Projet boite à outils
Arezki SADOUNE.Leidiana MARTINS. Latéfa FAïZ
I-BOITE A OUTILS 1: Extraction de texte:
L'objectif de cette première étape est d'écrire un script PERL qui parcourt l'arborescence de fils RSS pour extraire de chaque balise
<item> le contenu des balises <title> ainsi que<description>.
Nous avons également choisi de donner la possibilité à l'utilisateur de notre programme
d'opter soit pour le traitement de tous les fils, soit pour extraire et traiter les fils de la rubrique de son choix.
L'extraction s'effectuera par deux méthodes, d'abord en utilisant les expressions régulières,
ensuite avec la méthode parsefile() de la bibliothèque XML::RSS.
On aura donc en sortie deux scripts pour, théoriquement, les mêmes résultats.

1)Mise en place de notre interface utilisateur:
Oui! Comme mentionné plus haut nous avons mis en place un système pour interroger en ligne de commande l'utilisateur sur la rubrique qu'il désire traiter
Comme on peut le voir sur l'image qui suit, la syntaxe pour exécuter le programme en ligne de commande est 'perl', suivi du 'nom_du_programme' ensuite de l'argument 'arborescence' L'arborescence des fils du monde de 2010 est disponible sur ce lien.
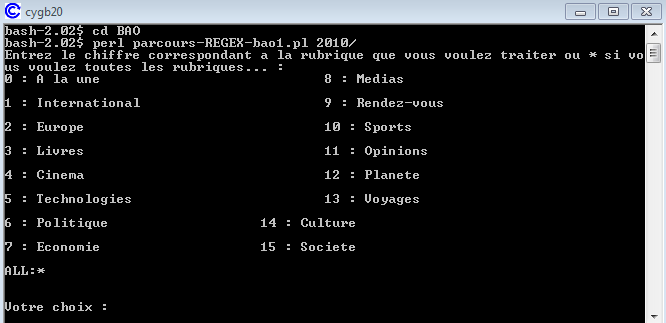
Ce dispositif nous permet de récupérer ce choix, de stocker le chiffre dans une variable ($id).On relie chaque choix à une autre variable($num)qui lui correspond (($num) correspond au numéro qui distingue chaque rubrique).
Voilà ce qui simplifie la sélection des fichiers à traiter selon le choix de l'utilisateur.
2)Chemin 1: script extracteur par les expressions régulières:
En se basant sur les bouts de code initiaux fournis par nos enseignants, il s'agit d'extraire, filtrer et nettoyer le texte contenu dans les fils avec un seul programme.
voici le code filtreur de départ:
open(FILEINPUT,"$ARGV[0]");
while ($ligne =
if ($ligne=~/REGEXP/) {
print $ligne;
}
close(FILEINPUT) ;
Donc, ouverture d'un fichier en lecture, ensuite impression de chaque ligne, tant qu'il y a une ligne(sous la boucle while).
La qualité du texte récupéré nécessite un gros travail de nettoyage, d'où l'utilité de chercher et de remplacer les anomalies (de codage entre autres) comme suit:
open(FILEINPUT,"$ARGV[0]");
while ($ligne =
$ligne=~s/forme-erronée/remplacement/g;
print $ligne;
}
close(FILEINPUT);
En ce qui est du programme dans son ensemble, pour résumer on dira qu'il crée les fichiers texte et XML de sortie(après avoir interrogé l'utilisateur) sur lesquels il écrit les résultats($DUMPTXT et $DUMPXML) de la procédure 'parcoursarborescencefichiers' qui, elle même, fait appel à la procédure 'nettoietexte'. Autrement dit, notre code pour filtrer a été intégré à la procédure 'parcoursarborescencefichiers' et le nettoyeur dans une autre procédure.
Aperçu de notre script avec les expressions régulières:

Aperçu d'une sortie texte réalisée avec ce script(rubrique'rendez-vous'):

> script et sorties
Cliquez sur ce lien si vous voulez télécharger notre script basé sur les expressions régulières ainsi que les sorties XML et TXT pour toutes les rubriques (un seul traitement avec *) et pour la rubrique international
2)Chemin 2: script extracteur avec XML::RSS:
La méthode $rss->parsefile ($file) reconstitue toutes les structures des fils, notre programme stocke ces données sous un tableau avant de repérer les objets qui nous intéressent.
Cliquez sur ce lien si vous voulez visionnez notre script version XML::RSS.
Aperçu d'une sortie XML réalisée avec ce script(rubrique'SPORT'):

> script et sorties XML::RSS
Cliquez ici pour télécharger notre script XML::RSS ainsi que les sorties XML et TXT de la rubrique sport et 'de toutes les rubriques'. Pour avoir les autres sorties, il suffit de l'exécuter en respectant la syntaxe indiquée plus haut et évidemment avec votre choix de la rubrique.