Cette boîte à outils consiste en l'extraction d'informations d'une feuille de données au format XML et de parcourir une arborescence de fichiers. Un premier script permet d'extraire le contenu textuel d'un ensemble de fichiers vers une sortie au format txt contenant, pour chaque article, le titre et la description. Un deuxième script permet d'obtenir un fichier XML avec le module perl XML::RSS. Enfin, nous réalisons un script pour la profondeur dans la prochaine boîte à outil.
Quelques explications sur le script
Pour le premier script, nous utilisons le schéma conceptuel suivant :
ouverture du fichier
si c'est un fichier xmlrécupérer le texte du fichierchercher les balises 'titre' et 'description'imprimer le contenu des balises dans un fichier txtimprimer le contenu des balises dans un fichier XML dans les balises 'titre' et 'description'
Voilà la liste des fichiers dans l'arborescence :
Et voilà un extrait d'un fichier :
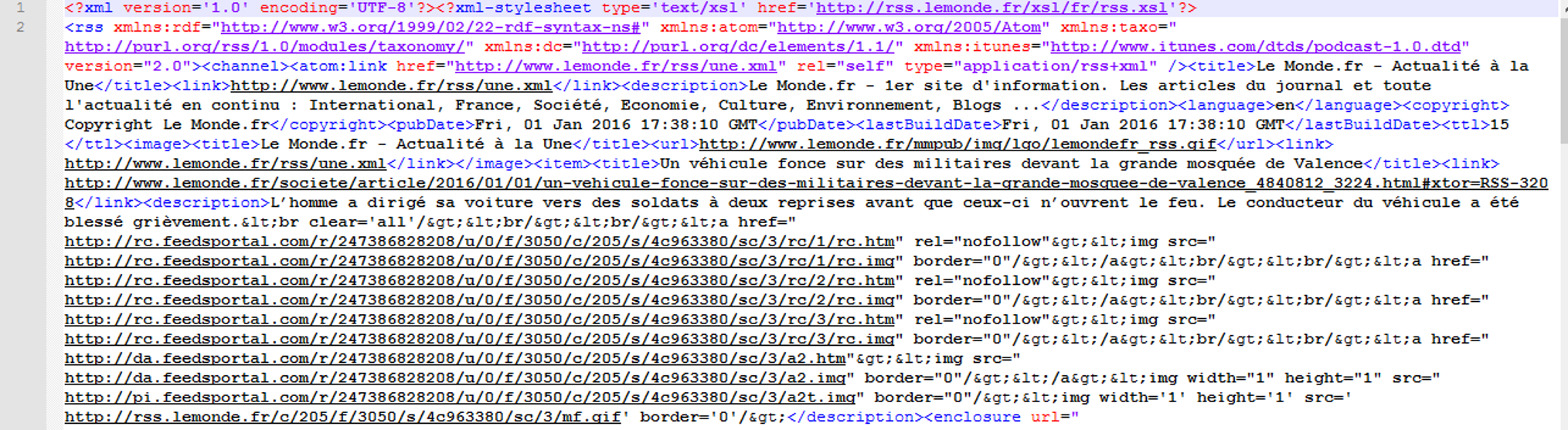
On récupère d'abord le contenu du fichier avec une boucle. On utilise un 'chomp' pour pouvoir récupérer l'ensemble sur une seule ligne.
while (my $ligne = <FIC>){chomp $ligne;$texte = $texte . $ligne;}
Mettre tout le contenu du fichier de sortie sur une seule ligne permet ensuite d'utiliser une autre boucle en faisant une recherche de motif avec l'option m sur une requête d'expression régulière.
while ($texte =~m/<item><title>([^<]+?)<\/title><link>([^<]+?)<\/link><description>([^<]+?)<\/description>/g)my $titre=$1;my $link=$2;my $description=$3;
Dans l'expression régulière, l'utilisation de parenthèses permet de récupérer les valeurs dans des variables par défaut en perl, ainsi le contenu de la première parenthèse est récupéré dans la variable $1. On peut donc assigner les contenus des parenthèses à nos variables.
$titre=~ s/<.+?>//g;$description=~ s/<.+?>//g;$link=~ s/#xtor=RSS-3208//g;$titre.=".";
Afin de ne pas récupérer deux fois le même article, on met en place une vérification en utilisant une table de hashage, on teste si l'article n'est pas déjà dans notre table, sinon on rajoute le titre de l'article dans la table avec comme valeur 1, cela permet ensuite de pouvoir utiliser une structure en if comme test booléen.
if (!(exists $dico{$titre})){$dico{$titre} = 1;
Le script complet est téléchargeable ici.
Utilisation du module XML::RSS
La deuxième possiblité pour effectuer la même tâche est d'utiliser le module perl XML::RSS téléchargeable sur CPAN. Vous trouverez une page explicative ici.
On créé une entité rss :
Le module permet de parser directement le fichier RSS récupéré au format XML et importe toutes les informations dans un tableau :my $rss = new XML::RSS;
On traite ensuite les entités du fichier RSS dans une table de hashage, on peut donc récupérer directement les balises du fichier RSS :$rss->parsefile($file);
On peut ensuite tout imprimer dans notre fichier de sortie en utilisant des balises XML :foreach my $item(@{$rss->{'items'}}) {$TEXTEDUFILXML.= "<article id=\"$nombredechampsdescription\">\n";my $titre=$item->{'title'};my $description=$item->{'description'};$TEXTEDUFILXML="<titre>".$titre."</titre>\n";$TEXTEDUFILXML="<description>".$description."</description>\n";}
print OUT "TITRE = $titre\n";print OUT "DESCRIPTION = $description\n";print OUT2 "<titre>".$titre."</titre>\n";print OUT2 "<description>".$description."</description>\n";
Le script complet est téléchargeable ici.
Données extraites
Vous pouvez trouver ici des exemples des différents fichiers de sortie que nous obtenons avec ces scripts :