Choix des patrons à extraire
Nous avons choisi dans un premier temps d'étudier les ensembles de patrons de type :
NOM + PREP + NOM + PREP + NOM
Ce qui donne comme recherche dans notre fichier de motif :
NC.+ PREP NC.+ PREP NC.+
Cet ensemble permet des résultats consistants car il demande deux substantifs, les groupes nominaux auront un contenu analysable (plus d'un ensemble de type NOM + ADJ par exemple) et seront surtout en nombre suffisants dans le corpus. Ils ne seront pas non plus trop nombreux. Nous obtiendrons a priori un nombre de résultats suffisant pour permettre une analyse pertinente par son contenu et sa fréquence.
Dans un deuxième temps, nous rechercherons les patrons suivants :
NOM + ADJ + ADJ
Notre recherche se présente sous la forme suivante :
NC.+ ADJ.+ ADJ.+
Comme précédemment, ces patrons sont en nombre suffisants pour une analyse et ils présentent l'avantage d'être une construction fréquente dans le journalisme. En effet, c'est un type syntagmatique apprécié des auteurs en général, car l'accumulation de deux qualificatifs après un substantif le met presque automatique en relief dans une phrase voire dans un paragraphe. N'est-ce pas là une mine d'or qui n'attend qu'à être exploitée ?
Choix des rubriques
Le choix des rubriques repose sur un souhait d'étudier la place de la France à l'international et aussi d'analyser une question d'actualité qu'est la place de l'Europe et sa relation avec la France d'une part, et d'autre part son utilité, souvent remise en question depuis 2005 et plus particulièrement depuis 2015 avec la crise des réfugiés. En choisissant les rubriques Internationale, Europe et France, nous souhaitons répondre à ces questions. Quelle est la place de la France dans l'actualité internationale ? Quels sont les liens entre l'actualité internationale, européenne et française ? Comment la France traite-t-elle la question de l'Europe ? Nous espérons donc traiter des rapports entre la France et les autres puissances mondiales ou européennes, ainsi qu'avec les pays qui font malgré eux la une de tous les articles internationaux (Grèce, Syrie ...).
Résultats de l'extraction
Nous avons donc obtenu les fichiers de résultats suivants :
-
- un fichier txt contenant les titres et descriptions de chaque article pour chaque rubrique : 3210.txt, 3214.txt, 3224.txt.
- son équivalent étiqueté par treetagger au format xml pour chaque rubrique : 3210.xml, 3214.xml, 3224.xml


-
- un fichier txt contenant les titres et descriptions de chaque article à partir d'un script utilisant XML::RSS : 3210_xmlrss.txt, 3214_xmlrss.txt, 3224_xmlrss.txt.
- son équivalent étiqueté par treetagger et formé avec XML::RSS : 3210_xmlrss.xml, 3214_xmlrss.xml, 3224_xmlrss.xml.
-
- un fichier étiqueté par CORDIAL pour chaque rubrique : 3210_ansi.cnr, 3214_ansi.cnr, 3224_ansi.cnr.
-
- un fichier txt contenant les résultats de l'extraction des patrons pour chaque ensemble de patrons et pour chaque rubrique : 3210_patrons1.txt, 3210_patrons2.txt, 3214_patrons1.txt, 3214_patrons2.txt, 3224_patrons1.txt, 3224_patrons2.txt.
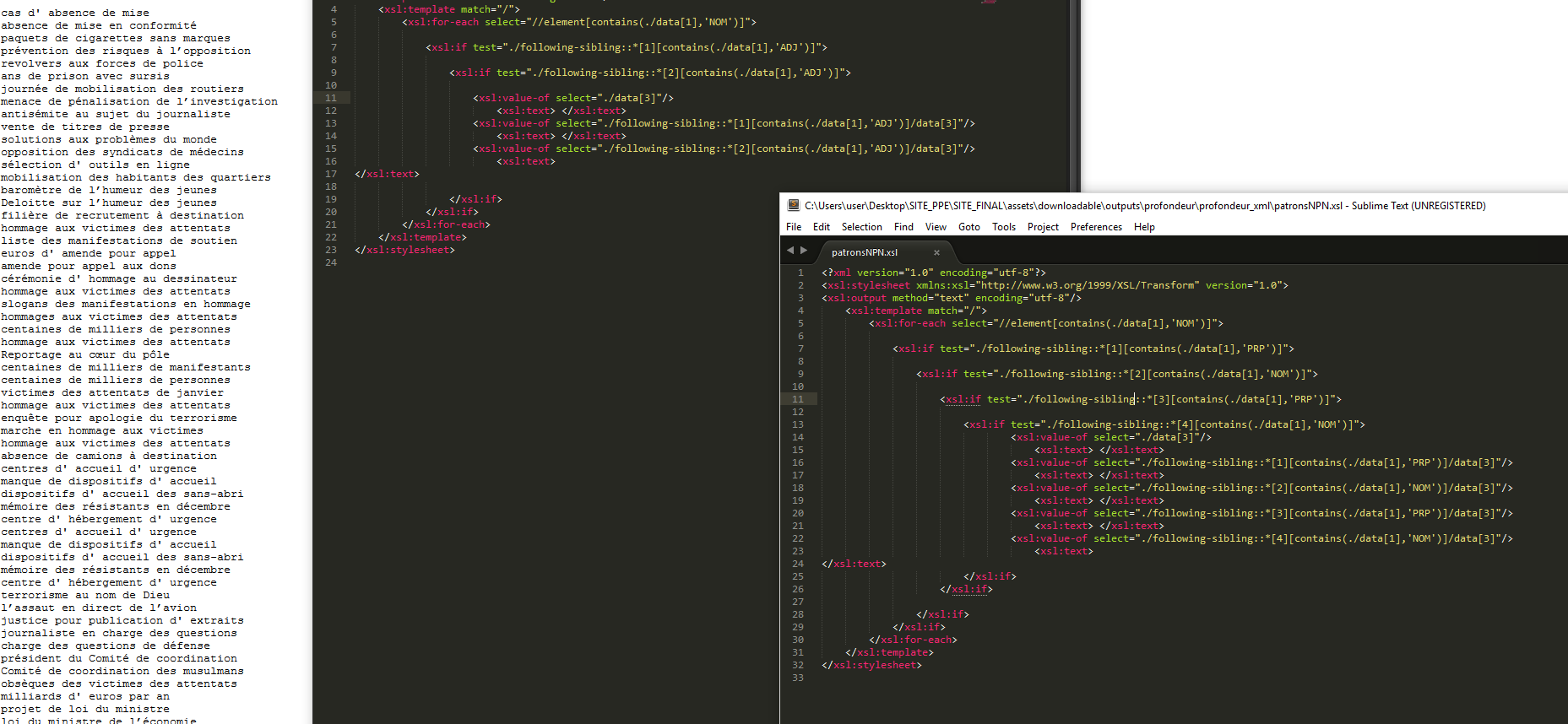
- un fichier contenant les extractions des patrons avec une feuille de style XSLT à partir des fichiers xml : 3210_patrons1.xml, 3210_patrons2.xml, 3214_patrons1.xml, 3214_patrons2.xml, 3224_patrons1.xml, 3224_patrons2.xml.
- les fichiers pour la profondeur correspondant :
- profondeur3210.txt, profondeur3214.txt, profondeur3224.txt
- profondeur3210.xml, profondeur3214.xml, profondeur3224.xml
- les fichiers pour la profondeur étiquetés :
- profondeur3210_xmlrss.txt, profondeur3214_xmlrss.txt, profondeur3224_xmlrss.txt
- profondeur3210_xmlrss.xml, profondeur3214_xmlrss.xml, profondeur3224_xmlrss.xml
Dans la boîte à outils 4, nous avons tiré des graphes à partir de nos fichiers de résultat. Nous avons cherché les liens autour des mots : "france", "monde" et "europe" pour commencer.
Evaluation de TreeTagger et de Cordial
Nous allons nous attarder sur les différences d'étiquetage entre CORDIAL et TreeTagger. Le premier étant un logiciel de correction orthographique, d'étiquetage et d'analyse syntaxique payant, alors que TreeTagger est un logiciel gratuit, on peut s'attendre à une meilleure qualité d'étiquetage par CORDIAL. Nous verrons les différences qui peuvent exister.
Il est intéressant de constater que pour une même rubrique, un même patron et un même mot-clé, les résultats de Cordial et de TreeTagger n'ont rien à voir l'un avec l'autre, mais en plus chacun donne des résultats significatifs. En effet, pour le motif "migrants", Cordial nous donne comme cooccurrence bateau, naufrage... alors que TreeTagger nous donne comme résultats passeurs, afflux, accueil...
Cependant, il est arrivé plusieurs fois que l'étiquetage Cordial donne comme résultats des coocccurrences inutiles comme sélection-des-photographies-d'actualité . Alors que TreeTagger fournit toujours des données exploitables et sensées.
Après cette étude, il est ressorti que l'étiquetage le plus fiable, et donnant des résultats satisfaisants était TreeTagger, celui qui est gratuit, rappelons-le...
Bilan sur les différences entre surface et profondeur
A partir de nos fichiers, nous avons aussi comparés les résultats obtenus pour la surface et pour la profondeur.
Dans un premier temps, nous avons désiré utiliser trois patrons morpho-syntaxiques, finalement, au vue de la quantité de données considérable fournie par les deux premiers, nous avons renoncé. Comme l'on pouvait s'y attendre, notre premier patron syntagmatique est celui qui donne le plus de résultats. Cependant il est aussi celui qui offre le plus de bruit à nos oreilles informatiques. Lors d'un rapide calcul du rappel et de la précision, nous nous sommes vite rendu compte que le silence certes important du patron "NOM ADJ ADJ", donnait quand même bien plus satisfaction que l'ensemble "NOM PREP NOM PREP NOM", auquel notamment se rattachent les syntagmes inutiles du genre : "mise à jour des pages" .
En conclusion, même si le NOM ADJ ADJ est plus petit, il donne finalement plus de résultats.
D'autre part, et c'est la partie la plus importante de cette analyse, nous avons mené une étude sur ce qui ressort de l'étude de la surface et de l'étude de la profondeur. Dans un cas, nous n'avons étudié donc que le contenu du titre et de la description et dans l'autre, nous avons étudié le contenu complet de l'article. Le but était d'arriver à déterminer si l'étude du titre et de la description d'un article suffisent à son analyse ou s'il est nécessaire de mener une analyse en profondeur. Nous avions donné l'exemple des sites qui regroupaient des articles de médecine qui pour chaque article donnent un résumé, est-il possible de mener une analyse sur de tels corpus, ou est-il nécessaire de regarder les contenus complets des articles ?
Finalement, les thèmes qui ressortent de nos résultats sont sensiblement proches, il est surtout question des migrants (à noter la présence de "réfugiés" aussi forte que "migrants", souvenir de Programmation Projet Encadré Semestre 1...), des différents discours des ministres, des attentats, de la BCE...
Là où se fait la différence c'est lorsque l'on observe les coocurrences des mots-clés . En effet, ils sont très diversifiés pour les motifs de la profondeur alors que pour ceux de la surface, ce sont souvent les mêmes, une répétition récurrente, en particulier lors des patrons "NOM ADJ ADJ", ce qui est assez compréhensible dans la mesure où l'on voit rarement cette structure nominale dans un titre ou dans une description. Toutefois, compréhensible ou pas, l'analyse de données sur le patron le plus performant révèle la nécessité d'utiliser le contenu textuel d'un article pour avoir une source d'informations suffisante et diversifiée.
Bilan sur les différences entre surface et profondeur
Ce qu'il faut retenir de cette étude, c'est que malgré le fait que l'analyse de surface permet de se faire une idée d'un contenu et donc de travailler sur des données, les résultats vraiment probants ne peuvent être obtenus que grâce à une analyse en profondeur des données, et donc utiliser l'emsemble d'un contenu textuel, afin de travailler sur des informations utiles mais également fiables.