
BàO #3 [ Extraction de patrons ]
Objectif
Le but de cette troisème étape est d'extraire des suites de mots, correspondant à des patrons syntaxiques prédéfinis. Les résultats de ces extractions seront ensuite transmis à la BàO #4 pour générer des graphes. Cette partie du projet a été l'occasion de tester de (très) nombreuses façons de faire :
- quatre scripts Perl, récupérant "manuellement" les suites de catégories morpho-syntaxiques voulues à partir des étiquetages textuels de TreeTagger et Cordial ;
- un script Perl utilisant une bibliothèque, XML::XPath, qui a permis de récupérer les patrons à partir des étiquetages formatés en XML ;
- et des feuilles de style XSLT permettant de restreindre l'affichage des étiquetages XML aux patrons voulus.
Nous sommes partis à la base sur l'extraction de patrons NOM ADJ, ADJ NOM et NOM PREP NOM, mais le choix de nous focaliser sur le motif "Nicolas Sarkozy" dans la BàO #4 nous a amené à élargir cette liste (NOM VER VER, par exemple). Les exemples proposés sur cette page ne traitent cependant que des trois premiers patrons. Il serait impossible de détailler ici le fonctionnement précis de tous les scripts : nous vous invitons donc à vous reporter aux nombreux commentaires dont ils sont garnis ! Vous retrouverez l'intégralité des scripts dans le deuxième onglet de cette page.
Et une tripotée de scripts Perl !
Les quatre premiers scripts Perl que nous avons écrit fonctionnent sur le même principe : ils prennent en entrée un fichier étiqueté par l'un ou l'autre des étiqueteurs, ainsi qu'une liste de patrons. Le fichier est lu ligne à ligne, et les scripts récupèrent les suites de mots dont les catégories correspondent à celles demandées. En sortie, un gros fichier textuel est généré, contenant l'ensemble des suites reconnues pour chacun des patrons.
Ils n'utilisent aucun module spécial, et analysent les fichiers grâce à leur structuration : un grand soin a donc été apporté à la normalisation de l'écriture des patrons ainsi que des fichiers étiquetés, pour éviter tout problème lors du parsage. Nous voulions également qu'ils puissent tourner aussi bien sur les étiquetages de Cordial que de TreeTagger. Du coup, nous avons introduit des tests pour reconnaître de quel type de fichier il s'agit (qui se basent sur l'extension du fichier... oui, c'est très basique, mais amplement suffisant dans le cas présent !), et des traitements différents en fonction du programme, puisque TreeTagger suit un modèle token [tabulation] catégorie [tabulation] lemme et Cordial token [tabulation] lemme [tabulation] catégorie.
 La tripotée de scripts
La tripotée de scriptsPourquoi tant de scripts ? C'était pour nous l'occasion de nous entraîner à la programmation, sur un exercice relativement simple, mais pouvant être résolu de plein de façon différentes ! Aussi, chaque programme a ses spécificités, même si son fonctionnement global est similaire aux autres (lecture des fichiers, comparaison entre les patrons et l'étiquetage, et extraction des suites de POS).
Script "Extraction-Basique.pl"
"Basique", parce qu'il s'agit du premier qui a été proposé et sur lequel nous avons travaillé. Il stocke les parties du discours comme une suite d'éléments séparés par des espaces, et fait de même pour les tokens : de cette façon, on peut utiliser les espaces comme repères pour associer une position dans la suite de POS à une position dans la suite de mots. Lorsqu'un patron est reconnu, il s'agit donc de "compter les blancs" dans le contexte gauche pour savoir exactement à quel endroit on se situe. La méthode est simple et idéale pour "se mettre dans le bain", mais peu efficace : elle oblige à une succession de comparaisons de chaînes de caractères, qui sont des opérations relativement lentes (surtout quand la masse de données est grande). De plus, le script d'origine obligeait à ouvrir et fermer le fichier de patrons à chaque fois qu'un signe de ponctuation était rencontré, ce qui ralentissait également son exécution. Nous avons donc très vite préféré les autres méthodes détaillées ci-dessous. A noter que le script est aussi victime d'un B. I. N. I. (Bug Informatique Non-Identifié) : certaines suites de POS sont reconnues alors qu'elles ne devraient pas l'être... Mystère non-élucidé à ce jour...
Cliquez ici pour télécharger le script et les résultats.
 Un B. I. N. I.
Un B. I. N. I.Scripts "Extraction-Listes.pl" et "Extraction-Intuitive.pl"
Ces deux programmes utilisent des @listes pour se repérer, à la place des espaces laissés dans les chaînes de caractères du script précédent. L'idée est de toujours garder une trace de "l'endroit" où l'analyseur se situe : cette position est matérialisée par l'indice dans la liste. Le premier script a été écrit par Serge Fleury, et nous l'avons souvent utilisé parce qu'il est assez efficace. Mais nous voulions mettre au point notre propre variante qui utiliserait des listes : d'où l'idée de la version extraction-intuitive. C'était également le premier programme qui identifiait l'étiqueteur et proposait un traitement différent en fonction de cela : même si nous avons finalement intégré cette fonctionnalité à tous les autres scripts, le nom d'extraction "intuitive" est resté. Là où extraction-listes construit deux listes (@listedetokens et @listedepos) contenant l'intégralité des POS et des mots du fichier étiqueté (et les parcourt en parallèle), extraction-intuitive stocke chaque ligne du fichier dans une seule liste, sans découpage préalable. Dans tous les cas, le principe est de regarder si un POS correspond au début d'un patron : si oui, on regarde si le POS suivant correspond au deuxième POS du patron, et ainsi de suite jusqu'à identifier une liste acceptable.
Cliquez ici pour télécharger le script "extraction-listes.pl" et ici pour "extraction-intuitive.pl".
Scripts "Extraction-Ngram.pl" (et "posCordial.pl")
Pour cette dernière variante, nous avons utilisé des tables de hachage : chaque patron à chercher devient en effet la clé d'un %hash, et chaque fois qu'une suite est reconnue, elle est ajoutée à la liste des valeurs de cette clé (on a donc au final des @tableaux stockés dans une %hash). L'avantage de cette technique est qu'on cherche si une chaîne de caractères (une suite de POS du "suspectés" du fichier étiqueté) est une clé dans le tableau associatif, ce qui est bien plus rapide que de passer par une comparaison de deux chaînes de caractères. L'inconvénient, c'est qu'il faut être très précis : il n'y a plus la possibilité d'utiliser des expressions régulières d'un côté ou de l'autre. Cordial étant très précis dans son annotation (il précise par exemple le genre et le nombre des noms et des adjectifs, mais pas seulement (!)), il faut donc pour un patron comme ADJ NOM envisager l'intégralité des possibilités de combinaison (le problème ne se pose pas avec TreeTagger, qui n'annote que la catégorie). Paresse aidant, nous avons écrit le script posCordial.pl, qui prend en entrée un fichier taggé par Cordial et restitue toutes les combinaisons possibles de nos trois patrons d'étude, en fonction des abréviations utilisées dans le fichier. A partir de là, extraction-ngram.pl va :
- créer autant de clés dans le tableau associatif qu'il y a de patrons (480 pour Cordial !) ;
- calculer la taille de chacun de ces patrons (selon leur nombre de POS), soit 2 ou 3 éléments dans notre cas ;
- générer tous les n-grammes de POS possibles à partir de la liste des POS du fichier étiqueté, selon la taille des patrons (bigrammes et trigrammes ici) ...
- ... en vérifiant si chaque n-gramme est une clé du tableau associatif : si oui, un système d'indices permet de remonter aux mots correspondants (stockés dans une liste à part).
Au final, la méthode vaut sans doute le coup que l'on s'embête à générer toutes les combinaisons de patrons possibles : c'est la plus rapide. La liste des POS du fichier taggé n'est finalement interrogée que deux fois, et ce même s'il y a 480 patrons à vérifier !
Cliquez ici pour télécharger le script "extraction-ngram.pl" et ici pour le générateur de patrons pour Cordial.
Autres solutions
Utilisation de la bibliothèque XML::XPath : "Extraction-XML.pl"
Une autre possibilité d'extraction des patrons est d'utiliser la bibliothèque Perl XML::XPath. Comme indiqué dans la section FAQ du site, ce module permet d'évaluer des expressions XPath, et de récupérer la valeurs des noeuds identifiés. Au lieu de lire un document XML de façon "plate" comme un vulgaire fichier texte, cette méthode permet de construire des objets XML::XPath et de prendre en compte l'arborescence du document. Le script prend donc en entrée les fichiers XML générés en BàO #2 à partir des fichiers textuels étiquetés, ainsi que des fichiers de patrons "traditionnels", comme le faisaient les autres scripts. Nous n'avons pas implémenté de solution permettant au programme de tourner sur le fichier General.xml et de récupérer à la fois des suites de tokens étiquetés par Cordial et par TreeTagger : le fichier est en effet trop lourd (plus de 60 Mo), ce qui n'aurait pas permis de le traiter. En effet, le module a déjà beaucoup de mal à tourner sur les fichiers Cordial.xml et TreeTagger.xml, qui pèsent 30 Mo chacun... Au final, c'est une solution tout de même intéressante pour parser des documents XML : elle évite d'avoir à décrire toute la structuration des documents via des expressions régulières.
Cliquez ici pour télécharger le script et les résultats.
Utilisation de feuilles de style XSLT
Enfin, il est possible d'utiliser des feuilles de style pour extraire les patrons syntaxiques qui nous intéressent. Le principe est d'utiliser des templates qui n'affichent que les noeuds répondant à certains critères, c'est-à-dire ici par exemple les noeuds <element> catégorisés comme NOM et dont les noeuds suivants sont catégorisés comme ADJ :
| 1 | <xsl:choose> |
|---|---|
| 2 | <xsl:when test="(./data[contains(text(),'NC')]) and (following-sibling::element[1][./data[contains(text(),'ADJ')]])"> |
| 3 | <span class="nom"><xsl:value-of select="./data[3]"/></span><xsl:text> </xsl:text> |
| 4 | </xsl:when> |
| 5 | <xsl:when test="(./data[contains(text(),'ADJ')]) and (preceding-sibling::element[1][./data[contains(text(),'NC')]])"> |
| 6 | <span class="adj"><xsl:value-of select="./data[3]"/></span><br/> |
| 7 | </xsl:when> |
| 8 | </xsl:choose> |
Nous avons donc défini trois feuilles de style, une pour chaque fichier XML produit en BàO #2, qui n'affichent pour chaque fil RSS que les suites identifiées comme matchant un patron. L'intérêt de cette méthode est double : des éléments de style permettent de structurer les résultats et d'obtenir un affichage clair et agréable, et le fichier General.xml permet d'avoir un alignement des extractions, pour comparer l'étiquetage entre Cordial et TreeTagger.
Comparaison des patrons extraits
Dans une dernière étape de la boîte à outils, nous avons écrit un programme permettant d'identifier les différences d'étiquetage (et donc d'extraction des patrons) entre les versions TreeTagger et Cordial : "Comparaison.pl". Puisque nos cinq programmes d'extraction de patrons produisant des sorties textuelles formatent ces sorties de la même façon, le script s'est révélé relativement simple à écrire.
Il fonctionne par étapes :
- il lit chaque fichier séparément ;
- pour chaque fichier, dès qu'il tombe sur les trois lignes introduisant un type de patron (voir l'image ci-contre : une ligne de tirets "-----", les POS, une ligne de tirets), il récupère le patron et le stocke comme clé d'un tableau associatif (un %hash pour Cordial, et un pour TreeTagger) ;
- il harmonise également les patrons : Cordial et TreeTagger n'utilisant pas les mêmes abréviations, une procédure se charge de leur faire parler le même langage ;
- toutes les autres lignes sont alors des mots qui correspondent au patron courant, et le script remplit donc les valeurs des clés avec ;
- l'ultime étape est de comparer les valeurs de chaque "clé-patron" de chaque programme : on détermine ainsi les patterns communs, et les suites de mots récupérés d'un côté mais pas de l'autre.
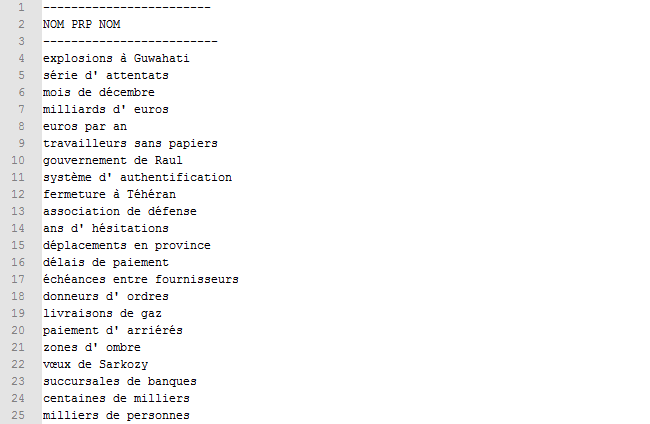 Résultat d'extraction type
Résultat d'extraction type
En sortie, le script produit un fichier regroupant toutes les extractions communes, mais également un fichier par type de patron, synthétisant les extractions communes, les extractions propres à TreeTagger et celles propres à Cordial. Nous n'avons pas eu le temps de créer des sorties XML, qui auraient pu permettre une meilleure visualisation des différences. Cependant, les résultats sont tout de même intéressants, et permettent de se rendre compte de certains phénomènes récurrents : par exemple, Cordial considère les nombres comme des adjectifs numéraux, là où TreeTagger les classe simplement comme NUM (ce qui fait qu'ils ne sont pas prélevés par nos patrons). Cordial connaît aussi plus d'expressions composées que TreeTagger, et analysera plutôt "cotisations sociales" comme un seul et même NOM plutôt que comme un NOM et ADJ (ce que fera TreeTagger). Les graphes de la BàO #4 nous font d'ailleurs voir nettement les effets de ces différences d'étiquetage.
Cliquez ici pour télécharger le script et les résultats.
Télécharger les fichiers
Retrouvez ici l'intégralité des fichiers de la BàO #3
Chaque zip contient le script à exécuter, les fichiers étiquetés d'entrée, les listes de patrons et des exemples de sorties.
Script "extraction-basique.pl"
Cliquez ici pour le visualiserCliquez ici pour le télécharger
Exemples de sortie : TreeTagger | Cordial
Script "extraction-listes.pl"
Cliquez ici pour le visualiserCliquez ici pour le télécharger
Exemples de sortie : TreeTagger | Cordial
Script "extraction-intuitive.pl"
Cliquez ici pour le visualiserCliquez ici pour le télécharger
Exemples de sortie : TreeTagger | Cordial
Script "posCordial.pl"
Cliquez ici pour le visualiserCliquez ici pour le télécharger
Liste de tous les patrons possibles (Cordial)
Script "extraction-ngram.pl"
Cliquez ici pour le visualiserCliquez ici pour le télécharger
Exemples de sortie : TreeTagger | Cordial
Script "extraction-xml.pl"
Cliquez ici pour le visualiserCliquez ici pour le télécharger
Exemples de sortie : TreeTagger | Cordial
Méthode via feuilles de styles XSLT
TreeTagger : extrait | completCordial : extrait | complet
Général : extrait | complet
Script "comparaison.pl"
Cliquez ici pour le visualiserCliquez ici pour le télécharger
Exemples : NOM ADJ | NOM PRP NOM
