
Accueil
Bienvenue !
Ce site, réalisé dans le cadre du cours de "Projet encadré et programmation 2" du M1 "PluriTAL" (Paris III, INALCO, Paris X), présente le traitement effectué sur le corpus de fils RSS du journal Le Monde 2009. Le but du projet est d'extraire des informations, correspondant à des patrons syntaxiques particuliers. Les résultats seront présentés en fin de traitement sous forme de graphes de mots.
Ce genre de traitement peut s'avérer fort utile pour l'extraction terminologique ou encore la fouille de textes et l'extraction de connaissances.
Le traitement réalisé peut être découpé en quatre boîtes à outils (+ une partie dite "Web Services"), dans lesquelles sont résumés notre démarche de travail ainsi que nos résultats :
Ce site Internet nécessite l'activation de Javascript. Il est optimisé pour tous les navigateurs, sauf cette saleté d' Internet Explorer. Template créée par nos soins [ Pictogrammes par pictoico | Javascript adapté du menu de Dezinerfolio | versions HTML des scripts générées grâce à notre programme pltohtml.pl ]. Un grand merci à nos professeurs pour leur soutien et leur patience, et aux étudiants des promotions précédentes pour leur aide indirecte !
FAQ
C'est ici que l'on apprend plein de choses !
Perl : variables et fonctions
Nous avions déjà détaillé beaucoup de variables et de fonctions utilisées en Perl lors de notre précédent projet. Cette partie prend donc la suite de la liste précédente, consultable à cette adresse.
- Les tables de hachage : c'est un type de variable qui permet d'associer une valeur à une clé. Chaque clé stockée dans une table de hachage est un item unique, et sa valeur peut être une chaîne de caractères ($quelquechose) ou une liste (@autrechose).
Exemple : déclaration et remplissage d'une table de hachage.
| 1 | my %hash; |
|---|---|
| 2 | $hash { "clé" } = "chaîne de caractères"; |
- shift et unshift : fonctions pour respectivement enlever le premier élément d'un tableau, et au contraire mettre un élément en première position dans un tableau.
| 1 | shift ( @liste ); |
|---|---|
| 2 | unshift ( @liste , "élément_à_ajouter" ); |
- pop et push : à l'inverse des fonctions précédentes, ceux deux-là permettent de supprimer le dernier élément d'une liste ou d'ajouter un élément en dernière position dans une liste (leur syntaxe est la même que les deux autres).
- chomp ( "cdc" ) : permet de supprimer le caractère de retour à la ligne (\n) d'une chaîne de caractères.
- opendir | readdir | closedir ( dossier ) : respectivement, ouvrir, lire et fermer un dossier.
- sort : opérateur permettant d'effectuer des tris (par défaut, tri lexical croissant).
Exemple : tri lexical croissant d'une liste, et tri numérique décroissant des clés d'une table de hachage.
| 1 | @liste_triee = sort { $a cmp $b } @liste_en_vrac; # "{$a cmp $b}" est ici facultatif |
|---|---|
| 2 | @liste_triee = sort { $b <=> $a } keys %hash; |
- split et join : fonctions pour éclater une chaîne de caractères en une liste, et réunir les éléments d'une liste en une seule chaîne de caractères, sur la base d'un patron (le caractère d'espace par exemple).
| 1 | @liste = split ( /patron/ , $string ); |
|---|---|
| 2 | $string = join ( /\s/ , @liste ); |
- system ( instruction ) : permet d'exécuter un programme externe au script.
- until ( condition à atteindre ) et unless ( condition à satisfaire ) : deux boucles fort utiles, permettant d'exécuter une action jusqu'à atteindre une certaine condition, et de ne pas exécuter d'action à moins qu'une condition spécifique soit satisfaite (la syntaxe est la même que pour n'importe quelle boucle).
Perl : modules spéciaux utilisés
- XML::RSS : créer et mettre à jour des flux RSS
Lien vers la fiche CPAN : ici
Si le module propose à la base des fonctionnalités utiles à qui veut créer et mettre à jour des flux RSS, c'est également un outil très pratique pour lire ce genre de fichiers et naviguer aisément à l'intérieur. Il nous a ainsi permis de parser les fils RSS du Monde pour récupérer les informations textuelles, sans avoir à décrire précisément à l'aide d'expressions régulières alambiquées la structure des documents.
Méthodes utilisées : new XML::RSS, pour construire un objet RSS, et parsefile() pour parser l'objet et reconstruire l'arborescence XML du fichier.
| 1 | my $rss = new XML::RSS; |
|---|---|
| 2 | $rss -> parsefile ( $file ); |
- HTML::Entities : pour encoder ou décoder des chaînes de caractères contenant des entités HTML
Lien vers la fiche CPAN : ici
Ce module nous a permis de rétablir automatiquement les caractères correspondant aux entités HTML présentes dans les flux RSS : on économise ainsi du temps en ne dressant pas fastidieusement la liste de toutes les entités HTML possibles et imaginables. Cependant, il ne les reconnaît pas forcément toutes : nous avons donc dû écrire des règles de réécritures pour certaines d'entre-elles.
Méthode utilisée : decode_entities( $texte ), pour transformer les entités d'un texte en leur caractère correspondant.
- XML::XPath : évaluation d'expressions XPath
Lien vers la fiche CPAN : ici
Avec ce module, il est possible de parcourir un document XML à l'aide de requêtes XPath, et de récupérer les valeurs des noeuds sélectionnés. Il a cependant été nécessaire de faire en sorte que le contenu de chaque balise <element> soit sur une seule ligne : le module plante sinon !
Méthodes utilisées : le constructeur, XML::XPath->new( filename => fichier.XML ), pour construire un objet XML::XPath à partir d'un fichier XML ; findnodes( expression XPath )->get_nodelist(), pour trouver une liste de noeuds ; getChildNode et getParentNode, pour aller au noeud fils et remonter au noeud parent ; string_value pour récupérer les valeurs des noeuds.
| 1 | my $xp = XML::XPath->new( filename => $tag_file ) |
|---|---|
| 2 | my @noeuds = $xp->findnodes($search_path)->get_nodelist() |
| 3 | $noeud_tmp = $noeud -> getParentNode; |
| 4 | $motif = $noeud_tmp->getChildNode(3)->string_value; |
- WWW::Wikipedia : interface automatisée pour Wikipédia
Lien vers la fiche CPAN : ici
Grâce à ce module, il est possible de chercher une entrée dans Wikipédia, et de récupérer l'intégralité de l'article s'il y en a un. Nous l'avons utilisé dans notre premier script de la partie Web Services, afin de vérifier l'existence d'une supposée entité nommée dans l'encyclopédie en ligne, et d'en extraire des informations le cas échéant.
Méthodes utilisées : le constructeur, WWW::Wikipedia->new(), pour construire un objet WWW::Wikipedia ; language(), pour changer la langue par défaut (anglais) ; search(), pour interroger l'encyclopédie ; et text_basic(), pour récupérer le texte d'introduction d'un article.
| 1 | my $wiki = WWW::Wikipedia->new( language => 'fr' ); |
|---|---|
| 2 | my $entry = $wiki->search( 'Perl' ); |
| 3 | print $entry->text(); |
RSS : gniiih ?!
Un fil RSS (flux RSS ou encore canal RSS), que l'on peut traduire par "fil de syndication", est un document texte au format XML donnant à voir un condensé des dernières informations mises à jour d'un site et mis à disposition de tout utilisateur. Ces informations peuvent être textuelles, audio ou video ("podcasting").
L'utilisateur choisit et s'abonne au(x) fil(s) dédié/associé(s) à(aux) l'information(s) qui l'intéresse, et peut ensuite consulter leur contenu à l'aide d'un logiciel de lecture de flux (qui peut être intégré au navigateur Web), que l'on appelle agrégateur puisqu'il permet d'agréger le contenu des différents fils sur une même page.
Il existe différents formats RSS, d'où la variation de signification du sigle :
- Rich Site Summary (RSS 0.91) ;
- RDF Site Summary (basé sur la norme RDF) (RSS 0.9, 1.0 et 1.1) ;
- Really Simple Syndication (RSS 2.0), qui est le plus répandu.
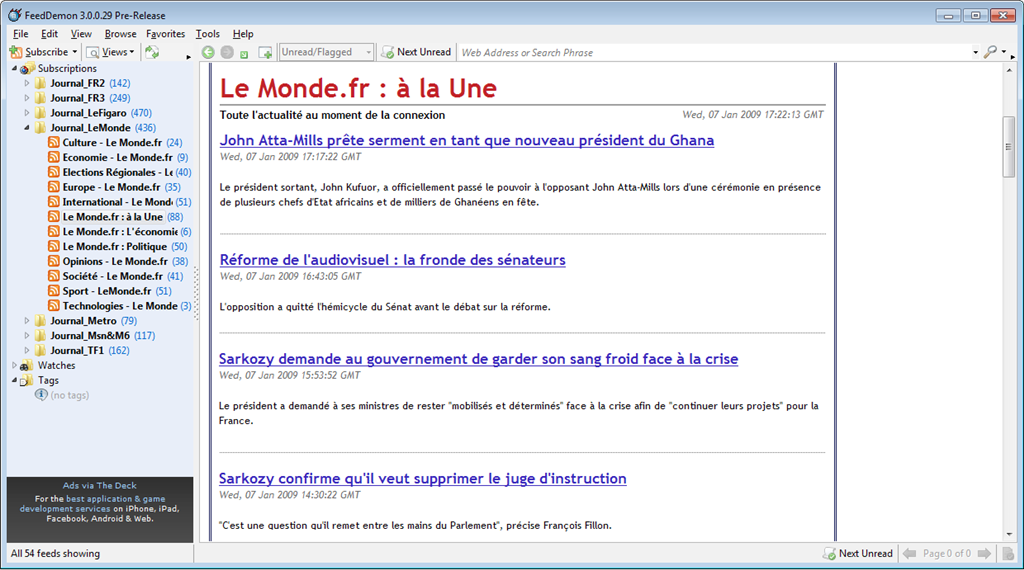 Fil RSS du Monde vu dans le logiciel FeedDemon
Fil RSS du Monde vu dans le logiciel FeedDemonRemarque : il existe également un format Atom, qui est aussi une application XML créée afin de pallier aux manques de flexibilité et d'interoperabilité des formats RSS.
Utilité :
- Pour tout internaute, c’est une façon simple d'être informé automatiquement des dernières nouveautés ;
- Pour les entreprises, c'est un outil de veille efficace par un accès rapide et facilité à l'information ;
- Pour les blogueurs ou les éditeurs de sites, c'est le moyen adéquat pour réutiliser le contenu d'un site Web dans sa propre page.
Pour en savoir plus, Wikipédia est là.
Utiliser TreeTagger : un pur moment de bonheur
A priori, l'exécution du logiciel n'a rien d'un casse-tête et l'exécutable Windows fourni au début du cours permet de le lancer sans avoir à s'embêter à l'installer. Nous avons cependant rencontré des problèmes, notamment parce qu'il refuse de tourner sur des versions 64 Bits de Windows (installées, bien entendu, sur nos deux machines personnelles). De ce fait, nous l'avons fait tourner sous environnement Unix, et donc installé via la méthode décrite sur le site de TreeTagger. Aussi, les scripts "Parcours-fils" ont été écrits en conséquence, et permettent de lancer le programme comme s'il était installé sur l'ordinateur de l'utilisateur. Pour lancer l'exécutable fourni avec le script, merci donc de modifier la ligne qui appelle TreeTagger en conséquence :
| 1 | # Procédure d'étiquetage Treetagger |
|---|---|
| 2 | sub lancetreetagger { |
| 3 | system("perl TreeTagger/tokenise-fr.pl $outputtmp | TreeTagger/tree-tagger.exe TreeTagger/french.par -lemma -token -no-unknown -sgml > treetagger.txt"); |
| 4 | } |
Liens utiles
Vous trouverez dans cette section une sélection de liens nous ayant servi tout au long du projet.
Perl
- Site du CPAN
- Documentation en ligne (à consulter à outrance) du site perldoc
- Les articles des Mongueurs de Perl
XML
- Leçons (très informatives) du site W3School
- Les slides du cours "Documents structurés" : également très utiles pour ce projet !
RSS
- Page des fils RSS du site LeMonde.fr
- Wikipédia : article sur les fils RSS
- Article sur le site Comment ça marche.net
Liens universitaires
- Site de la formation pluriTAL
- Sites des Universités auxquelles la formation est rattachée : Paris III Sorbonne Nouvelle | Paris X Nanterre | INALCO
- Site du cours "Programmation et projet encadré 2"
- Les productions des étudiants des promos précédentes : 2008/2009 | 2007/2008 | 2006/2007 | 2005/2006
Contacts
$ perl Contactez-nous.pl
Bonjour, je suis le script Contactez-nous.pl, et mon but est de vous permettre de contacter les auteurs du projet.
Merci de choisir votre option et d'entrer le mot-clé correspondant !
Question, remarque, problème -> Oups Message d'amour ou de soutien -> Love Message de haine, insultes -> ChameauxMot-clé :
love
Ooouh, comme c'est gentil ! Envoyez donc votre poème à axelcourt@gmail.com et marjorie.seizou@gmail.com en précisant dans le sujet "Vous êtes géniaux, je vous aime !".
Merci de m'avoir utilisé ! A bientôt peut-être !
Marjorie&Axel@pluriTAL ~
$
