
Web Services
Méthodes de détection des entités nommées
En fin de projet, nous avions eu l'idée d'écrire un programme permettant d'identifier les entités nommées contenues dans les fils RSS. Nous avions intégré toute cette partie comme "bonus" de la BàO #3. Finalement, nous avons décidé d'axer la partie Web Services autour des entités nommées, afin de réutiliser les résultats obtenus grâce à ce module, et parce qu'il nous semblait intéressant de pouvoir faire ressortir les personnalités, lieux ou organisations qui ont marqué l'année 2009. Nous présentons donc dans cette partie deux méthodes d'identification des entités nommées : une qui fait appel à Wikipédia pour extraire et catégoriser les entités, et une qui utilise le Web Service AlchemyAPI.
Méthode "maison" avec consultation de Wikipédia
Constitution de la liste des entités nommées : "Entrainement-Entites.pl"
Dans le premier programme que nous avions écrit, nous avions décidé d'utiliser une méthode "maison", se basant sur l'étiquetage de Cordial (préalablement converti en UTF-8) et sur l'interrogation de l'encyclopédie en ligne Wikipédia pour extraire les entités nommées. En effet, nous voulions partir des données obtenues dans les BàO précédentes, et les fichiers taggés représentaient en cela une bonne base de départ : en théorie, la plupart des noms propres sont déjà censés avoir été identifiés. Nous avons donc restreint la détection aux tokens déjà catégorisés comme NPqqch. On limite ainsi la quantité de travail à abattre et sa complexité, même si le risque est de louper une partie des entités nommées, voire de récupérer du bruit. En l'occurrence, cela nous suffit amplement pour le moment !
Le but du jeu consiste donc à constituer les plus longues suites possibles de tokens étiquetés NP (au cas où un nom et prénom n'auraient pas été étiquetés ensemble, par exemple), chaque suite créée devenant ainsi un candidat au statut d'entité nommée. Comment confirmer ce statut ? Bonne question… Nous avons choisi de vérifier la présence de l'entité supposée dans Wikipédia : si une entrée existe bel et bien, et puisque la suite de mots a été taggée comme NP, on suppose alors qu'il y a des chances pour qu'il s'agisse d'une entité nommée. Il existe bien sûr des méthodes plus efficaces : la nôtre évite simplement d'avoir à déployer un outillage trop complexe (analyse syntaxique, par exemple).
Pour que le script se connecte à Wikipédia, nous avons utilisé le module WWW::Wikipedia, qui permet de rechercher n'importe quelle entrée dans l'encyclopédie (dans toutes les langues possibles). L'avantage est qu'il peut retourner le texte de l'article, qui est une mine d'informations permettant caractériser les entités. L'inconvénient, c'est qu'il faut tester chaque nouveau candidat au statut d'entité nommée : ils sont très (trèèès) nombreux, ce qui prend un temps considérable (il faut environ une heure pour parcourir l'ensemble du fichier étiqueté par Cordial). Nous avons donc divisé les opérations en deux scripts : un pour récupérer la liste des entités nommées et leurs informations, et l'autre pour traiter nos fils RSS en conséquence. Cette phase d'entrainement préalable permet d'éviter de ré-interroger l'encyclopédie à chaque fois. Malheureusement, les données que récupère le module manquent d'harmonie et ne sont parfois pas très propres, et il est difficile de trouver des règles générales permettant un affichage correct de tous les articles récupérés. Par manque de temps, nous avons donc concentré nos efforts sur les zones Infobox que contiennent la plupart des entrées : elles synthétisent les principales caractéristiques de l'entité, et ont une forme (en général !) régulière, sur le modèle attribut1 = valeur1 | attribut2 = valeur2 | etc.
 Informations récupérées sur des entités
Informations récupérées sur des entités
S'il n'y a pas d'Infobox, nous avons choisi de ne pas récupérer l'article. Au final, on récolte tout de même de très nombreuses informations sur beaucoup d'entités, que l'on structure dans une fichier texte sous la forme présentée ci-dessus. Entre crochets est stocké le type d'entité, comme ici par exemple [[Type=Premier Ministre]], et entre accolades les autres informations que le script a réussi à glaner : {{nom=Angela Merkel}} par exemple.
Pour visualiser le script, cliquez ici.
Pour visualiser les informations récupérées sur une partie des entités nommées, cliquez ici.
Pour télécharger le script + le résultat sur l'ensemble du corpus, cliquez ici.
Détection des entités nommée dans les fils RSS : "Detection-Entites.pl"
Une fois la liste des entités nommées constituée, un deuxième script permet d'annoter le corpus des flux RSS. Plus exactement, il produit quatre sorties (mais on pourrait en imaginer d'autres en fonction de ce que l'on souhaite faire) :
- une page HTML contenant l'ensemble du texte des fils. Chaque entité nommée identifiée est colorée en rouge, pointe vers la page Wikipédia correspondante, et un texte [ entre crochets ] indique de quel type d'entité il s'agit ([ NONE ] si inconnu). C'est un bon moyen de visualiser les entités du texte.
- une deuxième page HTML, qui synthétise les informations récupérées sur les entités, ainsi que les contextes dans lesquelles elles apparaissent, et qui présente le tout sous forme de tableaux.
- une sortie textuelle qui se contente de regrouper les contextes d'apparition des entités nommées, pour chacune d'elles ;
- enfin, une sortie au format XML, structurée comme celle produite par AlchemyAPI, qui se compose de l'ensemble des entités reconnues, avec leur type et leur nombre d'occurrences ;
La détection des entités se fait à partir du fichier étiqueté par Cordial (encore lui !), et le script prend comme deuxième argument le fichier entites.txt obtenu grâce au programme précédent. Une première procédure se charge de lire le fichier des entités, et de stocker les informations dans différentes tables de hachage : nom de l'entité, type, attributs, etc. Le fichier Cordial est ensuite lu, et le premier fichier HTML créé : tous les tokens non-taggés comme NPqqch sont copiés normalement ; en revanche, si un NP est rencontré, on cherche à trouver la plus grande suite de NP possible, et on confronte l'entité obtenue à la liste des entités connues ; s'il y a matching, on récupère les informations et on applique la mise en forme. Pour le deuxième fichier HTML, nous avons réutilisé la méthode "n-grammes" mise en place dans la BàO #3. Le script va donc générer tous les n-grammes de mots (correspondant au nombre d'unités dans les entités identifiées), et vérifier pour chacun d'eux s'ils correspondent à des entités connues. Dans le cas d'une reconnaissance, on récupère le contexte gauche (les trois mots précédent l'entité) et le contexte droit (les trois mots suivants). L'avantage de cette méthode est qu'elle permet d'utiliser un simple fichier texte plutôt que le résultat d'étiquetage de Cordial : à aucun moment on ne fait appel aux catégories syntaxiques, et on pourrait donc repérer les entités nommées de n'importe quel autre texte. L'inconvénient, c'est que si un nom commun a été taggé ne serait-ce qu'une fois comme NP, et que la recherche dans Wikipédia a abouti, il sera quand même systématiquement détecté…
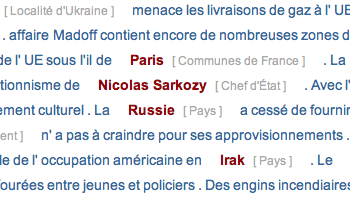 Exemple de page HTML repérant les entités nommées
Exemple de page HTML repérant les entités nommées[ cliquez pour ouvrir (extrait) ]
 Exemple de résultat de la détection des EN
Exemple de résultat de la détection des EN[ cliquez pour ouvrir (extrait) ]
Ce méthode "maison" illustre qu'il est relativement facile de réutiliser les informations tirées de l'étiquetage des fils RSS pour ajouter du sens au texte et étendre le champ des possibilités d'analyse. Tout en étant très simple, elle reste plutôt efficace "à notre petit niveau", et permet d'obtenir un début de filtrage et de classification des données. Le système pourrait cependant être amélioré en empêchant par exemple que la suite "Nicolas Sarkozy" soit matchée à la fois par "Sarkozy" et par "Nicolas Sarkozy", et en améliorant l'extraction des informations tirées de Wikipédia (aussi bien du côté de la récupération du texte des articles par le module WWW::Wikipedia que du côté de leur tri dans notre script). Bref, il y aurait fort à faire !
A partir du fichier textuel résultant de l'extraction des contextes autour des entités nommées, nous avons pu obtenir des nuages de mots intéressants, plus "fins" que ceux qu'on aurait pu générer à partir du texte brut puisque centrés autour de ces entités.
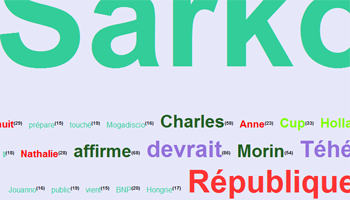

Pour visualiser le script, cliquez ici.
Exemples de sorties (extraits) : Texte + entités | Entités et contextes (HTML) | Entités et contextes (TXT) | Entités et type (XML).
Pour télécharger le script + le résultat sur l'ensemble du corpus, cliquez ici.
Méthode "Web Service" : utilisation de l'API Alchemy
Dans le but d'intégrer un Web Service à notre projet, nous avons cherché des ressources permettant de tagger automatiquement des entités nommées. AlchemyAPI est un ensemble d'outils en ligne permettant d'effectuer différents types d'anotations sur un texte, et notamment d'en extraire les entités nommées. Le service est utilisable de différentes manières : via un logiciel avec interface utilisateur, des SDK (Software Development Kit) dans différents langages de programmation ou via une plateforme REST. Comme nous n'avons pas vu d'exemples de modules Perl permettant de construire une architecture REST, et que la documentation du site d'AlchemyAPI est plus que sommaire, nous avons décidé de nous servir des SDK mis si gentiment à notre disposition ! Pour Perl, cela se traduit par l'installation d'un module, téléchargeable sur le site après enregistrement d'une clé API.
Concrètement, le module fait pour nous tout ce qui aurait été pénible à mettre en place via une véritable architecture Web Services avec l'utilisation de REST : il se connecte aux bons serveurs sans qu'on ait à les lui préciser, paramètre lui-même les accès, et récupère le résultat du traitement une fois celui-ci effectué ! Pour autant, le principe de ce type de services reste inchangé : on envoie des données par Internet à un serveur distant, où un programme auquel nous n'avons pas accès effectue sa petite cuisine et nous retourne un résultat sous forme structurée en XML.
Du coup, le script appelant l'API est très simple à écrire : il suffit de lire le fichier textuel généré dans la BàO #1 (SORTIE_3208.txt, également converti en UTF-8 pour l'occasion), d'envoyer le texte en paramètre d'un objet AlchemyApi, et d'imprimer le résultat dans un fichier XML. L'accès aux serveurs étant restreint aux seuls possesseurs d'une clé API, il faut également que le script lise cette clé dans un fichier fourni avec.
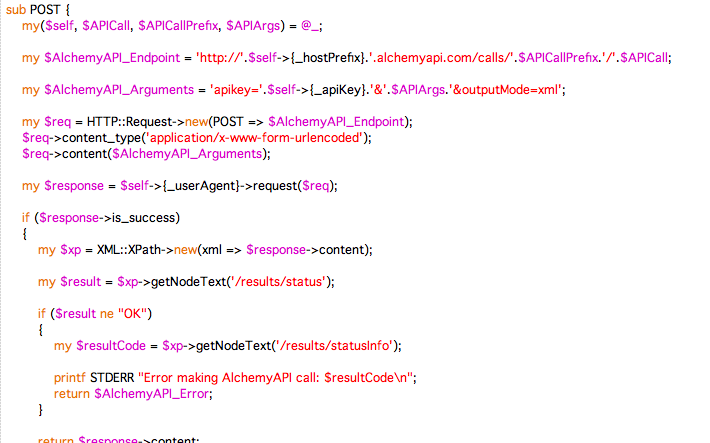
Des paramétrages serveur complexes : merci petit module Perl de nous épargner ça !
Bref, tout ça est quand même plus simple que d'écrire soi-même sa méthode de résolution des entités nommées ! L'utilisation de l'API se réduit à ces quelques lignes de code :
| 1 | # Création d'un objet AlchemyAPI |
|---|---|
| 2 | my $alchemyObj = new AlchemyAPI(); |
| 3 | # Chargement de la clé API (via un fichier txt api_key.txt) |
| 4 | $alchemyObj->LoadKey("api_key.txt"); |
| 5 | # Décodage des entités nommées |
| 6 | $result = $alchemyObj->TextGetRankedNamedEntities($texte); |
Au final, la sortie obtenue respecte l'architecture suivante (que nous avons réutilisée en sortie du script detection-entites.pl), pour chacune des entités nommées :
| 1 | <entity> |
|---|---|
| 2 | <type> Type d'entité </type> |
| 3 | <relevance> Certitude du système </relevance> |
| 4 | <count> Nombre d'occurrences </count> |
| 5 | <text> Token </text> |
| 6 | <\entity> |
Le seul problème ? Il faut envoyer le texte à l'API petits bouts par petits bouts, pour éviter la surcharge ! La détection des entités se fait donc par tranches de 250 lignes (elle est relancée 28 fois pour le fichier SORTIE_3208.txt, mais le temps d'exécution reste tout de même plutôt rapide). Pour que le nombre d'occurrences soit correct et afin d'empêcher la répétition des mêmes tokens (puisque le "compteur d'entités" se réinitialise toutes les 250 lignes), il a fallu stocker les données dans des tables de hachage et recréer une sortie XML globale une fois les 28 traitements effectués...
Pour visualiser le script, cliquez ici.
Exemple de sortie (extrait) : cliquez ici.
Pour télécharger le script + le résultat sur l'ensemble du corpus, cliquez ici.
Comparaison des résultats
Afin de comparer les résultats, nous avons écrit un petit script (téléchargeable ici) qui permet de fusionner les deux sorties XML en une seule. Une feuille de style XSLT (accessible ici) permet d'afficher les résultats des deux méthodes en parallèle et ainsi d'observer les différences.
La première chose qui saute aux yeux est le grand nombre d'entités que la méthode Wikipédia ne parvient pas à catégoriser. En revanche, les entités caractérisées le sont beaucoup plus précisément que dans la version AlchemyAPI : là où l'API se contente de 26 catégories, il n'y a en théorie pas de limite aux types définis par l'encyclopédie. De plus, ces catégories sont (nomalement) exactes. Un gros travail serait donc à faire sur la normalisation du texte récupéré dans les articles de Wikipédia pour améliorer le rappel et profiter de cette précision intéressante.
De son côté, AlchemyAPI a une gestion bien plus efficace des mots composés (même si perfectible), et détecte des entités qui ne sont pas des noms propres (ce que ne permet pas l'algorithme du script entrainement-entites.pl). Les différences de fréquences semblent dues à la segmentation des éléments, qui est généralement meilleure du côté de l'API. Il reste des erreurs de catégorisation, mais globalement, nous avons été convaincu par la facilité d'implémentation du Web Service dans notre chaîne de traitement. Une technologie bien prometteuse !
Pour visualiser le résultat (complet), cliquez ici.
Pour le télécharger, cliquez ici.
Télécharger les fichiers
Retrouvez ici l'intégralité des fichiers de la partie Web Service
Script "Entrainement-Entites.pl"
Cliquez ici pour le visualiserCliquez ici pour télécharger script + résultat
Script "Detection-Entites.pl"
Cliquez ici pour le visualiserCliquez ici pour télécharger script + résultats
Web Service "AlchemyAPI"
Cliquez ici pour télécharger le SDK PerlCliquez ici pour visualiser le script
Cliquez ici pour télécharger script + résultats
Comparaison des deux méthodes
Cliquez ici télécharger "2XMLto1XML.pl" Cliquez ici pour visualiser le fichier XMLCliquez ici pour le télécharger
