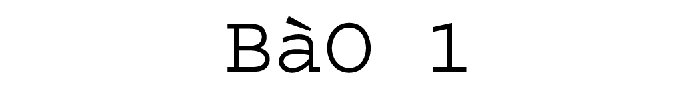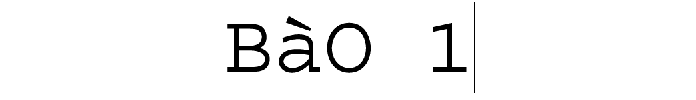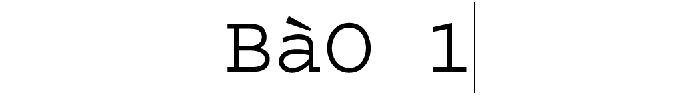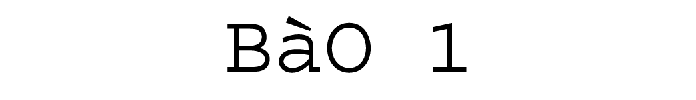
La première partie du projet Boîte à Outils a été dévéloppée pendant les premières séances du Projet Encadré 2, cours dispensé par Serge FLEURY et Jean-Michel DAUBE. À l'aide du langage de programmation Perl, nous avons conçu deux versions: Perl « pur » avec regexp (avec des expressions régulières) et une autre avec le module XML::RSS (qui prendra la grammaire spécifique à RSS). En plus, on a rédigé notre propre version intégrant le module XML::XPath.
Les expressions régulières constituent un sujet très riche en développements et, d'ailleurs, on pourrait même considérer Perl comme leur alma-mater. Notons que una grande partie de la puissance de Perl reside sur son aisance avec l'analyse et le traitement des données textuelles. XML::RSS est une bibliothèque qui est utilisé principalement pour créer, renouveler et soutenir les fichiers RDF Site Summery (RSS). Il sert également à générer des fichiers en format HTML à partir des fichiers RSS.
De l'autre côté, la bibliothèque XML::XPath exécute les fonctionnements spécifiques de XPath. Succinctement, XPath est un élément majeur dans la norme XSLT. Il peut être utilisé pour naviguer à travers les éléments et attributs dans un document XML. XPath utilise des expressions de chemin pour sélectionner des nœuds ou des ensembles de nœuds dans un document XML.
Toutes les versions du programme recherchent dans un dossier tous les fichiers XML (en l'occurrence, ce sont des articles différenciés par rubriques du journal Le Monde pour l'année 2018) dans un répertoire qui représente une arborescence des dossiers. Ce fil RSS contient 17 fichiers (chacun correspondant à une rubrique différente) qui sont générés une fois par jour sur toute l'année.
Pour notre projet, on a choisi les rubriques Sciences, Culture, Technologies, Cinéma et Livres, qui correspondent aux identifiants de rubriques 3244, 3246, 651865, 3476 et 3260 respectivement. Vu que les sujets sont souvent liés entre eux, c'est possible que notre programme supprimera beaucoup de doublons entre les sections.
Le programme extrait les titres, les descriptions et les dates de publication de chaque article et à ce stade produit deux sorties : un fichier texte brut et un fichier XML avec des balises < titre > , < description >, qui sert notamment à organiser et identifier les informations par des marqueurs.
En outre, on a rajouté l'information sur la date de la publication de l'article; la balise qui sert à ce but est : < pubDate >. Cette sortie nous permettra éventuellement de faire de la tokenisation et de l'étiquetage via TreeTagger et Talismane en BAO 2, de l'extraction de patrons en BAO 3 et de passer de textes aux graphes en BAO 4.
L'algorithme de traitement de cette étape comprend deux niveaux principaux: parcours récursif du répertoire arborescent et l'extraction de données textuelles des sections qui nous intéressent. En plus, on a fait le nettoyage des fichiers des éventuelles scories. Dans la plupart de cas, on aura à remplacer les entités HTML commencant par "&" par les caractères qu'elles représentent. Dans la plupart des cas, ils correspondent notamment aux apostrophes, guillemets doubles et simples.
Le cœur de la Boîte à Outils 1 se fonde sur un programme Perl qui va parcourir l'arborescence d'une manière récursive. Ça veut dire que lorsque l'algorithme atteint le bout de l'arbre, il va sortir et entrer dans la ramification suivante. Cet algorithme est une technique classique de parcours de l'arbre qui est souvent appelée Algorithme de parcours en profondeur (ou DFS, pour Depth-First Search) qui sert à parcourir des arbres mais plus généralement des graphes.
À chaque fois qu'on atteint la fin d'arborescence et on trouve un fichier XML contenant l'identifiant de la rubrique passée en paramètre sous la ligne de commande, on va extraire les balises de titres, descriptions et dates avec leurs valeurs textuelles et les sauvegarder dans les fichiers de sortie sous la forme de texte brut et format structuré XML.

La version pure de Perl qui utilise des expressions regulières (on peut dire que Perl était le point de départ et l'alma mater des ER) représente la programmation classique et explicite. Elle nous permet de comprendre le fonctionnement du programme pas à pas.
XML::RSS : À l'aide du module XML::RSS, qui permet notamment de créer et de mettre à jour les fichiers RSS, on a conçu une version alternative pour notre programme. En utilisant un parser, on a pu parcourir toute l'arborescence des fichiers contenus dans le corpus et, ensuite, extraire très aisément les informations prévues grâce aux fonctions contenues dans le module.
XML::XPath : On a également crée une troisième version utilisant le module XML::XPath, dont son fonctionnement s'avère, en l'occurrence, très proche de celui du module préalable.
Le lancement reste toujours le même dans les trois versions :
perl5.28.1.exe bao1_version_NOM.pl NOM_REPERTOIRE_A_PARCOURIR NOM_RUBRIQUE_A_EXTRAIRE
Voici la sortie en format texte brut :
Exemple :
Voici la sortie en format structuré (XML) :
Exemple :

Temporibus autem quibusdam et aut officiis debitis aut rerum necessitatibus saepe

Temporibus autem quibusdam et aut officiis debitis aut rerum necessitatibus saepe

Temporibus autem quibusdam et aut officiis debitis aut rerum necessitatibus saepe

Temporibus autem quibusdam et aut officiis debitis aut rerum necessitatibus saepe

Temporibus autem quibusdam et aut officiis debitis aut rerum necessitatibus saepe