Projet boite à outils
Arezki SADOUNE.Leidiana MARTINS. Latéfa FAïZ
BOITE A OUTILS 3 : Extraction de patrons
Après avoir étiqueté nos sorties, l'étape qui suit consiste dans le repérage et l'extraction de patrons syntaxiques bien définis. Pour ce faire, plusieurs méthodes vont être employées ; extraction de patrons sur la sortie XML par un script perl utilisant la bibliothèque XML::XPath. Dans un deuxième temps on
exploitera la sortie Cordial pour l'extraction de patrons en utilisant un deuxième script Perl. Enfin, on établira une requête Xpath dans une feuille de style (XSLT) pour construire une liste de patrons.
a) Extraction de patrons sur la sortie au format XML (Treetagger) via un script perl utilisant la bibliothèque XML::XPath:
Cette méthode d'extraction se base sur le script perl de M.Belmouhoub qui prend en premier argument la sortie XML (étiquetée par TreeTagger)
et en second le fichier en texte brut des patrons à extraire.
On va intégrer cette nouvelle requête via une commande system() à notre script de BAO2:
system("perl bao3_rb.pl $folder./treetagger_$rubrique.xml patterns.txt $folder")
}
}
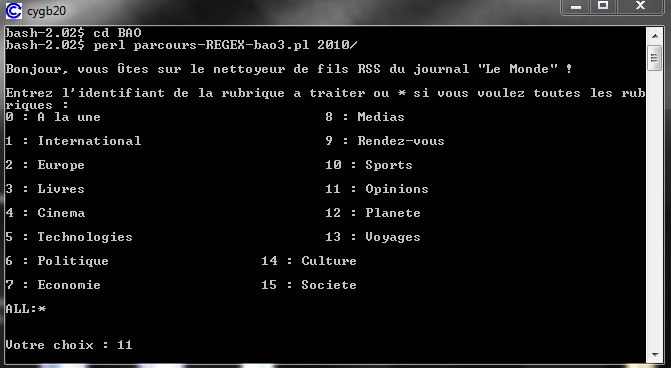
Testons notre nouveau script:parcours-REGEX-bao3.pl
Explorons à présent notre sortie_opinions:
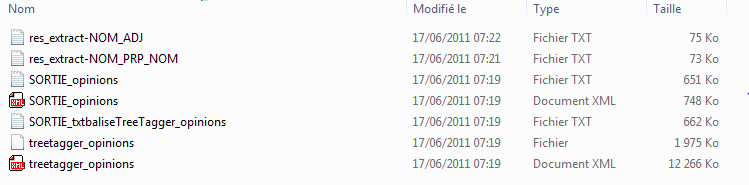
Voilà les fichiers de patrons extraits:res_extract-NOM_ADJ.txt et res_extract-NOM_PRP_NOM.txt. Notons finalement que le choix de la rubrique est ici fortuit. On dira que ceci était une illustration. Vous savez ce qui vous reste à faire pour arriver aux listes de patrons de vos choix pour les autres rubriques. Le nécessaire est sous cette archive
b)Extraction de patrons sur les sorties de l'étiquetage Cordial via un script perl:
Un autre script Perl pour cette deuxième méthode, extract-terminologie-cordial.pl, adapté aux sorties Cordial se charge d'opérer l'extraction. Ce dernier prend pour premier argument la sortie Cordial(.cnr), en second le fichier de patrons (lui aussi adapté) et enfin un fichier créé pour l'écriture de la liste de patrons extraits. Les motifs du fichier de patrons pour cette extraction sont sous la forme (ADJ[^ ]+#NC[^ ]+) ce qui permet d'inclure les sous-catégories indiquées par Cordial. Le motif #NC[^ ]+ par exemple comprend (NPMP, NPFP, NPMS...etc) Voici la syntaxe pour cette extraction:
perl extract-terminologie-cordial.pl SORTIE_international_cordial.cnr Pos_Adj_NC.txt > resultat_international_ADJ_NC.txtRésultat : resultat_international_ADJ_NC.txt
Puisque c'est si simple, un peu d'exercice ne peut faire que du bien...
perl extract-terminologie-cordial.pl SORTIE_international_cordial.cnr Pos_NC-Prep-NC.txt > resultat_international_NC-Prep-NC.txt
perl extract-terminologie-cordial.pl SORTIE_toutes_les_rubriques_cordial.cnr Pos_NC-Prep-NC.txt > resultat_toutesrubriques_NC-Prep-NC.txt
perl extract-terminologie-cordial.pl SORTIE_toutes_les_rubriques_cordial.cnr Pos_Adj_NC.txt > resultat_toutesrubriques_ADJ_NC.txt
perl extract-terminologie-cordial.pl SORTIE_toutes_les_rubriques_cordial.cnr Pos_Adj_Adj_NC_Adj_Adj.txt > resultat_toutesrubriques_Adj_Adj_NC_Adj_Adj.txt
perl extract-terminologie-cordial.pl SORTIE_europe_cordial.cnr Pos_Adj_NC.txt > resultat_europe_Adj_NC.txt
perl extract-terminologie-cordial.pl SORTIE_europe_cordial.cnr Pos_NC-Prep-NC.txt > resultat_europe_NC-Prep-NC.txt
c)Extraction de patrons par des feuilles de style (XSLT):
Pour cette méthode nous prenons comme fichier d'entrée le résultat du traitement sous TreeTagger issu de BAO2 et nous créons une feuille XSLT selon les patrons syntaxiques que l'on veut obtenir :
NOM ADJ
ADJ NOM
NOM PRP NOM
Nous souhaitons avoir un résultat en HTML et un autre en texte brut. Pour cela, il faut donc deux feuilles XSLT à l'en-tête desquelles nous ajoutons les lignes suivantes indiquant le format des sorties :
xsl:output method="text"
Il est important d'ajouter également dans le fichier XML la ligne :
Une fois toutes ces modifications opérées, nous créons en ligne de commande nos sorties(.html et .txt) via l'outil Bash xsltproc
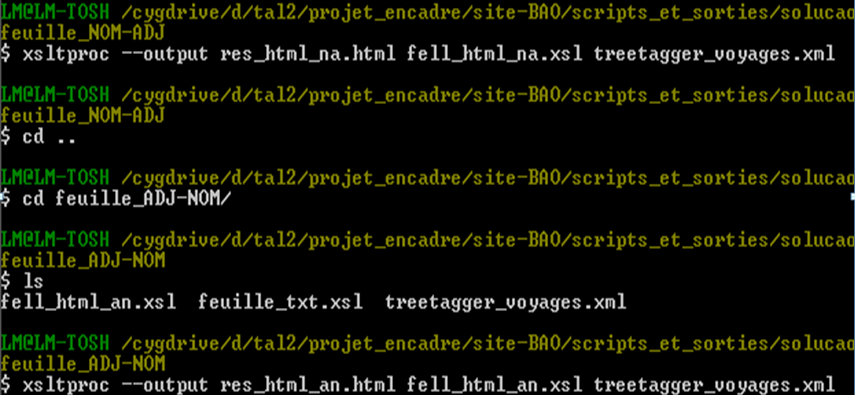
Voilà la commande pour avoir nos sorties :
Nous avons remarqués que dû à la grande taille de certains fichiers XML (nos sorties TreeTagger, notamment treetagger_toutes_les_rubriques.xml '94610 ko'), nous ne pouvons mettre en ouvre ce mode d'extraction à nos sorties volumineuses. Le programme plante et affiche systématiquement pour tous les documents dépassant environ 7000 ko :«excessive depth in document ».
Ceci dit nous allons procéder à l'extraction mode XSLT sur une sortie TreeTagger relativement légère treetagger_voyages.xml
feuilles ADJ-NOM :
Extraction et transformation XSL en texte brut:
la feuille de style: fell_txt_Adj-Nom.xsl
le résultat de l'extraction: res_txt_Adj-Nom.txt
Extraction et transformation XSL en HTML:
la feuille de style: fell_html_Adj-Nom.xsl
le résultat de l'extraction: res_html_Adj-Nom.html
feuilles NOM -ADJ:
la feuille de style: fell_txt_Nom-Adj.xsl
le résultat de l'extraction:res_txt_Nom-Adj-voyages.txt
Extraction et transformation XSL en HTML:
la feuille de style:fell_html_Nom-Adj.xsl
le résultat de l'extraction:res_html_Nom-Adj.html
feuilles NOM-PRP-NOM:
la feuille de style:fell_txt_NomPrpNom.xsl
le résultat de l'extraction:res_txt_NomPrpNom.txt
Extraction et transformation XSL en HTML:
la feuille de style: fell_html_NomPrpNom.xsl
le résultat de l'extraction: res_html_NomPrpNom.html