Boîte à outils 4 : des textes aux graphes
Le but de cette boîte à outils est de proposer des visualisations sous forme de graphe à partir des relations de dépendance extraites dans la BAO3.
L'outil utilisé, Padagraph, a été développé par Pierre Magistry. Il requiert l'utilisation de données au format CSV qu'on redige directement du terminal vers
l'interface PadaGraph avec la commande "curl".
Script Python commenté
#pour lancer le script depuis le terminal:
#python3 bao4.py fichier_xml relation | curl -X POST -H 'Content-Type: text/csv' --data-binary @- "https://padagraph.magistry.fr/post_csv/salomechandora_rubrique"
import re
from pathlib import Path
import sys
#quand on lance le script, le premier argument est le fichier d'entrée (étiqueté par UDPipe) et le deuxième la relation
fic = sys.argv[1]
relation = sys.argv[2]
# on crée un buffer (dictionnaire) pour les phrases. La clé sera l'identifiant (indice) du mot dans la phrase et la valeur son lemme.
sent_buf = {}
#on crée un buffer (une liste) pour les dépendants qui contiendra des tuples de forme (lemme, gouverneur)
rel_buf = []
#on crée un set contenant les couples (tuples) de la forme (gouverneur, dépendant)
couples = set()
def nettoyage(s: str):
return re.sub('[^\w]', '', s)
for line in Path(fic).read_text().split("\n"):
#si la ligne commence par la balise <item> (c'est-à-dire qu'il s'agit d'un mot de la phrase)
if line.startswith("<item>"):
#les champs correspondent aux informations contenues dans ces balises: l'indice du mot dans la phrase, la forme, le lemme, le POS
#l'indice du gouverneur et le type de relation
#les champs "_" concernent les informations qui ne nous intéressent pas
fields = re.findall("<a>([^<]+)</a>", line)
idx, word, lemma, tag, _, _, head, rel, _, _ = fields
lemma = nettoyage(lemma)
#on ajoute au dictionnaire l'identifiant du mot comme clé et son lemme comme valeur
sent_buf[idx] = lemma
#si le champ "relation" est celui que l'on souhaite étudier
if rel == relation:
#on ajoute au buffer le tuple contenant le lemme du mot et l'identifiant de son gouverneur
rel_buf.append((lemma, head))
#si la ligne commence par la balise </p> (c'est-à-dire la fin d'une phrase)
if line == "</p>":
#on parcourt les tuples stockés dans le buffer
for dep_lemma, head in rel_buf:
#et on ajoute au set les tuples contenant le gouverneur et le dépendant
couples.add((f"{sent_buf[head]}", f"{dep_lemma}"))
#on réinitialise les buffers pour la nouvelle phrase
rel_buf = []
sent_buf = {}
#on affiche directement dans le terminal : Padagraph récupérera les données directement grâce àla commande Bash
print("@Gouv: #id, label")
for lemme in {gov for gov, _ in couples}:
print(f'g_{lemme},{lemme}')
print("@Dep: #id, label")
for lemme in {dep for _, dep in couples}:
print(f'd_{lemme},{lemme}')
print(f"_{relation}:")
for gouv, dep in couples:
print(f"g_{gouv},--,d_{dep}")
Pour télécharger le script Python : Script Python
RELATION OBJ

POUR LA RUBRIQUE INTERNATIONAL:
- Projet: sans grande surprise, les verbes qui ont pour objet "projet" sont assez classiques. Les projets dont il est question semblent être à la fois des projets parlementaires ("adopter", "retarder") et des projets économiques ("financer", "lancer"). On peut lire à travers ce graphe les difficultés liées au passage d'un projet de loi ("retarder", "menacer", "ralentir", "rejeter").
- Pays: les verbes associés au mot "pays" sont plutôt négatifs. On peut penser que cela est dû au contexte de pandémie : de nombreux pays ont dû faire face au manque d'infrastructures, aux pénuries de personnel soignant et aux nombreux décès causés par le virus. C'est ce que semblent suggérer les verbes "submerger", "endeuiller" ou "replonger". On pourrait aussi penser que le verbe "replonger" fait référence à la reprise de l'Afghanistan par les Talibans. On voit cependant une tendance inverse avec des verbes plus positifs comme "devenir", "hisser" ou "regagner", qui font peut-être référence à l'atténuation de l'épidémie et aux conséquence positives de celle-ci.
- Gouvernement: Les résultats obtenus sont assez cohérents avec la BAO3. Nous avons vu que de nombreuses élections présidentielles avaient eu lieu en 2021. Cela se confirme avec la présence des verbes "former", "choisir" et "promet".
- Million: Le mot "million" semble se référer à des sommes et non à des morts comme le laissait penser les résultats de la BAO3. Là encore, on peut penser que ce mot est lié au contexte de la pandémie puisque les Etats ont fait de nombreuses dépenses pour maintenir l'économie à flot ("dépenser", "offrir", "régler", "coûter", "débourser"...). Le verbe "infecter" fait sûrement référence au virus qui a touché des millions de personnes en 2021.

POUR LA RUBRIQUE ECONOMIE:
- Million: Comme dans la rubrique International, on peut voir que le mot "million" est lié à la pandémie. Les verbes "injecter" et "débloquer" semblent faire référence au soutien financier de l'Etat aux entreprises pour faire face à la pandémie. Cependant, d'autres verbes sont plus difficiles à interpréter car on ne connaît pas le contexte ("rallier", "former", "susciter", "accueillir"...).
- Risque: Dans un contexte de pandémie, où l'économie a beaucoup souffert, la présence des verbes "augmenter", "peser", "rester" ou "planer" n'est pas suprenante. La rubrique semble donc dépeindre une situation plutôt négative. Cependant l'expression "prendre des risques" est très fréquente. Cela pourrait aussi signifier une relance de l'économie post-Covid ainsi que de l'innovation de la part des entreprises.
- Projet: Les verbes associés à "projet" sont relativement similaires à ceux de la rubrique International. Les projets sont soit acceptés ("s'imposer", "concrétiser", "déployer") soit abandonnés ("rejeter", "abandonner", "remiser", "ralentir"...). Ces verbes ne sont donc pas liés à un contexte précis. On peut cependant voir qu'il y a une plus forte dimension d'innovation que dans la rubrique 3210, probablement liée au monde des entreprises ("concrétiser", "s'imposer", "mener"...)

POUR LA RUBRIQUE IDEES:
- Pays: Comme dans la rubrique International, les verbes qui ont pour objet "pays" sont assez négatifs ("replonger", "diviser", "fuir", "toucher"...). Mais ont voit tout de même des verbes plus positifs et tournés vers l'avenir comme "devenir", "assurer" ou "apaiser".
- Président: Les verbes les plus intéressants à mon sens sont "compromettre", "interpeller" et "dénoncer". Cette rubrique semble être plutôt tournée vers la France. On pourrait donc rattacher ces expressions aux mouvements sociaux qui ont touché le pays ainsi que le mécontentement croissant envers le président Emmanuel Macron, surtout dans un contexte pré-électoral.
- France: Ce qui ressort de cette rubrique est un besoin de protection comme le montrent les verbes "protéger" et "sauver". Là encore on peut supposer que les menaces touchant la France sont celles liées à la pandémie, mais il faudrait pouvoir voir les passages en question pour s'en assurer.
RELATION NSUBJ

POUR LA RUBRIQUE INTERNATIONAL:
- Président: Conformément à l'image du pouvoir exécutif, les verbes qui ont ce mot pour sujet sont globalement des verbes d'action. On y retrouve "signaler", "renforcer", "engager" ou "reprocher". Les verbes "menacer" et "brandir" sont agressifs et pourraient faire référence, si l'on se fie aux autres rubriques, au comportement bélliqueux de pays comme la Russie.
- Etats-Unis: Les Etats-Unis sont vus d'une manière plutôt favorable si l'on s'en tient aux verbes "s'engager", "promettre", "défendre" ou "opérer". Le pays est présenté comme actif sur la scène internationale, n'hésitant pas à "condamner" ou "sanctionner" les comportements d'autres Etats.
- Chine: Comme indiqué dans la BAO3, la rubrique International laisse une grande part à la Chine et aux Etats-Unis, ennemis historiques. Cependant, les verbes associés à la Chine sont plutôt neutres. L'influence de la pandémie est visible, avec la présence des verbes "enregistrer" (nombre de malades ou de morts) et "inoculer".
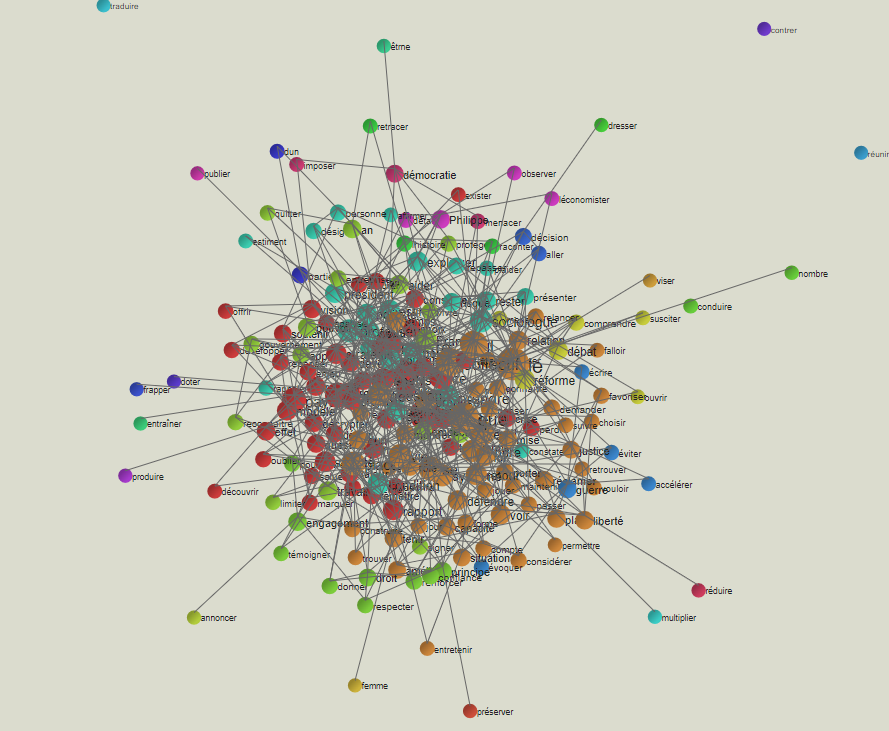
POUR LA RUBRIQUE ECONOMIE:
- Gouvernement: Comme le président dans la rubrique 3210, le gouvernement a un rôle actif dans l'économie. Les verbes "autoriser", "préparer", "travailler" et "approuver" le montrent. La présence du verbe "subventionner" fait peut-être référence au rôle accru de l'Etat pendant la pandémie et aux nombreuses aides accordées aux secteurs touchés en France.

POUR LA RUBRIQUE IDEES:
- Devoir: Comme mentionné précédemment, la rubrique Idées semble se composer d'interventions d'intellectuels et spécialistes donnant leur point de vue sur différents thèmes. L'association du mot "devoir" avec "Joe"(Biden), "l'Allemagne", "vaccin", ou "Afghanistan" montrent que les experts exposent ce qui, selon leur avis, devrait être fait.
- Politique: Il est intéressant de voir que le mot "politique" fait partie des mots importants de cette rubrique. Cela signifie que l'on s'intéresse à la politique en tant que domaine assez abstrait, et correspond bien au rejet du monde politique, vu comme éloigné des réalités de la vie par de nombreux Français. En effet, les verbes "changer", "détruire", et "responsable" semblent le confirmer. Il est aussi important de noter la présence de l'adjectif "sanitaire", qui est fortement lié au contexte de pandémie et aux mesures, souvent controversées, prises par le gouvernement.
- France: Comme pour la relation OBJ, la France apparaît comme une abstraction. Les mots "mériter", "doit" ou encore "besoin" montrent là encore que les auteurs de la rubrique expriment un idéal qu'ils ont du pays, et ce qu'il faudrait faire pour le respecter.