
Scripts supplémentaires
Une fois les tableaux obtenus grâce à notre script principal, nous avons écrit deux petits scripts afin d'obtenir deux corpus par langue: un corpus global avec des contextes aggrandis et un corpus "zoomé" avec des contextes beaucoup plus réduits. Les deux scripts consistent en la concaténation de tous les fichiers "dump" ou "contextes". Le but final était de pouvoir comparer les résultats des analyses avec iTrameur (ces analyses sont visibles ici) entre les deux corpus.
Le premier script ci-dessous est celui permettant de constituer le corpus global à partir des fichiers dump segmentés. Comme nous l'avions marqué sur notre blog ici, nous avions dû utiliser un segmenteur afin de pouvoir réaliser les petits traitements linguistiques contenus dans le script principal sur la langue chinoise.
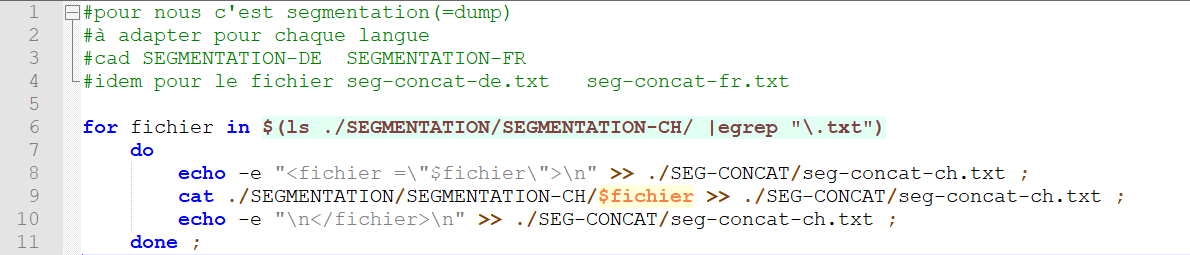
Le deuxième script supplémentaire ci-dessous est le même que le précédent mais adapté pour les fichiers contextes.

Nous avons utilisé ces deux scripts sur les dossiers SEGMENTATION et CONTEXTES de chaque langue (que nous avions dû trier rapidement par langue) afin d'obtenir pour les trois langues de notre travail un corpus général, large et un corpus réduit, "zoomé".